现代深度学习模型和技术
Transformer模型的理解和应用
Transformer模型自2017年由Vaswani等人在论文《Attention is All You Need》中提出以来,已经彻底改变了自然语言处理(NLP)领域的面貌。Transformer的核心是自注意力(Self-Attention)机制,它使模型能够在处理序列数据时,直接关注到序列中任意位置的元素,从而捕获丰富的上下文信息。这一特性不仅解决了传统循环神经网络(RNN)中的长距离依赖问题,也大大提高了模型的并行处理能力。
Transformer的核心组件
- 自注意力(Self-Attention):允许模型在处理某个元素时,考虑到序列中所有元素的信息,并根据这些信息动态地调整自己对每个元素的关注程度。
- 多头注意力(Multi-Head Attention):是自注意力的扩展,它将输入分割成多个“头”,分别进行自注意力计算,然后将结果合并。这样可以让模型在不同的表示子空间中捕获信息。
- 位置编码(Positional Encoding):由于自注意力机制本身不考虑序列中元素的位置信息,位置编码通过为每个元素添加位置信息来解决这个问题,使模型能够利用序列的顺序。
- 前馈网络(Feed-Forward Networks):在每个Transformer块中,多头注意力的输出会被传递给一个前馈网络,这个网络对每个位置的输出都是独立处理的。
BERT的介绍
BERT(Bidirectional Encoder Representations from Transformers)是Google在2018年提出的一个基于Transformer的模型。它的创新之处在于使用了大量未标记文本通过双向Transformer编码器进行预训练,学习到的表示可以被用来改进各种NLP任务的性能。
BERT的关键特点
- 双向训练:传统的语言模型是单向的,而BERT通过掩码语言模型(MLM)任务实现了双向训练,这使得每个单词都能够根据上下文进行有效编码。
- 预训练和微调:BERT模型首先在大规模文本上进行预训练,然后可以通过在特定任务上进行微调来适应不同的NLP任务,如情感分析、问答等。
BERT的应用
由于BERT的预训练-微调范式,它可以被应用到几乎所有的NLP任务中,包括但不限于:
- 文本分类:如情感分析、意图识别等。
- 命名实体识别(NER):识别文本中的特定实体,如人名、地点、组织等。
- 问答系统:从一段给定的文本中找到问题的答案。
- 文本摘要:生成文本的简短版本,保留主要信息。
- 机器翻译:尽管BERT主要用于理解任务,它的表示也可以用来改进翻译模型。
使用BERT进行微调
使用BERT进行微调的一般步骤包括:
- 选择预训练的BERT模型:根据任务需求选择合适的预训练模型,如
bert-base-uncased。 - 准备数据集:将数据集格式化为适合BERT处理的格式,通常包括特定的标记,如
[CLS]和[SEP]。 - 微调模型:在特定的下游任务上微调BERT模型。这通常涉及添加一个或多个额外的输出层,然后在下游任务的数据集上训练整个模型。
- 评估和应用:评估微调后的模型在特定任务上的性能,并将其应用于实际问题。
BERT及其变体(如RoBERTa、ALBERT等)已经成为NLP领域的重要基石,它们的成功证明了Transformer架构在处理语言任务上的强大能力。
生成对抗网络(GAN)的原理和实现
生成对抗网络(GAN)是一种深度学习模型,由Ian Goodfellow于2014年提出。它由两部分组成:生成器(Generator)和判别器(Discriminator),通过对抗过程学习生成数据。
GAN的原理
GAN的核心思想是基于“博弈”的概念,让生成器和判别器相互竞争:
- **生成器(G)**的目标是生成尽可能接近真实数据的假数据。它试图“欺骗”判别器,让判别器认为其生成的数据是真实的。
- **判别器(D)**的目标是区分输入的数据是真实数据还是由生成器生成的假数据。
这个过程可以类比为伪造者(生成器)试图制造假币,并使其尽可能地看起来像真币,而鉴别者(判别器)则试图区分开真币和假币。
训练过程
GAN的训练过程涉及以下步骤:
- 训练判别器:固定生成器,用真实数据和生成的假数据训练判别器,使其能够区分真假数据。
- 训练生成器:固定判别器,更新生成器的参数,使得生成的假数据在判别器看来更加“真实”。
这个训练过程可以表示为一个最小化最大化问题(minimax game),目标函数为:
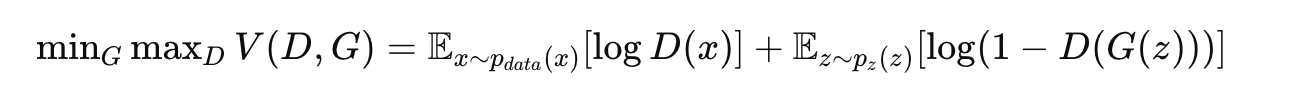
其中,x 是真实数据,z 是生成器的输入噪声。
实现示例
以下是使用PyTorch实现一个简单的GAN模型的基本步骤:
1. 定义模型
首先,定义生成器和判别器。这里以最简单的全连接网络为例:
import torch
import torch.nn as nnclass Generator(nn.Module):def __init__(self, input_size, hidden_dim, output_size):super(Generator, self).__init__()self.net = nn.Sequential(nn.Linear(input_size, hidden_dim),nn.ReLU(True),nn.Linear(hidden_dim, output_size),nn.Tanh())def forward(self, x):return self.net(x)class Discriminator(nn.Module):def __init__(self, input_size, hidden_dim):super(Discriminator, self).__init__()self.net = nn.Sequential(nn.Linear(input_size, hidden_dim),nn.LeakyReLU(0.2),nn.Linear(hidden_dim, 1),nn.Sigmoid())def forward(self, x):return self.net(x)
2. 训练模型
训练GAN涉及到同时更新生成器和判别器的参数:
# 伪代码,用于展示训练流程的基本思想
for epoch in range(num_epochs):for data in dataloader:# 1. 训练判别器real_data = datafake_data = generator(noise)d_loss = -torch.mean(torch.log(discriminator(real_data)) + torch.log(1 - discriminator(fake_data)))d_loss.backward()update(discriminator.parameters())# 2. 训练生成器fake_data = generator(noise)g_loss = -torch.mean(torch.log(discriminator(fake_data)))g_loss.backward()update(generator.parameters())
应用
GAN被广泛应用于各种领域,包括但不限于:
- 图像合成:生成逼真的人脸、风景等图像。
- 图像转换:风格迁移、年龄变换、图像修复等。
- 数据增强:为小数据集生成新的训练样本。
- 文本到图像的转换:根据文本描述生成相应的图像。
GAN的训练是具有挑战性的,可能会遇到模式崩溃(mode collapse)、训练不稳定等问题。因此,研究人员提出了许多技巧和改进版本的GAN,如CGAN、DCGAN、WGAN等,以提高模型性能和训练稳定性。
深度学习在特定领域的应用
深度学习技术在多个领域内的应用已经取得了显著的进展,尤其是在自然语言处理(NLP)、计算机视觉和强化学习这三个领域。以下是这些领域的一些关键应用和相关技术的概览。
自然语言处理(NLP)
NLP是深度学习应用最为广泛的领域之一,涉及理解、解释和生成人类语言的任务。
- 机器翻译:使用序列到序列(seq2seq)模型,如Transformer,实现从一种语言自动翻译到另一种语言。
- 情感分析:利用卷积神经网络(CNN)或循环神经网络(RNN)来分析文本数据中的情感倾向。
- 问答系统:基于BERT等预训练语言模型,构建能够理解自然语言问题并提供准确答案的系统。
- 文本摘要:使用注意力机制的seq2seq模型自动生成文档的摘要。
计算机视觉
计算机视觉是深度学习应用的另一个重要领域,旨在使计算机能够“看”和理解图像和视频。
- 图像分类:使用卷积神经网络(如AlexNet、VGG、ResNet)来识别图像中的对象。
- 目标检测:使用R-CNN、SSD、YOLO等模型在图像中识别和定位多个对象。
- 图像分割:应用如U-Net、Mask R-CNN等模型实现像素级的图像理解,区分图像中的每个对象及其轮廓。
- 图像生成:使用生成对抗网络(GANs)生成逼真的图像,如风格转换、图像修复。
强化学习
强化学习关注如何基于环境反馈进行决策和学习,它在游戏、机器人、自动驾驶等领域有着广泛的应用。
- 游戏:DeepMind的AlphaGo和OpenAI的OpenAI Five利用深度强化学习技术在围棋、Dota 2等复杂游戏中达到了超越人类的水平。
- 机器人:应用深度强化学习进行机器人的控制和自主学习,使其能够执行抓取、行走等任务。
- 自动驾驶:利用强化学习技术训练自动驾驶汽车在各种环境中做出决策。
结论
深度学习的这些应用展示了其在理解复杂模式、处理大规模数据集方面的强大能力。随着技术的进步和更多研究的进行,深度学习预计将在这些领域及其它领域开辟更多的应用前景。尽管如此,深度学习也面临着挑战,如模型的可解释性、数据的隐私和安全问题、以及算法的偏见和公平性问题。解决这些问题需要跨学科的合作和持续的研究努力。
项目实践
使用预训练的Transformer模型进行文本分类或问答任务
使用预训练的Transformer模型进行文本分类或问答任务是近年来自然语言处理(NLP)领域的一个重要趋势。预训练模型,如BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-trained Transformer)和RoBERTa(Robustly Optimized BERT Approach),通过在大规模文本数据上学习语言的通用特征,已经在多个NLP任务上取得了突破性的成果。以下是使用这些预训练Transformer模型进行文本分类和问答任务的基本步骤:
文本分类任务
文本分类任务的目标是将文本文档分配到一个或多个类别中。例如,情感分析是一种文本分类任务,旨在判断文本的情感倾向是正面还是负面。
步骤
-
选择预训练模型:根据任务需求选择合适的预训练模型。例如,BERT和RoBERTa对于文本分类任务表现良好。
-
数据准备:格式化数据集,确保输入格式符合模型的要求。通常需要将文本转换为模型能够理解的格式,包括添加特殊标记(如
[CLS]和[SEP]标记),并将文本转换为模型的词汇表中的ID。 -
微调模型:虽然预训练模型已经学习了丰富的语言表示,但通过在特定任务的数据集上进行微调,可以进一步优化模型以适应特定任务。这通常涉及添加一个针对特定任务的输出层(如一个全连接层用于分类)。
-
训练和评估:在训练数据上训练模型,并在验证集上评估模型的性能。根据需要调整微调的参数和训练设置。
问答任务
问答(QA)任务要求模型根据给定的问题和上下文来生成或选择答案。一些模型,如BERT,可以通过预测文本中答案的起始和结束位置来处理抽取式问答任务。
步骤
-
选择预训练模型:BERT等模型因其理解上下文的能力而特别适用于问答任务。
-
数据准备:准备数据,其中每个样本包括一个问题、一个包含答案的上下文段落,以及答案的起始和结束位置。数据需要被转换成模型能理解的格式。
-
微调模型:在问答数据集上微调模型。通常需要自定义模型的头部,使其能够预测答案在上下文中的位置。
-
训练和评估:与文本分类类似,你需要在训练数据上训练模型,并在验证集或测试集上评估其性能。
实现
大多数深度学习框架和库,如Hugging Face的Transformers库,提供了这些预训练模型的易用接口,使得加载预训练模型、微调和评估变得非常简单。例如,使用Transformers库进行微调时的代码大致如下:
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import AdamW, get_linear_schedule_with_warmup# 加载预训练模型和分词器
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')# 数据准备和预处理...# 微调模型
optimizer = AdamW(model.parameters(), lr=2e-5)# 训练循环...
使用预训练的Transformer模型进行文本分类或问答任务,不仅可以利用模型学习到的丰富语言表示,还可以显著提高特定任务的性能,这已经成为当下NLP领域的标准做法。
设计并训练一个GAN生成新的图像
设计并训练一个生成对抗网络(GAN)来生成新图像涉及几个关键步骤,从构建模型架构到训练流程,再到评估生成图像的质量。下面是一个简化的流程,展示如何使用PyTorch框架来实现这一过程。
步骤 1: 构建模型
生成器(Generator)
生成器的目标是接受一个随机噪声向量作为输入,并生成一张图像。这个过程通常通过使用多个转置卷积层(也称为反卷积层)来实现,每个层次都会逐渐放大特征图,最终生成与真实图像同样大小的图像。
import torch
import torch.nn as nnclass Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.model = nn.Sequential(# 输入是一个噪声n维向量nn.ConvTranspose2d(in_channels=100, out_channels=1024, kernel_size=4, stride=1, padding=0),nn.BatchNorm2d(1024),nn.ReLU(True),nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(512),nn.ReLU(True),nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(256),nn.ReLU(True),nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(128),nn.ReLU(True),nn.ConvTranspose2d(in_channels=128, out_channels=3, kernel_size=4, stride=2, padding=1),nn.Tanh()# 输出是一个3通道的图像)def forward(self, x):return self.model(x)
判别器(Discriminator)
判别器的目标是判断输入的图像是真实图像还是由生成器生成的假图像。这通常通过一个标准的卷积神经网络来实现,网络的最后输出一个单一的标量表示图像的真假。
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(# 输入是一个3通道的图像nn.Conv2d(in_channels=3, out_channels=128, kernel_size=4, stride=2, padding=1),nn.LeakyReLU(0.2),nn.Conv2d(in_channels=128, out_channels=256, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(256),nn.LeakyReLU(0.2),nn.Conv2d(in_channels=256, out_channels=512, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(512),nn.LeakyReLU(0.2),nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(0.2),nn.Conv2d(in_channels=1024, out_channels=1, kernel_size=4, stride=1, padding=0),nn.Sigmoid()# 输出是一个标量,表示图像的真假)def forward(self, x):return self.model(x).view(-1, 1).squeeze(1)
步骤 2: 训练模型
训练GAN包括同时训练生成器和判别器,让生成器生成越来越逼真的图像,而让判别器更好地区分真假图像。
# 初始化模型
generator = Generator()
discriminator = Discriminator()# 优化器
optimizer_g = torch.optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_d = torch.optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))# 损失函数
criterion = nn.BCELoss()# 训练过程
for epoch in range(num_epochs):for i, data in enumerate(dataloader, 0):# 训练判别器# ...# 训练生成器# ...
在训练过程中,对判别器,首先使用真实图像训练并最大化对真实图像分类正确的概率,然后使用生成的假图像训练并最大化对假图像分类正确的概率。对生成器,使用判别器的反馈来更新生成器的权重,以生成更逼真的图像。
步骤 3: 评估和使用模型
生成器训练完成后,就可以用它来生成新的图像了。通常,通过向生成器输入随机噪声向量,生成器会输出新的图像。
注意事项
- 模式崩溃:这是训练GAN时可能遇到的问题,其中生成器开始生成非常少的不同输出。
- 平衡:训练过程中保持生成器和判别器之间的平衡是很重要的。
GAN的训练是具有挑战性的,需要仔细调整超参数和训练策略。不过,成功训练的GAN能够在多种任务上生成高质量的结果,从图像生成到艺术创作等。
相关文章:
现代深度学习模型和技术
Transformer模型的理解和应用 Transformer模型自2017年由Vaswani等人在论文《Attention is All You Need》中提出以来,已经彻底改变了自然语言处理(NLP)领域的面貌。Transformer的核心是自注意力(Self-Attention)机制…...

go的orm框架-Gorm
官网文档 特点 全功能 ORM 关联 (拥有一个,拥有多个,属于,多对多,多态,单表继承) Create,Save,Update,Delete,Find 中钩子方法 支持 Preload、Joins 的预加载 事务&…...
嵌入式开发学习---(部分)数据结构(无代码)
数据结构 为什么学习数据结构? 1)c语言告诉如何写程序,数据结构是如何简洁高效的写程序 2)遇到一个实际问题,需要写程序去实现相应功能,需要解决那两个方面的问题? 如何表达数据之间的逻辑规律…...
ChatGPT 之联盟营销
原文:ChatGPT for Affiliate Marketing 译者:飞龙 协议:CC BY-NC-SA 4.0 第二章 制定转化对话 制定转化对话是每个营销人员和企业所有者都应该掌握的关键技能。它涉及创建和传递引人入胜的信息,吸引您的受众并激励他们采取行动。…...

1.k8s简介
目录 k8s是什么 k8s不是什么 云原生 微服务 整体式架构与微服务架构 微服务的特性 微服务的优势 k8s是什么 Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快…...
go包下载时报proxyconnect tcp: dial tcp 127.0.0.1:80: connectex错误的解决方案
一大早的GoLand就开始抽风了,好几个文件import都红了,于是我正常操作点击提示的sync,但是却报了一堆错: go: downloading google.golang.org/grpc v1.61.1 go: downloading google.golang.org/genproto v0.0.0-20240228224816-df9…...

Vaadin框架是如何处理前后端交互的?列举几个Vaadin中常用的UI组件,并描述它们的作用。如何使用Vaadin的布局管理器来构建复杂的用户界面?
Vaadin框架是如何处理前后端交互的? Vaadin框架处理前后端交互的方式主要基于服务端渲染和事件驱动的编程模型。以下是具体的处理过程: 服务端渲染:Vaadin应用程序的UI组件是在服务器端创建和渲染的。当用户在浏览器中访问应用程序时&#x…...
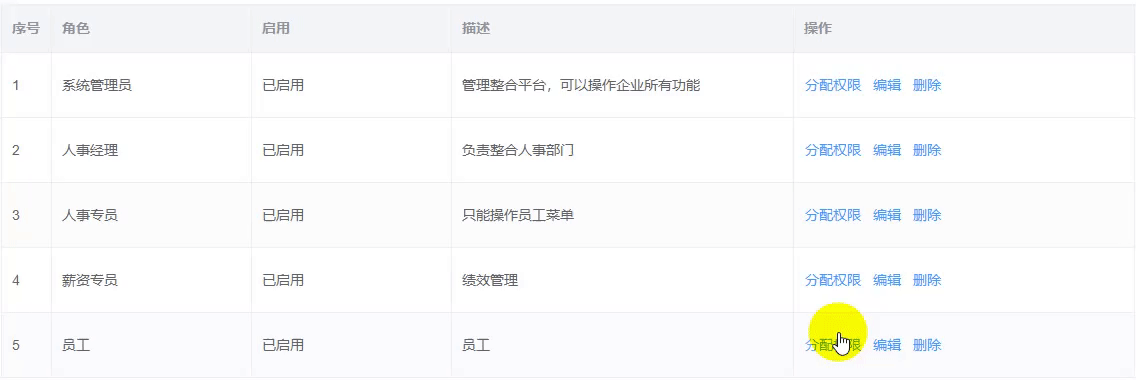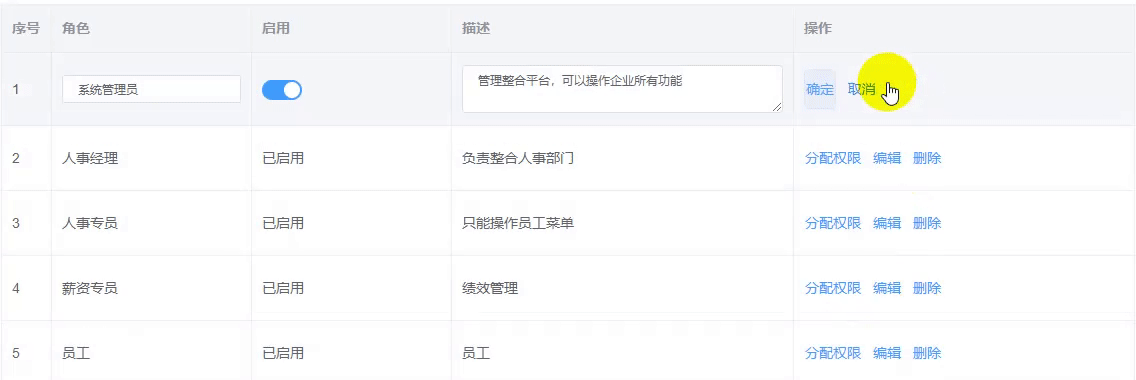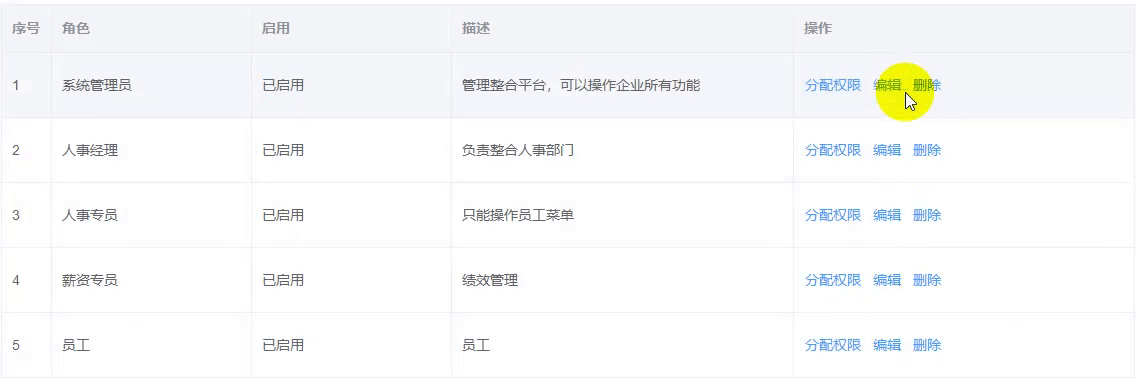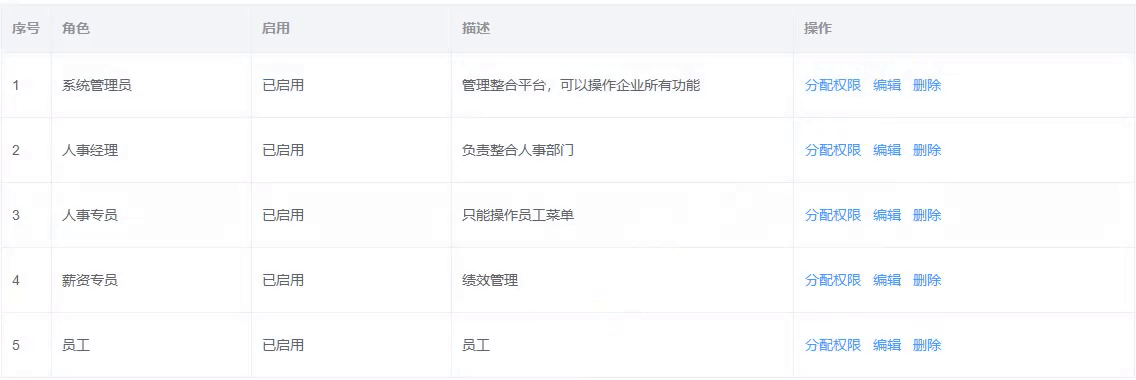
动态属性的响应式问题和行内编辑的问题
动态属性的响应式问题 通过点击给目标添加动态数据,该数据不具备响应式特性 如下图: 点击编辑,前面的数据框会变成输入框,点取消会消失 // 获取数据 async getList () {const res await xxxthis.list res.data.rows// 1. 获…...
)
微信小程序第六次课(模块化和绑定事件)
模块化 1.首先 我们在utils里面创建一个新的js文件 2.新的js文件里面写我们要实现的函数功能 3.把新的函数功能 通过 module.export.对外公开文件名 新文件名 的方式把之前的函数公开到其他他模块 (类似于public 让别的模块可以…...
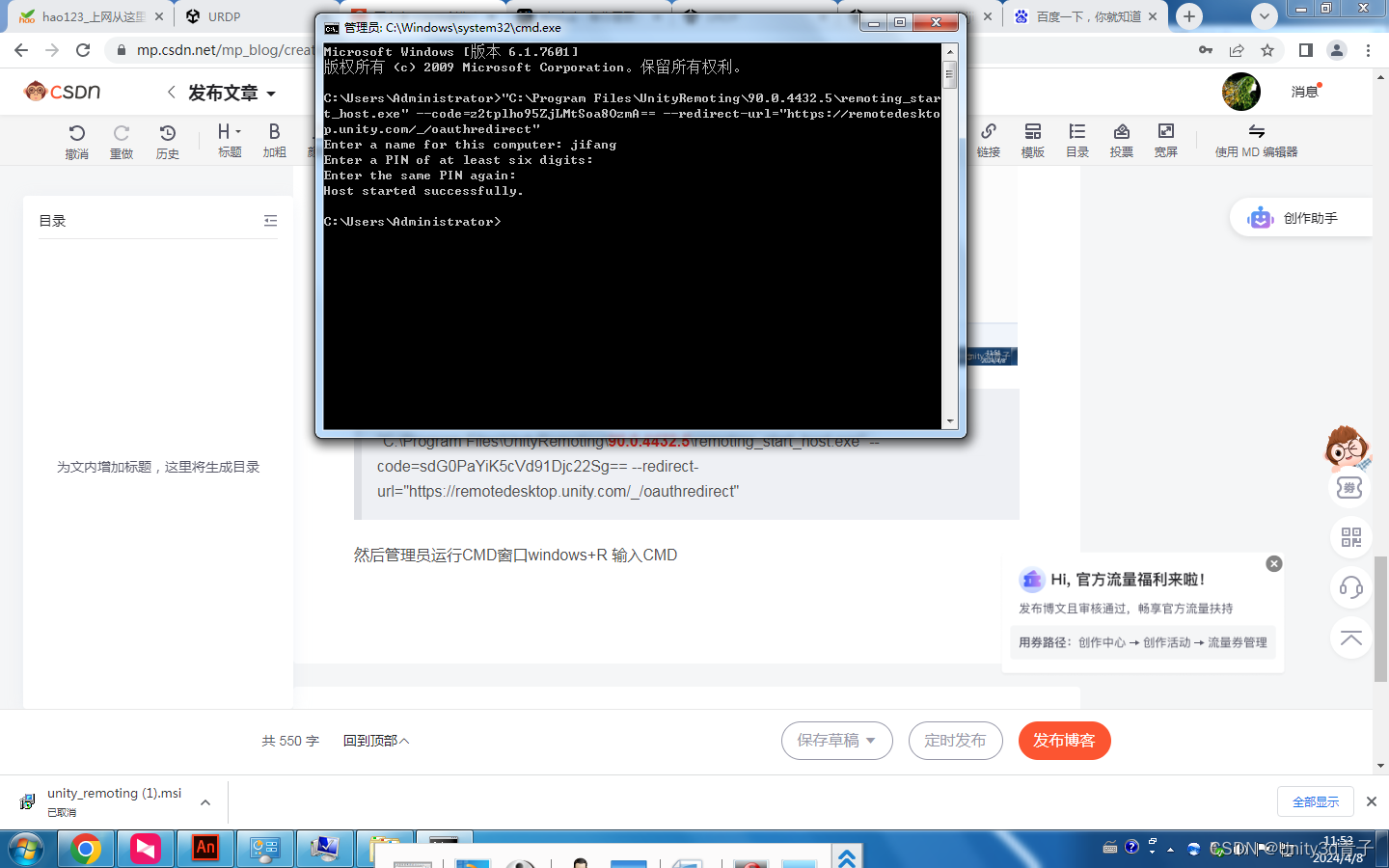
【Unity添加远程桌面】使用Unity账号远程控制N台电脑
设置地址: URDP终极远程桌面;功能强大,足以让开发人员、设计师、建筑师、工程师等等随时随地完成工作或协助别人https://cloud-desktop.u3dcloud.cn/在网站登录自己的Unity 账号上去 下载安装被控端安装 保持登录 3.代码添加当前主机 "…...

maven的settings.xml、pom.xml配置文件
1、配置文件 maven的配置文件主要有 settings.xml 和pom.xml 两个文件。 其中在maven安装目录下的settings.xml,如:D:\Program Files\apache-maven-3.6.3\conf\settings.xml 是全局配置文件 用户目录的.m2子目录下的settings.xml,如&#…...
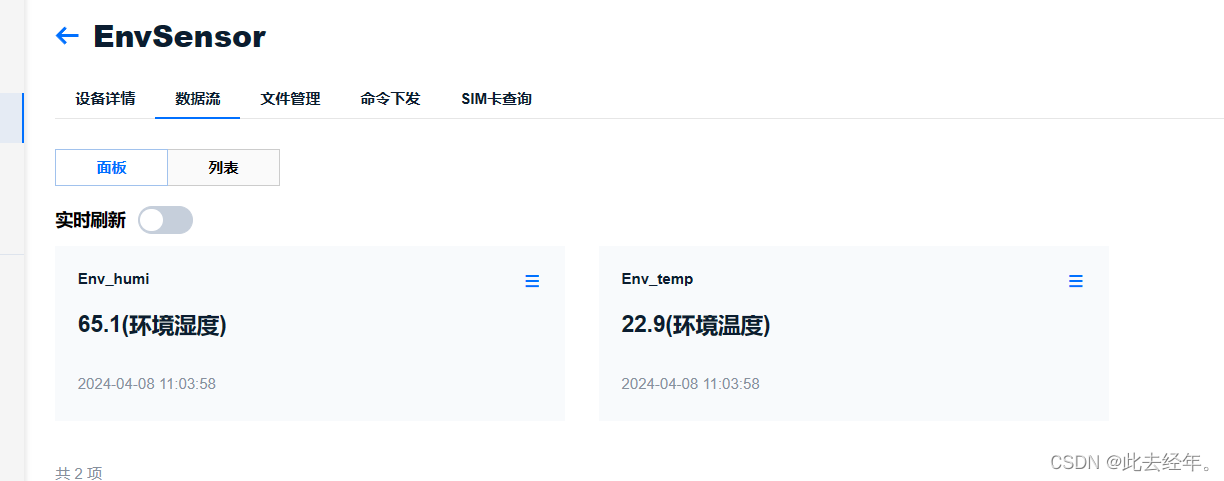
使用MQTT.fx接入新版ONENet(24.4.8)
新版ONENet使用MQTT.fx 模拟接入 目录 新版ONENet使用MQTT.fx 模拟接入开始前的准备创建产品设备获取关键参数 计算签名使用MQTT.fx连接服务器数据流准备与上传数据流准备数据发送与接收 开始前的准备 创建产品 设备下载Token签名工具生成签名 创建产品设备 根据以下内容填写…...

Selenium 自动化遇见 shadow-root 元素怎么处理?
shadow-root是前端的特殊元素节点,其使用了一个叫做shadowDOM的技术做了封装,shadowDOM的作用可以理解为在默认的DOM结构中又嵌套了一个DOM结构(和iframe有点类似,只不过iframe内嵌的是HTML),我们遇见shado…...

软件系统质量属性_2.面向架构评估的质量属性
为了评价一个软件系统,特别是软件系统的架构,需要进行架构评估。在架构评估过程中,评估人员所关注的是系统的质量属性。评估方法所普遍关注的质量属性有:性能、可靠性、可用性、安全性、可修改性、功能性、可变性、互操作性。 1.…...

设计模式:抽象工厂
定义 抽象工厂模式是一种创建型设计模式,它提供了一个接口,用于创建一系列相关或相互依赖的对象,而无需指定它们具体的类。这种模式特别适用于处理产品族,但在不可能修改的情况下扩展产品族是困难的。 应用场景 抽象工厂模式通…...
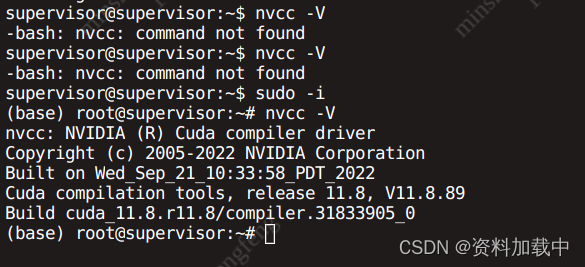
【环境搭建】ubuntu工作站搭建全流程(显卡4090)
安装ubuntu22.04系统 首先,先压缩windows分区,按住Win X快捷键,选择磁盘管理,压缩分区,压缩出新的分区用于安装ubuntu22.04 windows插入系统盘,点击重启,一直按F12,选择系统盘启动方式语言选择chinese–…...
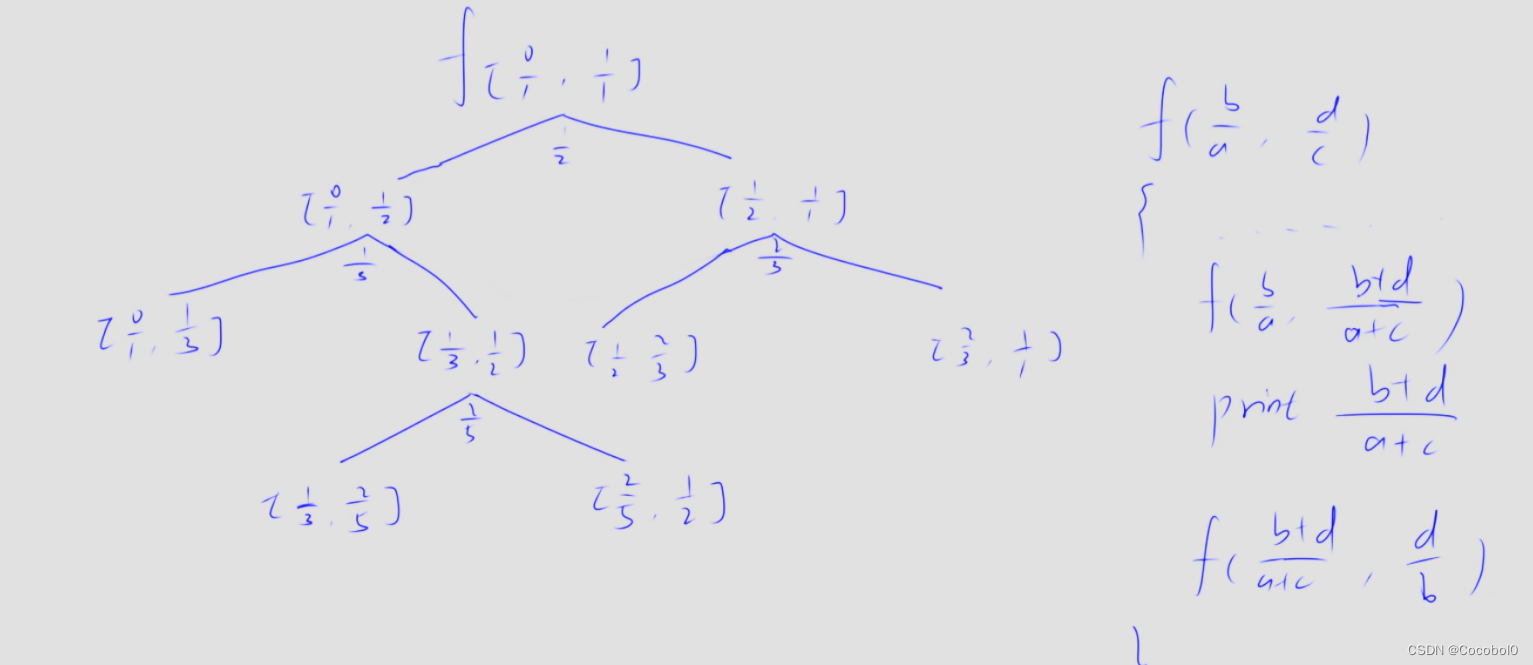
蓝桥杯每日一题:有序分数(递归)
给定一个整数 N,请你求出所有分母小于或等于 N,大小在 [0,1] 范围内的最简分数,并按从小到大顺序依次输出。 例如,当 N5 时,所有满足条件的分数按顺序依次为: 0/1,1/5,1/4,1/3,2/5,12/,35,2/3,3/4,4/5,1/…...
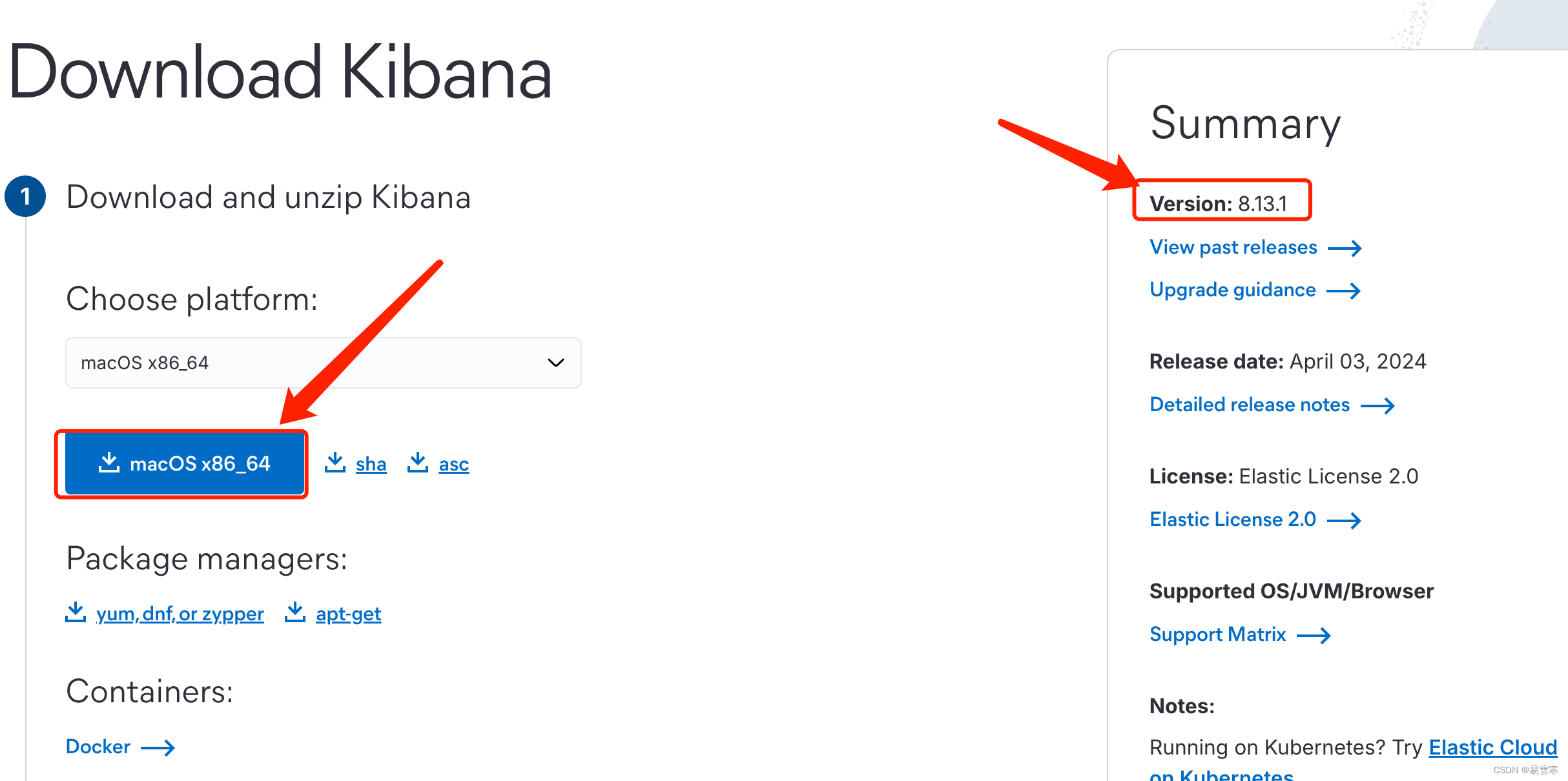
SpringBoot学习之Kibana下载安装和启动(Mac版)(三十二)
一、简介 Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。 …...
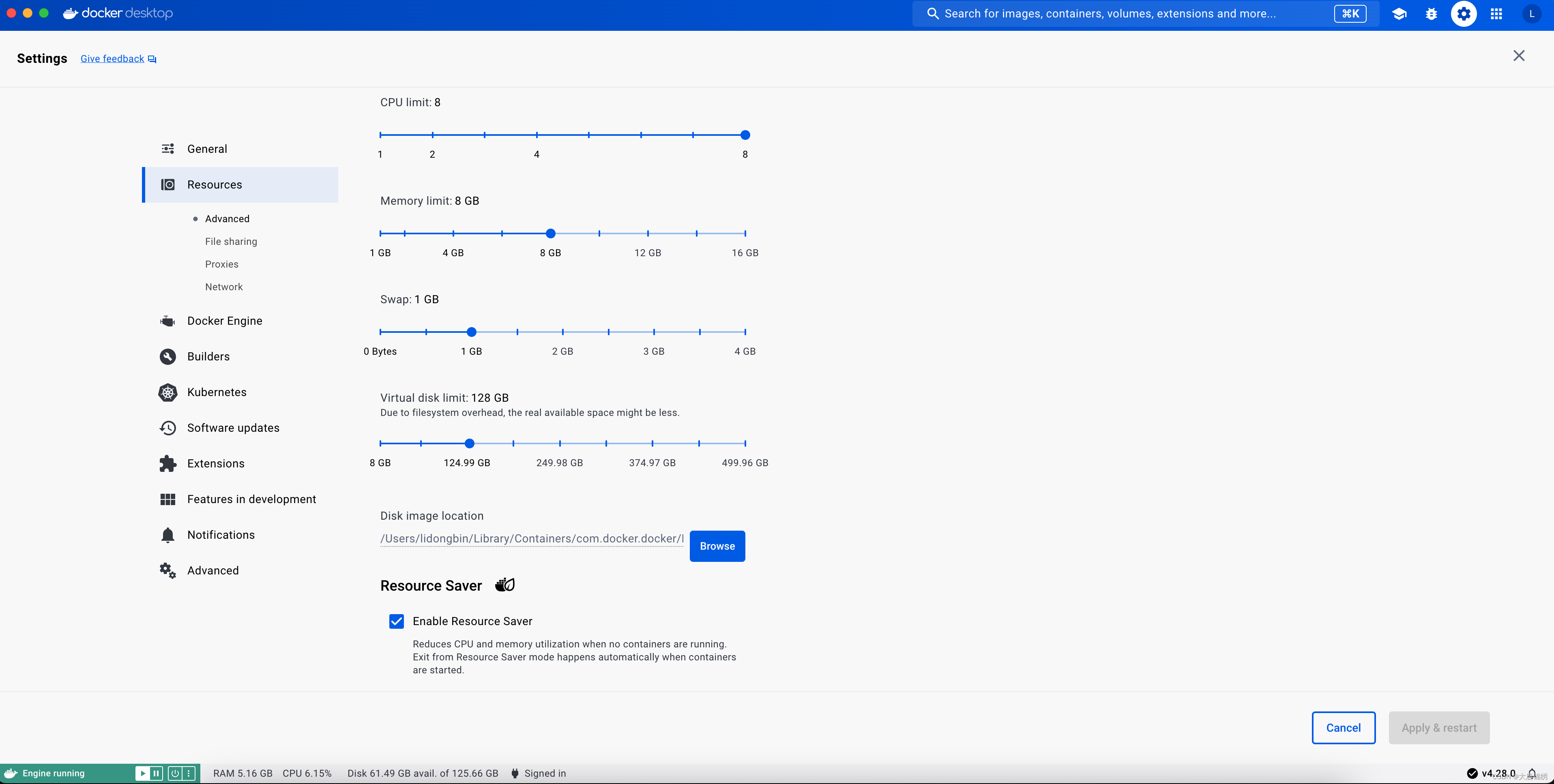
Mac下Docker Desktop starting的解决方法
记录下自己在新增了一个新的容器后,Disk Size过大导致启动Docker Desktop会一直卡在Docker Desktop starting,并且重启无效的解决方法。该方法无需重新卸载,并且能保留原有的镜像和容器。 一、确认问题 首先确认Docker.raw大小以确认是否和笔…...

Leetcode面试经典150_Q80删除有序数组中的重复项 II
题目: 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件…...
完整解析)
埃拉托斯特尼筛法(埃氏筛)完整解析
一、算法用途 快速找出 2 ~ n 之间的所有素数。 暴力判断每个数:O(nn) 埃氏筛:O(nloglogn),接近线性,极快。 二、核心思想 先假设所有数都是素数。 从最小素数 2 开始,把它的所有倍数标记为合数。 取下一个没被标记的数(一定是素数),继续标记它的倍数。 最后没被标记…...

【实验原理深度解析】弗兰克-赫兹实验:如何用电子“碰撞”揭示原子能级的秘密
1. 电子与原子的"对话":弗兰克-赫兹实验的设计哲学 想象你站在一个漆黑的房间里,向对面墙壁投掷网球。如果墙壁是实心的,球会直接弹回;但如果墙上有一排高度不同的窗口,球只有达到特定速度才能穿过对应高度的…...

基于AkShare构建A股基础数据自动化采集方案
1. 为什么需要自动化采集A股基础数据 做量化研究的朋友都知道,获取准确、完整的股票基础数据是策略开发的基石。我刚开始做量化时,最头疼的就是每次跑策略前都要手动更新股票列表,经常因为数据不全导致回测结果失真。后来发现AkShare这个宝藏…...

告别复杂配置!OSHI+JNA五分钟搞定Windows/Linux/macOS硬件信息采集
五分钟极简指南:用OSHIJNA实现全平台硬件监控零门槛接入 运维工程师小张最近接手了公司混合云环境下的服务器监控任务。当他面对Windows服务器、Linux虚拟机、macOS开发机三种不同系统时,传统方案需要分别调用WMI、/proc文件系统和system_profiler&#…...

Nunchaku-FLUX.1-dev开源大模型部署案例:电商素材批量生成零API成本
Nunchaku-FLUX.1-dev开源大模型部署案例:电商素材批量生成零API成本 1. 引言 如果你正在经营一家电商店铺,或者从事内容创作、设计工作,那么对图片素材的需求一定不小。从商品主图、详情页配图,到社交媒体海报、广告素材&#x…...

赋能音乐自由:Unlock Music技术解密与全场景应用指南
赋能音乐自由:Unlock Music技术解密与全场景应用指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:…...

4个维度解析Lenovo Legion Toolkit:游戏本性能管理的轻量革命
4个维度解析Lenovo Legion Toolkit:游戏本性能管理的轻量革命 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 1.…...

Agent的决策模糊
文章目录Langchian Agent内部记忆:信息过载LLM注意力有限的解释:上下文窗口长度很大,会有这种问题么对比langGraphLangchian Agent内部记忆: 官方 ReAct 内部机制(铁律) LangChain 的 AgentExecutor 在一次 invoke () 内部&#…...

实战演练:基于快马平台生成学生成绩排名系统,掌握排序算法应用
最近在做一个学生成绩管理系统的实战项目,其中排序功能是核心模块。通过这个项目,我深刻体会到排序算法在实际应用中的重要性。下面分享一下我的实现思路和经验总结。 学生类设计 首先需要定义一个学生类,包含学号、姓名、各科成绩和总成绩等…...

SpringBoot3.3.1+Elasticsearch8.13.4日期转换踩坑实录:LocalDateTime保存为时间戳的完整方案
SpringBoot3.3.1与Elasticsearch8.13.4时间类型转换实战:从踩坑到优雅解决 最近在升级技术栈到SpringBoot3.3.1时,发现与Elasticsearch8.13.4的集成出现了一个棘手的问题:LocalDateTime类型在保存和查询时表现异常。这让我花了整整两天时间排…...