SRNIC、选择性重传、伸缩性、连接扩展性、RoCEv2优化(六)
参考论文SRDMA(A Scalable Architecture for RDMA NICs ):https://download.csdn.net/download/zz2633105/89101822
借此,对论文内容总结、加以思考和额外猜想,如有侵权,请联系删除。
如有描述不当之处,欢迎留言指正,拜谢!
概述
RDMA 被期望具有高度的可扩展性:在不可避免存在丢包的大规模数据中心网络中表现良好(高网络可伸缩性),并支持每个服务器的大量高性能连接(高连接可伸缩性)。商用 RoCEv2 网卡(rnic)由于依赖于无损的、有限规模的网络结构,缺乏可伸缩性,并且只支持少量的性能连接。最近的研究IRN通过放宽无丢包网络的要求来提高网络的可扩展性,但连接的可扩展性问题仍未得到解决。
本文描述旨在提高网络可伸缩性及连接可扩展性。
伸缩性
商用RoCEv2网卡基于目前以太网络设施部署,需要 PFC 来实现无损网络结构,基于优先级的流控制(PFC)引起了网络可伸缩性问题。 PFC 带来了诸如离线阻塞、拥塞扩散、偶尔死锁和大规模集群中的 PFC 风暴等问题 。因此,数据中心运营商倾向于将 PFC 配置限制在较小的网络范围内(例如,中等规模的集群)。
RoCEv2网卡通过特殊处理明显改善网络状况,方案有两种:1)引入额外内存开销的方案;2)扩展IB协议的选择性重传方案。
通过引入额外内存开销的方案
核心思想是:通过引入额外内存消耗的解决乱序问题、降低网络中负载以及选择性重传read response丢失的报文请求,可以一定程度上提高了网络伸缩性,但还需PFC协助尽可能减少丢包。
响应端
思路很简单,假定逻辑有非常大的缓存空间,将请求端所有包接收下来,对于乱序包则重排处理,对于丢包则等对端超时重传或主动NAK。

①一个数据包到达响应端,包的PSN与预期ePSN一致,则表示是正常顺序包,将由逻辑正常处理:对于send,先从RQ中取RWQE解析地址,再将数据写到host ddr;对于write/read,检查合法性无误则写入host ddr。
②数据包的PSN与预期ePSN不一致,则认为是乱序包,乱序包整包送入到QP的重排缓存区,进入OOO模式(乱序重排模式),由ePSN - PSN 计算出offset置位bitmap。
③当bitmap 0bit非0时,将通过data ptr指针找到乱序重排缓冲区0bit对应的整包,取到OOO模块解析处理,对于send,先从RQ中取RWQE解析地址,再将数据写到host ddr;对于write/read,检查合法性无误则写入host ddr。最后bitmap右移1bit,data ptr指向下一个packet。
④当bitmap全0时,退出OOO模式。
Reorder Buffer需要内存比较大,一般放在HOST DDR上,也就是说,对于乱序包,先送到HOST DDR重排缓存空间等待排队就绪,然后RNIC再从HOST DDR中读下来解析处理,最后送到HOST DDR真正的用户内存空间。相比乱序直接NAK让请求端重传的做法,这种方案只牺牲响应端部分PCIe带宽便可减小网络上压力,一定程度上提高了网络伸缩性。该方案QPC需要存放乱序维护结构,增加了sram消耗,此外,乱序重排BUF也需要占用host较大内存。
上述只能解决出现乱序报文问题,对于丢包则无太大益处。对于丢包,可直接等待请求端超时重传(时间较长),也可由响应端主动回复NAK触发重传。可选方案,以一定算法监测bitmap中空洞,当空洞较长时间未填补或后续bit位连续多个置位后,认为该空洞对应报文已丢失,主动触发NAK重传。
请求端
send & write & read
对于超时请求,正常重发;对于NAK请求,正常重发。
read response
请求端收到的read response可能乱序或丢包。

①收到read response PSN与预期ePSN一致,则认为是顺序包,将由正常传输逻辑处理送到HOST DDR。
②收到read response PSN与预期ePSN不一致,则认为发生了乱序或丢包,将进入SR(选择性重传)模式。接收的数据将正常送入用户HOST DDR中,同时由ePSN - PSN 计算出offset置位bitmap。
③当bitmap 0bit非0时,将整个bitmap右移,直到0bit为0。以一定算法监测bitmap中空洞,当空洞较长时间未填补或后续bit位连续多个置位后,认为该空洞对应报文已丢失,主动重传部分read请求。例如,请求端发起一个长度为7个pmtu的read请求报文,响应端接收请求回复7个pmtu报文,但是网络中丢失了0、4、6号报文,则请求端可以分别发送1个pmtu的read报文请求0、4、6号位置数据,从而选择性重传部分read请求,以便减少网络上负载,一定程度上提高了网络伸缩性。
由于是请求端主动发起的请求,所以只需要给活跃的QP的QPC中分配read response维护结构即可,对sram消耗增加不大。
扩展IB协议的选择性重传方案
核心思想:通过扩展IB协议,指示响应端准确的将任意包放入用户内存中,解决因乱序、丢包导致响应端无法立即处理报文问题;通过扩展IB协议,指示请求端需要重传哪些请求,精确重传丢失报文,去掉无效报文,保障了网络伸缩性。
当乱序或丢包发生,响应端接收报文无法正确处理,要么乱序重排,要么NAK重传,将极大影响吞吐率。通过扩展IB协议,在请求报文中额外附加信息告诉响应端怎么处理报文,实现报文就地重排上送用户内存中。
注意:发送端与请求端是在不同场景下不同称呼而已,同理接收端与响应端也是。
send
对于send报文,接收端接收到预期之外PSN报文将不知如何处理,如下图。

发送端发送了3个send报文,报文在网络中丢失了PSN0,接收端预期接收PSN0的报文,但却先接收到了PSN1的报文,此时接收端无法立即处理PSN1报文,因为接收端不知道PSN0的报文类型,不能准确使用RWQE(QP RQ中资源),只能将PSN1报文丢弃或放入缓存中等待乱序重排。
通过扩展IB协议,发送端在BTH之后附加SSN、PSN_OFFSET、RWQEN,那么接收端就可以准确处理任何send报文。

- 发送方发送了4个包给对面;
- 数据包在网络中丢失了3个;
- 接收端只接受到PSN4的数据包;
- 接收端根据包中扩展内容可以知道这个包需要使用RWQE1且数据偏移一个PMTU,接收端将数据放入用户内存;
- 接收端将乱序报文PSN与预期ePSN送给软件,由软件跟踪丢包信息。
可选的丢包恢复措施:
- 接收端软件择机触发硬件回复NAK(PSN 0)并附加指示信息指示对端重传哪些报文,例如丢包的bitmap信息0x0003,指示发送端精确重传丢失报文。
- 接收端等待ACK超时主动重传所有请求。
write
对于write报文,响应端接收到预期之外PSN报文将不知如何处,如下图。

请求端发送了3个报文,报文在网络中丢失了PSN0,接收端预期接收PSN0的报文,但却先接收到了PSN1的报文,此时接收端无法立即处理PSN1报文,因为write last中没有addr、key、len等信息。
通过扩展IB协议,请求端在BTH之后附加每个write需要写的目的addr、key、len、PSN_OFFSET,那么接收端就可以准确处理任何write报文。

- 请求端发送了4个包给对面;
- 数据包在网络中丢失了3个;
- 响应端只接受到PSN4的数据包;
- 响应端根据包中扩展内容查询MTT表项将数据写入用户内存;
- 响应端将乱序报文PSN与预期ePSN送给软件,由软件跟踪丢包信息。
可选的丢包恢复措施:
- 接收端软件择机触发硬件回复NAK(PSN 0)并附加指示信息指示对端重传哪些报文,例如丢包的bitmap信息0x0003,指示发送端精确重传丢失报文。
- 接收端等待ACK超时主动重传所有请求。
read
通过扩展IB协议,请求端在请求报文中添加本端数据存放的laddr、lkey、len等元数据信息,响应端回复read response中附加元数据信息返回给请求端。
对于read请求报文丢失,由请求端超时重发或响应端主动NAK请求端重发均可。
对于read response报文,由于response中携带有本地的laddr、lkey、llen、PSN_OFFSET等信息,可以任意接受乱序报文并准确将数据写入本端用户内存,此外由软件维护乱序response bitmap,以便决定选择性重传更小粒度read请求,如下图所示。

- 请求端发送read请求(IB协议本身包含对端raddr、rkey、len,扩展包含本端数据存放的laddr、lkey);
- 响应端接收请求根据rkey查询MTT,再从raddr开始读取len数据;
- 响应端组装read response报文,并附加请求端送来的元数据(laddr、lkey)以及len和PSN OFFSET;
- read response在网络中丢失了PSN1报文;
- 请求端接收到PSN0报文,根据扩展信息查询MTT并写入数据到用户内存;
- 请求接收到PSN2报文,发现与预取ePSN不一致,则进入丢包恢复流程,将报文元数据送给软件,但数据将写入用户内存中;
- 请求端软件以一定算法扫描bitmap空洞,择机选择性重传更小粒度read请求。
read response中携带PSN OFFSET是为了在丢包时好让软件跟踪bitmap。
注意:正常情况下,请求端本端会维护read未完成报文元数据PSN、 MSN、 PSN_OFFSET 之间的映射,所以响应端任意回复(乱序)报文也能正确放入本端用户内存中。那么为什么还要在read请求报文中添加本端数据存放的laddr、lkey、len等元数据信息呢?下面文章中揭晓。
连接扩展性
连接可伸缩性问题是当QP连接数量超过某个小阈值(如256)时,RDMA 性能急剧下降的现象,这种性能崩溃现象的根本原因是连接增多后,QP context之间的上下文切换导致缓存丢失 。
先看一张mlx实验性能图。

商用RNIC性能下降的根本原因通常被认为是缓存缺失。商用 RNIC 通常采用无 DRAM 架构,不将DRAM 直接连接到 RNIC 芯片以降低成本、功耗和面积,而只有有限的片上 SRAM。因此, rnic 只能在芯片上缓存少量 QP,而将其余 QP 存储在主机内存中。当活动 QP 的数量增加到超出片上内存大小时,频繁的缓存缺失和主机内存和 RNIC 之间的上下文切换将导致性能崩溃。上图中的实验在某种意义上证实了这一点,在性能崩溃期间,观察到显著的额外 PCIe 带宽(b绿色)和 ICM 缓存错误(b蓝色)的增加。这两个指标都反映了某些类型的缓存丢失,导致 256 个 QP 后额外的 PCIe 流量增加。
虽然片上 SRAM 是有限的,但性能下降这么早,这是不正常的。给定一个片上内存大小和 QP context(QPC)大小,可以估计在没有缓存丢失和性能崩溃的情况下可以支持的性能 QP 的最大数量: max_QPS=srma_memory_size/sizeof(QPC)。
以 Mellanox CX-5 为例。它的片上内存大小为2 MB,一个 QPC 需要375 B,因此 CX-5 支持的性能 QP 的最大数量可以达到 5.6K (2 MB/375 B),这与上图所示的事实相矛盾,即 CX-5 的性能在 256个 QP 时开始崩溃得更早。这种矛盾意味着存在显著提高连接可伸缩性的空间。 基于这一矛盾,系统地分析 rnic 的内存需求,并在深入分析内存的基础上提高了连接的可伸缩性。
由于商业 rnic 是黑盒,不能使用它们的微架构作为参考。本文利用具有选择性重传的有损 RDMA概念模型来推导相关的数据结构,将这些数据结构归纳归类为两类:RDMA 一般需要的通用数据结构和有损耗 RDMA 带来的选择性重传特定数据结构,并分别讨论了将其最小化的不同优化策略,以提高连接的可伸缩性。

上图前三列显示了典型的数据结构及其使用 10K qp 时的内存需求。
通用数据结构
一般来说,公共数据结构对于 RDMA 是必不可少的,无论底层网络是有损耗的还是无损耗的。
Receiving Buffer
Receiving Buffer:RNIC网卡模块中的接收缓冲区用于对所有传入数据包进行排队。它的主要目的是吸收由上游以太网端口和整个下游 RNIC 处理逻辑之间的时间性能差距引起的突发。
优化方案:这部分结构是必须的,暂时无更好的优化方案。
QPC
QPC:维护一个 QP 的所有上下文,包括 DMA 状态(例如,开始和结束地址, SQ 和 RQ 的读写指针)和连接状态(例如,期望和下一个数据包序列号,拥塞控制的窗口或速率)。为每个 QP 分配的 QPC 大小为210 B,因此 10K QP 的总大小为 2.0 MB。
优化方案:将QPC拆成SQC和RQC两部分。对于RQC,由于不能预先知道什么时候会收到send报文,因此所有RQC都必须放置在本地SRAM中;对于SQC,由于本端知道何时调度到这个QP,可以将所有SQC放在host DDR中,本地只存放活跃QP(由调度模块调度就绪排队的QP,参见WQE Cache部分)的SQC。
注意:该部分的优化是个人猜想,在SRNIC原文中并未对其优化。
MTT
MTT:RDMA 使用数据包中的虚拟地址,而 PCIe 系统依赖于物理地址来执行 DMA 事务。为了执行地址转换, RNIC 维护一个 MTT 来将内存区域的虚拟页映射到物理页。 MTT 的大小取决于内存区域的总大小和页面大小,与连接数无关。
SRNIC原文中只描述了SRAM存放一个MTT表(4G内存)存放大小优化,这对应商用rnic是不可取的,因为多个QP的SQ和RQ可能同时需要查不同MTT表。
优化方案:将MTT一级表放本地SRAM,由key索引,MTT二级表放HOST DDR,同时让HOST使用2MB巨页存放用户数据和QP Buf,尽可能的减小MTT表项大小以及提高MTT一级表直接击中连续物理地址的概率。
WQE Cache
WQE Cache:SQ WQE 缓存可以用于缓存从主机内存中的 SQ 中获取的 Send WQE。假设每个 QP 在专用缓存中存储 8 个 WQEs (64b *8), 10K QP 占用 4.9 MB 的片上内存。类似地, RNIC 需要从 RQ 中获取 ReceiveWQEs 来处理传入的 SEND 请求,并且可以分配一个 RQ WQE 缓存来存储获取的 Receive WQEs。 RQ WQE缓存的内存大小与 SQ WQE 缓存的内存大小相似。
优化方案:
RQ:对于RWQE,由于难以预测哪个QP会收到对端的send报文,因此需要为每个QP都预取一些RWQE下来,但这样将大量浪费SRAM,因此决定采用无预取RWQE的方案,而是将RQC放到本地SRAM中,当接受到send报文便查询RQC拿到RQ Buf地址,再去host 取下RWQE使用,相比于提前预取RWQE多出1us左右的PCIe数据来回时延,但在数据中心,小消息的典型 RDMA 网络延迟是几十微秒,增加的 1µs 延迟一般可以忽略不计。对于延迟敏感的场景(1µs 很重要),例如机架级部署,可以通过SRQ的RWQE 缓存以优化延迟,即SRQ支持RWQE预取,减小片上SRAM需求,但对应用编程有挑战。
注意:SRNIC原文描述的是RQ使用共享RWQE Cashe的策略优化延时,但这还是难以解决大量QP突发性收到send的问题,因此从用户使用场景上要求以及逻辑配合优化更加容易实现,即SRQ预取方案。
SQ:SQ 在包含 WQE 时是活动的,在其他情况下是不活动的。 SQ 调度器每次从主机内存中的数万个SQs 中选择一个活动 SQ 来发送接下来的消息。SQ 调度器的设计挑战如下:
- 挑战1:活动 SQs 不能盲目调度,因为它们也受到拥塞控制。一个 SQ 一旦被调度,如果由于拥塞控制的信用不足而不允许发送消息,调度不仅不能生效,而且会浪费时间,降低性能。
- 挑战2:RNIC 和主机内存之间的 PCIe 往返延迟很高(基于 FPGA 的 RNIC 大约 1µs),并且至少需要两个 PCIe事务(一个 WQE 获取和一个消息获取)来执行一个调度决策。如果没有仔细的设计,调度迭代之间的高延迟将显著降低性能。
- 挑战#3:主机内存中有成千上万个 SQs,但 RNIC 内的片上内存非常有限。禁止在 RNIC 中为不同的 SQs 使用单独的 WQE 缓存。
为了解决这些挑战,提出指导原则:SQs 应该在它们既活跃又有信用时调度,即应对挑战1;使用适当的批次处理事务和少量WQE缓存,来隐藏PCIe 延迟,即应对挑战2和挑战3。
在这些原则的指导下,提出了一种无缓存 SQ 调度器,它可以在数万个 qp 之间进行快速调度,并且对片上内存的需求最小。

事件 Mux (EMUX): EMUX 模块处理所有调度相关事件,包括,(1)来自主机的 SQ 门铃(doorbell),以指示哪个 SQ 有新的 WQEs 和消息要发送;(2)来自拥塞控制模块的信用更新,以指示连接/SQ 的窗口或速率调整;(3)从调度队列中 dequeue 事件,表示一个 SQ 已被调度。 在接收到一个事件时, EMUX 改变 QPC 中的调度状态。有三种调度状态:active状态表示 SQ 有 WQEs;credit 值表示允许发送的消息字节数, ready 状态表示 SQ 在调度队列中并准备调度。一个 SQ 只有在它既活跃又有可用积分时才准备好调度,这解决了挑战#1。
Scheduler:调度器利用一个调度队列来维护准备进行调度的 SQs 列表。调度器在调度策略模块中实现循环策略,每次从调度队列头部弹出一个就绪 SQ,并从该 SQ 获取给定数量的 wq 和消息。在这个调度迭代之后,如果SQ 仍然准备好调度,它将被 EMUX 推回调度队列。其他调度策略(例如,加权轮询和严格优先级)可以通过修改调度策略模块来实现。
DMA 引擎:当调度一个 SQ 时, DMA 引擎从该 SQ 中获取最多 n 个 WQEs 和最小(burst_size,credit)字节的消息来解决挑战2。在调度迭代之后,如果与 n 个 WQEs 相关联的总消息大小超过 min(burst_size,credit)字节,则RNIC 中可能还有未使用的 WQEs。未使用的 wq 将被丢弃,而不是缓存在 RNIC 中,并且它们将在下一次SQ 被调度时再次获取。 使用少量WQE缓存来隐藏读取WQE时PCIe来回时延,也就是说,至少保证一次PCIe来回时延内,之前QP取下的WQE缓存未消耗完,这种原则下,能够实现少量WQE缓存调度,以解决挑战3。
有两个关键参数(n 和 burst_size)来平衡权衡。 n 是 wqe 的最大数量, burst_size 是在每个调度迭代中允许获取的消息的最大字节数。 n 反映了 PCIe 带宽使用和 PCIe 延迟隐藏之间的权衡。 n 越小,在取-放策略中浪费的PCIe 带宽就越少,但很难隐藏 PCIe 延迟或让小消息饱和 PCIe 带宽,而 n 越大则相反。“SRNIC”中, n = 8是为了平衡 PCIe 的带宽利用率和隐藏时延。在此设置下,单个 QP 的最大消息速率为每秒 800 万请求(Mrps)(即每 1µs 8 条消息)。至于 burst_size,它反映了 PCIe 带宽利用率和调度粒度之间的权衡。更小的burst_size 可以实现更细的调度粒度,因此 HoL 更少,但更难饱和 PCIe 带宽,而更大的 burst_size 则相反。基于此分析,将 burst_size 设置为 PCIe BDP,即 16kb,以平衡性能和调度粒度。
注意:SRNIC原文描述可以无WQE缓存,但从SRNIC使用来看,至少也需要8个WQE缓存(n=8),此外,文章没有考虑商用rnic最差情况,即每个活跃QP只有一个WQE可以使用,因此需要更多WQE缓存,但这个缓存对于整个片上SRAM来说是极小的。
选择重传特定数据结构
这些数据结构都是由有损耗 RDMA 引入的,采用选择性重传作为损耗恢复机制。
Bitmap
Bitmap:位图用于跟踪接收或丢失的数据包。正如 IRN(Revisiting network support for rdma,In Proc. SIGCOMM, 2018)中提到的,每个 QP 需要 5 个 BDP(带宽延迟乘积,bandwidth-delay product)大小的位图(每个位图有 500 个插槽,以适应带宽 100 Gbps 和 RTT 40µs的网络的 BDP 上限), 10K QP总共需要 3.0 MB 内存。
优化方案:
可以观察到,当没有丢包或乱序时,来自同一个 QP 的数据包依次发送和接收,响应端一个期望的 PSN (ePSN)和请求端一个最后确认的 PSN (lACK)就足以分别跟踪请求和响应数据包的顺序接收,而不需要bitmap来跟踪;丢包或乱序时出现OOO报文,位图只用于跟踪 OOO 报文。
基于上述观察,为每个 QP 维护一个 ePSN 和 QPC 中的 lACK 来处理硬件中的顺序数据包,并将所有bitmap加载到主机内存中以跟踪 OOO 数据包。假设丢包率较低且以顺序包为主,则大部分流量由硬件直接处理,少量包含 OOO 包的流量由软件处理,占用主机内存的位图占用内存。通过这种方式,实现了高性能和高连接可伸缩性之间的平衡。
下图展示基本处理流程:

响应端
①接收到报文判断是否与预期ePSN一致;
②对于PSN与ePSN一致的报文,将送入正常传输逻辑处理;对于PSN与ePSN不一致的报文,将数据存入用户内存后,再将把ePSN与报文基本信息送入系统软件(一般是host驱动)由软件追踪,并使硬件进入OOO模式(乱序报文),后续进入硬件都报文即使PSN与ePSN一致,也会把报文基本信息送给软件,直到OOO模式退出;
③软件跟踪丢包bitmap,当0 bit开始出现连续1且后续再无1,则更新逻辑ePSN并退出OOO模式。请求端
①收到响应端回复的报文,判断与预期ePSN是否一致;
②对于PSN与ePSN一致的报文,将送入正常传输逻辑处理并更新ePSN;对于PSN与ePSN不一致的报文,将数据存入用户内存后(read response),再将把ePSN与报文基本信息送入系统软件(一般是host驱动)由软件追踪,并进入丢包恢复模式;注意,这里read response能够准确放入用户内存是因为附加了额外的请求信息,查看 扩展IB协议的选择性重传方案 read部分;
③软件跟踪丢包bitmap(一般是read response),择机决定选择性重传更小粒度read请求,重传请求通过每个QP的重试队列提交;当所有重传报文都成功下发后(收到ACK),请求端退出丢包恢复模式。可选的丢包恢复措施:
①响应端软件择机触发硬件回复NAK并附加丢包的bitmap信息,指示发送端精确重传丢失报文。
②请求端超时重发所有请求(非read)。
上面描述处理方案可以将片上Bitmap结构移到host软件(一般是driver),去除大量sram消耗。
Reordering Buffer
Reordering Buffer:重排序缓冲区用于重新排列无序的数据包,并确保有序地传递到主机内存中的数据缓冲区。重排序缓冲区在标准 RoCEv2 报头的有损 RNIC 实现中是必需的。由于 RoCEv2 是为无损网络设计的,它的报头缺乏必要的信息来支持无序数据包接收,而没有额外的重排序缓冲区。 一种选择是为每个 QP 分配单独的重排序缓冲区。每个 QP 需要一个 bdp 大小(0.5 MB)的重排序缓冲区,因此支持 10K QP 需要 4.9 GB内存。 另一种选择是为所有 qp 维护一个共享的重排序缓冲区,但它无法扩展,当多个 qp 遇到乱序包时,由于片上 SRAM 有限,它可能很快就会耗尽共享缓冲区。
优化方案:每个 QP 使用重排序缓冲区重新排列 OOO 包,并确保按顺序传递到用户应用程序的数据缓冲区。通过就地重排可以拜托每个 qp 的重排序缓冲区,即利用固定在主机内存中的用户数据缓冲区作为重排序缓冲区。为了实现这一点,所有传入的数据包都应该直接放在正确地址的用户缓冲区中。 如 扩展IB协议的选择性重传方案 部分描述的一样,可以进行一下操作:1)有 SEND 包都携带发送消息序列号(SSN)、PSN_OFFSET、RWQEN,RNIC 接收端可以使用它来定位相应的接收 WQE 及其相关接收缓冲区中的偏移量;2)所有的write报文都携带它们的目标addr、key、len、PSN_OFFSET;3)所有的read response都携带addr、key、len、PSN_OFFSET。
Outstanding Request Table
Outstanding Request Table:未处理请求表用于维护未处理请求报文与其元数据之间的映射关系,用于快速定位和重传丢失报文。这些元数据包括,(1)数据包序列号(PSN),用于跟踪数据包序列, (2)消息序列号(MSN),用于跟踪消息序列并快速定位与该消息相关的 WQE,以及(3)数据包偏移量(PSN_OFFSET),用于定位相应数据缓冲区中的数据偏移量。使用这些字段,每个 QP 的未完成请求表大小为 11.7 KB(假设条目大小为 24 B,条目数500,大小为 BDP), 10K QP 总共消耗 114.4 MB。
优化方案:通过在包头上携带这些每个包的元数据,而不是将它们存储在片上存储器中。具体来说,让所有未完成的请求包在它们的头上携带这些元数据,并让它们的响应包回显相同的元数据。通过这种方式,请求端可以使用响应包报头中的元数据快速定位 WQE 及其消息。
在 扩展IB协议的选择性重传方案 read部分说道‘为什么还要在read请求报文中添加本端数据存放的addr、lkey、len等元数据信息呢’,原因就是去除Outstanding Request Table结构。
总结
通过上面所述优化,可以节省大量sram,从而存放更多的QPC,进而大幅度提高连接扩展性,即大规模连接下不会损失性能。此外,通过扩展IB协议可能很好的应对无损和有损网络,大幅度降低对PFC需求,甚至可以摒弃PFC。
相关文章:
SRNIC、选择性重传、伸缩性、连接扩展性、RoCEv2优化(六)
参考论文SRDMA(A Scalable Architecture for RDMA NICs ):https://download.csdn.net/download/zz2633105/89101822 借此,对论文内容总结、加以思考和额外猜想,如有侵权,请联系删除。 如有描述不当之处&…...

【神经网络】生成对抗网络GAN
生成对抗网络GAN 欢迎访问Blog总目录! 文章目录 生成对抗网络GAN1.学习链接2.GAN结构2.1.生成模型Generator2.2.判别模型Discrimintor2.3.伪代码 3.优缺点3.1.优势3.2.缺点 4.pytorch GAN4.1.API4.2.GAN的搭建4.2.1.结果4.2.2.代码 4.3.示意图:star: 1.学习链接 …...

智慧能耗预付费系统解决方案——用户侧能源计量及收费
安科瑞电气股份有限公司 祁洁 15000363176 一、方案组织架构 二、方案特点 (1)多样组网,多样设备接入,多样部署; (2)集团管理、项目分级、分层拓扑; (3)…...

探秘大模型:《提示工程:技巧、方法与行业应用》背后的故事
提示工程是一种新兴的利用人工智能的技术,它通过设计提示引导生成式 AI 模型产生预期的输出,来提升人与 AI 的互动质量,激发 AI 模型的潜力,提升AI的应用水平。 为了让每一个人都拥有驱动大模型的能力,以微软全球副总裁…...

2024年光学通信和物联网、自动化控制和大数据国际会议(OCITACB2024)
2024年光学通信和物联网、自动化控制和大数据国际会议(OCITACB2024) 会议简介 2024年国际光通信与物联网、自动控制和大数据会议(OCITACB2024)的主要目标是促进光通信与物联网、自动管理和大数据领域的研发活动。另一个目标是促进研究人员、开发人员、工…...
)含义)
q @ k运算及att = (q @ k.transpose(-2, -1))含义
以下代码经常在Transformer的算法中见到:q, k, v qkv[0], qkv[1], qkv[2] # query, key, value tensor q q * self.scale attn (q k.transpose(-2, -1))其中涉及到a b操作和transpose操作 a torch.Tensor([[1,2],[3,4]]) print(a)b torch.Tensor([[0.5,2],[…...

leetcode628-Maximum Product of Three Numbers
题目 给你一个整型数组 nums ,在数组中找出由三个数组成的最大乘积,并输出这个乘积。 示例 1: 输入:nums [1,2,3] 输出:6 分析 这道题目要求数组中三个数组成的最大乘积,由于元素有正数有负数ÿ…...
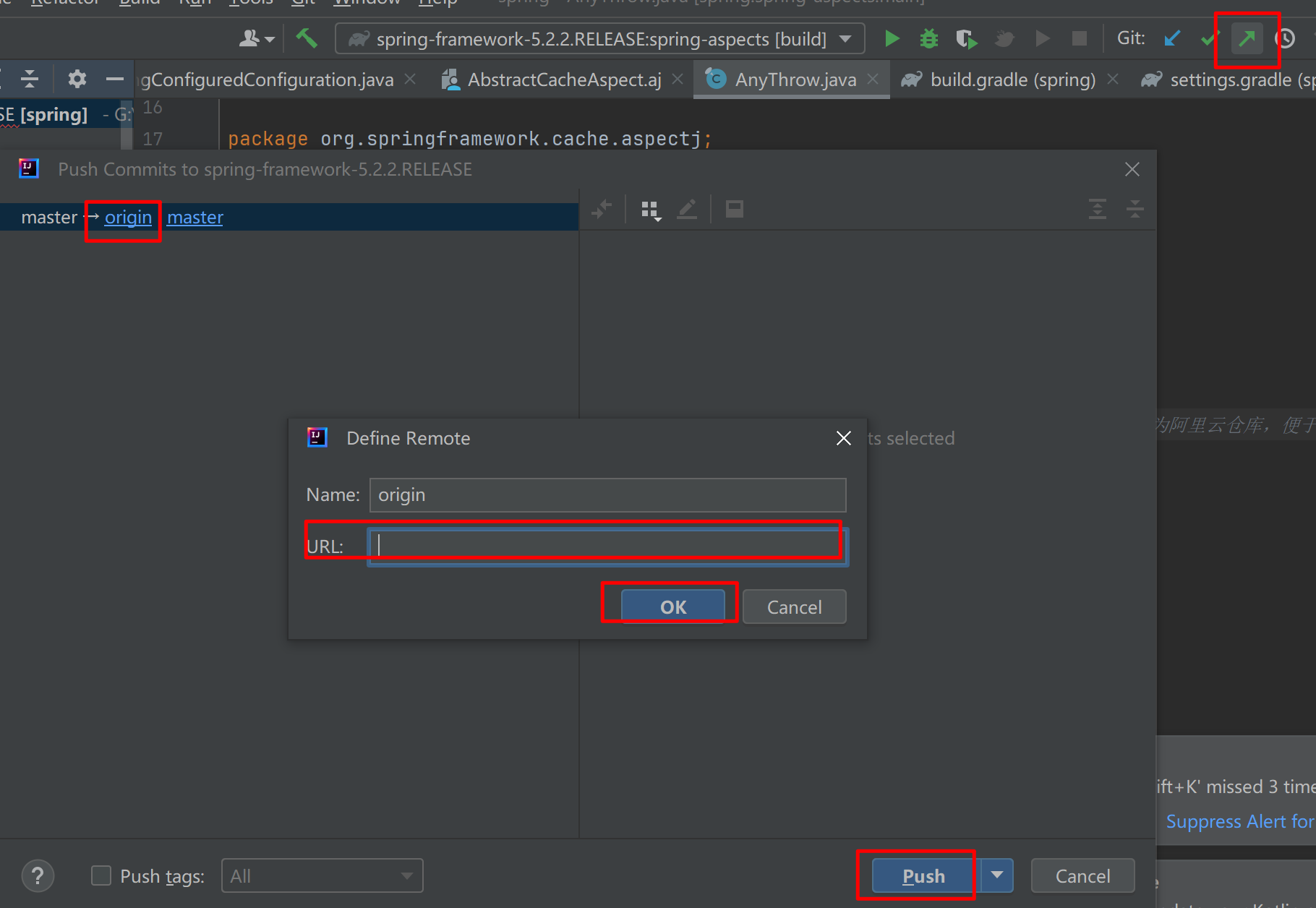
本地项目提交 Github
工具 GitIdeaGithub 账号 步骤 使用注册好的 Github 账号,登陆 Github; 创建 Repositories (存储库),注意填写图上的红框标注; 创建完成之后,找到存储库的 ssh 地址或 https 地址,这取决于你自己的配置…...
Idea中 maven 下载jar出现证书问题
目录 1: 具体错误: 2: 忽略证书代码: 3: 关闭所有idea, 清除缓存, 在下面添加如上忽略证书代码 4:执行 maven clean 然后刷刷新依赖 完成,撒花!&#x…...
ArcGIS Server 10发布要素服务时遇到的数据库注册问题总结(一)
工作环境: Windows 7 64 位旗舰版 ArcGIS Server 10.1 ArcGIS Desktop 10.1 IIS 7.0 开始的时候以为10.1发布要素服务和10.0一样,需要安装ArcSDE,后来查阅资料发现不需要,数据库直连方式就可以了。 首先我来说一下发布要素服…...
)
自我介绍的HTML 页面(入门)
一.前情提要 1.主要是代码示例,具体内容需自己填充 2.代码后是详解 二.代码实例和解析 代码 <!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8"> <title>自我介绍页面</title>…...

负载均衡原理及算法
负载均衡(Load Balancing)是在计算机网络中,将工作负载(即请求)分配给多个资源,以实现最优资源利用、最大化性能、最小化延迟和提高可用性等目标的技术。负载均衡通常用于分布式系统、网络服务和服务器集群…...

【iOS ARKit】USDZ文件
USDZ 概述 ARKit 支持 USDZ(Universal Scene Description Zip,通用场景描述文件包)、Reality 两种格式的模型文件,得益于 USDZ的强大描述能力与网络传输便利性,使得iOS 设备能够在其信息(Message࿰…...

鹅厂实习offer
#转眼已经银四了,你收到offer了吗# 本来都打算四月再投实习了,突然三月初被wxg捞了(一年前找日常实习投的简历就更新了下),直接冲了,流程持续二十多天,结果是运气还不错,应该是部门比…...
极狐GitLab 如何在 helm 中恢复数据
本文作者:徐晓伟 GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 本文主要讲述了如何在极狐GitLab …...
Hololens2远程音视频通话与AR远程空间标注,基于OpenXR+MRTK3+WebRTC实现
Hololens2远程音视频通话与AR远程空间标注 使用Unity2021.3.21版本开发,基于OpenXRMRTK3.0WebRTC实现。 (1)通过视频获取视频帧的矩阵的方法可以参考:https://learn.microsoft.com/zh-cn/windows/mixed-reality/develop/advanced…...
2024年03月CCF-GESP编程能力等级认证Scratch图形化编程二级真题解析
本文收录于专栏《Scratch等级认证CCF-GESP真题解析》,专栏总目录・点这里 一、单选题(一共 15 个题目,每题 2 分,共 30 分) 第1题 小杨的父母最近刚刚给他买了一块华为手表,他说手表上跑的是鸿蒙,这个鸿蒙是?( ) A、小程序 B、计时器 C、操作系统 D、神话人物 答案…...

开发语言漫谈-C#
C#的#,字面上的意思就是,也就是把C再。微软只所以搞C#就是要抗衡Java。微软当时搞了个J,被Java告了,没办法了只能另取炉灶。从纯技术角度来看,C#设计非常优秀,可以覆盖所有领域,是几乎唯一的全栈…...
微信小程序用户登录授权指定(旧版本)
配置旧版本基础库2.12.3 实现效果 点击登录按钮即可直接登录,获取用户昵称和头像 点击获取头像昵称按钮则需要授权,才能成功登录 代码实现 my.xml <!-- 登录页面,调试基础库为2.20.2库 --> <view class"mylogin"><block w…...

电商技术揭秘十五:数据挖掘与用户行为分析
相关系列文章 电商技术揭秘一:电商架构设计与核心技术 电商技术揭秘二:电商平台推荐系统的实现与优化 电商技术揭秘三:电商平台的支付与结算系统 电商技术揭秘四:电商平台的物流管理系统 电商技术揭秘五:电商平台…...

微软DebugMCP:可视化调试MCP协议,解决AI与工具通信黑盒问题
1. 项目概述:当你的AI助手开始“自言自语”,你需要一个调试器 最近在折腾AI应用开发的朋友,估计没少跟各种“智能体”打交道。无论是基于OpenAI的GPTs,还是那些能联网、能调用工具的自定义助手,它们背后的核心通信协议…...

框架式幕墙与单元式幕墙的价格差异
框架式幕墙与单元式幕墙的价格差异 框架式幕墙与单元式幕墙由于结构及安装方式的不同,在价格方面存着很大的差异。主要表现在以下几个方面: 铝型材的用量: 框架式幕墙铝型材用量一般在7—9 kg/平方米左右。 单元式幕墙铝型材用量一般在13—15kg/平方米左右。 两者每平方…...

Aurora框架解析:一体化高性能云原生开发平台的设计与实践
1. 项目概述与核心价值如果你在开源社区里混迹过一段时间,尤其是对现代化、高性能的Web开发框架感兴趣,那么“Aurora”这个名字你大概率不会陌生。它不是一个简单的库或者工具,而是一个由社区驱动的、旨在构建下一代企业级应用开发平台的雄心…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...

All in Token,移动,电信,联通,百度,阿里,字节,华为,Token战争,Token无用:李彦宏用DAA终结了AI的度量衡之争
今年4月,AI行业出现了一组让投资人坐立难安的数据:Anthropic年化营收突破300亿美元,正式超过OpenAI的约250亿美元。但反常的是,据第三方机构估算,Claude的月活用户仅约为ChatGPT的2.44%。以及,Anthropic的模…...

Apex Legends进阶指南:结构化训练框架与技能模块化拆解
1. 项目概述:一个面向Apex Legends玩家的成长型技能库如果你是一位《Apex Legends》的玩家,并且对提升自己的游戏水平有持续的热情,那么你很可能和我一样,经历过一个漫长的摸索期。从最初落地成盒,到逐渐熟悉地图、枪械…...

零基础实操:小龙虾 AI OpenClaw 接入 Kimi 详细步骤
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常运行OpenClaw客户端,顶部 Gateway 状态保持在线设备网络通畅,可正常访问 Kimi 开放平台拥有可正常登录的 Kimi 月之暗面 Moonshot 账号账号提…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...

I2C地址冲突全解析:从原理到实战的嵌入式系统设计指南
1. I2C地址:嵌入式系统设计的“门牌号”与“交通规则”如果你玩过单片机或者树莓派,肯定对I2C不陌生。两根线,SDA和SCL,就能挂上一堆传感器、显示屏、扩展芯片,听起来简直是嵌入式开发的“万金油”。但真正上手后&…...