Training - Kubeflow 的 PyTorchJob 配置 DDP 分布式训练 (ncclInternalError)
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/137569332

Kubeflow 的 PyTorchJob 是 Kubernetes 自定义资源,用于在 Kubernetes 上运行 PyTorch 训练任务,是 Kubeflow 组件中的一部分,具有稳定状态,并且,实现位于 training-operator 中。PyTorchJob 允许定义一个配置文件,来启动 PyTorch 模型的训练,可以是分布式的,也可以是单机的。
请注意,PyTorchJob 默认情况下不在用户命名空间中工作,因为 istio 自动侧车注入。为了使其运行,需要为 PyTorchJob pod 或命名空间添加注释 sidecar.istio.io/inject: "false" 以禁用它。
在 PyTorch Lightning 框架中,可以通过 strategy 配置多机多卡模式,例如 DDP(Distributed Data Parallel) 策略,即:
- 多机多卡,需要设置固定的随机种子
- 训练策略设置成 DDPStrategy
pl.Trainer()设置strategy(策略)、num_nodes(节点数)、devices(节点的卡数)
即:
from pytorch_lightning import seed_everything
from pytorch_lightning.strategies import DeepSpeedStrategy, DDPStrategy# 多机多卡,需要设置固定的随机种子
seed_everything(args.seed)# DeepSpeed 策略
# strategy = DeepSpeedStrategy(config=args.deepspeed_config_path)# DDP 策略
strategy = DDPStrategy(find_unused_parameters=False)# num_nodes 是节点数量,devices 是节点的 GPU 数量,可以设置成 auto
trainer = pl.Trainer(accelerator="gpu",# ...strategy=strategy, # 多机多卡配置num_nodes=args.num_nodes, # 节点数devices="auto", # 每个节点 GPU 卡数
)
Kubeflow 配置 PyTorchJob,即:
- Job的类型(kind),需要设置成 PyTorchJob,支持 DDP 模式。
- 包括 Master 节点与 Worker 节点,两个节点的配置可以相同。
- 运行命令
command相同,可以存储不同的nohup.out中,例如_master或_worker。 resources配置资源,即单机卡数;tolerations配置资源池。- 必须添加
sidecar.istio.io/inject: "false" replicas表示节点数量,Master 与 Worker 的总和,就是num_nodes的数量。
即:
apiVersion: "kubeflow.org/v1"
kind: PyTorchJob
metadata:name: [your project]-trainer-n8g1-20240409
spec:pytorchReplicaSpecs:Master:replicas: 1template:metadata:annotations:sidecar.istio.io/inject: "false"labels:file-mount: "true"user-mount: "true"spec:containers:- name: pytorchcommand:- /bin/sh- -cl- "bash run_train_n8g1.sh > nohup.run_train_n8g1_master.log 2>&1"image: "[docker image]"imagePullPolicy: AlwayssecurityContext: # Newprivileged: falsecapabilities:add: ["IPC_LOCK"]resources:limits:rdma/hca: 1cpu: 12memory: "100G"nvidia.com/gpu: 1workingDir: "[project dir]"volumeMounts:- name: cache-volume # change the name to your volume on k8smountPath: /dev/shmnodeSelector:gpu.device: "a100" # support 'a10' or 'a100'group: "algo2"tolerations:- effect: NoSchedulekey: roleoperator: Equalvalue: "algo2"volumes:- name: cache-volume # change the name to your volume on k8semptyDir:medium: MemorysizeLimit: "960G"Worker:replicas: 7template:metadata:annotations:sidecar.istio.io/inject: "false"labels:file-mount: "true"user-mount: "true"spec:containers:- name: pytorchcommand:- /bin/sh- -cl- "bash run_train_n8g1.sh > nohup.run_train_n8g1_worker.log 2>&1"image: "[docker image]"imagePullPolicy: AlwayssecurityContext: # Newprivileged: falsecapabilities:add: ["IPC_LOCK"]resources:limits:rdma/hca : 1cpu: 12memory: "100G"nvidia.com/gpu: 1workingDir: "[project dir]"volumeMounts:- name: cache-volume # change the name to your volume on k8smountPath: /dev/shmnodeSelector:gpu.device: "a100" # support 'a10' or 'a100'group: "algo2"tolerations:- effect: NoSchedulekey: roleoperator: Equalvalue: "algo2"volumes:- name: cache-volume # change the name to your volume on k8semptyDir:medium: MemorysizeLimit: "960G"
设置运行脚本:
# 激活环境
source /opt/conda/etc/profile.d/conda.sh # 必要步骤
conda activate alphaflow# DDP 模式需要设置 MASTER_PORT,否则异常
export MASTER_PORT=9800# 显示环境变量
export
注意:DDP 模式需要设置 MASTER_PORT,否则异常
运行日志,主要关注 RANK 与 WORLD_SIZE 变量,如下:
RANK="0"
WORLD_SIZE="8"RANK="6"
WORLD_SIZE="8"
WandB 效果图,示例:
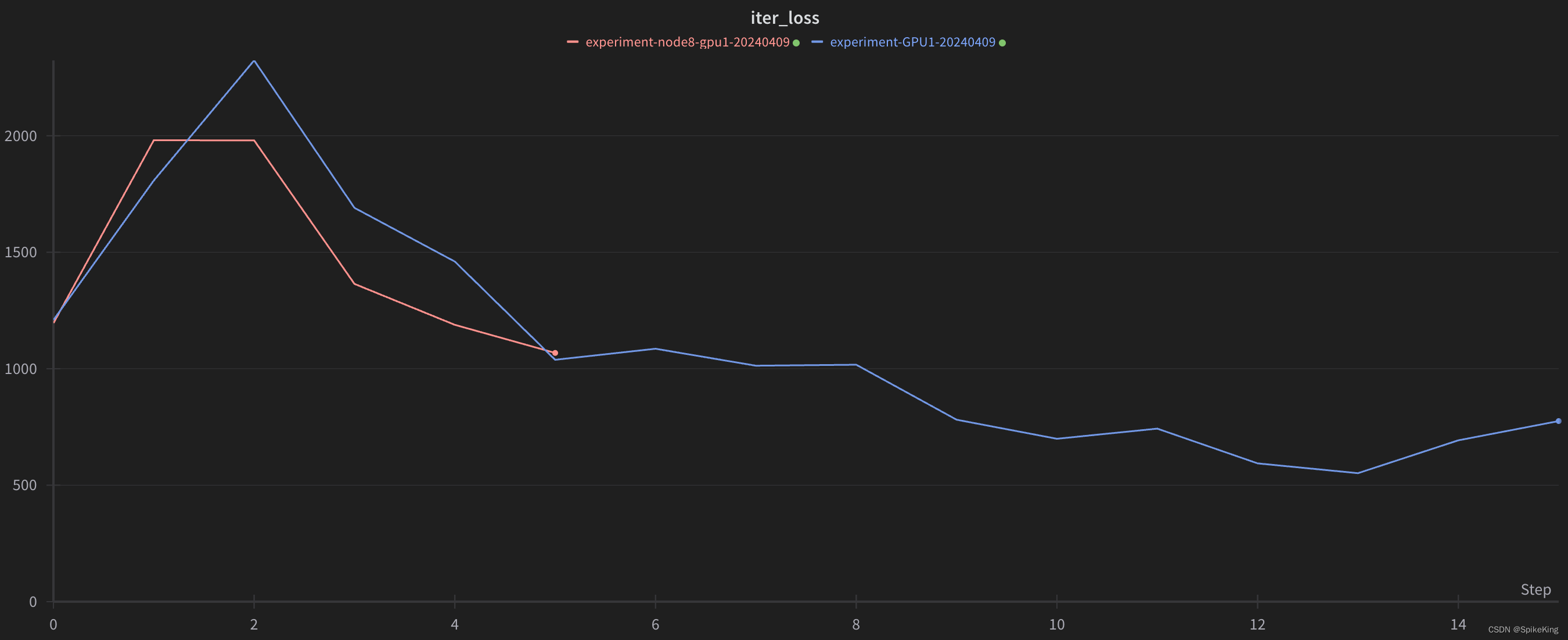
遇到 Bug:ncclInternalError: Internal check failed. ,即:
RuntimeError: NCCL error in: ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:1269, internal error, NCCL version 2.14.3
ncclInternalError: Internal check failed.
Last error:
Net : Call to recv from [IP]<[Port]> failed : Connection refused
原因是 DDP 策略需要设置 MASTER_PORT 参数,例如:
export MASTER_PORT=9800
参考:GitHub - multi node training error:NCCL error
相关文章:
Training - Kubeflow 的 PyTorchJob 配置 DDP 分布式训练 (ncclInternalError)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137569332 Kubeflow 的 PyTorchJob 是 Kubernetes 自定义资源,用于在 Kubernetes 上运行 PyTorch 训练任务,是 K…...
java Web在线考试管理系统用eclipse定制开发mysql数据库BS模式java编程jdbc
一、源码特点 JSP 在线考试管理系统是一套完善的web设计系统,对理解JSP java 编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,eclipse开发,数据库为Mysql5.0,使…...
爬虫 新闻网站 以湖南法治报为例(含详细注释) V4.0 升级 自定义可任意个关键词查询、时间段、粗略判断新闻是否和优化营商环境相关,避免自己再一个个判断
目标网站:湖南法治报 爬取目的:为了获取某一地区更全面的在湖南法治报的已发布的和优化营商环境相关的宣传新闻稿,同时也让自己的工作更便捷 环境:Pycharm2021,Python3.10, 安装的包:requests&a…...

科技云报道:从“奇点”到“大爆炸”,生成式AI开启“十年周期”
科技云报道原创。 世界是复杂的,没有人知道未来会怎样,但如果单纯从技术的角度,我们总是能够沿着技术发展的路径,找到一些主导未来趋势的脉络。 从Sora到Suno,从OpenAI到Copilot、Blackwell,这些热词在大…...

【用户案例】太美医疗基于Apache DolphinScheduler的应用实践
大家好,我叫杨佳豪,来自于太美医疗。今天我为大家分享的是Apache DolphinScheduler在太美医疗的应用实践。今天的分享主要分为四个部分: 使用历程及选择理由稳定性的改造功能定制与自动化部署运维巡检与优化 使用历程及选择理由 公司介绍 …...
权限管理系统【BUG】
1.1.简介 忙里偷闲,学点Java知识。越发觉得世界语言千千万,最核心的还是思想,一味死记硬背只会让人觉得很死板不灵活,嗯~要灵活~ 1.2.问题 permission.js:37 [Vue warn]: Error in render: "TypeError: Cannot read prope…...

【CPA考试】2024注册会计师报名照片尺寸要求解读及手机拍照方法
随着2024年注册会计师考试的临近,众多会计专业人士和学生都开始准备报名参加这一行业的重要考试,报名时间为4月8日至4月30日。报名过程中,一张符合要求的证件照是必不可少的。本文将为您详细解读2024年注册会计师考试报名照片的尺寸要求&…...

高并发环境下的实现与优化策略
在现代互联网应用中,高并发处理能力是衡量系统性能和稳定性的关键指标之一。尤其对于电商、社交、在线支付等业务场景,面对瞬间涌入的大规模用户请求,如何保证系统的稳定性和响应速度,对技术架构设计与优化提出了极高要求。本文将…...

华为海思校园招聘-芯片-数字 IC 方向 题目分享——第二套
华为海思校园招聘-芯片-数字 IC 方向 题目分享(共9套,有答案和解析,答案非官方,未仔细校正,仅供参考)——第二套(共九套,每套四十个选择题) 部分题目分享,完整版获取&am…...
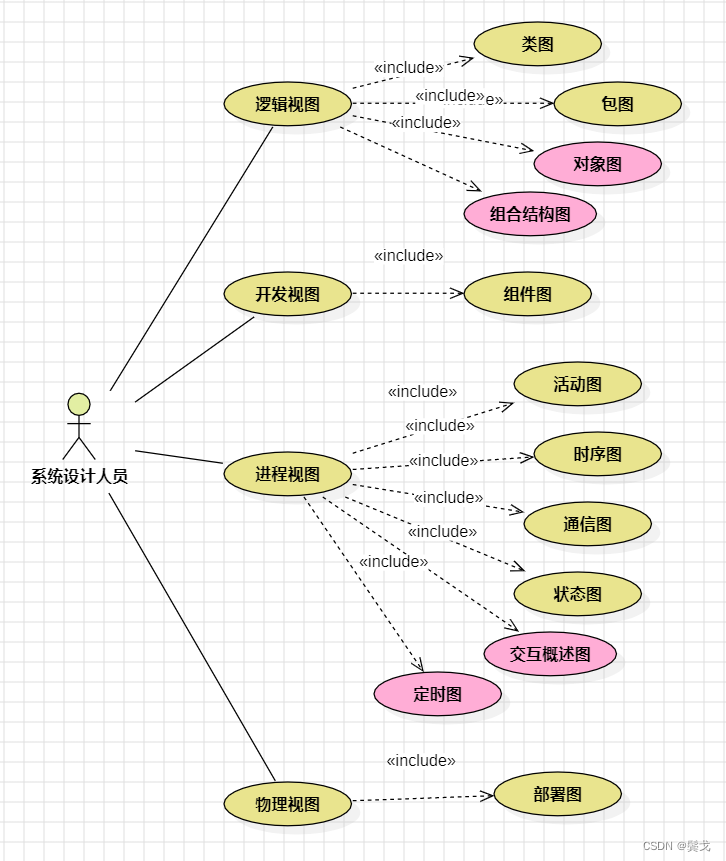
UML2.0在系统设计中的实际使用情况
目前我在系统分析设计过程中主要使用UML2.0来表达,使用StarUML软件做实际设计,操作起来基本很顺手,下面整理一下自己的使用情况。 1. UML2.0之十三张图 UML2.0一共13张图,可以分为两大类:结构图-静态图,行…...

django celery 异步任务 异步存储
环境:win11、python 3.9.2、django 4.2.11、celery 4.4.7、MySQL 8.1、redis 3.0 背景:基于django框架的大量任务实现,并且需要保存数据库 时间:20240409 说明:异步爬取小说,并将其保存到数据库 1、创建…...

apex0.1版本安装踩坑指南
踩了无数坑,发现只需要三行命令就可以成功安装apex0.1. 由于pip命令下只能找到0.9的版本,所以需要git clone的方式安装。 1. git clone https://www.github.com/nvidia/apex 这个命令的意思是下载apex到本地。注意,这里需要稳定的环境…...
)
HTML — 弹性布局(2)
弹性布局的其他属性 1. order 决定弹性项目(flex item)的排列顺序,使用较少,默认为0 。 order 的值可以为任意整数(正整数或负整数均可,也可为0),数值越小越排在前面。 2. align-s…...

MYSQL 8.0版本修改用户密码(知道登录密码)和Sqlyog错误码2058一案
今天准备使用sqlyog连接一下我Linux上面的mysql数据库,然后就报如下错误 有一个简单的办法就是修改密码为password就完事!然后我就开始查找如何修改密码! 如果是需要解决Sqlyog错误码2058的话,执行以下命令,但是注意root对应host是不是loca…...

Linux中磁盘管理
一.磁盘管理的概括和简要说明 磁盘空间的管理,使用硬盘三步: (1)分区: (2)安装文件系统格式化 (3)挂载: 硬盘的分类: (1&#x…...

tailwindcss在manoca在线编辑智能感知
推荐一下monaco-tailwindcss库,它实现在monaco-editor网页在线编辑器中对tailwindcss的智能感知提示,在利用tailwindcss实现html效果布局。非常的方便。 生成CSS...
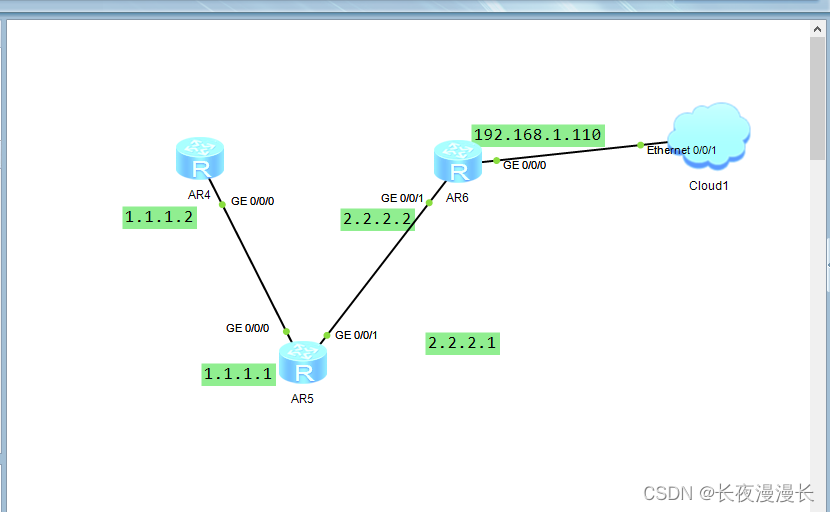
通过本机调试远端路由器非直连路由
实验目的:如图拓扑,通过本机电脑发,telnet调试远程AR4设备。 重点1:通过ospf路由协议配置拓扑网络,知识点:ospf配置路由器协议语法格式,area区域的定义,区域内网络的配置࿰…...

React路由快速入门:Class组件和函数式组件的使用
1. 介绍 在开始学习React路由之前,先了解一下什么是React路由。React Router是一个为React应用程序提供声明式路由的库。它可以帮助您在应用程序中管理不同的URL,并在这些URL上呈现相应的组件。 2. 安装 要在React应用程序中使用React路由,…...
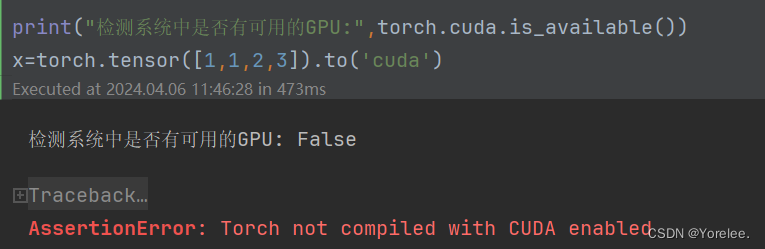
Pytorch数据结构:GPU加速
文章目录 一、GPU加速1. 检查GPU可用性:2. GPU不可用需要具体查看问题3. 指定设备4.将张量和模型转移到GPU5.执行计算:6.将结果转移回CPU 二、转移原理1. 数据和模型的存储2. 数据传输3. 计算执行4. 设备管理5.小结 三、to方法的参数类型 一、GPU加速 .…...

OpenHarmony开发-连接开发板调试应用
在 OpenHarmony 开发过程中,连接开发板进行应用调试是一个关键步骤,只有在真实的硬件环境下,我们才能测试出应用更多的潜在问题,以便后续我们进行优化。本文详细介绍了连接开发板调试 OpenHarmony 应用的操作步骤。 首先…...

告别手改脚本!用CANoe Panel面板做个变量控制台,测试效率翻倍
告别手改脚本!用CANoe Panel面板打造智能变量控制台 在车载网络测试领域,效率提升往往隐藏在那些被忽视的日常操作细节中。当测试工程师频繁打开CAPL脚本修改超时阈值、调整诊断ID或切换测试模式时,不仅打断了工作流,更在团队协作…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

Wand-Enhancer:免费解锁WeMod专业版功能的终极本地增强工具
Wand-Enhancer:免费解锁WeMod专业版功能的终极本地增强工具 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费用…...

地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书
地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书 副标题:全要素三维动态重建井下场景,融合井下无感坐标解算、跨断面跨镜轨迹串联、身体指纹人员轨迹存档,井下风险前置感知、动态全程透明追溯 前言 矿山井下深部硐室与纵…...

Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南
Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ker…...

ElevenLabs匈牙利语音API响应延迟飙升300%?内网穿透+CDN缓存+匈牙利语音素预加载三阶优化方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs匈牙利文语音API响应延迟飙升300%的现象复现与根因定位 近期多位开发者反馈,ElevenLabs API 在处理匈牙利语(hu-HU)文本转语音请求时,平均端到…...

Ruby LLM框架:为Ruby开发者打造的大语言模型应用开发工具包
1. 项目概述:一个为Ruby语言量身打造的LLM应用框架如果你是一名Ruby开发者,最近被各种大语言模型(LLM)的应用搞得心痒痒,但看着满世界的Python库和框架感到无从下手,那么crmne/ruby_llm这个项目可能就是你在…...
如何构建鲁棒的点云局部描述符)
从理论到实践:三维形状上下文(3DSC)如何构建鲁棒的点云局部描述符
1. 为什么我们需要三维形状上下文(3DSC) 想象一下你正在玩一个拼图游戏,但所有碎片都被随机撒上了胡椒粉,有些碎片还被书本盖住了一角。这就是计算机处理含噪声、遮挡的点云数据时的真实处境。在机器人导航、自动驾驶或者工业质检中,我们经常…...
)
【2026年阿里巴巴集团暑期实习- 5月16日-算法岗-第一题- 分组计数】(题目+思路+JavaC++Python解析+在线测试)
题目内容 给定 nnn 个人的权值序列 a1,a2,…,ana_1,a_2,\dots,a_na...

Linux光标主题管理工具x-cursor-help:从原理到实战
1. 项目概述:一个被低估的鼠标光标辅助工具如果你在Linux桌面环境下工作,尤其是使用像GNOME、KDE Plasma这类现代化的桌面环境,你可能会遇到一个不大不小但很恼人的问题:鼠标光标主题的安装和管理。从网上下载了一个漂亮的.tar.gz…...