Transformer详解和知识点总结
目录
- 1. 注意力机制
- 1.1 注意力评分函数
- 1.2 多头注意力(Multi-head self-attention)
- 2. Layer norm
- 3. 模型结构
- 4. Attention在Transformer中三种形式的应用
论文:https://arxiv.org/abs/1706.03762
李沐B站视频:https://www.bilibili.com/video/BV1pu411o7BE/?spm_id_from=333.788&vd_source=21011151235423b801d3f3ae98b91e94
D2L: https://zh.d2l.ai/chapter_attention-mechanisms/index.html
知乎讲解:https://zhuanlan.zhihu.com/p/639123398
1. 注意力机制
注意力机制由三个重要组成部分:query, key, value, query和key通过注意力评分函数计算出注意力权重,用于对value进行加权平均,得到最后的输出,如下图所示:
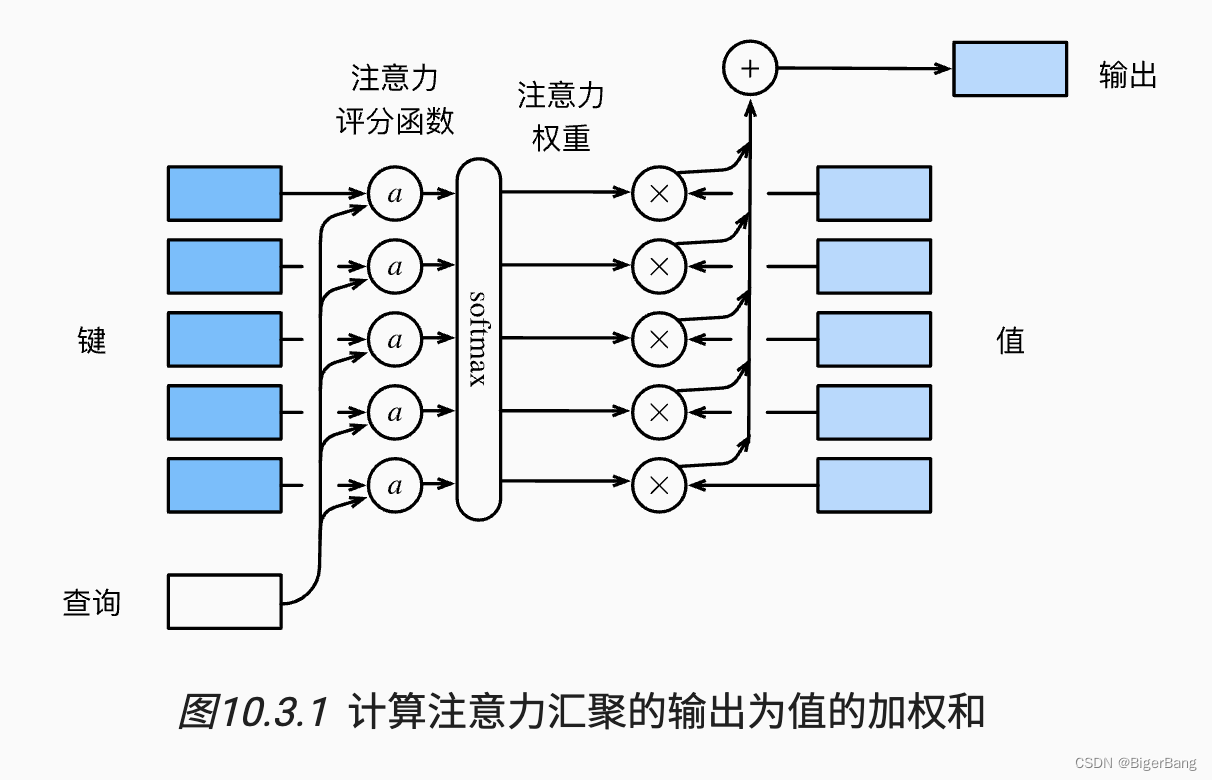
举例:
如果:
key的维度为(m, k),表示有m个key,每个key的向量维度为k;
value的维度为(m,v), 表示有m个value(key和value的个数一定相同),每个value的向量维度为v;
那么给定一个query的维度为(q), 那么通过注意力评分函数W(query, key)将得到一个维度为(m)的权重向量, 这个权重向量与value相乘,就完成了每个特征的加权求和,得到的维度为(v)。
当然也可以一个求多个query的结果,比如query是(n,q), 最后得到的结果维度就是(n, v);
1.1 注意力评分函数
常用的注意力评分函数有两种:加性注意力(Additive Attention)和 点积注意力 (Dot-Product Attention),Transformer这篇论文采用的是缩放点积注意力(Scaled Dot-Product Attention),就是在点积注意力的基础上加入一个缩放;
-
加性注意力
当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。

先使用两个全连接层,将query和key统一到相同长度,然后将每一个query都和每一个键相加,再经过一个线性映射得到注意力权重
-
缩放点积注意力


-
为什么要缩放?
- 当dk的值比较小的时候,这两个机制的性能相差相近,当dk比较大时,加法attention比不带缩放的点积attention性能好。我们怀疑,维度dk很大时,点积结果也变得很大,那么某些向量中间的注意力分数将占绝对主导地位,将softmax函数推向具有极小梯度的区域。为了抵消这种影响,我们将点积缩小1/sqrt(dk)倍。
- 假设query和Key的所有元素都是独立的随机变量,并满足零均值和单位方差,那么两个向量点积的均值为0,方差为d(d为向量维度)。为保证点积的方差仍是1,那么就要将点积除以sqrt(d)
1.2 多头注意力(Multi-head self-attention)

-
类似于卷集中的多通道,可学习到不同模式
- 增加可学习的参数:本身缩放点积注意力是没什么参数可以学习的,就是计算点积、softmax、加权和而已。但是使用
Multi-head attention之后,投影到低维的权重矩阵W_Q, W_K, W_V是可以学习的,而且有h=8次学习机会。 - 多语义匹配:使得模型可以在不同语义空间下学到不同的的语义表示,也扩展了模型关注不同位置的能力。类似卷积中多通道的感觉。例如,“小明养了一只猫,它特别调皮可爱,他非常喜欢它”。“猫”从指代的角度看,与“它”的匹配度最高,但从属性的角度看,与“调皮”“可爱”的匹配度最高。标准的 Attention 模型无法处理这种多语义的情况。
- 注意力结果互斥:自注意力结果需要经过softmax归一化,导致自注意力结果之间是互斥的,无法同时关注多个输人。 使用多组自注意力模型产生多组不同的注意力结果,则不同组注意力模型可能关注到不同的输入,从而增强模型的表达能力。
- 增加可学习的参数:本身缩放点积注意力是没什么参数可以学习的,就是计算点积、softmax、加权和而已。但是使用
-
多头注意力对计算量没有影响
多头注意力的每个头单独通过矩阵运算进行注意力计算,也可以合并成一次矩阵运算
2. Layer norm
从下面两幅示意图可以清楚的理解Layer norm以及其和Batch norm等normalization模块的区别;
下图截取自何凯明在MIT的演讲PPT:

下图截取自沐神B站视频,蓝色是BN,黄色是LN

可以这么理解,BN是针对每个特征,对所有的样本计算均值和方差;而LN是针对每个样本,对这个样本的所有特征计算均值和方差;
如果输入的shape为(B, C, H, W),那么BN的均值和方差的维度是(1,C, 1, 1), 计算机视觉中的LN的均值和方差维度为(B, 1, 1, 1), transformer中的均值和方差维度为(B,1, H, W),instance norm的均值和方差维度为(B, 1, 1, 1), group norm 的均值和方差维度为(B, C/m, 1, 1)
-
为什么不使用batch norm?
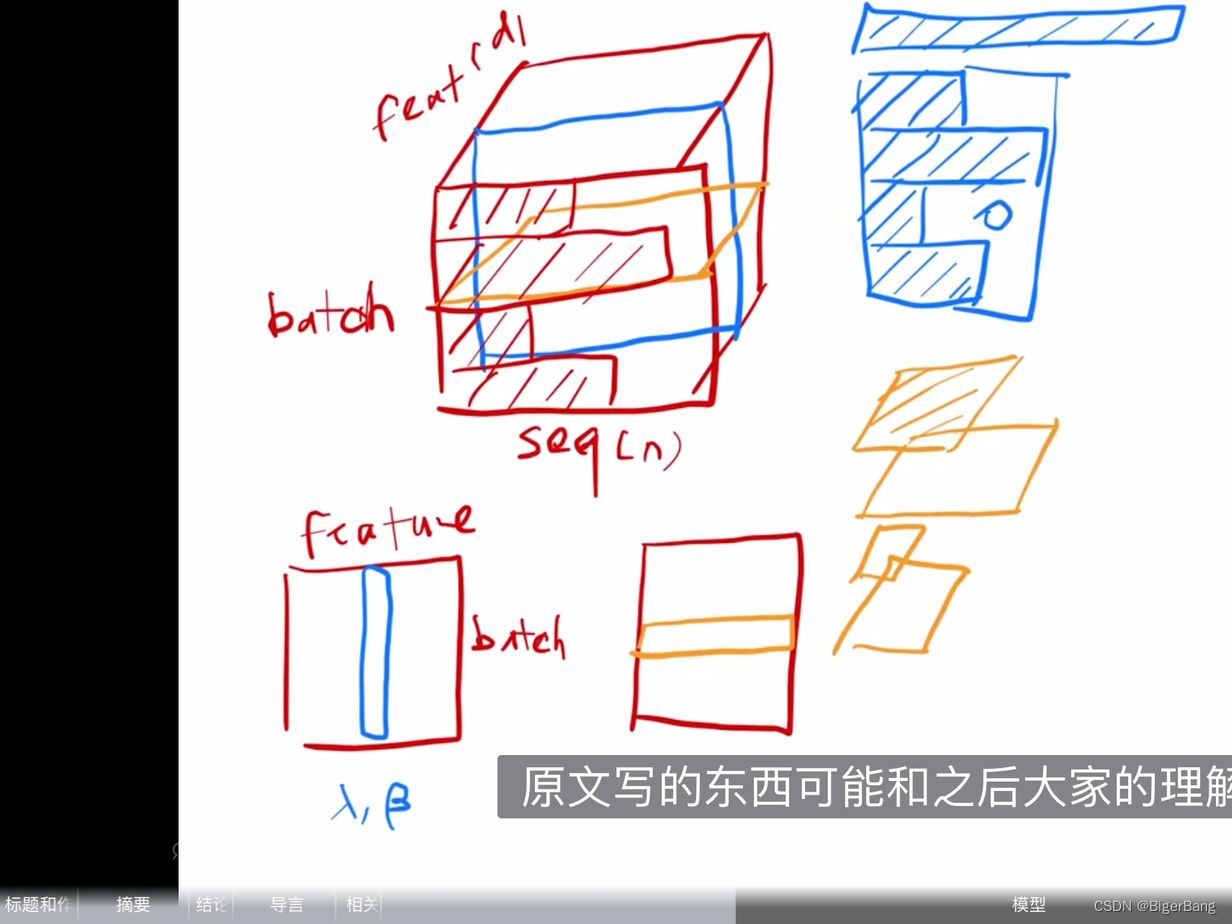
为什么这里使用LN而不是BN?
- 计算变长序列时,每个Batch中的序列长度是不同的,如上图的蓝色示意图,这样在一个batch中做均值时,变长序列后面会pad 0,这些pad部分是没有意义的,这样进行特征维度做归一化缺少实际意义。
- 序列长度变化大时,计算出来的均值和方差抖动很大。
- 预测时使用训练时记录下来的全局均值和方差。如果预测时新样本特别长,超过训练时的长度,那么之前记录的均值和方差可能会不适用,预测会出现问题。
而Layer Normalization在每个序列内部进行归一化,不存在这些问题:
- NLP任务中一个序列的所有token都是同一语义空间,进行LN归一化有实际意义
- 因为实是在每个样本内做的,序列变长时相比BN,计算的数值更稳定。
- 不需要存一个全局的均值和方差,预测样本长度不影响最终结果。
3. 模型结构
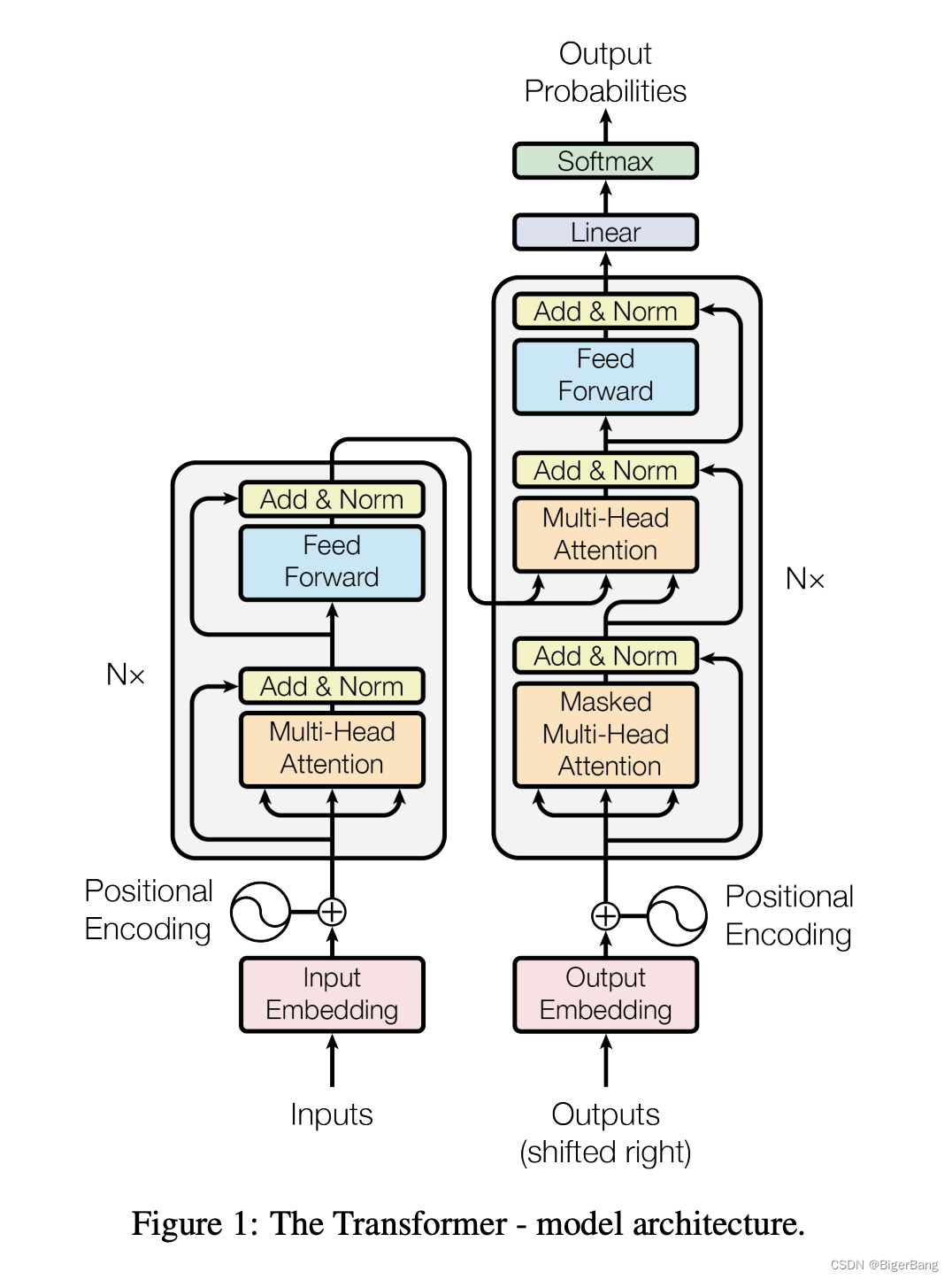
大多数的机器翻译网络都是这种encoder-decoder架构
-
Inputs 和 Outputs
本篇文章做的是机器翻译任务,比如若是完成中译英问题,inputs则是中文句子,outputs是英文翻译结果;
在翻译时采用的是auto-regressive,也就是网络在翻译当前词的时候不仅使用中文句子的信息,也会将已经翻译出来的英文单词的信息作为输入,提取其中的信息预测下一个词;
At each step the model is auto-regressive [10], consuming the previously generated symbols as additional input when generating the next.
-
Embedding
将输入和输出的token转成具有d_model维度的向量;
we use learned embeddings to convert the input
tokens and output tokens to vectors of dimension d_model. -
位置编码 Positional Encoding
Attention计算时本身是不考虑位置信息的,这样序列顺序变化结果也是一样的。所以我们必须在序列中加入关于词符相对或者绝对位置的一些信息。
为此,我们将“位置编码”添加到token embedding中。二者维度相同(例如d_model
=512),所以可以相加。有多种位置编码可以选择,例如通过学习得到的位置编码和固定的位置编码。
关于位置编码可学习:https://zh.d2l.ai/chapter_attention-mechanisms/self-attention-and-positional-encoding.html
-
编码器
编码器由N=6个相同encoder层堆栈组成。如上图中所示,每个encoder层有两个子层:
multi-head self-attentionFFNN(前馈神经网络层,Feed Forward Neural Network),其实就是MLP,为了fancy一点,就把名字起的很长。
每个子层的形式可以表达为:LayerNorm(x + Sublayer(x)),其中Sublayer(x)是当前子层的输出, 两个子层都使用残差连接(residual connection),然后进行层归一化(layer normalization)。
为了简单起见,模型中的所有子层以及嵌入层的向量维度都是d_model=512(如果输入输出维度不一样,残差连接就需要做投影,将其映射到统一维度)。(这和之前的CNN或MLP做法是不一样的,之前都会进行一些下采样)
这种各层统一维度使得模型比较简单,只有N和d_model两个参数需要调。这个也影响到后面一系列网络,比如bert和GPT等等。
-
解码器
解码器:解码器同样由 N=6个相同的decoder层堆栈组成,每个层有三个子层。
-
Masked multi-head self-attention:解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法如下图所示:在 Self Attention 分数经过 Softmax 层之前,使用attention mask,屏蔽当前位置之后的那些位置。所以叫Masked multi-head self Attention。(对应masked位置使用一个很大的负数-inf,使得softmax之后其对应值为0)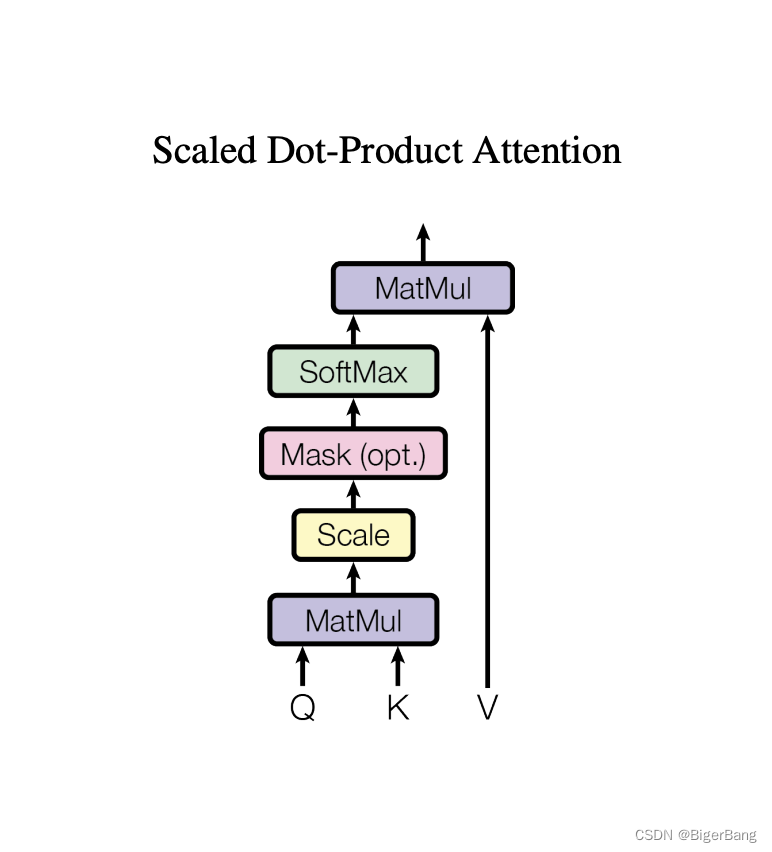
-
Encoder-Decoder Attention:也就是解码器中的第二个MHA层,这一个MHA的query是解码器的上一输出,key和 value都来自编码器输出最终向量,用来帮解码器把注意力集中中输入序列的合适位置。 -
FFNN:依然是MLP层
-
4. Attention在Transformer中三种形式的应用
multi-head self attention:标准的多头自注意力层,用在encoder的第一个多头自注意力层。所有key,value和query来自同一个地方,即encoder中前一层的输出。在这种情况下,encoder中的每个位置都可以关注到encoder上一层的所有位置。masked-self-attention:用在decoder中,序列的每个位置只允许看到当前位置之前的所有位置,这是为了保持解码器的自回归特性,防止看到未来位置的信息encoder-decoder attention:用于encoder block的第二个多头自注意力层。query来自前面的decoder层,而keys和values来自encoder的输出memory。这使得decoder中的每个位置都能关注到输入序列中的所有位置。
相关文章:
Transformer详解和知识点总结
目录 1. 注意力机制1.1 注意力评分函数1.2 多头注意力(Multi-head self-attention) 2. Layer norm3. 模型结构4. Attention在Transformer中三种形式的应用 论文:https://arxiv.org/abs/1706.03762 李沐B站视频:https://www.bilibi…...

【Ubuntu】update-alternatives 命令详解
1、查看所有候选项 sudo update-alternatives --list java 2、更换候选项 sudo update-alternatives --config java 3、自动选择优先级最高的作为默认项 sudo update-alternatives --auto java 4、删除候选项 sudo update-alternatives --rem…...

数据结构之堆练习题及PriorityQueue深入讲解!
题外话 上午学了一些JavaEE初阶知识,下午继续复习数据结构内容 正题 本篇内容把堆的练习题做一下 第一题 1.下列关键字序列为堆的是:( A ) A: 100,60,70,50,32,65 B: 60,70,65,50,32,100 C: 65,100,70,32,50,60 D: 70,65,100,32,50,60 E: 32,50,100,70,65,60 …...

MySQL——Linux安装包
一、下载安装包 MySQL下载路径: MySQL :: MySQL Downloads //默认下载的企业版MySQL 下载社区版MySQL MySQL :: MySQL Community Downloads 1、源码下载 2、仓库配置 3、二进制安装包 基于官方仓库安装 清华centos 软件仓库: Index of /cen…...

MySQL学习笔记(数据类型, DDL, DML, DQL, DCL)
Learning note 1、前言2、数据类型2.1、数值类型2.2、字符串类型2.3、日期类型 3、DDL总览数据库/表切换数据库查看表内容创建数据库/表删除数据库/表添加字段删除字段表的重命名修改字段名(以及对应的数据类型) 4、DML往字段里写入具体内容修改字段内容…...
)
Asible管理变量与事实——管理变量(1)
Ansible简介 Ansible支持利用变量来储存值,并在Ansible项目的所有文件中重复使用这些值。这可以简化项目的创建和维护,并减少错误的数量。 通过变量,您可以轻松地在Ansible项目中管理给定环境的动态值。例如,变量可能包含下面这些…...

【微服务】------微服务架构技术栈
目前微服务早已火遍大江南北,对于开发来说,我们时刻关注着技术的迭代更新,而项目采用什么技术栈选型落地是开发、产品都需要关注的事情,该篇博客主要分享一些目前普遍公司都在用的技术栈,快来分享一下你当前所在用的技…...
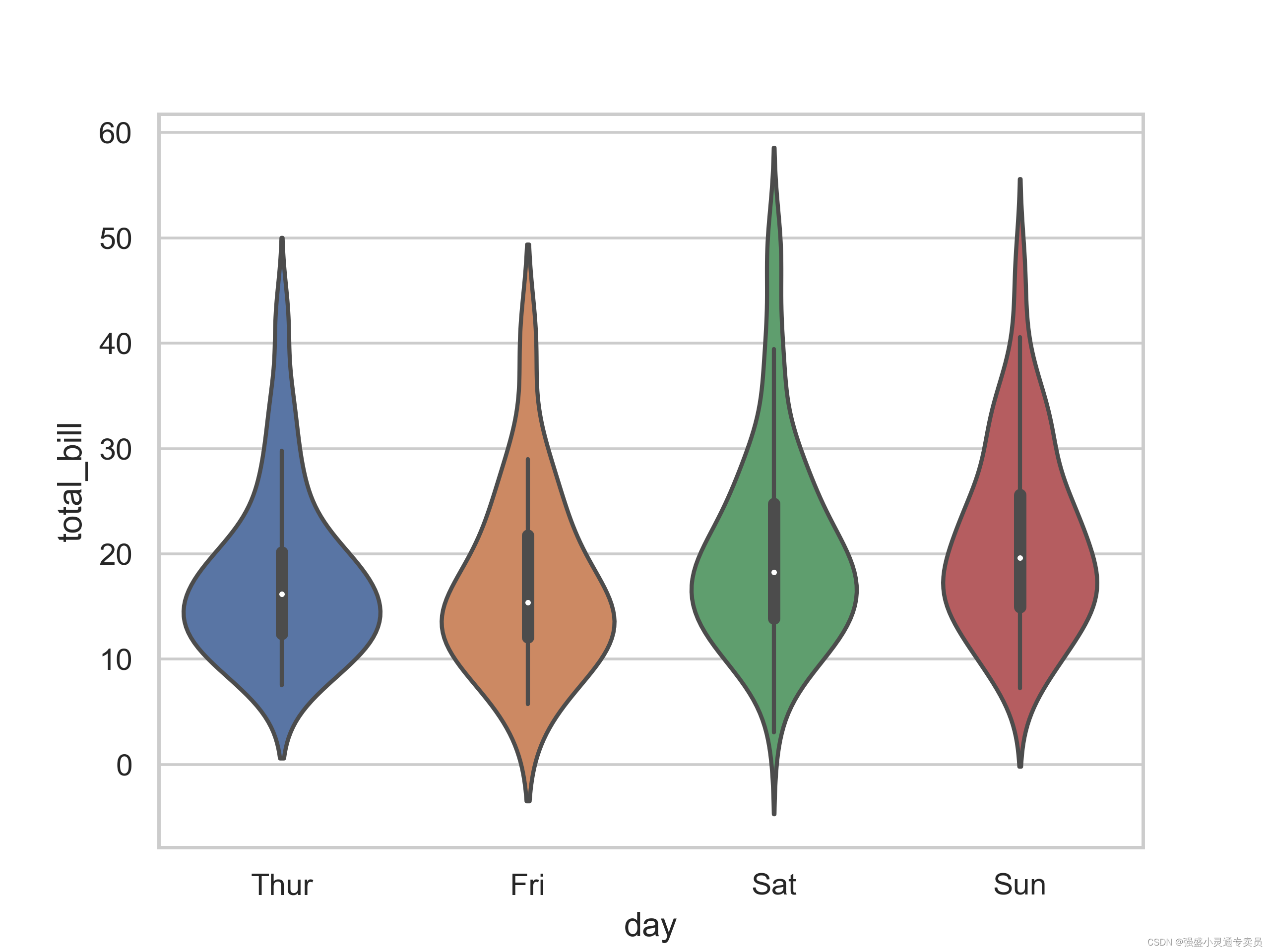
【SCI绘图】【小提琴系列1 python】绘制按分类变量分组的垂直小提琴图
SCI,CCF,EI及核心期刊绘图宝典,爆款持续更新,助力科研! 本期分享: 【SCI绘图】【小提琴系列1 python】绘制按分类变量分组的垂直小提琴图,文末附完整代码 小提琴图是一种常用的数据可视化工具…...
docker------docker入门
🎈个人主页:靓仔很忙i 💻B 站主页:👉B站👈 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:Linux 🤝希望本文对您有所裨益,如有不足之处&#…...

终极数据传输隐秘通道
SOCKS5代理作为网络请求中介的高级形态,提供了一种方法,通过它,数据包在传达其最终目的地前,首先经过一个第三方服务器。这种代理的先进之处在于其对各种协议的支持,包括HTTP、FTP和SMTP,以及它的认证机制&…...

Qt中的事件与事件处理
Qt框架中的事件处理机制是其GUI编程的核心部分,它确保了用户与应用程序之间的交互能够得到正确的响应。以下是对Qt事件处理机制的详细讲解以及提供一些基本示例。 1. 事件与事件处理简介 事件:在Qt中,所有的事件都是从QEvent基类派生出来的&…...
中间件漏洞攻防学习总结
前言 面试常问的一些中间件,学习总结一下。以下环境分别使用vulhub和vulfocus复现。 Apache apache 文件上传 (CVE-2017-15715) 描述: Apache(音译为阿帕奇)是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨…...

HarmonyOS开发实例:【分布式数据管理】
介绍 本示例展示了在eTS中分布式数据管理的使用,包括KVManager对象实例的创建和KVStore数据流转的使用。 通过设备管理接口[ohos.distributedDeviceManager],实现设备之间的kvStore对象的数据传输交互,该对象拥有以下能力 ; 1、注册和解除注…...

蓝桥杯——运动会
题目 n 个运动员参加一个由 m 项运动组成的运动会,要求每个运动员参加每个项目。每个运动员在每个项目都有一个成绩,成绩越大排名越靠前。每个项目,不同运功员的成绩不会相 同,因此排名不会相同。(但是不同项目可能成绩会相同) 每…...

如何搭建APP分发平台分发平台搭建教程
搭建一个APP分发平台可以帮助开发者更好地分发和管理他们的应用程序。下面是一个简要的教程,介绍如何搭建一个APP分发平台。 1.确定需求和功能:首先,确定你的APP分发平台的需求和功能。考虑以下几个方面: 用户注册和登录ÿ…...

【计算机专业必看】详细说明文件打开模式r,w,a,r+,w+,a+的区别和联系
文章目录 1、联系2、区别r(只读)w(只写)a(追加)r(读写,文件必须存在)w(读写,文件不存在则创建,存在则清空)a(读…...

Db2数据库稳定性解决方案
常见的数据库查询或写入慢,一般有以下情况 1、数据库经常有删除或有大量查询,(导致磁盘碎裂,数据库缓存堆积) 2、数据量大,导致在查询或写入时,由于负载高,导致系统慢 3、业务代码…...

如何用Python编写简单的网络爬虫(页面代码简单分析过程)
一、什么是网络爬虫 在当今信息爆炸的时代,网络上蕴藏着大量宝贵的信息,如何高效地从中获取所需信息成为了一个重要课题。网络爬虫(Web crawler)作为一种自动化工具,可以帮助我们实现这一目标,用于数据分析…...

【随笔】Git 高级篇 -- 最近标签距离查询 git describe(二十一)
💌 所属专栏:【Git】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! 💖 欢迎大…...
)
【leetcode面试经典150题】7.买卖股票的最佳时机(C++)
【leetcode面试经典150题】专栏系列将为准备暑期实习生以及秋招的同学们提高在面试时的经典面试算法题的思路和想法。本专栏将以一题多解和精简算法思路为主,题解使用C语言。(若有使用其他语言的同学也可了解题解思路,本质上语法内容一致&…...

ARM TRCCONFIGR寄存器解析与调试追踪实践
1. ARM TRCCONFIGR寄存器深度解析在嵌入式系统开发和处理器调试领域,ARM架构的调试追踪技术一直是工程师们分析程序执行流程、定位性能瓶颈的利器。作为ARMv8/v9架构中调试系统的核心组件,TRCCONFIGR寄存器扮演着追踪配置控制中心的角色。这个64位的系统…...

为什么你的电脑风扇总是“抽风“?3个简单步骤彻底解决Windows风扇控制难题
为什么你的电脑风扇总是"抽风"?3个简单步骤彻底解决Windows风扇控制难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://git…...

如何用Xenia Canary模拟器重温Xbox 360经典游戏?终极配置与优化指南
如何用Xenia Canary模拟器重温Xbox 360经典游戏?终极配置与优化指南 【免费下载链接】xenia-canary Xbox 360 Emulator Research Project 项目地址: https://gitcode.com/gh_mirrors/xe/xenia-canary Xenia Canary是一款免费开源的Xbox 360游戏模拟器&#…...

MAA助手:解放双手的明日方舟全自动游戏管理工具实战指南
MAA助手:解放双手的明日方舟全自动游戏管理工具实战指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://g…...

InfluxDB 备份恢复避坑指南:为什么你的 `influxd restore` 总失败?元数据与DB数据详解
InfluxDB 备份恢复深度解析:从原理到实战的完整避坑手册 1. 为什么你的InfluxDB恢复操作总是失败? 在运维InfluxDB的日常工作中,备份恢复是最容易"翻车"的操作之一。许多工程师都遇到过这样的场景:明明按照官方文档执行…...

UPS不间断电源正确使用指南:从开机到维护,一文掌握核心要点
凌晨两点,服务器机房突然跳闸,运维人员慌乱中误按UPS不间断电源关机键,导致核心数据丢失——这样的事故,本可通过规范操作避免。UPS电源作为电力保障的“最后一道防线”,其使用方法直接影响设备寿命与数据安全。本文结…...

Office RibbonX Editor:免费开源Office界面定制终极指南
Office RibbonX Editor:免费开源Office界面定制终极指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

自建密码管理器:基于Web Crypto API与Flask的零知识安全架构实践
1. 项目概述:一个基于Web的密码管理器最近在GitHub上看到一个挺有意思的项目,叫clawvault。乍一看名字,可能会联想到“爪子”和“保险库”,其实它就是一个用Python写的、基于Web界面的密码管理器。这类工具大家应该不陌生…...

如何3步搞定LaTeX中文排版?告别字体缺失烦恼的终极方案
如何3步搞定LaTeX中文排版?告别字体缺失烦恼的终极方案 【免费下载链接】latex-chinese-fonts Simplified Chinese fonts for the LaTeX typesetting. 项目地址: https://gitcode.com/gh_mirrors/la/latex-chinese-fonts 还在为LaTeX中文排版头疼吗ÿ…...

华为HarmonyOS用户必看:5分钟搞定MicroG完整安装与权限配置指南
华为HarmonyOS用户必看:5分钟搞定MicroG完整安装与权限配置指南 【免费下载链接】GmsCore Free implementation of Play Services 项目地址: https://gitcode.com/GitHub_Trending/gm/GmsCore 还在为华为HarmonyOS设备无法使用Google服务而烦恼吗?…...