如何用Python编写简单的网络爬虫(页面代码简单分析过程)
一、什么是网络爬虫
在当今信息爆炸的时代,网络上蕴藏着大量宝贵的信息,如何高效地从中获取所需信息成为了一个重要课题。网络爬虫(Web crawler)作为一种自动化工具,可以帮助我们实现这一目标,用于数据分析、搜索引擎优化、信息监测等目的。由于Python语言有易学、丰富的库和爬虫框架、多线程支持、跨平台支持和强大的数据处理能力等特点,在编写爬虫方面具有得天独厚的优势,这些优势使得Python成为爬虫开发的首选语言。本文介绍了一般网络爬虫的实现过程,并介绍如何Python语言编写一个简单的网络爬虫。
二、网络爬虫的实现步骤
网络爬虫的实现可概括为以下几个步骤:
-
发送HTTP请求: 网络爬虫首先向目标网站发送HTTP请求,请求特定的页面内容。这通常是使用Python中的
requests库或类似工具来完成的。 -
获取页面内容: 网络爬虫接收到服务器的响应后,获取页面的HTML内容。这个内容可能包含文本、图片、视频、链接等信息。
-
解析页面内容: 爬虫将获取到的HTML内容进行解析,通常使用HTML解析器(如
BeautifulSoup)来提取出需要的信息,比如链接、文本、图片等。 -
链接提取: 在解析页面内容的过程中,爬虫会提取出页面中的链接。这些链接可以是其他页面的URL,也可以是资源文件(如图片、视频)的URL。
-
递归爬取: 爬虫将提取到的链接作为新的目标,继续发送HTTP请求并获取页面内容。这样就形成了一个递归的过程,爬虫不断地发现新的页面,并从中提取出更多的链接。
-
数据处理与存储: 爬虫在提取到数据后,可能需要进行进一步的处理和清洗,然后将数据存储到本地文件或者数据库中供后续使用。
-
异常处理与反爬虫策略: 在爬取过程中,可能会遇到各种异常情况,如网络连接错误、页面解析错误等。爬虫需要考虑这些异常情况并进行适当的处理,同时也需要应对目标网站可能采取的反爬虫策略,如设置User-Agent、使用代理IP、降低爬取速度等。
总的来说,网络爬虫的原理就是模拟人类用户的行为,通过发送HTTP请求获取页面内容,然后解析页面内容提取出需要的信息。通过不断地递归爬取和处理,爬虫可以从互联网上收集到大量的数据。
三、如何用python编写一个简单的爬虫?
在Python中,我们可以使用第三方库如requests和BeautifulSoup来编写一个最简单的网络爬虫。以下是一个简单的示例,用于爬取西安电子科技大学研究生院的通知公告栏目第一页中的标题及相应链接:
第一步:安装所需库
首先,我们需要安装requests和BeautifulSoup库。如果这两个库没有安装,可以进入命令行,
使用以下命令来安装:
pip install requests
pip beautifulsoup4 第二步:分析要爬取的页面
1、查看robots.txt
爬取页面前,首先要确定该网站是否允许通过爬虫获取数据。网站是否允许爬虫爬取数据,以及允许爬取哪些资源,一般都是通过robots.txt来确定。
比如知乎,只允许一些知名搜索引擎去爬取特定目录,其他的爬虫,则不允许爬取其网站数据。
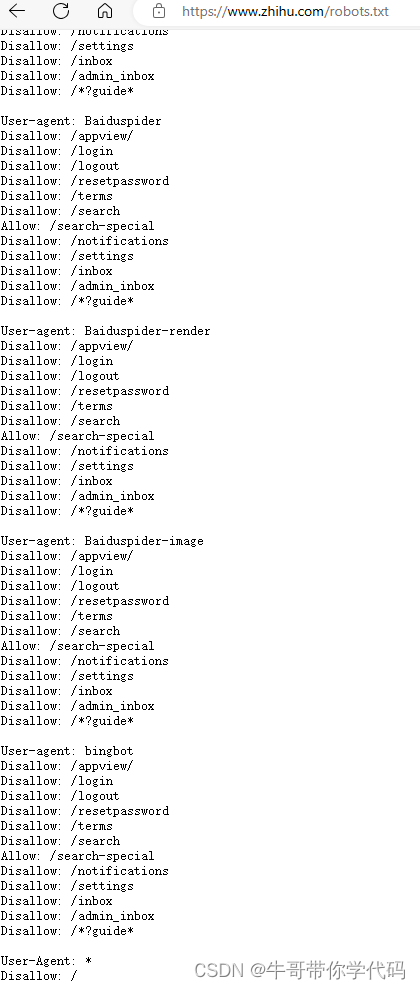
西安电子科技大学研究生院的网址是https://gr.xidian.edu.cn/,加上robots.txt,就是链接就是https://gr.xidian.edu.cn/robots.txt,未设置robots.txt文件进行说明,未做限制,那就拿它来试一下吧。经测试,西电网站确实比较友好,即使不修改,将爬虫伪装成浏览器,获取信息也没有什么困难。
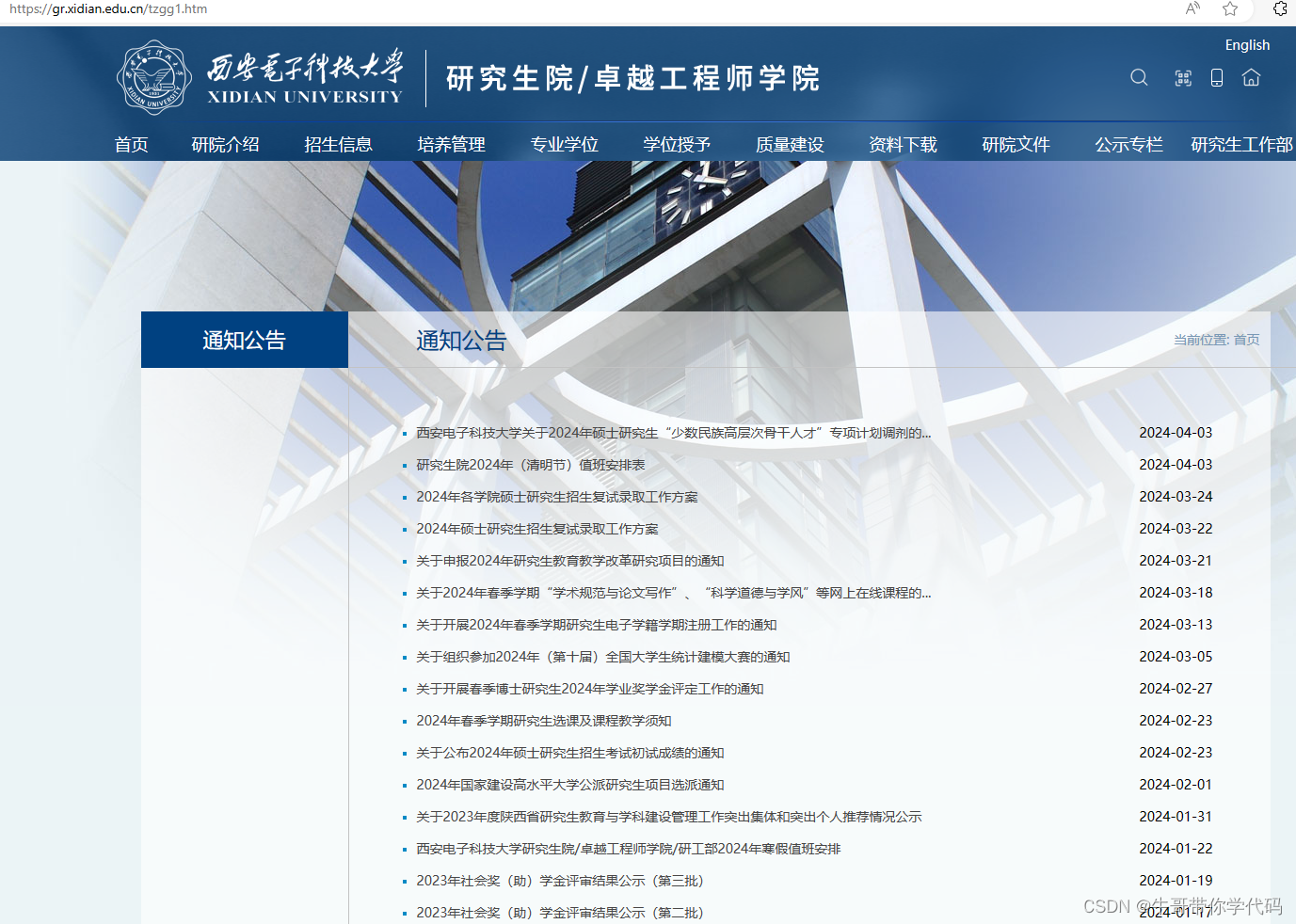
2、使用开发者工具对目标页面进行分析
打开网站通知公告栏目,可以看到网址是https://gr.xidian.edu.cn/tzgg1.htm
在浏览器中按F12,进入开发者工具。
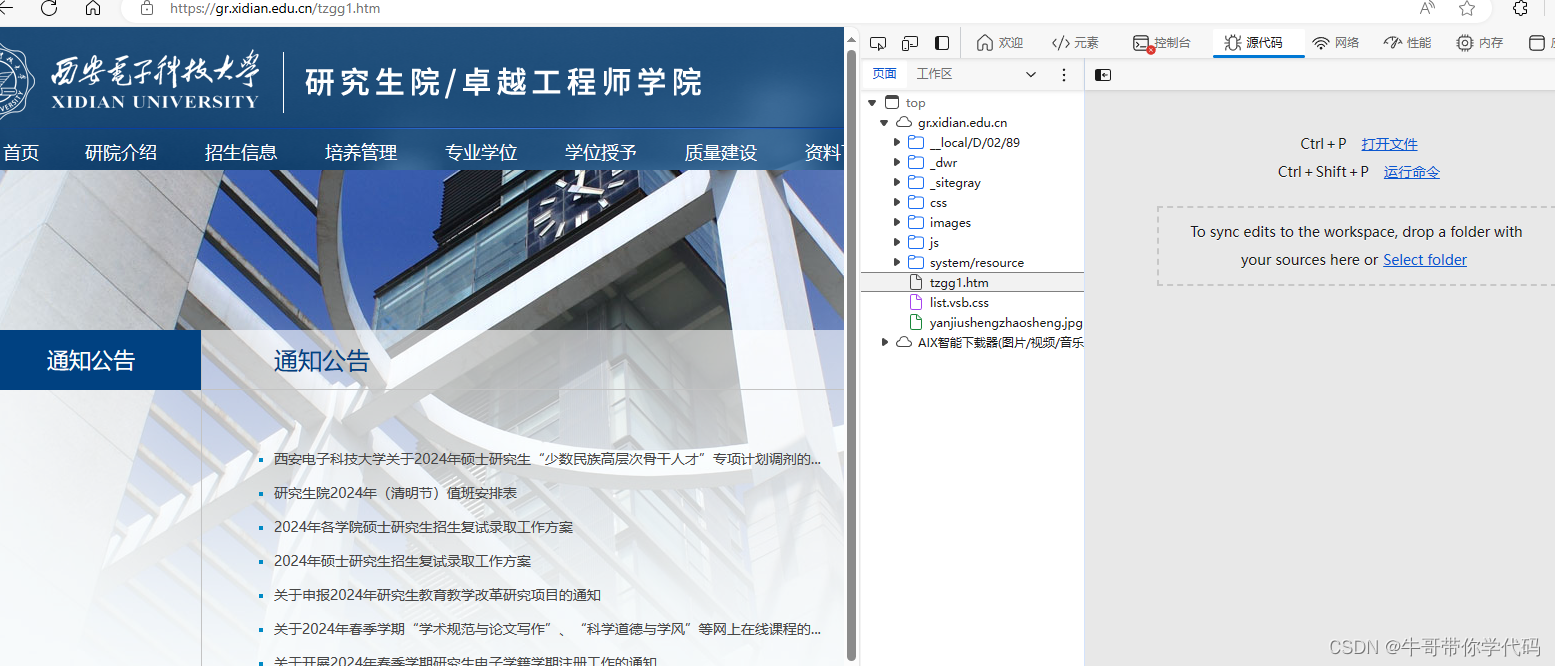
在开发者工具中选择“网络”-“全部”,然后再点击浏览器中左上角的刷新按钮。你会发现,刷新这一页面后,下载了好多东西,既有htm文件,又有css文件,还有js文件以及jpg图像文件等。一般来说,HTML文件(或htm文件)负责网页的架构;CSS文件负责网页的样式和美化;JavaScript(JS)则是负责网页的行为。正是因为这些文件相互配合,才使得页面能够正常显示。
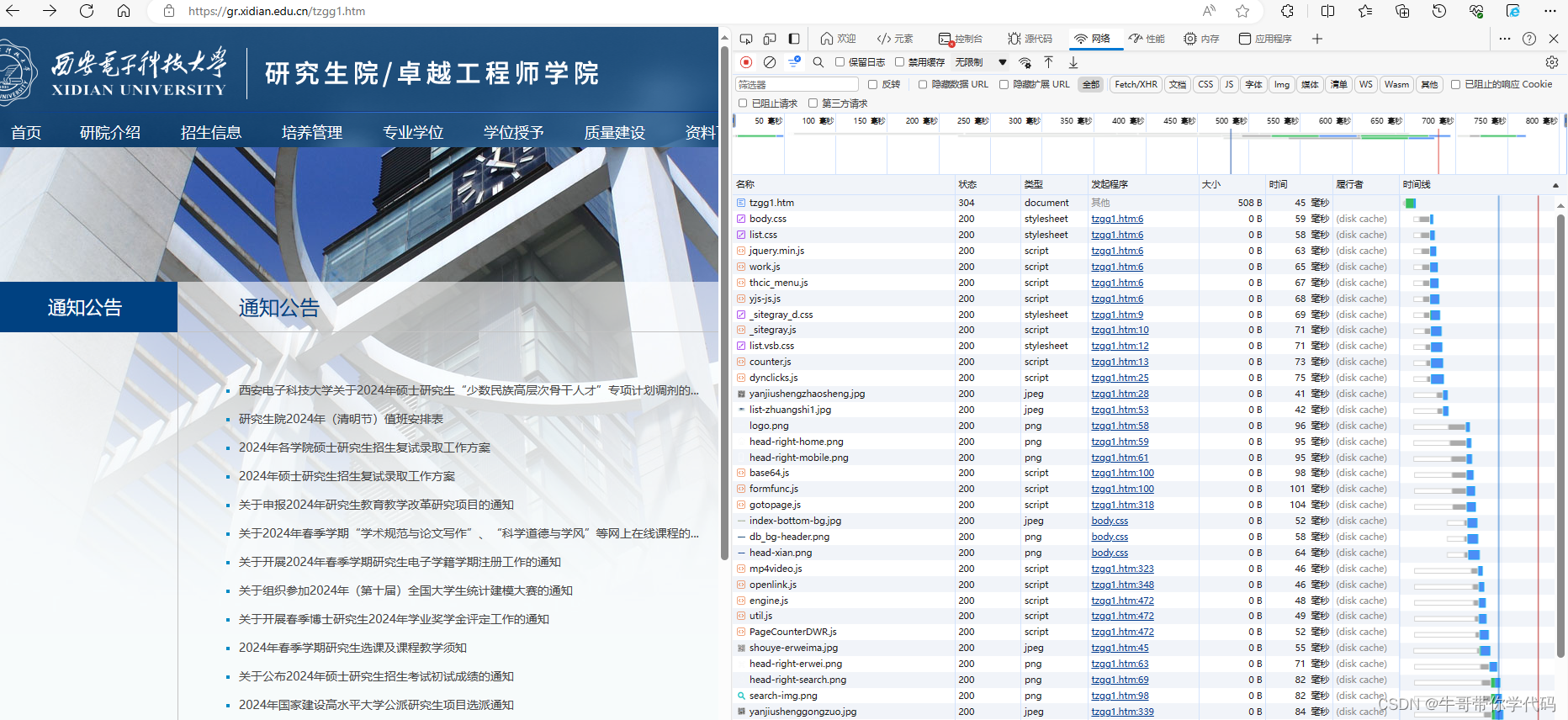
从浏览器的网址来看,通知公告的首页网址对应的文件应该是tzgg1.htm,从文件大小来比较,它的信息量也是最大的,点击它后,点击标头进行查看。
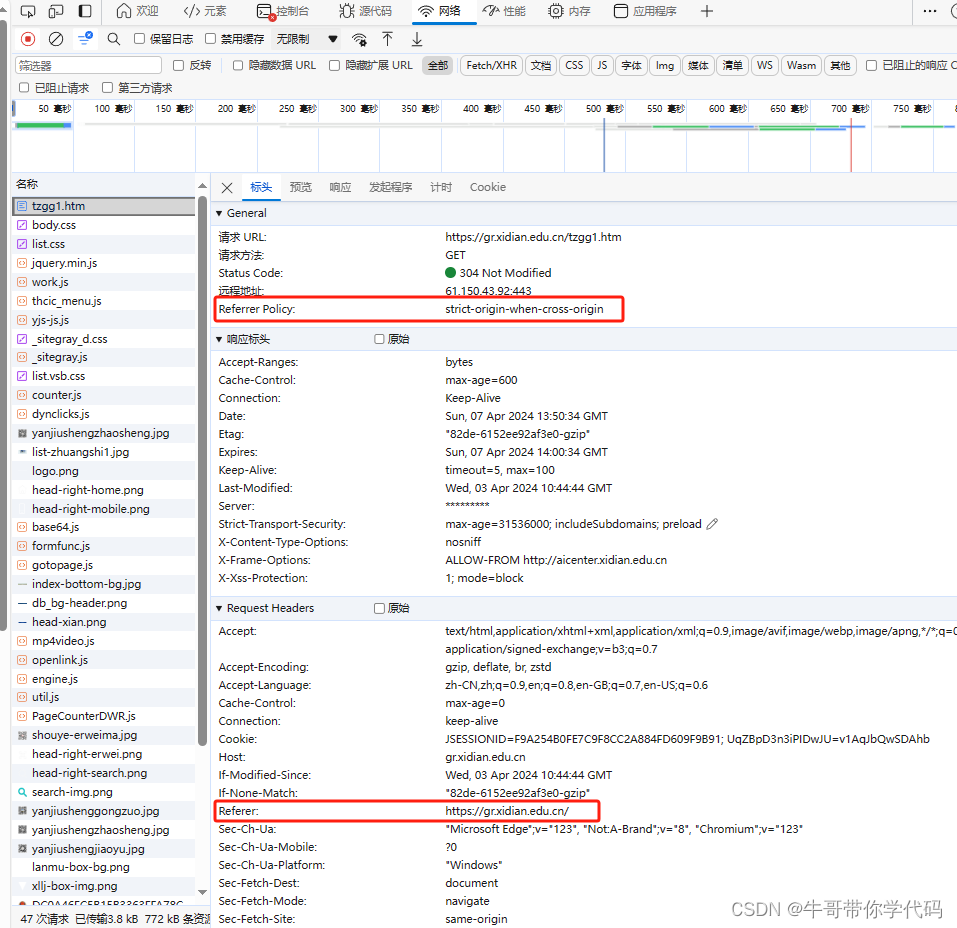
可以看到,标头中包含许多重要信息,是编写爬虫是必须要注意的部分。从标头中可以看到请示链接方法是用的GET方法,状态码是200为正常结束,GET方法相对于POST方法而言相对简单。发现这里使用了strict-origin-when-cross-origin的Referrer Policy,原以为这个策略会给我们的爬虫增加一些麻烦,结果并没有。
3、"strict-origin-when-cross-origin" 策略
"strict-origin-when-cross-origin" 是一种比较严格的 Referrer Policy 策略。它的行为如下:
- 当请求从一个页面 A 跳转到同一源的页面 B 时,Referrer 首部会包含完整的 URL 信息,包括路径和查询参数。这是为了确保目标页面 B 能够获取足够的信息来处理请求。
- 当请求从页面 A 跳转到不同源的页面 C 时,Referrer 首部只包含请求源的 origin 信息,而不包含路径或查询参数等详细信息。这是为了减少敏感信息的泄露。
可以看到通知公告首页面的Referer是主页面https://gr.xidian.edu.cn,我们正是从主页面进行通知公告栏目的,再点击下一页,可以看到Referer变成https://gr.xidian.edu.cn/tzgg1.htm,在站内不同页面之间的链接,是完全遵守"strict-origin-when-cross-origin" 策略的
原以为"strict-origin-when-cross-origin" 策略的引用可能是为防爬策略,不在Request Head中设置正确的Referer无法爬取正确的数据,结果似乎没什么影响,也许是因为动作太小吧。
编写网络爬虫相较于一般程序而言,性价比是比较低的,一是因为其一般没有什么通用性,一个网站的代码一种风格,规则也不一样;二是对于防爬做的好的网站,想将其分析透彻或是进行破解,可能要花费大量的时间。
4、源代码分析,查找链接对应的源代码
下面,我们要做的是,在页面源代码中找到有关通知标题对应的代码。
(1)源代码查找法
点击“响应”,可以看到网站服务器返回的响应信息,也就是文件tzgg1.htm的源代码,看到原页面中第一条通知包含“少数民族高层次骨干人才",点击代码,然后按Ctrl+F,输入“少数民族高层次骨干人才”回车,立即找到了相关的网页代码。
学习网络爬虫,是必须对HTML有一定了解的,但不需要精通,如果不太了解,可通过我写的另一篇博客快速了解HTML有关知识:HTML超详细教程_html教程-CSDN博客。
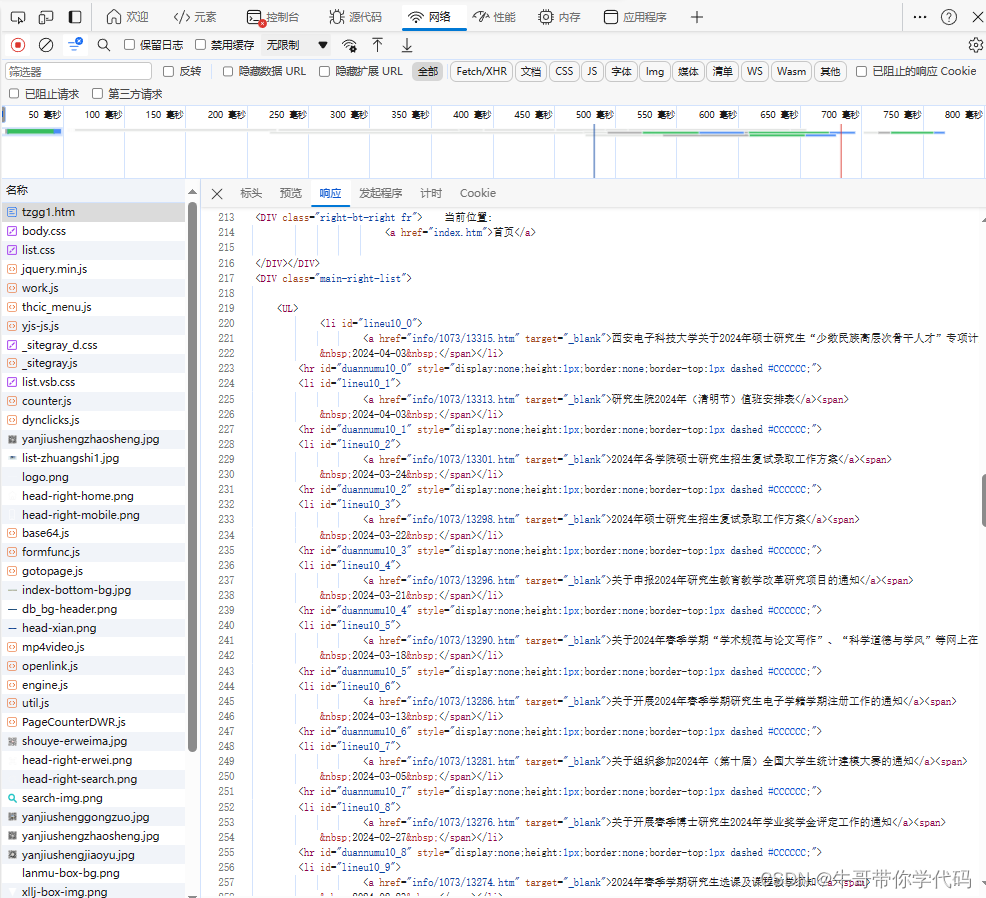
从代码中可以看到,通知都集中在<DIV class="main-right-list"> 中的 <UL>内,每条通知的标题和链接都包含在一个<li>的<a>内,
<DIV class="main-right-list"><UL><li id="lineu10_0"><a href="info/1073/13315.htm" target="_blank">西安电子科技大学关于2024年硕士研究生“少数民族高层次骨干人才”专项计划调剂的...</a><span> 2024-04-03 </span></li><hr id="duannumu10_0" style="display:none;height:1px;border:none;border-top:1px dashed #CCCCCC;"><li id="lineu10_1"><a href="info/1073/13313.htm" target="_blank">研究生院2024年(清明节)值班安排表</a><span> 2024-04-03 </span></li></UL>
</DIV>(2)元素查找定位法
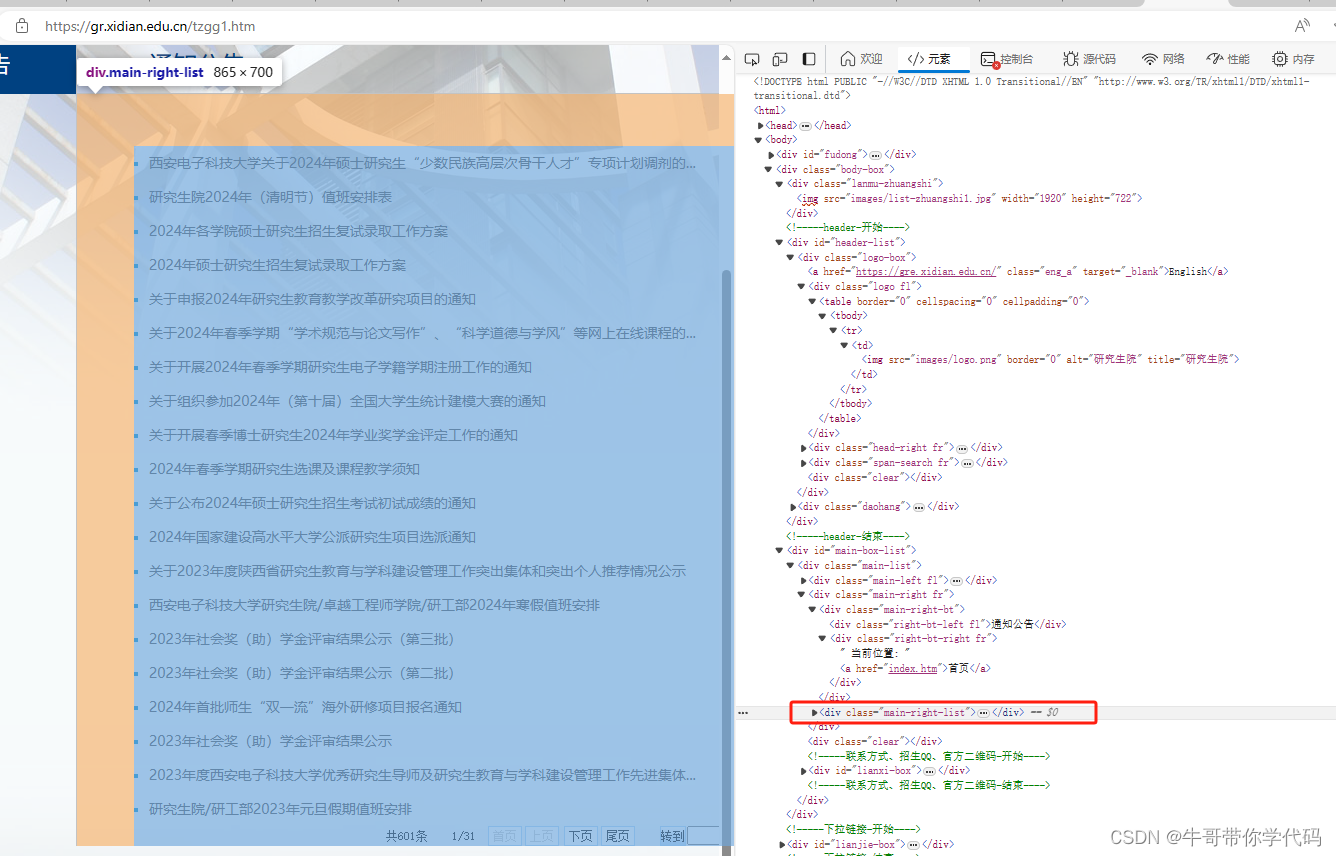
在开发工具中,点击“元素”,就可以将鼠标放在相应代码上,直接查看代码在左边页面上对应哪些模块。可也明显看到,通知的链接都在<div class="main-right-list">内,这样查找,更直观也更方便。
第二步:编写爬虫代码
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoupdef get_links(url):# 发送HTTP请求获取页面内容response = requests.get(url)#使用BeautifulSoup解析HTML内容soup = BeautifulSoup(response.content, "html.parser",from_encoding='utf-8')#定位到class名为main-right-list的divrightlist=soup.find('div', class_='main-right-list')# 找到div中所有链接并提取标题和URLlinks = rightlist.find_all("a")#链接只包含路径,未包含域名,将其补上return [(link.text, "https://gr.xidian.edu.cn/"+link.get("href")) for link in links]# 要爬取的网页URL
url = "https://gr.xidian.edu.cn/tzgg1.htm"# 获取链接并打印标题和URL
links = get_links(url)
for title, link in links:print(f"{title}: {link}")在这个示例中,我们首先使用requests库发送HTTP请求获取网页内容,然后使用BeautifulSoup库解析HTML内容。最后,我们提取所有链接的标题和URL,并将其打印出来。

在爬到的链接最后,列出了下一頁的网址,通过它就可以进行下一页的爬取,一直循环到将全部内容爬完,这里不再赘述。

四、爬虫使用注意事项
在编写爬虫时,还有一些注意事项需要注意:
- 尊重网站规则: 爬虫应该遵守网站的robots.txt文件,以确保不会对网站造成过度负荷或侵犯其隐私政策。
- 处理异常情况: 在爬取过程中,可能会遇到各种异常情况,如网络错误或页面解析错误。在编写爬虫时,应该考虑这些情况并进行适当处理。本文的爬虫比较简单,未进行异常处理。
- 频率控制: 为了避免对网站造成过度负荷,爬虫应该控制访问频率,并遵守网站的访问频率限制。
以上为个人爬虫学习的一点体会,如不当或不正确之处,欢迎指出,以便及时更正。

相关文章:
如何用Python编写简单的网络爬虫(页面代码简单分析过程)
一、什么是网络爬虫 在当今信息爆炸的时代,网络上蕴藏着大量宝贵的信息,如何高效地从中获取所需信息成为了一个重要课题。网络爬虫(Web crawler)作为一种自动化工具,可以帮助我们实现这一目标,用于数据分析…...

【随笔】Git 高级篇 -- 最近标签距离查询 git describe(二十一)
💌 所属专栏:【Git】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! 💖 欢迎大…...
)
【leetcode面试经典150题】7.买卖股票的最佳时机(C++)
【leetcode面试经典150题】专栏系列将为准备暑期实习生以及秋招的同学们提高在面试时的经典面试算法题的思路和想法。本专栏将以一题多解和精简算法思路为主,题解使用C语言。(若有使用其他语言的同学也可了解题解思路,本质上语法内容一致&…...

个人求职简历(精选8篇)
HR浏览一份简历也就25秒左右,如果你连「好简历」都没有,怎么能找到好工作呢? 如果你不懂得如何在简历上展示自己,或者觉得怎么改简历都不出彩,那请你一定仔细读完。 互联网运营个人简历范文> 男 22 本科 AI简历…...
Ubuntu22.04安装Anaconda
一、下载安装包 下载地址:https://www.anaconda.com/download#Downloads 参考:Ubuntu下安装Anaconda的步骤(带图) - 知乎 下载Linux 64-Bit (x86) installer 二、安装 在当前路径下,执行命令: bash Ana…...
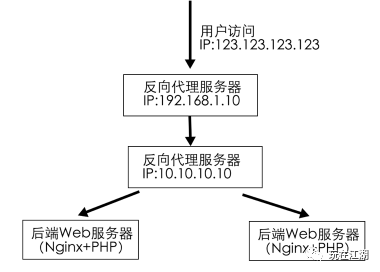
后端nginx使用set_real_ip_from获取用户真实IP
随着nginx的迅速崛起,越来越多公司将apache更换成nginx. 同时也越来越多人使用nginx作为负载均衡, 并且代理前面可能还加上了CDN加速,但是随之也遇到一个问题:nginx如何获取用户的真实IP地址. 前言:Nginx ngx_http_realip_module…...

python使用leveldb
LevelDB 是由 Google 开发的一个快速的键值存储库,提供了一个持久化的有序映射,非常适合用作简单的高性能数据库。 安装 Plyvel 首先,使用 pip3 来安装 plyvel pip3 install plyvel基本用法 接下来,介绍使用 plyvel 来操作 Le…...

hcs部署场景
HCS售前规划: eDesigner? SCT报价器? 将eDesigner项目导出到SCT后,报价器会自动对硬件进行配置及报价。 HCS规划设计工具 - HUAWEI CLOUD Stack Designer 用于支撑HUAWEI CLOUD Stack解决方案项目LLD设计,提升设计效率…...

从零开始学习的ai教程视频,如何入手?
个人认为小白想零基础学习ai应该从理论和实操两个方面入手。理论是支撑实践的前提,只有以一种全局观角度了解ai才能实现从熟练使用ai到有自我意识的用ai创作。 接下来将会简单介绍一些理论免费学习网站和软件(一笔带过,不重点)&a…...

【精选】发布应用到应用商店的基本介绍
摘要 本文旨在介绍如何在各大应用商店发布应用,包括市场选择、准备材料、上架步骤以及常见被拒原因及解决方法。通过详细的步骤和经验分享,帮助开发者顺利将应用推向市场。 引言 随着移动应用市场的不断发展,越来越多的开发者希望将他们的…...

LC 572.另一棵树的子树
572. 另一棵树的子树 给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。 二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tr…...
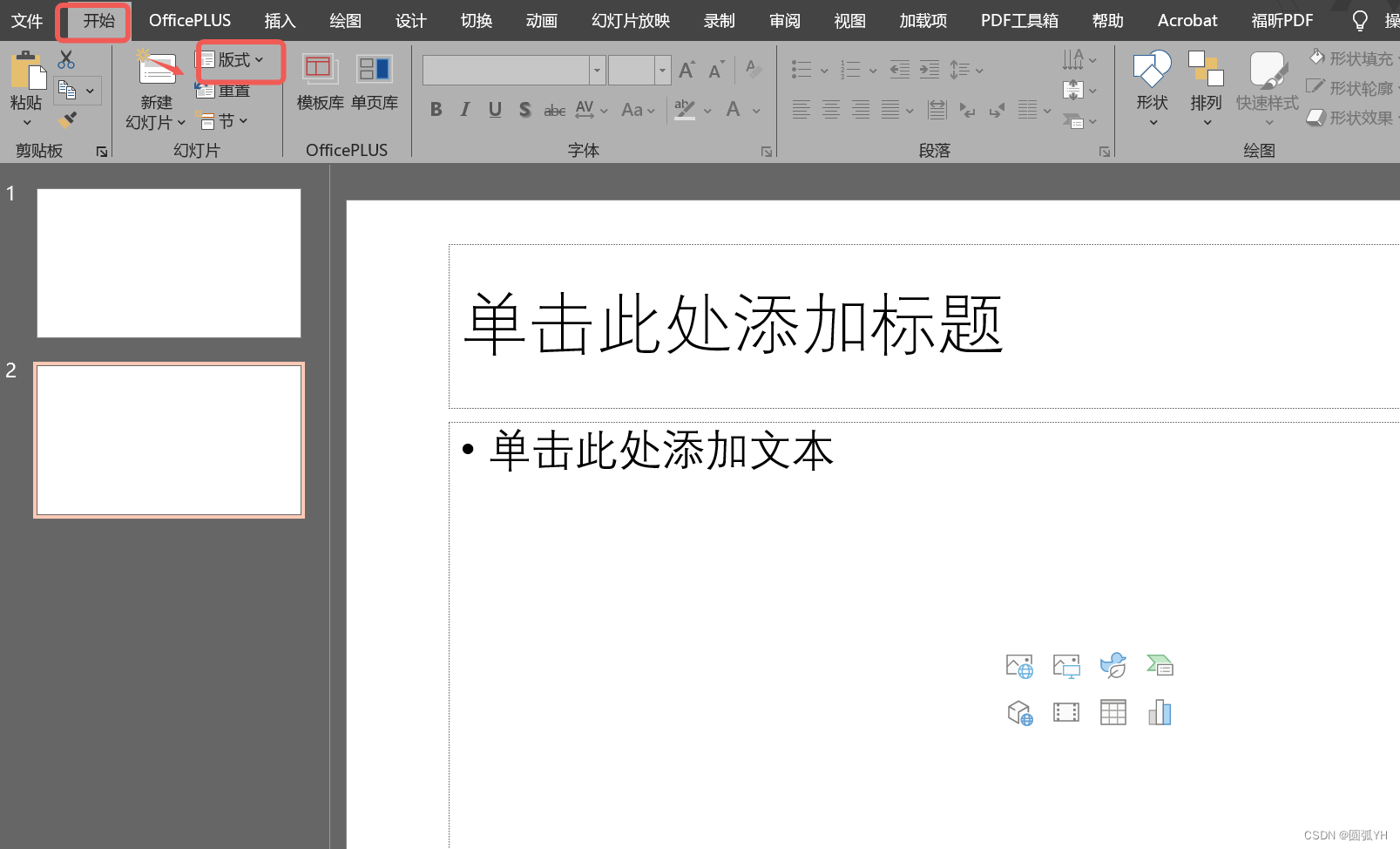
PPT 操作
WPS 版式 PPT中,巧妙使用母版,可以提高效率。 双击母版,选择其中一个版式,插入装饰符号。 然后选择关闭。 这个时候,在该版式下的所有页面,就会出现新加入的符号。不在该版式下的页面,不会出现…...

python项目练习——19、单词计数器
这个项目允许用户输入一段文本,然后统计其中每个单词出现的次数,并按照出现次数从高到低进行排序显示。它涉及到字符串处理、数据结构和用户界面设计等方面的技术。 示例: import tkinter as tk # 导入 Tkinter 库 from collections import Counter # 导入计数器工具类 c…...
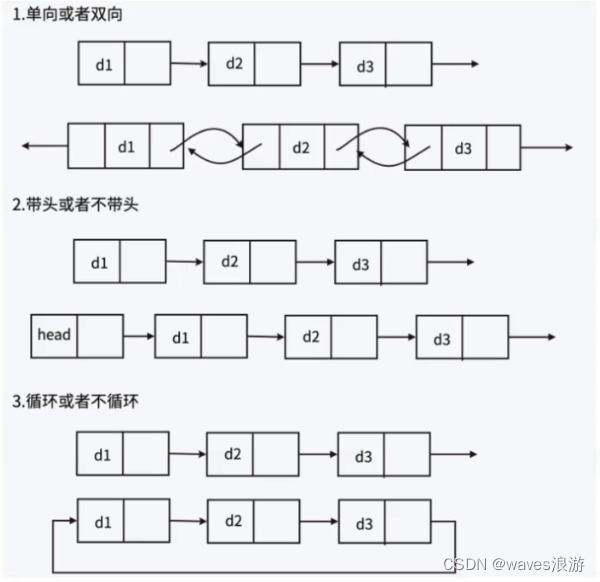
单链表专题
文章目录 目录1. 链表的概念及结构2. 实现单链表2.1 链表的打印2.2 链表的尾插2.3 链表的头插2.4 链表的尾删2.5 链表的头删2.6 查找2.7 在指定位置之前插入数据2.8 在指定位置之后插入数据2.9 删除pos节点2.10 删除pos之后的节点2.11 销毁链表 3. 链表的分类 目录 链表的概念…...

js把数组中的某一项移动到第一位
在JavaScript中,如果你要将数组中的某一项移动到第一位,你可以使用以下几种方法。 假设我们有一个数组arr,并且想要将位于索引index的项移动到数组的第一个位置: let arr [1, 2, 3, 4, 5]; let index 2; // 假设我们想将3&…...

MyBatis如何实现分页
文章目录 MyBatis分页方式对比使用数据库厂商提供的分页查询语句通过自定义 SQL 实现分页逻辑1. 使用 RowBounds 实现分页2. 使用 PageHelper 实现分页 数组分页使用 MyBatis-Plus 进行分页MyBatis物理分页和逻辑分页MyBatis 手写一个 拦截器分页 在 MyBatis 中实现分页通常有两…...

在 Python 编程中,面向对象编程的核心概念包括哪些部分?
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 在 Python 编程中,面向对象编程(Object-Oriented Programming,OOP)的核心概念主要包括类(Class)、对象(Object&#x…...

elementui树形组件自定义高亮颜色
1、需求描述:点击按钮切换树形的章节,同时高亮 2、代码实现 1)style样式添加 <style> .el-tree--highlight-current .el-tree-node.is-current > .el-tree-node__content {background-color: #81d3f8 !important; //高亮颜色colo…...

富格林:技巧抵抗曝光虚假套路
富格林悉知,黄金具备独特的优势吸引着众多投资者的目光,在现货黄金市场也被认为是一条潜力无限的盈利之道。但我们要明白风险与盈利是相辅相成的,因此在这复杂的市场中我们必须利用技巧来抵抗曝光的虚假套路。下面富格林将给大家分享一些正确…...
24年权威数学建模报名通知汇总(含妈妈杯、国赛、美赛、电工杯、数维杯、五一数模、深圳杯......)
1、MathorCup比赛 报名时间:2024年4月11日中午12点(周四) 比赛开始时间:2024年4月12日上午8时(周五) 比赛结束时间:2024年4月16日上午9时(周二) 报名费用:…...

Divinity Mod Manager:如何用技术架构解决《神界:原罪2》模组管理的复杂性?
Divinity Mod Manager:如何用技术架构解决《神界:原罪2》模组管理的复杂性? 【免费下载链接】DivinityModManager A mod manager for Divinity: Original Sin - Definitive Edition. 项目地址: https://gitcode.com/gh_mirrors/di/Divinity…...

开源破产法知识库:从实务场景到技术架构的深度解析与应用指南
1. 项目概述:一个律师的破产法知识库最近在GitHub上看到一个挺有意思的项目,叫zhang-lawyer-org/zhang-bankruptcy。光看这个名字,你大概能猜到,这是一个跟破产法相关的知识库,而且很可能是一位张律师(或张…...

如何为 Claude Code 配置 Taotoken 的稳定 API 连接
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为 Claude Code 配置 Taotoken 的稳定 API 连接 Claude Code 作为一款强大的 AI 编程助手,其原生服务在某些地区可…...
)
UWB定位标签天线怎么选?PATCH、PIFA、DIPOLE三种方案全对比(含NXP/Qorvo模组适配建议)
UWB定位标签天线选型指南:PATCH、PIFA、DIPOLE三大方案深度解析与工程决策 在物联网定位技术领域,超宽带(UWB)凭借其厘米级精度和强抗干扰能力,已成为工业定位、智能仓储和医疗设备追踪的核心解决方案。而天线作为UWB系统的"感官器官&qu…...

告别‘鬼影’与模糊:深入解读RangeNet++如何用高效kNN后处理搞定LiDAR语义分割的边界难题
RangeNet:用GPU加速的kNN后处理破解LiDAR语义分割的边界模糊难题 当自动驾驶车辆以每小时60公里的速度行驶时,每100毫秒的决策延迟意味着1.67米的盲区——这恰好是许多交通事故发生的临界距离。在LiDAR语义分割领域,传统方法在点云投影与反投…...

Promises/A+性能优化指南:让你的异步代码运行得更快
Promises/A性能优化指南:让你的异步代码运行得更快 【免费下载链接】promises-spec An open standard for sound, interoperable JavaScript promises—by implementers, for implementers. 项目地址: https://gitcode.com/gh_mirrors/pr/promises-spec 在Ja…...

低空经济项目|Java无人机接单派单平台系统源码开发实战
随着低空经济产业的规范化发展,无人机应用已渗透到航拍、测绘、电力巡检、农业植保、应急救援等多个细分场景,市场对专业飞手的需求持续增长,但供需对接效率低下的痛点日益突出:需求方难以快速匹配具备合法资质的飞手,…...

利用 STM32F407 BKPSRAM 实现运行时变量监控 —— 从方案到 Keil 调试实战
利用 STM32F407 BKPSRAM 实现运行时变量监控 —— 从方案到 Keil 调试实战 一、什么是 BKPSRAM 1.1 先看一张图 STM32F407 的存储系统里有一个很特别的区域叫备份域(Backup Domain)。备份域里住着几个东西: ┌───────────────…...

硬件预取技术:Alecto框架优化与性能提升
1. 硬件预取技术基础与挑战在现代处理器架构中,内存墙(Memory Wall)问题一直是制约性能提升的关键瓶颈。随着CPU与DRAM之间的速度差距不断拉大,硬件预取技术已成为缓解这一问题的核心手段。传统预取器通过分析程序的内存访问模式&…...

使用HIP编写GPU 算子向量加法
HIP (Heterogeneous-compute Interface for Portability) 来编写一个 GPU 算子(operator)。HIP 是 AMD 推出的 GPU 编程接口,类似 CUDA,但可在 AMD 和 NVIDIA GPU 上运行。下面我给你一个完整示例,演示如何写一个简单算…...