【RAG实践】Rerank,让大模型 RAG 更近一步
RAG+Rerank原理
上一篇【RAG实践】基于LlamaIndex和Qwen1.5搭建基于本地知识库的问答机器人
我们介绍了什么是RAG,以及如何基于LLaMaIndex和Qwen1.5搭建基于本地知识库的问答机器人,原理图和步骤如下:

这里面主要包括包括三个基本步骤:
1. 索引 — 将文档库分割成较短的 Chunk,并通过编码器构建向量索引。
2. 检索 — 根据问题和 chunks 的相似度检索相关文档片段。
3. 生成 — 以检索到的上下文为条件,生成问题的回答。
更加完善的RAG技术还包含了很多点,如下是RAG技术的大图,魔搭社区也将逐步分析,希望提供更多更好更详细的RAG技术分享。

本文主要关注在Rerank,本文中,Rerank可以在不牺牲准确性的情况下加速LLM的查询(实际上可能提高准确率),Rerank通过从上下文中删除不相关的节点,重新排序相关节点来实现这一点。
本文Rerank+RAG原理图:

技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
- 重磅消息!《大模型面试宝典》(2024版) 正式发布!
- 重磅消息!《大模型实战宝典》(2024版) 正式发布!
Rerank模型:bge-reranker-v2-m3
与embedding模型不同,Reranker使用问题和文档作为输入,直接输出相似度而不是embedding。本文通过向Reranker输入查询和段落来获得相关性分数。Reranker是基于交叉熵损失进行优化的,因此相关性得分不受特定范围的限制。bge-reranker-v2-m3适用于中英文双语Rerank场景。
LLM模型:通义千问1.5
Qwen1.5版本年前开源了包括0.5B、1.8B、4B、7B、14B、32B、72B和A2.7B-MoE在内的8种大小的基础和聊天模型,同时,也开源了量化模型。不仅提供了Int4和Int8的GPTQ模型,还有AWQ模型,以及GGUF量化模型。为了提升开发者体验,Qwen1.5的代码合并到Hugging Face Transformers中,开发者现在可以直接使用transformers>=4.37.0而无需trust_remote_code。
RAG框架:LLaMaIndex
LlamaIndex 是一个基于 LLM 的应用程序的数据框架,受益于上下文增强。 这种LLM系统被称为RAG系统,代表“检索增强生成”。LlamaIndex 提供了必要的抽象,可以更轻松地摄取、构建和访问私有或特定领域的数据,以便将这些数据安全可靠地注入 LLM 中,以实现更准确的文本生成。

Embedding模型:GTE文本向量
文本表示是自然语言处理(NLP)领域的核心问题, 其在很多NLP、信息检索的下游任务中发挥着非常重要的作用。近几年, 随着深度学习的发展,尤其是预训练语言模型的出现极大的推动了文本表示技术的效果, 基于预训练语言模型的文本表示模型在学术研究数据、工业实际应用中都明显优于传统的基于统计模型或者浅层神经网络的文本表示模型。GTE主要关注基于预训练语言模型的文本表示。

GTE-zh模型使用retromae初始化训练模型,之后利用两阶段训练方法训练模型:第一阶段利用大规模弱弱监督文本对数据训练模型,第二阶段利用高质量精标文本对数据以及挖掘的难负样本数据训练模型。
环境配置与安装
-
python 3.10及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上
安装依赖库
!pip install transformers -U
!pip install llama-index llama-index-llms-huggingface ipywidgets
!pip install sentence-transformers
import logging
import sys
from abc import ABC
from typing import Any, Listimport pandas as pd
import torch
from IPython.display import display, HTML
from llama_index.core import QueryBundle
from llama_index.core import (SimpleDirectoryReader,VectorStoreIndex,Settings,ServiceContext,set_global_service_context,
)
from llama_index.core.base.embeddings.base import BaseEmbedding, Embedding
from llama_index.core.postprocessor import SentenceTransformerRerank
from llama_index.core.prompts import PromptTemplate
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.llms.huggingface import HuggingFaceLLM
from modelscope import snapshot_download
from transformers import AutoModelForSequenceClassification, AutoTokenizerlogging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
加载大语言模型
因为Qwen本次支持了Transformers,使用HuggingFaceLLM加载模型,模型为(Qwen1.5-4B-Chat)
# Model names
qwen2_4B_CHAT = "qwen/Qwen1.5-4B-Chat"selected_model = snapshot_download(qwen2_4B_CHAT)SYSTEM_PROMPT = """You are a helpful AI assistant.
"""query_wrapper_prompt = PromptTemplate("[INST]<<SYS>>\n" + SYSTEM_PROMPT + "<</SYS>>\n\n{query_str}[/INST] "
)llm = HuggingFaceLLM(context_window=4096,max_new_tokens=2048,generate_kwargs={"temperature": 0.0, "do_sample": False},query_wrapper_prompt=query_wrapper_prompt,tokenizer_name=selected_model,model_name=selected_model,device_map="auto",# change these settings below depending on your GPUmodel_kwargs={"torch_dtype": torch.float16},
)
下载数据并加载文档:
!wget https://modelscope.oss-cn-beijing.aliyuncs.com/resource/rag/xianjiaoda.md
!mkdir -p /mnt/workspace/custom_data
!mv /mnt/workspace/xianjiaoda.md /mnt/workspace/custom_data
documents = SimpleDirectoryReader("/mnt/workspace/data/xianjiaoda/").load_data()
documents
构建embedding类:
加载GTE模型,使用GTE模型构造Embedding类
embedding_model = "iic/nlp_gte_sentence-embedding_chinese-base"
class ModelScopeEmbeddings4LlamaIndex(BaseEmbedding, ABC):embed: Any = Nonemodel_id: str = "iic/nlp_gte_sentence-embedding_chinese-base"def __init__(self,model_id: str,**kwargs: Any,) -> None:super().__init__(**kwargs)try:from modelscope.models import Modelfrom modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasks# 使用modelscope的embedding模型(包含下载)self.embed = pipeline(Tasks.sentence_embedding, model=self.model_id)except ImportError as e:raise ValueError("Could not import some python packages." "Please install it with `pip install modelscope`.") from edef _get_query_embedding(self, query: str) -> List[float]:text = query.replace("\n", " ")inputs = {"source_sentence": [text]}return self.embed(input=inputs)['text_embedding'][0].tolist()def _get_text_embedding(self, text: str) -> List[float]:text = text.replace("\n", " ")inputs = {"source_sentence": [text]}return self.embed(input=inputs)['text_embedding'][0].tolist()def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:texts = list(map(lambda x: x.replace("\n", " "), texts))inputs = {"source_sentence": texts}return self.embed(input=inputs)['text_embedding'].tolist()async def _aget_query_embedding(self, query: str) -> List[float]:return self._get_query_embedding(query)
建设索引:
加载数据后,基于文档对象列表(或节点列表),建设他们的index,就可以方便的检索他们。
embeddings = ModelScopeEmbeddings4LlamaIndex(model_id=embedding_model)
service_context = ServiceContext.from_defaults(embed_model=embeddings, llm=llm)
set_global_service_context(service_context)index = VectorStoreIndex.from_documents(documents)
加载Rerank模型:
rerank_llm_name = "AI-ModelScope/bge-reranker-v2-m3"
downloaded_rerank_model = snapshot_download(rerank_llm_name)
rerank_llm = SentenceTransformerRerank(model=downloaded_rerank_model, top_n=3)
首先,我们尝试使用Rerank,同时对查询+问答进行计时,检索召回top_k=10,Rerank重排top_n=3看看处理检索到的上下文的输出需要多长时间。
from time import timequery_engine = index.as_query_engine(similarity_top_k=10, node_postprocessors=[rerank_llm])now = time()
response = query_engine.query("西安交大由哪几个学校合并的")
print(response)
print(f"Elapsed: {round(time() - now, 2)}s")
输出和计时:

打印上下文context:

然后,我们尝试不加Rerank的情况下,查询和问答并计时:
from time import timequery_engine = index.as_query_engine(similarity_top_k=10)now = time()
response = query_engine.query("西安交大由哪几个学校合并的")
print(response)
print(f"Elapsed: {round(time() - now, 2)}s")
输出和计时:

打印上下文context:

正如我们所看到的,具有Rerank功能的retrieval引擎在更短的时间(本文速度提升了约2倍)内生成了准确的输出。虽然两种响应本质上都是正确的,但未经rerank的retrieval引擎包含了大量不相关的信息,从而影响了查询和推理的速度 - 我们可以将这种现象归因于“上下文窗口无效数据的污染”。
通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
相关文章:
【RAG实践】Rerank,让大模型 RAG 更近一步
RAGRerank原理 上一篇【RAG实践】基于LlamaIndex和Qwen1.5搭建基于本地知识库的问答机器人 我们介绍了什么是RAG,以及如何基于LLaMaIndex和Qwen1.5搭建基于本地知识库的问答机器人,原理图和步骤如下: 这里面主要包括包括三个基本步骤&#…...

私有化客服系统:在线客服搭建与部署的创新之路
随着互联网技术的飞速发展,企业与客户之间的沟通方式也在不断地演变。在这个信息爆炸的时代,一个高效、便捷、智能的在线客服系统成为了企业提升服务质量、增强客户满意度的重要工具。本文将详细介绍在线客服系统的构建、部署以及私有化客服的优势&#…...
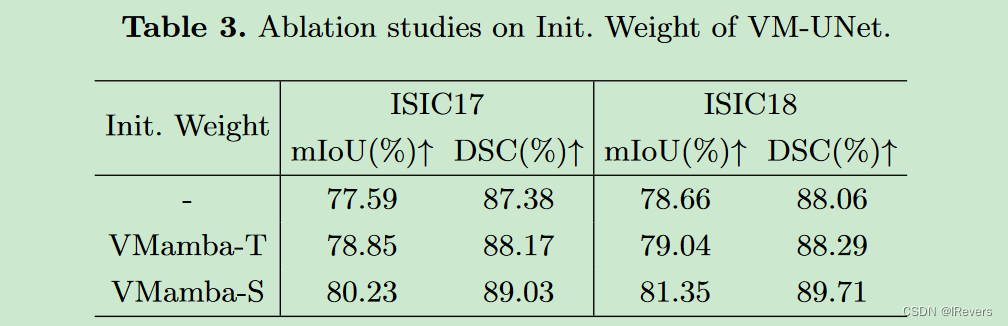
VM-UNet: Vision Mamba UNet for Medical Image Segmentation
VM-UNet: Vision Mamba UNet for Medical Image Segmentation VM-UNet:基于视觉Mamba UNet架构的医学图像分割 论文链接:http://arxiv.org/abs/2402.02491 代码链接:https://github.com/JCruan519/VM-UNet 1、摘要 文中利用状态空间模型SS…...

面向对象编程:在Python中的面向对象编程奥秘
面向对象编程在Python中的奥秘 在编程的世界里,面向对象编程(Object-Oriented Programming,简称OOP)是一种非常重要的编程范式。它改变了我们思考问题和设计代码的方式。Python作为一种支持面向对象的语言,为我们提供…...

考研数学|零基础100分保底复习方案+资料分享
目标100分其实很好实现,只要你有决心,不需要去看任何人的学习技巧 其实基础差,你只要专攻基础就好了,现在的很多考研课程和资料真的很不照顾基础不好的同学,好像就默认你什么都会一样,但是还是有对于基础差…...
【MATLAB源码-第29期】基于matlab的MIMO,MISO,SIMO,SISO瑞利rayleigh信道容量对比。
操作环境: MATLAB 2022a 1、算法描述 1. SISO(单输入单输出): - SISO 是指在通信系统中,只有一个天线用于传输信号,也只有一个天线用于接收信号的情况。这是最简单的通信方式。 2. SIMO(单…...
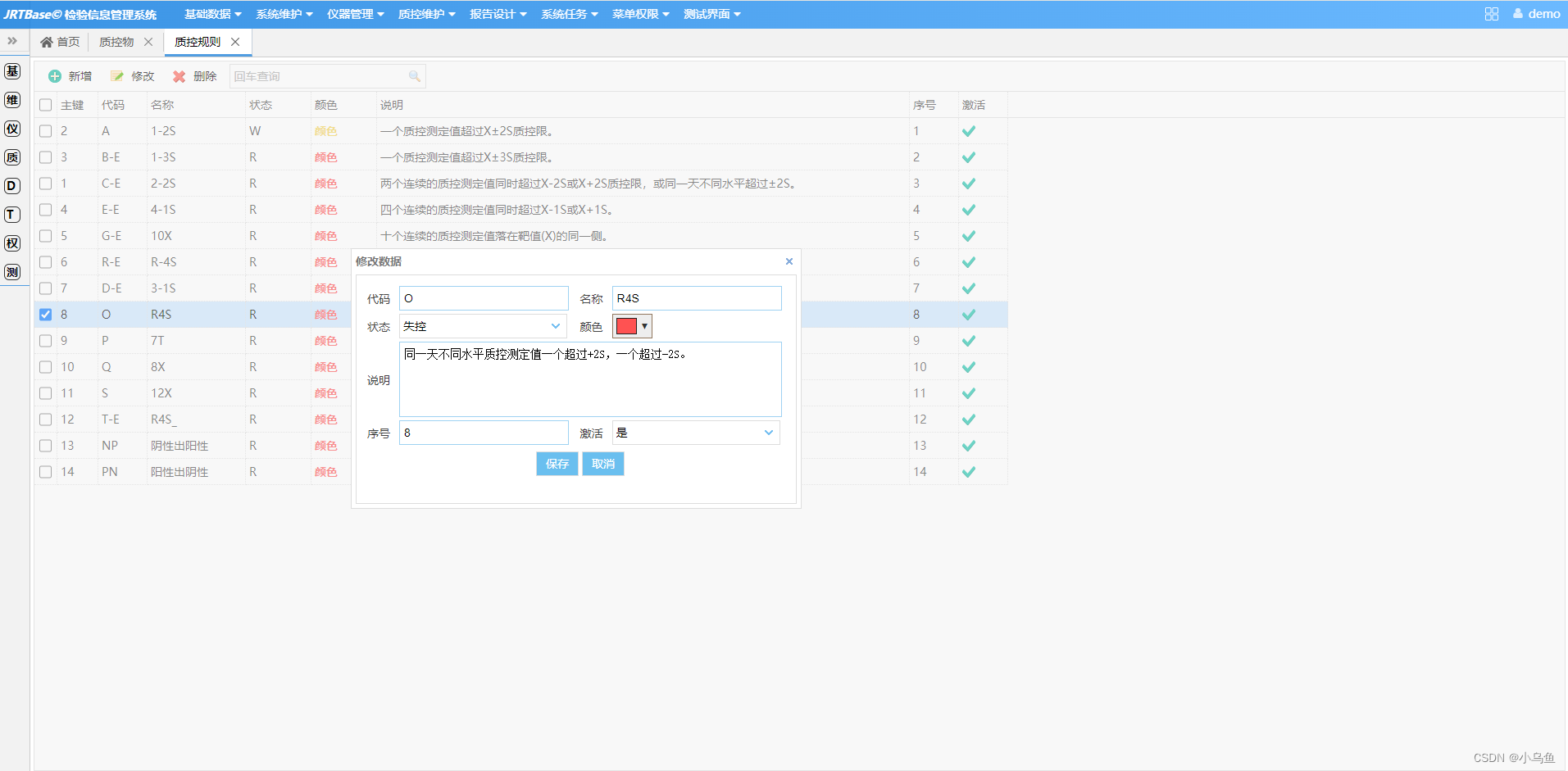
JRT高效率开发
得益于前期的基础投入,借助代码生成的加持,本来计划用一周实现质控物维护界面,实际用来四小时左右完成质控物维护主体,效率大大超过预期。 JRT从设计之初就是为了证明Spring打包模式不适合软件服务模式,觉得Spring打包…...

Spring Boot 切面的一种的测试方法,java中级开发面试
void afterReturnName() { Assertions.assertEquals(studentController.getNameById(123L).getName(), "测试姓名Yz");} } 但往往切面中的逻辑并非这么简单,在实际的测试中其实我们也完成没有必要关心在切面中到底发生了什么(发生了什么应该在…...
)
嵌入式自学路线-高薪路线(持续更新,欢迎关注)
1 入门:51STM32 主要学习内容中断、定时器、串口、NAND FLASH、网络控制器、LCD屏、触摸屏等的工作原理。学习资源推荐视频:野火,正点原子书籍:野火,正点原子学习建议如果你以后的方向是驱动开发,这部分学…...

SpringMVC的运行流程
SpringMVC的运行流程可以概括为以下几个主要步骤: 用户发送请求: 用户通过浏览器或其他客户端发送HTTP请求到服务器。 前端控制器(DispatcherServlet)接收请求: SpringMVC的前端控制器(通常是DispatcherSe…...

成绩分析 蓝桥杯 java
成绩分析 小蓝给学生们组织了一场考试,卷面总分为 100 分,每个学生的得分都是一个 0 到 100 的整数。 请计算这次考试的最高分、最低分和平均分。 输入格式 输入的第一行包含一个整数 n,表示考试人数。 接下来 n 行,每行包含一…...

计算psnr ssim niqe fid mae lpips等指标的代码
以下代码仅供参考,路径处理最好自己改一下 # Author: Wu # Created: 2023/8/15 # module containing metrics functions # using package in https://github.com/chaofengc/IQA-PyTorch import torch from PIL import Image import numpy as np from piqa import P…...

OpenHarmony开发技术:【国际化】实例
国际化 如今越来的越多的应用都走向了海外,应用走向海外需要支持不同国家的语言,这就意味着应用资源文件需要支持不同语言环境下的显示。本节就介绍一下设备语言环境变更后,如何让应用支持多语言。 应用支持多语言 ArkUI开发框架对多语言的…...

c++子类和父类成员函数重名
子类和父类返回值参数相同,函数名相同,有virtual关键字,则由对象的类型决定调用哪个函数。子类和父类只要函数名相同,没有virtual关键字,则子类的对象没有办法调用到父类的同名函数,父类的同名函数被隐藏了,…...

《C++程序设计》阅读笔记【7-堆和拷贝构造函数】
🌈个人主页:godspeed_lucip 🔥 系列专栏:《C程序设计》阅读笔记 本文对应的PDF源文件请关注微信公众号程序员刘同学,回复C程序设计获取下载链接。 1 堆与拷贝构造函数1.1 概述1.2 分配堆对象1.3 拷贝构造函数1.3.1 默…...

洛谷 P1048 [NOIP2005 普及组] 采药
辰辰是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师。为此,他想拜附近最有威望的医师为师。医师为了判断他的资质,给他出了一个难题。医师把他带到一个到处都是草药的山洞里对他说:“孩子,这个山洞里有一些不同…...
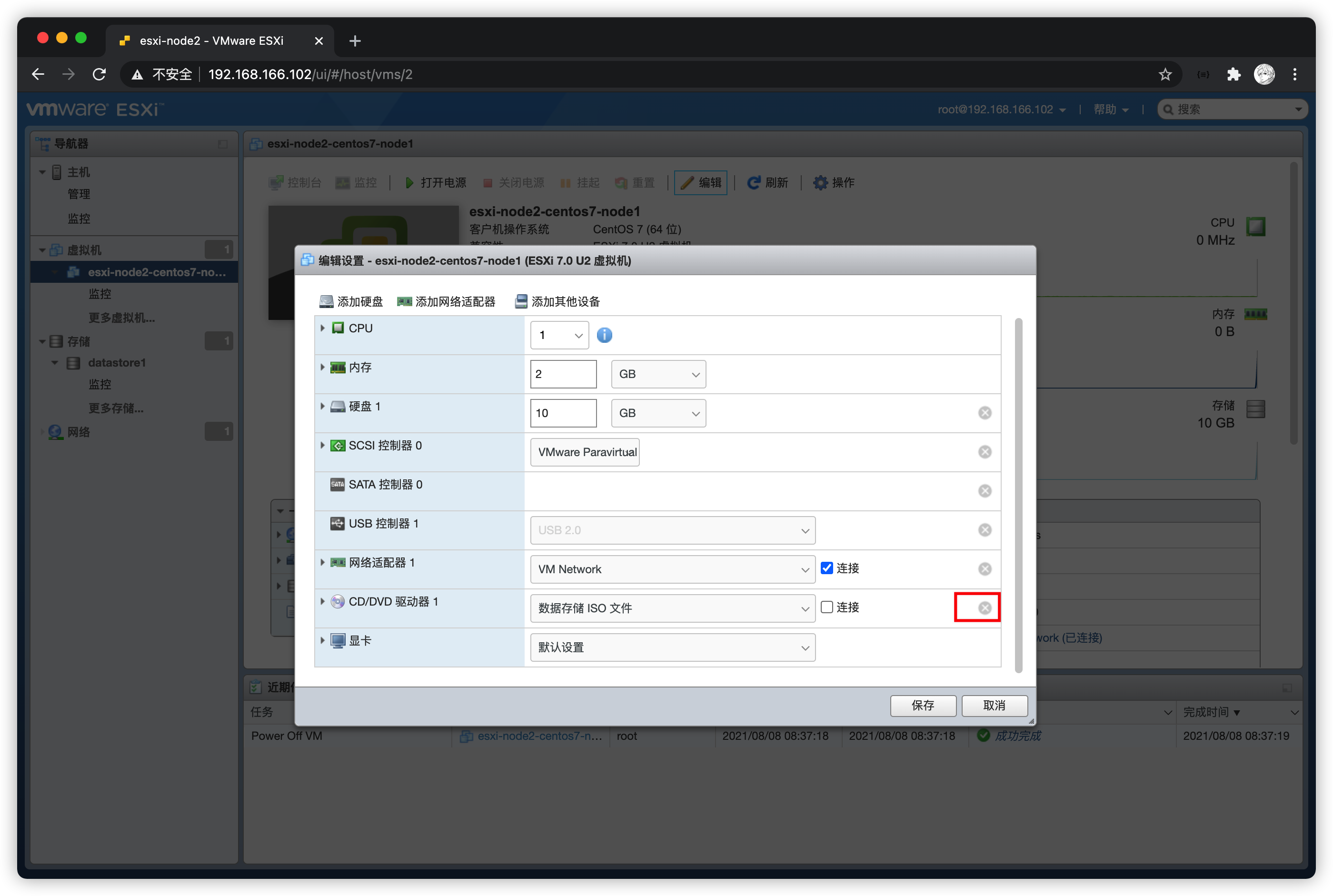
VMware vSphere虚拟化基础管理平台
VMware简介 VMware介绍 官网:https://www.vmware.com/cn.html VMware公司成立于1998年,2003年存储厂商EMC以6.35亿美元收购了VMware;2015年10月,戴尔宣布以670亿美元收购EMC。VMware公司在2018年全年收入79.2亿美元。 VMware主…...
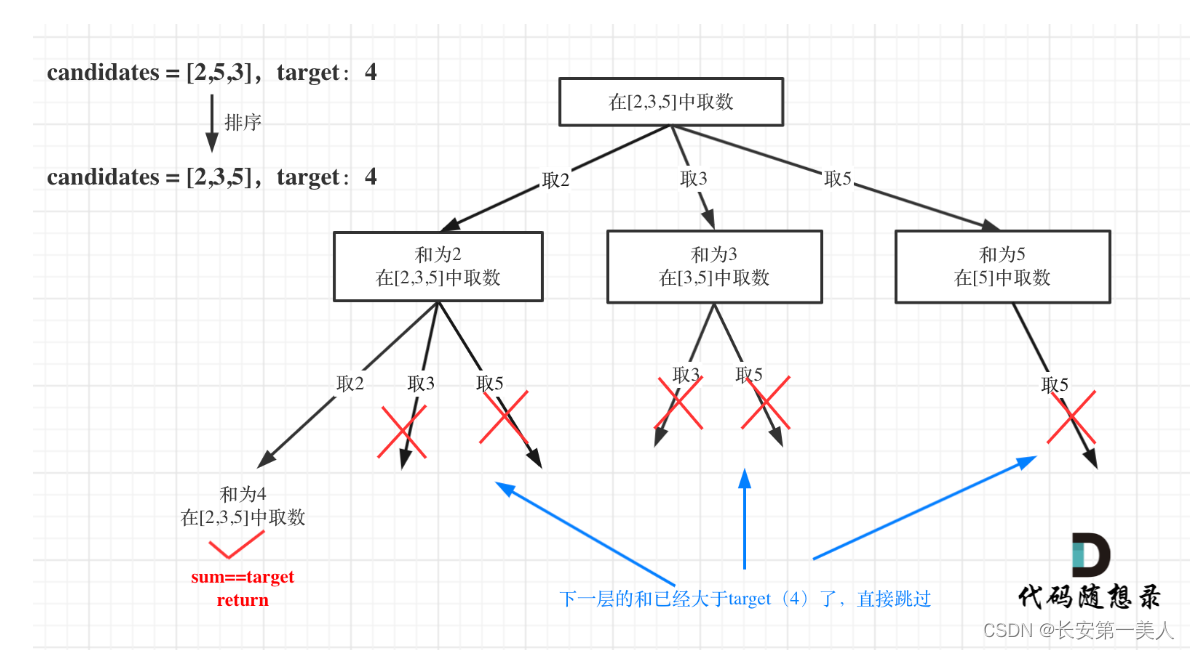
leetcode刷题-代码训练营-第7章-回溯算法1
回溯法模板 void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果} }理解 从…...

三种常见webshell工具的流量特征分析
又来跟师傅们分享小技巧了,这次简单介绍一下三种常见的webshell流量分析,希望能对参加HW蓝队的师傅们有所帮助。 什么是webshell webshell就是以asp、php、jsp或者cgi等网页文件形式存在的一种代码执行环境,主要用于网站管理、服务器管理、…...

pkg打包nodejs程序用动态require路由出现问题
动态路由问题 pkg打包的时候会自动生成一个虚拟路径/snapshot/…会导致你的路径出现一些问题 而项目中依据route文件夹下的文件动态use相应的router,这就需要动态require,但是这个require的路径会被虚拟路径代替导致取不到,所以可以使用写死…...

如何高效使用m4s-converter:专业开发者的B站缓存视频转换终极指南
如何高效使用m4s-converter:专业开发者的B站缓存视频转换终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter m4s-converter是一…...

基于RT-Thread与PSoC 6的智能环境监测系统设计与实现
1. 项目概述:当嵌入式RTOS遇上混合信号MCU最近在捣鼓一个智能环境监测的小玩意儿,核心需求很简单:实时采集环境的温湿度数据,一旦超过预设的阈值,就通过声光或者网络的方式发出警报。听起来像是毕业设计的经典题目&…...

物联网平台资本逻辑与开发实战:从涂鸦融资看行业价值回归
1. 从资本视角看物联网平台:一场关于“入口”与“生态”的持久战最近和几个做硬件的朋友聊天,大家不约而同地提到了一个词:“上云”。这个“云”,指的就是物联网开发平台。从智能家居的插座、灯泡,到工业产线上的传感器…...
)
485温湿度传感器Modbus通信避坑指南:从波特率匹配到报文解析(以4800波特率为例)
485温湿度传感器Modbus通信实战:从硬件对接到数据解析全流程 工业现场的数据采集往往从一串看似简单的十六进制代码开始。当您第一次将485温湿度传感器接入系统时,可能会遇到这样的场景:硬件连接无误,指示灯正常闪烁,但…...
基于RP2040与NeoPixel的交互式LED气泡桌:硬件选型、电路设计与动画编程全解析
1. 项目概述:打造一个会呼吸的光影气泡桌 几年前,我在一个艺术展上看到一个用灯光和烟雾营造氛围的装置,当时就被那种动态光影与物理形态结合的美感深深吸引。作为一个喜欢动手的嵌入式开发者,我一直在想,能不能做一个…...

AD中域用户密码策略不生效的解决方案
每到一个月,AD就会提示修改密码,改就改吧,但是还提示一些乱七八糟的规则。 我把这些规则都禁用或是设为没有定义了,但还是报“不能和之前的0个密码相同”, 最后, 解决方案: 在域控制器服务器中&…...

从零到一:构建与解析XTS测试环境的实战指南
1. 环境准备:搭建XTS测试环境的基础条件 第一次接触XTS测试环境搭建时,我完全被各种术语搞晕了。后来才发现,只要把基础环境准备好,后面的工作就会顺利很多。就像盖房子要先打地基一样,搭建XTS测试环境也需要先准备好几…...

基于规则引擎的自动化文件管理工具smartcat实战指南
1. 项目概述:一个智能化的文件分类与归档工具最近在整理个人电脑和服务器上的文件时,我又一次陷入了混乱。下载文件夹里塞满了各种格式的文档、图片、压缩包,项目目录下混杂着不同版本的代码、设计稿和会议记录。手动分类不仅耗时,…...

大模型私有化部署实战:LLAMATOR-Core核心引擎配置与性能调优指南
1. 项目概述:从“大模型”到“小核心”的工程化实践最近在折腾大模型应用落地的朋友,可能都绕不开一个核心痛点:如何把一个动辄几十GB、几百亿参数的“庞然大物”,真正塞进自己的业务系统里,让它稳定、高效、可控地跑起…...

基于计算机视觉的屏幕内容智能识别与自动化实践
1. 项目概述:当屏幕成为你的“眼睛”最近在折腾一个挺有意思的项目,我把它叫做“Screen Vision”,直译过来就是“屏幕视觉”。这名字听起来有点玄乎,但核心想法其实很直接:让计算机程序能像人一样,“看懂”…...