Hive概述与基本操作
一、Hive基本概念
1.什么是hive?
(1)hive是数据仓库建模的工具之一
(2)可以向hive传入一条交互式的sql,在海量数据中查询分析得到结果的平台
2.Hive简介
Hive本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更近一步说hive就是一个MapReduce客户端
3.Hive的优缺点:
优点:
1、操作接口采用类sql语法,提供快速开发的能力(简单、容易上手)
2、避免了去写MapReduce,减少开发人员的学习成本
3、Hive的延迟性比较高,因此Hive常用于数据分析,适用于对实时性要求不高的场合
4、Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。(不断地开关JVM虚拟机)
5、Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
6、集群可自由扩展并且具有良好的容错性,节点出现问题SQL仍可以完成执行
缺点:
1、Hive的HQL表达能力有限
(1)迭代式算法无法表达 (反复调用,mr之间独立,只有一个map一个reduce,反复开关)
(2)数据挖掘方面不擅长
2、Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗 (hql根据模板转成mapreduce,不能像自己编写mapreduce一样精细,无法控制在map处理数据还是在reduce处理数据)
4.Hive和传统数据库对比

hive和mysql什么区别?
首先,hive不是数据库,它只是一个数据仓库建模的工具,是可以在海量数据中查询分析得到结果的平台,数据存储位置在HDFS上。
mysql是数据库,数据存储位置在本地磁盘上
5.Hive应用场景
(1)日志分析:大部分互联网公司使用hive进行日志分析,如百度、淘宝等。
(2)统计一个网站一个时间段内的pv,uv,SKU,SPU,SKC
(3)多维度数据分析(数据仓库)
(4)海量结构化数据离线分析
(5)构建数据仓库
二、Hive架构
1.图解:

元数据Metastore
元数据包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是 外部表)、表的数据所在目录等。
一般需要借助于其他的数据载体(数据库)
主要用于存放数据库的建表语句等信息
推荐使用Mysql数据库存放数据
Driver(sql语句是如何转化成MR任务的?)
元数据存储在数据库中,默认存在自带的derby数据库(单用户局限性)中,推荐使用Mysql进行存储。
1) 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST(从3.x版本之后,转换成一些的stage),这一步一般都用第三方工具库完 成,比如ANTLR;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
2) 编译器(Physical Plan):将AST编译(从3.x版本之后,转换成一些的stage)生成逻辑执行计划。
3) 优化器(Query Optimizer):对逻辑执行计划进行优化。
4) 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark/flink。
数据处理
Hive的数据存储在HDFS中,计算由MapReduce完成。HDFS和MapReduce是源码级别上的整合,两者结合最佳。解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。
hive cli和beeline cli的区别
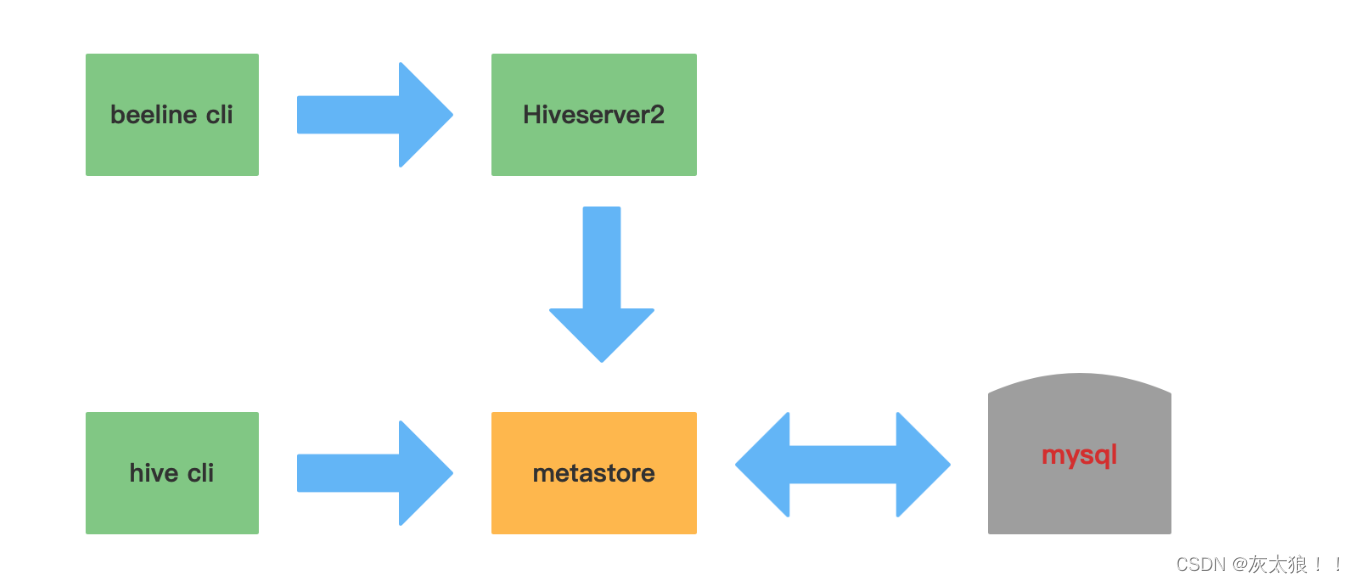
在客户端启动(beeline cli)的hiveserver2服务会将任务传给服务端,服务端通过元数据映射HDFS中的数据,进行处理
数据库中Hive元数据表
1、存储Hive版本的元数据表(VERSION),该表比较简单,但很重要,如果这个表出现问题,根本进不来Hive-Cli。比如该表不存在,当启动Hive-Cli的时候,就会报错“Table 'hive.version' doesn't exist”
2、Hive数据库相关的元数据表(DBS、DATABASE_PARAMS)
DBS:该表存储Hive中所有数据库的基本信息。
DATABASE_PARAMS:该表存储数据库的相关参数。
3、Hive表和视图相关的元数据表
主要有TBLS、TABLE_PARAMS、TBL_PRIVS,这三张表通过TBL_ID关联。
TBLS:该表中存储Hive表,视图,索引表的基本信息。
TABLE_PARAMS:该表存储表/视图的属性信息。
TBL_PRIVS:该表存储表/视图的授权信息。
4、Hive文件存储信息相关的元数据表
主要涉及SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。
SDS:该表保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。
TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息。
SD_PARAMS: 该表存储Hive存储的属性信息。 SERDES:该表存储序列化使用的类信息。
SERDE_PARAMS:该表存储序列化的一些属性、格式信息,比如:行、列分隔符。
5、Hive表字段相关的元数据表
主要涉及COLUMNS_V2:该表存储表对应的字段信息。
(加粗的部分的表比较重要)
三、Hive的基本操作
hive中的数据来源是HDFS,hive中的数据库,数据表对应HDFS上的文件夹,数据表中的数据对应HDFS上的文件,通常数据库会默认创建在HDFS中的/user/hive/warehouse目录下


3.1 Hive库操作
3.1.1 创建数据库
1)创建一个数据库,数据库在HDFS上的默认存储路径是/hive/warehouse/*.db。
create database testdb;
2)避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
create database if not exists testdb;
3)创建数据库并指定位置
create database if not exist 数据库名 location 指定路径;
3.1.2 修改数据库
alter database dept set dbproperties('createtime'='20220531');
数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
3.1.3数据库详细信息
1)显示数据库(show)
show databases;
2)可以通过like进行过滤
show databases like 't*';
3)查看详情(desc)
desc database testdb;
4)切换数据库(use)
use testdb;
3.1.4删除数据库(将删除的目录移动到回收站中)
1)最简写法
drop database testdb;
2)如果删除的数据库不存在,最好使用if exists判断数据库是否存在。否则会报错:FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
drop database if exists testdb;
3)如果数据库不为空,使用cascade命令进行强制删除。报错信息如下FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
drop database if exists testdb cascade;
3.2 Hive数据类型
3.2.1 基础数据类型:

3.2.2复杂的数据类型

3.3 Hive表操作
Hive没有专门的数据文件格式,常见的有以下几种:
TEXTFILE SEQUENCEFILE AVRO RCFILE ORCFILE PARQUET
TextFile:
TEXTFILE 即正常的文本格式,是Hive默认文件存储格式,此种格式的表文件在HDFS上是明文,可用hadoop fs -cat命令查看,从HDFS上get下来后也可以直接读取。
RCFile:
是Hadoop中第一个列文件格式。能够很好的压缩和快速的查询性能。通常写操作比较慢,比非列形式的文件格式需要更多的内存空间和计算量。ORCFile:
Hive从0.11版本开始提供了ORC的文件格式,ORC文件不仅仅是一种列式文件存储格式,最重要的是有着很高的压缩比,并且对于MapReduce来说是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅可以很大程度的节省HDFS存储资源,而且对数据的查询和处理性能有着非常大的提升。Parquet:
Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定。这也是parquet相较于orc的仅有优势:支持嵌套结构。SEQUENCEFILE:
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。AVRO:
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。Avro提供的机制使动态语言可以方便地处理Avro数据。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。


3.3.1 创建表
[ ]内的内容属于可选内容
建表1:全部使用默认建表方式
create table IF NOT EXISTS students
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; // 必选,指定列分隔符建表2:指定location(这种方式比较常用)
create table IF NOT EXISTS students2
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/bigdata27/input1';// 指定Hive表的数据的存储位置,一般在数据已经上传到HDFS,想要直接使用,会指定Location,通常Locaion会跟外部表一起使用,内部表一般使用默认的location
建表3:指定存储格式
create table IF NOT EXISTS test_orc_tb
(
id bigint,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC
LOCATION '/bigdata29/out6';// 指定储存格式为orcfile,如果不指定,默认为textfile,注意:除textfile以外,其他的存储格式的数据都不能直接加载,需要使用从表加载的方式。
建表4:将查询的结果作为表数据
create table xxxx as select ... from ... (表不存在,会新建一个表)
insert into table 表名 select ... from ... (表以存在,将查询的数据插入表中)
//覆盖插入 把into 换成 overwrite
建表5:建的表与另一张表结构相同
create table 新建表 like 结构相同表
举例:
简单用户信息表创建:
create table t_user(
id int,
uname string,
pwd string,
gender string,
age int
)
row format delimited fields terminated by ','
lines terminated by '\n';
表数据:
1,admin,123456,男,18
2,zhangsan,abc123,男,23
3,lisi,654321,女,16
复杂人员信息表创建:
create table IF NOT EXISTS t_person(
name string,
friends array<string>,
children map<string,int>,
address struct<street:string ,city:string>
)
row format delimited fields terminated by ',' -- 列与列之间的分隔符
collection items terminated by '_' -- 元素与元素之间分隔符
map keys terminated by ':' -- Map数据类型键与值之间的分隔符
lines terminated by '\n'; -- 行与行之间的换行符
表数据:
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,beng bu_anhui
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,he fei_anhui
3.3.2显示表的信息
show tables;
show tables like 'u*';
desc t_person;
desc formatted students; // 更加详细
3.3.3加载数据
1、使用
hdfs dfs -put '本地数据' 'hive表对应的HDFS目录下'2、使用 load data
(1)将HDFS上的/input1目录下面的数据 移动至 students表对应的HDFS目录下
load data inpath '/input1/students.txt' into table students(2)加上 local 关键字 可以将Linux本地目录下的文件 上传到 hive表对应HDFS 目录下 原文件不会被删除
load data local inpath '/usr/local/soft/data/students.txt' into table students;
(3)// overwrite 覆盖加载
load data local inpath '/usr/local/soft/data/students.txt' overwrite into table students;
3.3.4导出数据
将查询结果存放到本地
1.首先在本地(linux)上创建存放数据的文件夹
2.导出查询结果的数据
举例:
insert overwrite local directory '本地路径' select xxx from xxx;
按照指定的方式将数据输出到本地
1.创建存放数据的目录
2.导出查询结果的数据
举例:
insert overwrite local directory '/usr/local/soft/shujia/person'
ROW FORMAT DELIMITED fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n'
select * from t_person;
3.3.5清空表数据与删除表
清空表数据
truncate table 表名;
删除表
drop table 表名;
3.3.5修改列
查询表结构
desc 表名;
添加列
举例:alter table students2 add columns (education string);
更新列
举例:alter table stduents2 change education educationnew string;
四、Hive内部表与外部表
内部表简介:
1.默认建表的类型就是内部表
2.删除表的时候,表在hdfs中对应的文件夹会被删除,同时表数据(hdfs中的文件)也会被删除,
在数据库中存储的元数据信息也会被删除
举例:
// 内部表
create table student3
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
外部表简介:
1.外部表使用EXTERNAL关键字创建
2.外部表因为是指定其他的hdfs路径的数据加载到表中来,所以hive会认为自己不完全独占这份数据,所以删除hive表的时候,数据仍然保存在hdfs中不会被删除,但是数据库中的元数据会被删除。
3.设计外部表的初衷就是让表的元数据与表数据(hdfs下的文件数据)解耦
举例:
// 外部表
create external table students_external
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
相关文章:
Hive概述与基本操作
一、Hive基本概念 1.什么是hive? (1)hive是数据仓库建模的工具之一 (2)可以向hive传入一条交互式的sql,在海量数据中查询分析得到结果的平台 2.Hive简介 Hive本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS…...

安装 FFmpeg
安装 FFmpeg 1. Install FFmpeg On Ubuntu2. Install FFmpeg On Ubuntu 16.042.1. First add the repository2.2. Update the newly added repository2.3. Now install the ffmpeg2.4. For opening the ffmpeg for that type ffpmeg on the terminal 3. Uninstall ffmpegRefere…...

18、差分
差分 题目描述 输入一个长度为n的整数序列。 接下来输入m个操作,每个操作包含三个整数l, r, c,表示将序列中[l, r]之间的每个数加上c。 请你输出进行完所有操作后的序列。 输入格式 第一行包含两个整数n和m。 第二行包含n个整数,表示整…...

13 指针(上)
指针是 C 语言最重要的概念之一,也是最难理解的概念之一。 指针是C语言的精髓,要想掌握C语言就需要深入地了解指针。 指针类型在考研中用得最多的地方,就是和结构体结合起来构造结点(如链表的结点、二叉树的结点等)。 本章专题脉络 1、指针…...
AI 对话完善【人工智能】
AI 对话【人工智能】 前言版权开源推荐AI 对话v0版本:基础v1版本:对话数据表tag.jsTagController v2版本:回复中textarea.jsChatController v3版本:流式输出chatLast.jsChatController v4版本:多轮对话QianfanUtilChat…...

利用数组储存表格数据
原理以及普通数组储存表格信息 在介绍数组的时候说过,数组能够用来储存任何同类型的数据,这里的意思就表明只要是同一个类型的数组据就可以储存到一个数组中。那么在表格中同一行的数据是否可以储存到同一个数组中呢?答案自然是可以ÿ…...

[数据概念|数据技术]智能合约如何助力数据资产变现
“ 区块链上数据具有高可信度,智能合约将区块链变得更加智能化,以支持企业场景。” 之前鼹鼠哥已经发表了一篇文章,简单介绍了区块链,那么,智能合约又是什么呢?它又是如何助力数据资产变现的呢?…...

JS中的常见二进制数据格式
格式描述用途示例ArrayBuffer固定长度的二进制数据缓冲区,不直接操作具体的数据,而是通过类型数组或DataView对象来读写用于存储和处理大量的二进制数据,如文件、图像等let buffer new ArrayBuffer(16);TypedArray基于ArrayBuffer对象的视图…...
uniapp开发h5端使用video播放mp4格式视频黑屏,但有音频播放解决方案
mp4格式视频有一些谷歌播放视频黑屏,搜狗浏览器可以正常播放 可能和视频的编码格式有关,谷歌只支持h.264编码格式的视频播放 将mp4编码格式修改为h.264即可 转换方法: 如果是自己手动上传文件可以手动转换 如果是后端接口调取的地址就需…...
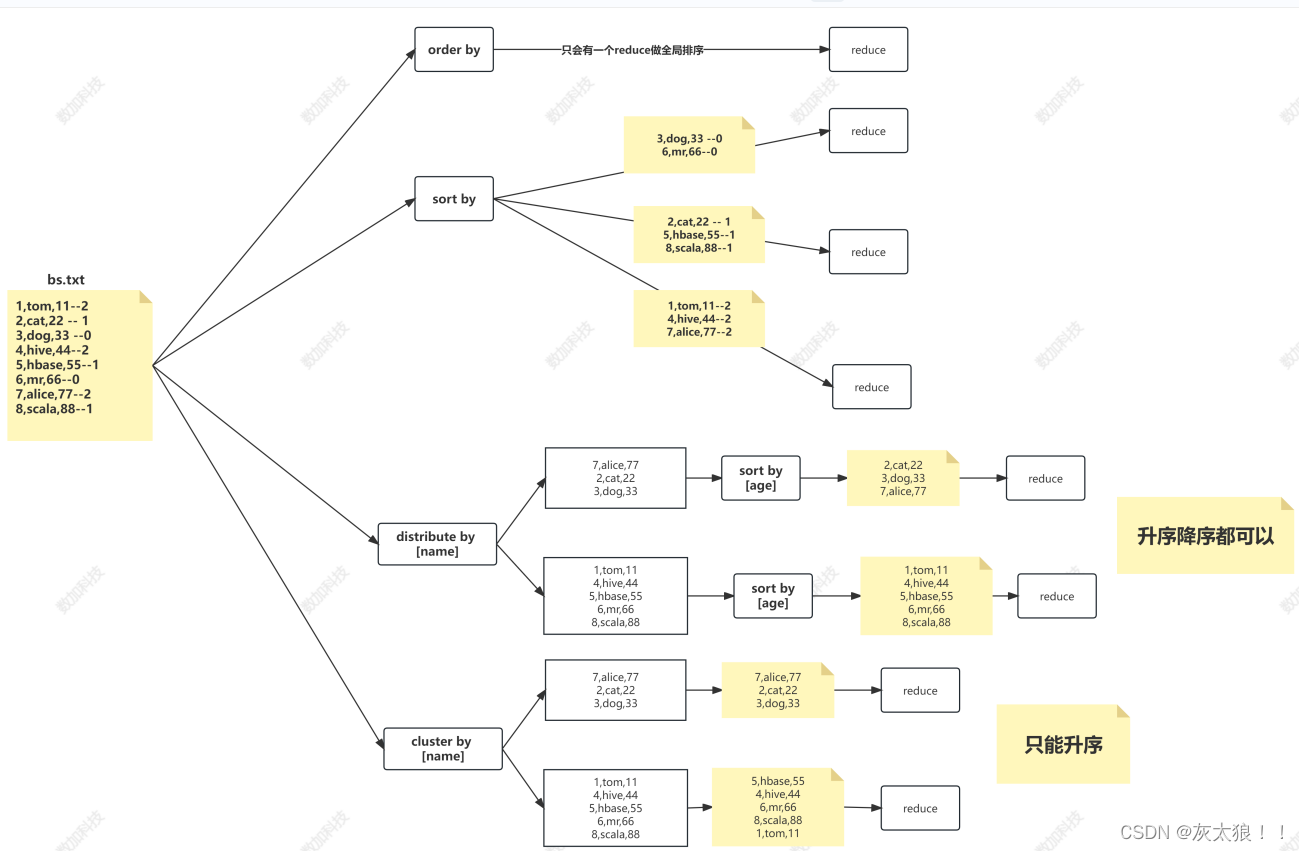
Hive的分区与排序
一、Hive分区 1.引入: 在大数据中,最常见的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的ÿ…...
4.9)
Objective-C学习笔记(内存管理、property参数)4.9
1.引用计数器retainCount:每个对象都有这个属性,默认值为1,记录当前对象有多少人用。 为对象发送一条retain/release消息,对象的引用计数器加/减1,为对象发一条retainCount,得到对象的引用计数器值,当计数器…...

C语言进阶课程学习记录-第29课 - 指针和数组分析(下)
C语言进阶课程学习记录-第29课 - 指针和数组分析(下) 数组名与指针实验-数组形式转换实验-数组名与指针的差异实验-转化后数组名加一的比较实验-数组名作为函数形参小结 本文学习自狄泰软件学院 唐佐林老师的 C语言进阶课程,图片全部来源于课…...
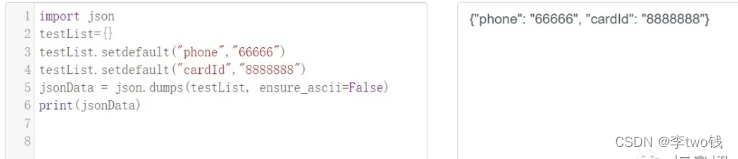
一起学习python——基础篇(13)
前言,python编程语言对于我个人来说学习的目的是为了测试。我主要做的是移动端的开发工作,常见的测试主要分为两块,一块为移动端独立的页面功能,另外一块就是和其他人对接工作。 对接内容主要有硬件通信协议、软件接口文档。而涉…...
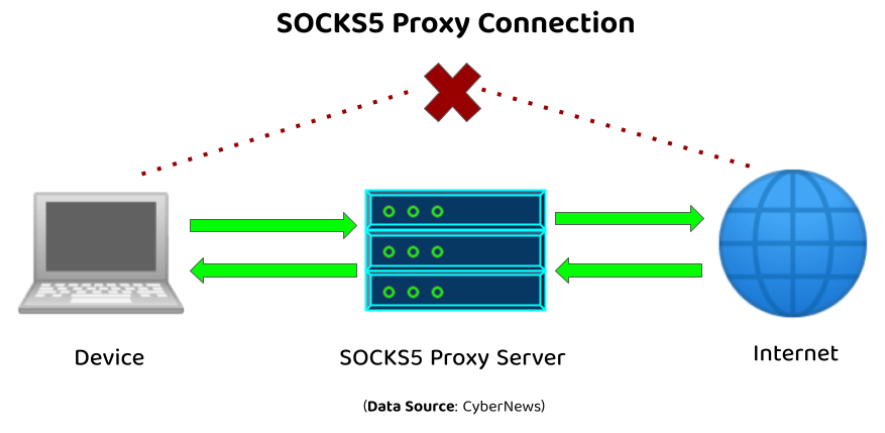
SOCKS代理概述
在网络技术的广阔领域中🌐,SOCKS代理是一个核心组件,它在提升在线隐私保护🛡️、实现匿名通信🎭以及突破网络访问限制🚫方面发挥着至关重要的作用。本文旨在深入探讨SOCKS代理的基础,包括其定义…...

AI助力M-OFDFT实现兼具精度与效率的电子结构方法
编者按:为了使电子结构方法突破当前广泛应用的密度泛函理论(KSDFT)所能求解的分子体系规模,微软研究院科学智能中心的研究员们基于人工智能技术和无轨道密度泛函理论(OFDFT)开发了一种新的电子结构计算框架…...
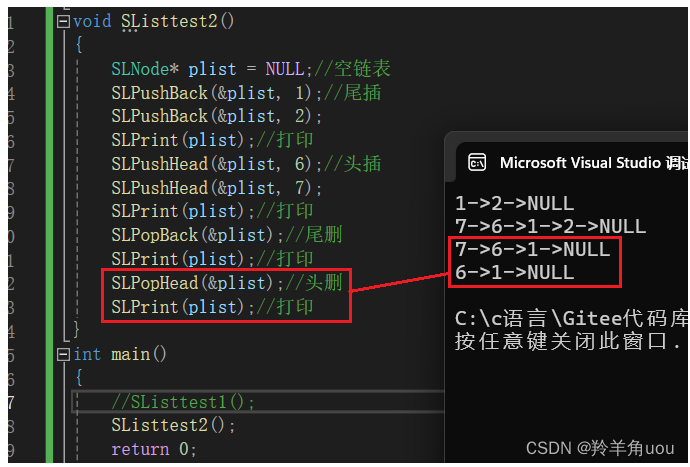
【数据结构】单链表(一)
上一篇【数据结构】顺序表-CSDN博客 我们了解了顺序表,但是呢顺序表涉及到了一些问题,比如,中间/头部的插入/删除,时间复杂度为O(N);增容申请空间、拷贝、释放旧空间会有不小的消耗;增容所浪费的空间... 我们如何去解…...

SCI一区 | Matlab实现INFO-TCN-BiGRU-Attention向量加权算法优化时间卷积双向门控循环单元注意力机制多变量时间序列预测
SCI一区 | Matlab实现INFO-TCN-BiGRU-Attention向量加权算法优化时间卷积双向门控循环单元注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现INFO-TCN-BiGRU-Attention向量加权算法优化时间卷积双向门控循环单元注意力机制多变量时间序列预测预测效果基本介绍模型描述程…...
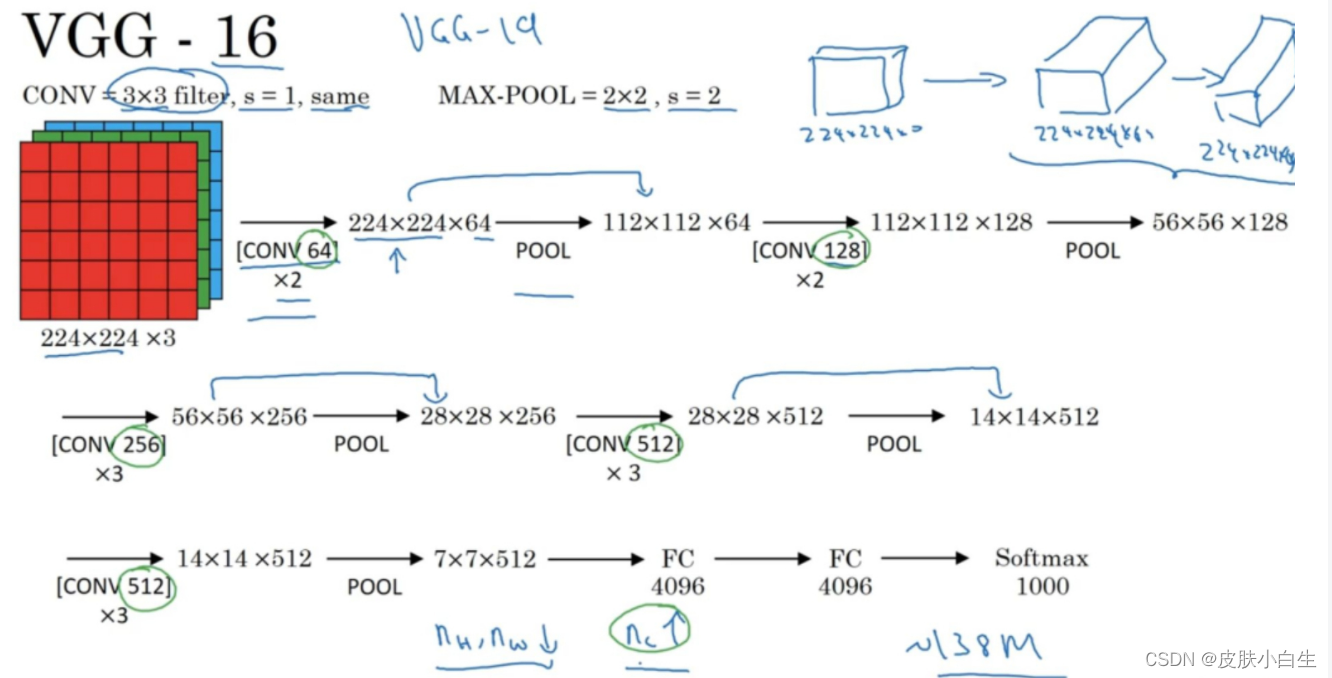
Coursera吴恩达《深度学习》课程总结(全)
这里有Coursera吴恩达《深度学习》课程的完整学习笔记,一共5门课:《神经网络和深度学习》、《改善深层神经网络》、《结构化机器学习项目》、《卷积神经网络》和《序列模型》, 第一门课:神经网络和深度学习基础,介绍一…...

C# 操作PDF表单 - 创建、填写、删除PDF表单域
通常情况下,PDF文件是不可编辑的,但PDF表单提供了一些可编辑区域,允许用户填写和提交信息。PDF表单通常用于收集信息、反馈或进行在线申请,是许多行业中数据收集和交换的重要工具。 PDF表单可以包含各种类型的输入控件࿰…...

Astropy:探索宇宙奥秘的Python工具箱
Astropy:探索宇宙奥秘的Python工具箱 什么是Astropy库? Astropy 是一个面向天文学领域的 Python 库,旨在提供常用的天文学数据结构、单位转换、物理常数以及天文学计算方法等功能。它为天文学家和研究人员提供了丰富的工具,用于处理和分析天文…...

突破试用限制:开源脚本实现IDM无限使用的完整解决方案
突破试用限制:开源脚本实现IDM无限使用的完整解决方案 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 一、问题引入:IDM用户的痛点与解决…...

MDS vs PCA:哪种降维方法更适合你的数据?
MDS与PCA深度对比:从算法原理到实战选型指南 当面对高维数据时,降维技术就像一把打开数据奥秘的钥匙。在众多降维方法中,多维尺度变换(MDS)和主成分分析(PCA)是最常被比较的两种经典技术。它们都能将复杂的高维数据简化为更易理解的二维或三维…...

VS2022 + WinForms:从拖控件到写逻辑,手把手带你做出第一个C#计算器
VS2022 WinForms:从拖控件到写逻辑,手把手带你做出第一个C#计算器 第一次打开Visual Studio 2022时,那个闪亮的启动界面可能会让你既兴奋又不知所措。作为微软最新的集成开发环境,VS2022为C#开发者提供了强大的工具链࿰…...

【实战指南】League Akari:英雄联盟智能工具全解析
【实战指南】League Akari:英雄联盟智能工具全解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 一、价值定位:重新定…...

从编译到定制:WinSCP全流程开发指南
从编译到定制:WinSCP全流程开发指南 【免费下载链接】winscp WinSCP is a popular free file manager for Windows supporting SFTP, FTP, FTPS, SCP, S3, WebDAV and local-to-local file transfers. A powerful tool to enhance your productivity with a user-fr…...
)
基于SpringBoot + Vue的养老院管理系统(角色:家属、护工、管理员)
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...
)
2027年非全日制国际商务硕士备考规划-暨南大学(珠海研究院)
2027年非全日制国际商务硕士备考规划 一、基本情况与备考总原则 个人时间画像 工作日:19:20到家,19:30-20:00吃饭休息,20:00-23:00为黄金学习时段(约2.5-3小时)。23:30前入睡,保证7小时睡眠。 周末…...
)
什么是哈希算法?(大白话+原理+应用,一次讲透)
文章目录一、一句话定义二、用生活例子秒懂对应到代码里:三、哈希算法的核心特性(面试必背)四、为什么 HashSet.contains() 是 O(1)?(结合哈希原理)五、哈希算法的常见应用(你日常都在用&#x…...
| 算法入门必看)
图的存储方式详解(邻接矩阵 + 邻接表)| 算法入门必看
在算法学习中,图是仅次于树的核心数据结构,广泛应用于路径规划、网络拓扑、社交关系等场景。而图的存储是后续图论算法(DFS、BFS、最短路等)的基础——选择合适的存储方式,能直接影响算法的时间和空间效率。 本文将详细讲解图的两种最常用存储方式:邻接矩阵和邻接表,从…...
)
工控机驱动安全自查:5分钟用DriverView揪出可疑第三方驱动(附分析技巧)
工控机驱动安全自查:5分钟用DriverView揪出可疑第三方驱动(附分析技巧) 工业自动化设备的稳定运行离不开安全的驱动环境。想象一下,当你负责的生产线突然出现不明原因的停机,经过层层排查,最终发现是一个来…...