Hive 之 UDF 运用(包会的)
文章目录
- UDF 是什么?
- reflect
- 静态方法调用
- 实例方法调用
- 自定义 UDF(GenericUDF)
- 1.创建项目
- 2.创建类继承 UDF
- 3.数据类型判断
- 4.编写业务逻辑
- 5.定义函数描述信息
- 6.打包与上传
- 7.注册 UDF 函数并测试
- 返回复杂的数据类型
UDF 是什么?
Hive 中的 UDF 其实就是用户自定义函数,允许用户注册使用自定义的逻辑对数据进行处理,丰富了Hive 对数据处理的能力。
UDF 负责完成对数据一进一出处理的操作,和 Hive 中存在的函数 year、month、day 等相同。
reflect
在 Hive 中,可以使用 reflect() 方法通过 Java 反射机制调用 Java 类的方法。
通俗来说,它可以调用 Hive 中不存在,但是 JDK 中拥有的方法。
语法
reflect()函数的语法为:reflect(class,method[,arg1[,arg2..]])。
静态方法调用
假设当前在 Java 中存在类如下:
package com.example;public class MathUtils {public static int addNumbers(int a, int b) {return a + b;}
}
那么使用 reflect() 方法调用时,如下所示:
SELECT reflect("com.example.MathUtils", "addNumbers", 3, 5) AS result;
注意! 这里的类 "com.example.MathUtils" 并不是在 JDK 中真实存在的,只是我作为说明的一个案例, reflect() 方法只能调用 JDK 中(原生内置)存在的方法。
所以当你需要使用 reflect() 方法时,需要先去查找调用的目标方法全类名、方法名以及是否需要传递参数。
实例方法调用
当我们需要调用 Java 中的实例方法时,先创建 Java 对象,然后再调用其方法。
例如:将乱码的字符串进行解析。
SELECT reflect('java.net.URLDecoder', 'decode', "Mozilla/5.0%20(compatible;%20MJ12bot/v1.4.7;%20http://www.majestic12.co.uk/bot.php?+)
" ,'utf-8') as result;
结果输出如下:

自定义 UDF(GenericUDF)
Hive 支持两种 UDF 函数自定义操作,分别是:
-
GenericUDF(通用UDF):用于实现那些可以处理任意数据类型的函数。它们的输入和输出类型可以是任意的,但需要在函数内部处理类型转换和逻辑,可以实现更复杂的逻辑处理。
-
UDF:用于实现那些只能处理特定数据类型的函数。每个 UDF 都明确指定了输入参数的类型和返回值类型,使用更为简单。
本文采用的是通用 UDF —— GenericUDF 实现方法
这里通过一个在 Hive 中实现两数相加的自定义 UDF 案例来进行说明,看完你就会啦,轻松拿捏。
1.创建项目
在 IDEA 中创建一个 Maven 项目,引入 Hive 依赖,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.jsu</groupId><artifactId>MyUDF</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><!-- hive-exec依赖无需打到jar包,故scope使用provided--><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.3</version><scope>provided</scope></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><!--将依赖编译到jar包中--><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><!--配置执行器--><execution><id>make-assembly</id><!--绑定到package执行周期上--><phase>package</phase><goals><!--只运行一次--><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>
注意,引入的 Hive 依赖版本请保持和你集群中使用的版本一致。
2.创建类继承 UDF
创建一个类,我这里取名为 AddTest,继承 Hive UDF 父类 GenericUDF,需要重写三个方法,如下所示:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;public class AddTest extends GenericUDF {@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {return null;}@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {return null;}@Overridepublic String getDisplayString(String[] strings) {return null;}
}
-
initialize(ObjectInspector[] objectInspectors)方法
这个方法是在 UDF 初始化时调用的。它用于执行一些初始化操作,并且可以用来验证 UDF 的输入参数类型是否正确。参数objectInspectors是一个包含输入参数的ObjectInspector数组,它描述了每个输入参数的类型和结构。
一般在这个方法中检查输入参数的数量和类型是否满足你的函数的要求。如果输入参数不符合预期,你可以抛出UDFArgumentException异常。如果一切正常,你需要返回一个合适的ObjectInspector对象,它描述了你的函数返回值的类型。 -
evaluate(DeferredObject[] deferredObjects)方法
在这个方法中定义真正执行 UDF 逻辑的地方,获取输入的参数,并且根据输入参数执行相应的计算或操作。参数deferredObjects是一个包含输入参数的 DeferredObject 数组,你可以通过它来获取实际的输入值。 -
getDisplayString(String[] strings)方法
这个方法用于描述 UDF 的信息,用于生成可读的查询执行计划(Explain),以便用户了解查询的结构和执行过程。
3.数据类型判断
实现 UDF 的第一步操作就是在 initialize 方法中,判断用户输入的参数是否合法,出现错误时,进行反馈。
在这里主要分为三个步骤:
-
检验参数个数
-
检查参数类型
-
定义函数返回值类型
一般情况下,可以使用下面的模板:
@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {// 1.校验参数个数if (objectInspectors.length != 2) {throw new UDFArgumentException("参数个数有误!");}// 2.检查第1个参数是否是int类型// 判断第1个参数的基本类型ObjectInspector num1 = objectInspectors[0];if (num1.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("第1个参数不是基本数据类型");}// 第1个参数类型判断PrimitiveObjectInspector temp = (PrimitiveObjectInspector) num1;if (PrimitiveObjectInspector.PrimitiveCategory.INT != temp.getPrimitiveCategory()) {throw new UDFArgumentException("第1个参数应为INT类型");}// 2.检查第2个参数是否是int类型// 判断第2个参数的基本类型ObjectInspector num2 = objectInspectors[1];if (num2.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("第2个参数不是基本数据类型");}// 第2个参数类型判断PrimitiveObjectInspector temp2 = (PrimitiveObjectInspector) num2;if (PrimitiveObjectInspector.PrimitiveCategory.INT != temp2.getPrimitiveCategory()) {throw new UDFArgumentException("第2个参数应为INT类型");}// 3.设置函数返回值类型(返回一个整型数据)return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}
4.编写业务逻辑
在 evaluate 方法中定义业务逻辑,这里比较简单,就是实现两数相加。
@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {// 完成两数相加的逻辑计算int num1 = Integer.parseInt(deferredObjects[0].get().toString());int num2 = Integer.parseInt(deferredObjects[1].get().toString());return num1 + num2;}
5.定义函数描述信息
在 getDisplayString 方法中定义函数在 Explain 中的描述信息,一般都是固定写法,如下所示:
@Overridepublic String getDisplayString(String[] strings) {return getStandardDisplayString("AddTest", strings);}
把对应的函数名称进行替换即可。
6.打包与上传
对编写的项目进行打包,并上传到 HDFS 上。
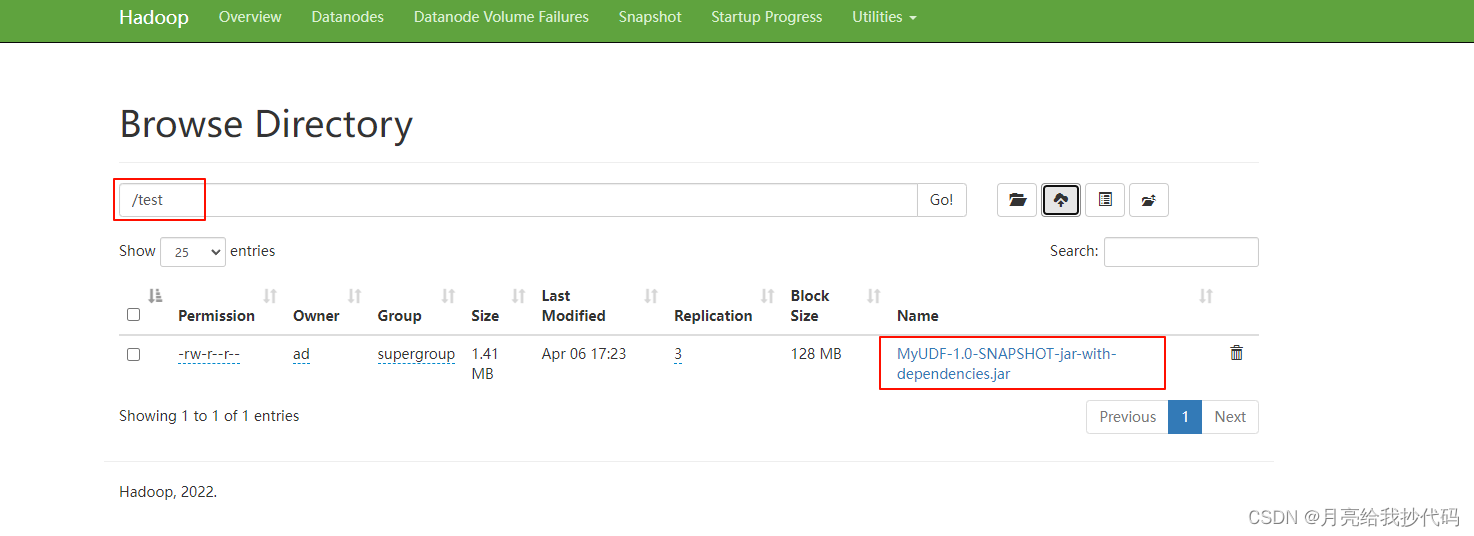
本案例的完整代码如下所示:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;public class AddTest extends GenericUDF {@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {// 1.校验参数个数if (objectInspectors.length != 2) {throw new UDFArgumentException("参数个数有误!");}// 2.检查第1个参数是否是int类型// 判断第1个参数的基本类型ObjectInspector num1 = objectInspectors[0];if (num1.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("第1个参数不是基本数据类型");}// 第1个参数类型判断PrimitiveObjectInspector temp = (PrimitiveObjectInspector) num1;if (PrimitiveObjectInspector.PrimitiveCategory.INT != temp.getPrimitiveCategory()) {throw new UDFArgumentException("第1个参数应为INT类型");}// 2.检查第2个参数是否是int类型// 判断第2个参数的基本类型ObjectInspector num2 = objectInspectors[1];if (num2.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("第2个参数不是基本数据类型");}// 第2个参数类型判断PrimitiveObjectInspector temp2 = (PrimitiveObjectInspector) num2;if (PrimitiveObjectInspector.PrimitiveCategory.INT != temp2.getPrimitiveCategory()) {throw new UDFArgumentException("第2个参数应为INT类型");}// 3.设置函数返回值类型(返回一个整型数据)return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {// 完成两数相加的逻辑计算int num1 = Integer.parseInt(deferredObjects[0].get().toString());int num2 = Integer.parseInt(deferredObjects[1].get().toString());return num1 + num2;}@Overridepublic String getDisplayString(String[] strings) {return getStandardDisplayString("AddTest", strings);}}
7.注册 UDF 函数并测试
进入 Hive 中对创建的 UDF 函数进行注册。
如果你期间修改了 JAR 包并重新上传,则需要重启与 Hive 的连接,建立新的会话才会生效。
-- 永久注册
create function testAdd as 'AddTest' using jar 'hdfs://hadoop201:8020/test/MyUDF-1.0-SNAPSHOT-jar-with-dependencies.jar';-- 删除注册的函数
drop function if exists testAdd;
-
testAdd:注册的 UDF 函数名称。 -
as 'AddTest':编写的 UDF 函数全类名。 -
using jar:指定 JAR 包的全路径。
注册成功后,如下所示:

测试
select testAdd(1,2);

如果输入错误的数据类型,会进行报错提示:

返回复杂的数据类型
在更多的场景下,我们可能有多个返回值,那么该如何定义与配置呢?
这里还是通过上面的两数相加的案例来进行说明,套下面的模板使用:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;public class AddTestReturnList extends GenericUDF {@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {// 1.校验参数个数if (objectInspectors.length != 2) {throw new UDFArgumentException("参数个数有误!");}// 2.检查第1个参数是否是int类型// 判断第1个参数的基本类型ObjectInspector num1 = objectInspectors[0];if (num1.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("第1个参数不是基本数据类型");}// 第1个参数类型判断PrimitiveObjectInspector temp = (PrimitiveObjectInspector) num1;if (PrimitiveObjectInspector.PrimitiveCategory.INT != temp.getPrimitiveCategory()) {throw new UDFArgumentException("第1个参数应为INT类型");}// 2.检查第2个参数是否是int类型// 判断第2个参数的基本类型ObjectInspector num2 = objectInspectors[1];if (num2.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("第2个参数不是基本数据类型");}// 第2个参数类型判断PrimitiveObjectInspector temp2 = (PrimitiveObjectInspector) num2;if (PrimitiveObjectInspector.PrimitiveCategory.INT != temp2.getPrimitiveCategory()) {throw new UDFArgumentException("第2个参数应为INT类型");}// 3.设置函数返回值类型(返回一个键值对数据)ArrayList<String> structFieldNames = new ArrayList<>();ArrayList<ObjectInspector> structFieldObjectInspectors = new ArrayList<>();structFieldNames.add("result");structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(structFieldNames, structFieldObjectInspectors);}@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {// 完成两数相加的逻辑计算ArrayList<Integer> arrayList = new ArrayList<>();int num1 = Integer.parseInt(deferredObjects[0].get().toString());int num2 = Integer.parseInt(deferredObjects[1].get().toString());arrayList.add(num1 + num2);return arrayList;}@Overridepublic String getDisplayString(String[] strings) {return getStandardDisplayString("AddTestReturnList", strings);}}
(退出当前与 Hive 的连接,建立新的连接,刷新缓存)
同样的,打包上传到 HDFS 上进行注册:
create function AddTestReturnList as 'AddTestReturnList' using jar 'hdfs://hadoop201:8020/test/MyUDF-1.0-SNAPSHOT-jar-with-dependencies.jar';
此时,可能会发生报错,这是由于我们之前已经加载过该 JAR 包了,再次加载时 Hive 会抛出异常,我们可以通过下面的语句进行调整:
-- 关闭向量化查询
set hive.vectorized.execution.enabled=false;
重新注册即可。
进行测试:
select AddTestReturnList(1,2);
计算结果如下:

是不是轻松拿捏了~
相关文章:
Hive 之 UDF 运用(包会的)
文章目录 UDF 是什么?reflect静态方法调用实例方法调用 自定义 UDF(GenericUDF)1.创建项目2.创建类继承 UDF3.数据类型判断4.编写业务逻辑5.定义函数描述信息6.打包与上传7.注册 UDF 函数并测试返回复杂的数据类型 UDF 是什么? H…...

数据驱动目标:如何通过OKR实现企业数字化转型
在数字化转型的浪潮中,企业管理者面临着前所未有的挑战和机遇。如何确保企业在变革中不仅能够生存,还能蓬勃发展?答案可能就在于有效的目标管理——特别是采用OKR(Objectives and Key Results,目标与关键成果ÿ…...

软考120-上午题-【软件工程】-软件开发模型02
一、演化模型 软件类似于其他复杂的系统,会随着时间的推移而演化。在开发过程中,常常会面临以下情形:商业和产品需求经常发生变化,直接导致最终产品难以实现;严格的交付时间使得开发团队不可能圆满地完成软件产品&…...
C语言面试题之返回倒数第 k 个节点
返回倒数第 k 个节点 实例要求 1、实现一种算法,找出单向链表中倒数第 k 个节点;2、返回该节点的值; 示例:输入: 1->2->3->4->5 和 k 2 输出: 4 说明:给定的 k 保证是有效的。实…...

力扣爆刷第116天之CodeTop100五连刷66-70
力扣爆刷第116天之CodeTop100五连刷66-70 文章目录 力扣爆刷第116天之CodeTop100五连刷66-70一、144. 二叉树的前序遍历二、543. 二叉树的直径三、98. 验证二叉搜索树四、470. 用 Rand7() 实现 Rand10()五、64. 最小路径和 一、144. 二叉树的前序遍历 题目链接:htt…...

B站广告推广操作教程及费用?
哔哩哔哩(B站)作为国内极具影响力的年轻人文化社区,已成为众多品牌与企业触达目标受众、提升品牌影响力的重要阵地。然而,面对B站复杂的广告系统与精细化运营需求,许多广告主可能对如何高效开展B站广告推广感到困惑。云…...

Linux操作系统之docker基础
目录 一、docker 1.1 简介 1.2 安装配置docker 二、dockerfile 1.1、简介 1.2、dockerfile 关键字 一、docker 1.1 简介 容器技术 容器其实就是虚拟机,每个容器可以运行不同的系统【系统是以linux为主的】 为什么要使用docker? docker容器之间相互隔…...

35-3 使用dnslog探测fastjson漏洞
一、DNSLog 原理 DNSLog是一种记录在DNS上的域名相关信息的机制,类似于日志文件,记录了对域名或IP的访问信息。了解多级域名的概念对理解DNSLog至关重要。因特网采用树状结构的命名方法,按照组织结构划分域,每个域都是名字空间中被管理的一个划分,可以进一步划分为子域。域…...

Qt——示波器/图表 QCustomPlot
一、介绍 QCustomPlot是一个用于绘图和数据可视化的Qt C小部件。它没有进一步的依赖关系,提供友好的文档帮助。这个绘图库专注于制作好看的,出版质量的2D绘图,图形和图表,以及为实时可视化应用程序提供高性能。QCustomPlot可以导出…...
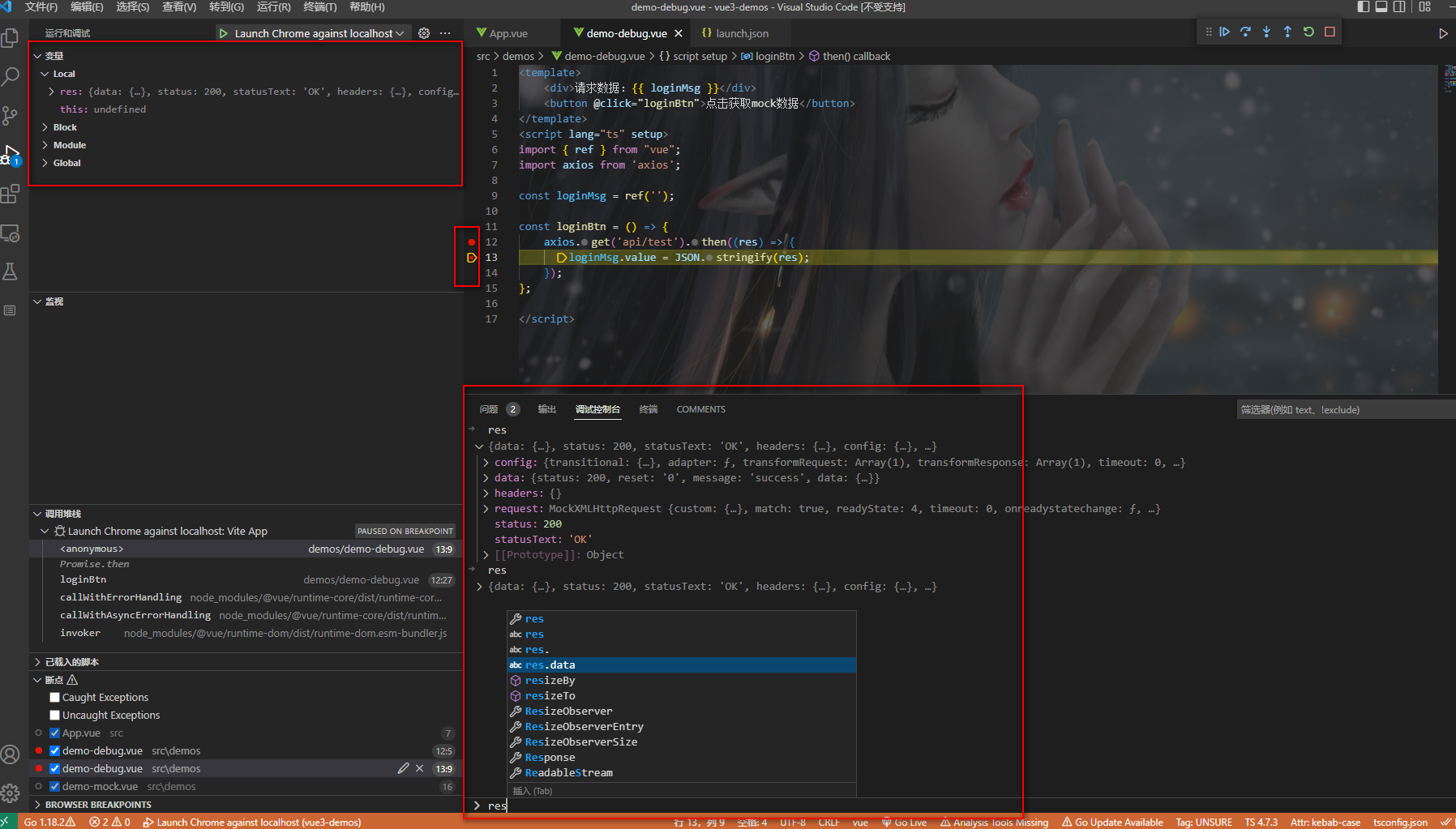
《图解Vue3.0》- 调试
如何对vue3项目进行调试 调试是开发过程中必备的一项技能,掌握了这项技能,可以很好的定义bug所在。一般在开发vue3项目时,有三种方式。 代码中添加debugger;使用浏览器调试:sourcemap需启用vs code 调试:先开启node服…...
【PyQt5篇】和子线程进行通信
文章目录 🍔使用QtDesigner进行设计🛸和子线程进行通信🎈运行结果 🍔使用QtDesigner进行设计 我们首先使用QtDesigner设计界面 得到代码login.ui <?xml version"1.0" encoding"UTF-8"?> <ui …...

JavaScript数组操作方法全录
改变原数组的方法: push() - 将一个或多个元素添加到数组的末尾,并返回新数组的长度。 pop() - 从数组中移除最后一个元素,并返回该元素。 shift() - 从数组中移除第一个元素,并返回该元素。 unshift() - 将一个或多个元素添加到…...
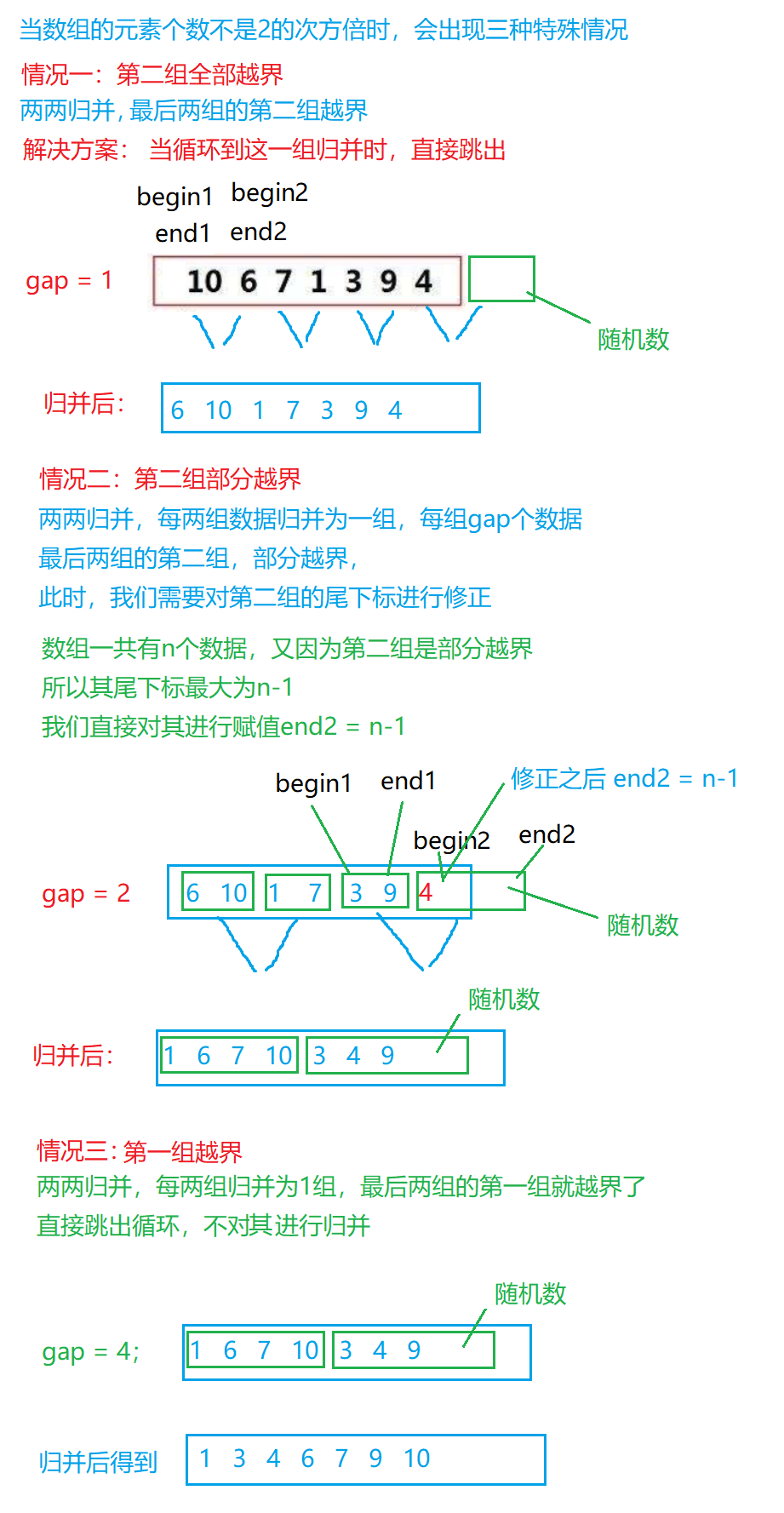
8.排序(直接插入排序、希尔排序、选择排序、堆排序、冒泡排序、快速排序、归并排序)的模拟实现
1.排序的概念及其运用 1.1排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录…...
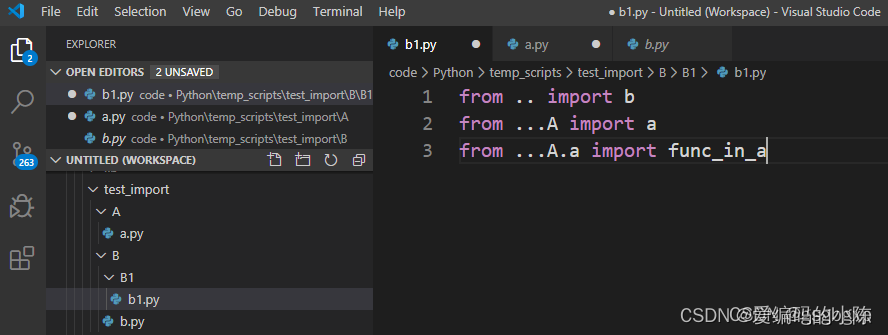
(详解)python调用另一个.py文件中的类和函数或直接运行另一个.py文件
一、同一文件夹下的调用 1.调用函数 A.py文件如下: def add(x,y):print(和为:%d%(xy))在B.py文件中调用A.py的add函数如下: import A A.add(1,2)或 from A import add add(1,2)2.调用类 A.py文件如下: class Add:def __ini…...

每日一题:修改后的最大二进制字符串
给你一个二进制字符串 binary ,它仅有 0 或者 1 组成。你可以使用下面的操作任意次对它进行修改: 操作 1 :如果二进制串包含子字符串 "00" ,你可以用 "10" 将其替换。 比方说, "00010"…...
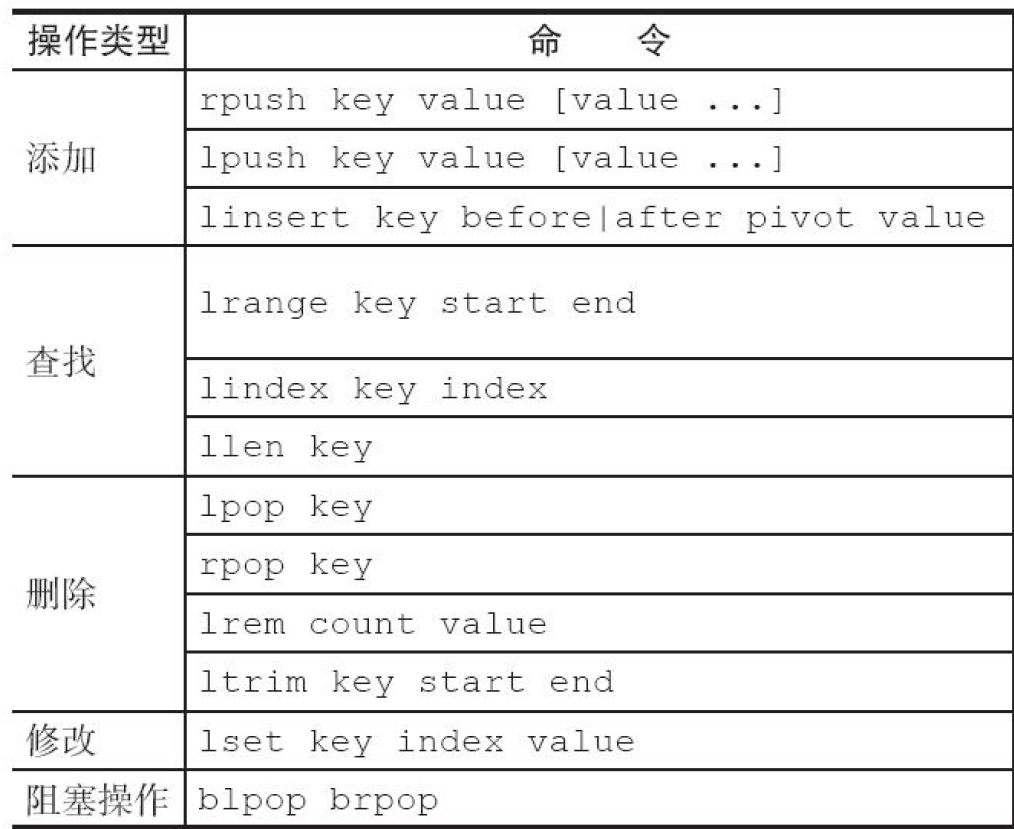
Redis 5种数据结构常用命令
文章目录 1 字符串2 哈希3 列表4 集合5 有序集合 1 字符串 命令描述set key value设置指定key的值为valueget key获取指定key的值del key [key …]删除一个或多个keymset key value [key value …]设置多个key的值mget key [key …]获取一个或多个key的值incr key将key中储存的…...

23、区间和
区间和 题目描述 假定有一个无限长的数轴,数轴上每个坐标上的数都是0。 现在,我们首先进行 n 次操作,每次操作将某一位置x上的数加c。 接下来,进行 m 次询问,每个询问包含两个整数l和r,你需要求出在区间…...
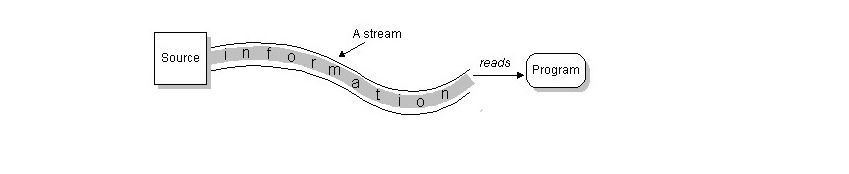
Python零基础从小白打怪升级中~~~~~~~文件和文件夹的操作 (1)
第七节:文件和文件夹的操作 一、IO流(Stream) 通过“流”的形式允许计算机程序使用相同的方式来访问不同的输入/输出源。stream是从起源(source)到接收的(sink)的有序数据。我们这里把输入/输…...
Qt plugin 开发UI界面插件
目录 1.创建接口 2.创建插件 3.创建插件界面 4.插件实现 5.创建应用工程 6.应用插件 1.创建接口 打开QtCreater,点击左上角“文件”->新建文件或项目,在弹窗中选择C/CHeader File。 输入文件名,选好路径(可自行设置名称…...

Android查看SO库的依赖
➜ bin pwd /Users/xxx/Library/Android/sdk/ndk/21.1.6352462/toolchains/aarch64-linux-android-4.9/prebuilt/darwin-x86_64/bin ➜ bin ./aarch64-linux-android-readelf -d /Download/libxxx.so 0x0000000000000001 (NEEDED) Shared library: [liblog.so]0x…...

VideoAgentTrek-ScreenFilter视觉盛宴:处理4K超高清屏幕录像的效果与性能挑战
VideoAgentTrek-ScreenFilter视觉盛宴:处理4K超高清屏幕录像的效果与性能挑战 最近在折腾一些屏幕录像的后期处理,特别是那些4K分辨率、高帧率的超高清素材。说实话,直接处理这种级别的视频,对硬件和软件都是不小的考验。我试用了…...
)
保姆级教程:在STM32F103上从零移植FreeModbus V1.6(RTU模式)
保姆级教程:在STM32F103上从零移植FreeModbus V1.6(RTU模式) Modbus协议作为工业自动化领域的"普通话",其开源实现FreeModbus凭借轻量级和可移植性成为嵌入式开发者的首选。本文将手把手带你在STM32F103C8T6开发板上完成…...

SeqGPT-560M智能客服问答系统部署指南
SeqGPT-560M智能客服问答系统部署指南 1. 引言 想象一下这样的场景:你的电商平台每天收到上千条客户咨询,从"这个衣服有货吗"到"怎么申请退货",问题五花八门。传统客服需要一个个手动回复,效率低下还容易出…...

从‘巡逻’到‘狂暴’:手把手用Unity行为树节点拼出一个有灵魂的BOSS战AI
从‘巡逻’到‘狂暴’:手把手用Unity行为树节点拼出一个有灵魂的BOSS战AI 想象一下,你正在玩一款动作游戏,面对一个看似普通的BOSS。起初它只是机械地挥舞武器,但随着战斗深入,它开始召唤小弟、释放范围技能࿰…...

3大突破:让网课学习效率提升300%的智能方案
3大突破:让网课学习效率提升300%的智能方案 【免费下载链接】auto-play-course 简单好用的刷课脚本[支持平台:职教云,智慧职教,资源库] 项目地址: https://gitcode.com/gh_mirrors/hc/auto-play-course 在数字化学习普及的今天,职业教育学生平均每…...

新手必看:在快马平台学习排列组合公式的代码实现
新手必看:在快马平台学习排列组合公式的代码实现 作为一个编程新手,当我第一次接触排列组合公式时,那些数学符号和递归逻辑让我一头雾水。直到在InsCode(快马)平台上找到了带详细注释的示例代码,才真正理解了Cn和An公式的实现原理…...

等保测评后,我的CentOS/Ubuntu服务器安全加固清单还加了这些
等保测评后,我的CentOS/Ubuntu服务器安全加固清单还加了这些 在完成等保测评基础整改后,许多安全工程师常陷入"合规即安全"的误区。实际上,等保要求只是安全基线的最低标准。本文将分享我在实际运维中积累的合规之上的实战加固技巧…...

Phi-3-mini-4k-instruct-gguf多场景落地:客服话术优化、会议纪要提炼、周报生成实战
Phi-3-mini-4k-instruct-gguf多场景落地:客服话术优化、会议纪要提炼、周报生成实战 1. 轻量级文本生成利器介绍 Phi-3-mini-4k-instruct-gguf是微软推出的轻量级文本生成模型,特别适合处理日常办公场景中的文本任务。这个模型体积小巧但能力出众&…...
)
Hunyuan-MT-7B开源镜像免配置部署:像素语言传送门一键启动教程(含GPU适配)
Hunyuan-MT-7B开源镜像免配置部署:像素语言传送门一键启动教程(含GPU适配) 1. 项目介绍 像素语言跨维传送门是一款基于Tencent Hunyuan-MT-7B大模型构建的创新翻译工具。它将传统翻译体验重构为16-bit像素冒险风格,让语言转换变…...

Wan2.2-I2V-A14B效果对比:LSTM时序预测辅助下的动态剧情生成
Wan2.2-I2V-A14B效果对比:LSTM时序预测辅助下的动态剧情生成 1. 引言 想象一下,当你输入一段文字描述,AI不仅能生成对应的视频,还能像专业导演一样把控剧情节奏和情感起伏。这正是Wan2.2-I2V-A14B结合LSTM时序预测技术带来的突破…...