爬取豆瓣(线程、Session)优化版本
爬取豆瓣(线程、Session)优化版本
该文章只是为了精进基础,对Session、threading、网站请求解析的理解。
此版本没有爬取详情页。还在学习阶段的读者可以尝试一下。
适用于基础刚开始学习爬虫的!
1.改进点:
- 将普通的
requests.get换成了requests.Session()。 - 增加了多线程
threading。
2.运行条件
pip install -i https://mirrors.aliyun.com/pypi/simple pymongo
pip install -i https://mirrors.aliyun.com/pypi/simple requests
PyCharm安装和破解
2.1.MongoDB下载地址
MongoDB打开地址选择4.4版本即可,或者其他版本。可视化工具可以下载Navicat Premium
3.Session
Session的作用在第一次请求之后,服务端响应的Cookie信息,在下次请求的时候会自动添加上去。
4.分析过程
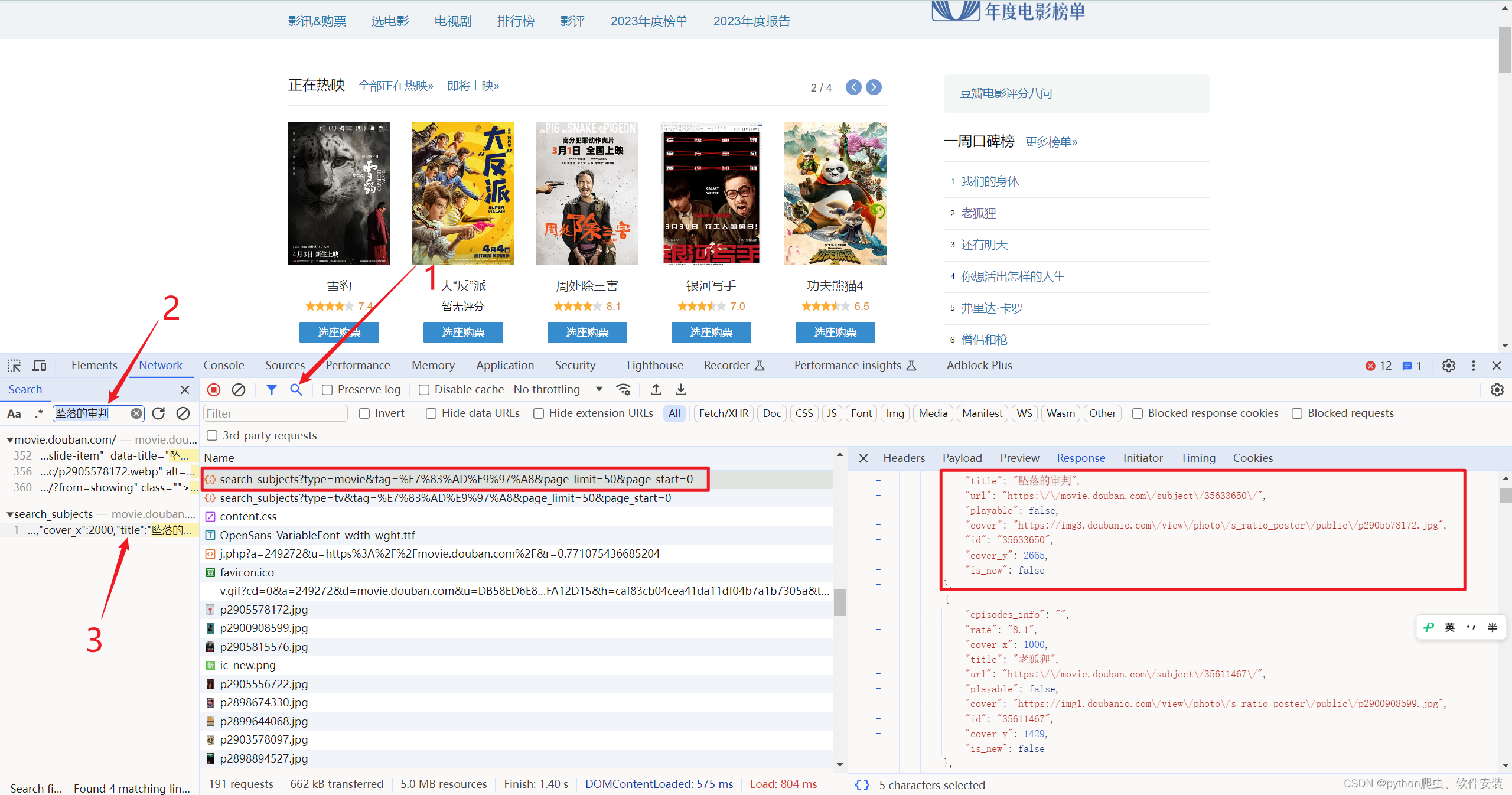
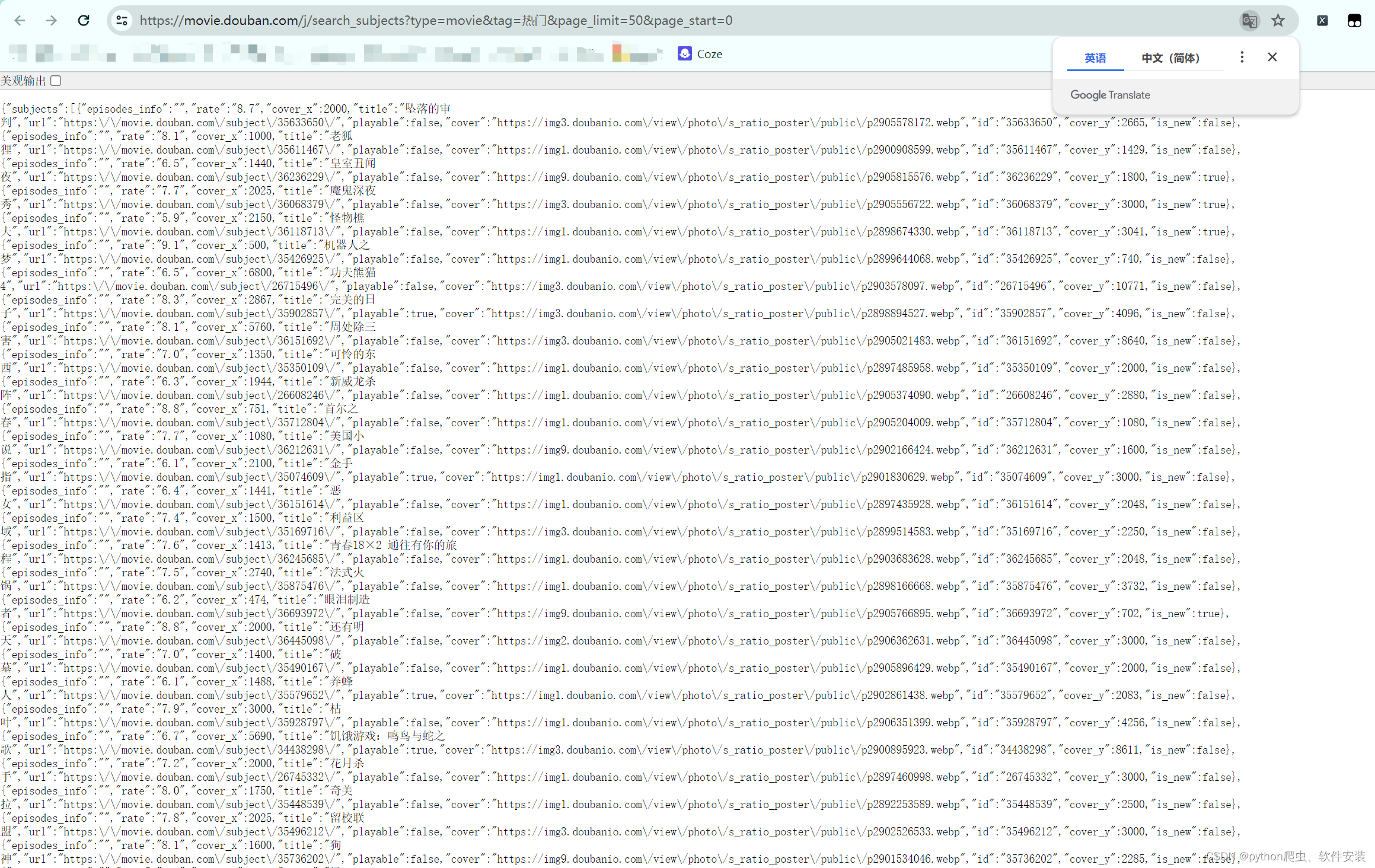
- 打开网址豆瓣电影
- F12分析请求过程。
- 根据电影名称搜索在哪个请求响应体中。
- 分析此URL,调整
tag和page_limit可以变更获取的内容。
5.配置参数
import time
import requests
from pymongo import MongoClient
import threading
import logginglogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')# 定义全局session,用于保存cookie
session = requests.Session()INDEX_URL = 'https://movie.douban.com/j/search_subjects?type=movie&tag={tag}&page_limit={page}' # 类型的url
DETAIL_URL = 'https://movie.douban.com/subject/{id}' # 详情的urlheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36','Referer': 'https://movie.douban.com/',
}# session设置某些全局请求头配置项目
session.headers = headers# 定义mongo链接
MONGO_URL = 'mongodb://localhost:27017'
MONGO_DB = 'douban_data'
COLLECTION_INDEX = 'douban_index'
COLLECTION_DETAIL = 'douban_detail'mongo = MongoClient(MONGO_URL) # 链接mongo
db = mongo[MONGO_DB] # 选择数据库
coll_index = db[COLLECTION_INDEX] # 首页的
coll_detail = db[COLLECTION_DETAIL] # 电影详情页的存储集合tags = None # 类型
6.获取电影类别信息
# 获取类型:https://movie.douban.com/j/search_tags?type=movie&source=index
def get_type():"""获取电影类型"""global tagsurl = 'https://movie.douban.com/j/search_tags?type=movie&source=index'response = session.get(url=url)tags = dict(response.json())['tags']logging.info('获取类型:%s' % tags)7.请求并获取JSON数据
其中
time.sleep()用来模拟网络请求延迟。测试多线程是否有效!
def spider_index(url):"""根据获取的类型挨个获取电影信息"""logging.info('开始获取:%s' % url)try:response_index = session.get(url=url)subjects = dict(response_index.json()).get('subjects')# logging.info('请求成功内容:%s' % subjects)time.sleep(2) # 模拟网络延迟for subject in subjects:# 写入mongodbcoll_index.insert_one(subject)except Exception as e:logging.error('请求出现异常!!!')
8.目前没有爬取详情页,后续完善!
9.完整代码
import time
import requests
from pymongo import MongoClient
import threading
import logginglogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')# 定义全局session,用于保存cookie
session = requests.Session()INDEX_URL = 'https://movie.douban.com/j/search_subjects?type=movie&tag={tag}&page_limit={page}' # 类型的url
DETAIL_URL = 'https://movie.douban.com/subject/{id}' # 详情的urlheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36','Referer': 'https://movie.douban.com/',
}# session设置某些全局请求头配置项目
session.headers = headers# 定义mongo链接
MONGO_URL = 'mongodb://localhost:27017'
MONGO_DB = 'douban_data'
COLLECTION_INDEX = 'douban_index'
COLLECTION_DETAIL = 'douban_detail'mongo = MongoClient(MONGO_URL) # 链接mongo
db = mongo[MONGO_DB] # 选择数据库
coll_index = db[COLLECTION_INDEX] # 首页的
coll_detail = db[COLLECTION_DETAIL] # 电影详情页的存储集合tags = None # 类型# 获取类型:https://movie.douban.com/j/search_tags?type=movie&source=index
def get_type():"""获取电影类型"""global tagsurl = 'https://movie.douban.com/j/search_tags?type=movie&source=index'response = session.get(url=url)tags = dict(response.json())['tags']logging.info('获取类型:%s' % tags)def spider_index(url):"""根据获取的类型挨个获取电影信息"""logging.info('开始获取:%s' % url)try:response_index = session.get(url=url)subjects = dict(response_index.json()).get('subjects')# logging.info('请求成功内容:%s' % subjects)time.sleep(2) # 模拟网络延迟for subject in subjects:# 写入mongodbcoll_index.insert_one(subject)except Exception as e:logging.error('请求出现异常!!!')if __name__ == '__main__':get_type()tasks = [INDEX_URL.format(tag=tag, page=250) for tag in tags]threads = [] # 创建线程列表for task in tasks:threads.append(threading.Thread(target=spider_index, args=(task,)))for thread in threads:thread.start()
相关文章:
爬取豆瓣(线程、Session)优化版本
爬取豆瓣(线程、Session)优化版本 该文章只是为了精进基础,对Session、threading、网站请求解析的理解。 此版本没有爬取详情页。还在学习阶段的读者可以尝试一下。 适用于基础刚开始学习爬虫的! 1.改进点: 将普通的r…...

拷贝控制总结
1.拷贝、值与销毁: 拷贝构造函数:如果一个构造函数的第一个参数是自身类类型的引用,且其他(如果有的话)参数都有默认实参,则此构造函数叫做拷贝构造函数;如果我们没有为类定义一个拷贝构造函数…...
无重复字符串的最长子串
题目描述:给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串的长度。 第一次提交记录 class Solution:def lengthOfLongestSubstring(self, s: str) -> int:if not s:return 0lookup set()left res 0for right in range(len(s)):while s…...
的用法)
javaScript Object.hasOwn()的用法
Object.hasOwn() 如果指定的对象自身有指定的属性,则静态方法 Object.hasOwn() 返回 true。如果属性是继承的或者不存在,该方法返回 false。 备注: Object.hasOwn() 旨在取代 Object.prototype.hasOwnProperty()。 **语法:**Objec…...

MINI2440 开发板 给他干出来了
环境是ubuntu14.04。不要问我为什么是这个版本,因为之前的ubuntu12.04 环境干不出来,你去试试就知道了!各种资源包下载不下来。 输入启动参数: 进入MINI2440:别说心里一万个开心,启动完成,输入p…...
上海人工智能实验室的书生·浦语大模型学习笔记(第二期第三课——上篇)
书生浦语是上海人工智能实验室和商汤科技联合研发的一款大模型,这次有机会参与试用,特记录每次学习情况。 一、课程笔记 本次学习的是RAG(Retrieval Augmented Generation)技术,它是通过检索与用户输入相关的信息片段…...
)
前端小白的学习之路(Vue2 三)
提示:学习vue2的第三天,笔记记录:生命周期,组件(注册,传值) 目录 一、生命周期 二、组件 1.注册组件 1)全局注册 2)局部注册 2.组件传值 1)父传子 2)子传父 3)兄弟传值 一…...

ChatGPT 之优势与缺陷
原文: 译者:飞龙 协议:CC BY-NC-SA 4.0 介绍 欢迎来到《ChatGPT:好的、坏的和丑陋的》。在本书中,我们踏上了探索 ChatGPT 多面世界的旅程,这是由 OpenAI 开发的先进自然语言处理模型。随着 ChatGPT 和类似…...
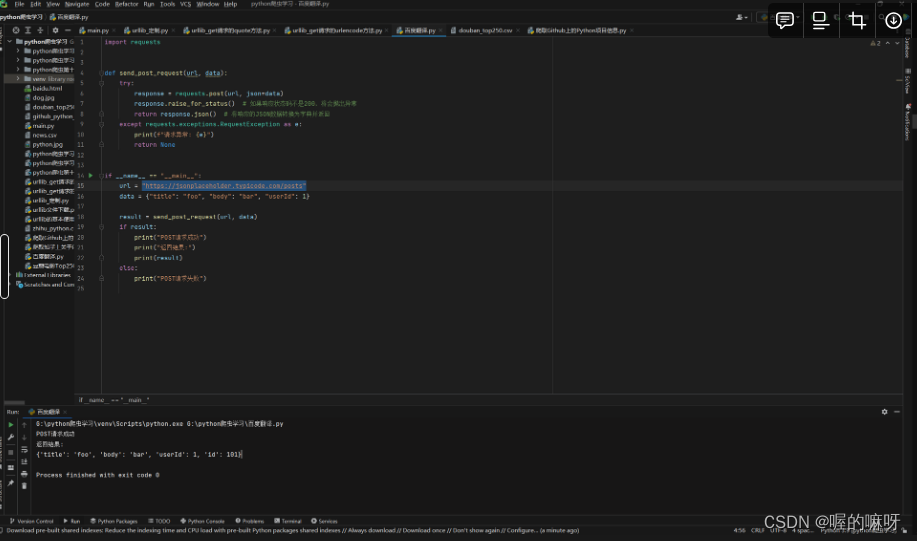
python爬虫———post请求方式(第十四天)
🎈🎈作者主页: 喔的嘛呀🎈🎈 🎈🎈所属专栏:python爬虫学习🎈🎈 ✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天…...

51蓝桥杯之DS18B20
DS18B20 基础知识 代码流程实现 将官方提供例程文件添加到工程中 添加onewire.c文件到keil4里面 一些代码补充知识 代码 #include "reg52.h" #include "onewire.h" #include "absacc.h" unsigned char num[10]{0xc0,0xf9,0xa4,0xb0,0x99,…...
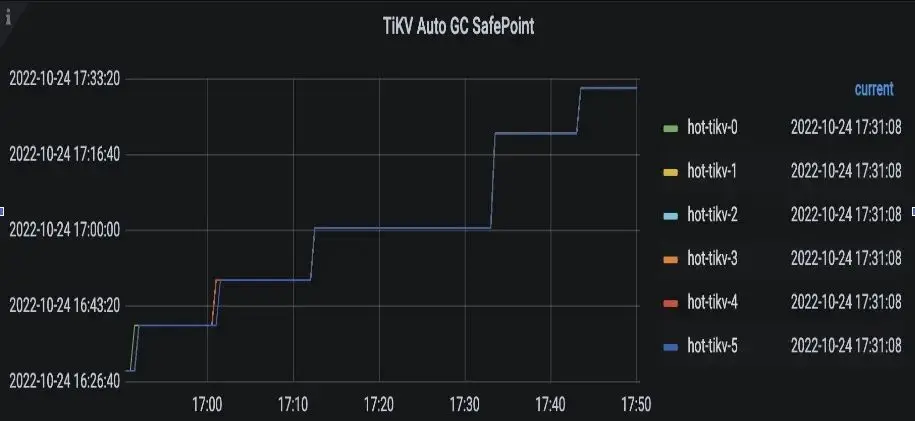
TiDB 组件 GC 原理及常见问题
本文详细介绍了 TiDB 的 Garbage Collection(GC)机制及其在 TiDB 组件中的实现原理和常见问题排查方法。 TiDB 底层使用单机存储引擎 RocksDB,并通过 MVCC 机制,基于 RocksDB 实现了分布式存储引擎 TiKV,以支持高可用分…...
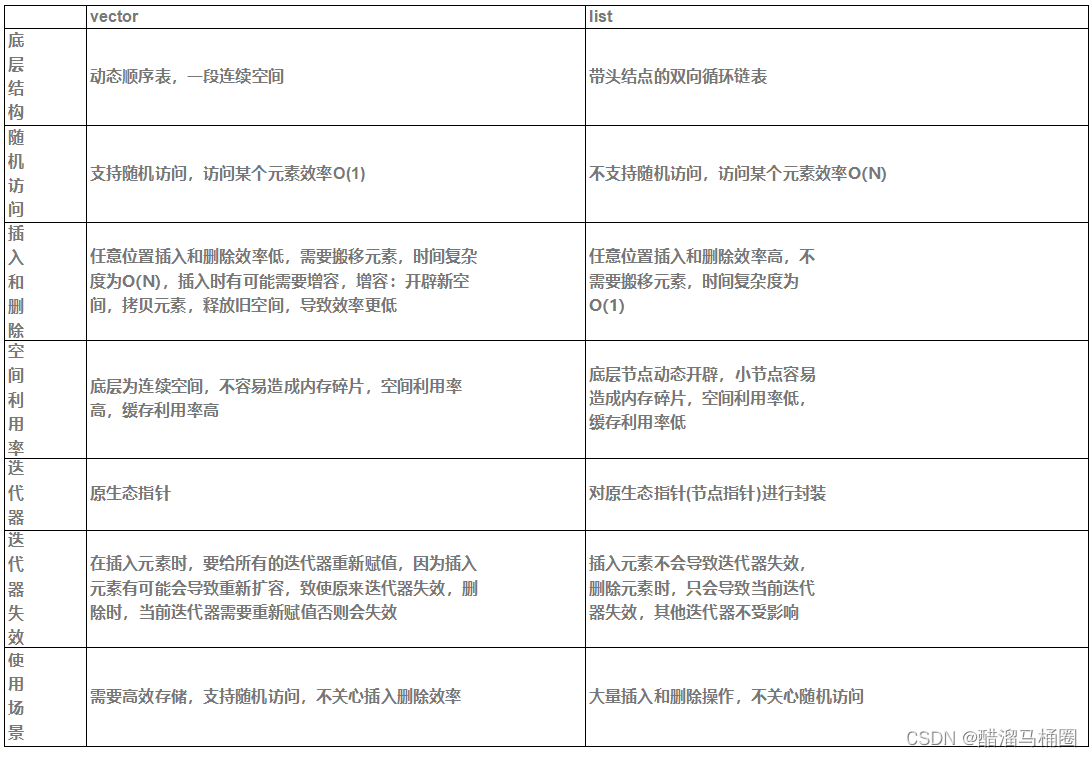
【c++】STl-list使用list模拟实现
主页:醋溜马桶圈-CSDN博客 专栏:c_醋溜马桶圈的博客-CSDN博客 gitee:mnxcc (mnxcc) - Gitee.com 目录 1. list的介绍及使用 1.1 list的介绍 1.2 list的使用 1.2.1 list的构造 1.2.2 list iterator的使用 1.2.3 list capacity 1.2.4 …...

号卡极团分销管理系统 index.php SQL注入漏洞复现
0x01 产品简介 号卡极团分销管理系统,同步对接多平台,同步订单信息,支持敢探号一键上架,首页多套UI+商品下单页多套模板,订单查询支持实时物流信息、支持代理商自定义域名、泛域名绑定,内置敢探号、172平台、号氪云平台第三方接口以及号卡网同系统对接! 0x02 漏洞概述…...
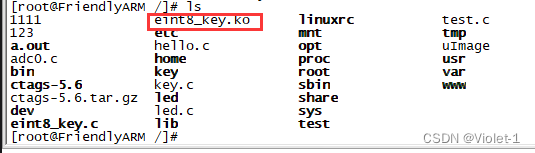
内核驱动更新
1.声明我们是开源的 .c 文件末尾加上 2.在Kconfig里面修改设备,bool(双态)-----》tristate(三态) 3.进入menuconfig修改为M 4.编译内核 make modules 也许你会看到一个 .ko 文件 5.复制到根目录文件下 在板子…...
故障诊断 | 一文解决,PLS偏最小二乘法的故障诊断(Matlab)
效果一览 文章概述 故障诊断 | 一文解决,PLS偏最小二乘法的故障诊断(Matlab) 模型描述 偏最小二乘法(Partial Least Squares, PLS)是一种统计建模方法,用于建立变量之间的线性关系模型。它是对多元线性回归方法的扩展,特别适用于处理高维数据和具有多重共线性的数据集。…...

我为什么选择成为程序员?
前言: 我选择成为程序员不是兴趣所在,也不是为了职业发展,全是生活所迫! 第一章:那年,我双手插兜,对外面的世界一无所知 时间回到2009年,时间过得真快啊,一下就是15年前…...

Open CASCADE学习|统计形状拓扑数量
边界表示法(Boundary Representation,简称B-Rep)是几何造型中最成熟、无二义的表示法。它主要用于描述物体的几何信息和拓扑信息。在边界表示法中,一个实体(Solid)由一组封闭的面(Faceÿ…...

LeetCode 热题 100 题解(二):双指针部分(2)| 滑动窗口部分(1)
题目四:接雨水(No. 43) 题目链接:https://leetcode.cn/problems/trapping-rain-water/description/?envTypestudy-plan-v2&envIdtop-100-liked 难度:困难 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图&am…...

常用的深度学习自动标注软件
0. 简介 自动标注软件是一个非常节省人力资源的操作,而随着深度学习的发展,这些自动化标定软件也越来越多。本文章将会着重介绍其中比较经典的自动标注软件 1. AutoLabelImg AutoLabelImg 除了labelimg的初始功能外,额外包含十多种辅助标注…...

选择程序员是为什么?
本章节是关于为什么会选择一名程序员的经验分享 首先,我为什么会选择这个方向,可能是因为钱多,学东西不就是为了赚钱嘛?这是一点,不过最让我接收这个行业的是好奇世界的新大陆,可以简单的说就是,…...
)
WebLogic T3协议漏洞实战:5分钟搞定ConnectionFilterImpl配置(附常见问题排查)
WebLogic T3协议安全加固实战:ConnectionFilterImpl配置与深度防御指南 1. 漏洞背景与防御必要性 WebLogic作为企业级Java应用服务器,其专有的T3协议长期存在反序列化漏洞风险。攻击者通过构造恶意T3协议数据包,可在未授权情况下实现远程代码…...

Phi-4-mini-reasoning应用场景:密码学协议安全性逻辑推演与攻击路径模拟
Phi-4-mini-reasoning应用场景:密码学协议安全性逻辑推演与攻击路径模拟 1. 模型概述 Phi-4-mini-reasoning是由微软开发的3.8B参数轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。该模型主打"小参数、强推理、长上下文、低延…...

nfc-list使用教程
nfc-list 是 Kali Linux 中基于 libnfc 库(开源 NFC 开发框架)的基础 NFC/RFID 设备检测工具,核心功能是扫描并列出当前连接的 NFC 读卡器设备,以及贴近读卡器的 NFC 卡片(或标签)的详细信息,包…...

别只盯着Web日志!一次Windows服务器被黑,我是这样用系统日志和FTP记录挖出攻击链的
从Windows系统日志到FTP记录:一次完整的服务器入侵溯源实战 深夜的应急响应中心,刺眼的告警提示打破了宁静。大多数安全工程师的第一反应是打开Web访问日志开始排查——这几乎成了行业条件反射。但真实攻击往往发生在你最意想不到的角落。上周处理的一起…...

手把手教你搭建基于Matlab/Simulink的插电式混合动力汽车4驱PHEV模型
基于Matlab/simulink的插电式混合动力汽车建模仿真模型4驱PHEV(比亚迪唐DM混动系统P2P4发动机——三擎四驱),包括整车HCU控制单元、发动机模型、驱动电机模型、ISG电机模型、AMT5档自动变速箱模型、驾驶员模型、电池能量管理控制模型等&#…...

终极指南:深度解析ExplorerBlurMica如何用3大核心技术重塑Windows文件资源管理器透明美化体验
终极指南:深度解析ExplorerBlurMica如何用3大核心技术重塑Windows文件资源管理器透明美化体验 【免费下载链接】ExplorerBlurMica Add background Blur effect or Acrylic (Mica for win11) effect to explorer for win10 and win11 项目地址: https://gitcode.co…...

Windows下Pytesseract报错‘Error opening data file’?三步搞定TESSDATA_PREFIX环境变量配置
Windows下Pytesseract报错终极解决方案:深入理解TESSDATA_PREFIX环境变量 每次看到屏幕上跳出那个令人沮丧的"Error opening data file"错误提示,我都忍不住想起自己第一次配置Pytesseract时的抓狂经历。作为一个长期与OCR打交道的开发者&…...

Spring Batch 大数据量处理实战:从入门到精通
Spring Batch 大数据量处理实战:从入门到精通别叫我大神,叫我 Alex 就好。处理百万级数据不用愁,Spring Batch 让批处理变得优雅而高效。一、Spring Batch 基础架构 1.1 核心配置 Configuration EnableBatchProcessing public class BatchCon…...

TresJS实战指南:Vue 3D场景开发从入门到精通
1. TresJS基础入门:从零搭建3D场景 第一次接触TresJS时,我完全被它的简洁性震惊了。作为一个基于Three.js的Vue组件库,它让3D开发变得像写普通Vue组件一样自然。先来看个最简单的例子: <template><TresCanvas><Tre…...

BiliBili-UWP:打造Windows平台高效B站观影体验深度指南
BiliBili-UWP:打造Windows平台高效B站观影体验深度指南 【免费下载链接】BiliBili-UWP BiliBili的UWP客户端,当然,是第三方的了 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBili-UWP BiliBili-UWP作为一款专为Windows平台设计的…...