GPT中的Transformer架构以及Transformer 中的注意力机制
目录
1 GPT中的Transformer架构
2 transformer中的注意力机制
参考文献:
看了两个比较好的视频,简单做了下笔记。
1 GPT中的Transformer架构
GPT是Generative Pre-trained Transformer单词的缩写,其中transformer是一种特定的神经网络,这里的单词是transformer不是transform.
当聊天机器人生成某个特定词汇时,首先输入内容会被拆分成许多小片段,





如果把这些向量看作是在一个高维空间中的坐标,那么含义相似的词汇倾向于彼此接近的向量上,

这些向量接下来会经过一个称为注意力块的处理过程,使得向量能够相互交流,


注意力模块的作用就是要确定上下文中哪些词对更新其他词的意义有关,以及应该如何准确地更新这些含义。

词语的所谓含义完全通过向量中的数字来表达。然后这些向量会经过另一种处理,这个过程根据资料的不同,可能被称作多层感知机或者前馈层,这个阶段向量不在互相交流,而是并行地经历同一处理。
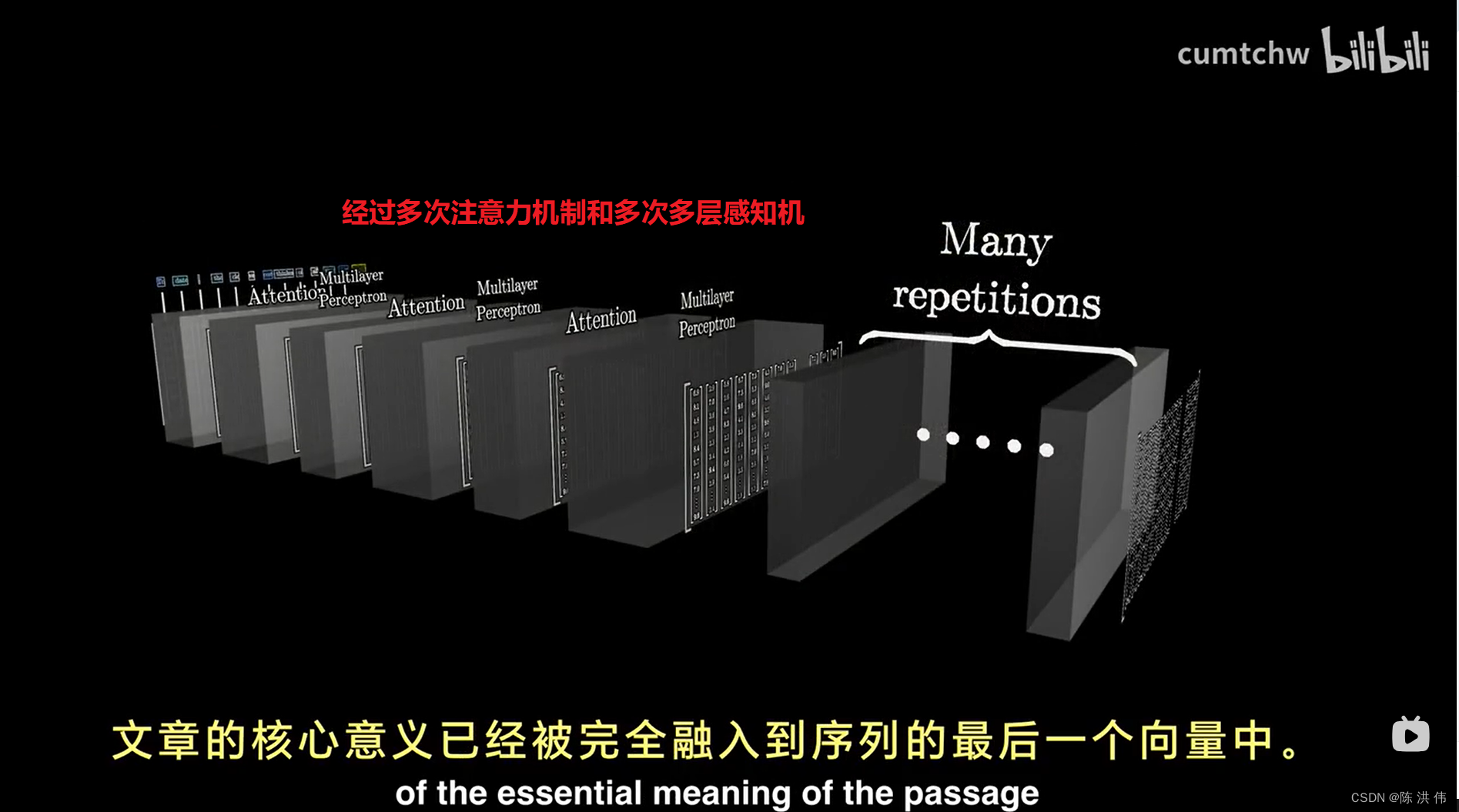
然后对这最后一个向量进行特定操作,产生一个覆盖所有可能token的概率分布,

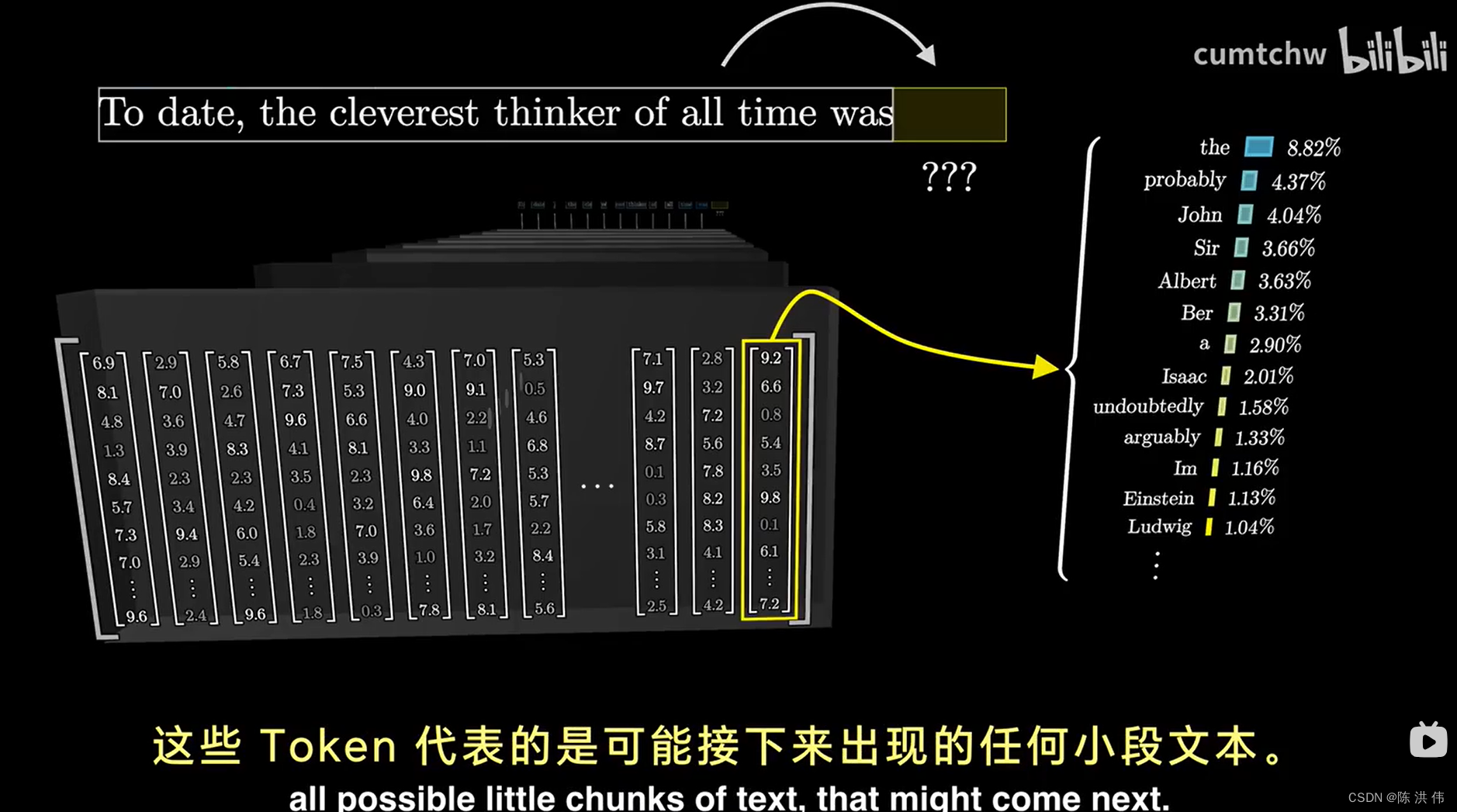
然后它就可以根据一小段文本预测下一步,给他一段初始文本,然后让他不断地进行预测下一步, 从概率分布中抽样,添加到现有文本, 然后不断地重复这个过程,就能生成一段文本。
将上面的工具转化为聊天机器人的一个简单方法就是准备一段文本,设定出用户与一个有帮助的AI助手交互的场景,这就是所谓的系统提示。
文本处理示例第一步:将输入分割成小片段,并将这些片段转换成向量。
模型拥有一个预设的词汇库,包含所有可能的单词,输入首先遇到一个矩阵叫做embedding嵌入矩阵,他为每个单词都分配了一个独立的列
这些列定义了第一部中每个单词转换成的向量。

这些嵌入空间中的向量,不仅仅代表着单个单词,他们还携带了词汇位置的信息,这些词汇能吸纳并反映语境。
2 transformer中的注意力机制
前面说过每个tokens都是一个嵌入向量,在所有可能得嵌入向量所构成的高维空间中, 不同的方向能够代表不同的语义含义 (比如有的方向对应着性别,即在这个空间中添加一定的变化可以从一个男性名词的嵌入转到对应的女性名词的嵌入)
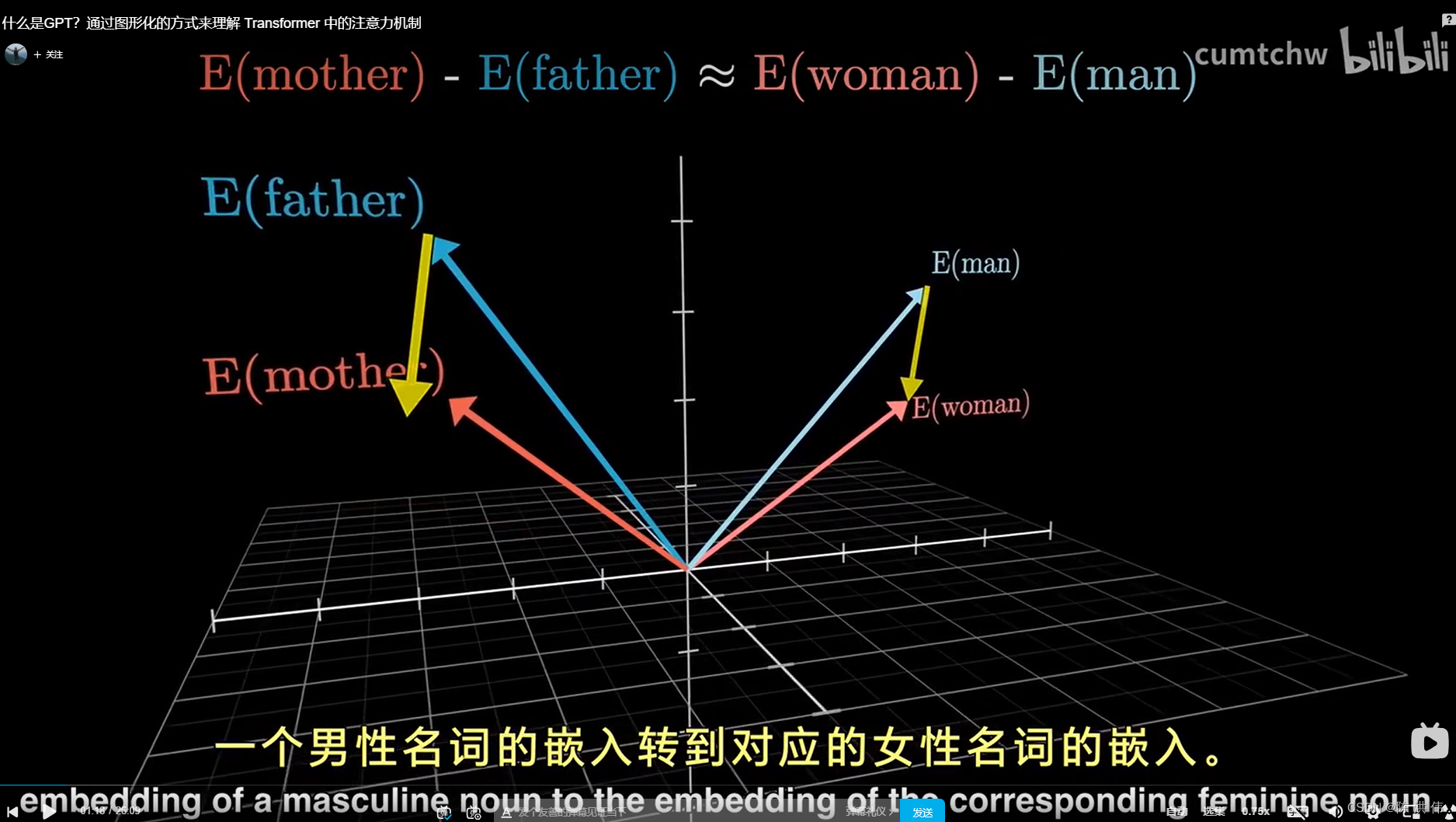
在这样一个复杂的空间中,有无数的方向, 每一个都可能代表词义的不同方面。
transformer的目标就是逐步调整这些嵌入,使他不仅仅编码单词本身,而是包含更丰富、更深层次的上下文含义。

但是,在transformer的第一步中,文本被拆分,每个token都被关联到一个向量,

因为初始的token嵌入向量,本质上是一个不参考上下文的查找表,直到transformer的下一步,周围的嵌入向量才有机会向这个token传递信息,
注意力模块不仅可以精确一个词的含义,还能将一个嵌入向量中的信息传递到另一个嵌入向量中,
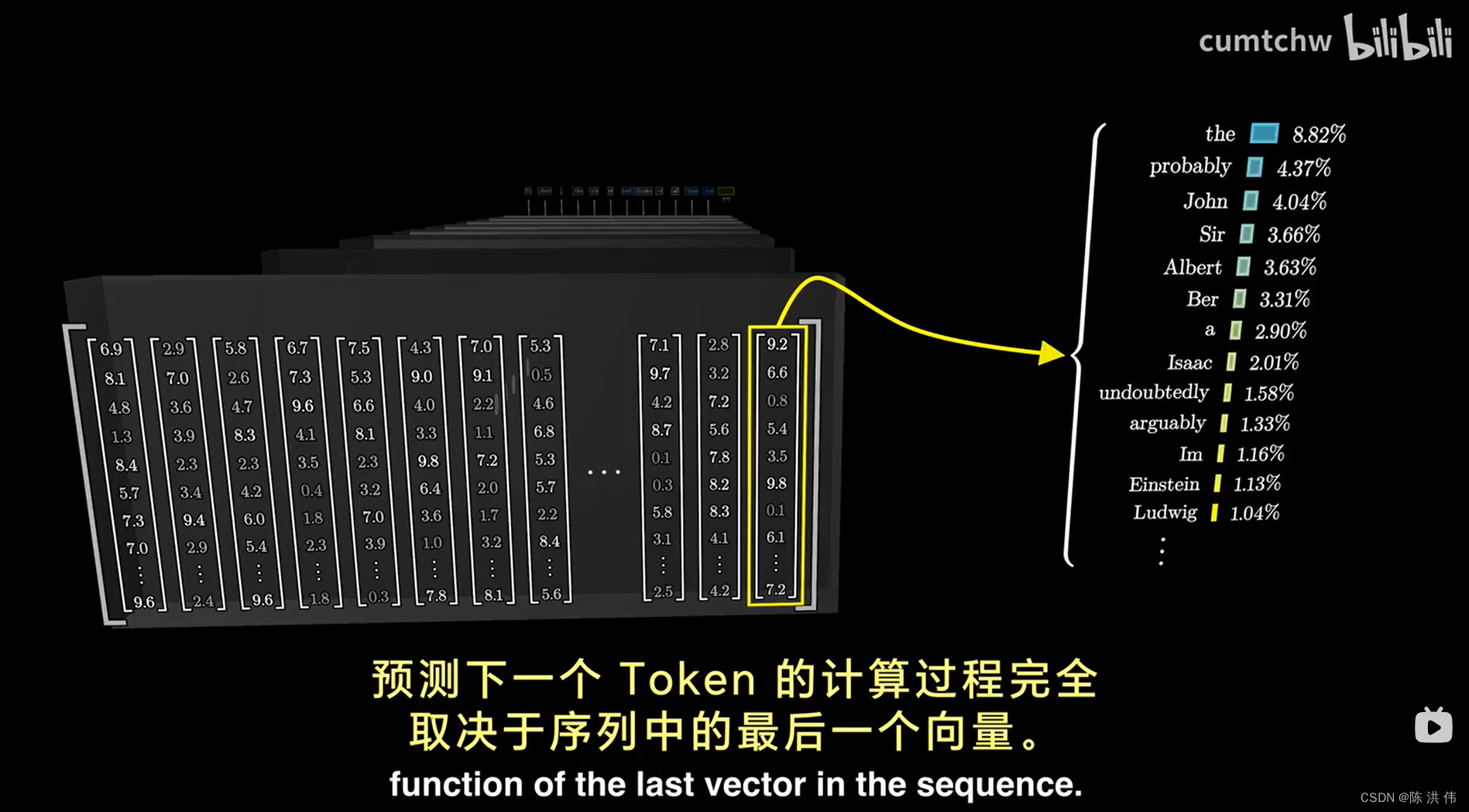
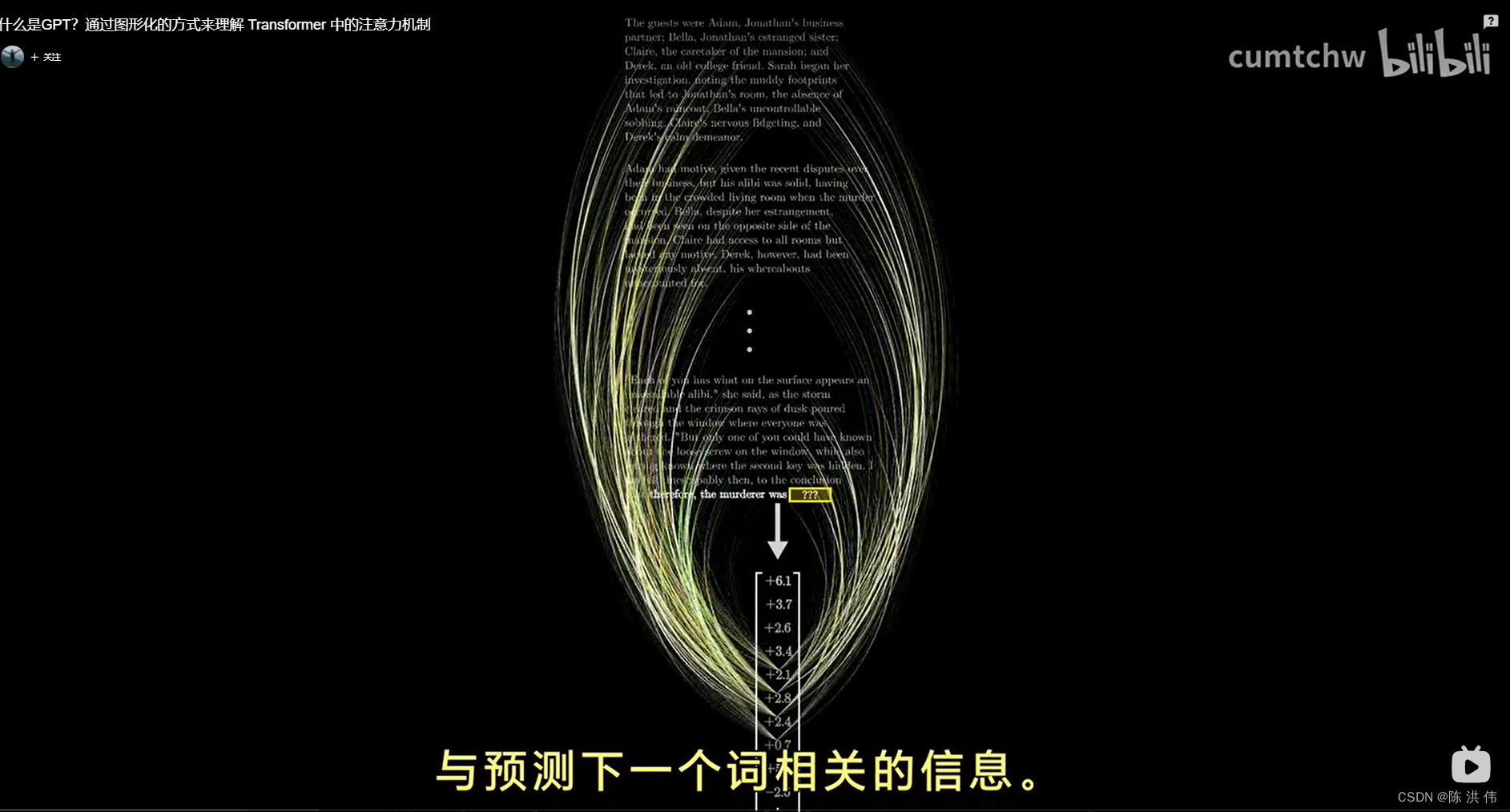
例如,你输入的文字是一整部悬疑小说,到了接近尾声的部分,写着“所以,凶手是”,如果模型要准确地预测下一个词语,那么这个序列中的最后一个向量,他最初只是嵌入了单词“是”,它必须经过所有的注意力模块的更新,以包含远超过任何单个单词的信息,通过某种方式编码了所有来自完整的上下文窗口中与预测下一个词相关的信息。
举一个简单的例子,假设输入一个句子

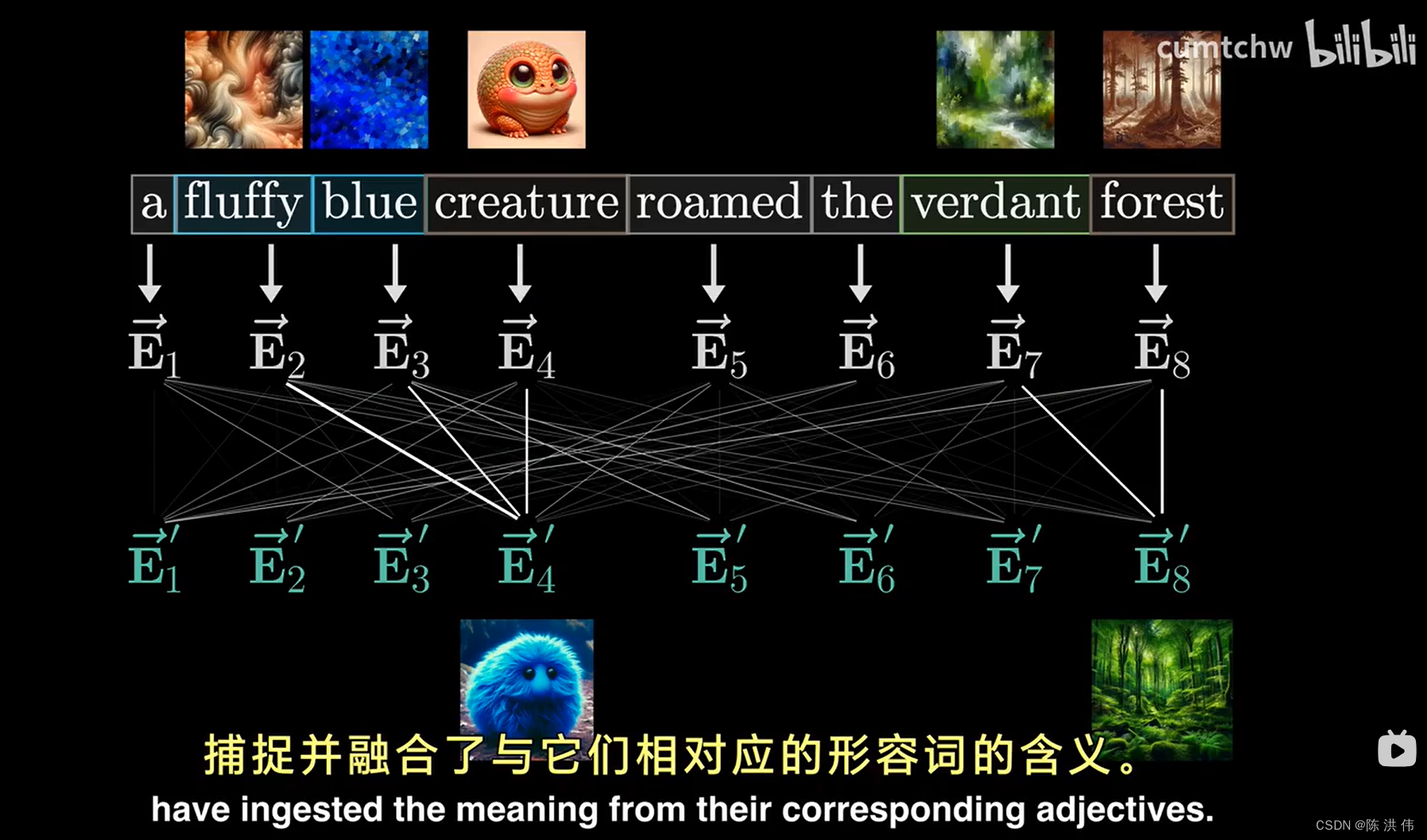
假设我们现在关注的只是让形容词调整其对应名词的含义这种更新方式。


每个词的初始嵌入向量是一个高维向量,只编码了该特定词的含义以及词的位置,不包含任何上下文,

我们用字母E来表示这些嵌入向量,我们的目标是,通过一系列计算,产生一组新的、更为精细的嵌入向量,这样做可以让名词的嵌入向量捕捉并融合了与他们相对应的形容词的含义。

其中的矩阵充满了可调节的权重,模型将根据数据来学习这些权重,
在这个过程的第一步,你可以想象每个名词,比如“生物”,都在问,有没有形容词在我前面,对于“毛茸茸的”和“蓝色的”这两个词,都会回答,我是一个形容词,我就在那个位置,这个问题会被编码成另一个向量,也就是一组数字,我们称之为这个词的查询向量,

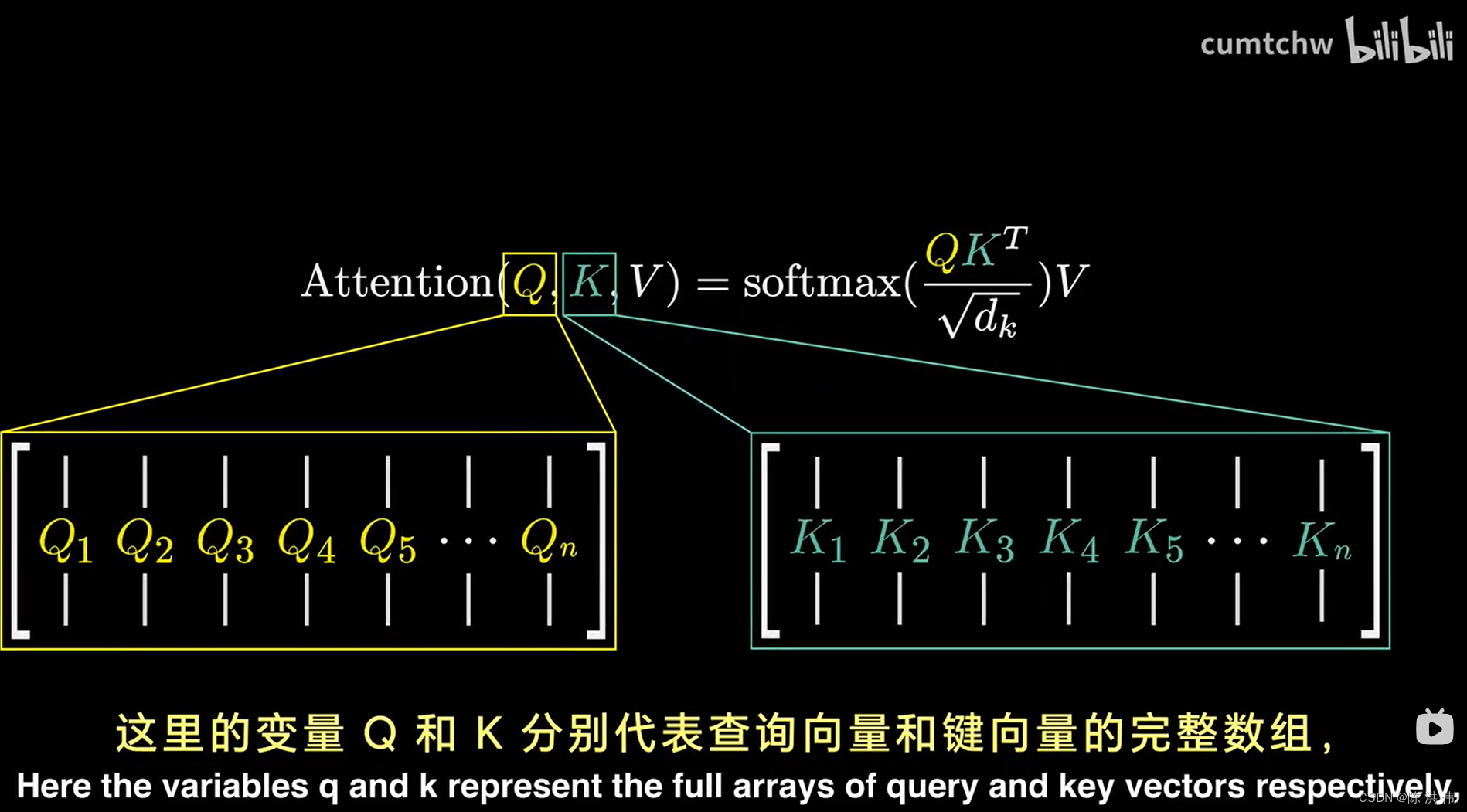
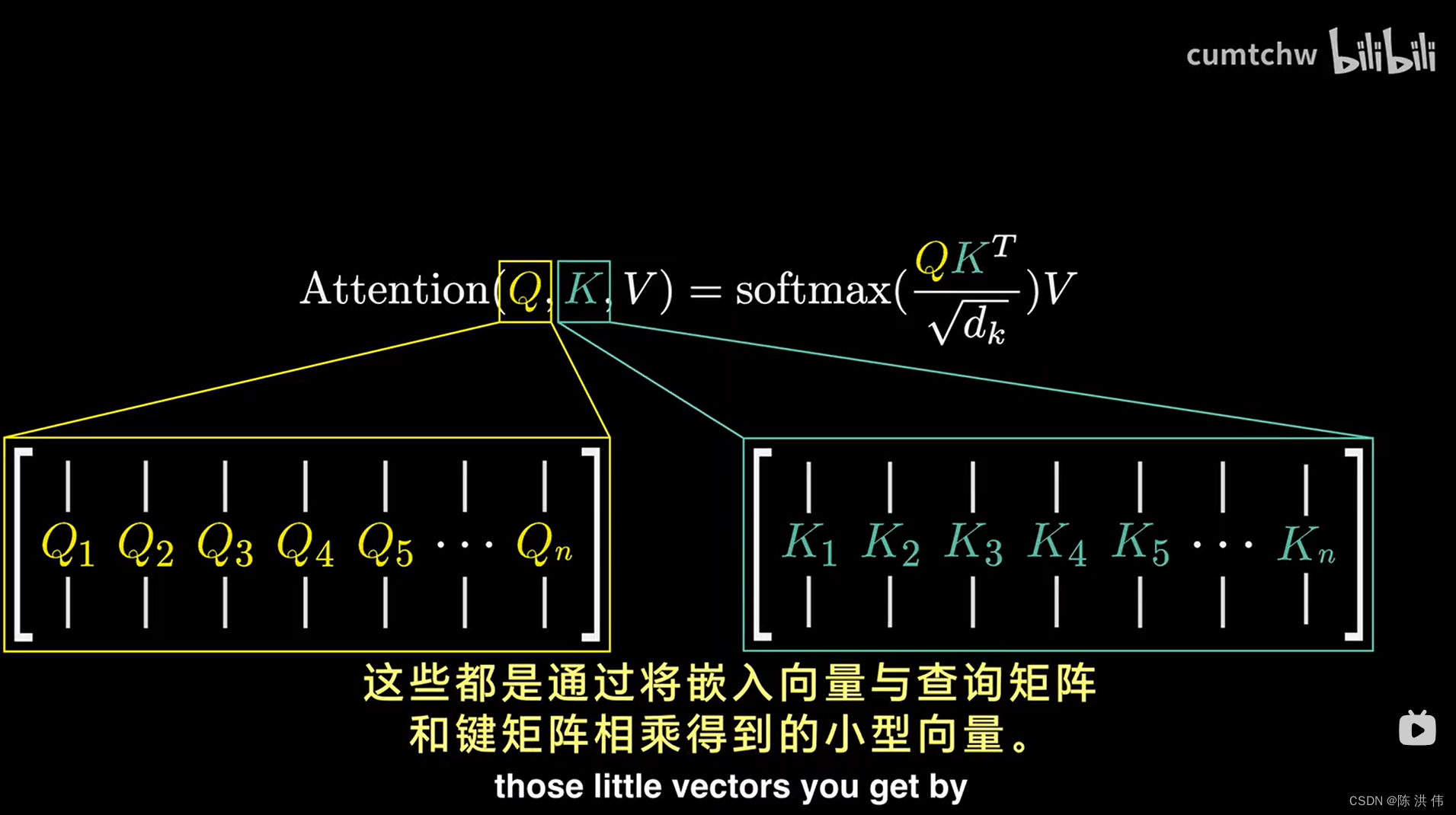
计算这个查询就是取一个特定的矩阵,也就是WQ,并将其与嵌入向量相乘,简化一下,我们把查询向量记作Q,
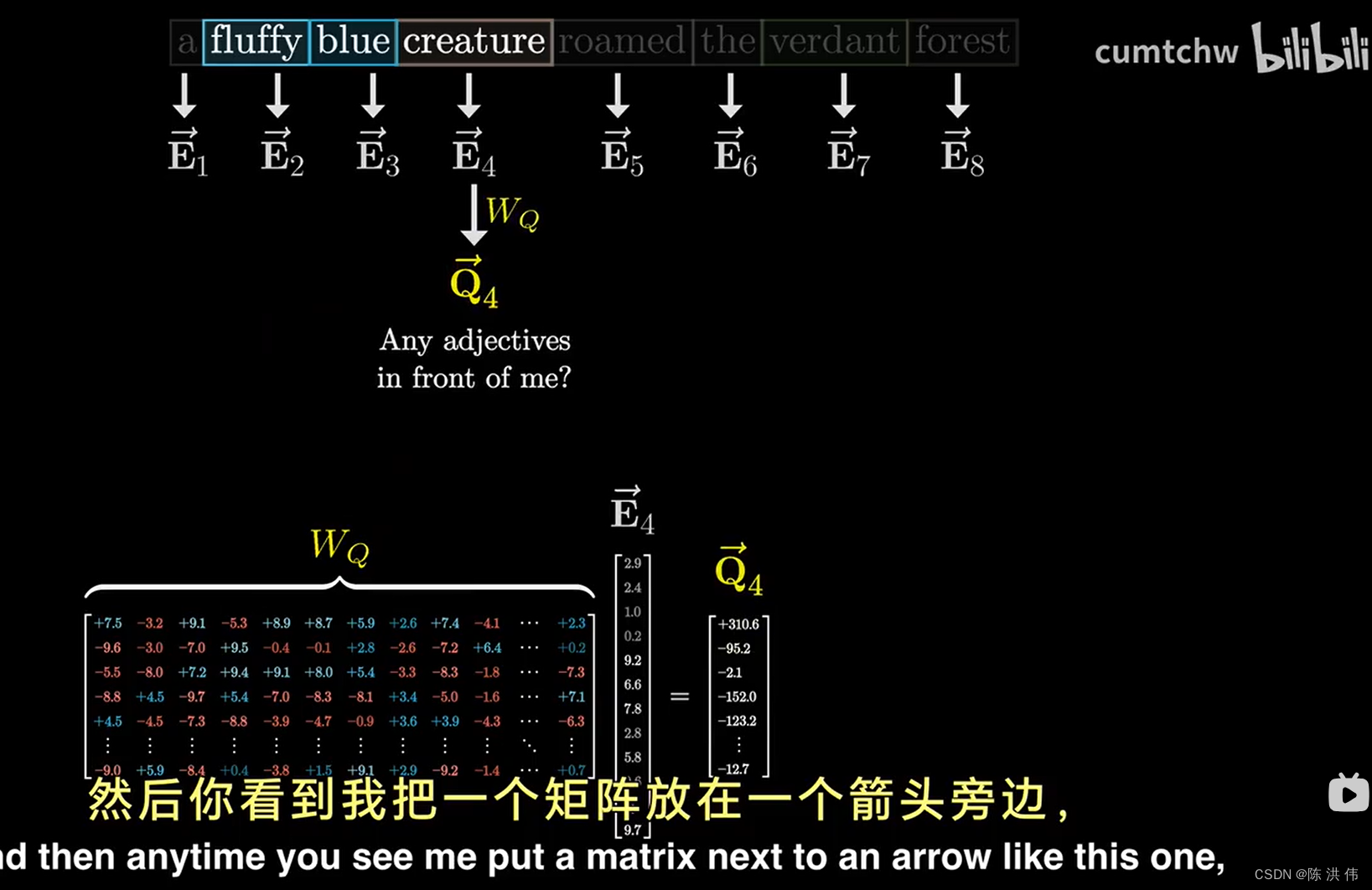
这里E和WQ相乘得到查询向量Q,在这种情况下,你将这个矩阵WQ和上下文中的所有嵌入向量相乘,得到的是每个token对应的一个查询向量,这个矩阵WQ由模型的参数组成,意味着它能从数据中学习到真实的行为模式。 在实际应用中,这个矩阵在特定注意力机制中的具体作用是相当复杂的, 理想的情况是,我们希望这个查询矩阵能将名词的嵌入信息映射到一个较小空间的特定方向上,

这种映射方式能够捕捉到一种特殊的寻找前置形容词的规律,
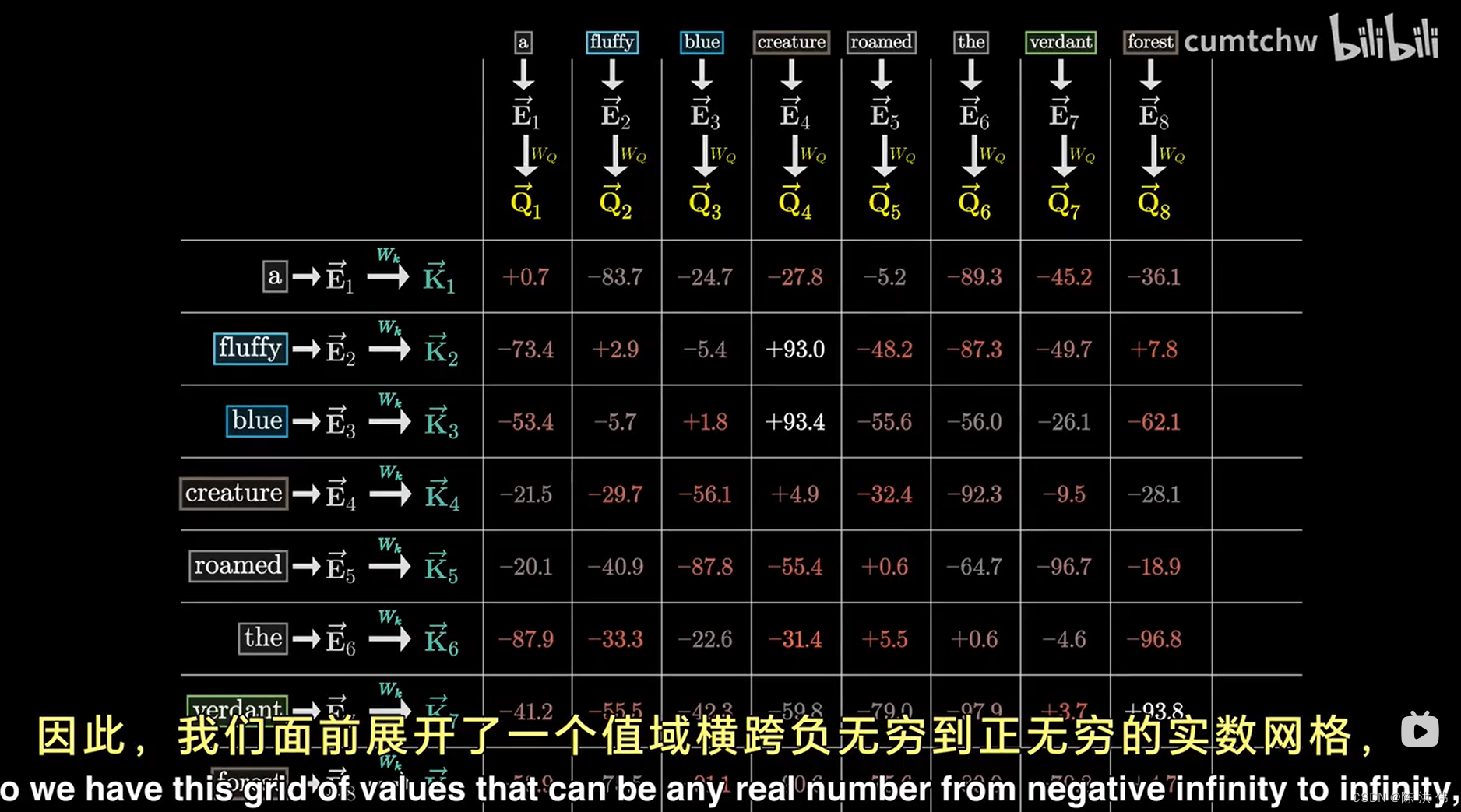
然后还有另一个被称之为键矩阵的矩阵,同时需要与所有嵌入向量相乘,这会生成一个我们称之为键的向量序列,从概念上讲,可以把键想象成是潜在的查询回答者,

这个键矩阵也冲忙了可调整的参数,同查询矩阵一样,将嵌入向量映射到同一个较小的维度空间中,当键与查询密切对齐时,你可以将键视为与查询相匹配,

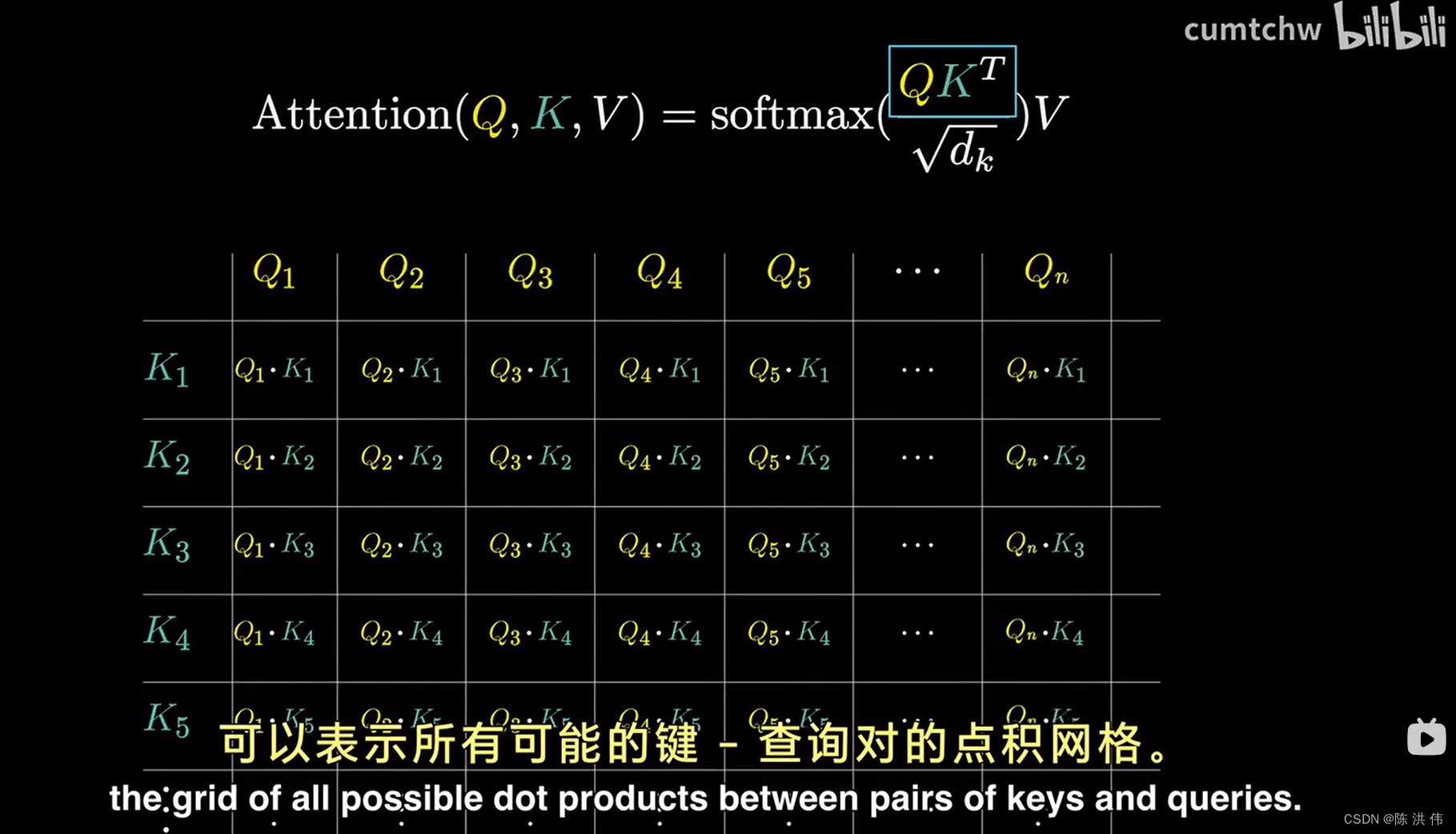
为了衡量每个键和每个查询的匹配程度,你需要计算每一对可能的键-查询组合之间的点积,我们可以将其想象为一个充满各种点的网络,其中较大的点对应着较大的点积, 即键与查询对齐的地方,就我们讨论的形容词与名词的例子而言,如果毛茸茸的和蓝色的生成的键确实与生物产生的查询非常吻合,那么这两个点的点积会是一些较大的正数,

相比之下,像the这样的词语的键,与生物的查询之间的点积会是一些较小或者负数,这反映出他们之间没有关联,
这个网格赋予了我们评估每个单词在更新其他单词含义上的相关性得分的能力,接下来我们将利用这些分数,执行一种操作:按照每个词的相关重要性,沿着每一列计算加权平均值,因此我们的目标不是让这些数据列的数值范围无线扩展,从负无穷到正无穷,相反,我们希望这些数据列中的每个数值都介于0和1之间。并且每列的数值总和为1,正如他们构成一个概率分布那样,这就需要做softmax操作,softmax之后如下
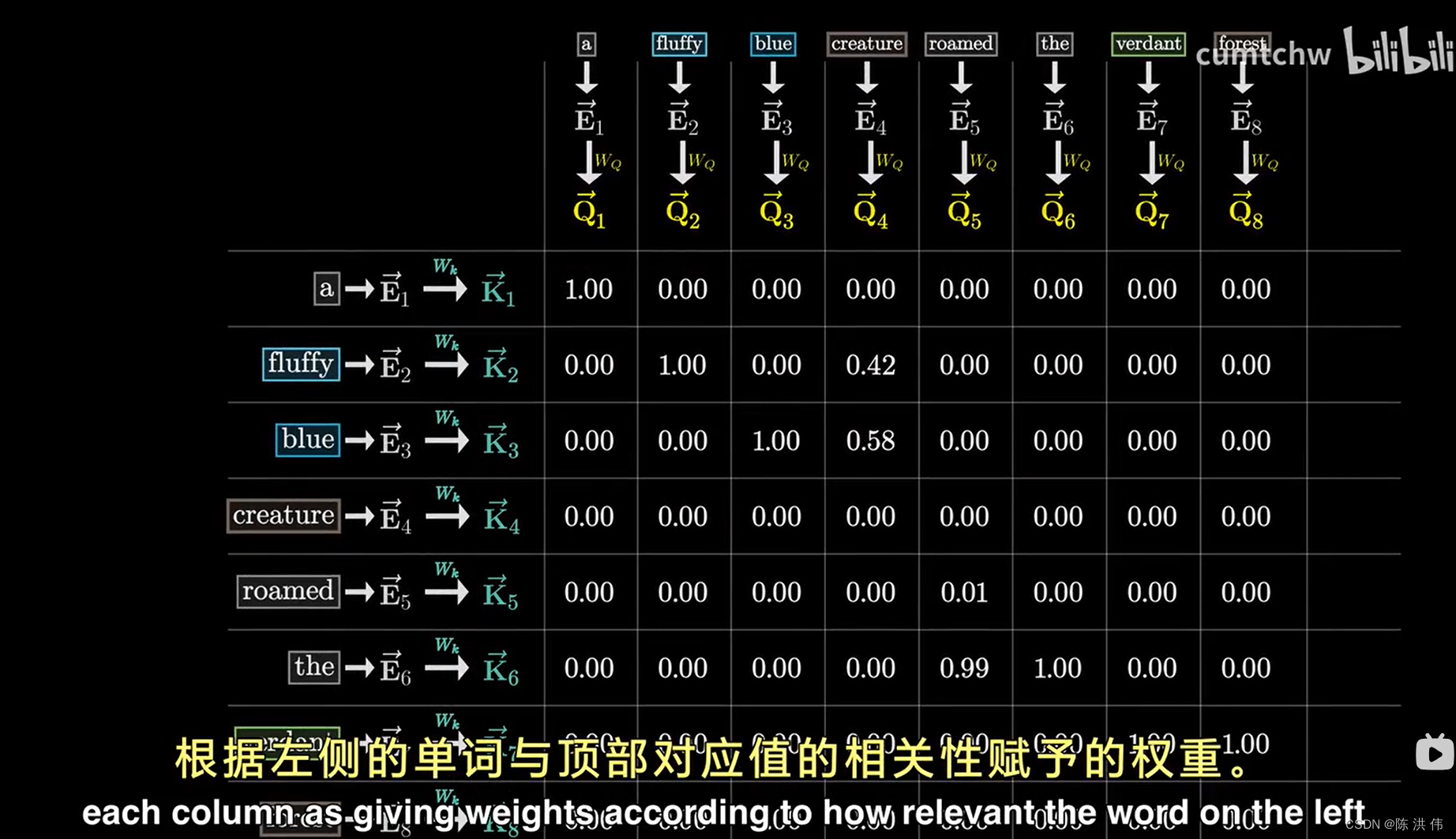
我们将这种网格称为 注意力模式。
在transformer的原始论文里面,
在这个公式中,还有个dk,为了数值稳定性,这里将所有这些值除以键-查询空间维度的平方根,
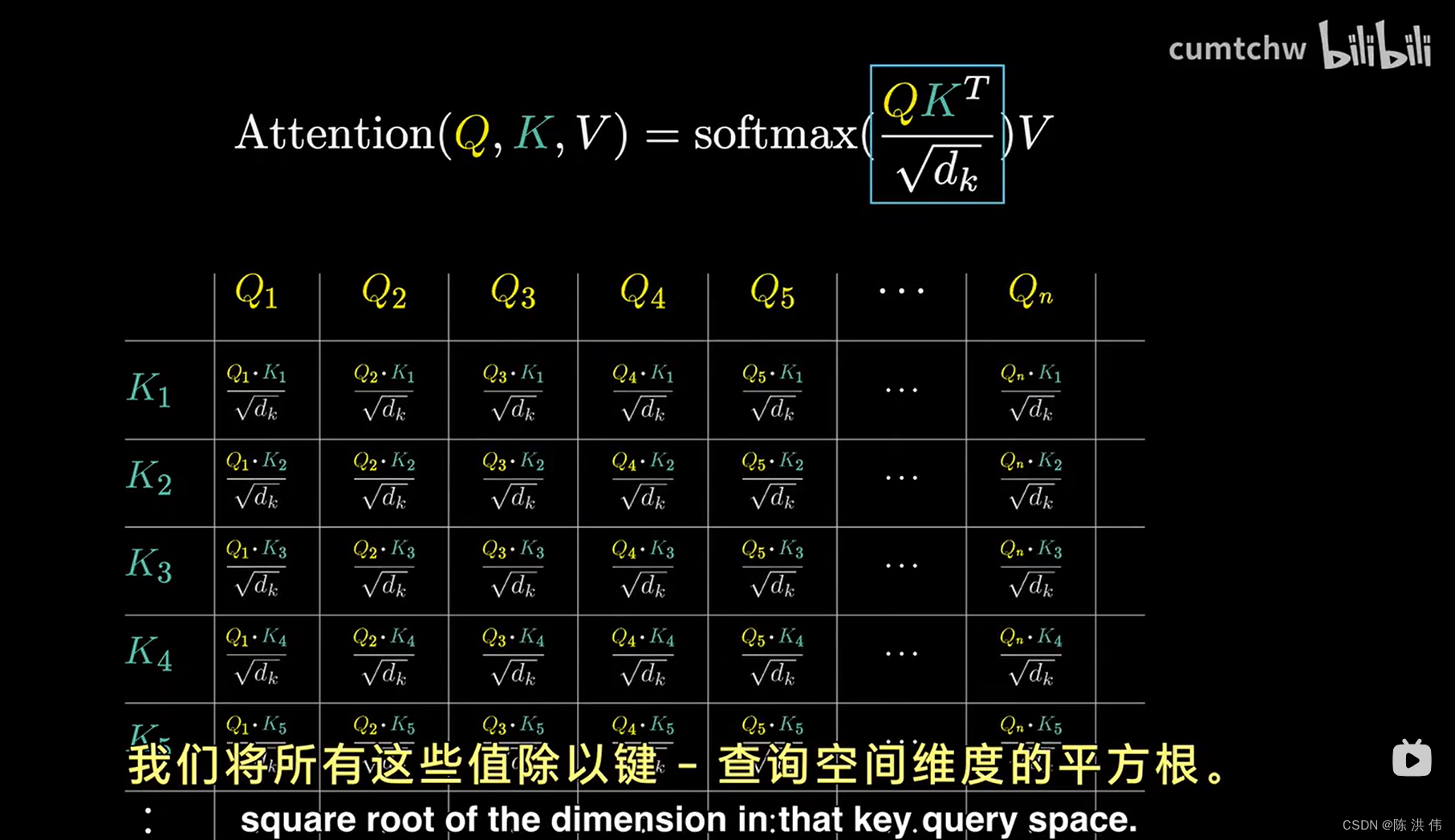
然后包含所有算式的softmax函数我们应理解为是按列应用的,然后公式中还有大写V,后面再讲。
之前没有提到一个技术细节,在训练过程中,对给定样本进行处理时,模型会通过调整权重来奖励或惩罚预测的准确性,即根据模型对文中下一个词的预测概率的高低,有种做法能显著提高整个训练过程的效率,那就是同时让模型预测, 该段落中每个初始token子序列之后所有可能出现得下一个token,

这样一来,一个训练样本就能提供更多的学习机会,在设计注意力模式时,一个基本原则是不允许后出现得词汇影响先出现得词汇,如果不这么做,后面出现得词汇可能会提前泄露接下来内容的线索,这就要求我们在模型中设置一种机制,确保代表后续token对前面token的影响力能够被有效削弱到0,直觉上我们可能会考虑直接将这些影响力设置为0,但这样做会导致一个问题,那些影响力值的列加和不再是1,也就失去了标准化的效果,为了解决这个问题,一个常见的做法是在进行softmax归一化操作之前将这些影响力值设置为负无穷大。这样,干净过softmax处理后,这些位置的数值会变成0,同时保证了整体的归一化条件不被破坏,这就是所谓的掩蔽过程,
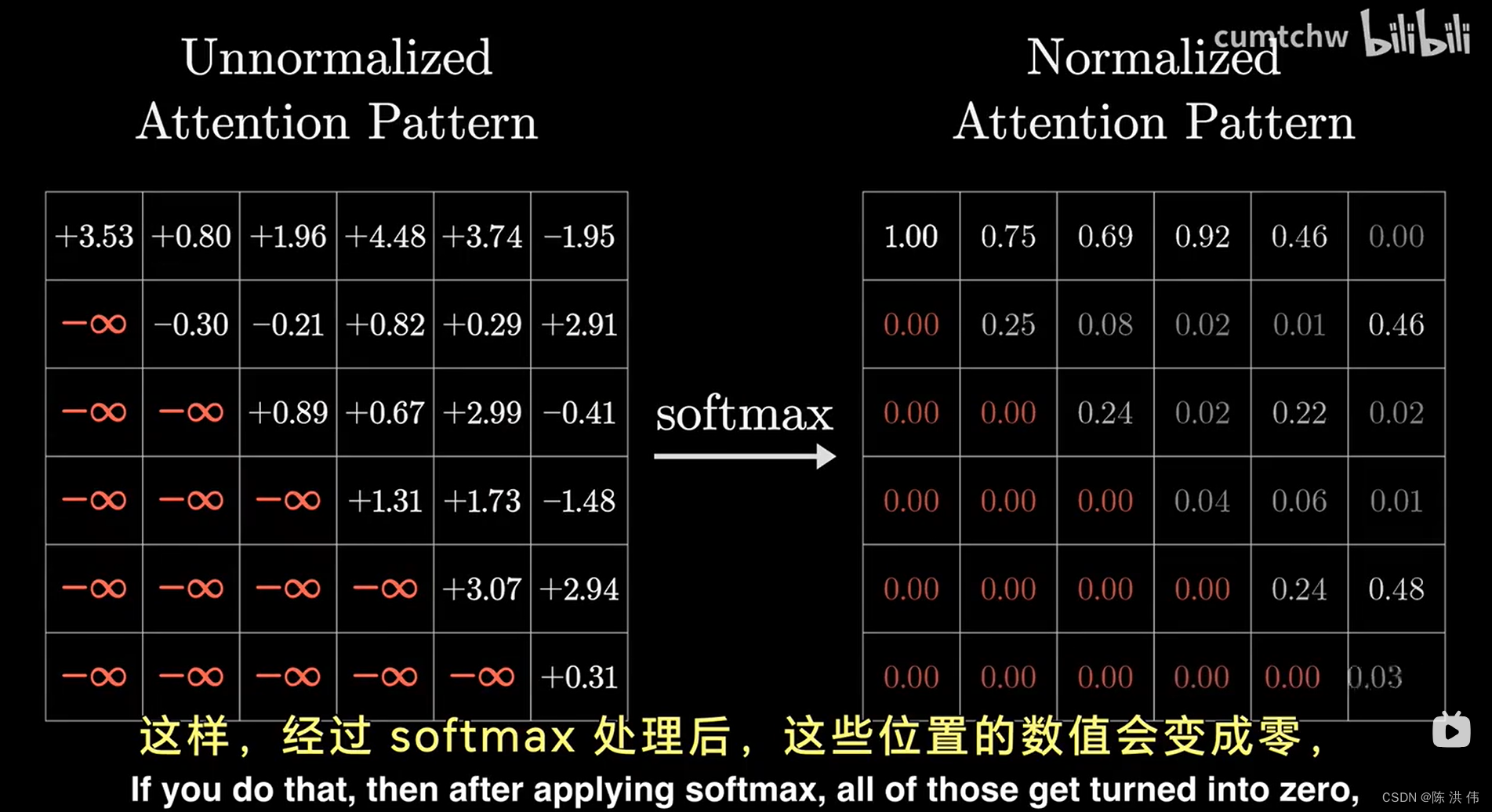
注意力模式的大小等于上下文大小的平方,这就解释了上下文大小可能会对大语言模型构成巨大瓶颈,

通过前面的计算,模型能够推断哪些词与其他词相关,然后就需要实际更新嵌入向量,让词语可以将信息传递给他们相关的其他词,比如说,你希望毛茸茸的嵌入向量能够使得生物发生改变,从而将它移动到这个12000维嵌入空间的另一部分,以更具体地表达一个毛茸茸的生物,

我首先向你展示的事执行这个操作的最简单方法,这个方法的核心是使用一个第三个矩阵,也就是我们所说的值矩阵Wv,你需要将它与某个单词的嵌入相乘,得到的结果我们称为值向量,
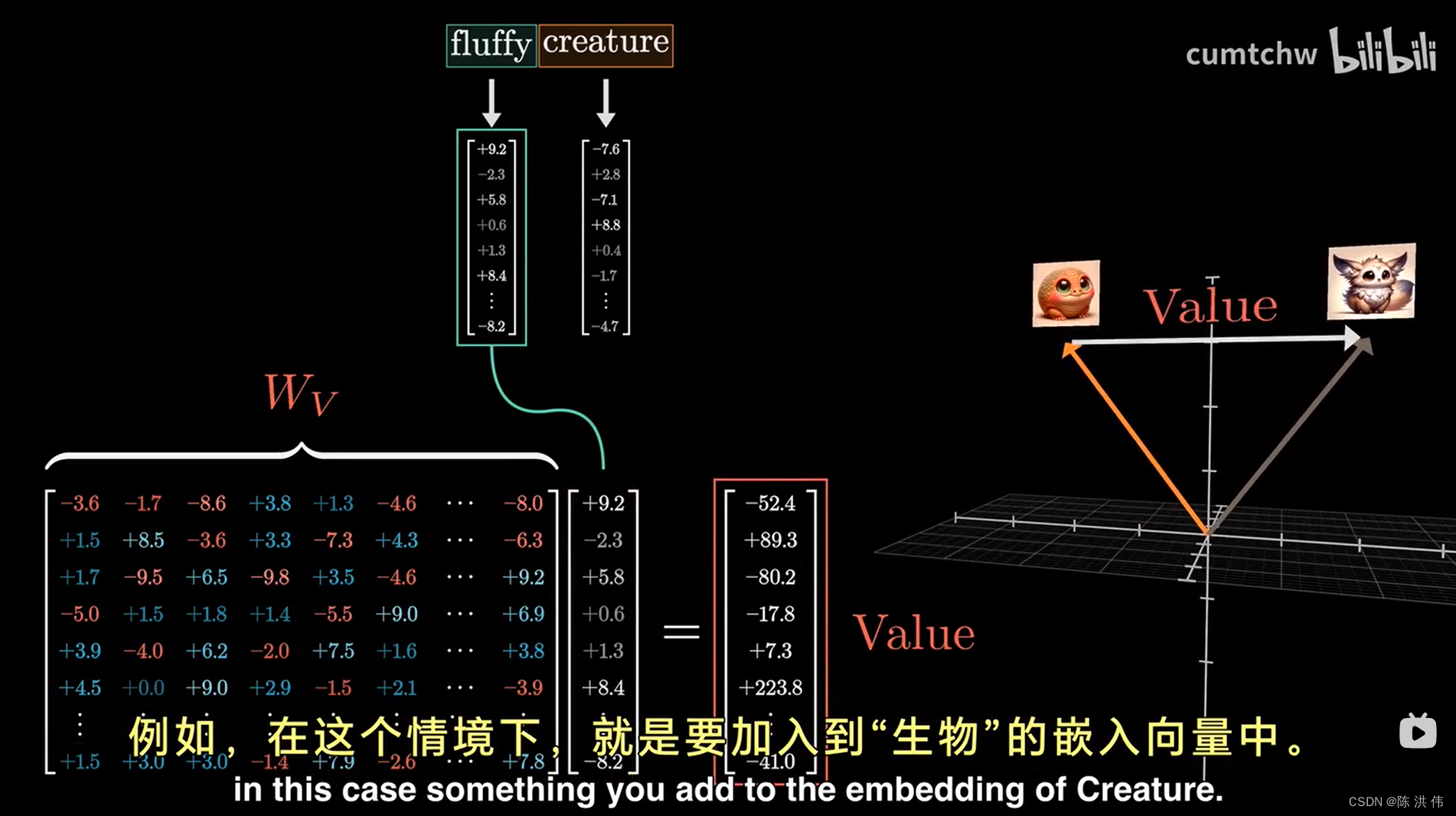
是你要就加入到第二个单词的嵌入向量中的元素,例如在这个情境下,就是要加入到“生物”的嵌入向量中,因此这个值向量就存在于和嵌入向量一样的,给常高维的空间中,当你用这个值矩阵乘以某个单词的嵌入向量时,可以理解为你在询问:如果这个单词对于调整其他内容的含义具有相关性,那么为了反应这一点,我们需要向那个内容的嵌入中添加什么呢,

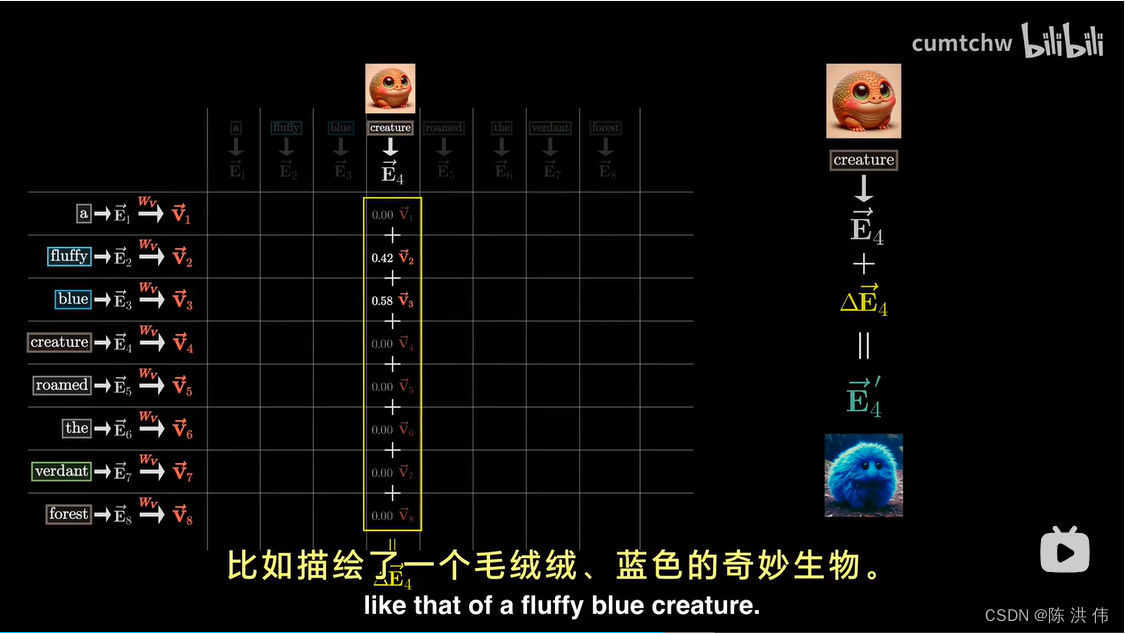
回到之前的注意力模式的图表,我们先不考虑所有的键和查询,因为一旦计算出注意力模式,这些就不再需要了,接下来,我们将使用这个值矩阵,将其与每一个嵌入向量相乘,从而生成一系列的值向量,这些值向量视作在某种程度上与他们对应的键有关。对于图表中的每一列来说,你需要将每个值向量与该列中相应的权重相乘,比如,对于代表生物的嵌入向量,你会主要假如毛茸茸的和蓝色的这两个值向量的较大比例,而其他的只向量则被减少为零,或者至少接近零,最后,为了更新这一列与之相关联的嵌入向量,原本这个向量编码了生物这一概念的某种基本含义(不考虑具体上下文),你需要将列中所有这些经过重新调整比例的值加总起来,这一步骤产生了一个我们想要引入的变化量,我将其称为delta-e。接着将这个变化量叠加到原有的嵌入向量上,希望最终得到的事一个更精细的向量,是一个更加细致和含有丰富上下文信息的向量,比如描绘了一个毛茸茸、蓝色的奇妙生物。
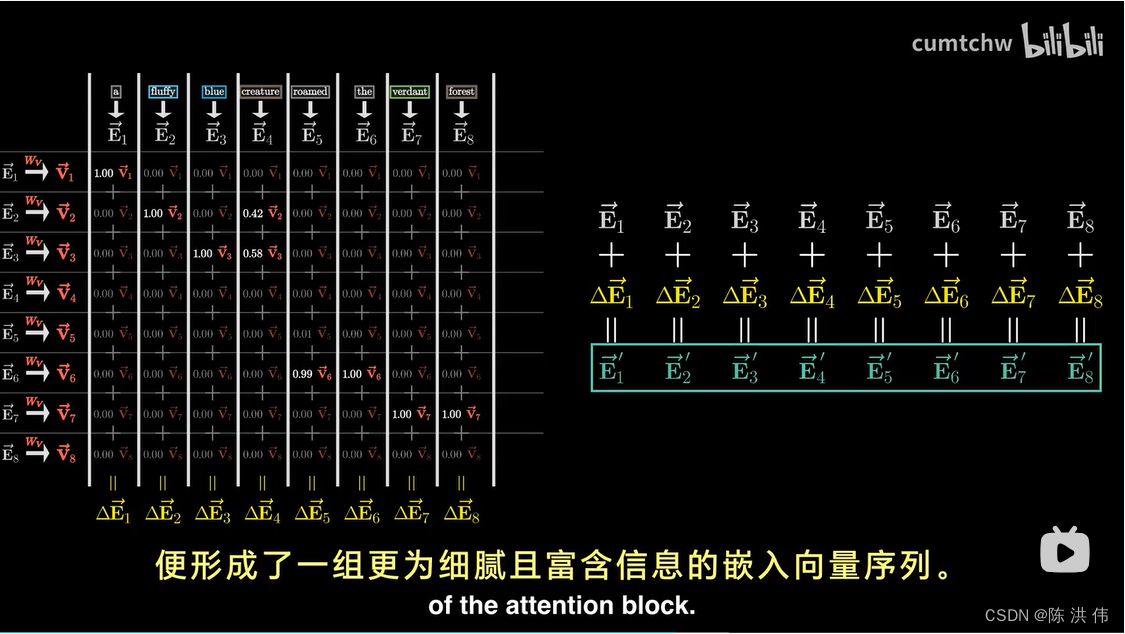
上面讨论的整个过程,构成了所谓的单头注意力机制。这一机制是通过三种不同的、充满可调整参数的矩阵来实现的。也就是键 查询 和 值。




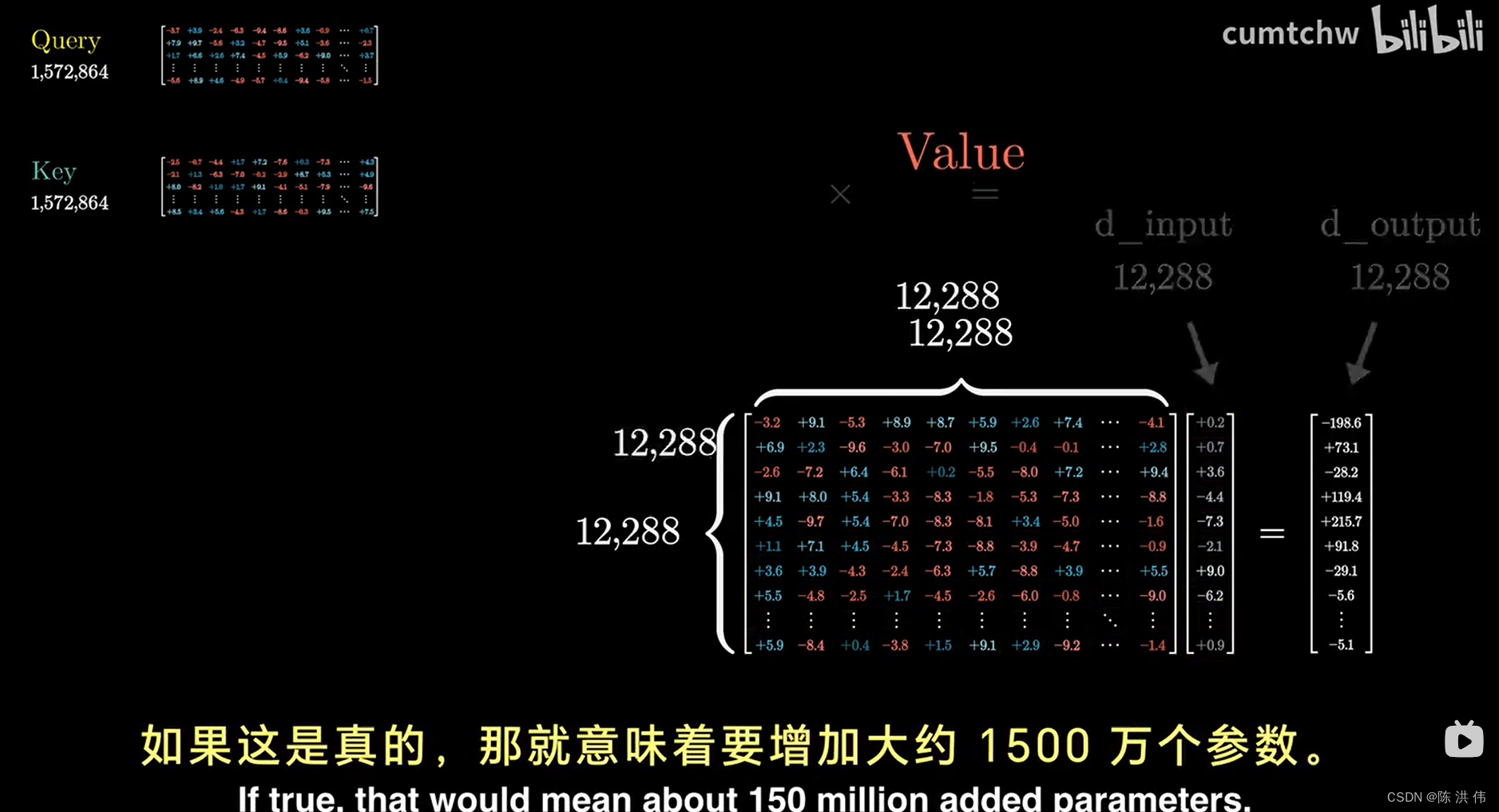
另外,值矩阵,有12288行和12288列,
参考文献:
图形化的理解GPT中的Transformer架构_哔哩哔哩_bilibili
什么是GPT?通过图形化的方式来理解 Transformer 中的注意力机制_哔哩哔哩_bilibili
相关文章:
GPT中的Transformer架构以及Transformer 中的注意力机制
目录 1 GPT中的Transformer架构 2 transformer中的注意力机制 参考文献: 看了两个比较好的视频,简单做了下笔记。 1 GPT中的Transformer架构 GPT是Generative Pre-trained Transformer单词的缩写,其中transformer是一种特定的神经网络&a…...

Hive的简单学习二
一Hive 库的基本操作 1.1 建库 1.默认路径是/user/hive/warehouse 例如 我输入命令 create database text1 则text1出现在 warehouse目录下 2.指定位置创建数据库 create database text2 location /bigdata29/bigdata29db 后面的路径是hdfs的路径 3.最终写法 加上if n…...

Qt事件处理机制3-事件函数的分发
Qt开发中,经常重写event函数和具体的事件处理函数,例如mousePressEvent、paintEvent等,那么这些具体的事件处理函数是怎样被调用的呢?答案是由继承自QObject的类中的event函数来处理事件分发。这里以间接继承自QWidget的派生类MyB…...
4月9号总结
java学习 一.steam流 1.介绍 Stream 是 Java 8 中引入的一种处理集合数据的新抽象。它提供了一种高效且便利的方式来处理集合中的元素,支持函数式编程的特性,使得集合操作变得更加简洁和灵活。 2.创建 List和Set可以直接调用接口的steam方法转换为流 …...

Linux生态系统:探索Linux的开源世界
Linux生态系统:探索Linux的开源世界 在前面的博客中,我们深入探讨了Linux的各种技能和技巧,从入门到进阶,再到高手级别。这一路走来,相信大家对Linux已经有了全面的认识和掌握。然而,Linux的魅力远不止于此。今天,我们将进一步探索Linux生态系统,了解Linux在开源世界中的重要地…...

XILINX 10G PCS PMA IP核使用
文章目录 一、设计框图二、模块设计三、IP核配置四、上板验证五、总结 一、设计框图 关于GT高速接口的设计一贯作风,万兆以太网同样如此,只不过这里将复位逻辑和时钟逻辑放到了同一个文件ten_gig_eth_pcs_pma_0_shared_clock_and_reset当中。如果是从第…...
Scrapy框架内存泄漏问题及解决
说明:仅供学习使用,请勿用于非法用途,若有侵权,请联系博主删除 作者:zhu6201976 一、问题背景及原因 官方文档:Debugging memory leaks — Scrapy 2.11.1 documentation Scrapy是一款功能强大的网络爬虫框…...

app 创建快捷入口 在手机上面多个icon
activity-alias详解及应用-CSDN博客 Android动态修改应用图标最佳实践 - 简书 AndroidManifest.xml 中 <activity-aliasandroid:name"包名.ui.mine.SecondActivityAlias"android:label"快捷入口"android:icon"mipmap/collection_one"andro…...
【网安小白成长之路】6.pkachu、sql-lbas、upload-lbas靶场搭建
🐮博主syst1m 带你 acquire knowledge! ✨博客首页——syst1m的博客💘 🔞 《网安小白成长之路(我要变成大佬😎!!)》真实小白学习历程,手把手带你一起从入门到入狱🚭 &…...

vue 项目中添加DES加密
vue 项目中添加DES加密 由于现在项目使用http协议,且登录界面是明文传输,项目真正上线后基本的密码传输都很不安全。 决定用前端框架加密后再进行传输,以提高密码传输过程中的安全性。 crypto-js 是一个流行的 JavaScript 加密库࿰…...

【记录问题】如何测试虚拟机已经可以连接网络
如何测试虚拟机已经可以连接网络 要测试虚拟机是否已经连接网络,可以采取以下步骤: 检查虚拟网络编辑器 使用管理员权限打开虚拟网络编辑器,检查NAT方式下的虚拟子网网段。 确保虚拟机的网络设置与虚拟子网网段相匹配。检查虚拟机网络设置 …...

MySQL数据库的详解(1)
DDL(数据库操作) 查询 查询所有数据库:show databases;当前数据库:select database(); 创建 创建数据库:create database [ if not exists] 数据库名 ; 使用 使用数据库:use 数据库名 ; 删除 删除数…...

Python 网络爬虫技巧分享:优化 Selenium 滚动加载网易新闻策略
简介 网络爬虫在数据采集和信息获取方面发挥着重要作用,而滚动加载则是许多网站常用的页面加载方式之一。针对网易新闻这样采用滚动加载的网站,如何优化爬虫策略以提高效率和准确性是一个关键问题。本文将分享如何利用 Python 中的 Selenium 库优化滚动…...

Apache SeaTunnel 社区 3 月月报
各位热爱 SeaTunnel 的小伙伴们,SeaTunnel 社区 3 月月报来啦!这里将记录 SeaTunnel 社区每个月的重要更新,并评选出月度之星,欢迎关注。 SeaTunnel 月度 Merge Stars 感谢以下小伙伴 3 月为 Apache SeaTunnel 做的精彩贡献&…...

ElasticSearch 的 ConstantScoreQuery 的理解
ConstantScoreQuery的定义: A query that wraps another query and simply returns a constant score equal to 1 for every document that matches the query. It therefore simply strips of all scores and always returns 1. 结合DisMaxQueryBuilder可以查找所…...
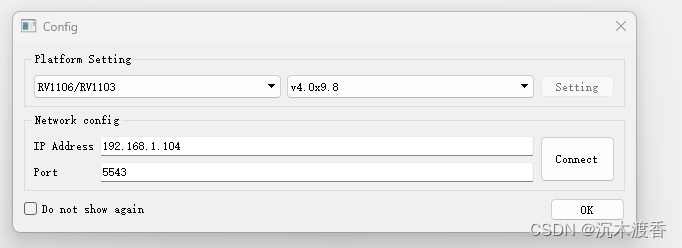
【RV1106的ISP使用记录之一】基础环境搭建
公司缺少ISP工程师,做为图像算法工程师的我这就不就给顶上来了么,也没给发两份工资,唉~ 先写个标题,占一个新坑,记录RK平台的传统ISP工作。 一、基础环境的硬件包括三部分: 1、相机环境,用于采…...
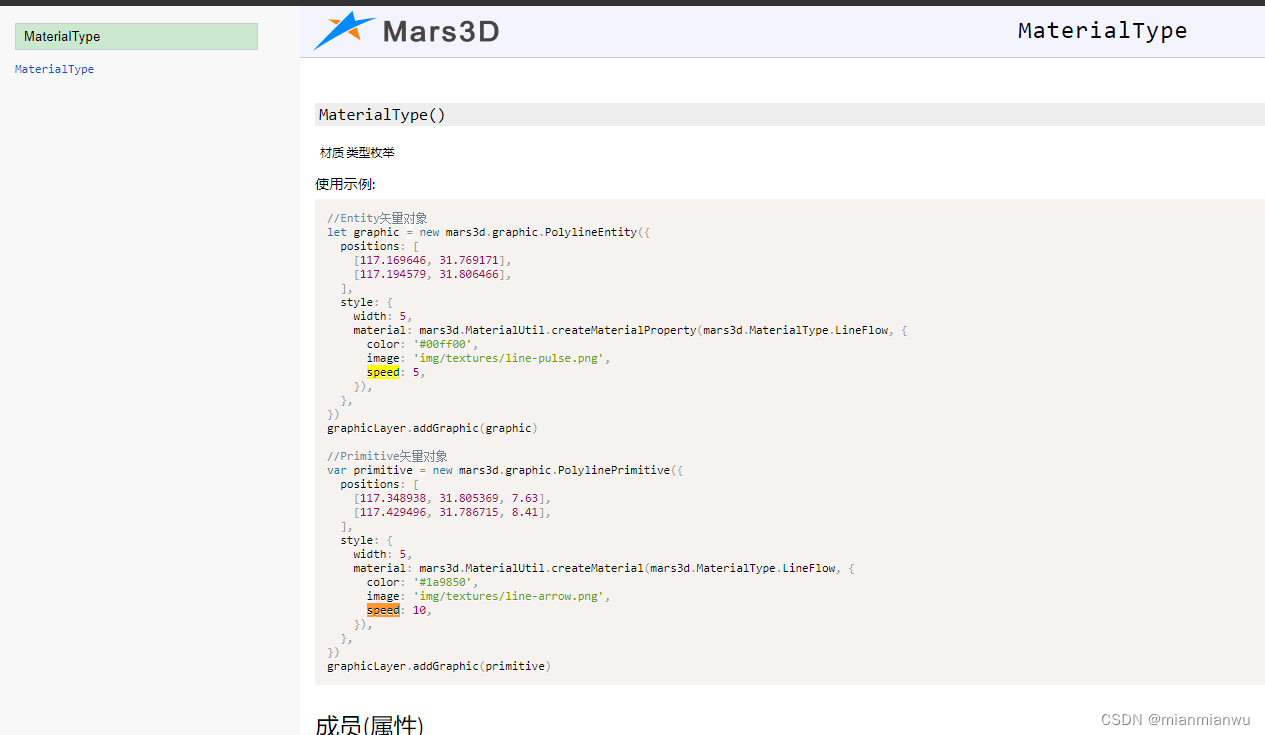
mars3d.MaterialType.Image2修改配置面状:图片2的speed数值实现动画效果说明
摘要: mars3d.MaterialType.Image2修改配置面状:图片2的speed数值实现动画效果说明 前提: 1.在示例中,尝试给mars3d.MaterialType.Image2材质的图片加上speed参数,实现动画效果,但是没有看到流动效果说明…...
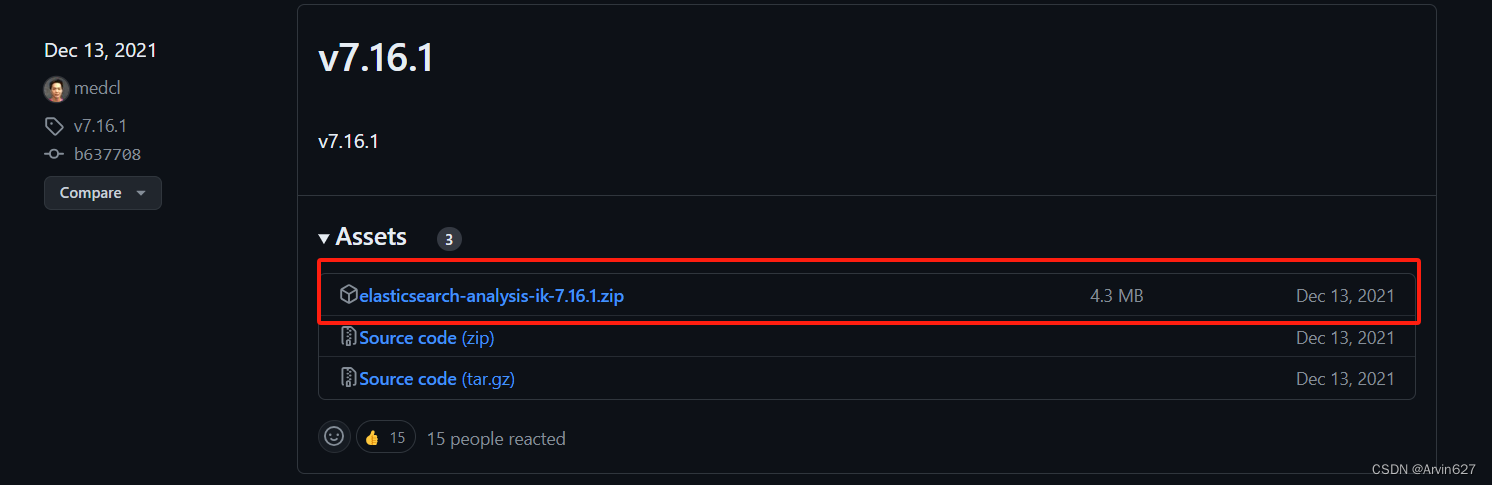
Elasticsearch部署安装
环境准备 Anolis OS 8 Firewall关闭状态,端口自行处理 Elasticsearch:7.16.1(该版本需要jdk11) JDK:11.0.19 JDK # 解压 tar -zxvf jdk-11.0.19_linux-x64_bin.tar.gz# 编辑/etc/profile vim /etc/profile# 加入如下…...
Android零基础入门(一)配置环境和安装Android Studio
闲来无事学一下Android,本人目前java为主,jdk的环境就不赘述了 配置环境 Java JDK5 或 以后版本 Android SDK Java运行时环境(JRE) Android Studio 你可以从 Oracle 的 Java 网站:JDKJava SE下载下载最新版本的 Jav…...

Golang编译优化——消除Copy指令
一、优化概述 以下是Go编译器对某个代码段编译生成的SSA IR摘选,对于Golang SSA IR的介绍我写了文章,但是在犹豫要不要发。 b1:-... Plain → b2 (5)b2: ← b1 b4-v9 (5) Phi <int> v8 v16 (i[int])v22 (8) Phi <int> v7 v14 (r[int])v1…...

【实战复盘】Win11 23H2 微信图片拖拽至抖店失效:跨越注册表修复的降级排障SOP
一、 故障描述与初始环境故障现象:用户无法将微信聊天窗口内的图片,直接拖拽至“抖店工作台”聊天输入框中,系统表现为拖拽操作被拦截或无响应。故障环境:Windows 11 23H2 版本。前置历史:该故障电脑此前拖拽功能正常&…...

光伏产业价值链迁移:从硬件制造到系统服务与金融创新的黄金机遇
1. 光伏行业的价值转移:从硬件制造到系统服务十年前,当我在深圳第一次接触光伏组件生产线时,满眼都是硅料、银浆和层压机,行业里人人谈论的是转换效率又提升了零点几个百分点,或是每瓦成本又降了几分钱。那时候&#x…...

从专利大国到专利强国:企业全球专利布局策略与实战指南
1. 从“专利大国”到“专利强国”:一场关于价值与布局的深度思考最近翻看一些行业旧闻,2016年EE Times上那篇关于中国专利“不出海”的讨论,现在读来依然很有嚼头。文章核心就一句话:根据世界知识产权组织(WIPO&#x…...

云代理商:Hermes Agent如何通过技能沉淀降低长期算力消耗
在 AI 智能体规模化落地的今天,算力成本高、重复推理多、长期运行效率衰减,已成为企业和开发者的核心痛点。传统 AI 智能体每处理一次相似任务,都要从零开始推理、反复调用工具,大量算力浪费在重复劳动中,长期使用成本…...

JavaScript 遍历 JSON 所有 Key 的方法
1️⃣ for…in 循环(最常用) const json {name: "张三",age: 25,city: "北京" };for (let key in json) {console.log(key); // name, age, cityconsole.log(json[key]); // 张三, 25, 北京 }2️⃣ Object.keys()&am…...

ARM PMSWINC寄存器解析与性能监控实践
1. ARM PMSWINC寄存器深度解析与性能监控实战在ARM架构的性能监控领域,PMSWINC(Performance Monitors Software Increment)寄存器是一个关键但常被忽视的组件。作为一位长期从事ARM平台性能调优的工程师,我将在本文中分享这个寄存…...

制作程序统计企业资质办理流程数据,梳理耗时节点,缩短资质办理周期,助力企业快速开展商务工作。
聚焦“企业资质办理流程数据的统计与周期优化”,适用于商务智能(BI)课程中的流程挖掘(Process Mining)与运营效率分析场景。一、实际应用场景描述在工程建设、招投标、医药、金融等行业,企业常需办理各类资…...

高效视频下载方案:VideoDownloadHelper插件一站式实战指南
高效视频下载方案:VideoDownloadHelper插件一站式实战指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾在浏览网页时遇…...

搞懂这6个核心问题,程序员转智能体开发少走3年弯路
文章目录前言问题一:我只会写CRUD,真的能转智能体开发吗?问题二:转智能体开发,到底需要学哪些技术?2.1 基础层:Python 提示词工程2.2 核心层:RAG 工具调用 记忆管理2.3 进阶层&am…...

告别Windows!手把手教你用Proxmox虚拟机零成本体验深度Deepin 20.6
在Proxmox虚拟环境中优雅体验Deepin:技术爱好者的零成本尝鲜指南 对于技术爱好者而言,尝试新操作系统总伴随着两难:既想深度体验系统特性,又担心影响现有工作环境。Proxmox VE作为开源的虚拟化平台,配合Deepin这一国产…...