新手入门:大语言模型训练指南
在这个信息爆炸的时代,人工智能技术正以前所未有的速度渗透到我们生活的方方面面。从智能手机上的语音助手到自动驾驶汽车,AI的应用无处不在。而在这些令人惊叹的技术背后,大语言模型(LLM)扮演着至关重要的角色。它们不仅能够理解和生成自然语言,还能在多种场景下提供智能决策支持。
然而,对于许多对AI感兴趣的新手来说,大语言模型的训练和应用似乎是一件高不可攀的事情。复杂的技术术语、晦涩的理论知识,以及高昂的硬件要求,往往让人望而却步。但其实,只要掌握正确的方法和工具,每个人都能成为AI领域的探索者和实践者。
本文将带你一步步了解大语言模型的基本概念、训练流程以及如何评估模型性能。无论你是编程新手,还是对AI有一定了解的探索者,本指南都将为你揭开大语言模型的神秘面纱,让你能够轻松上手,快速掌握AI的核心技能。
一、入门基础知识
目前,Transformer 架构在语言建模领域占据主导地位,这项由 Vaswani 等人提出的技术源自于开创性论文《Attention Is All You Need》。在本文中,我们将不会深入挖掘Transformer的技术细节,因为那将涉及到许多前驱技术。简而言之,Transformer 架构不仅使我们能够培育出具备卓越推理能力的大型语言模型(LLM),而且其简洁性使得机器学习新手也能够轻松入门。
Python 是训练和构建 Transformer 模型的首选编程语言,它的高级特性让其更接近自然语言,而非底层机器代码,这大大降低了普通人参与LLM训练的门槛。HuggingFace Transformers 库是目前最受追捧的 LLM 工具库,它几乎成为了 LLM 训练者的标配。
那么,什么是LLM?可以将其视作一种高级的文本压缩技术。LLM通过创建带有随机值和参数的张量(可以想象为多维矩阵),并输入大量文本数据(通常以TB计),学习数据中的关联和模式。这些模式以概率形式存储于张量中,模型学会了预测一个词后面跟随另一个词的可能性。因此,LLM可以被理解为将一种语言的概率分布转换成一系列矩阵的形式。
例如,如果你输入“你是”,LLM会计算出下一个词的概率分布。它可能预测出“谁?”的概率为60%,“中国人”的概率为20%,等等。
通常,LLM的训练是从零开始的,即随机初始化模型的参数,这一过程需要巨大的计算资源和高昂的成本(对于大型模型可能涉及数百万美元的投入)。因此,对于大多数人而言,采取“微调”方法更为实际。微调即是在预训练模型的基础上,通过输入少量数据(通常是几MB)来调整模型,使其更好地适应特定的任务。比如,如果你想培养一个编程代码助手,就可以通过对代码样本的微调来实现。
1.1、Transformer 架构
理解Transformer架构在微调(fine-tuning)模型的过程中虽非强制,但了解其基本工作原理对于高效使用相关技术是大有裨益的。尤其当您需要执行特定脚本,这些脚本旨在调用 Transformers 库中的Trainer类时,基础知识显得尤为重要。
要深入了解 Transformer 架构,阅读《Attention Is All You Need》论文无疑是最佳起点。作为深度学习领域的标杆文献,它详细阐述了Transformer模型的构建与运作原理。然而,在深入探究之前,建议读者具备一定的神经网络基础,以便更好地理解论文内容。推荐的阅读路径为:
- 深度学习中的神经网络:概述
- 卷积神经网络简介
- 循环神经网络(RNN):一个温和的介绍与概述
论文太难读懂?
别担心,你不是唯一一个觉得学术论文晦涩难懂的人。一般研究人员会故意使用复杂的语言来描述他们的研究成果。你可以尝试阅读一些博客文章或科普文章,它们通常会用更通俗易懂的方式解释相关概念。HuggingFace 的博客文章是一个不错的资源。
二、训练基础知识
训练 LLM 主要有三种方法:预训练、微调和 LoRA/QLoRA。
2.1、预训练
预训练过程包括以下步骤:
- 收集数据: 首先,我们需要收集大量的文本数据,通常需要达到 TB 级别。
- 选择模型架构: 选择或设计一个适合任务的模型架构,例如 Transformer。
- 训练分词器: 训练一个分词器(tokenizer)来处理文本数据,将文本分割成更小的单元(token),以便模型能够理解。
- 数据预处理: 使用分词器将文本数据转换成模型可以理解的格式,例如将 token 映射成数字 ID,并添加一些特殊的 token 或注意力掩码(attention masks)。
- 模型训练: 使用预处理后的数据训练模型,让模型学习预测句子中的下一个词,或者填补句子中缺失的词。
模型的训练过程是一个不断迭代优化的过程,目标是让模型能够根据上下文,尽可能准确地预测出正确的词语或句子。预训练阶段通常采用一种称为“自监督学习”的技术,例如掩码语言模型 (Masked Language Modeling) [6] 或因果语言模型 (Causal Language Modeling) [7]。掩码语言模型会将句子中的某些词语遮盖住,然后让模型根据上下文预测这些被遮盖的词语;而因果语言模型则会让模型根据前面的词语预测下一个词语。
预训练的目的是让模型学习通用的语言知识,使其成为一个优秀的语言编码器。然而,预训练模型通常缺乏针对特定任务或领域的知识。为了解决这个问题,我们需要进行下一步:微调。
2.2、微调
微调是指使用预训练模型,并输入少量特定领域的数据,来调整模型的行为,使其适应特定的任务。微调的步骤如下:
- 收集数据: 收集与任务相关的数据,例如,如果要训练一个代码助手模型,就需要收集代码数据。
- 初始化模型: 使用预训练模型的参数初始化模型。
- 模型训练: 使用特定领域的数据训练模型,并根据任务目标调整模型的参数。
微调过程中会使用一些优化算法,例如随机梯度下降 (SGD) 或 Adam [8],来更新模型的参数,使模型的预测结果更加准确。为了提高微调的效果,还可以使用学习率调度 [4]、正则化方法(例如 dropout [17] 或权重衰减 [12])或提前停止 [5] 等技术。
2.3、低秩自适应 (LoRA)
微调模型需要大量的计算资源,尤其是对于包含数十亿参数的大型模型来说。为了解决这个问题,研究人员提出了一种新的方法:低秩自适应 (Low-Rank Adaptation, LoRA) [14]。LoRA 可以大幅减少模型训练所需的计算量和内存占用。与使用 Adam 算法微调 OPT-175B 模型相比,LoRA 可以将可训练参数的数量减少 10,000 倍,并将 GPU 内存需求减少 3 倍以上。
为了进一步降低内存需求,研究人员又提出了量化低秩自适应 (Quantized Low-Rank Adaptation, QLoRA) [15] 方法。QLoRA 使用 bitsandbytes 库 [7] 对模型进行量化,可以在普通消费级 GPU 上训练包含 700 亿参数的超大型模型。
本文的后续部分将重点介绍微调和 LoRA/QLoRA 方法的具体操作步骤。
三、微调
正如之前提到的,微调模型的成本取决于你选择的模型大小。通常来说,你需要至少 60 亿到 70 亿参数的模型才能获得比较好的效果。接下来,我们将探讨获取训练所需计算资源的几种方法。
3.1、训练计算
训练 LLM 需要大量的计算资源,尤其是内存。所需的内存大小取决于你的模型大小和数据集大小。你可以参考 EleutherAI 的 Transformer Math 101 这篇文章 [12],了解详细的计算方法。
假设你要微调一个 70 亿参数的模型,例如 Llama-2 7B 或 Mistral 7B。这类模型通常需要 160GB 到 192GB 的内存。你可以考虑以下几种获取计算资源的方案:
- 云服务租用 GPU: 一些云服务平台,例如 Runpod、VastAI、Lambdalabs 和 Amazon AWS Sagemaker,都提供 GPU 租赁服务。其中,VastAI 的价格最便宜,但稳定性也相对较差;Amazon Sagemaker 的价格最贵。我推荐使用 Runpod 或 Lambdalabs。
- Google TPU 研究云: 你可以申请 Google TPU 研究云 (TRC) 的免费使用权限,有机会获得多达 110 台 TPU 机器。TPU 是一种专门为机器学习设计的芯片,与 GPU 在架构上有所不同,使用之前需要学习一些相关的知识。幸运的是,Google 通过 Google Colaboratory 提供了免费的 TPU 使用机会,虽然性能较弱,但可以用来学习和试验。此外,还有一些开源库和指南可以帮助你在 TPU 上微调 LLM,例如 Mesh Transformers JAX 和 EasyLM。
3.2、收集数据集
数据集是微调模型的关键。数据集的质量和数量都很重要,但质量更为关键。
首先,你需要明确你希望微调后的模型能够做什么。例如,写故事、进行角色扮演、帮你写邮件,或者创建一个 AI 聊天机器人。假设你想要训练一个像 Pygmalion 这样的聊天和角色扮演模型,那么你需要收集大量的对话数据,尤其是互联网角色扮演风格的对话。收集数据可能是一个比较困难的过程,需要你自己想办法解决。
3.3、数据集结构
构建数据集时,需要注意以下几点:
- 数据多样性: 你不希望你的模型只能完成非常特定的任务。例如,即使你只想训练一个聊天模型,也不应该只收集单一类型的对话数据。你需要收集各种场景下的对话数据,让模型能够学习如何应对不同的输入。
- 数据集大小: 与 LoRA 或 Soft Prompts 等方法不同,微调模型需要相对较多的数据。虽然不需要像预训练模型那样使用海量数据,但至少也要准备 10MB 以上的数据。通常来说,数据越多越好,因为 LLM 很少会出现过拟合的问题。
- 数据集质量: 数据的质量至关重要。你希望模型生成什么样的输出,就需要提供什么样的训练数据。如果你的数据质量很差,那么模型生成的输出也会很差。
3.4、处理原始数据集
收集到的原始数据可能需要进行一些处理,才能用于训练模型。假设你的数据集是以下几种格式之一:
3.4.1、HTML
- HTML: 如果你从网站上爬取数据,那么你的数据可能是 HTML 格式的。你需要从 HTML 文件中提取出文本内容。可以使用 Python 的 Beautiful Soup 库来完成这项任务。例如:
from bs4 import BeautifulSoup# 要解析的HTML内容
html_content = '''
<html>
<head><title>示例HTML页面</title>
</head>
<body><h1>欢迎来到示例页面</h1><p>这是一段文本。</p><div class="content"><h2>第一部分</h2><p>这是第一部分的内容。</p></div><div class="content"><h2>第二部分</h2><p>这是第二部分的内容。</p></div>
</body>
</html>'''# 创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html_content, 'html.parser')# 从 HTML 提取文本
text = soup.get_text()# 打印提取的文本
print(text)你将得到这样的输出
示例HTML页面欢迎来到示例页面
这是一段文本。
第一部分
这是第一部分的内容。
第二部分
这是第二部分的内容。3.4.2、CSV
如果你从开放数据源获取数据,你的数据可能是 CSV 格式。可以使用 pandas 库轻松解析 CSV 文件。基本用法如下:
import pandas as pd# 阅读CSV文件
df = pd.read_csv('dataset.csv')# 从特定列中提取明文
column_data = df['column_name'].astype(str)
plaintext = column_data.to_string(index=False)# 打印提取的明文数据
print(plaintext)这里必须要指定列名。
3.4.3、SQL
解析 SQL 数据集稍微复杂一些。你可以使用数据库框架(如 MariaDB 或 PostgreSQL)将数据导出为纯文本,也可以使用 Python 库(如 sqlparse)进行解析。sqlparse 的基本用法如下:
>>> import sqlparse>>> # 拆分包含两个SQL语句的字符串:
>>> raw = 'select * from foo; select * from bar;'
>>> statements = sqlparse.split(raw)
>>> statements
['select * from foo;', 'select * from bar;']>>> # 格式化第一条语句并打印出来:
>>> first = statements[0]
>>> print(sqlparse.format(first, reindent=True, keyword_case='upper'))
SELECT *
FROM foo;>>> # 解析SQL语句:
>>> parsed = sqlparse.parse('select * from foo')[0]
>>> parsed.tokens
[<DML 'select' at 0x7f22c5e15368>, <Whitespace ' ' at 0x7f22c5e153b0>, <Wildcard '*' … ]
>>>3.5、最小化噪声
优秀的语言模型通常具有随机性,这意味着即使输入相同的提示,模型的输出也可能不同。这种随机性有时会导致模型生成低质量或不理想的文本。因此,需要清理数据集中的噪声,例如无意义的字符、重复的内容等。
如果你的数据源是合成的(例如由 GPT-3/4 生成),则更需要注意清理噪声。建议去除诸如“作为一个 AI 语言模型...”、“有害或攻击性内容...”、“...由 OpenAI 训练...”等短语,因为这些短语可能会对模型训练产生负面影响。ehartford 的脚本和 gptslop (https://github.com/AlpinDale/gptslop)库可以帮助你完成这项任务。
3.6、开始训练
本教程使用 axolotl 训练器进行微调,因为它易于使用且功能齐全。如果你使用云计算服务(如 RunPod),则可能已经满足了所有必要条件。
首先,克隆 axolotl 仓库并安装依赖项:
git clone https://github.com/OpenAccess-AI-Collective/axolotl && cd axolotlpip3 install packaging
pip3 install -e '.[flash-attn,deepspeed]'这将安装 axolotl,然后我们就可以开始微调了。
Axolotl 在一个 yaml 文件中获取所有训练选项。在示例目录中已经有一些示例配置,用于各种不同的模型。
在这个例子中,我们将使用 QLoRA 方法训练 Mistral 模型,这应该可以在单个 3090 GPU 上实现。要开始运行,只需执行以下命令:
accelerate launch -m axolotl.cli.train examples/mistral/config.yml恭喜!你刚刚训练了 Mistral 模型!示例配置使用了一个非常小的数据集,训练时间应该在几分钟到几小时之间。
要使用自定义数据集,你需要将其格式化为 JSONL 文件。Axolotl 支持多种数据格式,你可以在文档中找到示例。然后,编辑 qlora.yml 文件,将数据集路径指向你的 JSONL 文件。所有配置选项的详细说明可以在文档中找到,点击“展开”按钮查看所有选项。
你现在已经了解了如何训练模型,下一节将介绍 LoRA 的原理及其有效性。
四、LoRA
低秩适应 (LoRA) 是一种高效的训练方法,可以加速大语言模型的训练过程,同时降低内存消耗。LoRA 的核心思想是冻结预训练模型的大部分参数,仅训练一小部分新增的低秩矩阵。这些低秩矩阵通过秩分解技术获得,参数量远小于原始模型,因此可以有效减少内存占用和计算量。
LoRA 的优势包括:
- 保护预训练知识: LoRA 冻结了预训练模型的大部分参数,避免了灾难性遗忘 (catastrophic forgetting) 问题,即模型在学习新知识时遗忘旧知识的现象。
- 参数高效且可移植: LoRA 的参数量远小于原始模型,训练得到的参数可以轻松迁移到其他模型或任务中。
- 与注意力机制集成: LoRA 通常应用于 Transformer 模型的注意力层,通过调节适应比例参数 (alpha) 可以控制模型对新数据的适应程度。
- 降低计算成本: LoRA 的内存效率使得在资源有限的设备上进行模型微调成为可能。
4.1、LoRA 超参数设置
4.1.1、LoRA 秩 (rank)
这个参数决定了我们要使用多少个分解矩阵来降低模型的内存和计算成本。根据 LoRA 原始论文的建议,至少应该设置秩为 8 (r = 8)。但要注意,更高的秩虽然能带来更好的训练效果,但同时也需要更强大的计算资源。你的数据集越复杂,可能就需要设置更高的秩。 如果你想进行一次全面的微调,可以将秩设置为与模型隐藏层的大小相同。不过,这样做可能会导致资源的极大浪费,因此并不推荐。你可以通过查看模型的配置文件 config.json,或者使用 Transformer 库的 AutoModel 功能并调用 model.config.hidden_size 方法来获取模型的隐藏层大小:
from transformers import AutoModelForCausalLM
model_name = "huggyllama/llama-7b" # 也可以是本地目录路径
model = AutoModelForCausalLM.from_pretrained(model_name)
hidden_size = model.config.hidden_size
print(hidden_size)4.1.2、LoRA Alpha
LoRA 缩放因子是用于调整模型对新训练数据适应程度的一个比例系数。这个系数会影响训练过程中更新矩阵的贡献度。如果设置得较低,模型就会更多地依赖原始数据,保留更多的已有知识;如果设置得较高,则会更多地适应新数据。
4.1.3、LoRA 训练目标模块
在这里,你可以指定哪些特定的权重和矩阵需要进行训练。通常,最先训练的是查询向量 (Query Vectors) 和值向量 (Value Vectors) 的投影矩阵。这些矩阵的名称会根据不同的模型而有所不同。你可以通过以下脚本来查询这些矩阵的确切名称:
from transformers import AutoModelForCausalLM
model_name = "huggyllama/llama-7b" # 也可以是本地目录路径
model = AutoModelForCausalLM.from_pretrained(model_name)
layer_names = model.state_dict().keys()
for name in layer_names:print(name)运行上述脚本后,你可能会得到类似下面的输出:
model.embed_tokens.weight
model.layers.0.self_attn.q_proj.weight
model.layers.0.self_attn.k_proj.weight
model.layers.0.self_attn.v_proj.weight
model.layers.0.self_attn.o_proj.weight
model.layers.0.self_attn.rotary_emb.inv_freq
model.layers.0.mlp.gate_proj.weight
model.layers.0.mlp.down_proj.weight
model.layers.0.mlp.up_proj.weight
model.layers.0.input_layernorm.weight
model.layers.0.post_attention_layernorm.weight
...
model.norm.weight
lm_head.weight模型的权重命名规则大致如下:{identifier}.{layer}.{layer_number}.{component}.{module}.{parameter}。下面是对每个模块的简单解释(请注意,这些名称会根据不同的模型架构而有所变化):
- 上行投影 (up_proj):在解码器到编码器的注意力传递过程中使用的投影矩阵,用于将解码器的隐藏状态调整到与编码器相同的维度,以保证注意力计算的兼容性。
- 下行投影 (down_proj):在编码器到解码器的注意力传递过程中使用的投影矩阵,用于将编码器的隐藏状态调整到解码器期望的维度,以进行注意力计算。
- 查询投影 (q_proj):在注意力机制中应用于查询向量的投影矩阵,用于将输入的隐藏状态转换到适合查询表示的维度。
- 值投影 (v_proj):在注意力机制中应用于值向量的投影矩阵,用于将输入的隐藏状态转换到适合值表示的维度。
- 键投影 (k_proj):在注意力机制中应用于键向量的投影矩阵,用于转换输入的隐藏状态以适应键的表示。
- 输出投影 (o_proj):应用于注意力机制输出的投影矩阵,用于在进一步处理前将注意力输出转换到适当的维度。
然而,有三个特殊的权重 (如果你的模型包含偏差权重,可能是四个) 并不符合上述的命名规则,它们省略了层名称和编号。这些权重包括:
- 嵌入 Token 权重 (embed_tokens):代表模型嵌入层的参数,通常位于模型的前端,负责将输入的 Token 或单词映射到相应的密集向量表示。如果你的数据集包含自定义的语法规则,这个权重非常重要。
- 归一化权重 (norm):模型中的归一化层,通常使用层归一化或批量归一化来提高深度神经网络的稳定性和收敛速度。这些层通常位于模型的特定层之间或之后,以解决梯度消失或梯度爆炸的问题,帮助模型更快地训练并获得更好的泛化能力。通常不建议将这个权重作为 LoRA 训练的目标。
- 输出层 (lm_head):语言模型的输出层,负责根据前面层学习到的表示生成下一个 Token 的预测或分数。这个层位于模型的最底部,如果你的数据集包含自定义的语法规则,这个层非常重要。
五、QLoRA
QLoRA (量化低秩适配器) 是一种高效的模型微调 (finetuning) 方法,它减少了内存使用,同时保持了大型语言模型的高性能。使用 QLoRA,我们可以在单个 48GB 的 GPU 上微调一个 65B 参数的模型,并且不会降低 16 位微调任务的性能。
QLoRA 的主要创新包括:
- 通过冻结的、4 位量化的预训练语言模型将梯度反向传播到低秩适配器 (LoRA) 中。LoRA 是一种低秩矩阵分解技术,可以有效地减少模型参数数量。
- 使用一种称为 4 位 NormalFloat (NF4) 的新数据类型,它可以最佳地处理正态分布的权重,进一步降低内存占用。
- 双重量化,通过量化量化常数来减少平均内存占用。
- 分页优化器,有效管理微调过程中的内存峰值。
在接下来的部分中,我们将详细介绍训练超参数 (hyperparameters) 的作用以及如何设置它们。
六、训练超参数
训练超参数在塑造模型的行为和性能方面起着至关重要的作用。这些超参数是指导训练过程的设置,决定了模型如何从提供的数据中学习。选择合适的超参数可以显著影响模型的收敛性、泛化能力和整体有效性。
在本节中,我们将解释在训练阶段需要仔细考虑的关键训练超参数,包括批量大小、时期、学习率、正则化等概念。通过深入了解这些超参数及其影响,您将能够有效地微调和优化您的模型,确保在各种机器学习任务中的最佳性能。
6.1、批量大小和周期
随机梯度下降 (SGD) 是一种常用的模型训练算法,它具有多个超参数可供使用。其中,批量大小和时期数是两个经常让新手感到困惑的概念。它们都是整数值,并且看起来做着同样的事情。让我们来详细解释一下:
- 随机梯度下降 (SGD):这是一种迭代学习算法,利用训练数据集逐步更新模型参数,使模型逐渐学习到数据的规律。
- 批量大小:批量大小是指在每次更新模型参数之前,需要处理的训练样本数量。换句话说,它指定了每次迭代中使用多少个样本 来计算误差并调整模型。较大的批量大小可以提高训练效率,但可能会导致模型收敛到局部最优解。
- 训练周期数:训练周期数是指模型对整个训练数据集进行完整遍历的次数。每个周期都会更新一次模型参数,模型会逐渐学习到数据的规律。更多的训练周期可以提高模型的准确性,但可能会导致过拟合。
我们将进一步把这一部分分成五个部分来详细解释。
6.1.1、随机梯度下降
随机梯度下降 (SGD) 是一种优化算法,用于找到模型的最佳内部参数,目标是最小化性能指标,例如对数损失 (logarithmic loss) 或均方误差 (mean squared error)。对数损失和均方误差都是衡量模型预测值与真实值之间差异的指标,值越小表示模型的预测越准确。
优化可以被认为是一个搜索过程,算法在这个过程中学习如何改进模型。使用的特定优化算法称为“梯度下降”。“梯度”指的是计算误差斜率或梯度,而“下降”表示沿着这个斜率向下移动,以接近最小误差水平,也就是找到最优的模型参数。
该算法以迭代方式工作,这意味着它会经历多个离散步骤,每个步骤都旨在增强模型参数。在每个步骤中,模型使用当前的内部参数集对样本子集进行预测。然后将这些预测与实际预期结果进行比较,从而计算出误差。然后利用该误差来更新内部模型参数。更新过程根据所使用的算法而有所不同,但在人工神经网络的情况下,使用反向传播 (backpropagation) 更新算法。
在深入探讨批量和时期的概念之前,让我们先解释一下“样本”的含义。
6.1.2、样本
样本或序列是单行数据。它包含输入到算法中的输入和用于与预测进行比较并计算误差的输出。
训练数据集由多行数据组成,例如许多样本。样本也可以称为实例、观察值、输入向量、序列或特征向量。
现在我们知道了什么是样本,让我们定义一个批量。
6.1.3、批量
批量大小 (batch size) 是一个超参数 (hparam),它决定了在更新模型的内部参数之前处理多少个样本。可以把它想象成一个 "for 循环" (for-loop),它迭代特定数量的样本并进行预测。在处理完批量后,将预测与预期输出进行比较,并计算出误差。然后使用该误差通过调整其参数来改进模型,使其朝着误差梯度的方向移动。
训练数据集可以分为一个或多个批量。以下是基于批量大小的不同类型的梯度下降算法:
- 批量梯度下降:当批量大小等于训练样本总数时,称为批量梯度下降。在这种情况下,整个数据集用于计算预测并计算误差,然后再更新模型。
- 随机梯度下降:当批量大小设置为 1 时,称为随机梯度下降。这里,每个样本都被单独处理,并且模型参数在每个样本之后更新。这种方法在学习过程中引入了更多的随机性。
- 小批量梯度下降:当批量大小大于 1 且小于训练数据集的总大小时,称为小批量梯度下降。该算法处理小批量的样本,进行预测并相应地更新模型参数。小批量梯度下降在批量梯度下降的效率和随机梯度下降的随机性之间取得了平衡。
通过调整批量大小,我们可以控制计算效率和学习过程的随机性之间的权衡,使我们能够找到有效训练模型的最佳平衡。
在小批量梯度下降的情况下,流行的批量大小包括 32、64 和 128 个样本。您可能会在大多数教程的模型中看到这些值的使用。
如果数据集不能被批量大小整除怎么办?
这经常发生。这意味着最后一个批量的样本比其他批量的样本少。您可以简单地从数据集中删除一些样本或更改批量大小,以便数据集中的样本数量可以被批量大小整除。大多数训练脚本会自动处理这个问题。
6.1.4、周期
训练周期 (Epochs) 是一个超参数,它决定了学习算法将迭代整个数据集的次数。
一 (1) 个时期表示训练数据集中的每个样本都被使用过一次来更新模型的内部参数。它由一个或多个批量组成。例如,如果我们每个时期有一个批量,则它对应于前面提到的批量梯度下降算法。
您可以将时期数可视化为一个 "for 循环",它迭代训练数据集。在这个循环中,还有另一个嵌套的 "for 循环",它遍历每一批样本,其中一批样本根据批量大小包含指定数量的样本。
为了评估模型在时期内的性能,通常会创建折线图,也称为学习曲线。这些图在 x 轴上显示时期作为时间,在 y 轴上显示模型的误差或技能。学习曲线有助于诊断模型是过度学习(高训练误差,低验证误差)、学习不足(低训练和验证误差)还是达到了对训练数据集的合适拟合(低训练误差,合理低的验证误差)。我们将在下一部分深入研究学习曲线。
6.1.5、批次与周期的区别
批次大小指的是在模型进行一次更新前,所处理的样本数目。
而周期数,则是模型完整遍历训练数据集的次数。
批次大小至少为一(bsz >= 1),且不能超过训练数据集中的样本总数(bsz <= 样本数)。
周期数可以设定为从一(1)到无限大之间的任何整数值。你可以根据需要运行算法,甚至可以根据模型误差随时间的变化(或不变)来决定何时停止,而不仅仅是固定的周期数。
它们都是整数,并且是学习算法的超参数(hparams),即学习过程中的设置参数,而非学习过程中确定的内部模型参数。
在开始学习算法之前,你需要设置批次大小和周期数。
配置这些超参数没有固定的规则。你需要尝试不同的设置,以找到最适合你特定情况的配置。
下面是一个快速示例:
假设你有一个数据集,包含200个样本(数据行或序列),你选择了5作为批次大小,设置了1,000个周期。这意味着数据集将被划分为40个批次,每个批次包含五个样本。每处理一个批次的五个样本后,模型的权重就会更新一次。这也意味着,一个周期将包括40个批次,即模型将被更新40次。
在1,000个周期中,模型将会被整个数据集“见”1,000次。这在整个训练过程中,总共会有40,000个批次。
记住,更大的批次大小会占用更多的GPU内存。为了应对这一点,我们将采用梯度累积步骤!
6.2、学习率
正如之前在讨论批次和周期时提到的,机器学习中,我们常用一种名为随机梯度下降(SGD)的优化方法来训练模型。学习率在SGD中扮演着关键角色,它决定了每次更新权重时,模型应对估计误差的反应程度。
可以将学习率视为控制模型改进步伐大小的调节器。如果学习率设置得太小,模型可能需要很长时间来学习,或者可能陷入不是最佳的解决方案。相反,如果学习率设置得太大,模型可能学得太快,导致结果不稳定或不够精确。
正确选择学习率对训练成功至关重要。它就像寻找一个“刚刚好”的区域——既不太小也不太大。你需要通过实验来探索不同学习率对模型性能的影响,从而对学习率如何影响模型训练过程中的行为建立直观感知。
因此,在微调训练过程时,要特别注意学习率,因为它在决定模型学习效率和表现方面起着至关重要的作用。
6.2.1、学习率与梯度下降
随机梯度下降通过使用训练数据集中的样本估计模型当前状态的误差梯度,然后利用误差反向传播算法(简称“反向传播”)更新模型权重。在训练期间调整权重的幅度称为步长或“学习率”。
具体而言,学习率是一个训练过程中可调节的超参数,它是一个很小的正数,通常在0.0到1.0之间。(注意:是介于这两个值之间,而不是这两个值本身。)
学习率控制着模型适应问题的速度。较小的学习率意味着每次更新时对权重的调整较小,因此需要更多的训练周期。较大的学习率会导致权重快速变化,从而减少所需的训练周期。
高学习率 = 更少的周期。
低学习率 = 更多的周期。
“学习率可能是最重要的超参数。如果你只有时间调整一个超参数,那就调整学习率。” —《深度学习》
让我们学习如何配置学习率。
6.2.2、配置学习率
从一个合理的范围开始:首先考虑在类似任务中常用的一系列学习率值。基于你正在微调的预训练模型所使用的学习率,找出一个起点。例如,对于Transformer模型,一个常见的起点是1e-5(0.00001),这通常被认为是有效的。
观察训练进展:用选定的学习率运行训练过程,并监控模型在训练过程中的表现。密切关注损失或准确率等指标,评估模型的学习效果。
太慢了?如果学习率太小,你可能会发现模型训练进展缓慢,需要很长时间才能收敛或取得明显的改进。这种情况下,可以考虑增加学习率以加速学习过程。
太快了?如果学习率设置得太大,可能会导致模型学得过快,结果不稳定。如果在训练过程中观察到损失或准确率出现剧烈波动,这可能是学习率过高的信号。这时,应考虑降低学习率。
迭代调整学习率:根据上述第3步和第4步的观察,迭代调整学习率,并重新进行训练。逐步缩小能够产生最佳性能的学习率范围。
计算学习率的一个通用公式是:
base_lr * sqrt(supervised_tokens_in_batch(批次中受监督的Token总数) / pretrained_bsz(预训练的批次大小))
其中,base_lr 是预训练模型的学习率。对于Mistral来说,这个值是5e-5。批次中受监督的Token总数指的是,一旦你开始训练,系统会报告的在批次中的受监督Token的总数,这个数字除以总步数(系统同样会报告)再除以总周期数;即,总受监督Token数 / (总步数 / 总周期数)。预训练的批次大小指的是基础模型的原始批次大小。对于Mistral和Llama来说,这是4,000,000(四百万)。例如,假设我们在使用一个包含两百万受监督Token的数据集来训练Mistral,并且我们在单个GPU上以批次大小1进行训练。假设这需要350步。最终的公式看起来是这样的:
5e-5 * sqrt(2000000/(350/1) / 4000000) = 0.00000189 (1.89e-6)
作为参考,Llama-2模型的基础学习率是3e-4。
6.3、梯度累积 (Gradient Accumulation)
在训练大语言模型的过程中,使用较大的批次大小可以提高训练效率,但也容易导致显存不足的问题。为了解决这个问题,我们可以采用“梯度累积”的技巧。
梯度累积是指将原本用于训练模型的一个大批次样本数据,拆分成若干个更小的“小批次”,然后依次使用这些小批次进行模型训练。

6.3.1、反向传播 (Backpropagation)
在一个模型中,我们有许多层共同作用来处理我们的数据。可以将这些层想象成相互连接的构建模块。当我们将数据输入模型时,它会逐步通过这些层。随着数据在层间的传递,模型会根据数据做出预测。
在数据经过所有层并且模型做出预测之后,我们需要衡量模型预测的准确性。我们通过计算一个称为“损失”(Loss)的值来实现这一点。损失值告诉我们模型的预测与正确答案之间的偏差程度。
接下来是关键部分。我们希望模型能够从错误中学习并提升其预测的准确性。为此,我们需要了解当我们对模型的内部参数(如权重和偏差)进行微小调整时,损失值会如何变化。
这时就需要用到梯度(Gradients)的概念了。梯度帮助我们了解,随着每个模型参数的调整,损失值会如何变化。可以将梯度想象成箭头,它们指示出当我们微调参数时损失变化的方向和幅度。
得到梯度后,我们可以利用它们来更新模型的参数。我们会选用一个优化器(Optimizer),它类似于一个专门负责指导参数更新的算法。优化器会考虑梯度以及学习率(Learning Rate,决定了更新的幅度)和动量(Momentum,有助于学习和稳定性的速度)等因素。
为了简化理解,我们可以考虑一个常用的优化算法:随机梯度下降(Stochastic Gradient Descent,SGD)。它可以用一个公式来表示:V = V - (lr * grad)。在这个公式中,V 代表我们想要更新的模型参数(比如权重或偏差),lr 是学习率,grad 是我们之前计算出的梯度。这个公式告诉我们如何根据梯度和学习率来调整参数。
总结来说,反向传播是一个计算模型错误程度的过程,我们通过梯度来了解如何调整模型参数的方向,然后应用优化算法(如随机梯度下降)来进行调整,帮助模型学习和提升预测的准确性。
6.3.2、梯度累积的详细解释
梯度累积是一种我们在不更新模型变量的情况下执行多次计算的技术。我们会跟踪这些步骤中计算得到的梯度,并在之后用它们来更新变量。这个方法实际上相当简单!
为了更好地理解梯度累积,可以想象我们将一个样本批次分割成多个较小的组,称为小批次(mini-batches)。在每一步中,我们处理一个小批次,但不更新模型的变量。这意味着模型在处理所有小批次时使用相同的变量集。
通过在这些步骤中不更新变量,我们确保了为每个小批次计算得到的梯度和更新与使用完整大批次时的结果一致。换句话说,我们确保了从小批次中累积得到的梯度之和与从完整大批次中得到的梯度相同。
简而言之,梯度累积允许我们将大批次分割成多个小批次,对每个小批次进行计算而不更新变量,然后累积这些小批次的梯度。这样的累积确保我们得到的总体梯度与使用完整大批次时无异。
6.3.3、梯度累积的迭代过程
假设我们在 5 步中累积梯度。在前 4 步中,我们不更新任何变量,只是存储梯度。然后在第 5 步中,我们将前 4 步累积的梯度与当前步骤的梯度结合起来,计算并应用变量的更新。
在第一步中,我们处理一个小批次的样本,并进行前向传播和反向传播,计算每个可训练模型参数的梯度。但我们并不立即更新变量,而是将这些梯度存储起来。为此,我们会为每个可训练的模型参数创建额外的变量,用来保存累积的梯度。
计算出第一步的梯度后,我们将其存储在相应的累积梯度变量中。这样,第一步的梯度就可以供后续步骤使用。
我们重复这个过程,在接下来的三个步骤中继续累积梯度,但不更新变量。到了第五步,我们有了前四步累积的梯度和当前步骤的梯度。结合这些梯度,我们可以计算出变量的更新,并进行相应的应用。下面是这个过程的示意图:
现在开始第二步,第二步中的所有样本再次通过模型的所有层进行传播,计算出第二步的梯度。与前一步相同,我们此时还不需要更新变量,所以不用计算变量的更新。不过,与第一步不同的是,我们不仅要将第二步的梯度存储在变量中,还要把它们加到第一步梯度的当前值上。
第三步和第四步与第二步类似,我们仍然不更新变量,而是继续累积梯度,将新的梯度值加到之前累积的变量中。
到了第五步,我们打算更新变量,因为我们计划在 5 步中累积梯度。计算出第五步的梯度后,我们将其加入到之前累积的梯度中,得到这 5 步所有梯度的总和。然后,我们将这个总和作为参数输入到优化器中,得到的更新就是基于这 5 步所有梯度计算出的,涵盖了全局批次中所有样本的更新。
如果我们以随机梯度下降(SGD)为例,让我们看看在第五步结束时,根据这 5 步的梯度计算出的变量更新情况(以下示例中 N=5):
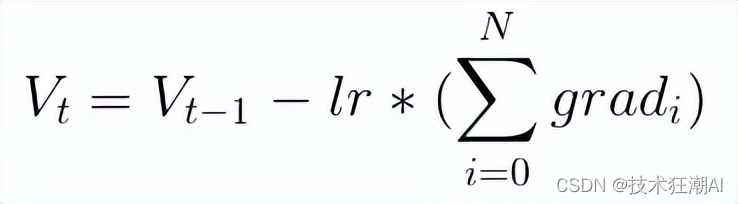
6.3.4、如何配置梯度累积的步数
正如我们之前详细讨论的,使用梯度累积步数可以帮助我们达到或超过期望的批量尺寸。
例如,如果您希望的批量尺寸是 32 个样本,但您的 VRAM 内存有限,只能处理 8 个样本的批量尺寸,您可以将梯度累积步数设置为 4。这意味着您将在执行更新之前累积 4 步的梯度,从而有效地模拟了 32 个样本的批量尺寸(8 * 4)。
总的来说,建议根据可用资源合理设置梯度累积步数,以提高计算效率。太少的累积步数可能导致梯度信息不足,而太多的累积步数会增加内存需求并拖慢训练速度。
七、解读学习曲线
学习曲线(Learning Curves)是逐步学习算法中一个非常实用的工具,它帮助我们理解模型是如何从训练数据集中逐步学习的。我们会用一个验证集来评估模型,并通过损失函数的图表来展示模型当前的输出与我们期望的输出之间的差距。接下来,我们将详细探讨学习曲线的具体内容,以及如何利用它们来诊断我们模型的学习和泛化能力。
7.1、概览
学习曲线(Learning Curves)就像一个图表,展示了时间或经验(x轴)与学习进步或改善(y轴)之间的关系。举个例子,就像你学习日语,每周都对自己的语言能力打分,一年后,通过这些分数的变化,你可以清晰地看到自己掌握日语的过程。
学习(y轴)随经验(x轴)的折线图。
为了让评分更直观,我们可以设定一个标准:分数越低,表示学习效果越好。比如,一开始你可能在词汇和语法上遇到困难,分数较高;但随着学习的深入,分数逐渐降低,说明你对日语的掌握越来越牢固。如果你的分数达到了0.0,那就表示你已经完全掌握了日语。
在模型训练过程中,我们可以通过评估每一步的表现来监控模型的学习情况。这个评估可以在训练数据集上进行,以了解模型的学习效果。同时,我们还可以在未用于训练的验证数据集上进行评估,以检验模型对新数据的泛化能力。
常见的学习曲线有两种:
- 训练学习曲线(Train Learning Curve):基于训练数据集生成,展示了模型在训练过程中的学习情况。
- 验证学习曲线(Validation Learning Curve):使用独立的验证数据集创建,帮助我们了解模型对新数据的泛化能力。
通常,同时关注训练和验证数据集的学习曲线会更有帮助。
有时候,我们可能需要跟踪多个评估指标。例如,在分类问题中,我们可能会根据交叉熵损失(Cross-Entropy Loss)来优化模型,并用分类准确度(Classification Accuracy)来评估模型的性能。这种情况下,我们会绘制两个图表,每个图表展示两个学习曲线:一个是训练数据集的,另一个是验证数据集的。
我们把这些学习曲线分为两类:
- 优化学习曲线(Optimization Learning Curves):根据用于优化模型参数的指标(例如损失)计算得出。
- 性能学习曲线(Performance Learning Curves):根据用于评估和选择模型的指标(例如准确度)派生。
通过分析这些学习曲线,我们可以深入了解模型的学习进度和它有效学习和泛化的能力。
现在我们对学习曲线有了基本的了解,接下来让我们来看看在学习曲线图表中常见的一些形态。
7.2、模型行为诊断
通过观察学习曲线的形状和变化,我们可以对模型的学习行为进行分析,进而可能提出一些配置调整的建议,以提升模型的学习效果或性能表现。
在分析学习曲线时,通常会发现三种典型的情况:
- 欠拟合(Underfit)
- 过拟合(Overfit)
- 拟合良好(Well-fit)
接下来,我们将详细探讨每一种情况。这里假设我们关注的是一个最小化指标,即 y 轴上较小的数值代表更好的学习效果。
7.2.1、欠拟合学习曲线
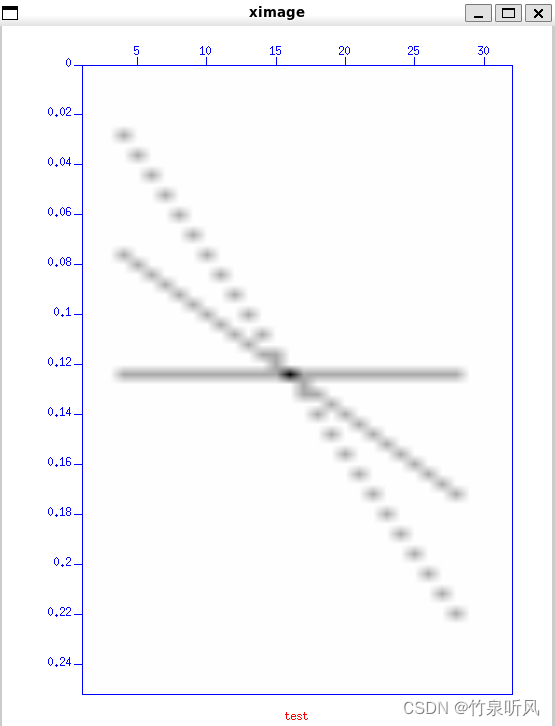
当模型无法有效学习训练数据集时,我们称之为欠拟合。这种情况可以通过观察训练损失曲线来识别:曲线可能呈现一条平坦线或者波动较大的高损失值,这表明模型根本没有学会训练数据集的内容。如下图所示,这种情况常见于模型的容量不足以应对数据集的复杂性:
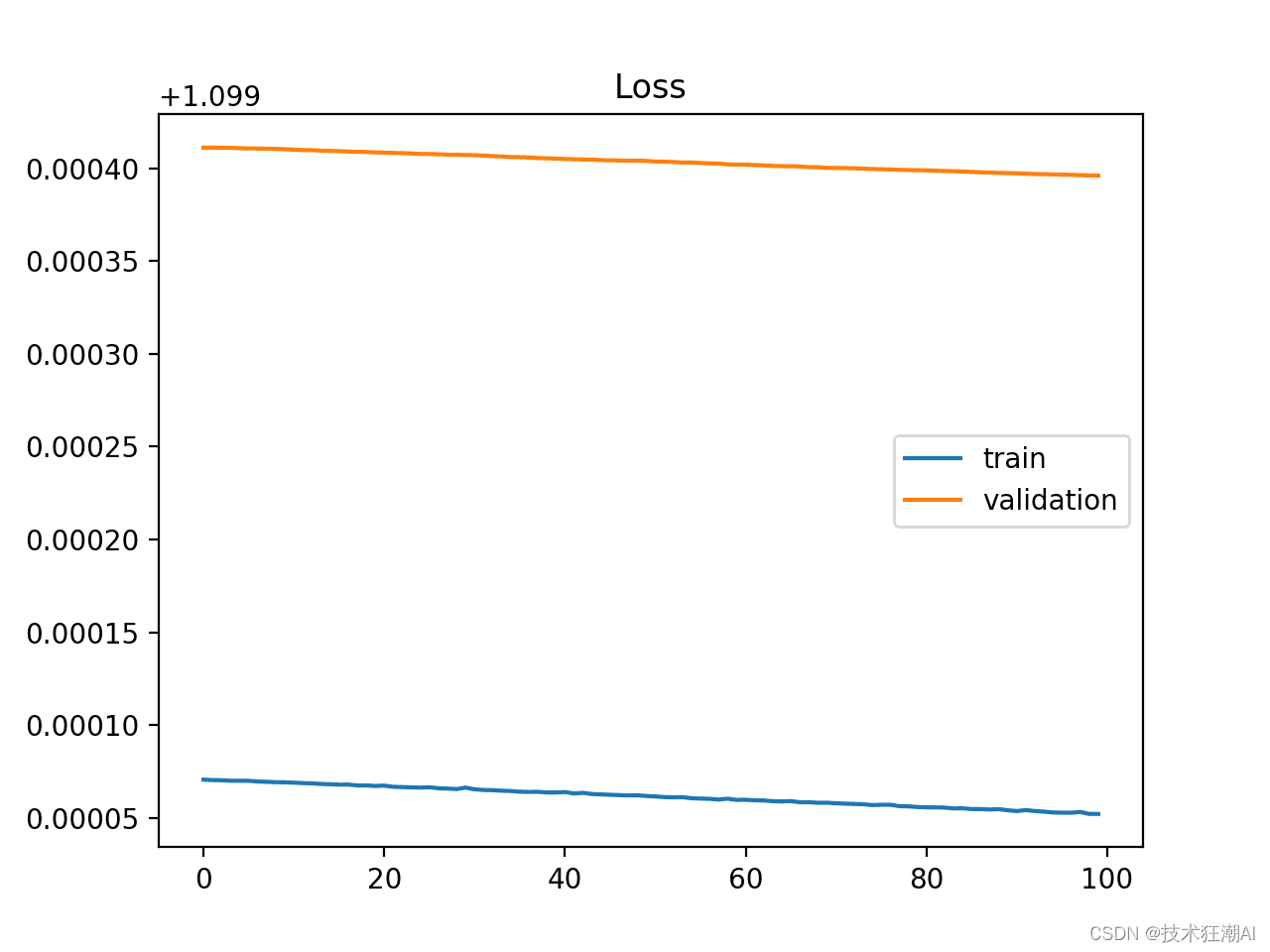
欠拟合曲线的特点包括:
- 训练损失在训练过程中保持不变。
- 训练损失持续下降,直至训练结束。
7.2.2、过拟合学习曲线
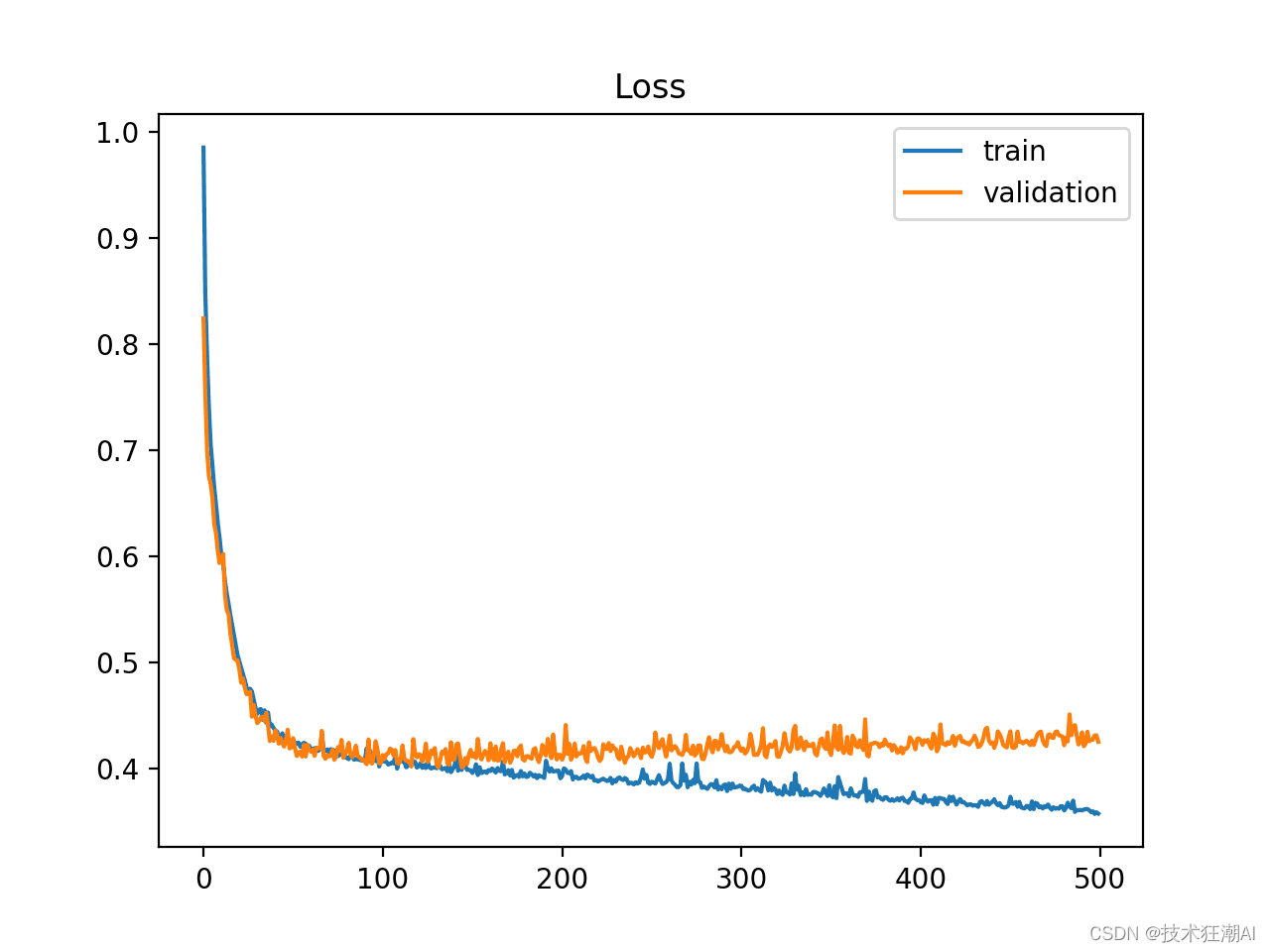
过拟合是指模型对训练数据集学习得过于透彻,以至于记住了数据的细节,而不是进行泛化。这包括了训练数据集中的统计噪声或随机波动。过拟合的问题在于,模型越是专门化于训练数据,对新数据的泛化能力就越差,导致泛化误差的增加。这种泛化误差的增加可以通过模型在验证数据集上的表现来衡量。通常,如果模型的复杂度过高或训练时间过长,就可能出现过拟合。学习曲线图显示过拟合的情况如下:
- 训练损失随着经验的增加持续下降。
- 验证损失先下降到某一点,然后又开始上升。
验证损失的转折点可能是停止训练的时机,因为此后的经验将显示出过拟合的特征。下图展示了一个过拟合模型的学习曲线:
7.2.3、拟合良好的学习曲线
这是我们训练模型时的目标状态——位于过拟合和欠拟合之间的理想曲线。
一个好的拟合状态通常表现为训练损失和验证损失都降低到一个稳定的水平,并且两者之间的差距很小。
模型在训练数据集上的损失总是会低于在验证数据集上的损失。这意味着我们应该预期训练损失和验证损失之间会存在一定的差距,这个差距被称为“泛化差距”。
下图展示了一个拟合良好的模型的学习曲线:

八、总结
本文是一份全面的新手指南,旨在指导初学者如何有效地培训大型语言模型(LLM)。文章首先介绍了Transformer架构的基础知识,这是现代LLMs的核心。接着,它深入探讨了预训练和微调的概念,强调了这些步骤在模型开发中的重要性。文章还详细讨论了低阶适应(LoRA)技术,这是一种新兴的高效训练方法,可以显著降低大型模型训练的计算和内存成本。此外,指南涵盖了关键的超参数调整,如批量大小、学习率和梯度累积,这些对于优化模型性能至关重要。文章还强调了数据集的准备和处理在训练过程中的作用,以及如何通过学习曲线来诊断和改进模型。最后,指南提供了实用的训练运行启动步骤,确保新手能够顺利开始他们的LLM培训之旅。整体而言,这份指南为新手提供了一个坚实的起点,帮助他们理解和掌握LLM培训的关键技术和策略。
九、参考资料
[1]. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, R. (2023). Attention Is All You Need: https://arxiv.org/abs/1706.03762
[2]. HuggingFace Transformers: https://github.com/huggingface/transformers
[3]. Juergen Schmidhuber, R. (2014). Deep Learning in Neural Networks: an Overview:https://arxiv.org/abs/1404.7828
[4]. Keiron O'Shea, Ryan Nash, R. (2015). An Introduction to Convolutional Neural Networks:https://arxiv.org/abs/1511.08458
[5]. Robin M. Schmidt, R. (2019). Recurrent Neural Networks (RNNs): A gentle Introduction and Overview:https://arxiv.org/abs/1912.05911
[6]. Masked Language Modeling:https://huggingface.co/docs/transformers/main/tasks/masked_language_modeling
[7]. Causal Language Modeling:https://huggingface.co/docs/transformers/main/tasks/language_modeling
[8]. Diederik P. Kingma, Jimmy Ba, R. (2017). Adam: A Method for Stochastic Optimization:https://arxiv.org/abs/1412.6980
[9]. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, R. (2021). LoRA: Low-Rank Adaptation of Large Language Models:https://arxiv.org/abs/2106.09685
[10]. PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware:https://huggingface.co/blog/peft
[11]. bitsandbytes:https://github.com/timdettmers/bitsandbytes
[12]. Transformer Math 101: https://blog.eleuther.ai/transformer-math
[13]. EasyLM: https://github.com/young-geng/EasyLM
[14]. sqlparse:https://sqlparse.readthedocs.io/en/latest/
[15].axolotl:https://github.com/OpenAccess-AI-Collective/axolotl
[16]. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, R. (2021). LoRA: Low-Rank Adaptation of Large Language Models:https://arxiv.org/pdf/2106.09685.pdf
相关文章:
新手入门:大语言模型训练指南
在这个信息爆炸的时代,人工智能技术正以前所未有的速度渗透到我们生活的方方面面。从智能手机上的语音助手到自动驾驶汽车,AI的应用无处不在。而在这些令人惊叹的技术背后,大语言模型(LLM)扮演着至关重要的角色。它们不…...
Win11 WSL2 install Ubuntu20.04 and Seismic Unix
Win11系统,先启用或关闭Windows功能,勾选“适用于Linux的Windows子系统”和“虚拟机平台”两项 设置wsl默认版本为wsl2,并更新 wsl --list --verbose # 查看安装版本及内容 wsl --set-default-version 2 # 设置wsl默认版本为wsl2 # 已安装…...
rust使用print控制台打印输出五颜六色的彩色红色字体
想要在控制台打印输出彩色的字体,可以使用一些已经封装好的依赖库,比如ansi_term这个依赖库,官方依赖库地址:https://crates.io/crates/ansi_term 安装依赖: cargo add ansi_term 或者在Cargo.toml文件中加入&#…...
贪心算法|435.无重叠区间
力扣题目链接 class Solution { public:// 按照区间右边界排序static bool cmp (const vector<int>& a, const vector<int>& b) {return a[1] < b[1];}int eraseOverlapIntervals(vector<vector<int>>& intervals) {if (intervals.siz…...
C++的并发世界(七)——互斥锁
0.死锁的由来 假设有两个线程T1和T2,它们需要对两个互斥量mtx1和mtx2进行访问。而且需要按照以下顺序获取互斥量的所有权: -T1先获取mte1的所有权,再获取mt2的所有权。 -T2先获取 mtx2的所有权。再铁取 mtx1的所有权。 如果两个线程同时执行,…...
NI-LabView的DAQ缺少或丢失的解决办法(亲测有效)
DAQmx在Labview中不显示或缺失 问题:在NI Packasge Manager安装完DAQ后在labview中不显示控件解决办法 问题:在NI Packasge Manager安装完DAQ后在labview中不显示控件 在打开测量I/O时,见不到 DAQmx,或者在Express中见不到DAQ助手…...

cesium 调整3dtiles的位置 世界坐标下 相对坐标下 平移矩阵
cesium调整3dtiles的位置用到的是平移矩阵,原理是在世界坐标系中用偏移点减去原始点得到一个平移向量,再根据这个向量得到平移矩阵。 原始点:一般是模型的中心点位置,可通过模型的包围盒得到偏移点:可分为两种情况&…...

flutter跑通腾讯云直播Demo
运行示例 前提条件 要求java jdk 11版本 并且配置到了环境变量 重要 要求flutter 版本 2.8.0 并且配置到了环境变量 重要 要求dart-sdk版本2.15 并且配置到了环境变量 重要 您已 注册腾讯云 账号,并完成 实名认证。 申请 SDKAPPID 和 SECRETKEY 登录实时音视频控…...

飞机降落蓝桥杯[2023蓝桥省赛B组]
2023蓝桥省赛B组 B题 飞机降落 题解 标准深搜板子题,难度不大 #include<bits/stdc.h> using namespace std; #define MAX 10 struct node{int t,d,l;//t:飞机到达时间 d:飞机最大盘旋时间 l:飞机降落所需时间bool v;//标记此架飞机是否被搜索过 用于剪枝 };…...

如何动态渲染HTML内容?用v-html!
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

EFcore 6 连接oracle19 WinForm vs2022
用EFcore访问Oracle,终于不需要Oracle的什么安装包了,直接在VS2022中就可以轻松搞定。在csdn上看到一哥们的帖子,测试了一下,发现很方便。使用的场景是:VS2022中EFcore6。经过测试,同 Navicat Premium 16比…...
 Object Pascal 学习笔记---第9章第2节(finally代码块))
(delphi11最新学习资料) Object Pascal 学习笔记---第9章第2节(finally代码块)
9.2 finally 代码块 还有第四个用于异常处理的关键字,我已经提到过,但到目前为止还没有使用过,那就是 finally。finally块用于执行一些应始终执行的操作(通常是清理操作)。事实上,无论是否发生异常&…...
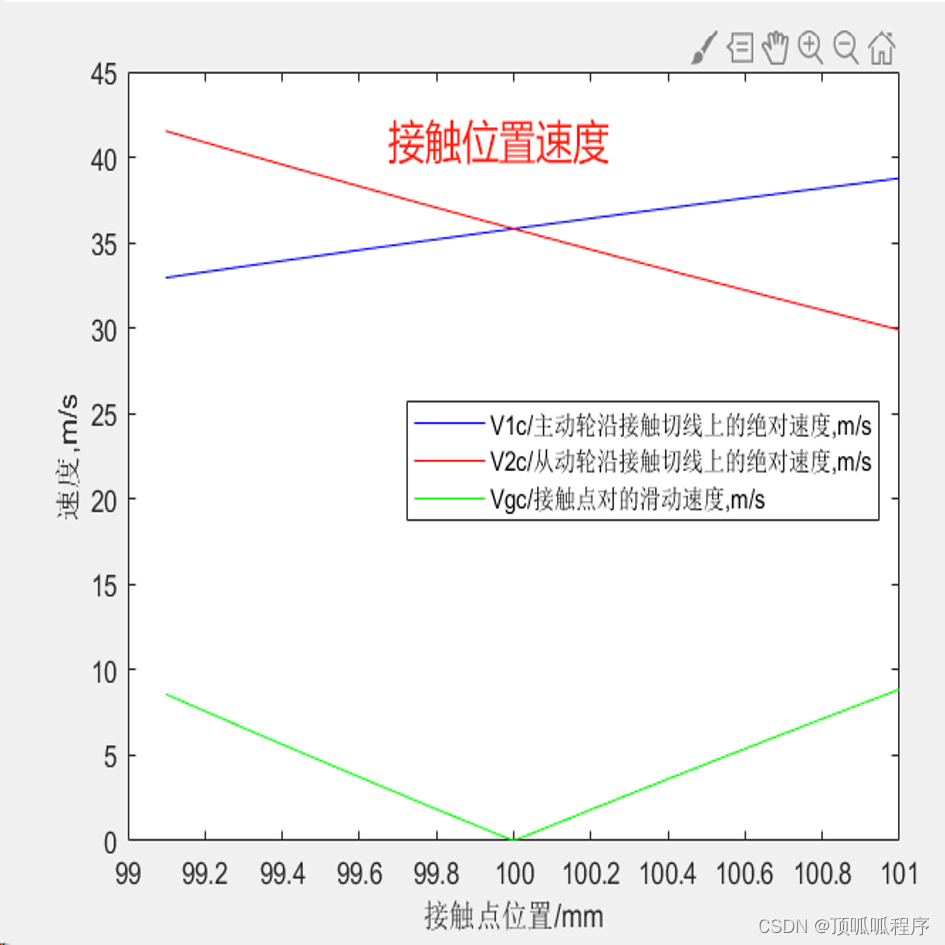
220 基于matlab的考虑直齿轮热弹耦合的动力学分析
基于matlab的考虑直齿轮热弹耦合的动力学分析,输入主动轮、从动轮各类参数,考虑润滑油温度、润滑油粘度系数等参数,输出接触压力、接触点速度、摩擦系数、对流传热系数等结果。程序已调通,可直接运行。 220直齿轮热弹耦合 接触压力…...
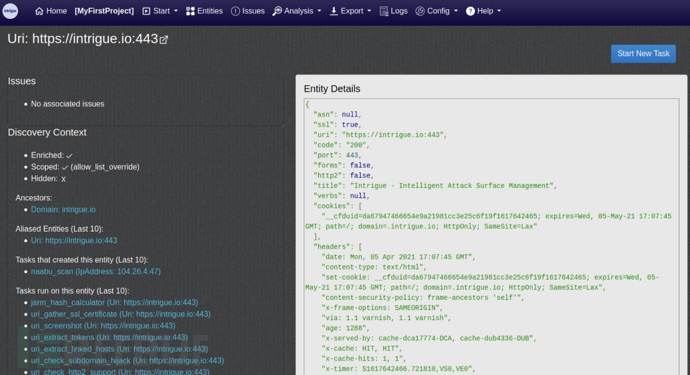
Intrigue Core:一款功能强大的攻击面枚举引擎
关于Intrigue Core Intrigue Core是一款功能强大的开源攻击面枚举引擎,该工具可以帮助广大研究人员更好地管理应用程序的攻击面。 Intrigue Core集成了各种各样的安全数据源,可以将这些数据提取到标准化的对象模型中,并通过图形数据库跟踪关…...

【精品PPT】智慧路灯大数据平台整体建设实施方案(免费下载)
1、知识星球下载: 如需下载完整PPTX可编辑源文件,请前往星球获取:https://t.zsxq.com/19QeHVt8y 2、免费领取步骤: 【1】关注公众号 方案驿站 【2】私信发送 【智慧路灯大数据平台】 【3】获取本方案PDF下载链接,直…...
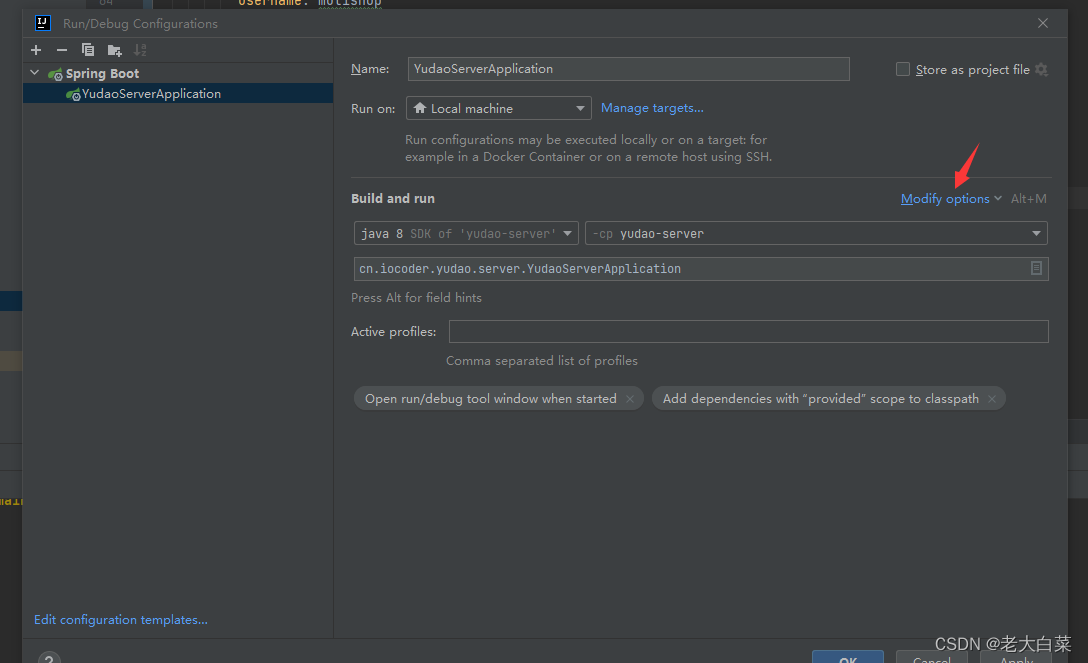
idea 中运行spring boot 项目报 Command line is too long的解决办法。
Command line is too long 在这里选择edit configures 选择shrten command line , 选择 jar manifest 运行即可。...

Windows终端添加git bash
环境:windows11 终端:windows terminal git bash默认的界面不太好看,添加到终端会比较好用 步骤 打开 windows terminal,在向下箭头 点击 设置左侧栏 点击 “添加新配置文件”,如下图配置,主要修改项&…...
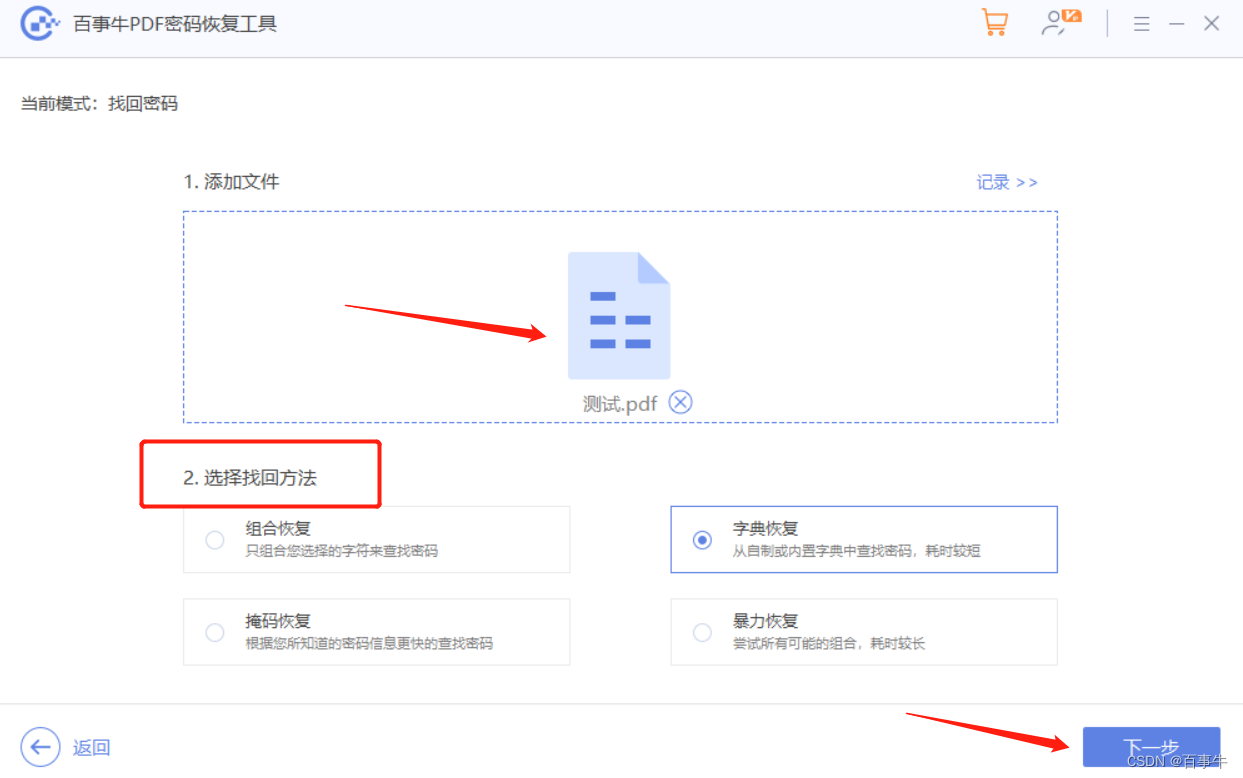
【方法】PDF密码如何取消?
对于重要的PDF文件,很多人会设置密码保护,那后续不需要保护了,如何取消密码呢? 今天我们来看看,PDF的两种密码,即“限制密码”和“打开密码”,是如何取消的,以及忘记密码的情况要怎…...
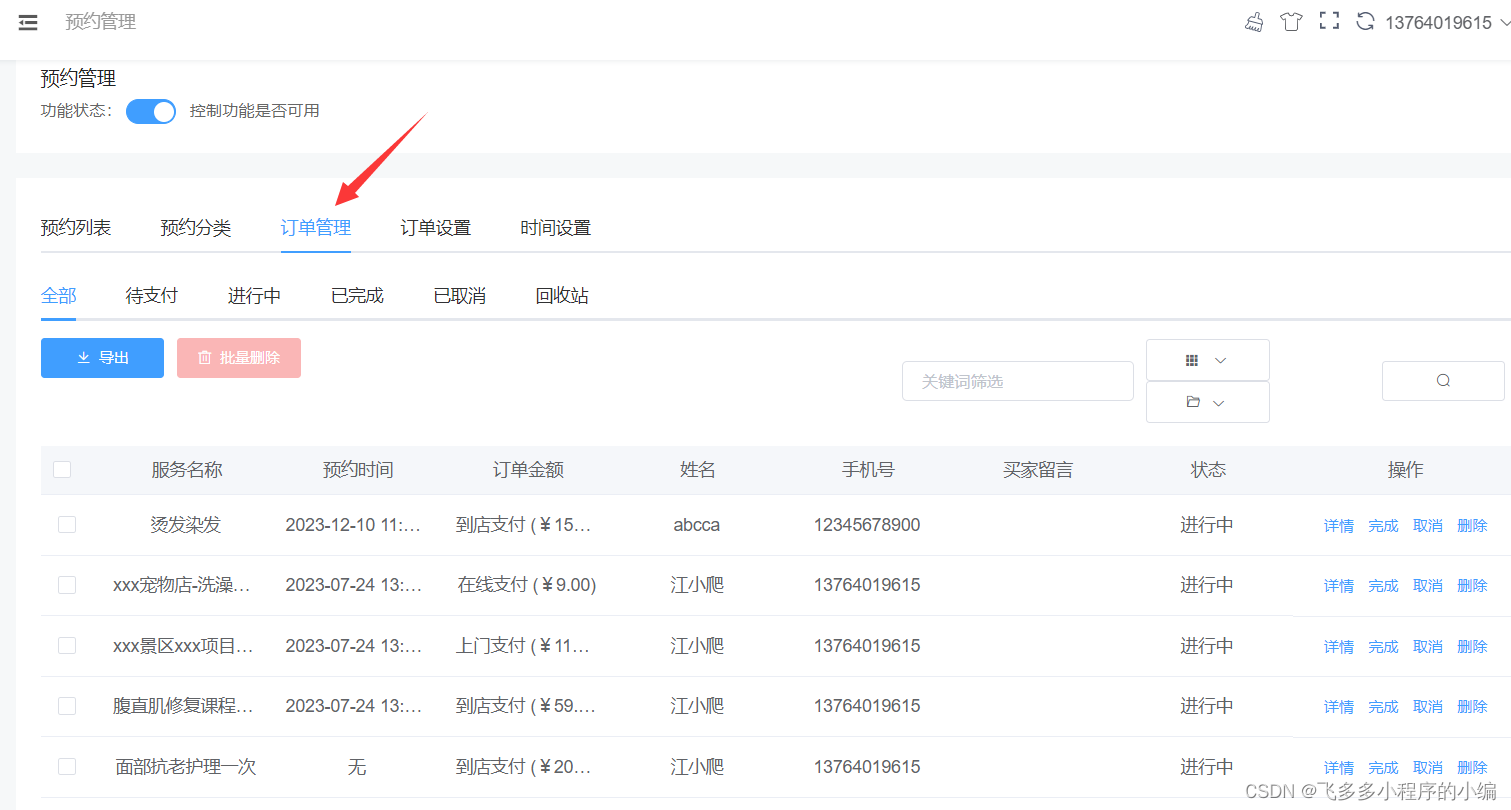
怎么开发一个预约小程序_一键预约新体验
预约小程序,让生活更便捷——轻松掌握未来,一键预约新体验 在快节奏的现代生活中,我们总是在不断地奔波,为了工作、为了生活,不停地忙碌着。然而,在这繁忙的生活中,我们是否曾想过如何更加高效…...
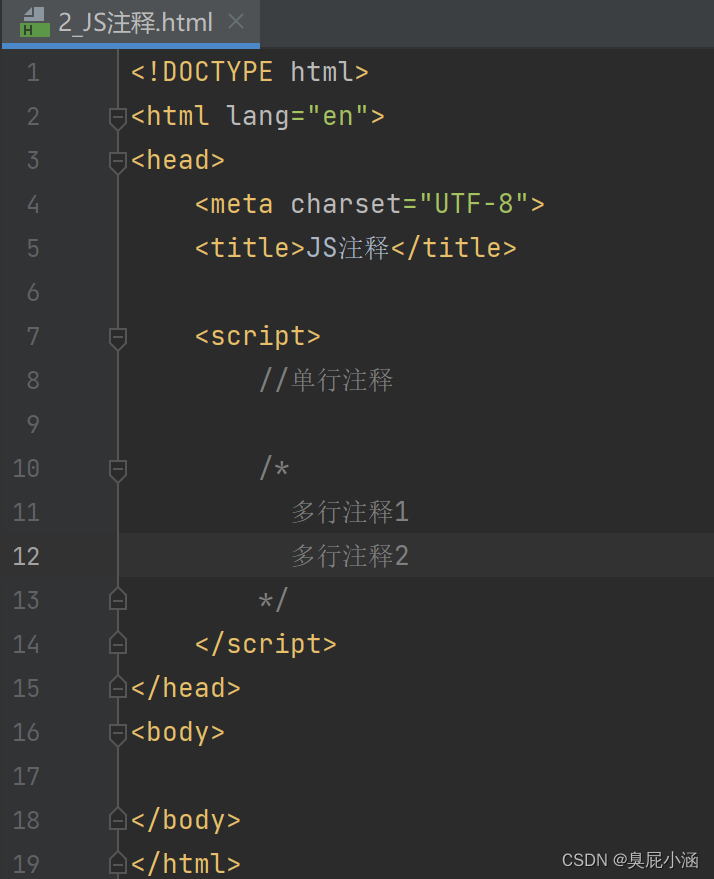
JavaScript_注释数据类型
JavaScript_语法_注释&数据类型: 1.2注释: 1.单行注释://注释内容 2.多行注释:/*注释内容*/ 1.3数据类型: 1.原始数据类型(基本数据类型):(只有这五种) 1.number:数字…...
)
Windows 11 + CUDA 12.1 保姆级教程:手把手搞定Detectron2环境搭建(含Git加速与权限避坑)
Windows 11 CUDA 12.1 终极指南:零障碍搭建Detectron2开发环境 RTX 40系显卡用户注意了!如果你正在Windows 11上尝试搭建Detectron2开发环境,却苦于找不到针对CUDA 12.1的完整解决方案,这篇指南将为你扫清所有障碍。不同于网上那…...
)
从零搭建到百万QPS:Python MCP服务器模板实战对比(含Docker镜像体积、CI/CD兼容性、调试友好度全维度打分)
第一章:从零搭建到百万QPS:Python MCP服务器模板实战对比总览在构建高并发、低延迟的MCP(Model Control Protocol)服务时,Python凭借其生态丰富性与开发效率成为主流选型之一,但原生GIL限制与异步模型差异常…...

AutoGen Studio效果展示:看Qwen3-4B如何协作完成网页设计
AutoGen Studio效果展示:看Qwen3-4B如何协作完成网页设计 1. AutoGen Studio简介 AutoGen Studio是一个基于微软AutoGen框架开发的低代码界面工具,它让构建和组合AI代理变得简单直观。通过这个平台,你可以快速创建多个AI代理,为…...

CLIP-GmP-ViT-L-14图文匹配工具入门必看:上传图片+批量文本匹配全流程
CLIP-GmP-ViT-L-14图文匹配工具入门必看:上传图片批量文本匹配全流程 你是不是经常好奇,AI到底能不能看懂图片?比如,你给它一张小狗的照片,它能准确说出这是“一只狗”而不是“一只猫”或“一辆车”吗?今天…...

MongoDB高级面试:进阶面试题50题及答案详解
更多内容请见: 《深入掌握MongoDB数据库》 - 专栏介绍和目录 文章目录 一、高级查询优化与执行计划 (8题) 二、高级索引策略 (8题) 三、高级分片策略与优化 (8题) 四、性能调优与瓶颈分析 (7题) 五、高级复制集配置与故障处理 (6题) 六、高级事务与一致性模型 (5题) 七、安全高…...

告别桌面混乱:NoFences让文件管理效率提升80%的空间收纳方案
告别桌面混乱:NoFences让文件管理效率提升80%的空间收纳方案 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 每天在杂乱的桌面图标中寻找文件,就像在堆…...

抖音批量下载工具:高效获取无水印视频与图文内容的全攻略
抖音批量下载工具:高效获取无水印视频与图文内容的全攻略 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

使用seo站点管理系统需要注意哪些事项
SEO站点管理系统的核心注意事项 在当今数字化时代,SEO站点管理系统(Site Management System for SEO)是网站运营和推广的关键工具。它不仅能帮助提升网站在搜索引擎中的排名,还能带来更多的流量和转化。要真正利用这一工具&#x…...
`反而变慢了?Python 3.14 JIT缓存键生成算法变更深度解析(附3.13→3.14 ABI不兼容警告))
为什么你的`@jit(cache=True)`反而变慢了?Python 3.14 JIT缓存键生成算法变更深度解析(附3.13→3.14 ABI不兼容警告)
第一章:Python 3.14 JIT 编译器性能调优 面试题汇总Python 3.14 引入了实验性内置 JIT(Just-In-Time)编译器,基于 PGO(Profile-Guided Optimization)与轻量级字节码重写机制,在 CPU-bound 场景下…...

7个高效步骤:Meshroom开源三维重建工具从入门到精通
7个高效步骤:Meshroom开源三维重建工具从入门到精通 【免费下载链接】Meshroom 3D Reconstruction Software 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom 技术原理:三维重建的底层逻辑与技术选型 摄影测量技术的数学基础 三维重建技…...