YOLOv8最新改进系列:融合最新顶会提出的HCANet网络中卷积和注意力融合模块(CAFM),有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先!
YOLOv8最新改进系列:YOLOv8最新改进系列:融合最新顶会提出的HCANet网络中卷积和注意力融合模块(CAFM),有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先!
B站全文戳这里!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
截止到发稿时,B站YOLOv8最新改进系列的源码包,已更新40种+损失函数的改进!自己排列组合2-4种后,不考虑位置已达10万种以上改进方法!考虑位置不同后可排列上百万种!!专注AI学术,关注B站博主:Ai学术叫叫兽er!
YOLOv8最新改进系列:融合最新顶会提出的HCANet网络中卷积和注意力融合模块(CAFM),有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先!
HCANet提出原文戳这!
一、摘要
摘要高光谱图像去噪是高光谱数据有效分析和解释的关键。然而,同时建模全局和局部特征很少被探索以增强HSI去噪。在这封信中,我们提出了一个混合卷积和注意力网络(HCANet),它利用了卷积神经网络(CNN)和变压器的优势。为了增强全局和局部特征的建模,我们设计了一个卷积和注意力融合模块,旨在捕获长程依赖性和邻域光谱相关性。此外,为了改善多尺度信息聚合,我们设计了一个多尺度前馈网络,通过提取不同尺度的特征来提高去噪性能。在主流HSI数据集上的实验结果验证了HCANet的合理性和有效性。该模型能有效去除各种复杂噪声。我们的代码可在https://github.com/summitgao/HCANet上获得。
二、介绍
超光谱成像是一种强大的技术,它可以从物体或场景中获取丰富的光谱信息。与RGB数据相比,高光谱图像(HSI)捕获的光谱信息更精细。因此,HSI已被广泛用于许多实际应用中,例如解混[1]和地物分类[2]。然而,HSI经常受到传感器成像过程中不可避免的混合噪声的困扰,这是由于曝光时间和反射能量不足造成的。这些噪声可能会降低图像质量并妨碍后续分析和解释的性能。消除这些噪声可以提高地面目标检测和分类的准确性。因此,HSI去噪是许多遥感应用中预处理阶段的关键和不可缺少的技术。受HSI的空间和光谱特性的启发,传统的HSI去噪方法利用具有先验的优化方案,例如低秩[3],全变差[4],非局部相似性[5],虽然这些方法已经取得了可观的性能,但它们通常取决于手工先验和真实世界噪声模型之间的相似程度。近年来,卷积神经网络(CNN)[7]为HSI去噪提供了新的思路,表现出显着的性能进步。Maffei等人。[8]提出了一种基于CNN的HSI去噪模型,将噪声水平图作为输入来训练网络。Wang等人。[9]提出了一种基于联合Octave和注意力机制的卷积网络,用于HSI去噪。Pan等人。[10]提出了一种渐进的多尺度信息聚合网络,以消除HSI中的噪声。这些基于CNN的方法使用卷积核进行局部特征建模。最近,随着Vision Transformer(ViT)的出现,基于Transformer的方法在各种计算机视觉任务中取得了重大成功。现有的基于Transformer的图像去噪方法通过学习全局上下文信息取得了很大的成功。然而,如果局部特征被有效地考虑和利用,HSI去噪性能可能会进一步提高。因此,通过结合CNN和Transformers来考虑局部和全局信息以提高去噪性能是很重要的。由于以下两个挑战,为HSI去噪构建有效的Transformer和CNN混合模型通常是不平凡的:1)局部和全局特征建模的最佳混合架构仍然是一个悬而未决的问题。卷积核捕捉局部特征,这意味着失去了长距离的信息交互。卷积和注意力的结合可以提供一个可行的解决方案。2)Transformer中前馈网络的单尺度特征聚合受到限制。一些方法使用深度卷积来改善FFN中的局部特征聚合。然而,由于隐藏层中的信道数量较多,单尺度令牌聚合很难利用丰富的信道表示。为了解决上述两个挑战,我们提出了一种用于HSI去噪的混合卷积和注意力网络(HCANet),它同时利用全局上下文信息和局部特征,如图1所示。具体来说,为了增强全局和局部特征的建模,我们设计了一个卷积和注意力融合模块(CAFM),旨在捕获长程依赖性和邻域光谱相关性。此外,为了提高FFN中的多尺度信息聚合,我们设计了一个多尺度前馈网络(MSFN),通过提取不同尺度的特征来提高去噪性能。在MSFN中使用了三个具有不同步长的并行扩张卷积。通过在两个真实世界的数据集上进行实验,我们验证了我们提出的HCANet是上级优于其他国家的最先进的竞争对手。
这封信的贡献可以总结如下:
1.探索了用于HSI去噪的全局和局部特征建模的有前途但具有挑战性的问题。据我们所知,这是第一个将联合收割机卷积和注意力机制结合起来用于HSI去噪任务的工作。
2.提出了多尺度前馈网络,在不同尺度上无缝提取特征,有效抑制多尺度噪声。
3.在两个基准数据集上进行了大量实验,验证了HCANet的合理性和有效性。
结论
我们提出了HCANet,一种新的网络HSI去噪。特别是,我们提出了卷积和注意力融合模块,CAFM,融合全局和局部特征。此外,我们提出了多尺度前馈网络,MSFN从多个尺度提取特征,提高去噪性能。在具有挑战性的HSI数据集上的实验结果表明,与现有的HSI去噪方法相比,我们提出的模型是有效的。我们的模型实现了显着的去噪性能的定量指标和重建图像的视觉质量。
二、HCANet全文代码
import sys
import torch
import torch.nn as nn
import torch.nn.functional as F
from pdb import set_trace as stx
import numbersfrom einops import rearrange
import os
sys.path.append(os.getcwd())# m_seed = 1
# # 设置seed
# torch.manual_seed(m_seed)
# torch.cuda.manual_seed_all(m_seed)def to_3d(x):return rearrange(x, 'b c h w -> b (h w) c')def to_4d(x,h,w):return rearrange(x, 'b (h w) c -> b c h w',h=h,w=w)class BiasFree_LayerNorm(nn.Module):def __init__(self, normalized_shape):super(BiasFree_LayerNorm, self).__init__()if isinstance(normalized_shape, numbers.Integral):normalized_shape = (normalized_shape,)normalized_shape = torch.Size(normalized_shape)assert len(normalized_shape) == 1self.weight = nn.Parameter(torch.ones(normalized_shape))self.normalized_shape = normalized_shapedef forward(self, x):sigma = x.var(-1, keepdim=True, unbiased=False)return x / torch.sqrt(sigma+1e-5) * self.weightclass WithBias_LayerNorm(nn.Module):def __init__(self, normalized_shape):super(WithBias_LayerNorm, self).__init__()if isinstance(normalized_shape, numbers.Integral):normalized_shape = (normalized_shape,)normalized_shape = torch.Size(normalized_shape)assert len(normalized_shape) == 1self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.normalized_shape = normalized_shapedef forward(self, x):mu = x.mean(-1, keepdim=True)sigma = x.var(-1, keepdim=True, unbiased=False)return (x - mu) / torch.sqrt(sigma+1e-5) * self.weight + self.biasclass LayerNorm(nn.Module):def __init__(self, dim, LayerNorm_type):super(LayerNorm, self).__init__()if LayerNorm_type =='BiasFree':self.body = BiasFree_LayerNorm(dim)else:self.body = WithBias_LayerNorm(dim)def forward(self, x):h, w = x.shape[-2:]return to_4d(self.body(to_3d(x)), h, w)##########################################################################
## Multi-Scale Feed-Forward Network (MSFN)
class FeedForward(nn.Module):def __init__(self, dim, ffn_expansion_factor, bias):super(FeedForward, self).__init__()hidden_features = int(dim*ffn_expansion_factor)self.project_in = nn.Conv3d(dim, hidden_features*3, kernel_size=(1,1,1), bias=bias)self.dwconv1 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3,3,3), stride=1, dilation=1, padding=1, groups=hidden_features, bias=bias)# self.dwconv2 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3,3,3), stride=1, dilation=2, padding=2, groups=hidden_features, bias=bias)# self.dwconv3 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3,3,3), stride=1, dilation=3, padding=3, groups=hidden_features, bias=bias)self.dwconv2 = nn.Conv2d(hidden_features, hidden_features, kernel_size=(3,3), stride=1, dilation=2, padding=2, groups=hidden_features, bias=bias)self.dwconv3 = nn.Conv2d(hidden_features, hidden_features, kernel_size=(3,3), stride=1, dilation=3, padding=3, groups=hidden_features, bias=bias)self.project_out = nn.Conv3d(hidden_features, dim, kernel_size=(1,1,1), bias=bias)def forward(self, x):x = x.unsqueeze(2)x = self.project_in(x)x1,x2,x3 = x.chunk(3, dim=1)x1 = self.dwconv1(x1).squeeze(2)x2 = self.dwconv2(x2.squeeze(2))x3 = self.dwconv3(x3.squeeze(2))# x1 = self.dwconv1(x1)# x2 = self.dwconv2(x2)# x3 = self.dwconv3(x3)x = F.gelu(x1)*x2*x3x = x.unsqueeze(2)x = self.project_out(x)x = x.squeeze(2) return x##########################################################################
## Convolution and Attention Fusion Module (CAFM)
class Attention(nn.Module):def __init__(self, dim, num_heads, bias):super(Attention, self).__init__()self.num_heads = num_headsself.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))self.qkv = nn.Conv3d(dim, dim*3, kernel_size=(1,1,1), bias=bias)self.qkv_dwconv = nn.Conv3d(dim*3, dim*3, kernel_size=(3,3,3), stride=1, padding=1, groups=dim*3, bias=bias)self.project_out = nn.Conv3d(dim, dim, kernel_size=(1,1,1), bias=bias)self.fc = nn.Conv3d(3*self.num_heads, 9, kernel_size=(1,1,1), bias=True)self.dep_conv = nn.Conv3d(9*dim//self.num_heads, dim, kernel_size=(3,3,3), bias=True, groups=dim//self.num_heads, padding=1)def forward(self, x):b,c,h,w = x.shapex = x.unsqueeze(2)qkv = self.qkv_dwconv(self.qkv(x))qkv = qkv.squeeze(2)f_conv = qkv.permute(0,2,3,1) f_all = qkv.reshape(f_conv.shape[0], h*w, 3*self.num_heads, -1).permute(0, 2, 1, 3) f_all = self.fc(f_all.unsqueeze(2))f_all = f_all.squeeze(2)#local convf_conv = f_all.permute(0, 3, 1, 2).reshape(x.shape[0], 9*x.shape[1]//self.num_heads, h, w)f_conv = f_conv.unsqueeze(2)out_conv = self.dep_conv(f_conv) # B, C, H, Wout_conv = out_conv.squeeze(2)# global SAq,k,v = qkv.chunk(3, dim=1) q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)q = torch.nn.functional.normalize(q, dim=-1)k = torch.nn.functional.normalize(k, dim=-1)attn = (q @ k.transpose(-2, -1)) * self.temperatureattn = attn.softmax(dim=-1)out = (attn @ v)out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)out = out.unsqueeze(2)out = self.project_out(out)out = out.squeeze(2)output = out + out_convreturn output##########################################################################
## CAMixing Block
class TransformerBlock(nn.Module):def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type):super(TransformerBlock, self).__init__()self.norm1 = LayerNorm(dim, LayerNorm_type)self.attn = Attention(dim, num_heads, bias)self.norm2 = LayerNorm(dim, LayerNorm_type)self.ffn = FeedForward(dim, ffn_expansion_factor, bias)def forward(self, x):x = x + self.attn(self.norm1(x))x = x + self.ffn(self.norm2(x))return xclass OverlapPatchEmbed(nn.Module):def __init__(self, in_c=31, embed_dim=48, bias=False):super(OverlapPatchEmbed, self).__init__()self.proj = nn.Conv3d(in_c, embed_dim, kernel_size=(3,3,3), stride=1, padding=1, bias=bias)def forward(self, x):x = x.unsqueeze(2)x = self.proj(x)x = x.squeeze(2)return xclass Downsample(nn.Module):def __init__(self, n_feat):super(Downsample, self).__init__()self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat//2, kernel_size=3, stride=1, padding=1, bias=False),nn.PixelUnshuffle(2))def forward(self, x):# x = x.unsqueeze(2)x = self.body(x)# x = x.squeeze(2)return xclass Upsample(nn.Module):def __init__(self, n_feat):super(Upsample, self).__init__()self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat*2, kernel_size=3, stride=1, padding=1, bias=False),nn.PixelShuffle(2))def forward(self, x):# x = x.unsqueeze(2)x = self.body(x)# x = x.squeeze(2)return x##########################################################################
##---------- HCANet -----------------------
class HCANet(nn.Module):def __init__(self, inp_channels=31, out_channels=31, dim = 48,num_blocks = [2,3,3,4], num_refinement_blocks = 1,heads = [1,2,4,8],ffn_expansion_factor = 2.66,bias = False,LayerNorm_type = 'WithBias',):super(HCANet, self).__init__()self.patch_embed = OverlapPatchEmbed(inp_channels, dim)self.encoder_level1 = nn.Sequential(*[TransformerBlock(dim=dim, num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])self.down1_2 = Downsample(dim) self.encoder_level2 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])self.down2_3 = Downsample(int(dim*2**1)) self.encoder_level3 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])self.up3_2 = Upsample(int(dim*2**2)) self.reduce_chan_level2 = nn.Conv3d(int(dim*2**2), int(dim*2**1), kernel_size=(1,1,1), bias=bias)self.decoder_level2 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])self.up2_1 = Upsample(int(dim*2**1)) self.decoder_level1 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])self.refinement = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_refinement_blocks)])self.output = nn.Conv3d(int(dim*2**1), out_channels, kernel_size=(3,3,3), stride=1, padding=1, bias=bias)def forward(self, inp_img):inp_enc_level1 = self.patch_embed(inp_img)out_enc_level1 = self.encoder_level1(inp_enc_level1)inp_enc_level2 = self.down1_2(out_enc_level1)out_enc_level2 = self.encoder_level2(inp_enc_level2)inp_enc_level3 = self.down2_3(out_enc_level2)out_enc_level3 = self.encoder_level3(inp_enc_level3)out_dec_level3 = out_enc_level3inp_dec_level2 = self.up3_2(out_dec_level3)inp_dec_level2 = torch.cat([inp_dec_level2, out_enc_level2], 1)inp_dec_level2 = self.reduce_chan_level2(inp_dec_level2.unsqueeze(2))inp_dec_level2 = inp_dec_level2.squeeze(2)out_dec_level2 = self.decoder_level2(inp_dec_level2)inp_dec_level1 = self.up2_1(out_dec_level2)inp_dec_level1 = torch.cat([inp_dec_level1, out_enc_level1], 1)out_dec_level1 = self.decoder_level1(inp_dec_level1)out_dec_level1 = self.refinement(out_dec_level1)out_dec_level1 = self.output(out_dec_level1.unsqueeze(2)).squeeze(2) + inp_imgreturn out_dec_level1if __name__ == "__main__":model = HCANet()# print(model)# summary(model, (1,31,128,128))inputs = torch.ones([2,31,128,128]) #[b,c,h,w]outputs = model(inputs)print(outputs.size())三、 改进教程
2.1 修改YAML文件
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
2.2 新建HCANet.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
2.3 修改tasks.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
三、验证是否成功即可
执行命令
python train.py
改完收工!
关注B站:AI学术叫叫兽
从此走上科研快速路
遥遥领先同行!!!!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
相关文章:
,有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先!)
YOLOv8最新改进系列:融合最新顶会提出的HCANet网络中卷积和注意力融合模块(CAFM),有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先!
YOLOv8最新改进系列:YOLOv8最新改进系列:融合最新顶会提出的HCANet网络中卷积和注意力融合模块(CAFM),有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先! B站全文戳这里! 详细的改进教程以及源码…...
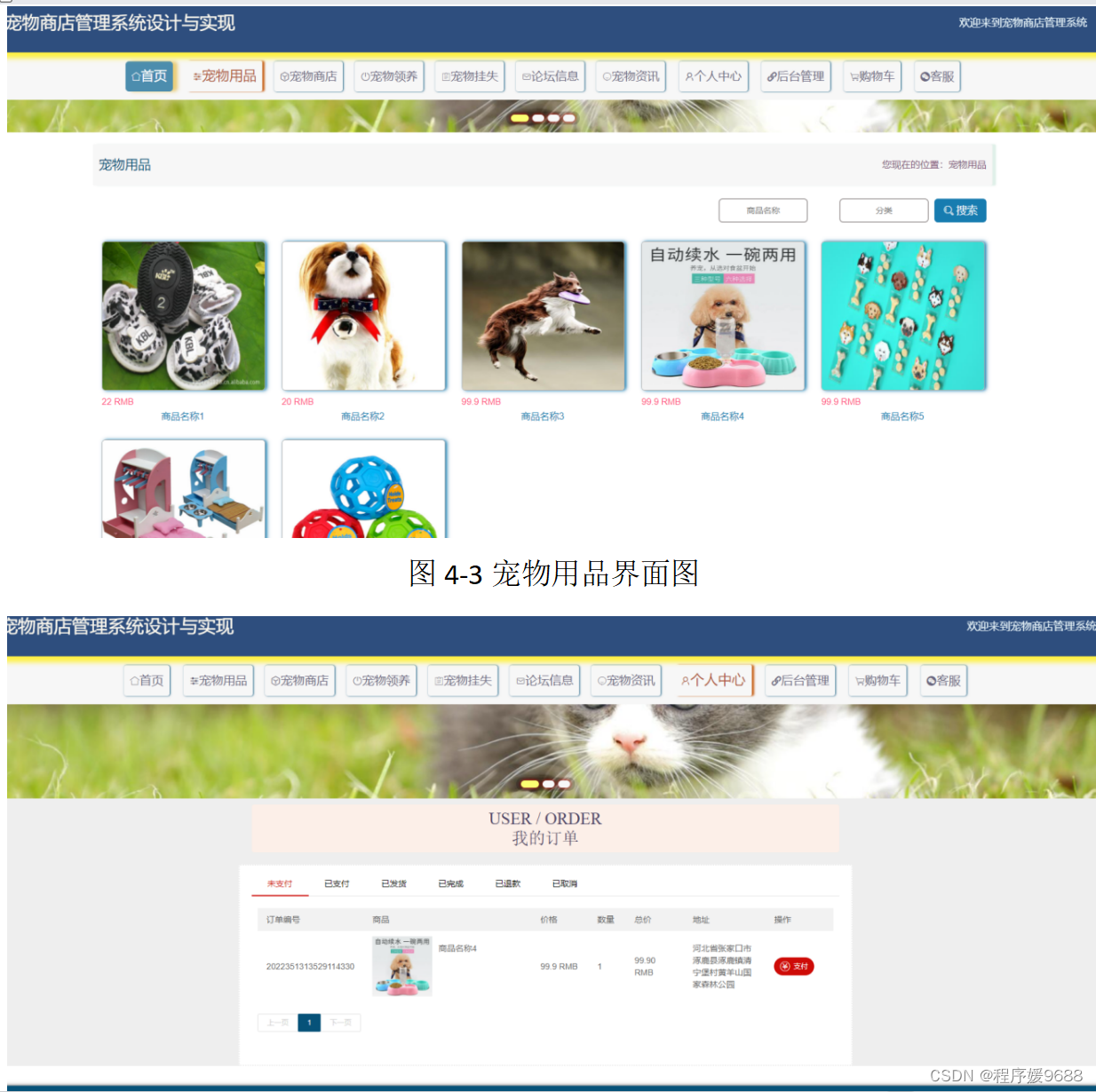
【计算机毕业设计】网上宠物商店管理系统——后附源码
🎉**欢迎来到我的技术世界!**🎉 📘 博主小档案: 一名来自世界500强的资深程序媛,毕业于国内知名985高校。 🔧 技术专长: 在深度学习任务中展现出卓越的能力,包括但不限于…...
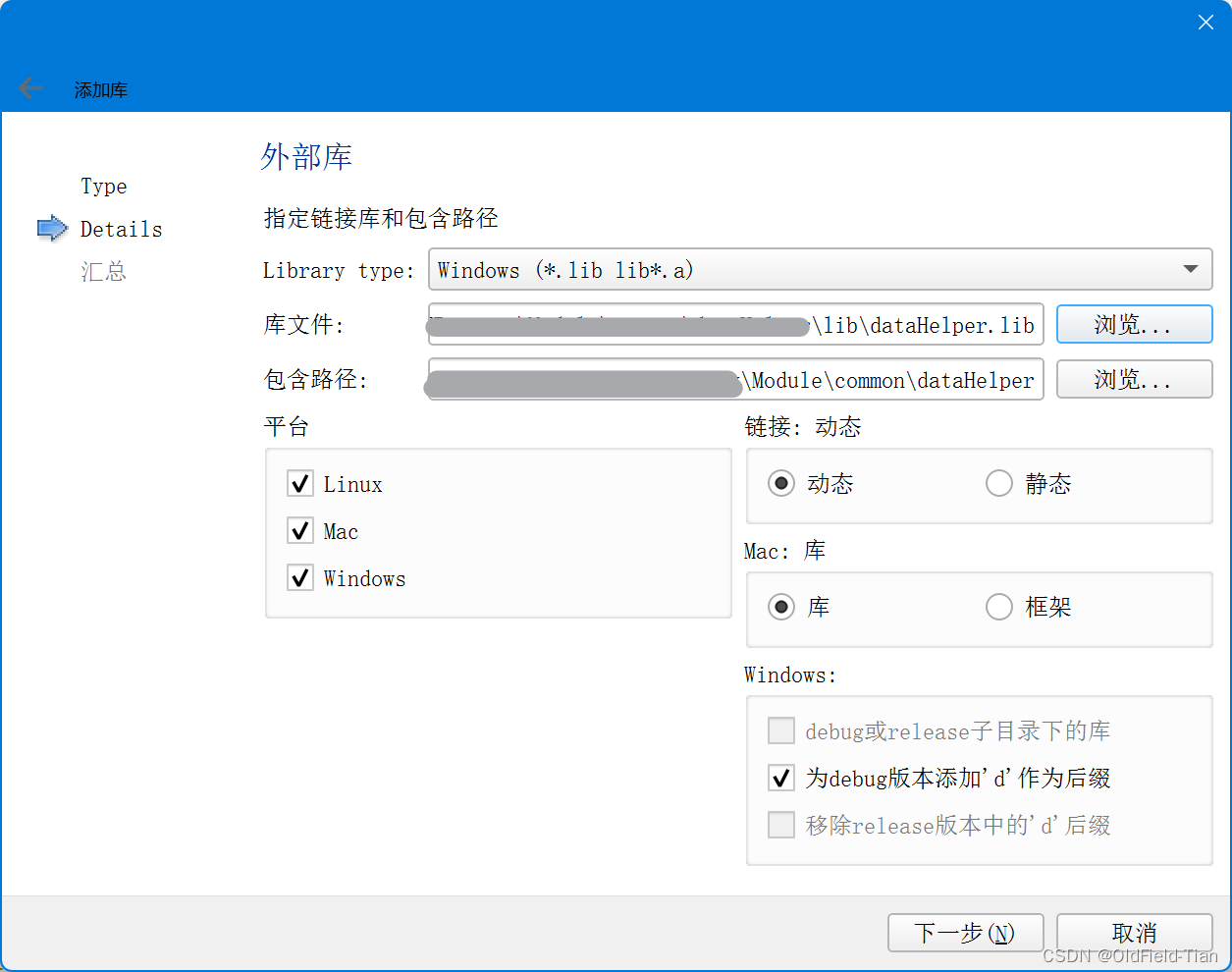
详解Qt添加外部库
在Qt项目中添加外部库是一项常见任务,无论是静态库还是动态库都需要正确的配置才能让项目顺利编译链接。以下是详细步骤和不同场景下的配置方法: 方法一:手动编辑.pro文件 添加头文件路径: 在Qt项目中的.pro文件中使用INCLUDEPAT…...
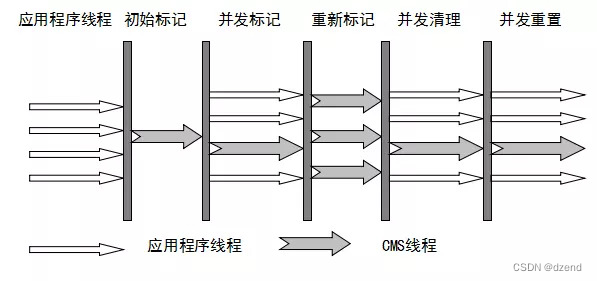
深入理解JVM垃圾收集器
相关系列 深入理解JVM垃圾收集算法-CSDN博客 目前市面常见的垃圾收集器有Serial、ParNew、Parallel、CMS、Serial Old、Parallel Old、G1、ZGC以及有二种不常见的Epsilon、Shenandoah的,从上图可以看到有连线的的垃圾收集器是可以组合使用,是年轻代老年代…...
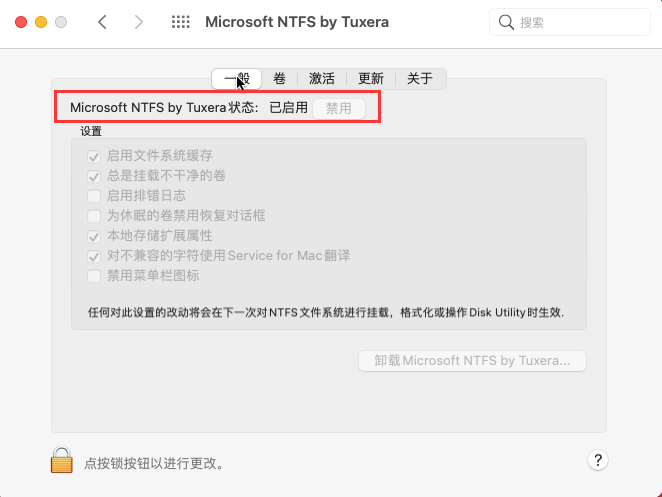
macU盘在电脑上读不出来 u盘mac读不出来怎么办 macu盘不能写入 Tuxera NTFS for Mac免费下载
对于Mac用户来说,使用U盘是很常见的操作,但有时候可能会遇到Mac电脑无法读取U盘的情况,这时候就需要使用一些特定的工具软件来帮助我们解决问题。本文就来告诉大家macU盘在电脑上读不出来是怎么回事,u盘mac读不出来怎么办。 一、m…...
)
448.找到所有数组中消失的数字(原地修改)
给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。 示例 1: 输入:nums [4,3,2,7,8,2,3,1] 输出:[5,6] 原地修改 …...
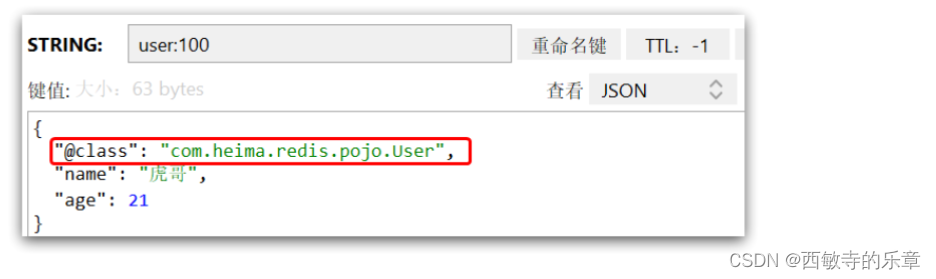
Redis学习从入门到掌握(基础篇)
文章目录 一、初识Redis1.认识 Redis2.Redis常见命令(1)Redis 数据结构介绍(2)Redis 通用命令(3)String 类型(4)String 类型的常见命令(5)Hash 类型ÿ…...
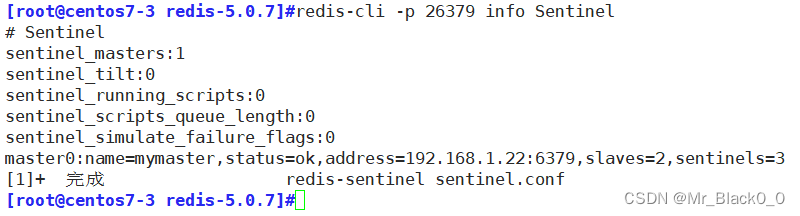
redis主从复制、哨兵
目录 1. 主从复制 特点: 工作原理: 配置: 2. 哨兵 特点: 工作原理: 配置: 编辑 1. 主从复制 特点: 主从复制是 Redis 最基本的高可用性方案。主节点(Master)…...

uniapp登录拦截白名单使用
1、创建uni.promisify.adaptor.js文件 // 根目录新建 uni.promisify.adaptor.js // 路由白名单 const list [/, /pages/stroke/stroke]; //创建路由拦截,这里只判断一般跳转 uni.addInterceptor(switchTab, {invoke(res) {console.log(res);//存在token就跳转if (…...
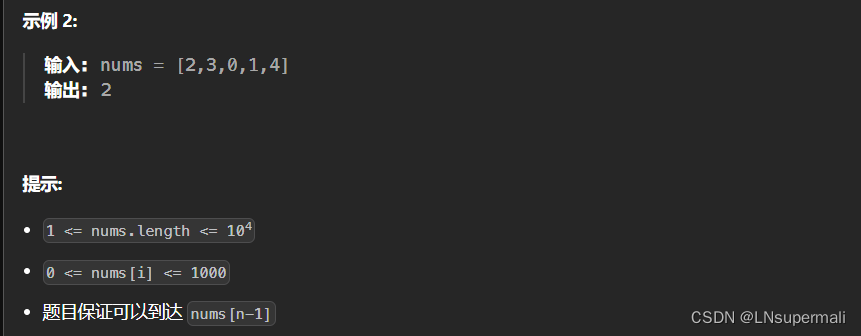
力扣45. 跳跃游戏 II
Problem: 45. 跳跃游戏 II 文章目录 题目描述思路复杂度Code 题目描述 思路 1.获取数组的长度len,定义int类型变量end用于标记每次在当前可以跳到的最远距离,farthest用于记录每次可以跳跃到的最远距离,jumps用于记录最小的跳跃次数ÿ…...

MXNet安装:专业指南与深度解析
一、引言 MXNet是一个高效且灵活的深度学习框架,它支持多种编程语言和平台,并提供了丰富的深度学习算法和工具。随着深度学习技术的广泛应用,MXNet因其出色的性能和易用性受到了越来越多开发者和研究人员的青睐。本文将详细介绍MXNet的安装过…...

C++函数模板案例--数组封装
目录 一、数组封装的需求 案例描述: 二、实操 创建.hpp文件,编写数组类。 浅拷贝危害 拷贝构造函数 “”重载 尾插法 尾删法 “[]"重载 返回数组容量、大小 完整代码 编写.cpp文件,对自定义数组进行测试。 打印数组函数 test01测试函数…...

传统文字检测方法+代码实现
文章目录 前言传统文字检测方法1、基于最大稳定极值区域(MSER)的文字检测1.1 MSER(MSER-Maximally Stable Extremal Regions)基本原理代码实现——使用Opencv中的cv2.MSER_create()接口 2、基于笔画宽度变换(Stroke Wi…...

Jmeter从数据为查找结果集数据方法随笔
一、Jmeter连接数据库 1.下载对应数据库的驱动包到jmeter安装目录的lib下ext文件中,并导入到jmeter的测试计划中,本实例中使用的是mysql如下所示: 点击测试计划–>点击浏览–>选中mysql驱动jar包–>打开 2.添加线程组,…...

Objective-C网络请求开发的高效实现方法与技巧
前言 在移动应用开发中,网络请求是一项至关重要的技术。Objective-C作为iOS平台的主要开发语言之一,拥有丰富的网络请求开发工具和技术。本文将介绍如何利用Objective-C语言实现高效的网络请求,以及一些实用的技巧和方法。 1.Objective-C技…...

Java:OOP之术语或概念
■■ 编程和程序设计 ■□ 程序员和编程■ 程序员:programmer■ 编程:program, programming■ 面向过程:Process oriented■ 面向对象:object-oriented● 面向对象分析:OOA,全称Object-oriented Analysis●…...
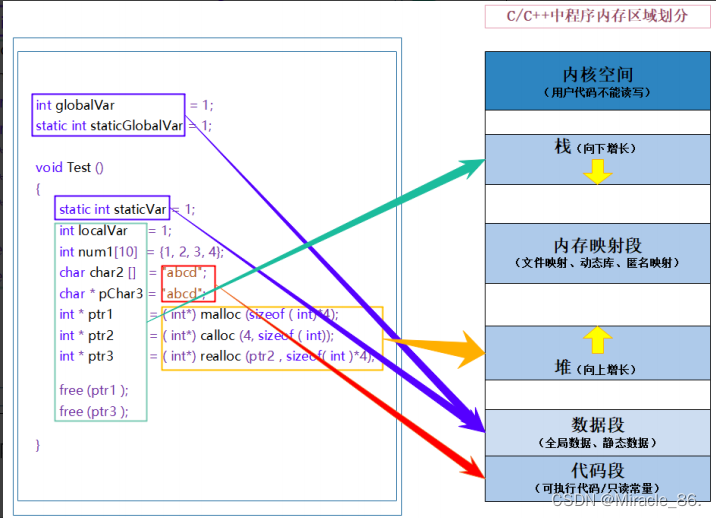
内存地产风云录:malloc、free、calloc、realloc演绎动态内存世界的楼盘开发与交易大戏
欢迎来到白刘的领域 Miracle_86.-CSDN博客 系列专栏 C语言知识 先赞后看,已成习惯 创作不易,多多支持! 在这个波澜壮阔的内存地产世界中,malloc、free、calloc和realloc四位主角,共同演绎着一场场精彩绝伦的楼盘开…...
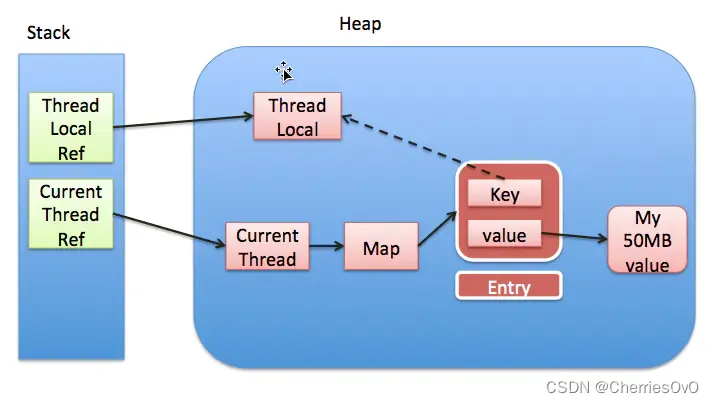
个人博客项目笔记_05
1. ThreadLocal内存泄漏 ThreadLocal 内存泄漏是指由于没有及时清理 ThreadLocal 实例所存储的数据,导致这些数据在线程池或长时间运行的应用中累积过多,最终导致内存占用过高的情况。 内存泄漏通常发生在以下情况下: 线程池场景下的 ThreadL…...
)
基础知识点全覆盖(1)
Python基础知识点 1.基本语句 1.注释 方便阅读和调试代码注释的方法有行注释和块注释 1.行注释 行注释以 **# **开头 # 这是单行注释2.块注释 块注释以多个 #、三单引号或三双引号(注意: 基于英文输入状态下的标点符号) # 类 # 似 # 于 # 多 # 行 # 效 # 果 这就是多行注释…...

异常处理java
在Java中,异常处理可以使用"throws"关键字或者"try-catch"语句。这两种方法有不同的用途和适用场景。 "throws"关键字: 在方法声明中使用"throws"关键字,表示该方法可能会抛出异常,但是并不立即处理…...

2025届学术党必备的五大降重复率方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下知网已然上线了AI检测功能,会针对论文里疑似人工智能生成的内容展开识别。为…...

拾亩绿光纯亚麻籽微粉效果怎么样
很多人想通过亚麻籽补充营养,却常遇到传统亚麻籽难吸收、营养易流失的问题:直接嚼咽口感粗糙,普通研磨粉冲调结块,榨油后Omega-3等核心营养大量损耗。拾亩绿光纯亚麻籽微粉依托南京国英健康科技有限公司的专利技术,可解…...
)
Excel数据同步ERP/CRM太麻烦?一个Python脚本搞定多系统自动填充(基于GoBot)
Excel数据同步ERP/CRM太麻烦?一个Python脚本搞定多系统自动填充(基于GoBot) 每次月底看着财务同事在ERP系统里逐条录入Excel数据,市场部同事又在CRM里重复同样的操作,这种低效场景你一定不陌生。数据在不同系统间的孤岛…...

计算机视觉十年演进:从手工特征到工业落地实战
1. 计算机视觉的十年跃迁:从手工特征到端到端理解2012年,AlexNet在ImageNet大赛上以15.3%的错误率碾压第二名10.8个百分点,整个计算机视觉领域像被按下了快进键。那会儿我在实验室调试SIFT特征匹配,光是调一个尺度参数就要跑三小时…...

告别信号混乱!手把手教你正确处理Qt QLineEdit的编辑完成与回车事件
告别信号混乱!手把手教你正确处理Qt QLineEdit的编辑完成与回车事件 在Qt开发中,QLineEdit作为最常用的输入控件之一,其信号处理看似简单却暗藏玄机。许多开发者都曾遇到过这样的困扰:明明只想在用户完成编辑时触发一次验证逻辑&a…...

如何彻底移除Windows Defender?5步掌握完整安全组件卸载指南
如何彻底移除Windows Defender?5步掌握完整安全组件卸载指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirro…...

居家办公网络优化指南:从Wi-Fi原理到实战部署
1. 居家隔离如何压垮了我们的家庭Wi-Fi网络如果你在2020年初也经历过居家办公或学习,大概率会对某个场景记忆犹新:视频会议卡成PPT、在线课程频繁掉线、追剧时那个转不完的缓冲圈。这不是你一个人的问题,而是全球无数家庭网络在特定时期承受的…...

FILCO架构:动态可重构DNN加速器设计解析
1. FILCO架构设计背景与核心挑战深度神经网络(DNN)加速器设计正面临一个根本性矛盾:专用架构在特定负载下能达到峰值效率,但实际应用中工作负载的多样性日益增长。以自动驾驶系统为例,单个任务流程可能同时包含MLP分类器、Transformer视觉模型…...

在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用 对于构建AI功能的后端Node.js开发者而言,直接对接单一模型供…...
)
毕设成品 深度学习安全帽佩戴检测(源码+论文)
文章目录 0 前言🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力…...