二手车价格预测第十三名方案总结
代码开源链接:GitHub - wujiekd/Predicting-used-car-prices: 阿里天池与Datawhale联合举办二手车价格预测比赛:优胜奖方案代码总结
比赛介绍
赛题以二手车市场为背景,要求选手预测二手汽车的交易价格,这是一个典型的回归问题。
其他具体流程可以看比赛官网。
数据处理
1、box-cox变换目标值“price”,解决长尾分布。
2、删除与目标值无关的列,例如“SaleID”,“name”。这里可以挖掘一下“name”的频度作为新的特征。
3、异常点处理,删除训练集特有的数据,例如删除“seller”==1的值。
4、缺失值处理,分类特征填充众数,连续特征填充平均值。
5、其他特别处理,把取值无变化的列删掉。
6、异常值处理,按照题目要求“power”位于0~600,因此把“power”>600的值截断至600,把"notRepairedDamage"的非数值的值替换为np.nan,让模型自行处理。
特征工程
1、时间地区类
从“regDate”,“creatDate”可以获得年、月、日等一系列的新特征,然后做差可以获得使用年长和使用天数这些新特征。
“regionCode”没有保留。
因为尝试了一系列方法,并且发现了可能会泄漏“price”,因此最终没保留该特征。
2、分类特征
对可分类的连续特征进行分桶,kilometer是已经分桶了。
然后对"power"和"model"进行了分桶。
使用分类特征“brand”、“model”、“kilometer”、“bodyType”、“fuelType”与“price”、“days”、“power”进行特征交叉。
交叉主要获得的是后者的总数、方差、最大值、最小值、平均数、众数、峰度等等
这里可以获得非常多的新特征,挑选的时候,直接使用lightgbm帮我们去选择特征,一组组的放进去,最终保留了以下特征。(注意:这里使用1/4的训练集进行挑选可以帮助我们更快的锁定真正Work的特征)
'model_power_sum','model_power_std',
'model_power_median', 'model_power_max',
'brand_price_max', 'brand_price_median',
'brand_price_sum', 'brand_price_std',
'model_days_sum','model_days_std',
'model_days_median', 'model_days_max',
'model_amount','model_price_max',
'model_price_median','model_price_min',
'model_price_sum', 'model_price_std',
'model_price_mean'
3、连续特征
使用了置信度排名靠前的匿名特征“v_0”、“v_3”与“price”进行交叉,测试方法以上述一样,效果并不理想。
因为都是匿名特征,比较训练集和测试集分布,分析完基本没什么问题,并且它们在lightgbm的输出的重要性都是非常高的,所以先暂且全部保留。
4、补充特征工程
主要是对输出重要度非常高的特征进行处理
特征工程一期:
对14个匿名特征使用乘法处理得到14*14个特征
使用sklearn的自动特征选择帮我们去筛选,大概运行了半天的时间。
大致方法如下:
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LinearRegression
sfs = SFS(LGBMRegressor(n_estimators = 1000,objective='mae' ),k_features=50,forward=True,floating=False,cv = 0)sfs.fit(X_data, Y_data)
print(sfs.k_feature_names_)
最终筛选得到:
'new3*3', 'new12*14', 'new2*14','new14*14'
特征工程二期:
对14个匿名特征使用加法处理得到14*14个特征
这次不选择使用自动特征选择了,因为运行实在太慢了,笔记本耗不起。
使用的方法是删除相关性高的变量,把要删除的特征记录下来
大致方法如下:(剔除相关度>0.95的)
corr = X_data.corr(method='spearman')
feature_group = list(itertools.combinations(corr.columns, 2))
print(feature_group)# 删除相关性高的变量,调试好直接去主函数进行剔除
def filter_corr(corr, cutoff=0.7):cols = []for i,j in feature_group:if corr.loc[i, j] > cutoff:print(i,j,corr.loc[i, j])i_avg = corr[i][corr[i] != 1].mean()j_avg = corr[j][corr[j] != 1].mean()if i_avg >= j_avg:cols.append(i)else:cols.append(j)return set(cols)drop_cols = filter_corr(corr, cutoff=0.95)
print(drop_cols)
最终获得的应该删除的特征为:
['new14+6', 'new13+6', 'new0+12', 'new9+11', 'v_3', 'new11+10', 'new10+14', 'new12+4', 'new3+4', 'new11+11', 'new13+3', 'new8+1', 'new1+7', 'new11+14', 'new8+13', 'v_8', 'v_0', 'new3+5', 'new2+9', 'new9+2', 'new0+11', 'new13+7', 'new8+11', 'new5+12', 'new10+10', 'new13+8', 'new11+13', 'new7+9', 'v_1', 'new7+4', 'new13+4', 'v_7', 'new5+6', 'new7+3', 'new9+10', 'new11+12', 'new0+5', 'new4+13', 'new8+0', 'new0+7', 'new12+8', 'new10+8', 'new13+14', 'new5+7', 'new2+7', 'v_4', 'v_10', 'new4+8', 'new8+14', 'new5+9', 'new9+13', 'new2+12', 'new5+8', 'new3+12', 'new0+10', 'new9+0', 'new1+11', 'new8+4', 'new11+8', 'new1+1', 'new10+5', 'new8+2', 'new6+1', 'new2+1', 'new1+12', 'new2+5', 'new0+14', 'new4+7', 'new14+9', 'new0+2', 'new4+1', 'new7+11', 'new13+10', 'new6+3', 'new1+10', 'v_9', 'new3+6', 'new12+1', 'new9+3', 'new4+5', 'new12+9', 'new3+8', 'new0+8', 'new1+8', 'new1+6', 'new10+9', 'new5+4', 'new13+1', 'new3+7', 'new6+4', 'new6+7', 'new13+0', 'new1+14', 'new3+11', 'new6+8', 'new0+9', 'new2+14', 'new6+2', 'new12+12', 'new7+12', 'new12+6', 'new12+14', 'new4+10', 'new2+4', 'new6+0', 'new3+9', 'new2+8', 'new6+11', 'new3+10', 'new7+0', 'v_11', 'new1+3', 'new8+3', 'new12+13', 'new1+9', 'new10+13', 'new5+10', 'new2+2', 'new6+9', 'new7+10', 'new0+0', 'new11+7', 'new2+13', 'new11+1', 'new5+11', 'new4+6', 'new12+2', 'new4+4', 'new6+14', 'new0+1', 'new4+14', 'v_5', 'new4+11', 'v_6', 'new0+4', 'new1+5', 'new3+14', 'new2+10', 'new9+4', 'new2+6', 'new14+14', 'new11+6', 'new9+1', 'new3+13', 'new13+13', 'new10+6', 'new2+3', 'new2+11', 'new1+4', 'v_2', 'new5+13', 'new4+2', 'new0+6', 'new7+13', 'new8+9', 'new9+12', 'new0+13', 'new10+12', 'new5+14', 'new6+10', 'new10+7', 'v_13', 'new5+2', 'new6+13', 'new9+14', 'new13+9', 'new14+7', 'new8+12', 'new3+3', 'new6+12', 'v_12', 'new14+4', 'new11+9', 'new12+7', 'new4+9', 'new4+12', 'new1+13', 'new0+3', 'new8+10', 'new13+11', 'new7+8', 'new7+14', 'v_14', 'new10+11', 'new14+8', 'new1+2']]
特征工程三、四期:
这两期的效果不明显,为了不让特征冗余,所以选择不添加这两期的特征,具体的操作可以在feature处理的代码中看到。
5、神经网络的特征工程补充说明
以上特征工程处理都是针对于树模型来进行的,接下来,简单说明神经网络的数据预处理。
各位都知道由于NN的不可解释性,可以生成大量的我们所不清楚的特征,因此我们对于NN的数据预处理只要简单处理异常值以及缺失值。
大部分的方法都包含在以上针对树模型数据处理方法中,重点讲述几个不同点:
在对于“notRepairedDamage”的编码处理,对于二分类的缺失值,往往取其中间值。
在对于其他缺失值的填充,在测试了效果后,发现填充众数的效果比平均数更好,因此均填充众数。
选择的模型
本次比赛,我选择的是lightgbm+catboost+neural network。
本来也想使用XGBoost的,不过因为它需要使用二阶导,因此目标函数没有MAE,并且用于逼近的一些自定义函数效果也不理想,因此没有选择使用它。
经过上述的数据预处理以及特征工程:
树模型的输入有83个特征;神经网络的输入有29个特征。
1、lightgbm和catboost:
因为它们都是树模型,因此我同时对这两个模型进行分析
第一:lgb和cab的训练收敛速度非常快,比同样参数的xgb快非常多。
第二:它们可以处理缺失值,计算取值的增益,择优录取。
第三:调整正则化系数,均使用正则化,防止过拟合。
第四:降低学习率,获得更小MAE的验证集预测输出。
第五:调整早停轮数,防止陷入过拟合或欠拟合。
第六:均使用交叉验证,使用十折交叉验证,减小过拟合。
其他参数设置无明显上分迹象,以代码为准,不一一阐述。
查看本文全部内容,欢迎访问天池技术圈官方地址:二手车价格预测第十三名方案总结_天池技术圈-阿里云天池
相关文章:

二手车价格预测第十三名方案总结
代码开源链接:GitHub - wujiekd/Predicting-used-car-prices: 阿里天池与Datawhale联合举办二手车价格预测比赛:优胜奖方案代码总结 比赛介绍 赛题以二手车市场为背景,要求选手预测二手汽车的交易价格,这是一个典型的回归问题。…...
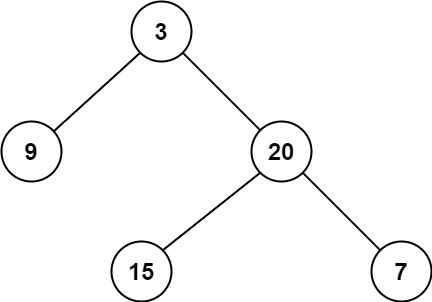
力扣刷题 二叉树层序遍历相关题目II
NO.116 填充每个节点的下一个右侧节点指针 给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下: struct Node {int val;Node *left;Node *right;Node *next; } 填充它的每个 next 指针,…...

智能电网将科技拓展至工厂之外的领域
【摘要/前言】 物联网已然颠覆我们日常生活的许多层面。在家居方面,家电变成连网设备,不仅让我们能控制灯光与上网购物,甚至在出门时提供安全功能。在工业领域,智能工厂改变产品制造的方式。工业物联网(IIoT)不仅让制造商更加敏捷…...

单列模式1.0
单列模式 单例模式能保证某个类在程序中只存在唯⼀⼀份实例, ⽽不会创建出多个实例 1.饿汉模式 只要程序一启动就会立即创建出一个对象 class Signleton{private static Signleton instancenew Signleton();//防止在以后的代码中再创建对象,我们将构造方法private,…...

golang kafka sarama源码分析
一些理论 1.topic支持多分区,每个分区只能被组内的一个消费者消费,一个消费者可能消费多个分区的数据; 2.消费者组重平衡的分区策略,是由消费者自己决定的,具体是从消费者组中选一个作为leader进行分区方案分配&#…...
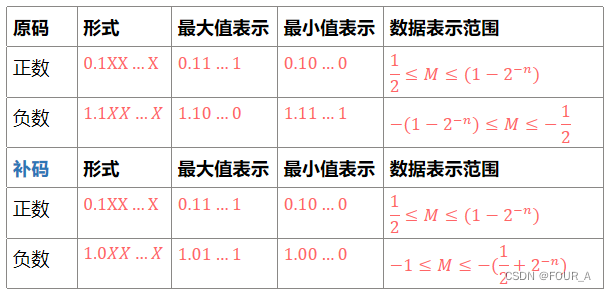
计算机组成原理【CO】Ch2 数据的表示和应用
文章目录 大纲2.1 数制与编码2.2 运算方法和运算电路2.3 浮点数的表示和运算 【※】带标志加法器OFSFZFCF计算机怎么区分有符号数无符号数? 【※】存储排列和数据类型转换数据类型大小数据类型转换 进位计数制进制转换2的次幂 各种码的基本特性无符号整数的表示和运算带符号整…...

dfs回溯 -- Leetcode46. 全排列
题目链接:46. 全排列 题目描述 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示…...
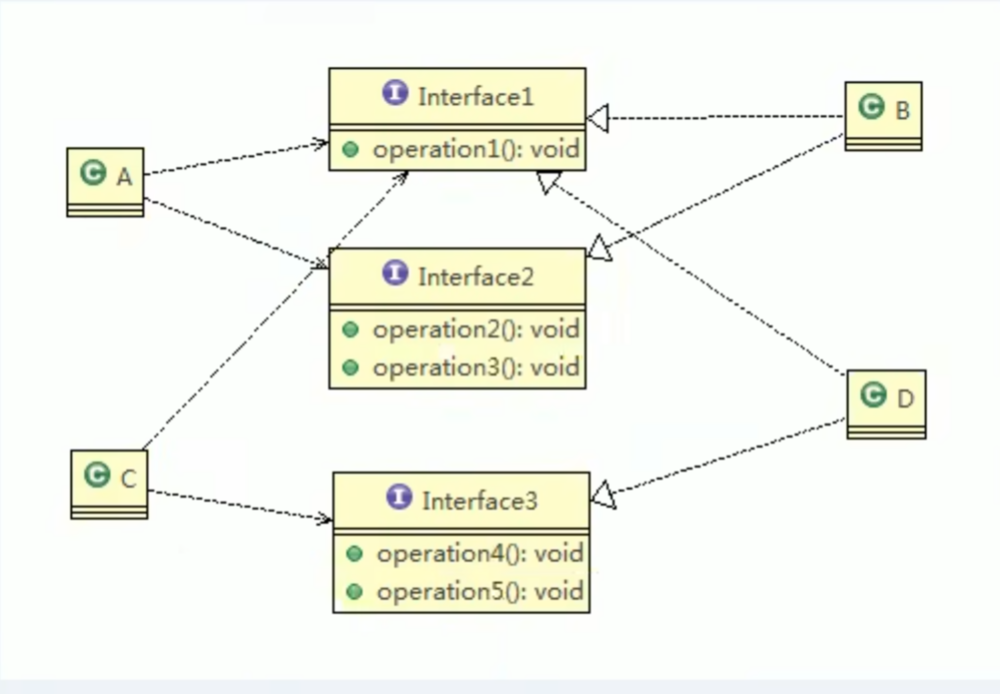
设计模式-接口隔离原则
基本介绍 客户端不应该依赖它不需要的接口,即一个类对另一个类的依赖应该建立在最小的接口上先看一张图: 类A通过接口Interface1 依赖类B,类C通过接口Interface1 依赖类D,如果接口Interface1对于类A和类C来说不是最小接口,那么类…...
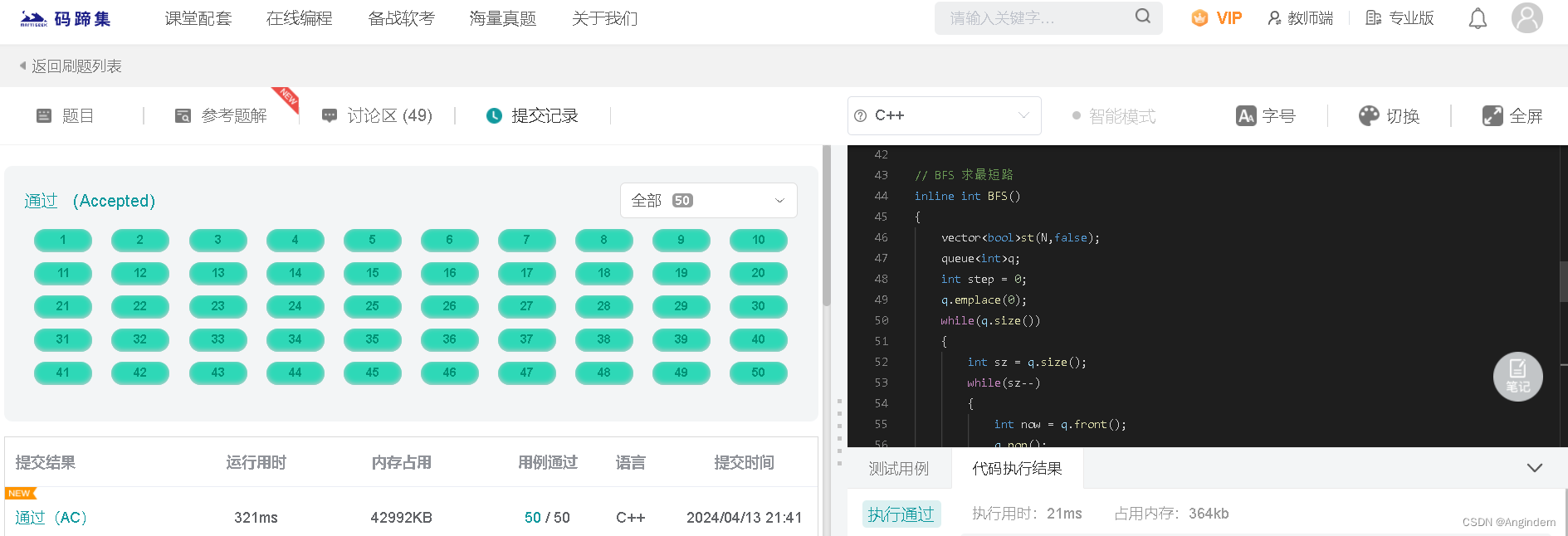
BD202311夏日漫步(最少步数,BFS或者 Dijstra)
本题链接:码蹄集 题目: 夏日夜晚,小度看着庭院中长长的走廊,萌发出想要在上面散步的欲望,小度注意到月光透过树荫落在地砖上,并且由于树荫的遮蔽度不通,所以月光的亮度不同,为了直…...

React - 你知道props和state之间深层次的区别吗
难度级别:初级及以上 提问概率:60% 如果把React组件看做一个函数的话,props更像是外部传入的参数,而state更像是函数内部定义的变量。那么他们还有哪些更深层次的区别呢,我们来看一下。 首先说props,他是组件外部传入的参数,我们知道…...
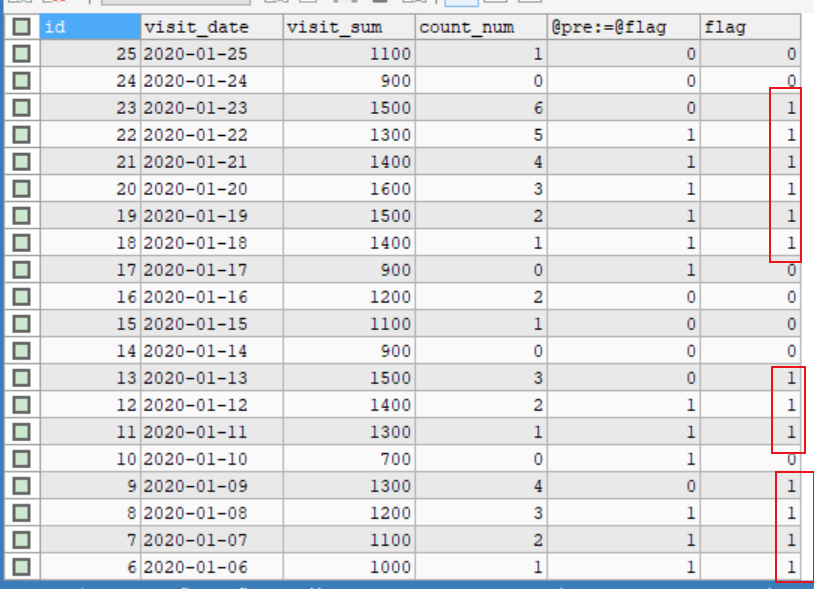
mysql 查询实战-变量方式-解答
对mysql 查询实战-变量方式-题目,进行一个解答。(先看题,先做,再看解答) 1、查询表中⾄少连续三次的数字 1,处理思路 要计算连续出现的数字,加个前置变量,记录上一个的值,…...

SpringBoot3配置SpringSecurity6
访问1:localhost:8080/security,返回:需要先认证才能访问(说明没有权限) 访问2:localhost:8080/anonymous,返回:anonymous(说明正常访问) 相关文件如下&…...
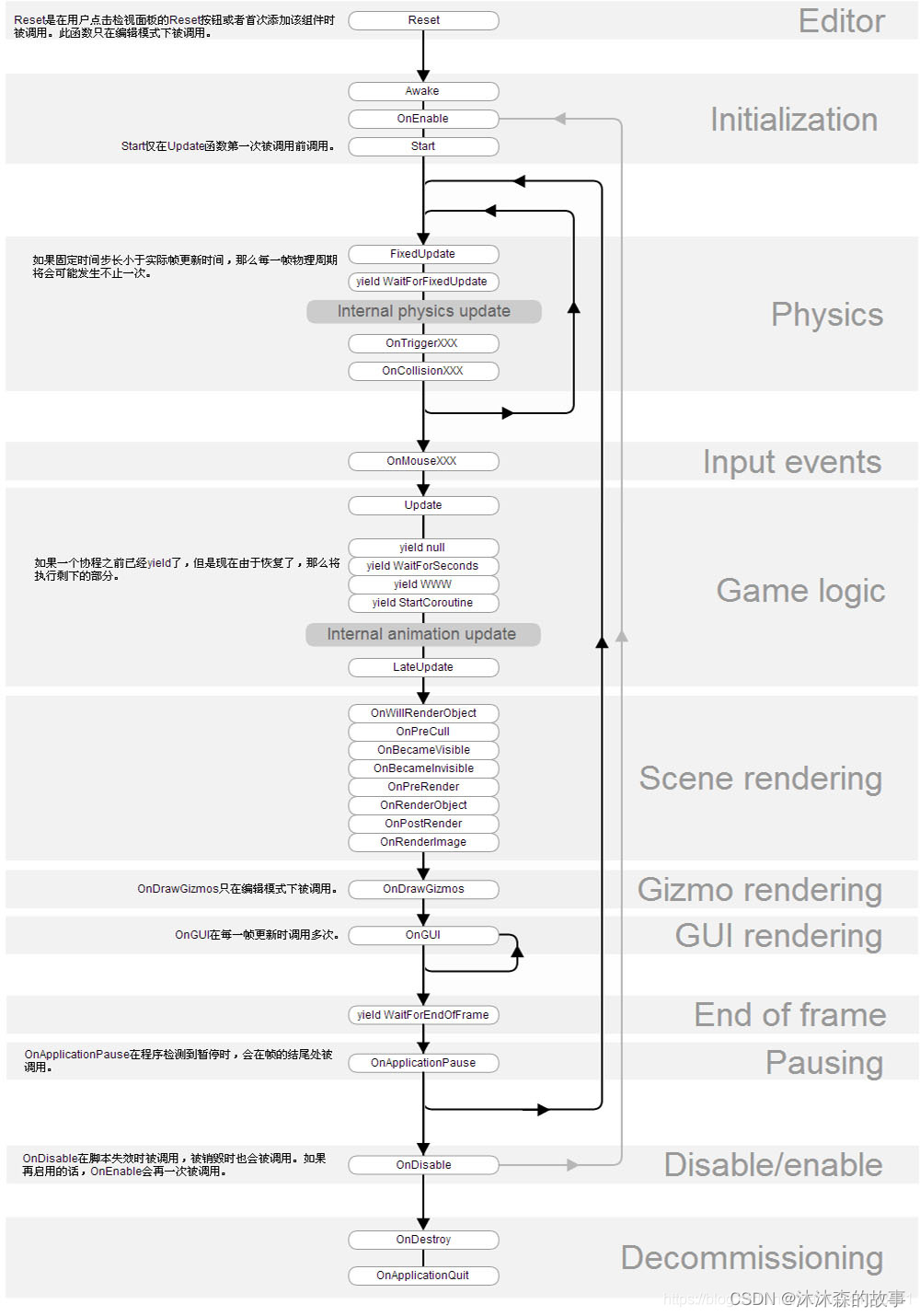
Unity之Unity面试题(三)
内容将会持续更新,有错误的地方欢迎指正,谢谢! Unity之Unity面试题(三) TechX 坚持将创新的科技带给世界! 拥有更好的学习体验 —— 不断努力,不断进步,不断探索 TechX —— 心探索、心进取…...
)
Linux命令-dos2unix命令(将DOS格式文本文件转换成Unix格式)
说明 dos2unix命令 用来将DOS格式的文本文件转换成UNIX格式的(DOS/MAC to UNIX text file format converter)。DOS下的文本文件是以 \r\n 作为断行标志的,表示成十六进制就是0D0A。而Unix下的文本文件是以\n作为断行标志的,表示成…...

企业怎么做数据分析
数据分析在当今信息化时代扮演着至关重要的角色。能够准确地收集、分析和利用数据,对企业的决策和发展都具有重要意义。数聚将介绍企业如何合理地利用数据分析,如何协助企业在竞争激烈的市场中取得优势。 一、建立完善的数据收集系统 在进行数据分析之…...

1111111111
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm1001.2014.3001.5343 给大家分享一句我很喜欢我话: 知不足而奋进,望远山而前行&am…...
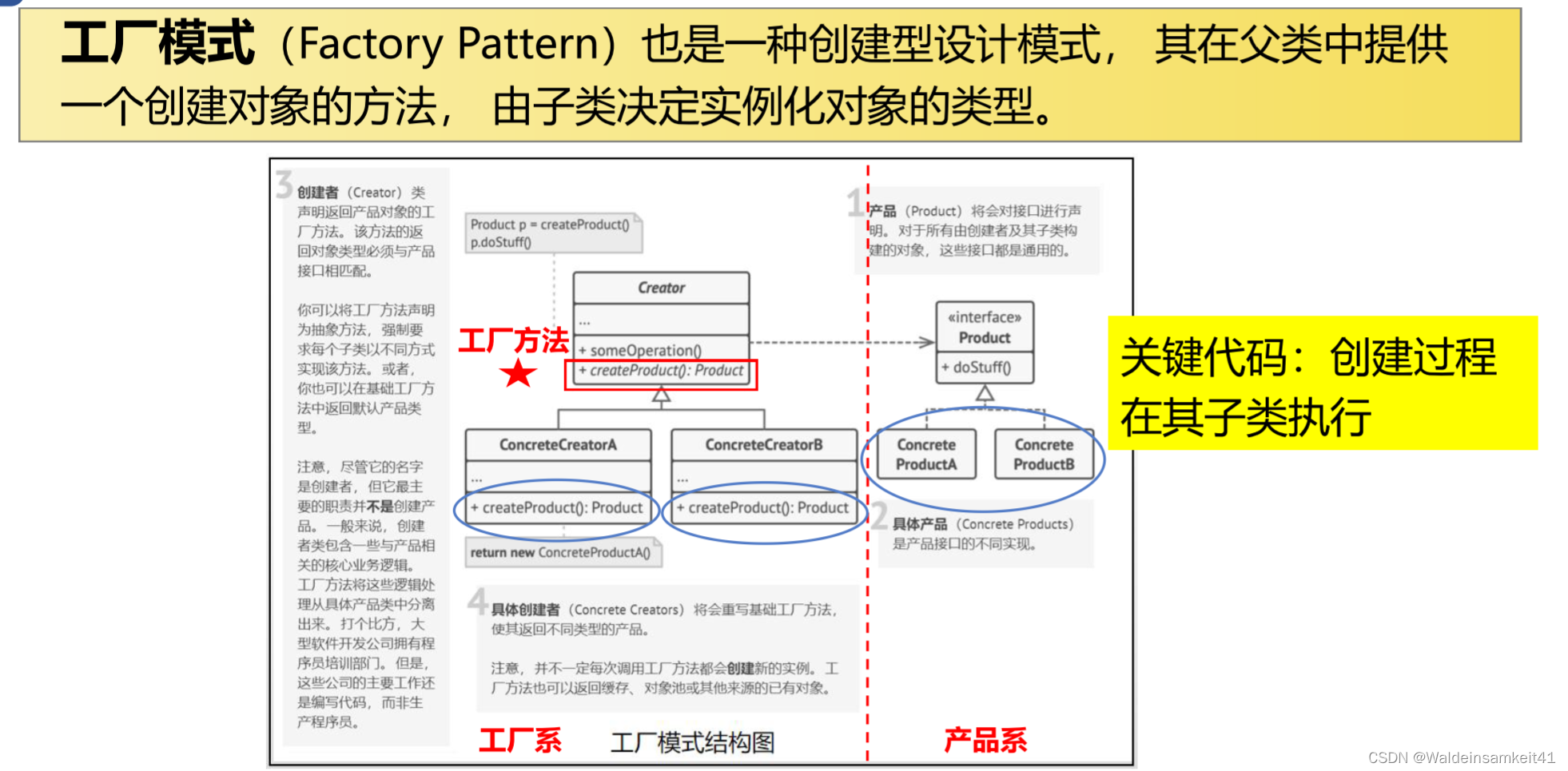
[面向对象] 单例模式与工厂模式
单例模式 是一种创建模式,保证一个类只有一个实例,且提供访问实例的全局节点。 工厂模式 面向对象其中的三大原则: 单一职责:一个类只有一个职责(Game类负责什么时候创建英雄机,而不需要知道创建英雄机要…...
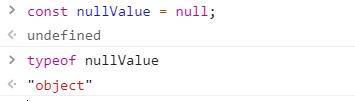
《前端防坑》- JS基础 - 你觉得typeof nullValue === null 么?
问题 JS原始类型有6种Undefined, Null, Number, String, Boolean, Symbol共6种。 在对原始类型使用typeof进行判断时, typeof stringValue string typeof numberValue number 如果一个变量(nullValue)的值为null,那么typeof nullValue "?" const u …...
【项目实战经验】DataKit迁移MySQL到openGauss(下)
上一篇我们分享了安装、设置、链接、启动等步骤,本篇我们将继续分享迁移、启动~ 目录 9. 离线迁移 9.1. 迁移插件安装 中断安装,比如 kill 掉java进程(安装失败也要等待300s) 下载安装包准备上传 缺少mysqlclient lib包 mysq…...
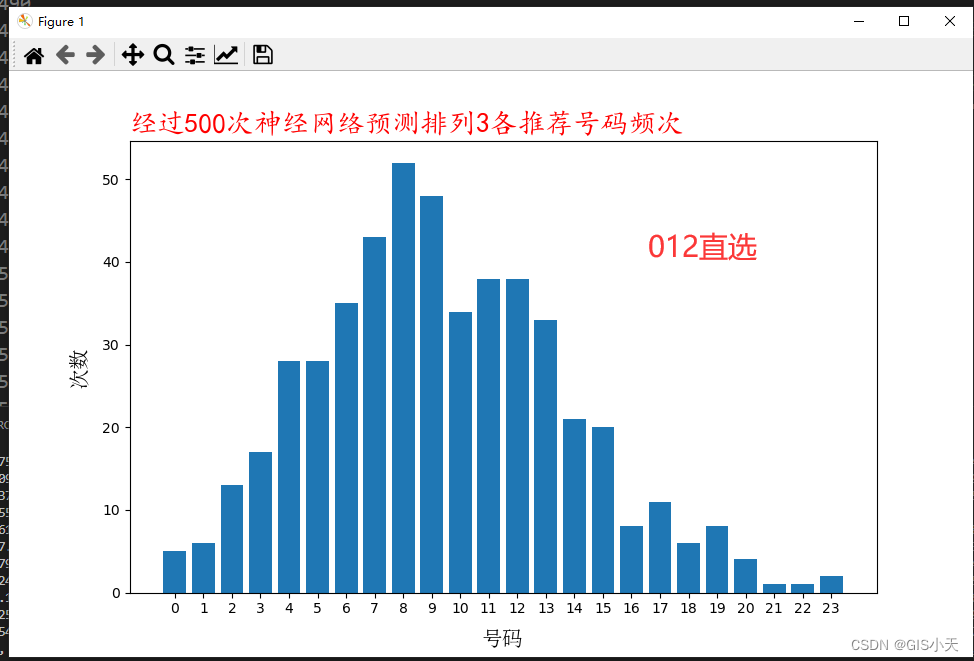
AI预测体彩排3第2弹【2024年4月13日预测--第1套算法开始计算第2次测试】
各位小伙伴,今天实在抱歉,周末回了趟老家,回来比较晚了,数据今天上午跑完后就回老家了,晚上8点多才回来,赶紧把预测结果发出来吧,虽然有点晚了,但是咱们前面说过了,目前的…...

Logseq AI助手插件:在知识管理笔记中集成ChatGPT智能写作与编辑
1. 项目概述:在Logseq中引入你的AI副驾驶 如果你和我一样,是个重度依赖Logseq来构建个人知识库的笔记爱好者,同时又对AI辅助写作和思考的潜力充满好奇,那么你肯定不止一次想过:要是能把ChatGPT的能力无缝集成到Logseq…...

5分钟搞定魔兽争霸3兼容性问题:终极优化工具完全指南
5分钟搞定魔兽争霸3兼容性问题:终极优化工具完全指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电脑上的各种兼…...

RPFM:全面战争MOD开发的终极效率提升指南
RPFM:全面战争MOD开发的终极效率提升指南 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https://gitcode.com/gh_…...

别再只会用strlen了!CAPL脚本字符串处理实战:从CAN报文解析到日志格式化
CAPL脚本字符串处理实战:从CAN报文解析到日志格式化 在汽车电子测试领域,CAPL脚本是Vector工具链(如CANoe/CANalyzer)中不可或缺的组成部分。字符串处理作为基础却关键的操作,直接影响着测试脚本的效率和可靠性。本文将…...
)
跟着 MDN 学 HTML day_36:(深入理解 Comment 接口与 DOM 注释节点)
在前端开发中,注释是开发者之间无声的对话。它们在页面上不可见,却在源代码中承载着说明、标记、甚至条件逻辑的重要职责。在 DOM 体系中,HTML 或 XML 中的每一条注释都会被解析为一个 Comment 节点。Comment 接口正是专门用于表示这些标记中…...

FigmaCN:3分钟解锁中文设计界面,设计师翻译校验的专业汉化方案
FigmaCN:3分钟解锁中文设计界面,设计师翻译校验的专业汉化方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 当你打开Figma准备开始一天的设计工作时ÿ…...
别再死记硬背了!用一张图帮你理清Spring全家桶里那些让人头疼的注解(@Autowired, @Transactional, @Value等)
Spring注解全解析:从零构建高效开发思维图谱 1. 引言:为什么需要系统性理解Spring注解? 每次打开Spring项目的代码,你是否会被各种以符号开头的注解弄得眼花缭乱?Autowired、Transactional、Value这些注解看似简单&…...

从人眼到算法:TV Line分辨率检测的实践与演进
1. TV Line检测技术的本质与演进 第一次接触TV Line检测是在2013年,当时我负责一款行车记录仪的摄像头模组验收。供应商提供的测试报告显示"分辨率达到1000线",但实际拍摄效果却模糊不清。这个矛盾让我开始深入研究TV Line检测的本质。 TV L…...

LibreDWG:解放AutoCAD文件的瑞士军刀,3个实用场景教你玩转开源CAD处理
LibreDWG:解放AutoCAD文件的瑞士军刀,3个实用场景教你玩转开源CAD处理 【免费下载链接】libredwg Official mirror of libredwg. With CI hooks and nightly releases. PRs ok 项目地址: https://gitcode.com/gh_mirrors/li/libredwg 还在为无法打…...

Android车载人工智能系统开发实践
引言 随着智能汽车技术的快速发展,Android车载操作系统(如Android Automotive OS)已成为行业主流平台。该系统基于开源Android框架,专为汽车环境优化,支持AI功能集成,提升驾驶安全性和便利性。本文将深入探讨Android车载AI系统的开发流程、关键技术挑战和解决方案,旨在…...