基于土壤数据与机器学习算法的农作物推荐算法代码实现
1.摘要
近年来,机器学习方法在农业领域的应用取得巨大成功,广泛应用于科 学施肥、产量预测和经济效益预估等领域。根据土壤信息进行数据挖掘,并在此基础上提出区域性作物的种植建议,不仅可以促进农作物生长从而带来经济效益,还可以改善土壤肥力,促进可持续发展。本文根据土土 壤养分元素[如:氮(N)、磷(P)、钾(K)等]的含量建立模型分析并且给出精准预测,可以实现了几种机器学习分类算法形成科学的种植方案,最终还实现了应用界面的实现。
2.数据介绍
该数据共有2200条土壤数据,其中每条数据包括土壤中液态氮、速效磷、速效钾、温度、湿度、ph、降雨和作物种类。作物种类包含中国中部以及东部常见耕地作物 8 种:小麦、水稻、玉米、糜子、黄豆等8种。数据显示如下:
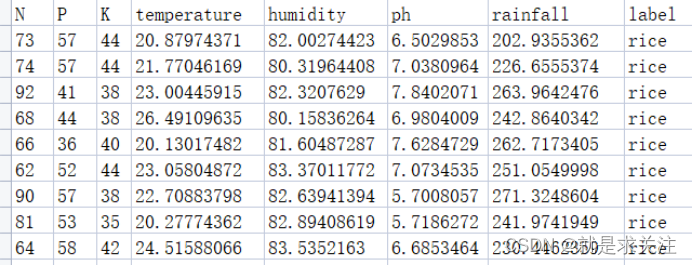
数据读取代码实现如下:
features = df[['N', 'P','K','temperature', 'humidity', 'ph', 'rainfall']]
target = df['label']
labels = df['label']3.模型实现
决策树模型:
DecisionTree = DecisionTreeClassifier(criterion="entropy",random_state=2,max_depth=5)
DecisionTree.fit(Xtrain,Ytrain)
predicted_values = DecisionTree.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('Decision Tree')
print("DecisionTrees's Accuracy is: ", x*100)测试结果输出的混淆矩阵如下:
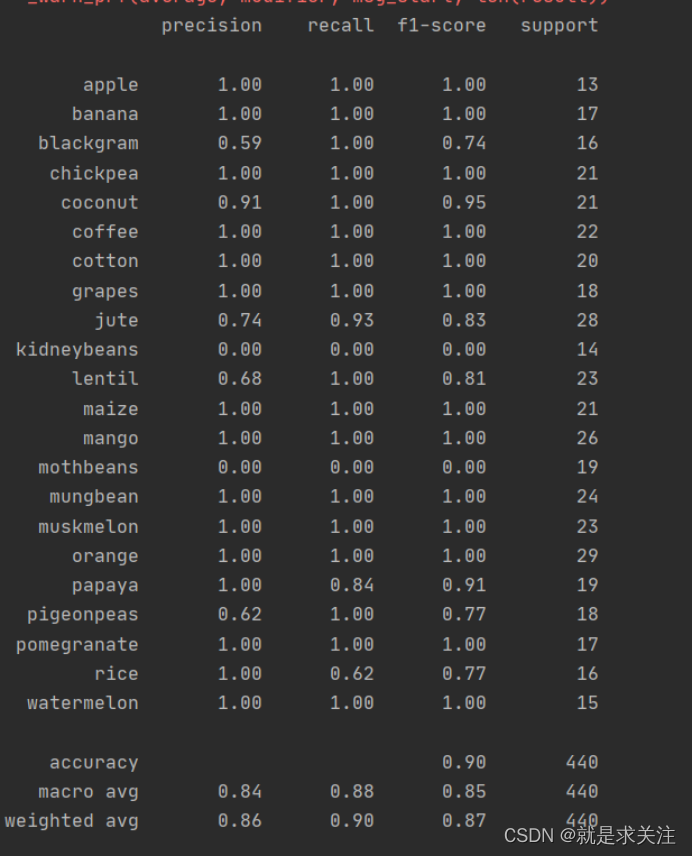
朴素贝叶斯模型:
from sklearn.naive_bayes import GaussianNB
NaiveBayes = GaussianNB()
NaiveBayes.fit(Xtrain,Ytrain)
predicted_values = NaiveBayes.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('Naive Bayes')
print("Naive Bayes's Accuracy is: ", x)
print(classification_report(Ytest,predicted_values))支持向量机模型:
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
norm = MinMaxScaler().fit(Xtrain)
X_train_norm = norm.transform(Xtrain)
X_test_norm = norm.transform(Xtest)
SVM = SVC(kernel='poly', degree=3, C=1)
SVM.fit(X_train_norm,Ytrain)
predicted_values = SVM.predict(X_test_norm)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('SVM')
print("SVM's Accuracy is: ", x)逻辑回归模型:
from sklearn.linear_model import LogisticRegression
LogReg = LogisticRegression(random_state=2)
LogReg.fit(Xtrain,Ytrain)
predicted_values = LogReg.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('Logistic Regression')
print("Logistic Regression's Accuracy is: ", x)
print(classification_report(Ytest,predicted_values))随机森林模型:
from sklearn.ensemble import RandomForestClassifier
RF = RandomForestClassifier(n_estimators=20, random_state=0)
RF.fit(Xtrain,Ytrain)
predicted_values = RF.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('RF')
print("RF's Accuracy is: ", x)
print(classification_report(Ytest,predicted_values))XGBoost模型:
import xgboost as xgb
XB = xgb.XGBClassifier()
XB.fit(Xtrain,Ytrain)
predicted_values = XB.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('XGBoost')
print("XGBoost's Accuracy is: ", x)
print(classification_report(Ytest,predicted_values))上述机器学习的代码类似,以上述XGBoost模型为例,我们对代码逻辑进行了解释:
首先,代码导入了名为xgboost的Python模块,并将其简写为xgb。然后,通过实例化xgb.XGBClassifier()创建了一个XGBoost分类器对象,并将其分配给变量XB。
接下来,使用XB.fit()方法对训练数据Xtrain和Ytrain进行拟合(即训练)。
然后,使用XB.predict()方法对测试数据Xtest进行预测,并将预测结果存储在变量predicted_values中。
最后,使用sklearn.metrics模块中的metrics.accuracy_score()函数计算了模型在测试集上的准确度,其中Ytest是真实标签,predicted_values是模型预测的标签,结果存储在变量x中。
综上所述,这段代码的作用是使用XGBoost分类器对给定的训练集和测试集进行拟合和预测,并计算模型在测试集上的准确度。
为了方便比较,我们绘制出了上述几种机器学习模型进行农作物预测的准确率对比图:

4.应用实现
Flask是一个基于Python编写的Web框架,它可以用来开发Web应用程序。同时,由于Python拥有强大的机器学习和数据处理库,因此Flask框架也可以用来开发基于机器学习算法的Web应用程序。实现界面如下:
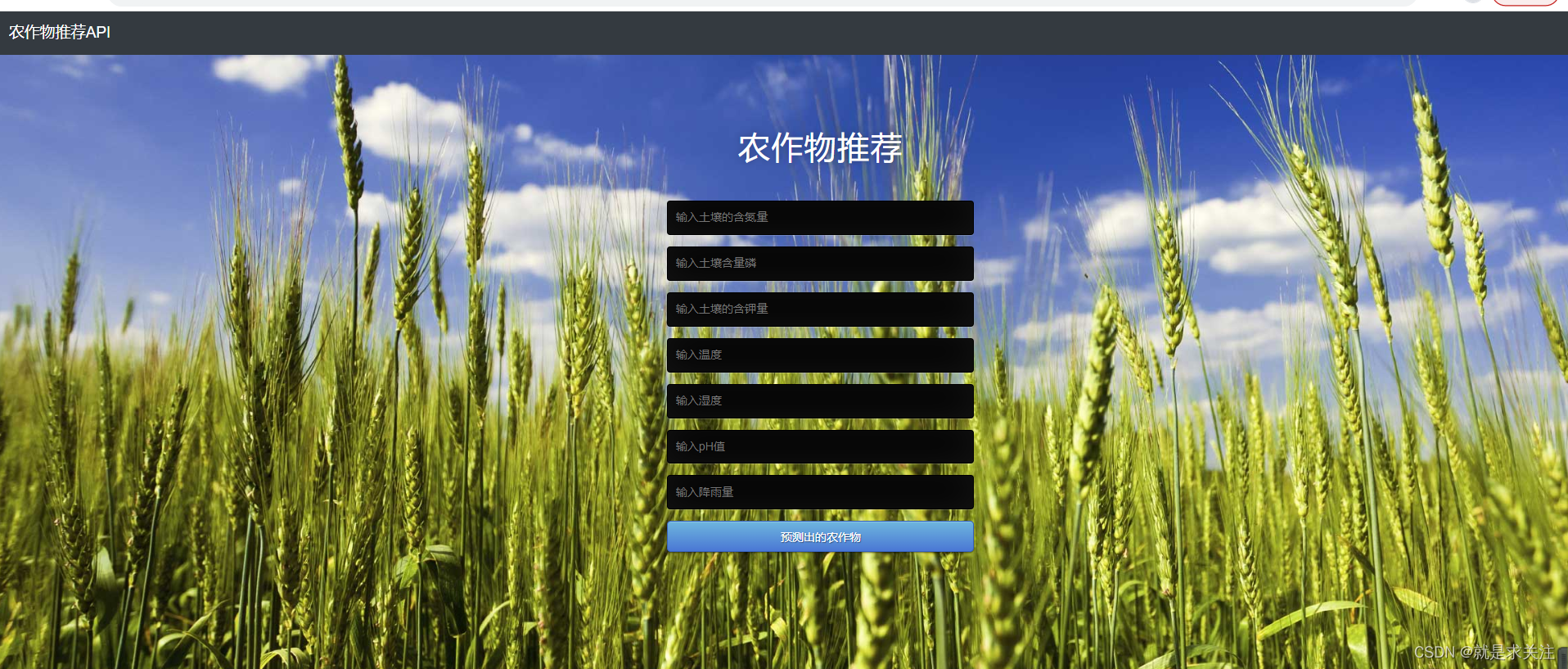

5.总结
本文主要实现了简单的机器学习模型,下一步,对土壤数据进行增强,获得更为均衡的土壤数据作为模型的输入;改进多分类的激活函数,使二分类推荐模型能应用于土壤作物推荐领域。
代码下载链接:
https://download.csdn.net/download/weixin_40651515/87542173
相关文章:
基于土壤数据与机器学习算法的农作物推荐算法代码实现
1.摘要 近年来,机器学习方法在农业领域的应用取得巨大成功,广泛应用于科 学施肥、产量预测和经济效益预估等领域。根据土壤信息进行数据挖掘,并在此基础上提出区域性作物的种植建议,不仅可以促进农作物生长从而带来经济效益&#…...

python中html必备基础知识
<!DOCTYPE html>此标签表示这是一个html文件<heml lang"en">向搜索引擎表示该页面是html语言,并且语言为英文网站,其"lang"的意思就是“language”,语言的意思,而“en”即表示English<head>…...

【专项训练】前言:刻意练习,不断的过遍数才是王道
如何精通一个领域? 拆分知识点刻意练习:每个区域的基础动作分解训练和反复刻意练习反馈(主动反馈、被动反馈、及时反馈)任何知识体系都是一颗树,一定要梳理成思维导图,明确知识与知识之间的关系! 通过7-8周密集训练,练好基本功,彻底攻克LeetCode! 严格执行五毒神掌!…...

【Leetcode】反转链表 合并链表 相交链表 链表的回文结构
目录 一.【Leetcode206】反转链表 1.链接 2.题目再现 3.解法A:三指针法 二.【Leetcode21】合并两个有序链表 1.链接 2.题目再现 3.三指针尾插法 三.【Leetcode160】相交链表 1.链接 2.题目再现 3.解法 四.链表的回文结构 1.链接 2.题目再现 3.解法 一.…...
M1、M2芯片Mac安装虚拟机
目录前言一、安装二、网络设置三、连接SSH客户端前言 一直想着给M1 Mac上安装虚拟机,奈何PD收费,找的破解也不稳定,安装上镜像就起不来。 注:挂长久的分享莫名其妙被封,需要安装包请私信我。 一、安装 虚拟机选择&a…...
算法刷题-只出现一次的数字、输出每天是应该学习还是休息还是锻炼、将有序数组转换为二叉搜索树
只出现一次的数字(位运算、数组) 给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 说明: 你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗&…...

详解专利对学生、老师和企业员工、创业者、积分落户、地方补助的好处
大家好,我是英子老师。作为一名知识产权专家,深耕于专利行业十余年,具有丰富的专利工作经验:曾在大型专利代理机构从事专利代理工作、专利质检工作(抽查代理机构的专利代理人的撰写质量并评分);之后在知名上市企业、行业龙头企业担任高级专利工程师的职位,主要工作内容…...

Python图像处理:频域滤波降噪和图像增强
图像处理已经成为我们日常生活中不可或缺的一部分,涉及到社交媒体和医学成像等各个领域。通过数码相机或卫星照片和医学扫描等其他来源获得的图像可能需要预处理以消除或增强噪声。频域滤波是一种可行的解决方案,它可以在增强图像锐化的同时消除噪声。 …...

智能手机高端“酣战”,转机在何方?
经过多年发展,如今全世界有七成手机由中国制造,但在利润最丰厚的高端市场,国产厂商在很长一段时间之内都是形单影只,曾经一度跻身高端的“华为”因为封禁成了“绝唱”。 华为“失声”高端之后,其他一众国产厂商或主动…...
K8s pod 动态弹性扩缩容 HPA
一、概述Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标自动调整 Deployment 、ReplicaSet 或 StatefulSet 或其他类似资源,实现部署的自动扩展和…...

C++中的类简要介绍
文章目录前言一、什么是类什么是对象1.类的概述2.对象的概述二、如何创建使用类三、class和struct创建类时的区别1.访问级别2.继承方式总结前言 本篇文章讲给大家介绍一个C中重要的概念,了解了这个概念大家就明白了为什么C会叫做面向对象编程了。 一、什么是类什么…...
项目管理工具DHTMLX Gantt灯箱元素配置教程:只读模式
DHTMLX Gantt是用于跨浏览器和跨平台应用程序的功能齐全的Gantt图表。可满足项目管理应用程序的大部分开发需求,具备完善的甘特图图表库,功能强大,价格便宜,提供丰富而灵活的JavaScript API接口,与各种服务器端技术&am…...

从LiveData迁移到Kotlin的 Flow,才发现是真的香!
LiveData 对于 Java 开发者、初学者或是一些简单场景而言仍是可行的解决方案。而对于一些其他的场景,更好的选择是使用 Kotlin 数据流 (Kotlin Flow)。虽说数据流 (相较 LiveData) 有更陡峭的学习曲线,但由于它是 JetBrains 力挺的 Kotlin 语言的一部分&…...
【BOOST C++】组件编程(2)-- 组件的设计原理
GitHub - ros2/demos at foxy 一、说明 为了研究ROS2的组件编程,首先要理解如何何为组件。组件本是微软的发明物体,但是在ubuntu上需要自己从底层实现,就说ROS2不用你写,但是就能看明白也是需要一点理论功底的。本篇按照COM内幕的…...

基于单细胞多组学数据无监督构建基因调控网络
在单细胞分辨率下识别基因调控网络(GRNs,gene regulatory networks)一直是一个巨大的挑战,而单细胞多组学数据的出现为构建GRNs提供了机会。 来自:Unsupervised construction of gene regulatory network based on si…...

蓝桥杯-最优清零方案(2022省赛)
蓝桥杯-最优清零方案1、问题描述2、解题思路3、代码实现1、问题描述 给定一个长度为 N 的数列 1,2,⋯,A1,A2,...,ANA_1,A_2,...,A_NA1,A2,...,AN 。现在小蓝想通过若干次操作将 这个数列中每个数字清零。 每次操作小蓝可以选择以下两种之一: 1. 选择一个大于 0 的整数, 将…...
)
Mac免费软件下载网站推荐(最全免费,替代MacWk)
一、Appstorrent 官方网站: https://appstorrent.ru/ 这是一个俄语网站,其他很多网站资源都来自这里。点击右上角切换到中文。不需要登录网站,直接从软件详情页下载即可。体验非常好。 二、Xclient 官方网站: https://xclie…...
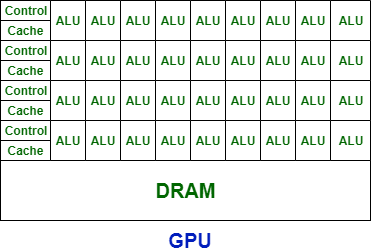
GPU是什么
近期ChatGPT十分火爆,随之而来的是M国开始禁售高端GPU显卡。M国想通过禁售GPU显卡的方式阻挡中国在AI领域的发展。 GPU是什么?GPU(英语:Graphics Processing Unit,缩写:GPU)是显卡的“大脑”&am…...

20230305学习计划
目录 第二天学习开发框架 前言 一、巩固复习第一天20230304学习笔记 二、SpringMVC中的控制器是不是单例模式?如果是,如何保证线程安全? 1、控制器是单例模式,是线程不安全的。 2、Spring中保证线程安全的方法: …...

SocketCan 应用编程
SocketCan 应用编程 由于 Linux 系统将 CAN 设备作为网络设备进行管理,因此在 CAN 总线应用开发方面,Linux 提供了SocketCAN 应用编程接口,使得 CAN 总线通信近似于和以太网的通信,应用程序开发接口更加通用,也更加灵…...

保边滤波深度学习红外可见光融合算法【附程序】
✨ 长期致力于红外与可见光图像融合、快速引导滤波器、交替引导滤波器、深度学习、卷积神经网络研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)双支流…...

Docker 的了解和使用
1. 虚拟化全虚拟化:虚拟机的操作系统可以和宿主机的操作系统完全不同。os层虚拟化:操作内核相同,软件虚拟化。2. docker安装 Docker容器本质上是Linux容器,它需要Linux内核环境才能运行。在Windows上直接运行Docker,需…...
)
手把手教你ClickHouse(二、Windows下Docker部署与可视化实战)
1. Windows下Docker环境准备 在开始部署ClickHouse之前,我们需要先确保Windows系统已经正确配置Docker环境。这里我推荐使用Docker Desktop for Windows,它提供了图形化界面和完整的容器管理功能。安装过程可能会遇到几个常见坑点,我把自己实…...
)
Sora 2与3D Gaussian结合实战指南(工业级部署避坑手册)
更多请点击: https://intelliparadigm.com 第一章:Sora 2与3D Gaussian结合的工业级部署全景图 Sora 2作为OpenAI新一代视频生成模型,在长时序建模与物理一致性方面取得显著突破;而3D Gaussian Splatting(3DGS&#x…...

微信消息自动转发终极指南:5分钟实现跨群智能消息同步
微信消息自动转发终极指南:5分钟实现跨群智能消息同步 【免费下载链接】wechat-forwarding 在微信群之间转发消息 项目地址: https://gitcode.com/gh_mirrors/we/wechat-forwarding 在微信群管理和协作场景中,消息的自动转发与同步是提升效率的关…...

can消息的大小端对源码的影响
下图为小端intel型信号,其dbc文件部分源码为:BO_ 1 id_0x1: 8 Vector__XXXSG_ aaa : 0|121 (1,0) [0|0] "" Vector__XXX,这里的0代表的是起始位置为0(起始0->7,8->12为高位)如果将该信号改为大端motorola型&#…...

Qdrant 如何配置 API Key 认证
Qdrant 如何配置 API Key 认证 Qdrant 是当下最流行的向量数据库之一,广泛应用于 RAG(检索增强生成)、相似度搜索、AI 应用等场景。生产环境中,API Key 认证是保障数据安全的基本手段。本文详细介绍 Qdrant 的 API Key 配置方法&a…...

现代差旅电力管理实战:从充电安全到设备续航全攻略
1. 一次久违的飞行:无处不在的电力焦虑与科技依赖距离上一次飞行已经过去了整整十七个月。当我上周踏入纽约拉瓜迪亚机场,准备开启后疫情时代的首次旅程时,感觉像是进入了另一个维度。在我缺席的这段时间里,LGA完成了一场彻底的蜕…...

AgenticROS:用自然语言操控ROS2机器人的AI Agent接口实践
1. 项目概述:当AI大模型遇见机器人操作系统如果你和我一样,既对AI大模型的能力着迷,又对机器人开发充满兴趣,那么你肯定想过一个问题:能不能让Claude、Gemini这样的AI,像我们人类工程师一样,直接…...

微信自动化终极指南:5个强大功能助你高效管理微信数据
微信自动化终极指南:5个强大功能助你高效管理微信数据 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 还在为繁琐的微信数据管理而烦恼吗?微信…...