如何提高爬虫工作效率
单进程单线程爬取目标网站太过缓慢,这个只是针对新手来说非常友好,只适合爬取小规模项目,如果遇到大型项目就不得不考虑多线程、线程池、进程池以及协程等问题。那么我们该如何提升工作效率降低成本?
学习之前首先要对线程,进程,协程做一个简单的区分吧:
进程是资源单位,每一个进程至少要有一个线程,每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。
线程是执行单位,启动每一个程序默认都会有一个主线程。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程是一种用户态的轻量级线程, 协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
了解了进程、线程、协程之间的区别之后,我们就可以思考如何用这些东西来提高爬虫的效率呢?
提高爬虫效率的方法
多线程
要体现多线程的特点就必须得拿单线程来做一个比较,这样才能凸显不同~
单线程运行举例:
def func():for i in range(5):print("func", i)if __name__ == '__main__':func()for i in range(5):print("main", i)
运行结果如下:
# 单线程演示案例result:
func 0
func 1
func 2
func 3
func 4
main 0
main 1
main 2
main 3
main 4
可以注意到在单线程的情况下,程序是先打印fun 0 - 4, 再打印main 0 - 4。
下面再举一个多线程的例子:
需要实例化一个Thread类 Thread(target=func()) target接收的就是任务(/函数),通过.start()方法就可以启动多线程了。
代码提供两种方式:
# 多线程(两种方法)
# 方法一:from threading import Threaddef func():for i in range(1000):print("func ", i)if __name__ == '__main__':t = Thread(target=func()) # 创建线程并给线程安排任务t.start() # 多线程状态为可以开始工作状态,具体的执行时间由CPU决定 for i in range(1000):print("main ", i)
# two
class MyThread(Thread):def run(self): # 固定的 -> 当线程被执行的时候,被执行的就是run()for i in range(1000):print("子线程 ", i)if __name__ == '__main__':t = MyThread()# t.run() #方法调用 --》单线程t.start() #开启线程for i in range(1000):print("主线程 ", i)
运行结果

子线程和主线程有时候会同时执行,这就是多线程吧。
线程创建之后只是代表处于能够工作的状态,并不代表立即执行,具体执行的时间需要看CPU。
感觉线程执行的顺序就是杂乱无章的。
接下来分享一下多进程:
多进程
进程的使用:Process(target=func())
先举一个例子来感受一下多进程的执行顺序:
from multiprocessing import Processdef func():for i in range(1000):print("子进程 ", i)if __name__ == '__main__':p = Process(target=func())p.start()for i in range(1000):print("主进程 ", i)
运行结果:

从结果中可以发出,所有的子进程按照顺序执行之后。就开始打印主进程0-999。进程打印的有序也表明线程是最小的执行单位。
开启多线程打印的时候,出现的数字并不是有序的。
线程池&进程池
在python中一般使用以下方法创建线程池/进程池:
with ThreadPoolExecutor(50) as t:t.submit(fn, name=f"线程{i}")
具体代码:
# 线程池:一次性开辟一些线程,我们用户直接给线程池提交任务,线程任务的调度交给线程池来完成
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutordef fn(name):for i in range(1000):print(name,i)if __name__ == '__main__':# 创建线程池with ThreadPoolExecutor(50) as t:for i in range(100):t.submit(fn, name=f"线程{i}")# 等待线程池中的任务全部执行完毕,才继续执行(守护)print(123)

进程池的创建方法类似。
协程
协程:当程序遇见IO操作的时候,可以选择性的切换到其他任务上。
在微观上是一个任务一个任务的进行切换,切换条件一般就是IO操作。
在宏观上,我们能看到的其实就是多个任务一起在执行。
多任务异步操作(就像你自己一边洗脚一边看剧一样~,时间管理带师(bushi)。
线程阻塞的一些案例:
例子1:
time.sleep(30) # 让当前线程处于阻塞状态,CPU是不为我工作的
# input() 程序也是处于阻塞状态
# requests.get(xxxxxx) 在网络请求返回数据之前,程序也是处于阻塞状态
# 一般情况下,当程序处于IO操作的时候,线程都会处于阻塞状态
# for example: 边洗脚边按摩
import asyncio
import timeasync def func():print("hahha")if __name__ == "__main__":g = func() # 此时的函数是异步协程函数,此时函数执行得到的是一个协程对象asyncio.run(g) # 协程程序运行需要asyncio模块的支持
输出结果:
root@VM-12-2-ubuntu:~/WorkSpace# python test.py
hahha
例子2:
async def func1():print("hello,my name id hanmeimei")# time.sleep(3) # 当程序出现了同步操作的时候,异步就中断了await asyncio.sleep(3) # 异步操作的代码print("hello,my name id hanmeimei")async def func2():print("hello,my name id wahahha")# time.sleep(2)await asyncio.sleep(2) # 异步操作的代码print("hello,my name id wahahha")async def func3():print("hello,my name id hhhhhhhc")# time.sleep(4)await asyncio.sleep(4) # 异步操作的代码print("hello,my name id hhhhhhhc")if __name__ == "__main__":f1 = func1()f2 = func2()f3 = func3()task = [f1, f2, f3]t1 = time.time()asyncio.run(asyncio.wait(task))t2 = time.time()print(t2 - t1)
运行结果:

注意到执行await asyncio.sleep(4)后,主程序就会调用其他函数了。成功实现了异步操作。(边洗脚边按摩bushi )
下面的代码看起来更为规范~
async def func1():print("hello,my name id hanmeimei")await asyncio.sleep(3)print("hello,my name id hanmeimei")async def func2():print("hello,my name id wahahha")await asyncio.sleep(2)print("hello,my name id wahahha")async def func3():print("hello,my name id hhhhhhhc")await asyncio.sleep(4)print("hello,my name id hhhhhhhc")async def main():# 第一种写法# f1 = func1()# await f1 # 一般await挂起操作放在协程对象前面# 第二种写法(推荐)tasks = [func1(), # py3.8以后加上asyncio.create_task()func2(),func3()]await asyncio.wait(tasks)if __name__ == "__main__":t1 = time.time()asyncio.run(main())t2 = time.time()print(t2 - t1)
再举一个模拟下载的例子吧,更加形象啦:
async def download(url):print("准备开始下载")await asyncio.sleep(2) # 网络请求print("下载完成")async def main():urls = ["http://www.baidu.com","http://www.bilibili.com","http://www.163.com"]tasks = []for url in urls:d = download(url)tasks.append(d)await asyncio.wait(tasks)if __name__ == '__main__':asyncio.run(main())
# requests.get() 同步的代码 => 异步操作aiohttpimport asyncio
import aiohttpurls = ["http://kr.shanghai-jiuxin.com/file/2020/1031/191468637cab2f0206f7d1d9b175ac81.jpg","http://i1.shaodiyejin.com/uploads/tu/201704/9999/fd3ad7b47d.jpg","http://kr.shanghai-jiuxin.com/file/2021/1022/ef72bc5f337ca82f9d36eca2372683b3.jpg"
]async def aiodownload(url):name = url.rsplit("/", 1)[1] # 从右边切,切一次,得到[1]位置的内容 fd3ad7b47d.jpgasync with aiohttp.ClientSession() as session: # requestsasync with session.get(url) as resp: # resp = requests.get()# 请求回来之后,写入文件# 模块 aiofileswith open(name, mode="wb") as f: # 创建文件f.write(await resp.content.read()) # 读取内容是异步的,需要将await挂起, resp.text()print(name, "okk")# resp.content.read() ==> resp.text()# s = aiphttp.ClientSession <==> requests# requests.get() .post()# s.get() .post()# 发送请求# 保存图片内容平# 保存为文件async def main():tasks = []for url in urls:tasks.append(aiodownload(url))await asyncio.wait(tasks)if __name__ == '__main__':asyncio.run(main())
相关文章:
如何提高爬虫工作效率
单进程单线程爬取目标网站太过缓慢,这个只是针对新手来说非常友好,只适合爬取小规模项目,如果遇到大型项目就不得不考虑多线程、线程池、进程池以及协程等问题。那么我们该如何提升工作效率降低成本? 学习之前首先要对线程&#…...

React结合Drag API实现拖拽示例详解
Drag API React中的Drag API是用于实现拖放功能的API。该API由React DnD库提供,可用于实现拖放操作,例如将元素从一个位置拖动到另一个位置。 React DnD库提供了两种Drag API:基于HTML5的拖放API和自定义实现的拖放API。 基于HTML5的拖放AP…...
)
【华为OD机试java、python、c++、jsNode】新学校选址(100%通过+复盘思路)
代码请进行一定修改后使用,本代码保证100%通过率。本文章提供java、python、c++、jsNode四种代码。复盘思路在文章的最后 题目描述 为了解新学期学生暴涨的问题,小乐村要建立所新学校, 考虑到学生上学安全问题,需要所有学生家到学校的距离最短。 假设学校和所有学生家都走在…...
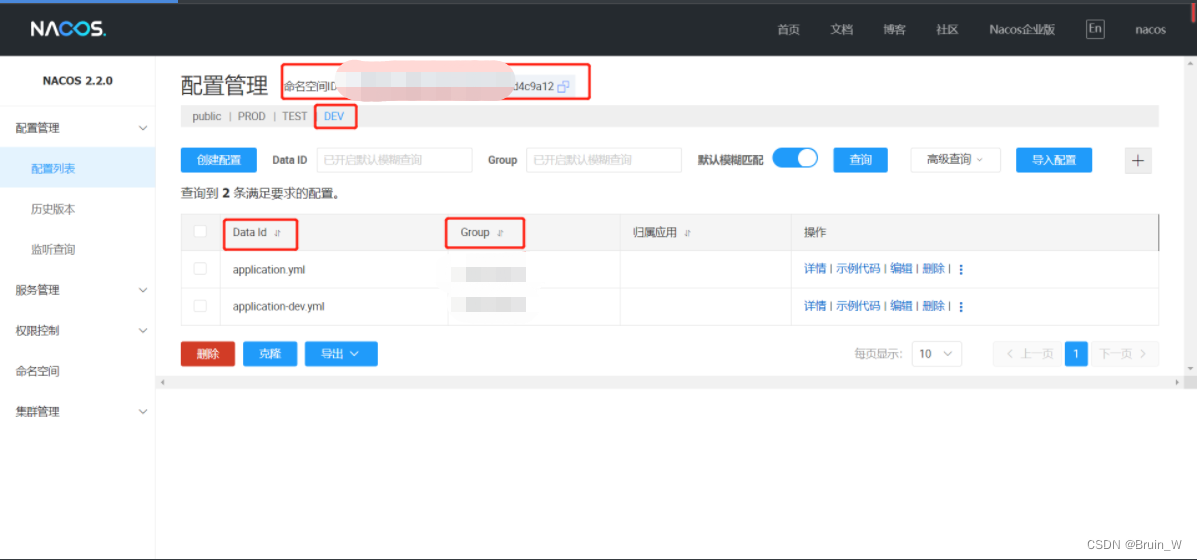
Nacos配置中心,分组配置参考,以及python、go、bash客户端连接获取
Nacos使用说明 nacos官方网站 https://nacos.io/zh-cn/docs/v2/what-is-nacos.html 1、基本配置说明 nacosIP地址:http://xxxxx:8848/nacos/ 服务管理端登录账号:nacos XXX Java最小配置,其他客户端可参考,配置可对应到第三章…...

node-red中有关用户登录,鉴权,权限控制的流程解析
前言 默认地,node-red编辑器可以被任何访问的用户操作,包括修改节点,流数据,重新部署流。 这种默认的部署方式只适用于运行在可靠的网络中。下面我就给大家介绍一下,在公网上部署node-red后,如何对其进行安全加固和权限验证。 主要分为三部分 开启https权限保护编辑器和…...

MQTT协议-使用CONNECT报文连接阿里云
使用网络调试助手发送CONNECT报文连接阿里云 参考:https://blog.csdn.net/daniaoxp/article/details/103039296 在前面文章介绍了如何组装CONNECT报文,以及如何计算剩余长度 CONNECT报文:https://blog.csdn.net/weixin_46251230/article/d…...

每日学术速递3.8
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CV 1.Unleashing Text-to-Image Diffusion Models for Visual Perception 标题:释放用于视觉感知的文本到图像扩散模型 作者:Wenliang Zhao, Yongming Rao, Zuya…...

测牛学堂:软件测试之接口测试理论基础总结
接口概念 接口:系统之间数据交互的通道。 这个系统,可以是外部和内部,也可以是两个内部系统之间的通道。 比如我们前端的登录信息,主要是用户名和密码,它通过接口传递给后端,后端校验以后,把结…...

基于土壤数据与机器学习算法的农作物推荐算法代码实现
1.摘要 近年来,机器学习方法在农业领域的应用取得巨大成功,广泛应用于科 学施肥、产量预测和经济效益预估等领域。根据土壤信息进行数据挖掘,并在此基础上提出区域性作物的种植建议,不仅可以促进农作物生长从而带来经济效益&#…...

python中html必备基础知识
<!DOCTYPE html>此标签表示这是一个html文件<heml lang"en">向搜索引擎表示该页面是html语言,并且语言为英文网站,其"lang"的意思就是“language”,语言的意思,而“en”即表示English<head>…...

【专项训练】前言:刻意练习,不断的过遍数才是王道
如何精通一个领域? 拆分知识点刻意练习:每个区域的基础动作分解训练和反复刻意练习反馈(主动反馈、被动反馈、及时反馈)任何知识体系都是一颗树,一定要梳理成思维导图,明确知识与知识之间的关系! 通过7-8周密集训练,练好基本功,彻底攻克LeetCode! 严格执行五毒神掌!…...

【Leetcode】反转链表 合并链表 相交链表 链表的回文结构
目录 一.【Leetcode206】反转链表 1.链接 2.题目再现 3.解法A:三指针法 二.【Leetcode21】合并两个有序链表 1.链接 2.题目再现 3.三指针尾插法 三.【Leetcode160】相交链表 1.链接 2.题目再现 3.解法 四.链表的回文结构 1.链接 2.题目再现 3.解法 一.…...
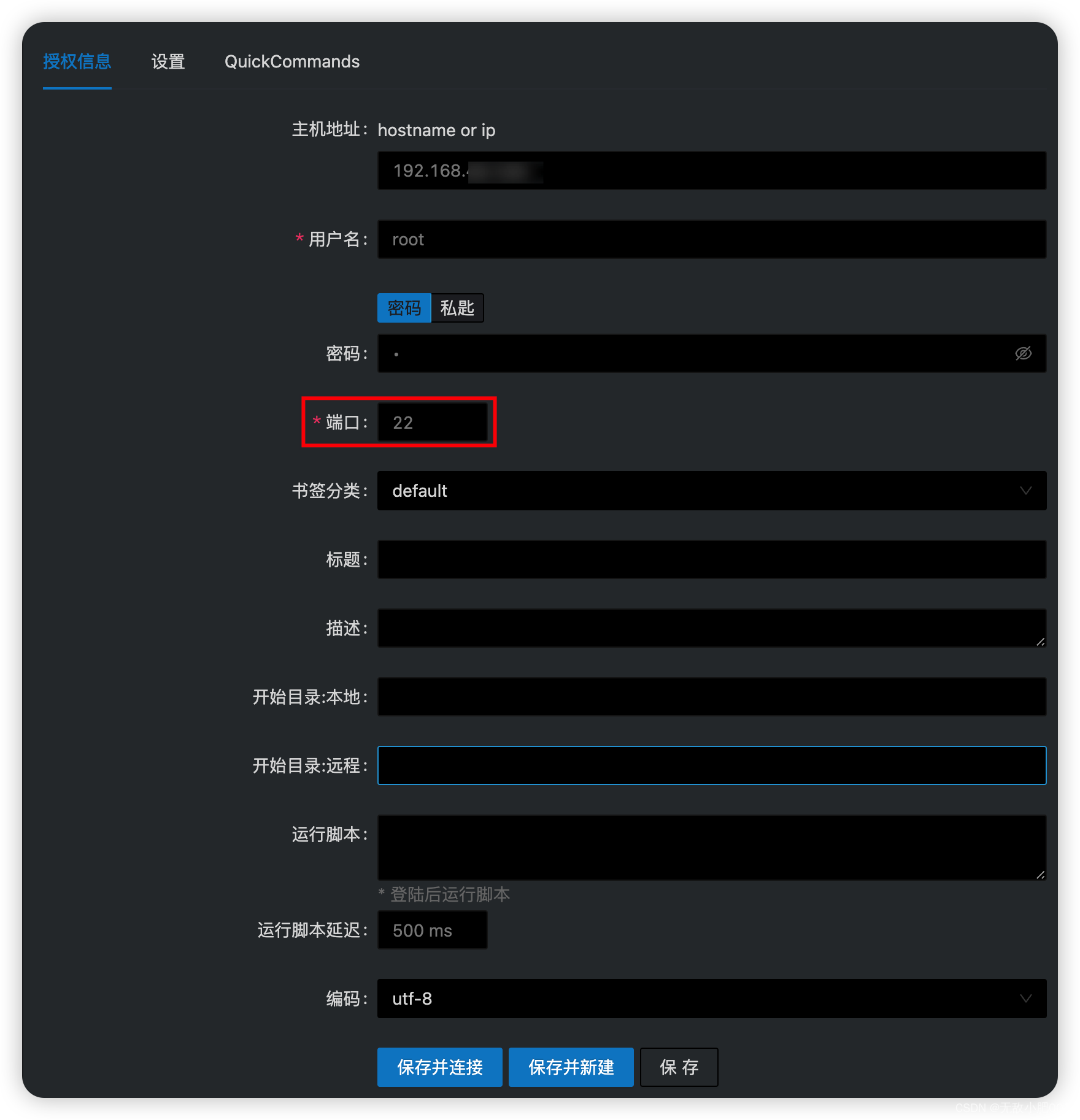
M1、M2芯片Mac安装虚拟机
目录前言一、安装二、网络设置三、连接SSH客户端前言 一直想着给M1 Mac上安装虚拟机,奈何PD收费,找的破解也不稳定,安装上镜像就起不来。 注:挂长久的分享莫名其妙被封,需要安装包请私信我。 一、安装 虚拟机选择&a…...
算法刷题-只出现一次的数字、输出每天是应该学习还是休息还是锻炼、将有序数组转换为二叉搜索树
只出现一次的数字(位运算、数组) 给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 说明: 你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗&…...

详解专利对学生、老师和企业员工、创业者、积分落户、地方补助的好处
大家好,我是英子老师。作为一名知识产权专家,深耕于专利行业十余年,具有丰富的专利工作经验:曾在大型专利代理机构从事专利代理工作、专利质检工作(抽查代理机构的专利代理人的撰写质量并评分);之后在知名上市企业、行业龙头企业担任高级专利工程师的职位,主要工作内容…...

Python图像处理:频域滤波降噪和图像增强
图像处理已经成为我们日常生活中不可或缺的一部分,涉及到社交媒体和医学成像等各个领域。通过数码相机或卫星照片和医学扫描等其他来源获得的图像可能需要预处理以消除或增强噪声。频域滤波是一种可行的解决方案,它可以在增强图像锐化的同时消除噪声。 …...

智能手机高端“酣战”,转机在何方?
经过多年发展,如今全世界有七成手机由中国制造,但在利润最丰厚的高端市场,国产厂商在很长一段时间之内都是形单影只,曾经一度跻身高端的“华为”因为封禁成了“绝唱”。 华为“失声”高端之后,其他一众国产厂商或主动…...
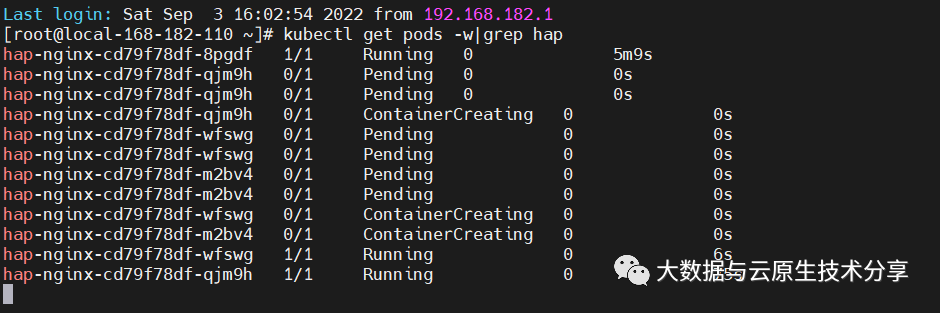
K8s pod 动态弹性扩缩容 HPA
一、概述Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标自动调整 Deployment 、ReplicaSet 或 StatefulSet 或其他类似资源,实现部署的自动扩展和…...

C++中的类简要介绍
文章目录前言一、什么是类什么是对象1.类的概述2.对象的概述二、如何创建使用类三、class和struct创建类时的区别1.访问级别2.继承方式总结前言 本篇文章讲给大家介绍一个C中重要的概念,了解了这个概念大家就明白了为什么C会叫做面向对象编程了。 一、什么是类什么…...
项目管理工具DHTMLX Gantt灯箱元素配置教程:只读模式
DHTMLX Gantt是用于跨浏览器和跨平台应用程序的功能齐全的Gantt图表。可满足项目管理应用程序的大部分开发需求,具备完善的甘特图图表库,功能强大,价格便宜,提供丰富而灵活的JavaScript API接口,与各种服务器端技术&am…...

WarcraftHelper:3步解决魔兽争霸3卡顿与兼容性问题终极指南
WarcraftHelper:3步解决魔兽争霸3卡顿与兼容性问题终极指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3在现代电…...

计算机视觉导航评估框架:从算法指标到用户体验的完整闭环
1. 项目概述:为什么我们需要一个“导航评估框架”?在计算机视觉辅助视障人士导航这个领域,我见过太多“实验室里的英雄”和“现实中的矮子”。一个算法在精心布置的走廊里识别障碍物准确率高达99.9%,但一到人潮涌动的火车站广场&a…...

AI驱动游戏开发:Godogen自动化流水线全解析
1. 项目概述:当AI成为你的游戏开发合伙人 如果你是一名独立游戏开发者,或者对用Godot引擎做点小玩意儿感兴趣,那你肯定体会过那种感觉:一个绝妙的点子在你脑海里盘旋,但一想到要从零开始搭场景、写脚本、画素材&#x…...

基于LangGraph与MCP构建Farcaster AI智能体:从架构到DeFi集成实战
1. 项目概述:一个面向Farcaster生态的AI智能体最近在探索SocialFi和AI Agent的结合点,发现了一个挺有意思的项目:oceantruong/farcaster-agent。简单来说,这是一个专门为Farcaster社交网络设计的AI智能体框架。Farcaster本身是一个…...

扩散模型如何重塑建筑设计流程:从概念生成到性能优化的AI协作
1. 项目概述:当AI成为建筑师的“副驾驶”几年前,当我在设计院通宵达旦地对着屏幕调整一个曲面屋顶的参数时,我就在想,有没有一种工具,能让我把脑子里那个模糊的意象,瞬间变成可供推敲的视觉草稿?…...

Dify实战指南:从零构建大模型应用与智能体开发全流程
1. 项目概述:从零到一,构建你的大模型应用开发实战手册如果你对AI应用开发感兴趣,但又觉得从零开始搭建一个能用的智能体(Agent)或者知识库问答系统门槛太高,那么你很可能已经听说过Dify这个名字。作为一个…...
)
arXiv论文智能检索革命(Perplexity深度集成实战白皮书)
更多请点击: https://intelliparadigm.com 第一章:arXiv论文智能检索革命(Perplexity深度集成实战白皮书) 传统 arXiv 检索依赖关键词匹配与手动筛选,面对日均超 2000 篇新增论文,科研人员常陷入信息过载困…...

BG3ModManager:博德之门3模组管理终极指南,告别模组冲突烦恼![特殊字符]
BG3ModManager:博德之门3模组管理终极指南,告别模组冲突烦恼!🚀 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModMa…...

TongWeb实战:GBase数据库连接池的配置与性能调优指南
1. 连接池基础与TongWeb集成 第一次在TongWeb里配置GBase数据库连接池时,我犯了个低级错误——直接把最大连接数设成了1000,结果系统刚上线就崩溃了。后来才明白,连接池不是越大越好,它本质上是个数据库连接的共享停车场。想象一…...

CREO 6.0装配实战:别再乱拖零件了,手把手教你用‘移动’和‘角度偏移’精准定位
CREO 6.0装配实战:从零件乱飞到精准定位的进阶技巧 刚接触CREO装配模块的新手设计师,最常遇到的挫败感莫过于:明明在脑海中构思好了零件位置,实际操作时却总是出现零件"乱飞"、"定位不准"的情况。这种体验就像…...