BERT入门:理解自然语言处理中的基本概念
1. 自然语言处理简介
自然语言处理(Natural Language Processing,NLP)是人工智能领域的重要分支,涉及计算机与人类自然语言之间的相互作用。NLP 的应用已经深入到我们日常生活中的方方面面,如智能助理、机器翻译、舆情分析等。
在下表中,列举了一些 NLP 在日常生活中的应用场景:
| 应用场景 | 描述 |
|---|---|
| 智能助理 | Siri、Alexa、小冰等智能助理系统使用NLP来理解和回应用户语音指令 |
| 机器翻译 | Google 翻译等机器翻译系统通过NLP技术实现不同语言之间的自动翻译 |
| 情感分析 | 社交媒体和舆情监控中,通过NLP分析用户文本信息的情感倾向 |
| 文本分类 | 新闻分类、垃圾邮件过滤等应用中,NLP被用于文本自动分类 |
以上是自然语言处理简介章节的内容概述,后续章节将深入探讨NLP的各个方面。
2. 深度学习与自然语言处理
1. 深度学习在NLP中的应用
- 深度学习是一种机器学习方法,通过模拟人类大脑的神经网络结构,能够学习复杂的特征表达。
- 在自然语言处理领域,深度学习方法已经取得了很大的成功,例如在文本分类、机器翻译、问答系统等任务中都表现出色。
- 深度学习方法通过大规模数据集的训练,可以自动学习文本中的特征,不需要手工设计特征工程,提高了模型的泛化能力。
2. 理解神经网络、Word Embeddings等基本概念
- 神经网络(Neural Networks):神经网络是一种模拟人脑神经元结构的计算模型,由多层神经元组成,通过前向传播和反向传播来优化模型参数。
- Word Embeddings:词嵌入是将词语映射到实数域向量空间中的技术,通过词向量可以表示词语之间的语义关系,常用的词嵌入模型有Word2Vec、GloVe等。
3. 传统NLP方法与深度学习方法的对比
下表展示了传统NLP方法与深度学习方法在几个方面的对比:
| 对比项 | 传统NLP方法 | 深度学习方法 |
|---|---|---|
| 特征提取 | 人工设计特征,如TF-IDF、词袋模型等 | 自动学习特征表示 |
| 数据需求 | 对数据质量和数量要求高 | 对数据量要求大,质量相对较高 |
| 模型复杂度 | 通常模型相对简单 | 模型复杂,参数量大 |
| 泛化能力 | 泛化能力一般 | 泛化能力较强 |
| 计算资源需求 | 相对较少的计算资源 | 对计算资源要求较高 |
# 示例代码:使用深度学习模型进行文本分类
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.models import Sequential# 构建模型
model = Sequential()
model.add(Embedding(input_dim=10000, output_dim=128, input_length=100))
model.add(LSTM(64))
model.add(Dense(1, activation='sigmoid'))# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=5, batch_size=32, validation_data=(X_val, y_val))
以上示例代码展示了使用TensorFlow构建文本分类模型的过程,包括模型的构建、编译和训练过程。
4. 总结
深度学习方法在自然语言处理领域发挥着越来越重要的作用,通过神经网络等深度学习模型,可以更好地处理文本数据,并取得比传统方法更好的效果。然而,深度学习方法也面临着数据量大、计算资源需求高等挑战,需要进一步研究和优化。
3. BERT模型概述
在本章中,我们将深入了解BERT(Bidirectional Encoder Representations from Transformers)模型的概述,包括定义及由来,BERT对NLP领域的影响以及BERT的预训练与微调过程。
1. BERT模型的定义及由来
BERT是一种基于Transformer架构的预训练模型,由Google在2018年提出。其全称为Bidirectional Encoder Representations from Transformers,可以在没有标签的大型文本语料库上进行预训练,然后在特定任务上进行微调,取得优秀的表现。
2. BERT对NLP领域的影响
BERT的问世对自然语言处理领域带来了革命性的影响,它在多项NLP任务上取得了SOTA(State-of-the-Art)的成绩,包括文本分类、问答系统、语义相似度计算等。
3. BERT的预训练与微调过程
下面通过代码和流程图简要介绍BERT的预训练和微调过程:
BERT预训练过程代码示例:
# 导入BERT模型
from transformers import BertTokenizer, BertForPreTraining# 加载BERT预训练模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForPreTraining.from_pretrained('bert-base-uncased')# 指定预训练数据集并对BERT模型进行预训练
# 此处省略具体的预训练代码
BERT微调过程代码示例:
# 导入BERT模型和优化器
from transformers import BertTokenizer, BertForSequenceClassification, AdamW# 加载BERT分类模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')# 准备微调数据并定义优化器
# 此处省略具体的微调代码
optimizer = AdamW(model.parameters(), lr=5e-5)# 进行微调训练
# 此处省略微调训练代码
BERT预训练流程图(mermaid格式):
通过以上内容,我们对BERT模型的定义及由来、对NLP领域的影响以及预训练与微调过程有了更深入的了解。BERT模型的出现极大地推动了自然语言处理领域的发展,为解决复杂的自然语言理解任务提供了有力工具。
4. Transformer模型架构
Transformer 模型是一个用于处理序列数据的革命性神经网络架构,为自然语言处理领域带来了重大的突破。下面我们将深入探讨 Transformer 模型的原理、基本组成,以及与传统的 RNN、LSTM 模型的对比。
Transformer 模型架构
Transformer 模型由以下几个核心组件构成:
-
自注意力机制(self-attention):该机制允许模型在处理序列数据时同时考虑序列中不同位置的信息,而无需像 RNN、LSTM 那样依赖于序列的顺序。自注意力机制能够更好地捕捉输入序列之间的依赖关系。
-
位置编码(positional encoding):在 Transformer 模型中,由于不包含递归或卷积结构,为了确保模型能够处理序列数据中的位置信息,需要使用位置编码来为输入的词向量序列添加位置信息。
-
前馈神经网络(feedforward neural network):Transformer 模型中每个层都包含一个前馈神经网络,用于在自注意力机制后对特征进行非线性变换。
-
残差连接(residual connection)和层归一化(layer normalization):Transformer 模型中引入残差连接和层归一化机制,有助于有效地训练深层神经网络。
对比 Transformer 与 RNN、LSTM
下表列出了 Transformer 模型与传统的 RNN、LSTM 模型在几个方面的对比:
| 模型 | 序列建模方式 | 并行性 | 长期依赖建模 | 结构 |
|---|---|---|---|---|
| RNN | 逐步建模 | 低 | 有限 | 递归 |
| LSTM | 逐步建模 | 低 | 良好 | 递归 |
| Transformer | 全局建模 | 高 | 良好 | 非递归 |
从上表可以看出,Transformer 模型相比传统的 RNN、LSTM 模型在并行性能力和长期依赖建模方面有显著的优势,尤其在处理长序列数据时表现更加出色。
代码示例
下面是一个简化的 Transformer 模型的 Python 代码示例:
import torch
import torch.nn as nnclass Transformer(nn.Module):def __init__(self, num_layers, d_model, num_heads, d_ff):super(Transformer, self).__init__()self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])def forward(self, x):for layer in self.encoder_layers:x = layer(x)return xclass EncoderLayer(nn.Module):def __init__(self, d_model, num_heads, d_ff):super(EncoderLayer, self).__init__()self.self_attn = MultiheadAttention(d_model, num_heads)self.linear1 = nn.Linear(d_model, d_ff)self.linear2 = nn.Linear(d_ff, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)def forward(self, x):x_res = xx = self.self_attn(x)x = self.norm1(x + x_res)x_res = xx = self.linear2(F.relu(self.linear1(x)))x = self.norm2(x + x_res)return xclass MultiheadAttention(nn.Module):def __init__(self, d_model, num_heads):super(MultiheadAttention, self).__init__()self.num_heads = num_heads# Implementation details omitted for brevitydef forward(self, x):# Implementation details omitted for brevityreturn x
以上代码展示了一个简单的 Transformer 模型及其组件的实现,实际应用中还需要结合更复杂的数据和任务进行详细调整和训练。
Transformer 模型流程图
下面使用 Mermaid 格式绘制 Transformer 模型的流程图:
以上就是关于 Transformer 模型架构的详细介绍。Transformer 模型的出现为自然语言处理领域带来了新的思路和方法,极大地推动了该领域的发展。
5. BERT在自然语言处理中的具体应用
文本分类、情感分析等任务
在自然语言处理中,BERT广泛用于文本分类和情感分析等任务。通过将BERT模型微调到特定领域的语料库上,可以获得更好的文本分类性能。以下是使用BERT进行文本分类的简单代码示例:
# 导入相关库
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import AdamW
import torch# 加载预训练的BERT模型和tokenizer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')# 准备文本数据
texts = ["I love using BERT for text classification.", "Negative review: BERT did not meet my expectation."]
labels = [1, 0]# 将文本转换为BERT模型输入
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")# 训练模型
optimizer = AdamW(model.parameters(), lr=5e-5)
labels = torch.tensor(labels).unsqueeze(0)
outputs = model(**inputs, labels=labels)
loss = outputs.loss
问答系统中的BERT应用
BERT在问答系统中也有广泛的应用,能够提高问答系统的准确性和效率。通过将问题和回答候选项编码为BERT模型输入,可以利用BERT模型对每个回答进行打分,从而找到最佳答案。以下是一个简单的伪代码流程图,展示了BERT在问答系统中的应用:
BERT在语言生成任务上的表现
虽然BERT主要用于处理自然语言处理中的各种任务,但它在一定程度上也可以应用于语言生成任务。通过对BERT模型进行微调,可以生成具有一定语义和逻辑连贯性的文本。以下是一些示例生成的文本:
| 输入文本 | 生成文本 |
|---|---|
| “Today is a beautiful day” | “The weather is perfect for a picnic.” |
| “I feel happy” | “There’s a huge smile on my face.” |
| “The cat sat on the mat” | “The fluffy cat lounges on the soft, warm mat.” |
通过对输入文本进行微调,BERT可以生成符合语境的自然语言文本,展示了在语言生成任务上的潜力。
希望以上示例能帮助您更好地理解BERT在自然语言处理中的具体应用!
6. 未来发展趋势与展望
BERT在NLP领域的未来发展方向
- 强化学习与BERT的结合:结合强化学习与BERT,使模型在交互式任务中表现更出色,如对话系统、推荐系统等。
- 多语言模型的进一步优化:优化多语言BERT模型,使其在各种语言下表现更好,推动跨语言交流和翻译的发展。
- 面向特定领域的预训练模型:针对特定领域(如医疗、法律、金融等)进行预训练,提高模型在特定领域任务上的准确性和效率。
新兴技术对NLP的影响
- 量子计算对NLP的应用:量子计算在NLP领域的潜在应用,如优化模型训练过程、加速自然语言处理任务等。
- 自监督学习的兴起:自监督学习技术在自然语言处理中的应用,提高数据利用效率,降低标注数据成本,促进模型的不断进步。
自然语言处理在其他领域的拓展与应用
- 跨学科融合:NLP与生物信息学、社会科学、艺术等领域的融合,推动跨学科研究与应用的发展。
- 自然语言处理与物联网的结合:结合NLP技术与物联网,实现更智能、自动化的物联网应用,如智能家居、智能城市等。
流程图示例
以上是关于BERT在NLP领域未来发展趋势、新兴技术对NLP的影响、以及自然语言处理在其他领域的拓展与应用的内容。希望这些信息能够丰富您的文章内容!
相关文章:

BERT入门:理解自然语言处理中的基本概念
1. 自然语言处理简介 自然语言处理(Natural Language Processing,NLP)是人工智能领域的重要分支,涉及计算机与人类自然语言之间的相互作用。NLP 的应用已经深入到我们日常生活中的方方面面,如智能助理、机器翻译、舆情…...

Discoverydevice.java和activity_discoverydevice.xml
一、Discoverydevice.java public class Discoverydevice extends AppCompatActivity {private DeviceAdapter mAdapter2;private final List<DeviceClass> mbondDeviceList new ArrayList<>();//搜索到的所有已绑定设备保存为列表private final List<Devic…...
)
华为OD机试 - 最多颜色的车辆(Java JS Python C C++)
须知 哈喽,本题库完全免费,收费是为了防止被爬,大家订阅专栏后可以私信联系退款。感谢支持 文章目录 须知题目描述输入描述输出描述解析代码题目描述 在一个狭小的路口,每秒只能通过一辆车,假设车辆的颜色只有 3 种,找出 N 秒内经过的最多颜色的车辆数量。 三种颜色编…...

【无人机/平衡车/机器人】详解STM32+MPU6050姿态解算—卡尔曼滤波+四元数法+互补滤波——附3个算法源码
效果: MPU6050姿态解算-卡尔曼滤波+四元数+互补滤波 目录 基础知识详解 欧拉角...
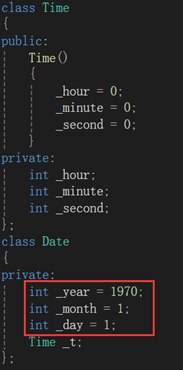
NzN的C++之路--构造函数与析构函数
如果一个类中既没有成员变量也没有成员函数,这个类简称为空类。空类中其实并不是什么都没有,任何类在什么都不写时,编译器会自动生成6个默认成员函数。那今天我们就来学习一下其中两个默认成员函数:构造函数与析构函数。先三连后看…...

【算法刷题day24】Leetcode:216. 组合总和 III、17. 电话号码的字母组合
文章目录 Leetcode 216. 组合总和 III解题思路代码总结 Leetcode 17. 电话号码的字母组合解题思路代码总结 草稿图网站 java的Deque Leetcode 216. 组合总和 III 题目:216. 组合总和 III 解析:代码随想录解析 解题思路 回溯三部曲:确定递归…...

一体化泵站的生产制造流程怎样
诸城市鑫淼环保小编带大家了解一下一体化泵站的生产制造流程怎样 综合泵站和传统式混泥土泵站的一大差别是,离去制造厂前,能够开展全部机械设备设备的生产加工及零部件加工,随后运送到建筑项目当场开展安裝。这类经营方式缩短了开发周期&…...

【1】C++设计模式之【单例模式】
单例模式在C中的实现方式有以下几种: 懒汉式(线程不安全)饿汉式(线程安全)双检锁/双重校验锁(DCL,线程安全)静态局部变量(线程安全)C11版本(线程…...

软件设计模式之解释器模式
一、引言 在软件设计中,我们经常遇到需要“解释”和执行某种特定语法或语言的情况。这时,解释器模式就派上了用场。解释器模式(Interpreter Pattern)是一种行为设计模式,它提供了一种解释语言的语法并定义一个句子如何…...
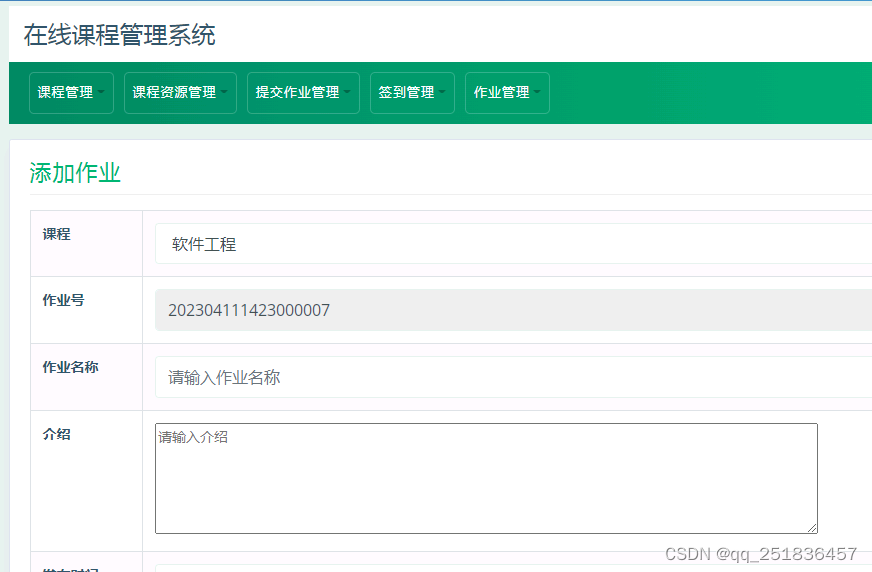
java Web课程管理系统用eclipse定制开发mysql数据库BS模式java编程jdbc
一、源码特点 JSP 课程管理系统是一套完善的web设计系统,对理解JSP java 编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOMCAT7.0,eclipse开发,数据库为Mysql5.0,使用ja…...
Electron 桌面端应用的使用 ---前端开发
Electron是什么? Electron是一个使用 JavaScript、HTML 和 CSS 构建桌面应用程序的框架。 嵌入 Chromium 和 Node.js 到 二进制的 Electron 允许您保持一个 JavaScript 代码代码库并创建 在Windows上运行的跨平台应用 macOS和Linux——不需要本地开发 经验。 入门…...
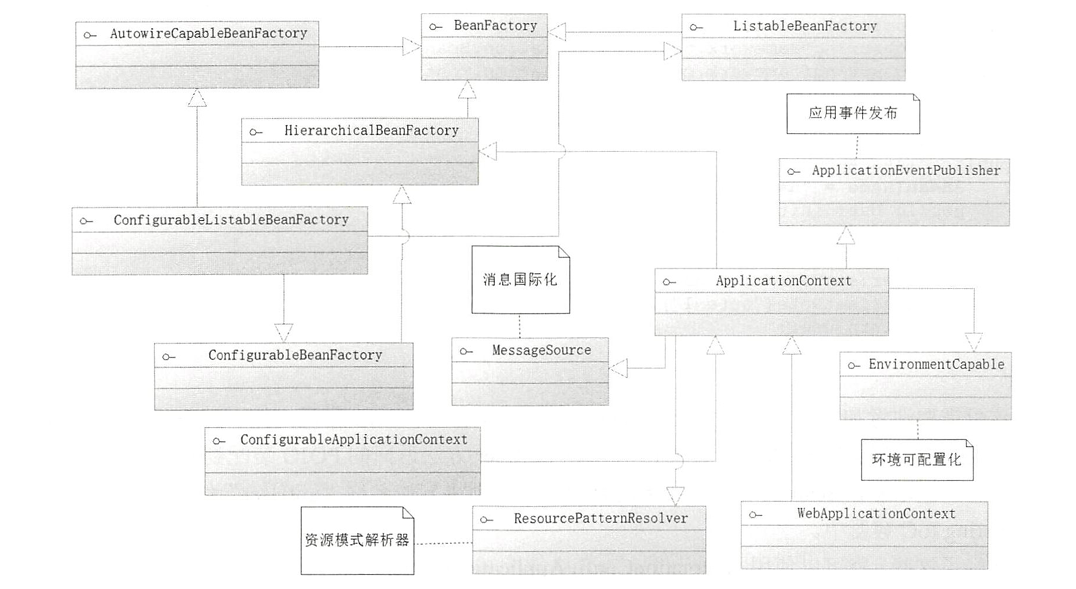
【SpringBoot:详解Bean装配】
🏡Java码农探花: 🔥 推荐专栏:<springboot学习> 🛸学无止境,不骄不躁,知行合一 文章目录 前言一、IoC容器的简介BeanFactory接口源码二、Bean装配扫描装配探索启动类条件装配自定义Bean总…...

前端如何将接口返回的码值转成对应的中文展示呢?
后端接口只返回码值,那前端如何将码值转成对应的中文展示呢? 项目中后端接口都是将码值返给前端,前端通过公共获取码值的接口然后将其对应转码 以下是举例操作: created() {//这是公共接口的码值表let oneType [{value: 01,content: 一类,},{value: 02,content: 二类,},];//…...

智慧公厕中的大数据、云计算和物联网技术引领未来公厕管理革命
现代社会对于公共卫生和环境保护的要求越来越高,智慧公厕作为城市基础设施建设的重要组成部分,正引领着公厕管理的革命。随着科技的不断进步,大数据、云计算和物联网技术的应用为智慧公厕带来了全新的可能性,(ZonTree中…...

Excel与项目管理软件比较?哪个是项目组合管理的最佳选择?
在定义和管理每个正在进行的项目的资源、任务、收益、风险和优先级时,项目组合管理已成为公司的战略要素。为了实现高效的项目组合管理,PMO 经理需要评估Excel 是否满足他们管理项目组合的需求,或者是否应该尝试不同的解决方案,例…...

过程控制风格的软件架构设计概念及其实际应用
摘要 过程控制风格的软件架构设计强调程序的流程控制逻辑和组件之间的交互方式,旨在提升系统的响应性、扩展性和可维护性。这种架构风格在需要严格的操作序列和流程控制的应用中尤为重要,例如在嵌入式系统、实时系统和复杂的业务流程管理中。本文将介绍…...

WPF 编辑器模式中隐藏/显示该元素
XAML中引用:xmlns:d"http://schemas.microsoft.com/expression/blend/2008" 在所需要的控件中加上d:Visibility"Visible"属性 d:Visibility属性有3个值,可以根据需要进行设置 转自:在Visual Studio设计器中隐藏WPF元素…...

分布式事务 - 个人笔记 @by_TWJ
目录 1. 传统事务1.1. 事务特征1.2. 事务隔离级别1.2.1. 表格展示1.2.2. oracle和mysql可支持的事务隔离级别 2. 分布式事务2.1. CAP指标2.2. BASE理论2.3. 7种常见的分布式事务方案2.3.1. 2PC2.3.2. 3PC2.3.3. TCC2.3.3.1. TCC的注意事项:2.3.3.2. TCC方案的优缺点…...

解决前端笔记本电脑屏幕显示缩放比例125%、150%对页面大小的影响问题--数据可视化大屏
近期在工作中遇到一个问题,记录一下,在项目上线之后,遇到一个问题,即缩放到90%时,页面字体比默认的100%字体大,一开始毫无头绪,经过一番的Google...Google...Google....,终于找到了解…...
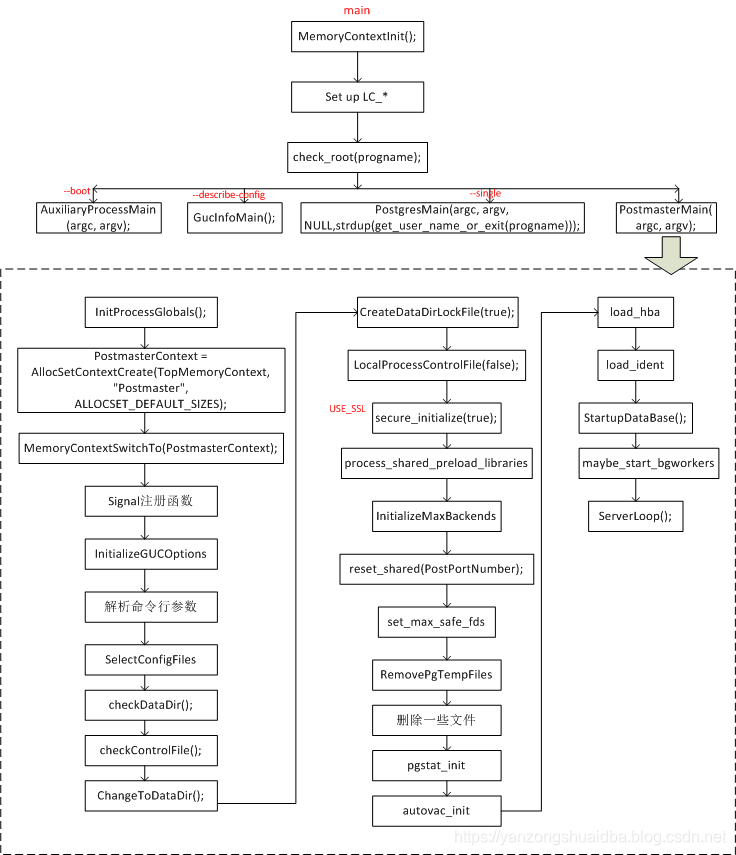
【PG-1】PostgreSQL体系结构概述
1. PostgreSQL体系结构概述 代码结构 其中,backend是后端核心代码,包括右边的几个dir: access:处理数据访问方法和索引的代码。 bootstrap:数据库初始化相关的代码。 catalog:系统目录(如表和索引的元数据…...

Dify自定义工具服务开发指南:独立部署与AI应用扩展实践
1. 项目概述:一个为Dify打造的定制化工具服务最近在折腾AI应用开发平台Dify时,发现虽然它内置的工具(Tools)生态已经挺丰富了,但总有些特定场景下的需求,比如调用一个内部审批系统、查询某个私有数据库的特…...

Poppins字体:如何用一款免费字体搞定多语言设计难题?
Poppins字体:如何用一款免费字体搞定多语言设计难题? 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 还在为多语言项目寻找合适的字体而烦恼吗ÿ…...
)
AI应用开发面试题总结(非八股文)
前端请求超过 3 秒,怎么分析原因? 1.看前端和网络 F12开发者模式去查看network,首先判断是前端问题还是后端问题 通过查看接口 Waiting 时间进行判断是后端响应时间太长还是说前端渲染问题 2.给后端接口添加日志进一步定位后端问题 3.如果…...

从‘方波变形记’聊起:为什么你的高速信号需要Tx EQ?一个给嵌入式软件/FPGA工程师的通俗图解
从‘方波变形记’聊起:为什么你的高速信号需要Tx EQ? 想象一下,你正在观看一场高清直播,画面突然出现马赛克;或者传输重要数据时,系统频繁报错。这些问题的根源,可能就藏在信号传输的微观世界里…...

Llama-3中文优化实战:从模型选型到本地部署全解析
1. 项目概述:从Llama-3到中文Llama-3的进化之路 如果你在过去一年里关注过开源大模型,那么“Llama”这个名字对你来说一定不陌生。从Meta发布Llama-2开始,这个系列就成为了开源社区构建垂直领域模型的基石。今年4月,Meta又扔下了一…...

Gentoo Linux 中通过 Overlay 优雅安装 Cursor 二进制编辑器
1. 项目概述与背景如果你是一名 Gentoo Linux 的用户,同时又对 Cursor 这款新兴的 AI 代码编辑器感兴趣,那么你很可能已经遇到了一个经典的 Gentoo 式难题:如何在这样一个以源码编译为核心的发行版上,方便地安装一个官方只提供.de…...

量子网络远程纠缠生成技术及其应用
1. 量子网络中的远程纠缠生成技术解析量子纠缠作为量子计算与量子通信的核心资源,其非局域特性为分布式系统提供了经典方法无法实现的协调能力。在金融高频交易、智能电网调度等对延迟极度敏感的领域,量子纠缠带来的协调优势尤为显著。基于腔量子电动力学…...

OpenClacky:AI Agent技能加密与商业分发平台实战指南
1. 项目概述:从开源共享到知识变现的桥梁在AI Agent(智能体)生态蓬勃发展的今天,我们看到了一个有趣的现象:无数开发者贡献了海量的“技能”(Skills),让像OpenClaw这样的平台功能日益…...

NanoSVG完整教程:从SVG文件解析到贝塞尔曲线渲染
NanoSVG完整教程:从SVG文件解析到贝塞尔曲线渲染 【免费下载链接】nanosvg Simple stupid SVG parser 项目地址: https://gitcode.com/gh_mirrors/na/nanosvg NanoSVG是一款轻量级的SVG解析库,能够将SVG文件高效转换为贝塞尔曲线数据,…...

Nitric本地开发环境搭建:快速测试和调试的完整流程
Nitric本地开发环境搭建:快速测试和调试的完整流程 【免费下载链接】nitric Nitric is a multi-language framework for cloud applications with infrastructure from code. 项目地址: https://gitcode.com/gh_mirrors/ni/nitric Nitric是一个多语言框架&am…...