Isolation Forest 简介
1. 简介
孤立森林 iForest(Isolation Forest)是一种无监督学习算法,用于识别异常值。其基本原理是:异常数据由于数量较少且与正常数据差异较大,因此在被隔离时需要较少的步骤。
两个假设:
1. 异常的值是非常少的(如果异常值很多,可能被识别为正常的);
2. 异常值与其他值的差异较大(主要是全局上都为异常的异常,局部小异常可能发现不了,因为差异并不大)。
2. 具体流程
2.1 训练森林
子采样: 首先从整个数据集中随机抽取一定数量的样本来为构建树做准备。这些抽样的子集大小通常远小于原始数据集的大小,这样可以限制树的大小,并且减少计算复杂度。
构建孤立树 (iTrees): 对于每个子采样集,算法构建一棵孤立树。构建孤立树的过程是递归的。在每个节点,算法随机选择一个特征,并在该特征的最大值和最小值之间随机选择一个分割值。然后,数据根据这个分割值将样本分到左子树或右子树(这里其实就是简单的将样本中特征小于这个分割点的样本分到左边,其次分到右边)。这个过程的结束条件:树达到限定的高度, 节点中的样本数量到一定的数目,或者所有样本的所选特征值都是同一个值。
森林构建: 重复1-2构建完特定数量的孤立树,集合为孤立森林。
2.2 首先要明确几个相关概念
路径长度( h ( x ) h(x) h(x)): 指样本通过该孤立树构建阶段的特征选择方式,从树的根节点到达该样本被孤立的节点(被孤立就是意味着这个样本最终到达的树的叶子节点)所需要的边数。
平均路径长度 E ( h ( x ) ) E(h(x)) E(h(x)): 该样本在森林中所有树的路径长度的平均值。
树的平均路径长度:
c ( n ) = 2 H ( n − 1 ) − 2 ( n − 1 ) n c(n)=2H(n-1)-\frac{2(n-1)}{n} c(n)=2H(n−1)−n2(n−1)
-----
iForest 适用于连续数据的异常检测,将异常定义为 容易被孤立的离群点。 具体的,确定一个维度的特征,
并在最大值和最小值之间随机选择一个值 x ,然后按照小于 x 和 大于等于x 可以把数据分成左右两组。
然后再随机的按某个特征维度的取值把数据进行细分,重复上述步骤,直到无法细分,
直到数据不可再分。直观上,异常数据较少次切分就可以将它们单独划分出来,而正常数据恰恰相反。
sklearn.ensemble.IsolationForest
contamination:默认为auto,数据集中异常样本的比例
优点:高精准度
3. 算法优缺点
3.1 优点
1. 高效性:IF特别适合处理大数据集。它具有线性的时间复杂度,并且由于使用了子采样,使得在计算上更加高效。
2. 易于并行化: 和RF一样,构建孤立树是独立的过程,构建森林可以并行化。
3.2 缺点
1. 异常值比例敏感性: 如果数据集中异常值的比例相对较高,其效果可能就会下降,因为它是基于异常值“少而不同”的假设。
2. 对局部异常检测不敏感:因为 “少而不同的” 前提条件决定主要解决全局异常的特点,对在局部区域表现出轻微异常特征的点检测不是很敏感。
3. 不适用于特别高维的数据:IF不会因为特征的多少而降低算法的效率,但也正因为每次只随机用其中一个特征作为分割的特征,如果特征维度很高,就会有很多特征没有用到。
4. demo
4.1 数据准备
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_splitn_samples, n_outliers = 120, 10
rng = np.random.RandomState(0)
cluster_1 = 0.4 * rng.randn(n_samples, 2) + np.array([2, 2])
cluster_2 = 0.3 * rng.randn(n_samples, 2) + np.array([-2, -2])
outliers = rng.uniform(low=-4, high=4, size=(n_outliers, 2))
X = np.concatenate([cluster_1, cluster_2, outliers])
y = np.concatenate([np.ones((2 * n_samples), dtype=int), -np.ones(n_outliers, dtype=int)])scatter = plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k")
handles, labels = scatter.legend_elements()
plt.axis("square")
plt.legend(handles=handles, labels=["outliers", "inliers"], title="true class")
plt.title("data distribution")
plt.show()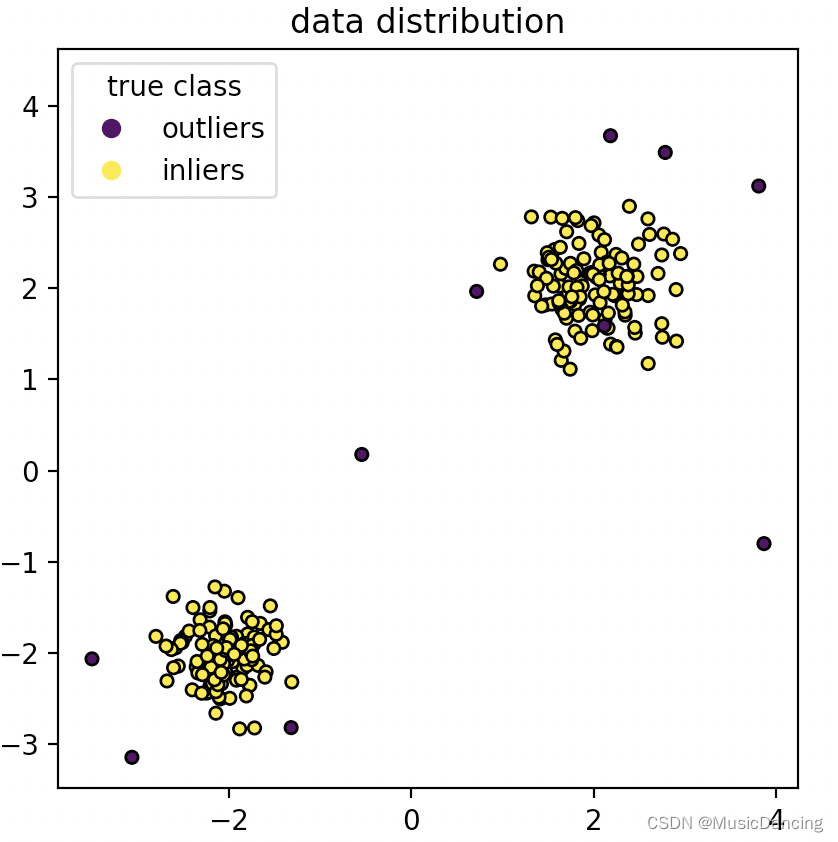
4.2 模型预测&可视化
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_splitn_samples, n_outliers = 120, 10
rng = np.random.RandomState(0)
cluster_1 = 0.4 * rng.randn(n_samples, 2) + np.array([2, 2])
cluster_2 = 0.3 * rng.randn(n_samples, 2) + np.array([-2, -2])
outliers = rng.uniform(low=-4, high=4, size=(n_outliers, 2))
X = np.concatenate([cluster_1, cluster_2, outliers])
y = np.concatenate([np.ones((2 * n_samples), dtype=int), -np.ones(n_outliers, dtype=int)])X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
from sklearn.ensemble import IsolationForest
clf = IsolationForest(max_samples=100, random_state=0)
clf.fit(X_train)
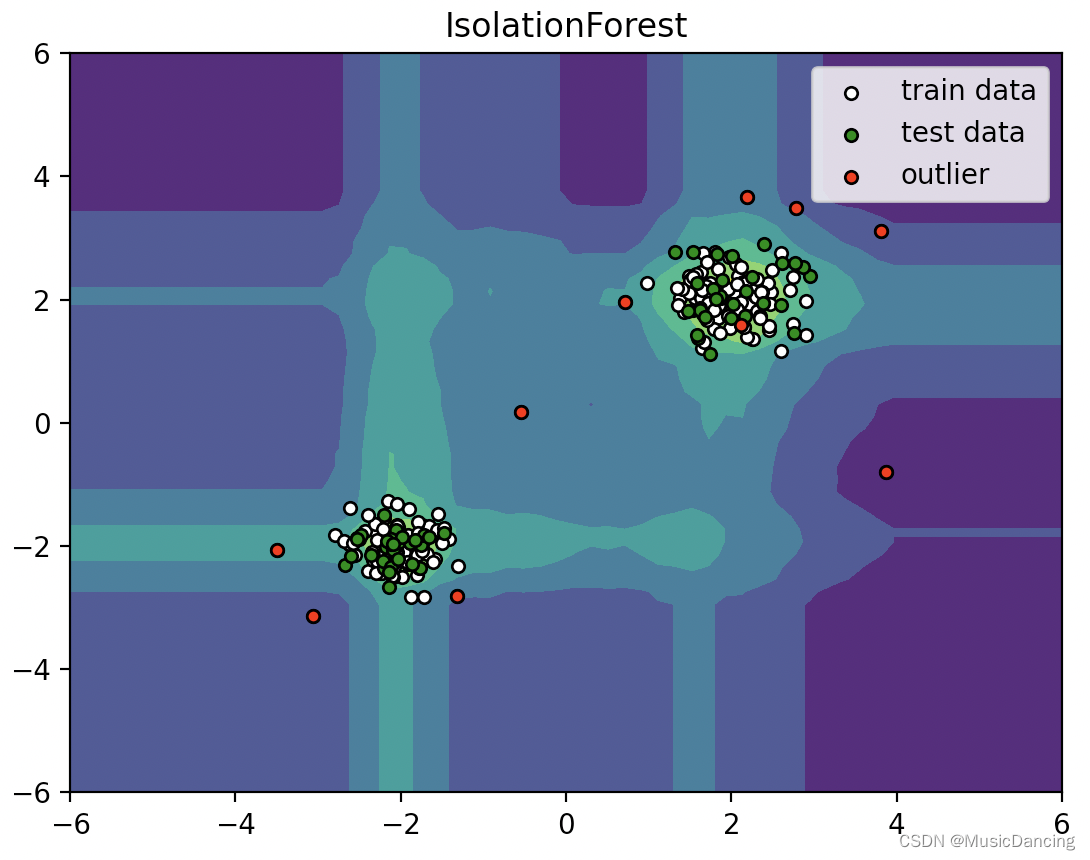
y_pre_score_test = clf.decision_function(cluster_1) # -1为异常, 1为正常,
y_pre_label_test = clf.predict(cluster_1)# ---------结果可视化--------------
# 通过网格的方式得到location的x和y坐标
xx, yy = np.meshgrid(np.linspace(-6, 6, 60), np.linspace(-6, 6, 60))
# concat x和y 得到输入的坐标
input_location = np.c_[xx.ravel(), yy.ravel()]
Z = clf.decision_function(input_location)
Z = Z.reshape(xx.shape)plt.title("IsolationForest")
plt.contourf(xx, yy, Z, camp=plt.cm.Blues_r)
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white', s=20, edgecolor='k')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='green', s=20, edgecolor='k')
c = plt.scatter(outliers[:, 0], outliers[:, 1], c='red', s=20, edgecolor='k')
plt.axis('tight')
plt.xlim((-6, 6))
plt.ylim((-6, 6))
plt.legend([b1, b2, c], ["train data", "test data", "outlier"], loc="best")
plt.show()
相关文章:
Isolation Forest 简介
1. 简介 孤立森林 iForest(Isolation Forest)是一种无监督学习算法,用于识别异常值。其基本原理是:异常数据由于数量较少且与正常数据差异较大,因此在被隔离时需要较少的步骤。 两个假设: 1. 异常的值是非常少的(如果异常值很多&…...

Java爬虫携带sign签名
站点:https://www.mytokencap.com/ 代码分析先不写了,大家自行解决,贴代码 1、业务请求设计 public static void md5Pro() {String url "https://api.mytokenapi.com/ticker/currencylistforall";Map<String, String> he…...
设计者模式之中介者模式(下)
3)中介者与同事类的扩展 1.结构图 新增了具体同事类Label和具体中介者类SubConcreteMediator。 2.代码实现 //文本标签类:具体同事类 public class Label extends Component {public void update() {System.out.println("文本标签内容改变&#…...
SAP SD学习笔记04 - 出荷Plant(交货工厂),出荷Point(装运点),输送计划,品目的可用性检查,一括纳入/分割纳入,仓库管理
上一章讲了SD的主数据。 SAP SD学习笔记03 - SD模块中的主数据-CSDN博客 本章讲出荷Plant(交货工厂),出荷Point(装运点)和出和路线。 还是偏理论多一些,后面的文章尽量多加些练习巩固一下。 1࿰…...
)
bind包装器——C++新特性(三)
文章目录 bindbind函数模板的原型bind 包装器的用途其他使用示例 🎖 博主的CSDN主页:Ryan.Alaskan Malamute 📜 博主的代码仓库主页 [ Gitee ]:ryanala [GitHub]: Ryan-Ala bind bind也是一种函数包装器…...

MXNet的下载安装及问题处理
1、MXNet介绍: MXNet是一个开源的深度学习框架,以其灵活性和效率著称,支持多种编程接口,包括Python、C、R、Julia、Scala等。MXNet支持大规模分布式训练,同时兼顾CPU和GPU的计算资源,尤其擅长于模型并行和数…...

Python 中的列表排序和排序规则
Python 中的列表排序和排序规则 在 Python 中,列表的排序是一个常见的操作,可以使用内置函数 sorted() 或列表对象的 sort() 方法来完成。下面将介绍这两种方法以及排序规则的使用方式。 1. 使用 sorted() 函数排序列表(临时性排序…...

面经整理1
感觉好几个都是backtracking Letter Combinations of a Phone Number - LeetCode 典型的backtracking,注意String的处理 class Solution {String[] keyboard new String[]{"", "", "abc","def","ghi","…...
)
ChatGPT个人专用版 SSRF漏洞复现(CVE-2024-27564)
0x01 产品简介 ChatGPT个人专用版是一种基于 OpenAI 的 GPT-3.5 、GPT-4.0语言模型的产品。它是设计用于 Web 环境中的聊天机器人,旨在为用户提供自然语言交互和智能对话的能力。PHP版调用OpenAI接口进行问答和画图,采用Stream流模式通信,一边生成一边输出。前端采用EventS…...

Python中的可哈希与不可哈希对象详解
文章目录 1. 前置知识:哈希是什么2. 可哈希和不可哈希对象的定义2.1可哈希2.2 不可哈希 3. 对象的哈希方法3.1 自定义对象的哈希方法3.2 可哈希性与等价性3.3 哈希值的用途 推荐 在复习可变对象和不可变对象时,学到了这个内容 1. 前置知识:哈…...

【嵌入式DIY实例】-DIY速度计
DIY速度计 文章目录 DIY速度计1、硬件准备1.1 NEO-6M GPS模块介绍1.2 硬件接线原理图2、代码实现本文将介绍如何使用模拟仪表和 GPS 模块制作 DIY Arduino 速度计。 仪表用于显示当前速度,而GPS模块用于实时跟踪速度。 该项目将 Arduino 板与 GPS 模块相结合,在经典模拟仪表上…...

1.0 Hadoop 教程
1.0 Hadoop 教程 分类 Hadoop 教程 Hadoop 是一个开源的分布式计算和存储框架,由 Apache 基金会开发和维护。 Hadoop 为庞大的计算机集群提供可靠的、可伸缩的应用层计算和存储支持,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集…...

【无人机/平衡车/机器人】详解STM32+MPU6050姿态解算—卡尔曼滤波+四元数法+互补滤波(文末附3个算法源码)
效果: MPU6050姿态解算-卡尔曼滤波+四元数+互补滤波 目录 基础知识详解 欧拉角...

智能水务系统:构建高效节水的城市水网
随着城市化进程的加速和人民生活水平的提高,对水务管理的需求也越来越高。传统的水务管理方式已经无法满足现代社会的需求,而智能水务系统的出现为水务管理带来了新的变革。本文将从项目背景、需求分析、建设目标、建设内容、技术方案、安全设计等方面&a…...

【JavaEE初阶系列】——网络编程 UDP客户端/服务器 程序实现
目录 🚩UDP和TCP之间的区别 🎈TCP是有连接的 UDP是无连接的 🎈TCP是可靠传输 UDP是不可靠传输 🎈TCP是面向字节流 UDP是面向数据报 🎈TCP和UDP是全双工 👩🏻💻UDP的socket ap…...
数据结构复习指导之绪论(算法的概念以及效率的度量)
文章目录 绪论: 2.算法和算法评价 知识总览 2.1算法的基本概念 知识点回顾与重要考点 2.2算法效率的度量 知识总览 1.时间复杂度 2.空间复杂度 知识点回顾与重要考点 归纳总结 绪论: 2.算法和算法评价 知识总览 2.1算法的基本概念 算法( Al…...
)
C语言经典例题(23)
1.求n的阶乘。(不考虑溢出) #include <stdio.h>int fac(int n);int main() {int n 0;scanf("%d", &n);int sum fac(n);printf("%d", sum);return 0; }int fac(int n) {if (n > 1){return n * fac(n - 1);}elsereturn 1; }2.求第n个斐波那契…...

Gitea的简单介绍
Gitea 是一个自由、开源、轻量级的 Git 服务程序。它是为了建立一个易于使用的、类似 GitHub 的 Git 服务而创建的。Gitea 采用 Go 语言编写,具有简单、快速、易于安装和配置的特点。 Gitea 提供了一个基本的 Web 界面,可以方便地进行代码托管、问题跟踪、协作等操作。用户可…...

Qt信号与槽
我们在使用Qt的时候,不使用Qt Designer 的方式进行开发,使用ui文件,信号与槽的连接方式是生成代码之后才能在setupUi函数里才能看到,或者需要进入Ui设计器里的信号槽模式里才能看到信号槽的连接。所以我们最好使用代码绘制界面。 …...
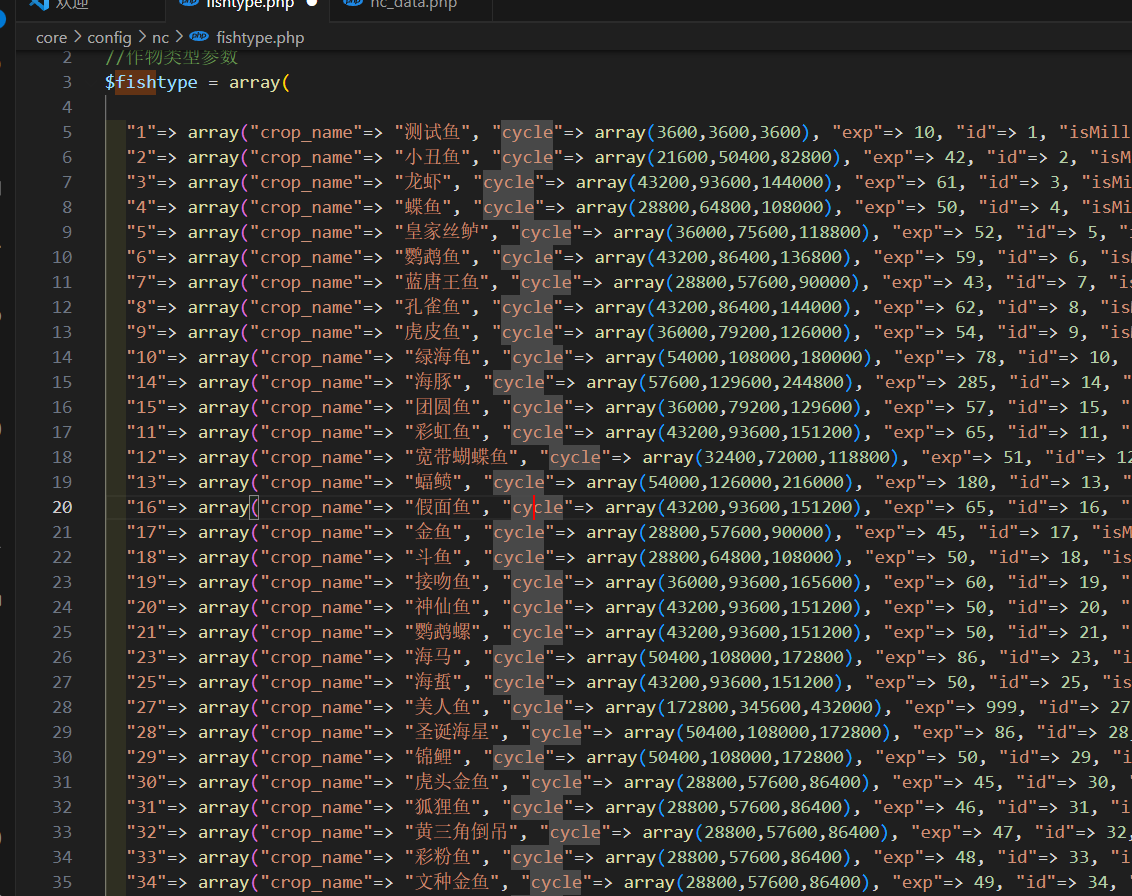
QQ农场-phpYeFarm添加数据教程
前置知识 plugin\qqfarm\core\data D:\study-project\testweb\upload\source\plugin\qqfarm\core\data 也就是plugin\qqfarm\core\data是一个缓存文件,如果更新农场数据后,必须要删除才可以 解决种子限制(必须要做才可以添加成功) 你不更改加入了id大于2000直接删除种子 D…...

鸿蒙系统安装
一、下载 DevEco Studio 打开华为开发者官网,找到 DevEco Studio 6.1.0 Release 下载页面。 DevEco Studio for Windows 6.1.0.830(2.8GB) 下载。 Mac 用户可以选择对应版本(x86/ARM)。 等待下载完成,得到 .exe 安装文件。二、安装…...

Atlas机器人:人形设计、液压驱动与救灾场景下的技术权衡
1. 项目概述:Atlas,一个充满争议的工程里程碑2013年,当波士顿动力公司为DARPA(美国国防高级研究计划局)打造的Atlas机器人首次公开亮相时,它在工程技术社区引发的震动,远不止于其令人惊叹的行走…...

AXI协议深度解析:从握手到低功耗,一次搞懂芯片内部数据流的那些“潜规则”
AXI协议深度解析:从握手到低功耗,一次搞懂芯片内部数据流的那些“潜规则” 在当今高性能计算和复杂SoC设计中,AXI协议已成为连接处理器、存储器和外设的黄金标准。但真正理解AXI的精髓,远不止于掌握基础操作——那些隐藏在规范字里…...

终极网盘直链下载助手完整指南:告别限速,快速获取八大平台真实下载地址
终极网盘直链下载助手完整指南:告别限速,快速获取八大平台真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里…...

基于双链笔记构建个人消费知识系统:从记录到生活策展
1. 项目概述与核心价值看到“SimonsTang/xiaofei-liberal-arts”这个项目标题,我的第一反应是,这应该是一个关于“消费”与“文科”交叉领域的知识库或工具集。作为一名长期关注效率工具和知识管理的从业者,我深知在信息爆炸的时代࿰…...

基于OpenClaw构建开源项目与Docker镜像自动化监控方案
1. 项目概述 作为一个常年泡在开源社区和容器生态里的开发者,我深知“追新”的痛。今天这个项目发布了v2.0,明天那个镜像更新了安全补丁,手动去GitHub和Docker Hub一个个检查,效率低不说,还容易遗漏关键更新。为了解决…...

终极指南:在Windows上轻松安装安卓应用,告别笨重模拟器
终极指南:在Windows上轻松安装安卓应用,告别笨重模拟器 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行安卓应…...

基于STM32的数控恒流源:从硬件闭环到软件PD调节的工程实践
1. 数控恒流源的核心需求与设计思路 第一次接触数控恒流源是在三年前的一个工业检测设备项目中,当时需要为传感器阵列提供精确的电流激励。传统模拟恒流方案遇到温度漂移问题,最终选择了STM32数控方案。这种方案最大的优势在于:硬件闭环保证响…...

RK3368安卓9.0固件烧录后开机卡Recovery?手把手教你调整分区表解决4GB闪存空间不足
RK3368安卓9.0固件烧录实战:4GB闪存分区优化全解析 当你满怀期待地将Android 9.0固件烧录到RK3368开发板,却发现设备直接进入了Recovery模式,屏幕上躺着那个令人沮丧的红色感叹号机器人——这可能是每个嵌入式开发者都经历过的"入门仪式…...

Metz Connect工业连接器国产替代技术解析
在工业自动化、楼宇控制以及通信基础设施领域,连接器作为底层物理连接单元,直接影响系统的稳定性与长期可靠运行。Metz Connect作为德国知名连接技术厂商,其产品涵盖工业以太网连接器、PCB端子、RJ45模块化接口、M12工业连接器以及DIN导轨I/O…...