头歌-机器学习 第11次实验 softmax回归
第1关:softmax回归原理
任务描述
本关任务:使用Python实现softmax函数。
相关知识
为了完成本关任务,你需要掌握:1.softmax回归原理,2.softmax函数。
softmax回归原理
与逻辑回归一样,softmax回归同样是一个分类算法,不过它是一个多分类的算法,我们的数据有多少个特征,则有多少个输入,有多少个类别,它就有多少个输出。
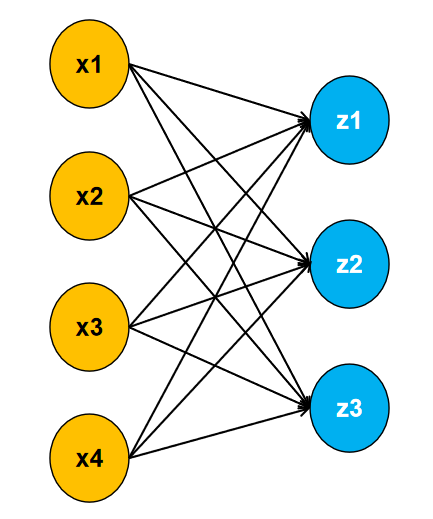
如上图,可以看出我们的数据有四个特征,三个类别。每个输入与输出都有一个权重相连接,且每个输出都有一个对应的偏置。具体公式如下:
z1=x1w11+x2w12+x3w13+x4w14+b1
z2=x1w21+x2w22+x3w23+x4w24+b2
z3=x1w31+x2w32+x3w33+x4w34+b3
输出z1,z2,z3值的大小,代表属于每个类别的可能性。如:z1=1,z2=10,z3=100表示样本预测为z3这个类别。 然而,直接将得到的输出作为判断样本属于某个类别的可能性存在不少的弊端。如,你得到一个输出为10,你可能觉得他属于这个类别的可能性很大,但另外两个输出的值都为1000,这个时候表示是这个类别的可能性反而非常小。所以,我们需要将输出统一到一个范围,如0到1之间。这个时候,如果有一个输出的值为0.9,那么你就可以非常确定,它属于这个类别了。
softmax函数
softmax函数公式如下:
y^i=∑i=1cexp(zi)exp((zi))
其中,i表示第i个类别,c为总类别数。由公式可知:
0≤y^≤0
i=1∑cy^=1
这样就可以将输出的值转换到0到1之间,且总和为1。每个类别对应的输出值可以当做样本为这个类别的概率。对于单个样本,假如一共有0,1,2三个类别,对应的输出为[0.2,0.3,0.5]则最后判断为2这个类别。
编程要求
根据提示,在右侧编辑器补充Python代码,实现softmax函数,底层代码会调用你实现的softmax函数来进行测试。
测试说明
程序会调用你实现的方法对随机生成的数据进行测试,若结果正确则视为通关,否则输出使用你方法后返回的数据。
#encoding=utf8
import numpy as npdef softmax(x):'''input:x(ndarray):输入数据,shape=(m,n)output:y(ndarray):经过softmax函数后的输出shape=(m,n)'''# 确保x是一个二维数组assert len(x.shape) == 2# 对每一行求最大值row_max = np.max(x, axis=1)# 对每个元素减去所在行的最大值x -= row_max.reshape((-1, 1))# 计算指数函数exp_x = np.exp(x)# 对每一行求和row_sum = np.sum(exp_x, axis=1)# 除以所在行的总和y = exp_x / row_sum.reshape((-1, 1))return y第2关:softmax回归训练流程
任务描述
本关任务:使用python实现softmax回归算法,使用已知鸢尾花数据对模型进行训练,并对未知鸢尾花数据进行预测。
相关知识
为了完成本关任务,你需要掌握:1.softmax回归模型,2.softmax回归训练流程。
softmax回归模型
与逻辑回归一样,我们先对数据进行向量化:
X=(x0,x1,...,xn)
其中,x0等于1。且X形状为m行n+1列,m为样本个数,n为特征个数。
W=(w1,...,wc)
W形状为n+1行c列,c为总类别个数。
Z=XW
Z形状为m行c列。
Y^=softmax(Z)
同样的,Y^的形状为m行c列。第i行代表第i个样本为每个类别的概率。
对于每个样本,我们将其判定为输出中最大值对应的类别。
softmax回归训练流程
softmax回归训练流程同逻辑回归一样,首先得构造一个损失函数,再利用梯度下降方法最小化损失函数,从而达到更新参数的目的。具体流程如下:
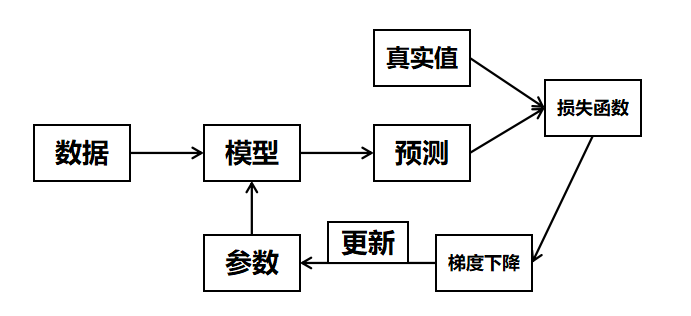
关于梯度下降详细内容请点击查看
softmax回归使用的损失函数为交叉熵损失函数,公式如下:
loss=m1i=1∑m−yilogy^i
其中,yi为onehot后的标签,y^i为预测值。同样的我们可以求得损失函数对参数的梯度为:
∂w∂loss=(y^−y)x
于是,在softmax回归中的梯度下降公式如下:
W=W−ηX.T(Y^−Y)
编程要求
根据提示,在右侧编辑器补充代码,实现softmax回归算法。
测试说明
程序会调用你实现的方法对模型进行训练,并对未知鸢尾花数据进行预测,正确率大于0.95则视为通关。
import numpy as np
from sklearn.preprocessing import OneHotEncoderdef softmax(x):'''input:x(ndarray):输入数据output:y(ndarray):经过softmax函数后的输出'''#********* Begin *********## 确保x是一个二维数组assert len(x.shape) == 2# 对每一行求最大值row_max = np.max(x, axis=1)# 对每个元素减去所在行的最大值x -= row_max.reshape((-1, 1))# 计算指数函数exp_x = np.exp(x)# 对每一行求和row_sum = np.sum(exp_x, axis=1)# 除以所在行的总和y = exp_x / row_sum.reshape((-1, 1))#********* End *********#return ydef softmax_reg(train_data,train_label,test_data,lr,max_iter):'''input:train_data(ndarray):训练数据train_label(ndarray):训练标签test_data(ndarray):测试数据lr(float):梯度下降中的学习率参数max_iter(int):训练轮数output:predict(ndarray):预测结果'''#********* Begin *********##将x0加入训练数据m,n = train_data.shapetrain_data = np.insert(train_data, 0, values=np.ones(m), axis=1)#转换为onehot标签enc = OneHotEncoder()train_label = enc.fit_transform(train_label.reshape(-1, 1)).toarray()#对w,z,y初始化w = np.zeros((n+1, train_label.shape[1]))z = np.dot(train_data, w)y = softmax(z)#利用梯度下降对模型进行训练for i in range(max_iter):# 计算梯度gradient = np.dot(train_data.T, (y - train_label))# 更新权重w -= lr * gradient# 重新计算z和yz = np.dot(train_data, w)y = softmax(z)#将x0加入测试数据m_test,n_test = test_data.shapetest_data = np.insert(test_data, 0, values=np.ones(m_test), axis=1)#进行预测predict = np.argmax(np.dot(test_data, w), axis=1)#********* End *********#return predict第3关:sklearn中的softmax回归
任务描述
本关任务:使用sklearn中的LogisticRegression类完成红酒分类任务。
相关知识
为了完成本关任务,你需要掌握如何使用sklearn提供的LogisticRegression类。
数据集介绍
数据集为一份红酒数据,一共有178个样本,每个样本有13个特征,3个类别,你需要自己根据这13个特征对红酒进行分类,部分数据如下图:

数据获取代码:
import pandas as pddata_frame = pd.read_csv('./step3/dataset.csv', header=0)
LogisticRegression
LogisticRegression中将参数multi_class设为"multinomial"则表示使用softmax回归方法。 LogisticRegression的构造函数中有三个常用的参数可以设置:
solver:{'newton-cg' , 'lbfgs', 'sag', 'saga'}, 分别为几种优化算法。C:正则化系数的倒数,默认为1.0,越小代表正则化越强。max_iter:最大训练轮数,默认为100。
和 sklearn 中其他分类器一样,LogisticRegression类中的fit函数用于训练模型,fit函数有两个向量输入:
X:大小为 [样本数量,特征数量] 的ndarray,存放训练样本Y:值为整型,大小为 [样本数量] 的ndarray,存放训练样本的分类标签
LogisticRegression类中的predict函数用于预测,返回预测标签,predict函数有一个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放预测样本
LogisticRegression的使用代码如下:
softmax_reg = LogisticRegression(multi_class="multinomial")softmax_reg.fit(X_train, Y_train)result = softmax_reg.predict(X_test)
编程要求
根据提示,在右侧编辑器补充代码,利用sklearn实现softmax回归。
测试说明
程序会调用你实现的方法对红酒数据进行分类,正确率大于0.95则视为通关。
#encoding=utf8
from sklearn.linear_model import LogisticRegression
def softmax_reg(train_data,train_label,test_data):'''input:train_data(ndarray):训练数据train_label(ndarray):训练标签test_data(ndarray):测试数据output:predict(ndarray):预测结果'''#********* Begin *********#clf = LogisticRegression(C=0.99,solver='lbfgs',multi_class='multinomial',max_iter=200)clf.fit(train_data,train_label)predict = clf.predict(test_data)#********* End *********#return predict相关文章:
头歌-机器学习 第11次实验 softmax回归
第1关:softmax回归原理 任务描述 本关任务:使用Python实现softmax函数。 相关知识 为了完成本关任务,你需要掌握:1.softmax回归原理,2.softmax函数。 softmax回归原理 与逻辑回归一样,softmax回归同样…...
Qt for MCUs 2.7正式发布
本文翻译自:Qt for MCUs 2.7 released 原文作者:Qt Group高级产品经理Yoann Lopes 翻译:Macsen Wang Qt for MCUs的新版本已发布,为Qt Quick Ultralite引擎带来了新功能,增加了更多MCU平台的支持,并且我们…...

共享IP和独享IP如何选择,两者有何区别?
有跨境用户在选择共享IP和独享IP时会有疑问,不知道该如何进行选择,共享IP和独享IP各有其特点和应用场景,选择哪种方式主要取决于具体需求和预算。以下是对两者的详细比较: 首先两者的主要区别在于使用方式和安全性:共…...

文心一言VSchatGPT4
文心一言和GPT-4各有优势,具体表现在不同的测试场景下。 在某些测试场景中心一言的表现优于GPT-4,例如在故事的完整度和情节吸引力方面,文心一言表现得更加符合指令,情节更吸引人。这可能得益于其模型在训练时对中文语境的深入理…...
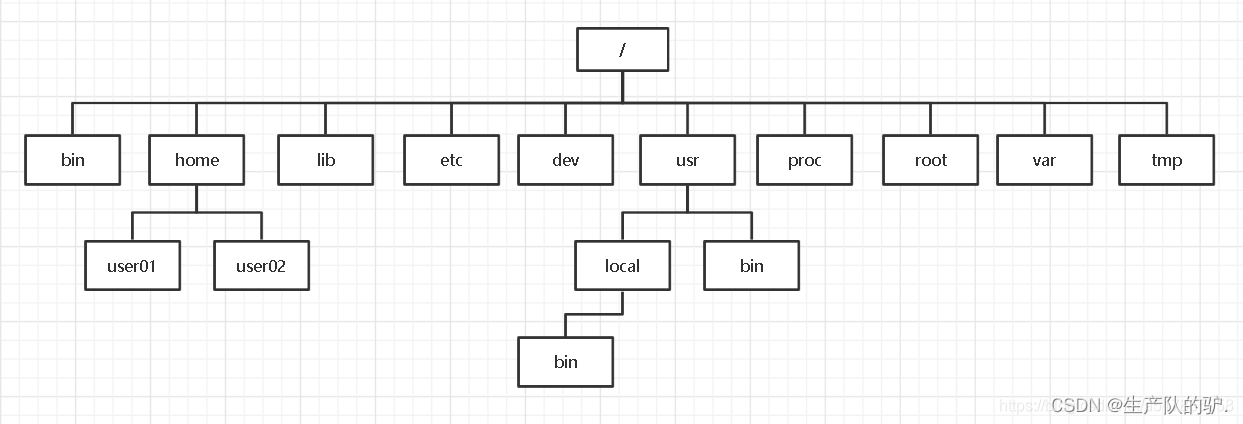
Linux 目录结构与基础查看命令
介绍 目录结构如下 /bin:存放着用户最经常使用的二进制可执行命令,如cp、ls、cat等。这些命令是系统管理员和普通用户进行日常操作所必需的。 /boot:存放启动系统使用的一些核心文件,如引导加载器(bootstrap loader…...
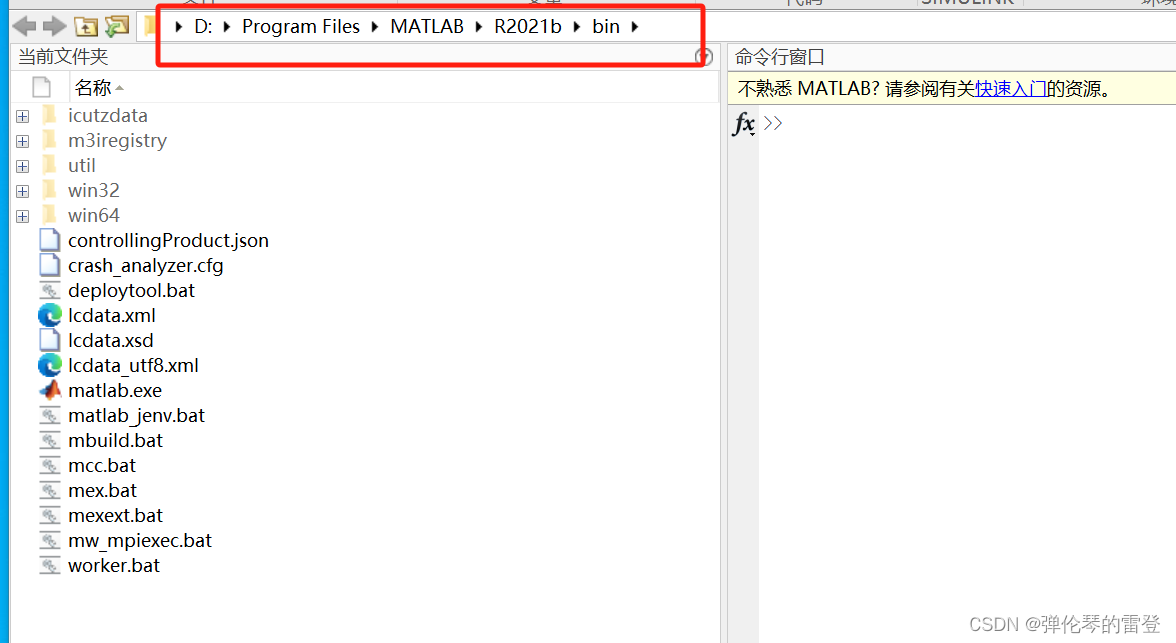
【matlab】如何解决打开缓慢问题(如何让matlab在十几秒内打开)
【matlab】如何解决打开缓慢问题(如何让matlab在十几秒内打开) 找到我们解压缩时Crack中的license_standalone.lic文件,将其拷贝 在安装matlab的路径下新建一个文件,粘贴上面的license_standalone.lic文件 在桌面鼠标移动到matl…...

【stata】求滚动波动情况
0.计算对象 计算 t t t、 t 1 t1 t1、 t 2 t2 t2 这三起滚动波动情况 V o l i , t l n ( ∑ n t n t 2 ( g n − g ˉ ) 2 3 ) Vol_{i,t} ln(\sqrt{\frac{\sum_{nt}^{nt2}(g_{n}-\bar{g})^2}{3}}) Voli,tln(3∑ntnt2(gn−gˉ)2 ) e . g e.g e.g: 假设 200…...
The C programming language (second edition,KR) exercise(CHAPTER 2)
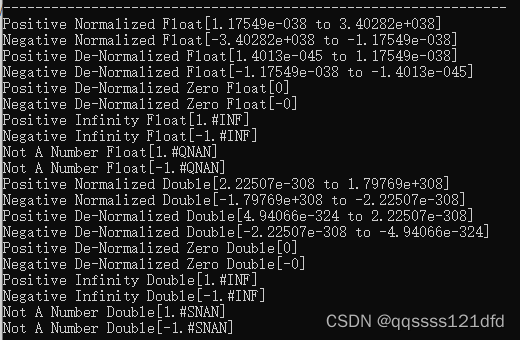
E x c e r c i s e 2 − 1 Excercise\quad 2-1 Excercise2−1:输出结果如图1和图2所示,这道练习题需要文章1和文章2的知识。 #include <stdio.h> #include <limits.h>float getFloat(char sign, unsigned char exp, unsigned mantissa); do…...

rust实现循环链表
作为一个计算机技术专家,针对你的问题,我将首先解释如何使用Rust语言实现循环链表,并提供相应的代码示例。然后,我将解释一个可能的报错问题及其解决方法。 循环链表的实现 在Rust中实现循环链表,首先需要定义链表节…...

2. Spring的创建和Bean的存取
经过前面的学习我们已经大体明白了 IOC 思想以及它的实现方式 DI ,本节要讲的是如何Spring框架实现实现DI。 本节目标: Spring(Core) 项目创建将对象存储到 Spring 中将对象(bean)从 Spring 中取出 1. 创建 Spring 项目 与开篇演示的 Spring Boot 项目不…...
策略模式【行为模式C++】
1.概述 策略模式是一种行为设计模式, 它能让你定义一系列算法, 并将每种算法分别放入独立的类中, 以使算法的对象能够相互替换。 策略模式通常应用于需要多种算法进行操作的场景,如排序、搜索、数据压缩等。在这些情况下&#x…...
)
php中session相关知识(目前了解部分)
#记录学习知识 一.ini_set() 在PHP中,ini_set() 函数用于在脚本运行时设置指定的配置选项的值。这些配置选项可以是PHP的核心设置,例如文件上传的最大大小、脚本的最大执行时间、错误报告级别等。使用 ini_set() 可以临时改变PHP.ini文件中的设置&am…...

从零实现诗词GPT大模型:GPT是怎么生成内容的?
专栏规划: https://qibin.blog.csdn.net/article/details/137728228 再开始编写GPT之前,我们得对GPT是怎么生成内容的有一个大致的了解。目前的神经网络我们大多都可以看成是一个黑盒,即我们把数据输送给网络后,网络给我我们输出,我们可以不用关心这个黑盒里到底是怎么实现…...

8路HDMI+8路AV高清视频流媒体编码器JR-3218HD
产品简介: JR-3218HD高清音视频编码产品支持8路高清HDMI音视频采集功能,8路AV视频采集功能,8路3.5MM独独立音频接口采集功能。编码输出双码流H.264格式,音频MP3/AAC格式。编码码率可调,画面质量可控制。支持HTTP/RTSP…...

LangChain入门:14.LLMChain:最简单的链的使用
摘要 本文将介绍LangChain库中LLMChain工具的使用方法。LLMChain将提示模板、语言模型(LLM)和输出解析器整合在一起,形成一个连贯的处理链,简化了与语言模型的交互过程。我们将探讨LLMChain的技术特点、应用场景以及它解决的问题…...
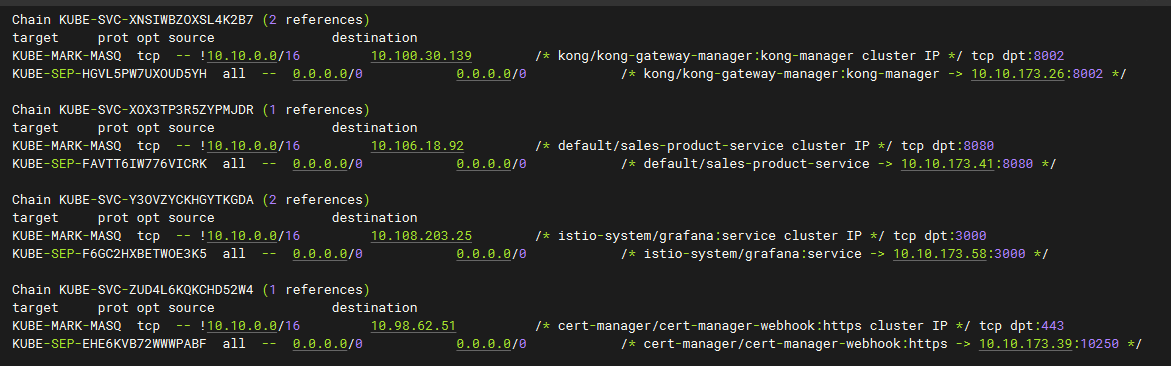
深入理解k8s kube-proxy
1、概述 我觉得只要大家知道kube-proxy是用来配置网络规则的而不是转发流量的,真正的流量由iptables/ipvs来转发就可以了。 网络是k8s的一个关键部分。理解k8s中网络组件如何工作可以帮助更好的设计和配置我们的应用。 kube-proxy就是K8s网络的核心组件。它把我们…...
Spark-机器学习(1)什么是机器学习与MLlib算法库的认识
从这一系列开始,我会带着大家一起了解我们的机器学习,了解我们spark机器学习中的MLIib算法库,知道它大概的模型,熟悉并认识它。同时,本篇文章为个人spark免费专栏的系列文章,有兴趣的可以收藏关注一下&…...

java的正则表达式校验,包含了中国几乎所有运营商手机号码的校验格式
时间2024年4月14日22:25:00 代码 String PHONE_REGEX "^1([38][0-9]|4[579]|5[0-3,5-9]|6[6]|7[0135678]|9[89])\\d{8}$";解释 这个Java代码段定义了一个常量 PHONE_REGEX,它包含了一个正则表达式,用于匹配中国大陆的手机号码。下面是对这…...
C#简单工厂模式的实现
using System.Diagnostics.Metrics; using System.Runtime.InteropServices; using static 手写工厂模式.Program;namespace 手写工厂模式 {internal class Program{public interface eats {void eat();}//定义了一个接口public class rice : eats{public void eat() {Console.…...
)
.NET 设计模式—观察者模式(Observer Pattern)
简介 在.NET中,观察者模式是一种设计模式,它允许对象之间进行一对多的依赖关系。当一个对象的状态发生变化时,所有依赖于它的对象都会收到通知并自动更新。这种模式在事件驱动的设计中非常常见。 在.NET中实现观察者模式,通常涉…...

告别格式烦恼:北航毕业论文LaTeX模板的5步终极指南
告别格式烦恼:北航毕业论文LaTeX模板的5步终极指南 【免费下载链接】BUAAthesis 北航毕设论文LaTeX模板 项目地址: https://gitcode.com/gh_mirrors/bu/BUAAthesis 还在为毕业论文格式调整而烦恼吗?想象一下,你已经花费数月时间完成了…...

如何在浏览器中重新解锁微信网页版?一款开源插件为你提供完美解决方案
如何在浏览器中重新解锁微信网页版?一款开源插件为你提供完美解决方案 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版无…...

构建企业级日志监控系统:Visual Syslog Server技术架构深度解析
构建企业级日志监控系统:Visual Syslog Server技术架构深度解析 【免费下载链接】visualsyslog Syslog Server for Windows with a graphical user interface 项目地址: https://gitcode.com/gh_mirrors/vi/visualsyslog 在当今复杂的IT基础设施环境中&#…...

实战部署Funannotate基因组注释工具:3种高效配置方案指南
实战部署Funannotate基因组注释工具:3种高效配置方案指南 【免费下载链接】funannotate Eukaryotic Genome Annotation Pipeline 项目地址: https://gitcode.com/gh_mirrors/fu/funannotate Funannotate是一款专业的真核生物基因组注释工具,特别针…...

终极指南:如何设计完美的HTTP API - 10个实用技巧让你的API更专业
终极指南:如何设计完美的HTTP API - 10个实用技巧让你的API更专业 【免费下载链接】http-api-design HTTP API design guide extracted from work on the Heroku Platform API 项目地址: https://gitcode.com/gh_mirrors/ht/http-api-design HTTP API设计是构…...

跨境社媒账号做不稳 很多时候不是内容不够好而是气质不够稳定
很多团队做跨境社媒时,最容易把注意力集中在“内容创意”上。 选题够不够新,切口够不够巧,视频开头能不能抓住人,标题会不会让人点开,这些当然都重要。但真正做久了之后会发现,一个账号能不能长期跑起来&am…...

2026发文避坑指南:告别大众型AI,用对垂直编辑器让过审更轻松
在2026年的学术大环境下,核心期刊的收录门槛持续走高,许多科研工作者正面临着一种隐性焦虑:明明实验数据扎实、研究背景深厚,投递出去的稿件却屡屡被退。其实,很多时候被拒的根本原因并非学术价值不足,而是…...

德尔·考德威尔:从微波校准到计量标准,塑造现代精密测量的隐形基石
1. 一位计量学巨匠的遗产:从德尔考德威尔看精密测量的基石在电子工程与测试测量这个庞大而精密的领域里,我们常常关注的是最新的示波器带宽、最前沿的矢量网络分析技术,或是某个芯片的测试方案。然而,支撑起整个现代工业测量体系可…...
)
别再死记公式了!用Python+NumPy手撸一个卡尔曼滤波器(附代码详解)
用PythonNumPy从零实现卡尔曼滤波器:原理剖析与调参实战 卡尔曼滤波器这个听起来高大上的算法,其实离我们并不遥远。想象一下你在玩一个无人机航拍游戏,屏幕上的无人机位置总是飘忽不定——GPS信号有延迟,惯性传感器有漂移&#…...

不只是抓包:巧用Drony为Android APP设置“专属网络通道”,测试本地Mock服务
巧用Drony构建Android应用专属调试通道:从Mock服务到精准流量控制 在移动应用开发与测试过程中,前后端分离架构已成为主流范式。然而,当Android应用硬编码了生产环境API地址或缺乏灵活的配置机制时,如何在不修改代码的情况下将特定…...