Hudi-ubuntu环境搭建
hudi-ubuntu环境搭建
运行
1.编译Hudi
#1.把maven安装包上传到服务器 # 官网下载安装包 https://archive.apache.org/dist/maven/maven-3/
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\apache-maven-3.6.3-bin.tar.gz zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage
#2.解压并配置maven环境变量
tar -zxvf apache-maven-3.6.3-bin.tar.gz -C
vim /etc/profile # 编辑系统配置文件
export MAVEN_HOME=/home/zhangheng/hudi/software/apache-maven-3.6.3 # maven路径
export PATH=$MAVEN_HOME/bin:$PATH
source /etc/profile # 重新加载系统配置文件
#3.新建maven仓库并设置本地仓库路径
cd /home/zhangheng/hudi
mkdir maven-repository
vim $MAVEN_HOME/conf/settings.xml
<localRepository>/home/zhangheng/hudi/maven-repository</localRepository>
#4.添加Maven镜像仓库路径
vim $MAVEN_HOME/conf/settings.xml # 编辑内容见【1.maven配置】,注意<mirror>标签放在<mirrors>里
#5.到Apache 软件归档目录下载Hudi 0.9源码包
cd /home/zhangheng/hudi/maven-repository
wget https://archive.apache.org/dist/hudi/0.9.0/hudi-0.9.0.src.tgz
#6.解压Hudi 0.9源码包
cd /home/zhangheng/hudi/maven-repository
tar -zxvf hudi-0.9.0.src.tgz -C /home/zhangheng/hudi/server/
#7.编译Hudi
cd /home/zhangheng/hudi/server/hudi-0.9.0
mvn clean install -DskipTests -DskipITs -Dscala-2.12 -Dspark3 # 执行编译的时候报错,见【1.编译报错】
mvn clean install -DskipTests -Drat.skip=true -Dscala-2.12 -Dspark3 -Pflink-bundle-shade-hive2
#8.运行Hudi
cd /home/zhangheng/hudi/server/hudi-0.9.0/hudi-cli
./hudi-cli.sh
2.安装HDFS
#1.把HDFS安装包上传到服务器
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\hadoop-2.7.3.tar.gz zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage
#2.解压安装包
tar -zxvf hadoop-2.7.3.tar.gz -C /home/zhangheng/hudi/server/
#3.创建hadoop软连接,方便后续软件版本升级和管理
cd /home/zhangheng/hudi/server/
ln -s hadoop-2.7.3 hadoop
#4.配置环境变量
vim /etc/profile # 编辑内容见【2.HDFS配置-/etc/profile】
source /etc/profile # 重新加载系统配置文件
#4.在Hadoop环境变量脚本配置JDK和HADOOP安装目录
vim /home/zhangheng/hudi/server/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_101
export HADOOP_HOME=/home/zhangheng/hudi/server/hadoop
#5.配置Hadoop Common模块公共属性
vim /home/zhangheng/hudi/server/hadoop/etc/hadoop/core-site.xml # 编辑内容见【2.HDFS配置-core-site.xml】,注意<property>标签放在<configuration>里
#6.配置HDFS分布式文件系统相关属性
vim /home/zhangheng/hudi/server/hadoop/etc/hadoop/hdfs-site.xml # 编辑内容见【2.HDFS配置-hdfs-site.xml】,注意<property>标签放在<configuration>里
#7.配置HDFS集群中从节点DataNode所运行机器
vim /home/zhangheng/hudi/server/hadoop/etc/hadoop/slaves
node1.itcast.cn # 增加配置内容
#8.创建临时数据目录
mkdir -p /home/zhangheng/hudi/server/hadoop/datas/tmp
mkdir -p /home/zhangheng/hudi/server/hadoop/datas/dfs/nn
mkdir -p /home/zhangheng/hudi/server/hadoop/datas/dfs/dn
#9.第一次启动HDFS文件之前,先格式HDFS文件系统(出现提示输入Y/N时要输入大写Y)
hdfs namenode -format # (这个命令只在第一次启动前运行一次,如果要再次运行,需要删除上面的三个目录重新创建)
#10.启动HDFS集群
hadoop-daemon.sh start namenode # 无法启动,需要配置虚拟机端口映射vim /etc/hosts 追加一行 10.8.4.212 node1.itcast.cn
hadoop-daemon.sh start datanode # 无法启动,查看日志文件,见【2.启动dataNode失败】
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
#11.访问HDFS WEB UI
http://node1.itcast.cn:50070/ # 无法访问,见【3.访问失败,网页打不开】
## 上传HDFS文件
hdfs dfs -mkdir -p /datas/
hdfs dfs -put /home/zhangheng/hudi/server/spark/README.md /datas
## 查看HDFS文件系统目录
hdfs dfs -ls /datas/hudi-warehouse/hudi_trips_cow
## 删除文件夹或文件
hdfs dfs -rm -r /folder_name # 放入回收站
hdfs dfs -rm -r -skipTrash /folder_name # 跳过回收站,直接进行删除
## 清空hdfs的回收站
hdfs dfs -expunge
3.安装Spark 3.x
#1.把Spark安装包、Scala安装包上传到服务器
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\spark-3.0.0-bin-hadoop2.7.tgz zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\scala-2.12.10.tgz zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage
#2.解压安装包
tar -zxvf spark-3.0.0-bin-hadoop2.7.tgz -C /home/zhangheng/hudi/server/
tar -zxvf scala-2.12.10.tgz -C /home/zhangheng/hudi/server/
#3.创建软连接,方便后期升级
ln -s /home/zhangheng/hudi/server/spark-3.0.0-bin-hadoop2.7 /home/zhangheng/hudi/server/spark
ln -s /home/zhangheng/hudi/server/scala-2.12.10 /home/zhangheng/hudi/server/scala
#4.设置环境变量
sudo su
vim /etc/profile
# SPARK_HOME
export SPARK_HOME=/home/zhangheng/hudi/server/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
# SCALA_HOME
export SCALA_HOME=/home/zhangheng/hudi/server/scala
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
#5.修改配置名称
cd /home/zhangheng/hudi/server/spark/conf
mv spark-env.sh.template spark-env.sh
#6.修改配置文件
vim $SPARK_HOME/conf/spark-env.sh
## 设置JAVA和SCALA安装目录
JAVA_HOME=/usr/local/src/jdk1.8.0_101
SCALA_HOME=/home/zhangheng/hudi/server/scala
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/home/zhangheng/hudi/server/hadoop/etc/hadoop
#7.本地模式启动spark-shell
cd /home/zhangheng/hudi/server/spark ## 进入Spark安装目录
bin/spark-shell --master local[2] ## 启动spark-shell
#7.将$【SPARK_HOME/README.md】文件上传到HDFS目录【/datas】,使用SparkContext读取文件
## 上传HDFS文件
hdfs dfs -mkdir -p /datas/
hdfs dfs -put /home/zhangheng/hudi/server/spark/README.md /datas
## 读取文件
scala> val datasRDD = sc.textFile("/datas/README.md")
## 条目数
scala> datasRDD.count
## 获取第一条数据
scala> datasRDD.first
## 使用SparkSession对象spark,加载读取文本数据,封装至DataFrame中
scala> val dataframe = spark.read.textFile("/datas/README.md")
scala> dataframe.show(10,truncate=false)4.spark-shell 使用
使用spark-shell命令行,模拟产生Trip乘车交易数据,将其保存至Hudi表,并且从Hudi表加载数据查询分析
#1.使用spark-shell命令行,以本地模式(LocalMode:--master local[2])方式运行
spark-shell \
--master local[2] \
--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1,org.apache.spark:spark_unused:1.0.0.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
#2.模拟产生Trip乘车交易数据
## 首先导入Spark及Hudi相关包和定义变量(表的名称和数据存储路径)
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._val tableName = "hudi_trips_cow"
val basePath = "hdfs://node1.itcast.cn:8020/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator
## 其中构建DataGenerator对象,用于模拟生成Trip乘车数据
val inserts = convertToStringList(dataGen.generateInserts(10))
## 接下来,将模拟数据List转换为DataFrame数据集
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
## 查看转换后DataFrame数据集的Schema信息
df.printSchema()
## 选择相关字段,查看模拟样本数据
df.select("rider", "begin_lat", "begin_lon", "driver", "fare", "uuid", "ts").show(10, truncate=false)
#3.将上述模拟产生Trip数据,保存到Hudi表中,由于Hudi诞生时基于Spark框架,所以SparkSQL支持Hudi数据源,直接通过format指定数据源Source,设置相关属性保存数据即可
## 采用Scala交互式命令行中paste模式粘贴代码
:paste
df.write.mode(Overwrite).format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).save(basePath)
# 按ctrl+D结束
## 其中的参数说明:
参数:getQuickstartWriteConfigs,设置写入/更新数据至Hudi时,Shuffle时分区数目
参数:PRECOMBINE_FIELD_OPT_KEY,数据合并时,依据主键字段
参数:RECORDKEY_FIELD_OPT_KEY,每条记录的唯一id,支持多个字段
参数:PARTITIONPATH_FIELD_OPT_KEY,用于存放数据的分区字段
## 数据保存成功以后,查看HDFS文件系统目录:
hdfs dfs -ls /datas/hudi-warehouse/hudi_trips_cow
#4.从Hudi表中读取数据,同样采用SparkSQL外部数据源加载数据方式,指定format数据源和相关参数options
val basePath = "hdfs://node1.itcast.cn:8020/datas/hudi-warehouse/hudi_trips_cow"
## 其中指定Hudi表数据存储路径即可,采用正则Regex匹配方式,由于保存Hudi表属于分区表,并且为三级分区(相当于Hive中表指定三个分区字段),使用表达式:/*/*/*/* 加载所有数据。
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
## 打印获取Hudi表数据的Schema信息
## 比原先保存到Hudi表中数据多5个字段,这些字段属于Hudi管理数据时使用的相关字段
tripsSnapshotDF.printSchema()
## 将获取Hudi表数据DataFrame注册为临时视图,采用SQL方式依据业务查询分析数据
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
### 查询业务一:乘车费用 大于 20 信息数据
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
### 查询业务二:选取字段查询数据
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()# 上传这三个jar包,后面集成的时候用
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\hudi-spark3-bundle_2.12-0.9.0.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackagescp -r D:\Users\zh\Desktop\Hudi\compressedPackage\spark-avro_2.12-3.0.1.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackagescp -r D:\Users\zh\Desktop\Hudi\compressedPackage\unused-1.0.0.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage# 启动spark-shell
spark-shell \
--master local[2] \
--jars /home/zhangheng/hudi/compressedPackage/hudi-spark3-bundle_2.12-0.9.0.jar,\
/home/zhangheng/hudi/compressedPackage/spark-avro_2.12-3.0.1.jar,/home/zhangheng/hudi/compressedPackage/unused-1.0.0.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" spark-sql \
--master local[2] \
--jars /home/zhangheng/hudi/compressedPackage/hudi-spark3-bundle_2.12-0.9.0.jar,\
/home/zhangheng/hudi/compressedPackage/spark-avro_2.12-3.0.1.jar,/home/zhangheng/hudi/compressedPackage/unused-1.0.0.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
# 刷新缓存
refresh table tablename
5.安装mysql
# 从官网安装下载mysql
cd /home/zhangheng/hudi/compressedPackage
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
# 解压
tar -zxvf mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz -C /home/zhangheng/hudi/server/
# 重命名
cd /home/zhangheng/hudi/server/
mv mysql-5.7.31-linux-glibc2.12-x86_64 mysql
# 编译安装并初始化mysql,记住管理员初始密码 zGnlw8h4or=k
cd mysql/bin/
./mysqld --initialize --user=mysql --datadir=/home/zhangheng/hudi/server/mysql/data --basedir=/home/zhangheng/hudi/server/mysql
# 编写配置文件 my.cnf ,并添加配置
vi /etc/my.cnf
[mysqld]
datadir=/home/zhangheng/hudi/server/mysql/data
port = 3306
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
symbolic-links=0
max_connections=400
innodb_file_per_table=1
lower_case_table_names=1
# 启动mysql 服务器
/home/zhangheng/hudi/server/mysql/support-files/mysql.server start # 启动报错,见【5.MySQL启动报错】
# 添加软连接,并重启mysql 服务
ln -s /home/zhangheng/hudi/server/mysql/support-files/mysql.server /etc/init.d/mysql
# ln -s /home/zhangheng/hudi/server/mysql/bin/mysql /usr/bin/mysql
service mysql restart
# 登录mysql ,密码就是初始化时生成的临时密码
mysql -u root -p
# 修改密码,因为生成的初始化密码难记
set password for root@localhost = password('123456');
# 开放远程连接
use mysql;
update user set user.Host='%' where user.User='root';
flush privileges;
# 设置开机自启
cp /home/zhangheng/hudi/server/mysql/support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig --list
6.安装Hive 2.1
#1.把Hive安装包上传到服务器
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\apache-hive-2.1.0-bin.tar.gz zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage#2.解压
cd /home/zhangheng/hudi/compressedPackage
chmod u+x apache-hive-2.1.0-bin.tar.gz
tar -zxf apache-hive-2.1.0-bin.tar.gz -C /home/zhangheng/hudi/server/
cd /home/zhangheng/hudi/server
mv apache-hive-2.1.0-bin hive-2.1.0-bin
ln -s hive-2.1.0-bin hive
# 集成Hive表,为了 Hive 能够正常读到 Hudi 的数据
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\hudi-hadoop-mr-bundle-0.9.0.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/server/hive/lib
#3.配置环境变量
cd /home/zhangheng/hudi/server/hive/conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.shHADOOP_HOME=/home/zhangheng/hudi/server/hadoopexport HIVE_CONF_DIR=/home/zhangheng/hudi/server/hive/confexport HIVE_AUX_JARS_PATH=/home/zhangheng/hudi/server/hive/lib
#4.创建HDFS目录
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanodehdfs dfs -mkdir -p /tmp
hdfs dfs -mkdir -p /usr/hive/warehouse
hdfs dfs -chmod g+w /tmp
hdfs dfs -chmod g+w /usr/hive/warehouse
#5.配置文件hive-site.xml
cd /home/zhangheng/hudi/server/hive/conf
vim hive-site.xml # 见【3.Hive配置】
#6.添加用户权限配置
cd /home/zhangheng/hudi/server/hadoop/etc/hadoop
vim core-site.xml<property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
#7.初始化数据库
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\mysql-connector-java-5.1.48.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/server/hive/lib
cd /home/zhangheng/hudi/server/hive/bin
./schematool -dbType mysql -initSchema
#8.启动HiveMetaStore服务
cd /home/zhangheng/hudi/server/hive
nohup bin/hive --service metastore >/dev/null &
#9.启动HiveServer2服务
cd /home/zhangheng/hudi/server/hive
bin/hive --service hiveserver2 >/dev/null &
#10.启动beeline命令行
cd /home/zhangheng/hudi/server/hive
bin/beeline -u jdbc:hive2://node1.itcast.cn:10000 -n root -p 123456
# 把写好的启动脚本放到hive的bin目录下
mkdir -p ${HIVE_HOME}/logsscp -r D:\Users\zh\Desktop\Hudi\compressedPackage\start-hiveserver2.sh zhangheng@10.8.4.212:/home/zhangheng/hudi/server/hive/binscp -r D:\Users\zh\Desktop\Hudi\compressedPackage\start-metastore.sh zhangheng@10.8.4.212:/home/zhangheng/hudi/server/hive/bin
# 赋予启动脚本可执行权限
chmod u+x start-*
# 用启动脚本启动
start-metastore.sh
start-hiveserver2.sh
start-beeline.sh
# 查看进程是否在运行
ps -ef|grep RunJar
kill -9 pid
7.安装Zookeeper 3.4.6
#1.把Zookeeper安装包上传到服务器
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\zookeeper-3.4.6.tar.gz zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage#2.解压
cd /home/zhangheng/hudi/compressedPackage
chmod u+x zookeeper-3.4.6.tar.gz
tar -zxf zookeeper-3.4.6.tar.gz -C /home/zhangheng/hudi/server/
cd /home/zhangheng/hudi/server
ln -s zookeeper-3.4.6 zookeeper
#3.配置环境变量
cd /home/zhangheng/hudi/server/zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
dataDir=/home/zhangheng/hudi/server/zookeeper/datas
sudo su
vim /etc/profileexport ZOOKEEPER_HOME=/export/server/zookeeperexport PATH=$PATH:$ZOOKEEPER_HOME/bin
exit
source /etc/profile
#4.启动服务
cd /home/zhangheng/hudi/server/zookeeper/
bin/zkServer.sh start
bin/zkServer.sh status
如果启动失败,报错说端口号被占用,就修改vim /home/zhangheng/hudi/server/zookeeper/conf/zoo.cfg文件端口号,这里改成了2190
8.安装Kafka 2.4.1
#1.把Kafka安装包上传到服务器
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\kafka_2.12-2.4.1.tgz zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage#2.解压
cd /home/zhangheng/hudi/compressedPackage
chmod u+x kafka_2.12-2.4.1.tgz
tar -zxf kafka_2.12-2.4.1.tgz -C /home/zhangheng/hudi/server/
cd /home/zhangheng/hudi/server
ln -s kafka_2.12-2.4.1 kafka
#3.配置环境变量
vim /home/zhangheng/hudi/server/kafka/config/server.propertieslisteners=PLAINTEXT://node1.itcast.cn:9099 log.dirs=/home/zhangheng/hudi/server/kafka/kafka-logszookeeper.connect=node1.itcast.cn:2190/kafkasudo su
vim /etc/profileexport KAFKA_HOME=/home/zhangheng/hudi/server/kafkaexport PATH=$PATH:$KAFKA_HOME/bin
exit
source /etc/profile
#4.创建存储目录
mkdir -p /home/zhangheng/hudi/server/kafka/kafka-logs
#5.启动服务
cd /home/zhangheng/hudi/server/kafka
bin/kafka-server-start.sh -daemon config/server.properties
jps
9.安装Flink
#1.把Zookeeper安装包上传到服务器
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\flink-1.12.2-bin-scala_2.12.tgz zhangheng@10.8.4.212:/home/zhangheng/hudi/compressedPackage#2.解压
cd /home/zhangheng/hudi/compressedPackage
chmod u+x flink-1.12.2-bin-scala_2.12.tgz
tar -zxvf flink-1.12.2-bin-scala_2.12.tgz -C /home/zhangheng/hudi/server/
cd /home/zhangheng/hudi/server
ln -s flink-1.12.2 flink
#3.添加hadoop依赖jar包,
scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\flink-shaded-hadoop-2-uber-2.7.5-10.0.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/server/flink/libscp -r D:\Users\zh\Desktop\Hudi\compressedPackage\hudi-flink-bundle_2.12-0.9.0.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/server/flink/libscp -r D:\Users\zh\Desktop\Hudi\compressedPackage\flink-sql-connector-kafka_2.12-1.12.2.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/server/flink/libscp -r D:\Users\zh\Desktop\Hudi\compressedPackage\flink-sql-connector-mysql-cdc-1.3.0.jar zhangheng@10.8.4.212:/home/zhangheng/hudi/server/flink/lib#4.修改配置
vim $FLINK_HOME/conf/flink-conf.yaml # 详见【4.Flink配置】
#5.启动HDFS集群
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
#6.启动Flink本地集群
cd /home/zhangheng/hudi/server/flink/bin/
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
start-cluster.sh
# 使用jps可看到以下两个进程
TaskManagerRunner
StandaloneSessionClusterEntrypoint
# 停止Flink
cd /home/zhangheng/hudi/server/flink/bin/
stop-cluster.sh
#7.访问Flink的Web UI
http://node1.itcast.cn:8081/#/overview
#8.启动Flink SQL Cli命令行
cd /home/zhangheng/hudi/server/flink/bin/
sql-client.sh embedded -j /home/zhangheng/hudi/server/flink/lib/hudi-flink-bundle_2.12-0.9.0.jar shell
#9.在SQL Cli设置分析结果展示模式
Flink SQL>set execution.result-mode=tableau;
Flink SQL>set execution.checkpointing.interval=3sec;
10.Flink CDC Hudi
CDC的全称是Change data Capture,即变更数据捕获,主要面向数据库的变更,是是数据库领域非常常见的技术,主要用于捕获数据库的一些变更,然后可以把变更数据发送到下游。
对于CDC,业界主要有两种类型:
-
一是基于查询的,客户端会通过SQL方式查询源库表变更数据,然后对外发送。这种 CDC 技术是入侵式的,需要在数据源执行 SQL 语句。使用这种技术实现CDC 会影响数据源的性能。通常需要扫描包含大量记录的整个表。
-
二是基于日志,这也是业界广泛使用的一种方式,一般是通过binlog方式,变更的记录会写入binlog,解析binlog后会写入消息系统,或直接基于Flink CDC进行处理。这种 CDC 技术是非侵入性的,不需要在数据源执行 SQL 语句。通过读取源数据库的日志文件以识别对源库表的创建、修改或删除数据。

#1.配置
vim /home/zhangheng/server/hudi-0.9.0/packaging/hudi-flink-bundle/pom.xml
<profile><id>flink-bundle-shade-hive2</id><properties><hive.version>2.1.0</hive.version></properties>
</profile>
#2.重新编译
cd /home/zhangheng/server/hudi-0.9.0
mvn clean install -DskipTests -Drat.skip=true -Dscala-2.12 -Dspark3 -Pflink-bundle-shade-hive2
#3.jar包准备
cd $FLINK_HOME/lib
hudi-flink-bundle_2.12-0.9.0.jar # 来自于/home/zhangheng/server/hudi-0.9.0/packaging/hudi-flink-bundle/target
flink-sql-connector-mysql-cdc-1.3.0.jar
cd $HIVE_HOME/lib
hudi-hadoop-mr-bundle-0.9.0.jar # 来自于/home/zhangheng/server/hudi-0.9.0/packaging/hudi-hadoop-mr-bundle/target
#4.开启MySQL binlog日志
vim /etc/my.cnf # 在[mysqld]下面添加内容:
server-id=2
log-bin=mysql-bin
binlog_format=row
expire_logs_days=15
binlog_row_image=full
#5.重启MySQL Server
service mysqld restart # 如果不行就cd mysql/support-files,mysql.server stop,mysql.server start
mysql -uroot -p
show master logs; # 查看是否生效
#6.在MySQL数据库,创建表,插入数据
create database test ;
create table test.tbl_users(id bigint auto_increment primary key,name varchar(20) null,birthday timestamp default CURRENT_TIMESTAMP not null,ts timestamp default CURRENT_TIMESTAMP not null
);
insert into test.tbl_users (name) values ('zhangsan');
insert into test.tbl_users (name) values ('lisi');
insert into test.tbl_users (name) values ('wangwu');
insert into test.tbl_users (name) values ('laoda');
insert into test.tbl_users (name) values ('laoer');
#7.创建 CDC 表(前提:HDFS服务、Hive服务、Flink Standalone集群均已启动)
# 启动Flink SQL Client客户端
cd /home/zhangheng/hudi/server/flink/bin/
sql-client.sh embedded -j /home/zhangheng/hudi/server/flink/lib/hudi-flink-bundle_2.12-0.9.0.jar shell
# 设置属性
set execution.result-mode=tableau;
set execution.checkpointing.interval=3sec;
# 创建输入表,关联MySQL表,采用MySQL CDC 关联
CREATE TABLE users_source_mysql (id BIGINT PRIMARY KEY NOT ENFORCED,name STRING,birthday TIMESTAMP(3),ts TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'node1.itcast.cn',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'server-time-zone' = 'Asia/Shanghai',
'debezium.snapshot.mode' = 'initial',
'database-name' = 'test',
'table-name' = 'tbl_users'
);
# 查询数据
select * from users_source_mysql;
# 创建一个临时视图,增加分区列part,方便后续同步hive分区表
create view view_users_cdc
AS
SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') as part FROM users_source_mysql;
select * from view_users_cdc;
# 8.创建 CDC Hudi Sink 表
CREATE TABLE users_sink_hudi_hive(
id bigint ,
name string,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
part VARCHAR(20),
primary key(id) not enforced
)
PARTITIONED BY (part)
with(
'connector'='hudi',
'path'= 'hdfs://node1.itcast.cn:8020/users_sink_hudi_hive',
'table.type'= 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field'= 'id',
'write.precombine.field'= 'ts',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true', --必须。启用Hive sync
'hive_sync.mode'= 'hms', --必须。设置模式未hms,默认为jdbc
'hive_sync.metastore.uris'= 'thrift://node1.itcast.cn:9083',-- 必须。端口需要在 hive-site.xml上配置
'hive_sync.jdbc_url'= 'jdbc:hive2://node1.itcast.cn:10000',-- 必须。hiveServer端口
'hive_sync.table'= 'users_sink_hudi_hive',-- 必须。同步过去的hive表名
'hive_sync.db'= 'default',-- 必须。同步过去的hive表所在数据库名
'hive_sync.username'= 'root',
'hive_sync.password'= '123456',
'hive_sync.support_timestamp'= 'true'
);
# 9.从视图中查询数据,再写入Hudi表
insert into users_sink_hudi_hive select id, name, birthday, ts, part from view_users_cdc;
select * from users_sink_hudi_hive;
# 10.Hive 表查询
cd /home/zhangheng/hudi/server/hive
bin/beeline -u jdbc:hive2://node1.itcast.cn:10000 -n root -p 123456
show tables in default; # 查看发现已自动生产hudi MOR模式的2张表
show partitions users_sink_hudi_hive_ro ; # 查看自动生成表的分区信息(ro表只能查parquet文件数据)
show partitions users_sink_hudi_hive_rt ; # 查看自动生成表的分区信息(rt表 parquet文件数据和log文件数据都可查)
set hive.exec.mode.local.auto=true;
set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
set hive.mapred.mode=nonstrict ;select id, name, birthday, ts, `part` from users_sink_hudi_hive_ro; # 查询Hive分区表数据
# 11.Hudi Client操作Hudi表
cd hudi/server/
hudi-0.9.0/hudi-cli/hudi-cli.sh
connect --path hdfs://node1.itcast.cn:8020/users_sink_hudi_hive # 连接Hudi表,查看表信息
commits show --sortBy "CommitTime" # 查看Hudi commit信息
compactions show all # 查看Hudi compactions 计划
附:用到的配置
1.maven配置
$MAVEN_HOME/conf/settings.xml
<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云spring插件仓库</name><url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror><id>repo2</id><name>Mirror from Maven Repo2</name><url>https://repo.spring.io/plugins-release/</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>UK</id><name>UK Central</name><url>http://uk.maven.org/maven2</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>jboss-public-repository-group</id><name>JBoss Public Repository Group</name><url>http://repository.jboss.org/nexus/content/groups/public</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>CN</id><name>OSChina Central</name><url>http://maven.oschina.net/content/groups/public/</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>google-maven-central</id><name>GCS Maven Central mirror Asia Pacific</name><url>https://maven-central-asia.storage-download.googleapis.com/maven2/</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>confluent</id><name>confluent maven</name><url>http://packages.confluent.io/maven/</url><mirrorOf>confluent</mirrorOf>
</mirror>
2.HDFS配置
/etc/profile
export HADOOP_HOME=/home/zhangheng/hudi/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
core-site.xml
/home/zhangheng/hudi/server/hadoop/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1.itcast.cn:8020</value></property><property><name>hadoop.tmp.dir</name><value>/home/zhangheng/hudi/server/hadoop/datas/tmp</value></property> <property><name>hadoop.http.staticuser.user</name><value>root</value></property><property><name>hadoop.proxyuser.zhangheng.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.zhangheng.groups</name><value>*</value></property>
</configuration>
hdfs-site.xml
/home/zhangheng/hudi/server/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.namenode.name.dir</name><value>/home/zhangheng/hudi/server/hadoop/datas/dfs/nn</value></property><property><name>dfs.datanode.data.dir</name><value>/home/zhangheng/hudi/server/hadoop/datas/dfs/dn</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>dfs.datanode.data.dir.perm</name><value>750</value></property>
</configuration>
/etc/hosts
/etc/hosts
10.8.4.212 node1.itcast.cn # 在后面追加这一行,表示本虚拟机IP和这个域名的映射关系
3.Hive配置
/home/zhangheng/hudi/server/hive/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://node1.itcast.cn:3306/hive_metastore?createDatabaseIfNotExist=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><property><name>hive.metastore.warehouse.dir</name><value>/usr/hive/warehouse</value> </property><property><name>hive.metastore.uris</name><value>thrift://node1.itcast.cn:9083</value></property><property><name>hive.mapred.mode</name><value>strict</value></property><property><name>hive.exec.mode.local.auto</name><value>true</value></property><property><name>hive.fetch.task.conversion</name><value>more</value></property><property><name>hive.server2.thrift.client.user</name><value>root</value></property><property><name>hive.server2.thrift.client.password</name><value>123456</value></property>
</configuration>
4.Flink配置
$FLINK_HOME/conf/flink-conf.yaml
jobmanager.rpc.address: node1.itcast.cn
jobmanager.memory.process.size: 1024m
taskmanager.memory.process.size: 2048m
taskmanager.numberOfTaskSlots: 4classloader.check-leaked-classloader: false
classloader.resolve-order: parent-firstexecution.checkpointing.interval: 3000
state.backend: rocksdb
state.checkpoints.dir: hdfs://node1.itcast.cn:8020/flink/flink-checkpoints
state.savepoints.dir: hdfs://node1.itcast.cn:8020/flink/flink-savepoints
state.backend.incremental: true
附:报错解决
1.编译报错
【命令】
mvn clean install -DskipTests -DskipITs -Dscala-2.12 -Dspark3
【报错代码】
Non-resolvable parent POMDownloading from alimaven: http://maven.aliyun.com/nexus/content/groups/public/org/apache/apache/21/apache-21.pom
[ERROR] [ERROR] Some problems were encountered while processing the POMs:
[FATAL] Non-resolvable parent POM for org.apache.hudi:hudi:0.9.0: Could not transfer artifact org. apache:apache:pom:21 from/to aliyunmaven (https://maven.aliyun.com/repository/spring-plugin): maven.aliyun.com: unknown error and 'parent. relativePath' points at wrong local POM @ line 23, column 11
【解决】
maven原版本太老(3.5.4)换成3.6.3就好了。
2.启动dataNode失败
【命令】
hadoop-daemon.sh start datanode
【错误】
2023-02-15 10:50:04,649 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.net.BindException: Problem binding to [0.0.0.0:50010] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindExceptionat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:721)at org.apache.hadoop.ipc.Server.bind(Server.java:425)at org.apache.hadoop.ipc.Server.bind(Server.java:397)at org.apache.hadoop.hdfs.net.TcpPeerServer.<init>(TcpPeerServer.java:113)at org.apache.hadoop.hdfs.server.datanode.DataNode.initDataXceiver(DataNode.java:897)at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:1111)at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:429)at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:2374)at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:2261)at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:2308)at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:2485)at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:2509)
Caused by: java.net.BindException: Address already in useat sun.nio.ch.Net.bind0(Native Method)at sun.nio.ch.Net.bind(Net.java:433)at sun.nio.ch.Net.bind(Net.java:425)at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)at org.apache.hadoop.ipc.Server.bind(Server.java:408)... 10 more
2023-02-15 10:50:04,650 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1
2023-02-15 10:50:04,651 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
【解决】
netstat -anp | grep 50010 # 查看被占用的端口号
sudo su # 切换到root用户
netstat -anp | grep 50010 # 查看被占用的端口号
sudo lsof -i:50010 # 查看被占用的端口号对应的PID
sudo kill -9 17231 # 杀掉PID对应的进程
# 再启动
3.访问失败,网页打不开
http://node1.itcast.cn:50070/
【错误和解决】
原因1:nameNode、dataNode未启动
输入jps,查看是否出现nameNode、dataNode,如果没出现,说明它们没启动,检查它们的启动日志看问题在哪里原因2:开了VPN
需要关掉VPN原因3:本机需要配置端口映射
C:\Windows\System32\drivers\etc -> hosts 文件
追加一行
10.8.4.212 node1.itcast.cn # 表示虚拟机IP和域名的映射关系,和虚拟机中/etc/hosts文件一致
4.虚拟机警告
警告对于指令执行并没有什么影响,但还是看着不舒服,通过这种方式可以解决。
【警告】
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
【原因】
找不到hadoop的native-hadoop library
【解决】
1.为了获取更多信息,开启debug日志
vim $HADOOP_CONF_DIR/log4j.properties
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=DEBUG # 在最后追加这行代码
2.执行hdfs命令,查看日志如下
hdfs dfs -ls /
3.java.library.path=...,查看这行代码中的路径是否正确
我的问题出现在这一步,配置文件里少了native路径:
错误原配置:java.library.path=/home/zhangheng/hudi/server/hadoop/lib
修改后配置:java.library.path=/home/zhangheng/hudi/server/hadoop/lib/native
sudo su切换到管理员账号
vim /etc/profile
export HADOOP_OPTS=-Djava.library.path=$HADOOP_HOME/lib/native
source /etc/profile
重启hadoop就好了。
4.如果3的路径是正确的,可以继续排查
ls -l /home/zhangheng/hudi/server/hadoop/lib/native
如果缺少libhadoop.so文件,有libhadoop.dylib文件,那么原因可能是在mac系统下编译的。解决办法就是在linux系统下重新编译
日志
23/02/17 14:32:56 DEBUG util.NativeCodeLoader: Trying to load the custom-built native-hadoop library...
23/02/17 14:32:56 DEBUG util.NativeCodeLoader: Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path
23/02/17 14:32:56 DEBUG util.NativeCodeLoader: java.library.path=/home/zhangheng/hudi/server/hadoop/lib
23/02/17 14:32:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
5.MySQL启动报错
【错误】
Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock'
【原因】
配置文件里没有配置 socket,默认值是/tmp/mysql.sock,所以上面报错的路径找不到
【解决】
加个软链接
ln -s /tmp/mysql.sock /var/run/mysqld/mysqld.sock
相关文章:
Hudi-ubuntu环境搭建
hudi-ubuntu环境搭建 运行 1.编译Hudi #1.把maven安装包上传到服务器 # 官网下载安装包 https://archive.apache.org/dist/maven/maven-3/ scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\apache-maven-3.6.3-bin.tar.gz zhangheng10.8.4.212:/home/zhangheng/hudi/com…...

Hive进阶Day05
一、HDFS分布式文件存储系统 1-1 HDFS的存储机制 按块(block)存储 hdfs在对文件数据进行存储时,默认是按照128M(包含)大小进行文件数据拆分,将不同拆分的块数据存储在不同datanode服务器上 拆分后的块数据会被分别存储在不同的服…...
ssh爆破服务器的ip-疑似肉鸡
最近发现自己的ssh一直有一些人企图使用ssh暴力破解的方式进行密码破解.就查看了一下,真是网络安全太可怕了. 大家自己的服务器密码还是要设置好,管好,做好最基本的安全措施,不然最后只能沦为肉鸡. ssh登陆日志可以在/var/log下看到,ubuntu的话为auth.log,centos为secure文件 查…...

4.JVM八股
JVM空间划分 线程共享和线程私有 1.7: 线程共享: 堆、方法区 线程私有: 虚拟机栈、本地方法栈、程序计数器 本地内存 1.8: 线程共享: 堆 线程私有: 老三样 本地内存,元空间 程序计数器 …...
内网渗透系列-mimikatz的使用以及后门植入
内网渗透系列-mimikatz的使用以及后门植入 文章目录 内网渗透系列-mimikatz的使用以及后门植入前言mimikatz的使用后门植入 msf永久后门植入 (1)Meterpreter后门:Metsvc(2)Meterpreter后门:Persistence NC后…...

5G网络开通与调测ipv4
要求如下: 1. 勘站规划 1. 【重】首先观察NR频点,完成设备选型 2645--选择N41 3455--选择N78 4725--选择N79 设备选型如下:观察AAU的通道数,最大发射功率;选择N41的选型频段也要选41 2. …...

Spark开窗函数之ROW
Spark 1.5.x版本以后,在Spark SQL和DataFrame中引入了开窗函数,其中比较常用的开窗函数就是row_number 该函数的作用是根据表中字段进行分组,然后根据表中的字段排序;其实就是根据其排序顺序,给组中的每条记录添 加一个序号;且每组的序号都是从1开始,可利用它的这个特性进行分组…...
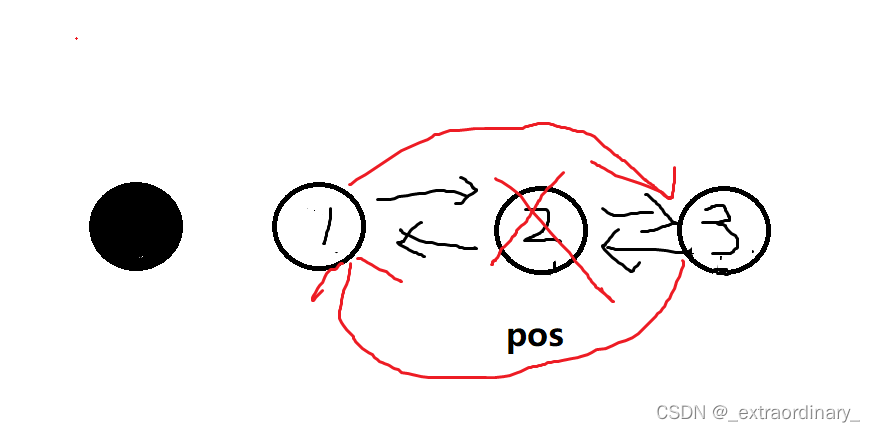
双向链表的实现(详解)
目录 前言初始化双向链表的结构为双向链表的节点开辟空间头插尾插打印链表尾删头删查找指定位置之后的插入删除pos节点销毁双向链表 前言 链表的分类: 带头 不带头 单向 双向 循环 不循环 一共有 (2 * 2 * 2) 种链表 带头指的是:带有哨兵位节点 哨兵位&a…...

SpringBoot项目中如何使用校验工具
用到hutool提供的校验方法与java提供的校验方法 1. 声明数据 String str "123" String regex "^123456$" Boolean is1_6 mismatch(str, regex);2. 定义校验方法 // 校验是否不符合正则格式 private static boolean mismatch(String str, String rege…...
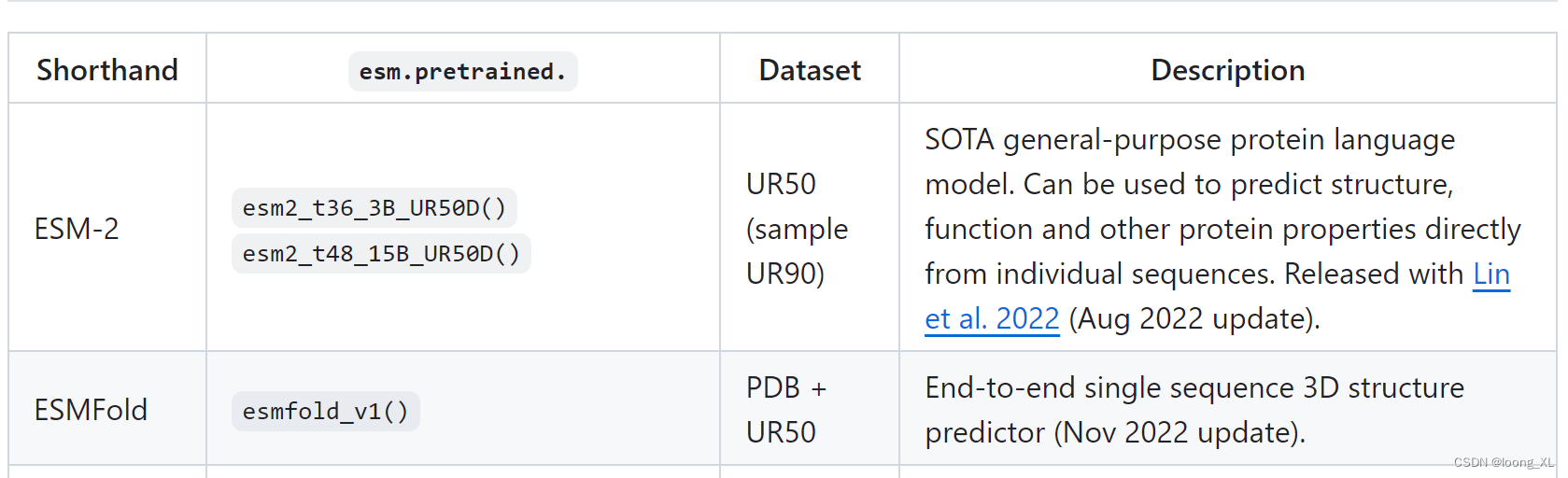
AI预测小分子与蛋白的相关特征: MegaMolBART, MoFlow,ESM-1, ESM-2
1、小分子:MegaMolBART, MoFlow 1)MegaMolBART https://github.com/NVIDIA/MegaMolBART 基于 SMILES 的小分子药物发现与化学信息学深度学习模型。 2)MoFlow https://github.com/calvin-zcx/moflow 用flow流方式分子生成 2、蛋白质:ESM-1, ESM-2 https://github.com/fa…...

基于深度学习的花卉检测系统(含PyQt界面)
基于深度学习的花卉检测系统(含PyQt界面) 前言一、数据集1.1 数据集介绍1.2 数据预处理 二、模型搭建三、训练与测试3.1 模型训练3.2 模型测试 四、PyQt界面实现参考资料 前言 本项目是基于swin_transformer深度学习网络模型的花卉检测系统,…...
深度学习图像处理基础工具——opencv 实战信用卡数字识别
任务 信用卡数字识别 穿插之前学的知识点 形态学操作 模板匹配 等 总体流程与方法 1.有一个模板 2 用轮廓检测把模板中数字拿出来 外接矩形(模板和输入图像的大小要一致 )3 一系列预处理操作 问题的解决思路 1.分析准备:准备模板&#…...

【HBase】HBase高性能架构:如何保证大规模数据的高可用性
HBase高性能原理 HBase 能够提供高性能的数据处理能力,主要得益于其设计和架构的几个关键方面。这些设计特点使得 HBase 特别适合于大规模、分布式的环境中进行高效的数据读写操作。以下是 HBase 高性能的主要原因: 1. 基于列的存储 HBase 是一个列式…...

JAVA基础两个项目案例代码
1.JAVA使用ArrayList上架菜品案例 视频参考链接 创建一个Food.java类 package org.example;// 菜品类 public class Food {private String name; // 菜品名private double price; // 价格private String desc; // 菜品描述public Food() {}public Food(String name, Double …...

asp.net core 网页接入微信扫码登录
创建微信开放平台账号,然后创建网页应用 获取appid和appsecret 前端使用的vue,安装插件vue-wxlogin 调用代码 <wxlogin :appid"appId" :scope"scope" :redirect_uri"redirect_uri"></wxlogin> <scri…...
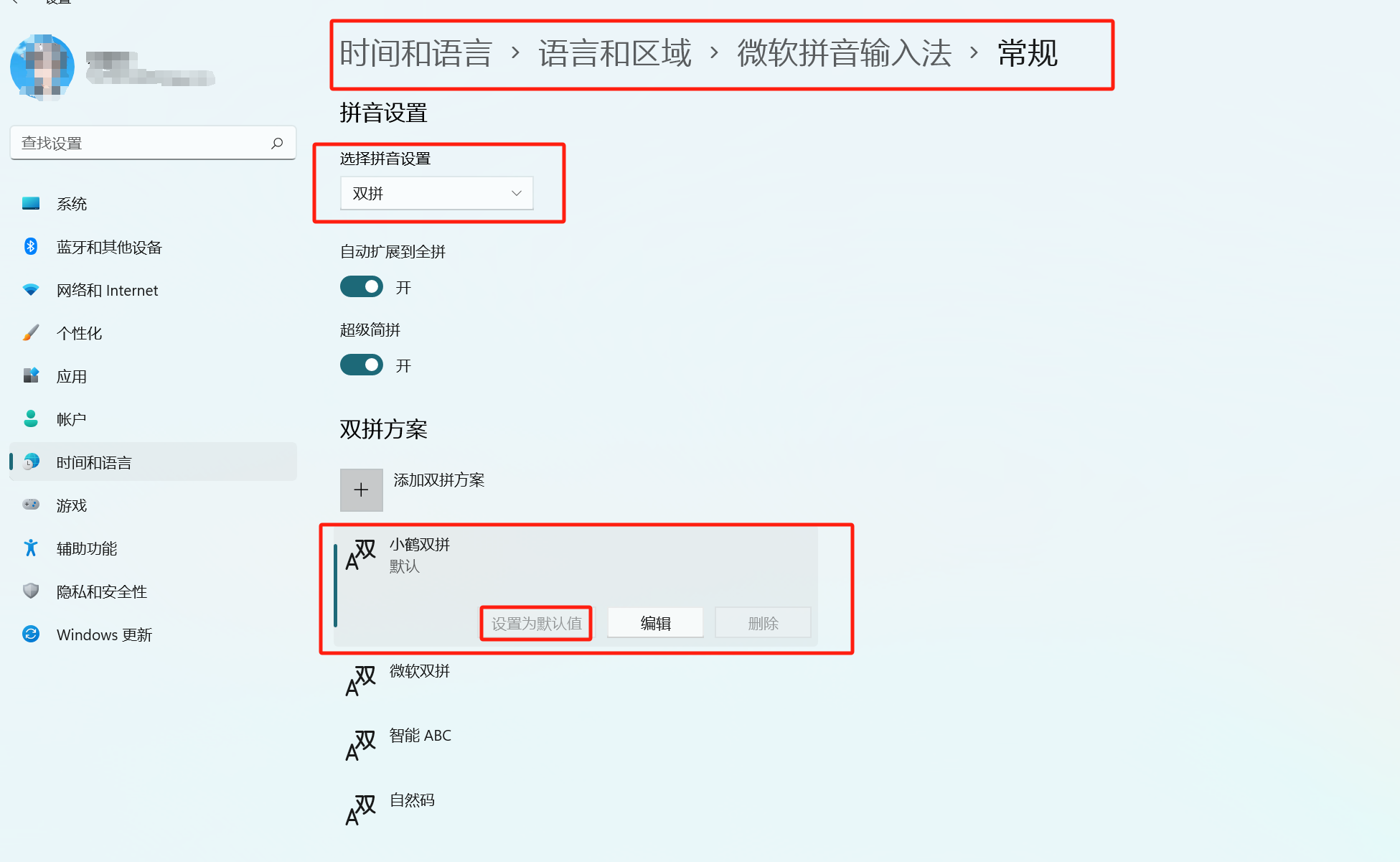
【板栗糖GIS】如何给微软拼音输入法加上小鹤双拼
【板栗糖GIS】如何给微软拼音输入法加上小鹤双拼 用过在注册表里新建的方法,结果弄完没有出现小鹤双拼方案,想到了自己写reg表 目录 1. 新建一个txt文件 2. 把.txt的后缀名改成.reg,双击运行 3. 在设置中找到微软输入法-常规 1. 新建一个…...
如何解决微信小程序无法使用css3过度属性transition
由于微信小程序不支持CSS3过度属性transition,所以我们需要利用微信小程序api进行画面过度的展示 首先是官方示例: wxml: <view animation="{{animationData}}" style="background:red;height:100rpx;width:100rpx"></view> js: Page(…...

【软件设计师知识点】九、网络与信息安全基础知识
文章目录 计算机网络的概念网络分类网络拓扑结构网络体系结构ISO/OSI 7层参考模型TCP/IP 4层模型TCP/IP 协议族应用层协议传输层协议网络层协议IP 地址IPV4 数据报IP 地址分类子网划分子网掩码IPv6地址...

广东省道路货物运输资格证照片回执可手机线上办理
广东省道路运输资格证是从事道路运输业务、危险品道路运输人员的必要证件,而在办理该证件的过程中,驾驶员照片回执是一项必不可少的材料。随着科技的发展和移动互联网的普及,现在办理驾驶员照片回执已经不再需要亲自前往照相馆,而…...
【微信小程序——案例——本地生活(列表页面)】
案例——本地生活(列表页面) 九宫格中实现导航跳转——以汽车服务为案例(之后可以全部实现页面跳转——现在先实现一个) 在app.json中添加新页面 修改之前的九宫格view改为navitage 效果图: 动态设置标题内容—…...

文心一言深度解析:国产多模态大模型的破局之路
文心一言深度解析:国产多模态大模型的破局之路 引言 在ChatGPT引爆全球AI热潮的背景下,国产大模型如何突围?百度推出的文心一言(ERNIE Bot)作为中国AI产业的一面旗帜,凭借其在多模态理解与生成、中文场景深…...

单片机开发者如何通过Taotoken调用大模型API优化代码注释
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 单片机开发者如何通过Taotoken调用大模型API优化代码注释 对于单片机开发者而言,编写清晰、准确的代码注释是提升项目可…...

可穿戴设备十年演进:从技术突破到健康与生产力工具
1. 从预言到现实:可穿戴计算浪潮的十年回望与深度拆解十年前,当EE Times那篇关于Apple iWatch和Google Glasses将引领可穿戴计算浪潮的文章发表时,业界还弥漫着一种将信将疑的氛围。彼时,智能手机正处巅峰,人们很难想象…...
)
告别手动刷新!用PowerShell脚本实现Windows下校园网自动重连(含任务计划设置)
告别手动刷新!用PowerShell脚本实现Windows下校园网自动重连(含任务计划设置) 每次开机都要手动登录校园网?网络突然断开还得重新输入账号密码?这些繁琐操作已经成为过去式。本文将手把手教你用PowerShell打造全自动校…...

Ruby纳米机器人框架:构建高内聚低耦合的自动化任务管道
1. 项目概述:当Ruby遇上纳米机器人最近在GitHub上闲逛,发现了一个名为icebaker/ruby-nano-bots的项目。这个标题本身就充满了想象力——Ruby,一门以优雅和生产力著称的动态语言;Nano-Bots,一个源自科幻、代表微观自动化…...

告别手动下载!3步轻松批量获取网易云音乐FLAC无损音乐
告别手动下载!3步轻松批量获取网易云音乐FLAC无损音乐 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 你是不是也遇到过这样的烦恼&#x…...
实战分配指南(MDK/IAR双环境))
告别内存焦虑!STM32H743全系列SRAM(ITCM/DTCM/AXI)实战分配指南(MDK/IAR双环境)
STM32H743内存优化实战:从理论到精准分配的完整指南 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。STM32H743作为STMicroelectronics推出的高性能微控制器系列,其复杂的内存架构既带来了性能优势,也增加了开发难…...

Nigate:让Mac与Windows硬盘和谐共处的开源桥梁
Nigate:让Mac与Windows硬盘和谐共处的开源桥梁 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NTFS …...

开源浏览器扩展SubLens:集中管理AI订阅账单,告别遗忘扣费
1. 项目概述:一个浏览器扩展,帮你管好AI订阅账单 不知道你有没有这种感觉,每个月信用卡账单出来的时候,总有几个“熟悉的陌生人”——那些你为了尝鲜或者工作需要而订阅的AI服务,比如ChatGPT Plus、Claude Pro、GitHub…...

如何快速掌握歌词滚动姬:新手到专家的5个终极秘籍
如何快速掌握歌词滚动姬:新手到专家的5个终极秘籍 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为音乐配上精准的LRC歌词而烦恼吗?歌词…...