从零实现诗词GPT大模型:数据集介绍和预处理
专栏规划: https://qibin.blog.csdn.net/article/details/137728228
本章将介绍该系列文章中使用的数据集,并且编写预处理代码,处理成咱们需要的格式。
一、数据集介绍
咱们使用的数据集名称是chinese-poetry,是一个在github上开源的中文诗词数据集,根据仓库中readme.md中的介绍,该数据集是最全的中华古典文集数据库,包含 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。诗人包括唐宋两朝近 1.4 万古诗人,和两宋时期 1.5 千古词人。
数据集的下载地址:https://github.com/chinese-poetry/chinese-poetry?tab=readme-ov-file,大家可以点击Code按钮,选择Download ZIP将该数据集下载到本地,如下图:
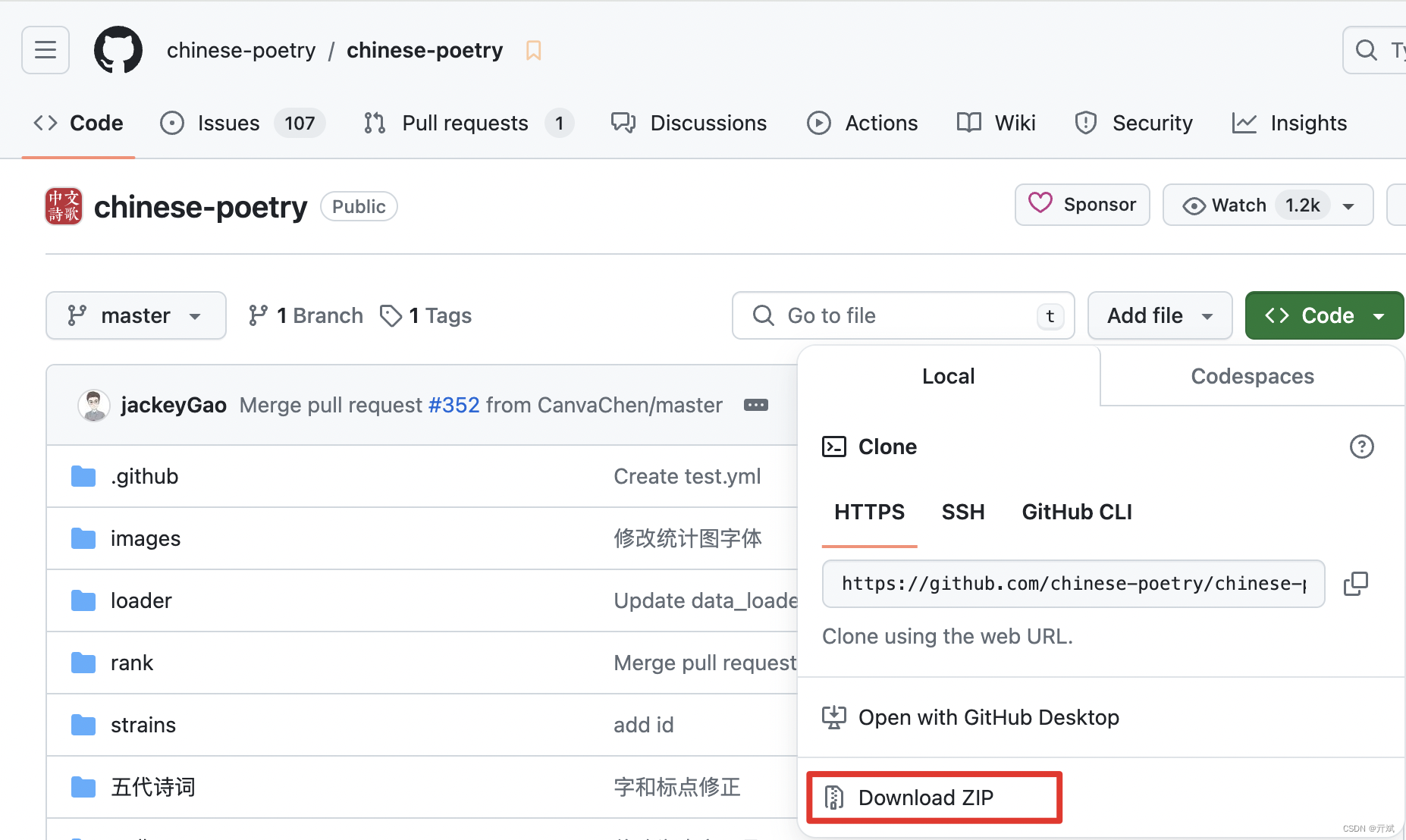
当然,作者收集数据也不易,大家可以顺手点一下star鼓励一下作者,如图:

如果你按照上面的步骤,把数据集下载到你本地了,解压后你可以看到如下图所示的目录结构
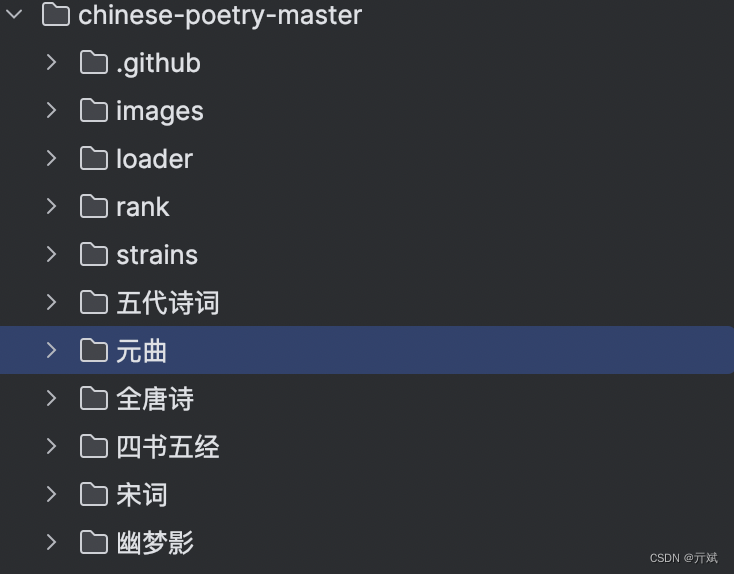
作者按照不同诗词类型进行了分类,并且在每个分类下提供了1个到多个的json文件,json文件里按照结构化数据组织了每一个诗词的信息,如下图

二、数据集预处理
上面咱们详细介绍了chinese-poetry数据集的下载方式和作者组织的结构,下面我们将提取每个诗词的标题和内容作为我们需要的部分,并聚合到一个文件中,以方便我们后续训练模型使用。
首先,我们需要把作者提供的诗词类目整理到一个数组中,方便我们后续进行目录的变量
classes = ['五代诗词', '元曲', '全唐诗', '四书五经', '宋词', '幽梦影', '御定全唐詩', '曹操诗集', '楚辞', '水墨唐诗','纳兰性德', '蒙学', '论语', '诗经']
然后,我们可以遍历该数组,拼接一个目录,遍历目录中中的文件,再进行文件处理
for cls in classes:dir = base_dir + clsfiles = os.listdir(dir)for f in files:f = f'{dir}/{f}'if os.path.isdir(f):if 'error' in f:continuefor ff in os.listdir(f):process_json(f'{f}/{ff}')else:process_json(f)
上面代码中,我们遍历每个类别的目录后,会列出该类别中所有的文件,文件如果是一个目录,则继续遍历这个目录,因为作者提供的目录结构会存在二级目录的情况。
最后,拿到每个json文件后,会调用process_json()函数处理对应的json文件。下面我们开始介绍process_json()函数。
process_json()函数会对上面代码中拿到的每个json文件进行处理,并且从json文件中提取我们需要的信息(诗词的标题和内容),重新组织结构,写入到一个新文件中;该函数还会根据一个简单的策略划分出训练集和测试集(训练集用来训练我们的模型,测试集用来在训练过程中测试模型的性能)。整体代码如下
def process_json(file):if not file.endswith('.json'):returnwith open(file, 'r') as f:json_content = f.read()array = json.loads(json_content)if type(array) != list:returnif len(array) > 100:train_array = array[:-1]test_array = array[-1:]else:train_array = arraytest_array = Nonefor item in train_array:if 'title' not in item.keys() or 'paragraphs' not in item.keys():continuewrite_file(item, dst_train_file)if test_array is not None:for item in test_array:if 'title' not in item.keys() or 'paragraphs' not in item.keys():continuewrite_file(item, dst_test_file)
在代码中,首先会打开该json文件,并读取json文件中的内容;读到内容后,通过json.loads()函数将它解码成在python中可以识别的数据结构。
接下来,我们根据该分类下诗词的数据决定是否要划分出测试集,策略很简单,如果个数大于100,我们就把最后一个作为测试集的一部分,当然这个策略可以根据你的需求进行调整。
最后,我们从json中拿到title和paragraphs属性通过一个write_file()函数写到我们的新文件中。
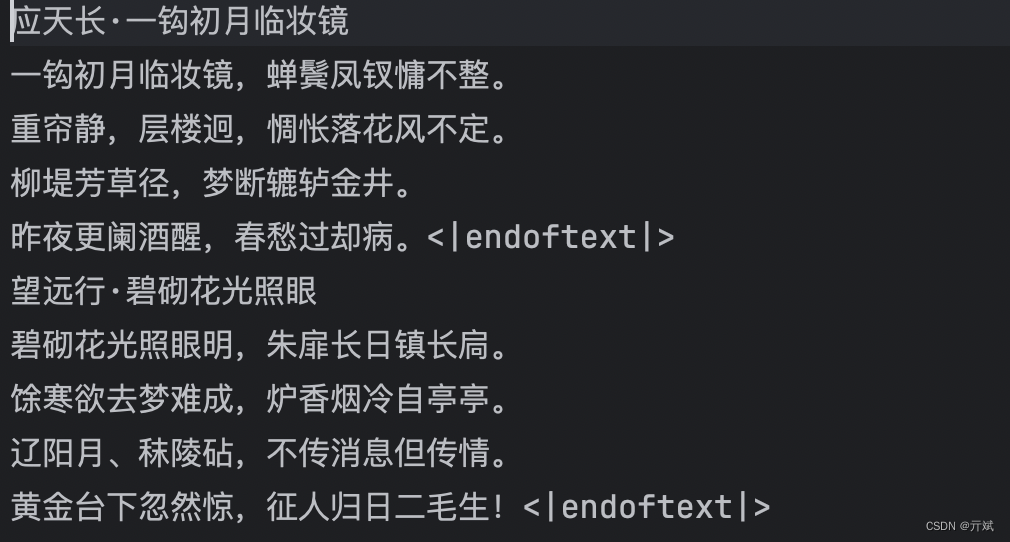
write_file()函数的实现也很简单,作用就是拿到title和paragraphs,组织好结构写入到一个新文件中;我们预处理后的文件不会像原数据集那样提供多个文件,而是全部写到同一个文件中,所以,此时就得考虑一个问题:所有的诗词在一个文件中,怎么标识出一首诗结束了呢?办法很简单,我们在没首诗结束的时候添加一个<|endoftext|>特殊标识,该标识很重要,因为在后面我们训练模型的时候,该标识也会根据此标识学习一首诗到哪结束了(不需要结束,咱们模型就无止境的输出了)。
def write_file(item, dst_file):global error_counttitle = item['title']paragraphs = item['paragraphs']content = f'\n{title}'for p in paragraphs:content = f'{content}\n{p}'content = converter.convert(content)if '𫗋' in content:print(f'{content}----')error_count += 1returncontent = content + '<|endoftext|>'dst_file.write(content)
上面代码中,处理前面我们介绍的部分,存在两个特殊的地方
...
content = converter.convert(content)
...
if '𫗋' in content
第一个的作用是将繁体中文转换成简体字,因为原数据集中存在大量的繁体字,显然,我们不想让咱们的模型生成的诗词是繁体字形式,所以这里我选择将繁体字转换成简体字,这里借助了一个python的转换库opencc实现,大家可以通过pip3 install opencc-python-reimplemented进行安装,该库的使用方法如下
import opencc
# 繁转简
converter = opencc.OpenCC('t2s')
content = converter.convert(content)
第二个特殊的地方就是我们代码中有一个𫗋,这是因为,通过上述代码转换成简体字的时候会有一些字转换错误,所以我们这里直接将存在转换错误情况的诗过滤掉,当然,这种情况不会很多,大概几十首诗词,对于咱们几十万首诗词的数据集来说都是毛毛雨。
好了,上面就是咱们数据预处理的全部过程,最终你会得到一个如下结构的train.txt和test.txt分别代表咱们前面提到过的训练集和测试集。
最后,我把全部代码整理出来,方便大家可以复制到本地直接运行
import os, json
import openccbase_dir = 'chinese-poetry-master/'
classes = ['五代诗词', '元曲', '全唐诗', '四书五经', '宋词', '幽梦影', '御定全唐詩', '曹操诗集', '楚辞', '水墨唐诗','纳兰性德', '蒙学', '论语', '诗经']dst_train_file = open('./train.txt', 'w')
dst_test_file = open('./test.txt', 'w')converter = opencc.OpenCC('t2s')
error_count = 0def write_file(item, dst_file):global error_counttitle = item['title']paragraphs = item['paragraphs']content = f'\n{title}'for p in paragraphs:content = f'{content}\n{p}'content = converter.convert(content)if '𫗋' in content:print(f'{content}----')error_count += 1returncontent = content + '<|endoftext|>'dst_file.write(content)def process_json(file):if not file.endswith('.json'):returnwith open(file, 'r') as f:json_content = f.read()array = json.loads(json_content)if type(array) != list:returnif len(array) > 100:train_array = array[:-1]test_array = array[-1:]else:train_array = arraytest_array = Nonefor item in train_array:if 'title' not in item.keys() or 'paragraphs' not in item.keys():continuewrite_file(item, dst_train_file)if test_array is not None:for item in test_array:if 'title' not in item.keys() or 'paragraphs' not in item.keys():continuewrite_file(item, dst_test_file)for cls in classes:dir = base_dir + clsfiles = os.listdir(dir)for f in files:f = f'{dir}/{f}'if os.path.isdir(f):if 'error' in f:continuefor ff in os.listdir(f):process_json(f'{f}/{ff}')else:process_json(f)dst_train_file.close()
dst_test_file.close()dst_train_file = open('./train.txt', 'r')
dst_test_file = open('./test.txt', 'r')train_count = 0
test_count = 0for line in dst_train_file:if '<|endoftext|>' in line:train_count += 1for line in dst_test_file:if '<|endoftext|>' in line:test_count += 1print(f'train_count: {train_count}, test_count: {test_count}, error_count: {error_count}')
下一篇,我们将对pytorch框架做一个简单的入门介绍
相关文章:
从零实现诗词GPT大模型:数据集介绍和预处理
专栏规划: https://qibin.blog.csdn.net/article/details/137728228 本章将介绍该系列文章中使用的数据集,并且编写预处理代码,处理成咱们需要的格式。 一、数据集介绍 咱们使用的数据集名称是chinese-poetry,是一个在github上开源的中文诗…...
45.HarmonyOS鸿蒙系统 App(ArkUI)创建列表(List)
列表是一种复杂的容器,当列表项达到一定数量,内容超过屏幕大小时,可以自动提供滚动功能。它适合用于呈现同类数据类型或数据类型集,例如图片和文本。在列表中显示数据集合是许多应用程序中的常见要求(如通讯录、音乐列…...

推荐算法之协同过滤
算法原理 透过百科,我们了解到协同过滤推荐(Collaborative Filtering recommendation)是在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤算法结合用户行为分析用户…...

Kotlin 面试题
lifecycleScope.launchWhenResumed launchWhenResumed是一个扩展函数,它是LifecycleCoroutineScope的一部分,并且它是在Android的Lifecycle库中引入的。 这个函数的主要目的是在Lifecycle的对应组件(通常是Activity或Fragment)处于“resumed”状态时启动协程。 public fun …...

TCM(Tightly Coupled Memory)紧密耦合存储器简介
在ARM Cortex处理器中,TCM通常指的是紧密耦合存储器(Tightly Coupled Memory)。TCM是一种位于处理器核心旁边的高速存储器,它的设计目的是为了提供低延迟和高带宽的内存访问性能。 TCM的特点是它与处理器内核紧密耦合,…...

《自动机理论、语言和计算导论》阅读笔记:p172-p224
《自动机理论、语言和计算导论》学习第 8 天,p172-p224总结,总计 53 页。 一、技术总结 1.Context-Free Grammar(CFG) 2.parse tree (1)定义 p183,But perhaps more importantly, the tree, known as a “parse tree”, when used in a …...

typescript playwright 笔记
录制调式 命令 npx playwright codegen url npx playwright codegen https://www.baidu.com/typescript 中 format 和 split 的使用 import * as util from util;const str1 hellow %s; const format util.format; const str2 format(str1, word);// 提取taskId const str3…...
从零实现诗词GPT大模型:了解Transformer架构
专栏规划: https://qibin.blog.csdn.net/article/details/137728228 这篇文档我们开始对GPT的核心组件Transformer进行一个详细的讲解, 加急编写中…...

温故知新之-TCP Keepalive机制及长短连接
[学习记录] 前言 TCP连接一旦建立,只要连接双方不主动 close ,连接就会一直保持。但建立连接的双方并不是一直都存在数据交互,所以在实际使用中会存在两种情况:一种是每次使用完,主动close,即短连接&…...

架构师系列-搜索引擎ElasticSearch(七)- 集群管理之分片
集群健康检查 Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是集群健康,它在 status字段中展示为 green(所有主分片和副本分片都正常)、yellow(所有数据可用,有些副本分片尚未…...

基于Spring Boot实现的图书个性化推荐系统
基于Spring Boot实现的图书个性化推荐系统 开发语言:Java语言 数据库:MySQL工具:IDEA/Ecilpse、Navicat、Maven 系统实现 前台首页功能模块 学生注册 登录 图书信息 个人信息 管理员功能模块 学生管理界面图 图书分类管理界面图 图书信息管…...

安全加速SCDN带的态势感知能为网站安全带来哪些帮助
随着安全加速SCDN被越来越多的用户使用,很多用户都不知道安全加速SCDN的态势感知是用于做什么的,德迅云安全今天就带大家来了解下什么是态势感知,态势感知顾名思义就是对未发生的事件进行预知,并提前进行防范措施的布置࿰…...
)
java面向对象.day21(继承02--super)
说明 super父 this当前 使用super时,首先要继承父类,其次是在子类里面才能使用super。 继承父类后,运行子类时会同时调用父类的构造方法,如果要显性调用父类的构造方法必须在子类的第一行调用。 单使用super()表示调用父类构造…...
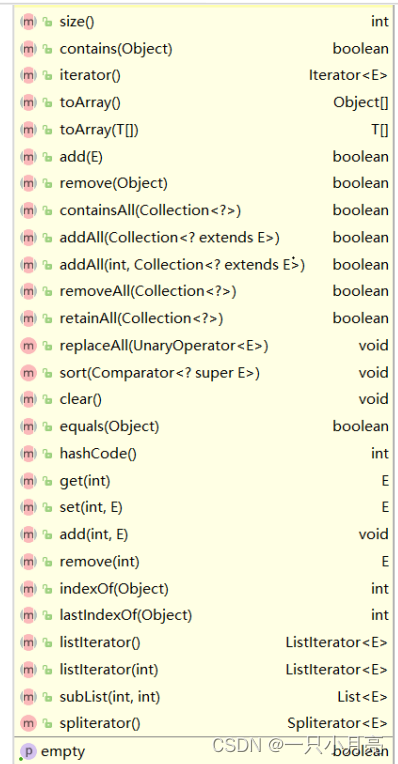
【数据结构】4.List的介绍
目录 1.什么是List 2.常见接口介绍 3.List的使用 1.什么是List 在集合框架中,List是一个接口,继承自Collection。 Collection也是一个接口,该接口中规范了后序容器中常用的一些方法,具体如下: Iterable也是一个接口…...

acwing算法提高之图论--最近公共祖先
目录 1 介绍2 训练 1 介绍 本博客用来记录"对于有根图中,求最近公共祖先"的题目。 求解方法: 向上标记法。每次求两个结点的最近公共祖先的时间复杂度是O(N)。由于时间复杂度较高,通常不用。倍增法。 倍增法重要思路࿱…...

C语言 函数——断言与防御式编程
目录 如何确定假设的真假? 断言 防御式编程(Defensive programming) 如何确定假设的真假? 程序中的假设 *某个特定点的某个表达式的值一定为真 *某个特定点的某个表达式的值一定位于某个区间等 问题:如何确定这些…...

【opencv】示例-travelsalesman.cpp 使用模拟退火算法求解旅行商问题
// 载入 OpenCV 的核心头文件 #include <opencv2/core.hpp> // 载入 OpenCV 的图像处理头文件 #include <opencv2/imgproc.hpp> // 载入 OpenCV 的高层GUI(图形用户界面)头文件 #include <opencv2/highgui.hpp> // 载入 OpenCV 的机器学习模块头文件 #includ…...

【linux深入剖析】深入理解软硬链接 | 动静态库的制作以及使用
🍁你好,我是 RO-BERRY 📗 致力于C、C、数据结构、TCP/IP、数据库等等一系列知识 🎄感谢你的陪伴与支持 ,故事既有了开头,就要画上一个完美的句号,让我们一起加油 目录 1.理解软硬链接1.1 操作观…...

xss常用标签和触发事件
无过滤情况 <script> <scirpt>alert("xss");</script> <img> 图片加载错误时触发 <img src"x" οnerrοralert(1)> <img src"1" οnerrοreval("alert(xss)")> 鼠标指针移动到元素时触发 <im…...

WPF中Binding的原理和应用
WPF中Binding的原理和应用 在WPF中,Binding机制是实现数据与界面的连接和同步的重要工具。了解Binding的原理和应用,对于开发人员来说是非常重要的。本文将详细介绍WPF中Binding的原理和应用,帮助读者更好地理解和运用这一强大的机制。 Bin…...
)
手把手教你搞定Sx1262射频前端:从天线匹配到LPF滤波的完整电路设计(附PCB布局建议)
手把手教你搞定Sx1262射频前端:从天线匹配到LPF滤波的完整电路设计(附PCB布局建议) 在物联网设备开发中,射频前端设计往往是硬件工程师最头疼的环节之一。特别是使用Semtech的Sx1262这类LoRa芯片时,一个设计不当的射频…...

终局架构:指纹隔离底座 + gRPC分布式调度,重塑千万级拼多多店群RPA集群
大家好,我是林焱,一名专注电商底层业务逻辑与 RPA 自动化架构定制的独立开发者。 在前面的几篇 CSDN 专栏中,我们探讨了如何利用“指纹浏览器底层隔离”解决风控关联问题,如何利用“EDA(事件驱动)”和“CD…...

AI支付架构选型:Card Rails与Agent Rails的深度对比与实践指南
1. 项目概述:AI支付架构的十字路口最近在设计和落地几个AI驱动的支付系统时,我反复被一个核心的架构选择所困扰:是采用“Card Rails”还是“Agent Rails”?这不仅仅是技术选型,更是两种截然不同的产品哲学和风险控制思…...

Vibe Coding:打造沉浸式编程学习环境,从环境到心流的高效开发实践
1. 项目概述:从“Vibe Coding”到沉浸式编程学习 最近在开发者社区里,一个名为“VibecodingCurriculum”的项目引起了我的注意。这个由 hashed 团队在 vibedojo 下维护的仓库,名字本身就很有意思——“Vibe Coding”,直译过来是“…...

别再死记硬背截止、放大、饱和了!用Arduino+面包板,5分钟直观演示三极管三种工作状态
用Arduino实战破解三极管工作状态的秘密 记得第一次学三极管时,盯着课本上那些截止区、放大区、饱和区的曲线图,我完全无法理解这些抽象概念和实际电路有什么关系。直到有一天,我在实验室里用Arduino和几个简单元件搭建了一个测试电路&#x…...

德国工业4.0工程师指南:从系统融合到职业发展
1. 项目概述:为什么德国是工业工程师的理想目的地?如果你是一名工业、自动化或机器人领域的工程师,正在寻找一个能将你的技术抱负与前沿产业实践深度结合的职业舞台,那么德国很可能就是你一直在寻找的答案。这不仅仅是因为德国拥有…...

AI驱动BI分析:MCP协议与Metabase助手实战指南
1. 项目概述:当AI助手成为你的BI分析师如果你和我一样,每天都要和Metabase打交道,那你肯定经历过这样的场景:业务同事跑过来问,“能不能帮我拉一下上个月每个渠道的转化率?”,或者产品经理说&am…...

Vue3 + Vite项目集成vue-particles避坑指南:从安装到性能优化全流程
Vue3 Vite项目集成vue-particles全流程实战:从安装到性能调优 在Vue3和Vite构建的现代前端项目中,集成像vue-particles这样的视觉特效组件往往会遇到意想不到的兼容性问题。不同于传统的Webpack环境,Vite的ES模块系统和Vue3的组合式API带来了…...

Cursor AI 编程助手配置优化:一键安装与自定义指南
1. 项目概述:为什么需要一套现成的 Cursor 配置?如果你和我一样,是 Cursor 的重度用户,那么你肯定经历过这样的阶段:刚上手时,觉得这个 AI 驱动的 IDE 简直是神器,但随着项目越来越复杂…...

工程师如何运用专业技能参与人道主义项目:从思维转变到实践落地
1. 项目概述:工程师的人道主义行动倡议每年8月19日,世界人道主义日都会提醒我们关注那些在全球最艰苦、最危险地区默默奉献的人们。这个日子最初是为了纪念在履职中牺牲的人道主义工作者,如今已演变为一个更广泛的号召——庆祝那种激励全球人…...