ins视频批量下载,instagram批量爬取视频信息
简介
Instagram 是目前最热门的社交媒体平台之一,拥有大量优质的视频内容。但是要逐一下载这些视频往往非常耗时。在这篇文章中,我们将介绍如何使用 Python 编写一个脚本,来实现 Instagram 视频的批量下载和信息爬取。
我们使用selenium获取目标用户的 HTML 源代码,并将其保存在本地:
def get_html_source(html_url):option = webdriver.EdgeOptions()option.add_experimental_option("detach", True)# option.add_argument("--headless") # 添加这一行设置 Edge 浏览器为无头模式 不会显示页面# 实例化浏览器驱动对象,并将配置浏览器选项driver = webdriver.Edge(options=option)# 等待元素出现,再执行操作driver.get(html_url)time.sleep(3)# ===============模拟操作鼠标滑轮====================i=1while True:# 1. 滚动至页面底部last_height = driver.execute_script("return document.body.scrollHeight")driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")time.sleep(4)# 2. 检查是否已经滚动到底部new_height = driver.execute_script("return document.body.scrollHeight")if new_height == last_height:breaklogger.info(f"Scrolled to page{i}")i += 1html_source=driver.page_sourcedriver.quit()return html_source
total_html_source = get_html_source(f'https://imn/{username}/')
with open(f'./downloads/{username}/html_source.txt', 'w', encoding='utf-8') as file:file.write(total_html_source)
然后,我们遍历每个帖子,提取相关信息并下载对应的图片或视频:,注意不同类型的帖子,下载爬取方式不一样
def downloader(logger,downlod_url,file_dir,file_name):logger.info(f"====>downloading:{file_name}")# 发送 HTTP 请求并下载视频response = requests.get(downlod_url, stream=True)# 检查请求是否成功if response.status_code == 200:# 创建文件目录if not os.path.exists("downloads"):os.makedirs("downloads")# 获取文件大小total_size = int(response.headers.get('content-length', 0))# 保存视频文件# file_path = os.path.join(file_dir, file_name)with open(file_path, "wb") as f, tqdm(total=total_size, unit='B', unit_scale=True, unit_divisor=1024, ncols=80, desc=file_name) as pbar:for chunk in response.iter_content(chunk_size=1024):if chunk:f.write(chunk)pbar.update(len(chunk))logger.info(f"downloaded and saved as {file_path}")return file_pathelse:logger.info("Failed to download .")return "err"def image_set_downloader(logger,id,file_dir,file_name_prx):logger.info("downloading image set========")image_set_url="https://imm"+idhtml_source=get_html_source(image_set_url)# # 打开或创建一个文件用于存储 HTML 源代码# with open(file_dir+file_name_prx+".txt", 'w', encoding='utf-8') as file:# file.write(html_source)
# 4、解析出每一个帖子的下载url downlod_urldownload_pattern = r'data-proxy="" data-src="([^"]+)"'matches = re.findall(download_pattern, html_source)download_file=[]# # 输出匹配到的结果for i, match in enumerate(matches, start=1):downlod_url = match.replace("amp;", "")file_name=file_name_prx+"_"+str(i)+".jpg"download_file.append(downloader(logger,downlod_url,file_dir,file_name))desc_pattern = r'<div class="desc">([^"]+)follow'desc_matches = re.findall(desc_pattern, html_source)desc=""for match in desc_matches:desc=matchlogger.info(f"desc:{match}")return desc,download_filedef image_or_video_downloader(logger,id,file_dir,file_name):logger.info("downloading image or video========")image_set_url="https://im"+idhtml_source=get_html_source(image_set_url)# # 打开或创建一个文件用于存储 HTML 源代码# with open(file_dir+file_name+".txt", 'w', encoding='utf-8') as file:# file.write(html_source)
# 4、解析出每一个帖子的下载url downlod_urldownload_pattern = r'href="(https://scontent[^"]+)"'matches = re.findall(download_pattern, part)# # 输出匹配到的结果download_file=[]for i, match in enumerate(matches, start=1):downlod_url = match.replace("amp;", "")download_file.append(downloader(logger,downlod_url,file_dir,file_name))# 文件名desc_pattern = r'<div class="desc">([^"]+)follow'desc_matches = re.findall(desc_pattern, html_source)desc=""for match in desc_matches:desc=matchlogger.info(f"desc:{match}")return desc,download_file
parts = total_html_source.split('class="item">')
posts_number = len(parts) - 2logger.info(f"posts number:{posts_number} ")for post_index, part in enumerate(parts, start=0):id = ""post_type = ""post_time = ""if post_index == 0 or post_index == len(parts) - 1:continuelogger.info(f"==================== post {post_index} =====================================")# 解析出每个帖子的时间和 IDtime_pattern = r'class="time">([^"]+)</div>'matches = re.findall(time_pattern, part)for match in matches:post_time = matchlogger.info(f"time:{match}")id_pattern = r'<a href="([^"]+)">'id_matches = re.findall(id_pattern, part)for match in id_matches:id = matchlogger.info(f"id:{id}")# 根据帖子类型进行下载if '#ffffff' in part:post_type = "Image Set"logger.info("post_type: Image Set")image_name_pex = "img" + str(post_index)desc, post_contents = image_set_downloader(logger, id, image_dir, image_name_pex)elif "video" in part:post_type = "Video"logger.info("post_type: Video")video_name = "video" + str(post_index) + ".mp4"desc, post_contents = image_or_video_downloader(logger, id, video_dir, video_name)else:logger.info("post_type: Image")post_type = "Image"img_name = "img" + str(post_index) + ".jpg"desc, post_contents = image_or_video_downloader(logger, id, image_dir, img_name)# 将信息写入 Excel 文件exceller.write_row((post_index, post_time, post_type, desc, ', '.join(post_contents)))
最后,我们调用上述定义的函数,实现图片/视频的下载和 Excel 文件的写入。
结果展示
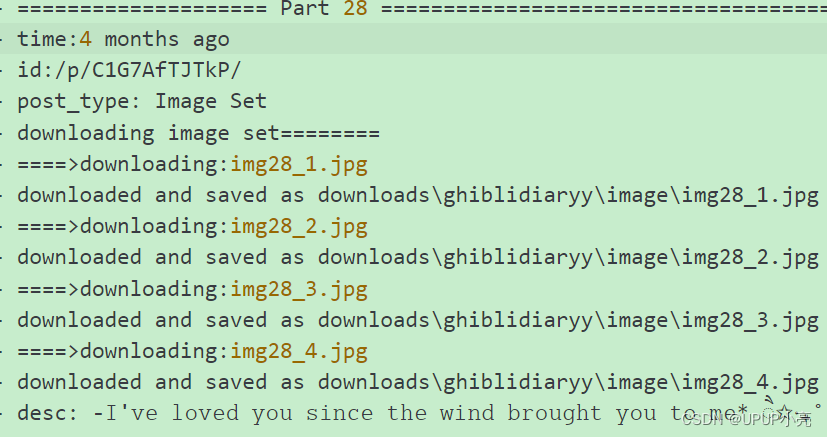
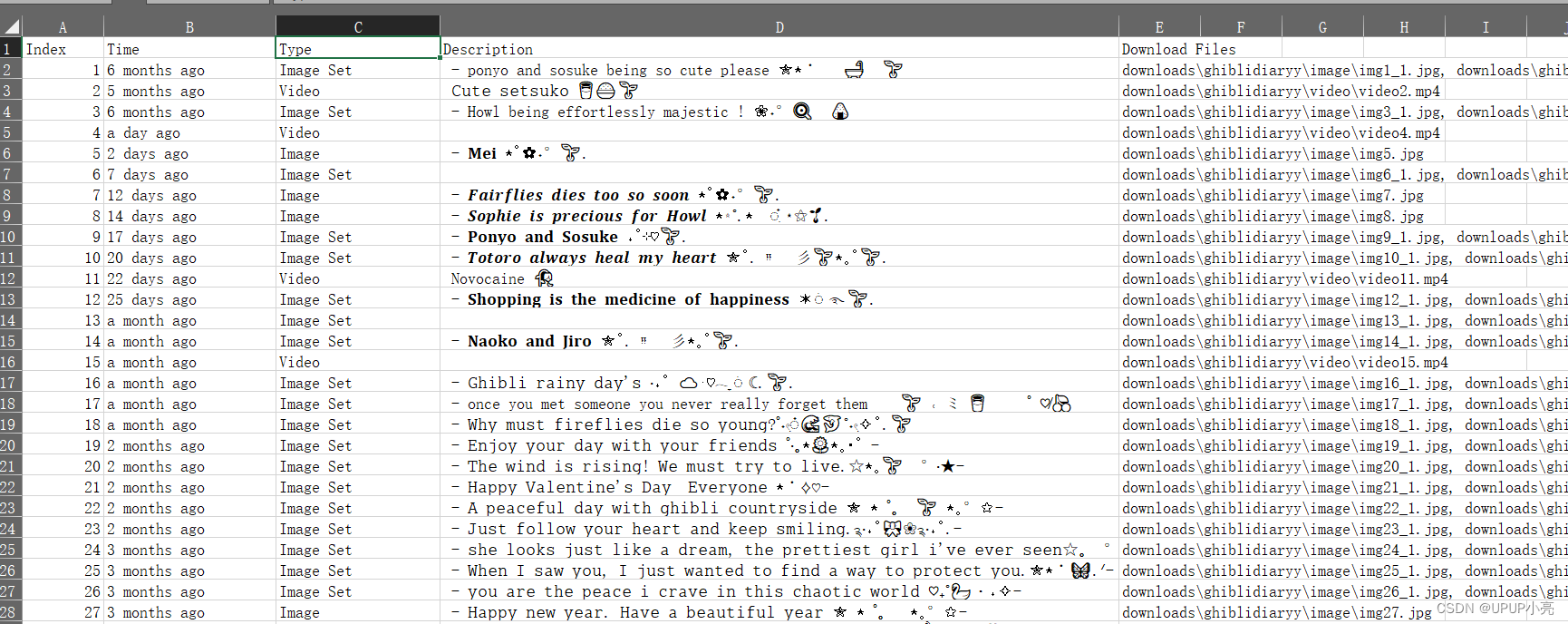
源码
想要获取源码的小伙伴加v:15818739505 ,手把手教你部署使用哦
相关文章:
ins视频批量下载,instagram批量爬取视频信息
简介 Instagram 是目前最热门的社交媒体平台之一,拥有大量优质的视频内容。但是要逐一下载这些视频往往非常耗时。在这篇文章中,我们将介绍如何使用 Python 编写一个脚本,来实现 Instagram 视频的批量下载和信息爬取。 我们使用selenium获取目标用户的 HTML 源代码,并将其保存…...
)
Canvas图形编辑器-数据结构与History(undo/redo)
Canvas图形编辑器-数据结构与History(undo/redo) 这是作为 社区老给我推Canvas,于是我也学习Canvas做了个简历编辑器 的后续内容,主要是介绍了对数据结构的设计以及History能力的实现。 在线编辑: https://windrunnermax.github.io/CanvasEditor开源地…...

阿里云Centos7下编译glibc
编译glibc 原来glibc版本 编译前需要的环境: CentOS7 gcc 8.3.0 gdb 8.3.0 make 4.0 binutils 2.39 (ld -v) python 3.6.8 其他看INSTALL, 但有些版本也不易太高 wget https://mirrors.aliyun.com/gnu/glibc/glibc-2.37.tar.gz tar -zxf glibc-2.37.tar.gz cd glibc-2.37/ …...

UE5数字孪生系列笔记(四)
场景的切换 创建一个按钮的用户界面UMG 创建一个Actor,然后将此按钮UMG添加到组件Actor中 调节几个全屏的背景 运行结果 目标点切换功能制作 设置角色到这个按钮的位置效果 按钮被点击就进行跳转 多个地点的切换与旋转 将之前的目标点切换逻辑替换成旋转的逻…...

品牌故事化:Kompas.ai如何塑造深刻的品牌形象
在这个信息爆炸的时代,品牌故事化已经成为企业塑造独特形象、与消费者建立情感联系的重要手段。一个引人入胜的品牌故事不仅能够吸引消费者的注意力,还能够在消费者心中留下持久的印象,建立起强烈的情感连接。本文将深入探讨品牌故事化对于构…...

5g和2.4g频段有什么区别
运行的频段不同 2.4G和5G频段的主要区别在于它们运行的频段不同,2.4G频段运行在2.4GHz的频段上,而5G频段(这里指的是5GHz频段)运行在5GHz的频段上。12 这导致了两者在传输速度、覆盖范围、抗干扰能力等方面的明显差异。以下是详…...

交通管理在线服务系统|基于Springboot的交通管理系统设计与实现(源码+数据库+文档)
交通管理在线服务系统目录 目录 基于Springboot的交通管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、用户信息管理 2、驾驶证业务管理 3、机动车业务管理 4、机动车业务类型管理 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计…...

konva.js 工具类
konva.js 工具类 class KonvaCanvas {/*** 初始化画布* param {String} domId 容器dom id*/constructor(domId) {this.layer null;this.stage null;this.scale 1;this.init(domId);}/*** 聚焦到指定元素* param {String} elementId 元素dom id*/focusOn(elementId) {if (!t…...
php未能在vscode识别?
在设置里搜php,找到settings.json,设置你的安装路径即可。 成功...

解读MongoDB官方文档获取mongo7.0版本的安装步骤与基本使用
mongo式一款NOSQL数据库,用于存储非结构化数据,mongo是一种用于存储json的数据数据,可以通过mongo提供的命令解析json获取想要的值。 数据模型 了解关系数据库会很熟悉database,table,row,column的概念,分别是数据库,…...

【数据结构|C语言版】顺序表
前言1. 初步认识数据结构2. 线性表3. 顺序表3.1 顺序表的概念3.1 顺序表的分类3.2 动态顺序表的实现 结语 前言 各位小伙伴大家好!小编来给大家讲解一下数据结构中顺序表的相关知识。 1. 初步认识数据结构 【概念】数据结构是计算机存储、组织数据的⽅式。 数据…...
Unity类银河恶魔城学习记录12-17 p139 In game UI源代码
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili UI.cs using UnityEngine;public class UI : MonoBehaviour {[SerializeFie…...
MongoDB学习【一】MongoDB简介和部署
MongoDB简介 MongoDB是一种开源的、面向文档的、分布式的NoSQL数据库系统,由C语言编写而成。它的设计目标是为了适应现代Web应用和大数据处理场景的需求,提供高可用性、横向扩展能力和灵活的数据模型。 主要特点: 文档模型: Mon…...

html 引入vue Element ui 的方式
第一种:使用CDN的方式引入 <!--引入 element-ui 的样式,--> <link rel"stylesheet" href"https://unpkg.com/element-ui/lib/theme-chalk/index.css"> <!-- 必须先引入vue, 后使用element-ui --> <…...

曾经备受追捧的海景房,为何如今却没人要了?
独家首发 ------------ 全国多地的海景房如威海乳山、惠州大亚湾、北海银滩等多地的海景房如今大跌也难以卖出,与当初各地对海景房的追捧形成了鲜明对比,为何这些海景房变成如此样子,在于现实与宣传存在着很大的区别。 曾几何时面朝大海鸟语花…...

[docker] 镜像部分补充
[docker] 镜像部分补充 这里补充一下比较少用的,关于镜像的内容 检查镜像 ❯ docker images REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> ca61c1748170 2 hours ago 1.11GB node latest 5212d…...
 委托(by) 封装 SharedPreferences)
Android(Kotlin) 委托(by) 封装 SharedPreferences
在 Kotlin 中,委托是一种通过将自身的某个功能交给另一个对象来实现代码重用的技术。通过委托,我们可以将某个属性或方法的实现委托给另一个对象,从而减少重复代码的编写。委托可以用于实现多重继承、代码复用和扩展现有类的功能。 Kotlin 中…...

2022年蓝桥杯省赛软件类C/C++B组----积木画
想借着这一个题回顾一下动态规划问题的基本解法,让解题方法清晰有条理,希望更多的人可以更轻松的理解动态规划! 目录 【题目】 【本题解题思路】 【DP模版】 总体方针: 具体解题时的套路: 【题目】 【本题解题思…...

Python数据挖掘项目开发实战:使用朴素贝叶斯进行社会媒体挖掘
注意:本文下载的资源,与以下文章的思路有相同点,也有不同点,最终目标只是让读者从多维度去熟练掌握本知识点。 Python数据挖掘项目开发实战:使用朴素贝叶斯进行社会媒体挖掘 一、项目背景与目标 在社交媒体时代&…...

【DM8】ET SQL性能分析工具
通过统计SQL每个操作符的时间花费,从而定位到有性能问题的操作,指导用户去优化。 开启ET工具 INI参数: ENABLE_MONITOR1 MONITOR_SQL_EXEC1 查看参数 select * FROM v$dm_ini WHERE PARA_NAMEMONITOR_SQL_EXEC;SELECT * FROM v$dm_ini WH…...

Anything V5镜像实战:从部署到生成你的第一张二次元头像
Anything V5镜像实战:从部署到生成你的第一张二次元头像 1. 项目介绍与核心价值 Anything V5是基于Stable Diffusion技术优化的高质量二次元图像生成模型。相比通用版本,它特别擅长生成动漫风格的人物肖像、场景插画等作品,在细节表现和风格…...
)
RViz实战:如何用C++在ROS中动态切换不同形状的物体(含避坑指南)
RViz实战:如何用C在ROS中动态切换不同形状的物体(含避坑指南) 在机器人开发过程中,RViz作为ROS生态中的三维可视化利器,其核心价值在于让抽象的数据变得直观可见。而Marker消息系统则是实现这种可视化的关键桥梁——它…...

Infiniband网络排错指南:从`ibstatus`异常到OpenSM日志分析,一次搞定常见连接问题
Infiniband网络排错实战:从基础诊断到高级调优的全链路指南 当40Gbps的Infiniband链路突然降速到10Gbps,或者关键节点的OpenSM服务频繁崩溃时,每个运维工程师都能体会到那种指尖发凉的焦虑。本文将带你穿越Infiniband故障迷雾,构建…...

手把手教学:用LongCat动物百变秀快速生成动物拟人化表情包和头像
手把手教学:用LongCat动物百变秀快速生成动物拟人化表情包和头像 1. 为什么选择LongCat动物百变秀 在当今社交媒体时代,个性化的动物表情包和头像已经成为网络交流的重要组成部分。LongCat动物百变秀是一款基于美团开源模型的本地化AI图像编辑工具&…...
Pixel Dream Workshop 算法原理浅析:从扩散模型到创意生成
Pixel Dream Workshop 算法原理浅析:从扩散模型到创意生成 1. 引言:理解扩散模型的价值 最近两年,扩散模型在图像生成领域掀起了一场革命。从最初的DALLE到Stable Diffusion,再到各种创意生成工具,这项技术正在改变我…...

OpenClaw技能分享:GLM-4.7-Flash驱动的邮件自动处理系统
OpenClaw技能分享:GLM-4.7-Flash驱动的邮件自动处理系统 1. 为什么需要自动化邮件处理 每天早晨打开邮箱,看到堆积如山的未读邮件总让人头皮发麻。作为一个小团队的负责人,我经常需要处理客户咨询、内部沟通、会议邀请等各种类型的邮件。最…...

C# : 引用类型都存在堆上吗
不完全是,这里要精确区分:引用类型的实例大多数存在堆上,但引用本身不一定在堆上。我们拆开来说:引用类型本身 vs 引用变量对象实例(类的实例)绝大多数情况下分配在 堆上由 垃圾回收器 管理生命周期引用变量…...

vLLM生产-解码分离架构:从概念到部署的吞吐优化实践
1. 为什么需要生产-解码分离架构 第一次部署大模型在线服务时,我盯着监控面板上的GPU利用率曲线直挠头——为什么计算单元总是间歇性满载又突然空闲?后来发现这是典型的Prefill-Decode耦合架构的弊端。就像餐厅里同一个厨师既要负责备菜(切配…...

SPIRAN ART SUMMONER优化指南:如何调整参数让生成的图片更符合预期
SPIRAN ART SUMMONER优化指南:如何调整参数让生成的图片更符合预期 1. 理解SPIRAN ART SUMMONER的核心参数 SPIRAN ART SUMMONER作为一款基于Flux.1-Dev模型的图像生成工具,其参数设置直接影响最终输出效果。与普通AI绘画工具不同,它融入了…...

5步实现Switch控制器PC全功能适配:从连接到精通的设备适配指南
5步实现Switch控制器PC全功能适配:从连接到精通的设备适配指南 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitc…...