Spark/Hive
Spark/Hive
- Hive 原理
- Spark with Hive
- SparkSession + Hive Metastore
- spark-sql CLI + Hive Metastore
- Beeline + Spark Thrift Server
- Hive on Spark
- Hive 擅长元数据管理
- Spark 擅长高效的分布式计算
Spark + Hive 集成 :
- Hive on Spark : Hive 用 Spark 作为底层的计算引擎时
- Spark with Hive : Spark 把 Hive 当元信息的管理工具
Hive 原理
Hive架构 , 可插拔的第 三方独立组件 :
- User Interface 提供 SQL 接入服务
- CLI 与 Web Interface 在本地接收 SQL 查询语句
- Hive Server 2 提供 JDBC/ODBC 客户端连接,从远程提交 SQL 查询请求
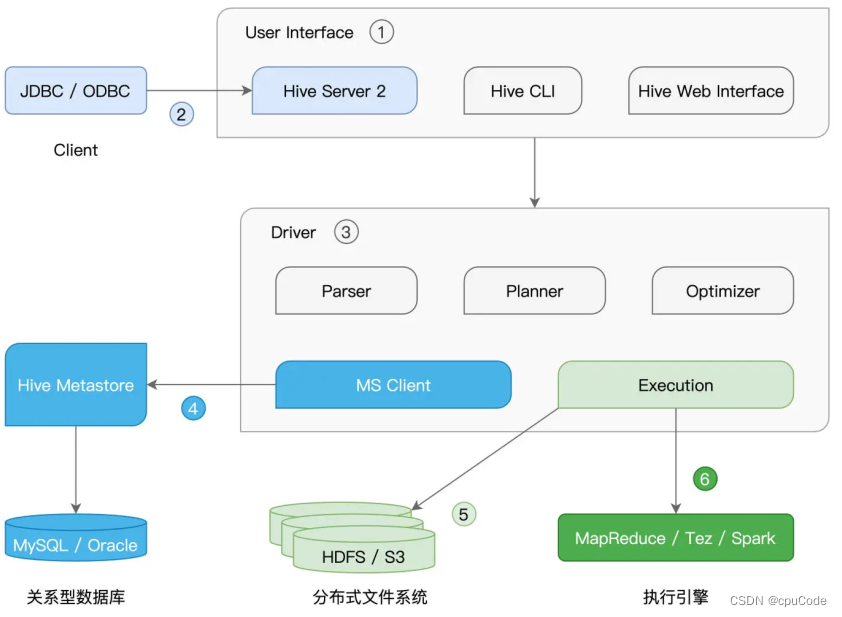
SQL 查询的工作过程 :
- 收到 SQL 后,Driver 先用 Parser ,将查询语句转化为 AST(Abstract Syntax Tree,查询语法树)
- Hive 从 Hive Metastore 拿表的元信息,如 : 表名、列名、字段类型、数据文件存储路径、文件格式
- Planner 根据 AST 生成执行计划
- Optimizer 优化执行计划
- Execution 提交执行计划
Spark with Hive
Spark with Hive 集成方式 :
- 创建 SparkSession,访问 Hive Metastore
- 通过 spark-sql CLI,访问本地 Hive Metastore
- 通过 Beeline,访问 Spark Thrift Server
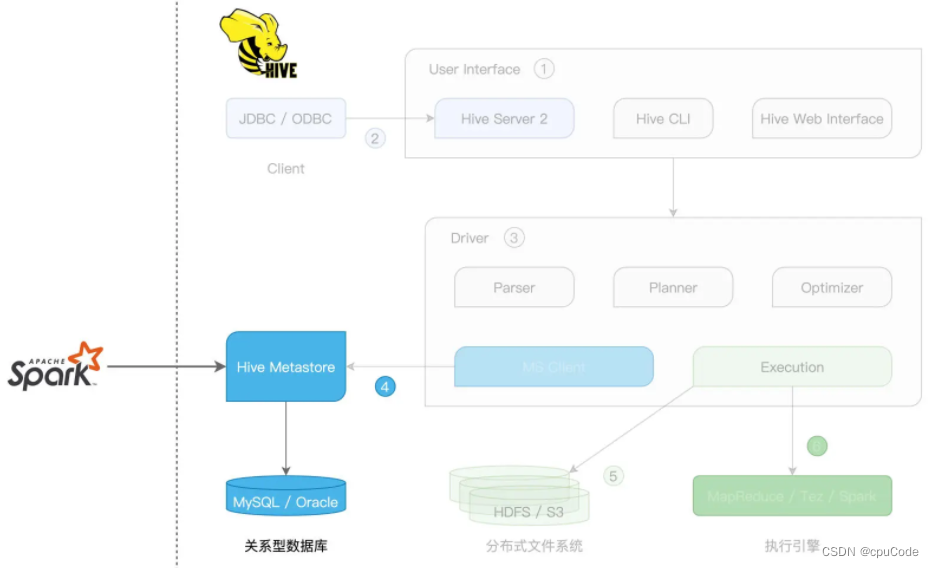
SparkSession + Hive Metastore
启动 Hive Metastore
hive --service metastore
Spark 拿 Metastore 访问地址的两种办法 :
- 创建 SparkSession 时,通过 config 指定
hive.metastore.uris - 把Hive的
hive-site.xml拷到 Spark 的 conf 下
spark-shell 下写代码 :
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrameval hiveHost: String = _// 创建SparkSession实例
val spark = SparkSession.builder().config("hive.metastore.uris", s"thrift://hiveHost:9083").enableHiveSupport().getOrCreate()// 读取Hive表,创建DataFrame
val df: DataFrame = spark.sql(“select * from salaries”)
df.show/** 结果打印
+---+------+
| id|salary|
+---+------+
| 1| 26000|
| 2| 30000|
| 4| 25000|
| 3| 20000|
+---+------+
*/
SparkSession + Hive Metastore 集成方式 :
- Spark 只涉及 Hive 的 Metastore
spark-sql CLI + Hive Metastore
spark-sql CLI 与 Hive Metastore 要在同个节点
- spark-sql CLI 只能访问 本地 Hive Metastore
Beeline + Spark Thrift Server
用 Beeline 客户端,连接 Spark Thrift Server,从而完成 Hive 表的访问与处理
Hive Server 2 (Hive Thrift Server 2) 采用 Thrift RPC 协议框架
Beeline + Spark Thrift Server 集成 :
- Spark Thrift Server 与 Hive Server 2 的实现逻辑一样。最大区别:SQL 查询接入后的解析、规划、优化与执行
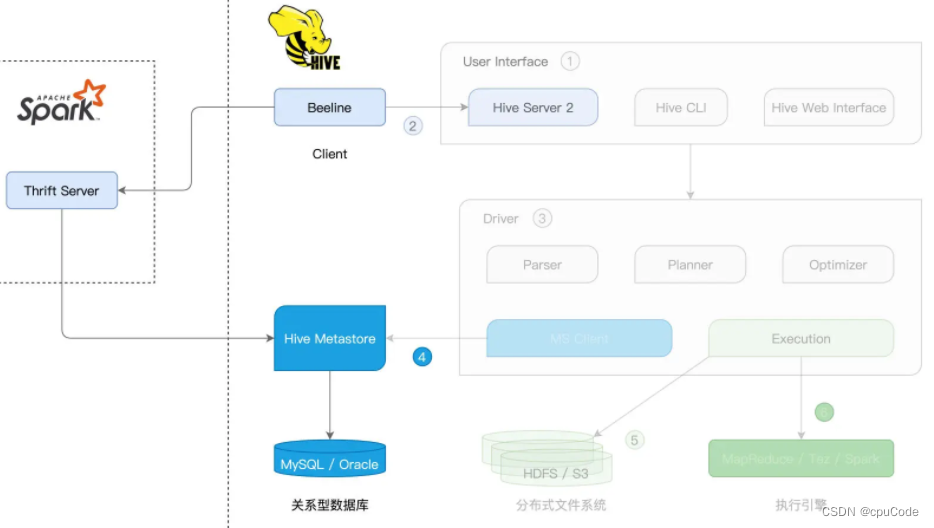
启动 Spark Thrift Server :
$SPARK_HOME/sbin/start-thriftserver.sh
Spark Thrift Server 启动后,在任意节点上通过 Beeline 就能访问该服务
beeline -u "jdbc:hive2://hostname:10000"
Hive on Spark
Hive on Spark :Hive 用 Spark 作为分布式执行引擎
- SQL 语句的解析、规划与优化都由 Hive 的 Driver 完成
- Hive on Spark 衔接的部分是 Spark Core
指定 Spark 执行引擎
set hive.execution.engine=spark
相关文章:
Spark/Hive
Spark/HiveHive 原理Spark with HiveSparkSession Hive Metastorespark-sql CLI Hive MetastoreBeeline Spark Thrift ServerHive on SparkHive 擅长元数据管理Spark 擅长高效的分布式计算 Spark Hive 集成 : Hive on Spark : Hive 用 Spark 作为底层的计算引擎时Spark w…...
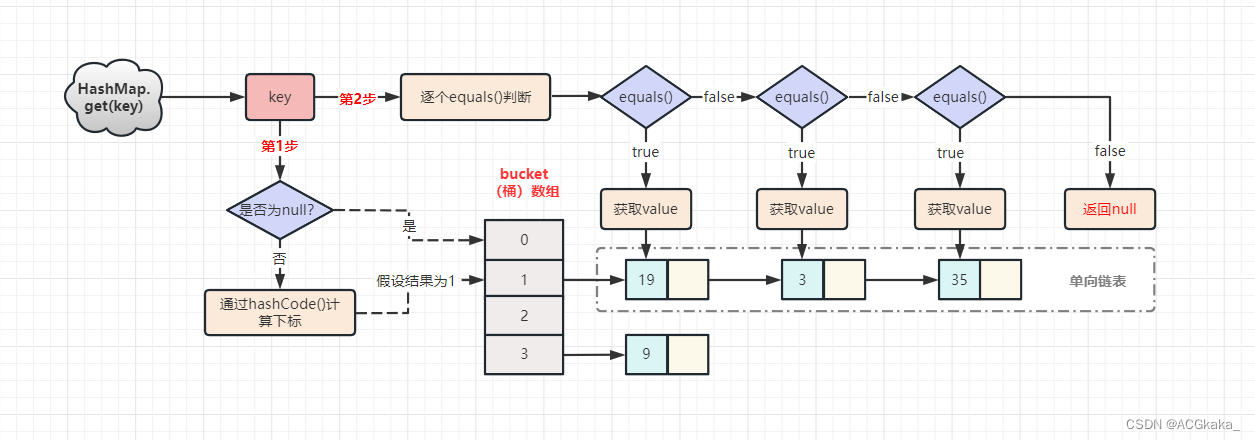
HashMap底层的实现原理(JDK8)
目录一、知识点回顾二、HashMap 的 put() 和 get() 的实现2.1 map.put(k, v) 实现原理2.2 map.get(k) 实现原理三、HashMap 的常见面试题3.1 为何随机增删、查询效率都很高?3.2 为什么放在 HashMap 集合 key 部分的元素需要重写 equals 方法?3.3 HashMap 的 key 为…...
操作系统-整理
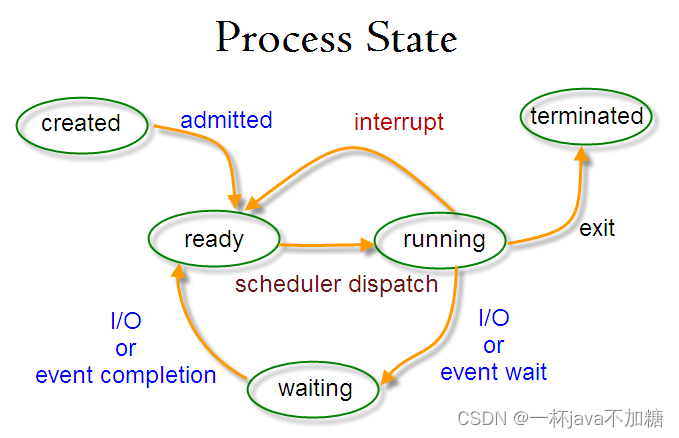
进程 介绍 进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大&#…...
系统换行符的思考
各系统换行符 换行符,也即是回车换行,因为表示为Carriage-Return和Line-Feed。 回车用Return-Carrige表示,简写为CR,字符表示为\r。 换行用Line-Feed表示,简写为LF,字符表示为\n。 由于历史原因…...
Wwise集成到unreal
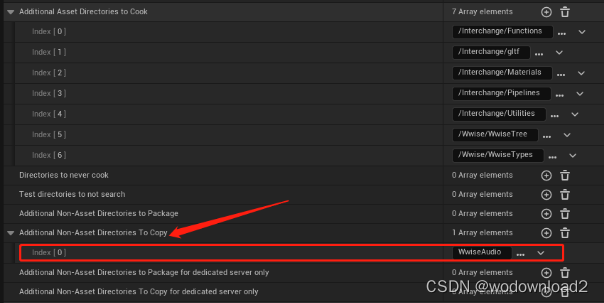
1、Wwise集成到Unreal 1.1 安装必要的软件 安装unreal 5.1;安装Audiokinetic Launcher;集成版本是Wwise 2021.1.12.7973。Audiokinetic Launcher下载地址: https://www.audiokinetic.com/zh/thank-you/launcher/windows/?refdownload&pl…...

前端秘籍之=>八股文经卷=>(原生Js篇)【持续更新中...】
大家好,最近想了想,打算总结归纳一版前端八股文经卷,给大家提供学习参考,如果帮助到大家,请大家,一键三连支持一下,你们的支持会激励我更加努力的更新更多有用的知识,博主先在这里谢…...
【Python安装配置教程】
Python由荷兰数学和计算机科学研究学会的吉多范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台…...

Spring-Retry失败重试
文章目录 重试的场景引入依赖启动类serviceController@Retryable参数@Recover注意事项重试的场景 1、网络波动需要,导致请求失败,需要重发。 2、发送消息失败,需要重发,重发失败要记录日志 … 引入依赖 <!-- spring-retry--> <dependency><groupId>or…...
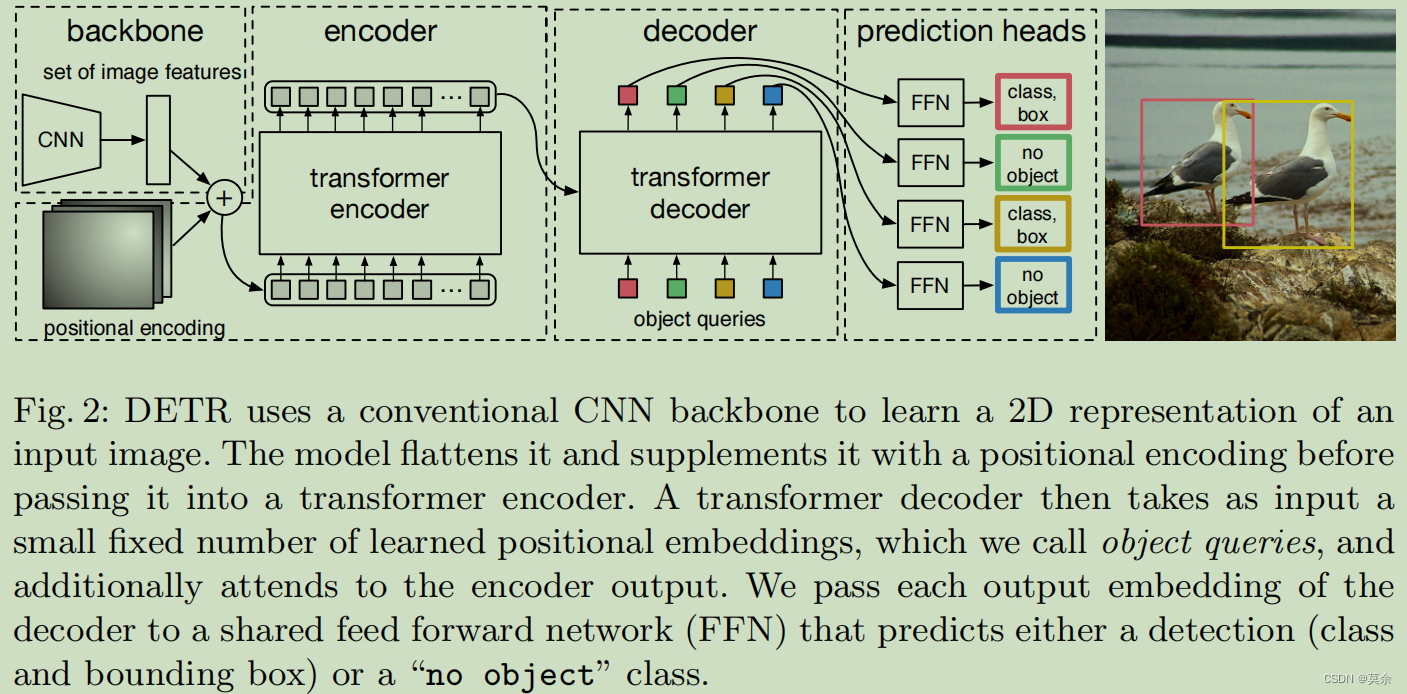
【目标检测 DETR】通俗理解 End-to-End Object Detection with Transformers,值得一品。
文章目录DETR1. 亮点工作1.1 E to E1.2 self-attention1.3 引入位置嵌入向量1.4 消除了候选框生成阶段2. Set Prediction2.1 N个对象2.2 Hungarian algorithm3. 实例剖析4. 代码4.1 配置文件4.1.1 数据集的类别数4.1.2 训练集和验证集的路径4.1.3 图片的大小4.1.4 训练时的批量…...

项目ER图和资料
常用的数据类型 模型类 一对多 from app import db import datetimeclass BaseModel(db.Model):__abstract__ Truecreate_time db.Column(db.DateTime,defaultdatetime.datetime.now())update_time db.Column(db.DateTime,defaultdatetime.datetime.now())class Role(db.M…...
)
剑指 Offer 20. 表示数值的字符串(java+python)
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。 数值(按顺序)可以分成以下几个部分: 若干空格 一个 小数 或者 整数 (可选)一个 ‘e’ 或 ‘E’ ,后面跟着一个 整数…...

程序员的逆向思维
前要: 为什么你读不懂面试官提问的真实意图,导致很难把问题回答到面试官心坎上? 为什么在面试结束时,你只知道问薪资待遇,不知道如何高质量反问? 作为一名程序员,思维和技能是我们职场生涯中最重要的两个方面。有时候…...
吐血整理学习方法,2年多功能测试成功进阶自动化测试,月薪23k+......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 测试进阶方向 测试进…...

mysql慢查询:pt-query-digest 分析
"某些SQL语句执行效率慢",这个问题总体上分为两类: 出现了慢查询语句某些查询语句没有使用索引 由于数据的写入量非常大,所以要想直接打开慢查询日志来查看到底哪些语句有问题几乎是不可能的,因为日志的刷新速度太快了…...

git的使用整合
git的下载和安装暂时不论述了,将git安装后会自动配置环境变量,所以环境变量也不需要配置。 一、初始化配置 打开git bash here(使用linux系统下运行的口令),弹出一个类似于cmd的窗口。 (1)配置属性 git config --glob…...

XCPC第九站———背包问题!
1.01背包问题 我们首先定义一个二维数组f,其中f[i][j]表示在前i个物品中取且总体积不超过j的取法中的最大价值。那么我们如何得到f[i][j]呢?我们运用递推的思想。由于第i个物品只有选和不选两种情况,当不选第i个物品时,f[i][j]f[i…...

【软考 系统架构设计师】论文范文④ 论基于构件的软件开发
>>回到总目录<< 文章目录 论基于构件的软件开发范文摘要正文论基于构件的软件开发 软件系统的复杂性不断增长、软件人员的频繁流动和软件行业的激烈竞争迫使软件企业提高软件质量、积累和固化知识财富,并尽可能地缩短软件产品的开发周期。 集软件复用、分布式对…...

spring-integration-redis中分布式锁RedisLockRegistry的使用
pom依赖:<!-- redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.integ…...
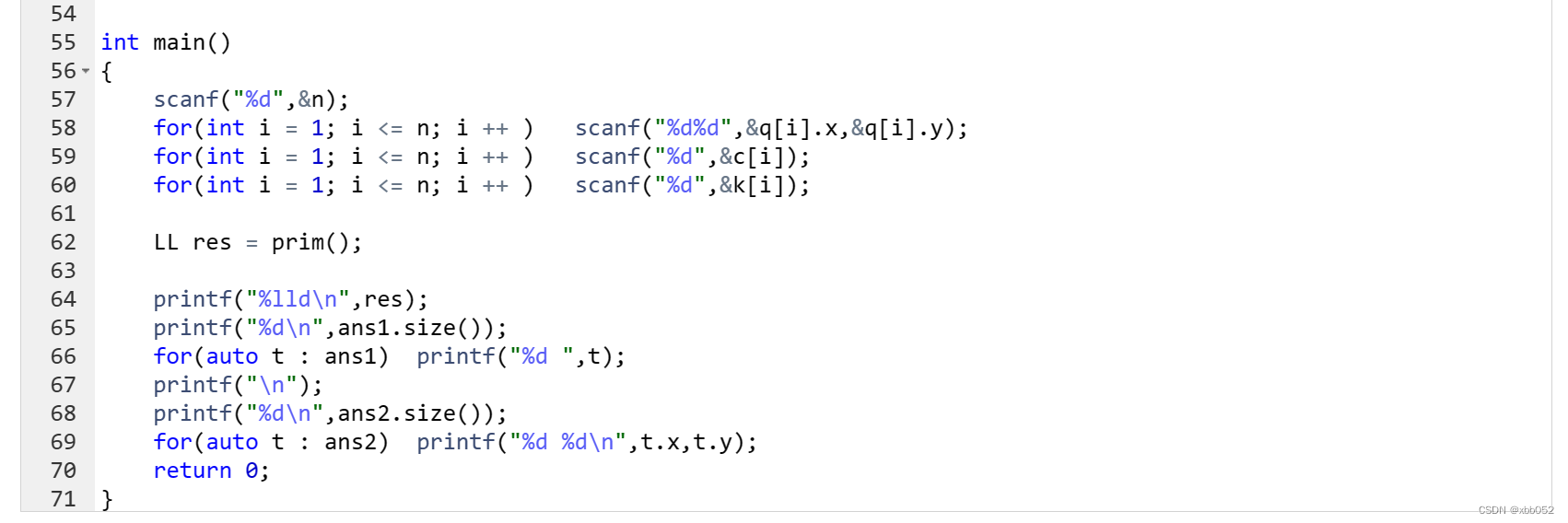
城市通电(prim算法)
acwing3728 蓝桥杯集训每日一题 平面上遍布着 n 座城市,编号 1∼n。 第 i 座城市的位置坐标为 (xi,yi) 不同城市的位置有可能重合。 现在要通过建立发电站和搭建电线的方式给每座城市都通电。 一个城市如果建有发电站,或者通过电线直接或间接的与建…...

【动态规划】
动态规划1引言题目509. 斐波那契数70. 爬楼梯746. 使用最小花费爬楼梯小结53. 最大子数组和结语引言 蓝桥杯快开始了啊,自从报名后还没认真学过算法有(>﹏<)′,临时抱一下佛脚,一起学学算法。 题目 509. 斐波那契数 斐波那契数 &am…...

ChatSVA:多智能体框架革新硬件验证中的SVA生成
1. ChatSVA:硬件验证领域的SVA生成革命在集成电路设计领域,功能验证已成为制约开发效率的最大瓶颈。据统计,现代芯片开发周期中超过50%的时间消耗在功能验证环节,而SystemVerilog断言(SVA)作为形式化验证和…...

基于深度学习的涂胶缺陷类型检测:数据集处理与YOLOv8模型实现
基于深度学习的涂胶缺陷类型检测:数据集处理与YOLOv8模型实现 摘要 涂胶工艺在智能制造中具有广泛的应用,尤其在汽车制造、新能源电池封装等领域,其质量直接关系到产品的密封性、绝缘性和结构可靠性。传统的涂胶缺陷检测依赖人工目检或规则式机器视觉方法,存在效率低、精…...
)
STM32F4 SPI DMA实战:用CubeMX和HAL库5分钟搞定高速数据传输(附避坑指南)
STM32F4 SPI DMA实战:CubeMXHAL库5分钟极速配置指南 在嵌入式开发中,SPIDMA的组合堪称数据传输的"黄金搭档"——既能享受SPI接口的高速特性,又能通过DMA解放CPU资源。但传统基于寄存器的手动配置方式,往往让开发者陷入繁…...

代码所有权的悖论:集体智慧与个人责任的边界
代码世界的身份迷局在软件测试的日常工作中,我们时常会陷入这样的困惑:当面对一行引发系统崩溃的代码时,究竟该追溯到最初编写它的开发者,还是问责于后续不断迭代维护的团队?当一个历经数十人之手、跨越数年周期的模块…...

模块化IC设计流程:应对复杂芯片挑战的解决方案
1. 现代IC设计面临的挑战与模块化流程的价值在当今半导体行业,芯片设计团队正面临前所未有的复杂挑战。随着工艺节点不断演进至5nm及以下,设计复杂度呈指数级增长。我曾参与的一个65nm SoC项目,团队最初采用传统线性设计流程,结果…...

RISC-V汽车电子开发:功能安全认证工具链的挑战与实践
1. 项目概述:RISC-V在汽车领域的破局与挑战最近和几个在主机厂和Tier 1做嵌入式开发的老朋友聊天,话题总绕不开芯片选型和开发工具。大家普遍的感觉是,传统的Arm架构虽然生态成熟,但在追求极致能效比和定制化的今天,成…...

对象变更记录objectlog工具
文章目录前言演示代码演示环境引入项目项目框架操作步骤设计介绍参考仓库前言 系统基于mybatis-plus, springboot环境 对于重要的一些数据,我们需要记录一条记录的所有版本变化过程,做到持续追踪,为后续问题追踪提供思路。下面展示预期效果(根…...

Unity美术资源导入避坑指南:从‘2的N次方’到‘ASTC压缩’,搞懂这些让你的游戏包体瘦身50%
Unity移动端美术资源优化实战:从纹理规范到跨平台压缩策略 移动游戏开发中,美术资源往往占据包体大小的70%以上。上周团队刚把一个150MB的Demo压缩到89MB,关键就在于纹理资源的规范处理。不同GPU架构对纹理格式的解析差异,可能导致…...

从SMP到NUMA:聊聊多核CPU时代Linux内存管理是怎么‘进化’的
从SMP到NUMA:多核CPU时代的内存管理演进之路 2000年代初,当单核CPU的主频竞赛逐渐触及物理极限时,计算机架构师们面临一个关键抉择:如何在芯片上堆叠更多晶体管?答案最终指向了多核设计。但随之而来的内存访问瓶颈&…...

LangGraph、OpenClaw、Hermes:三种 Agent 路线,不是一回事
开头 这两年,只要聊到 Agent,绕不开三个名字:LangGraph、OpenClaw、Hermes。 它们都很火。 但也很容易被混在一起。 有人把 LangGraph 当成一个“Agent 产品”。 有人把 OpenClaw 当成一个“Agent 框架”。 也有人把 Hermes 理解成“另…...