HiveSQL基础Day03
回顾总结
hive表的类型 :内部表和外部表
删除内部表会删除表的所有数据
删除外部表只会删除表的元数据,hdfs上的行数据会保留
表的分区和分桶
本质都是对表数据的拆分存储
分区的方式 是通过创建不同的目录来拆分数据 ,根据数据本身的内容最为目录名
分桶的方式 是通过创建不同的文件来拆分数据 文件名时hash取余的名字
数据拆分后可以提升数据的查询效率
分桶还有特殊使用场景
分桶关联多张表
分桶随机采样
序列化
本质就是对hdfs上的文件数据进行读取和写入
可以通过row format delimited fields terminated by ',' 指定如何读取和写入hdfs上的字段数据
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name(col_name data_type [COMMENT col_comment])[COMMENT table_comment]hive中的独有语法-- 分区字段指定,分区字段是不能表字段重复[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]-- 分桶字段,需要指定表中存在的字段[CLUSTERED BY (col_name, col_name, ...) INTO num_buckets BUCKETS] -- 指定分割符 默认的字段分割符\001[ROW FORMAT row_format] -- 指定表的存储目录位置 不指定默认是在对应的数据库目录下创建表目录[LOCATION hdfs_path]
一、内置函数
内置函数时hive中自带的函数方法,用来对不同类型的字段数据进行操作
字符串,数值,条件判断
字符串方法
length concat concat_ws substr split regexp_replace% round() ceil() floor()if() case when 条件1 then 结果when 条件2 then 结果when 条件3 then 结果else前面条件都不成返回的结果 end 字段名称-- 查看hive中的所有内置函数 show functions; -- 查看函数的具体用户 desc function extended 函数名;
1-1 日期类型操作
-- 获取当前日期
select `current_date`();
-- 获取当前日期时间
select `current_timestamp`();
-- 获取unix时间(时间戳) 从1970年1月1号0时0分0秒 到现在过去了多少秒
select unix_timestamp();
-- unix时间 和日期时间的转化
-- 日期时间转为unix
select unix_timestamp('2023-10-01 15:30:28');
-- 将unix时间转为日期时间
select from_unixtime(12390886789);
-- 年月日的取值
select year('2023-10-01 15:30:28');
select month('2023-10-01 15:30:28');
select day('2023-10-01 15:30:28');
select dayofmonth('2023-10-12 15:30:28');
select dayofweek('2023-10-12 15:30:28');
select hour('2023-10-12 15:30:28');
select minute('2023-10-12 15:30:28');
select second('2023-10-12 15:30:28');
-- 时间加减
select date_add('2023-10-12 15:30:28',5);
select date_add('2023-10-12 15:30:28',-5);
-- 比较时间相差多少天
select datediff(`current_date`(),'2023-10-12');
1-2 类型转化
-- 字段类型不符合计算需求,可以进行类型转化
-- 隐式转化 hive会自动判断进行转化数据然后计算
select '123'+'456';
-- 手动指定转化
select cast('123' as int) + cast('456' as int);
select * from itcast.tb_hero;
desc itcast.tb_hero;
-- 转化只是在计算时进行,并不会改变字段本身类型
select cast(blood as bigint) from itcast.tb_hero;
1-3 字符串数据转json,array,map操作
-
josn字符串操作
-
数据是一个 "{key:value}" 格式
-
使用方法取值value
-
create table tb_order_detail(json_field string ); select * from tb_order_detail; -- 对字段中的json字符串数据进行取值,按照key取value值 -- 方法一 get_json_object 每次只能取一个字段数据 ,可以向下一直取值 selectget_json_object(json_field,'$.orderid') as orderid,get_json_object(json_field,'$.total_price') as total_price,get_json_object(json_field,'$.total_num') as total_num,get_json_object(json_field,'$.goods') as goods,get_json_object(json_field,'$.goods[0]') as good1,get_json_object(json_field,'$.goods[0].name') as good1_name,get_json_object(json_field,'$.goods[1]') as good2 from tb_order_detail; -- json_tuple 一次取多个字段值,不能对嵌套数据往下取值 select json_tuple(json_field,'orderid','total_price','total_num','goods') as(orderid,total_price,total_num,goods) from tb_order_detail
将字符串数据切割转为数组数据
create table tb_user(id int,name string,hobby string )row format delimited fields terminated by ','; select id,name,split(hobby,'-') from tb_user;
将字符串数据切割转为map数据
-- 使用map方法
select `map`('name','张三','age',29);
create table tb_hero(id int,name string,blood int,skin string
)row format delimited fields terminated by ',';
-- 西部大镖客:288-大圣娶亲:888-全息碎片:0-至尊宝:888-地狱火:1688 --> {'西部大镖客':288,'大圣娶亲':88}
select id,name,blood,map(split(split(skin,'-')[0],":")[0], cast(split(split(skin,'-')[0],":")[1] as int),split(split(skin,'-')[1],":")[0],cast(split(split(skin,'-')[1],":")[1] as int))from tb_hero;
mysql中的内置函数操作
select concat(name,sex) from member;
select concat_ws(',',name,sex) from member;
select substr(s_birth,1,4) from student;
select replace(s_birth,'-','/') from student;
select round(3.1421,2);
select round(3.123);
select pow(2,3);
select current_timestamp;
select current_date;
select unix_timestamp();
select unix_timestamp('2023-10-10 10:10:10');
select from_unixtime(127381923);
select date_add('2023-10-10 10:10:10',interval 1 day);
select date_add('2023-10-10 10:10:10',interval 1 month );
select date_add('2023-10-10 10:10:10',interval 1 year );
select date_add('2023-10-10 10:10:10',interval -1 year );
select date_add('2023-10-10 10:10:10',interval -1 hour );
select timestampdiff(year ,'2020-02-02','2023-02-02');
select timestampdiff(month ,'2020-02-02','2023-02-02');
select timestampdiff(day ,'2020-02-02','2023-02-02');
select timestampdiff(hour ,'2020-02-02 16:23:12','2023-02-02 15:12:12');
select if(s_sex='男',1,2),s_sex from student;
select *,casewhen year(s_birth) between 1980 and 1989 then '80后'when year(s_birth) between 1990 and 1999 then '90后'end
from student;
二、DQL的查询计算(掌握)
对表进行查询计算
select 字段 from 表; select 字段1,字段2,字段3,常量值,内置函数计算 from tb
2-1 单表查询计算
where 的条件过滤
select 字段1,字段2,字段3,常量值,内置函数计算 from tb where 过滤条件
过滤条件,条件成立的将对的行数据返回
-
比较大小
-
字段 = 数值 判断字段和数值是否相等
-
字段 > 数值
-
字段 < 数值
-
字段 >= 数值
-
字段 <= 数值
-
字段 != 数值
-
-- 大小比较 -- 年龄大于19岁 select * from tb_stu where age >19; -- 查询性别为女性的学生信息 select * from tb_stu where gender='女'; -- 查询学科不是IS的学生信息 select * from tb_stu where cls !='IS';
-
判断空值
-
字段 is null 字段为空
-
字段 is not null
-
-- 空值判断 insert into tb_stu values(9023,null,'男',20,'MA'); select * from tb_stu where name is not null; select * from tb_stu where name is null; select * from tb_stu where name !=''; -- 空字符过滤是会将null值一起过滤掉 select * from tb_stu where name =''; -- 相等判断是,空字符是不会过滤出null值的
-
范围判断
-
字段 between 数值1 and 数值2
-
字段 >=数值 and 字段 <=数值
-
-
字段 in (数值1,数值2....) 字段的值等于任意一个值就返回结果
-
-- 范围判断 select * from tb_stu where age between 20 and 25; select * from tb_stu where age in(19,22); select * from tb_stu where age not in(19,22);
-
模糊查询
-
字段 like '% _ 数据' % 可以匹配任意多个 _ 匹配任意一个字符
-
字段 rlink '正则表达式'
-
create table tb_stu2(id int,name string,gender string,age int,cls string,email string
)row format delimited fields terminated by ',';
select * from tb_stu2;
-- like的模糊查询
-- 查询姓名为刘的学生
select * from tb_stu where name like '刘%'; -- % 代表任意多个字符
-- 查询姓名为刘的学生 名字个数时2个字的
select * from tb_stu where name like '刘_';
select * from tb_stu where name like '刘__'; -- 查询三个字的
-- rlike 的正则表达式
-- 表的是就是通过不同的符号来表示不同的数据进行匹配
-- \\d 匹配数据的表达式 \\w 匹配字符字母 \\s 匹配空格
select * from tb_stu2;
-- ^ 表是什么开头
select * from tb_stu2 where email rlike '^\\d'; -- 表是以数字开头
select * from tb_stu2 where email rlike '^\\w';
select * from tb_stu2 where email rlike '^\\S';
-- ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$
select email,split(email,'@')[1] from tb_stu2;
select email,split(split(email,'@')[1],'\\.')[0] from tb_stu2;
-
与或非
-
条件1 and 条件2 and 条件3 ... 多个条件都成立,返回对应的行数据
-
条件1 or 条件2 or 条件3 ... 多个条件满足任意一个,返回对应的行数据
-
-- 与 多个条件都成立 select * from tb_stu; -- 查询性别为男性,学科是is的 select * from tb_stu where gender='男' and cls = 'IS'; -- 查询性别为男性或学科是is的 select * from tb_stu where gender='男' or cls = 'IS';
聚合计算 sum,count
select * from tb_stu; select sum(age) from tb_stu2; select count(*) from tb_stu where name is not null; select avg(age) from tb_stu2; select max(age) from tb_stu; select min(age) from tb_stu;
分组聚合 group by
select sum(age) from tb_stu group by gender; select sum(age),gender from tb_stu group by gender;
注意分组后,select 中不能出现非分组字段
分组后过滤 having
select sum(age),gender from tb_stu group by gender having sum(age)> 200;
排序
order by 全局排序
select * from tb_stu order by age; -- 默认是升序 从小到大 select * from tb_stu order by age desc ; -- 降序 从大到小
分页 limit
-- 分页 select * from tb_stu limit 5; select * from tb_stu limit 10,5; -- 页数 m 每页数量是n (m-1)*n,n
2-2 多表关联查询
join的列关联
-
内关联
-
找关联字段相同的数据
-
-
左关联
-
展示保留左边表的所有数据,右边表有相同数据显示,没有相同数据则为null
-
-
右关联
-
展示保留右边表的所有数据,左边表有相同数据显示,没有相同数据则为null
-
-- table1: 员工表 CREATE TABLE employee(id int,name string,deg string,salary int,dept string) row format delimited fields terminated by ','; -- table2:员工家庭住址信息表 CREATE TABLE employee_address (id int,hno string,street string,city string ) row format delimited fields terminated by ','; -- table3:员工联系方式信息表 CREATE TABLE employee_connection (id int,phno string,email string ) row format delimited fields terminated by ',';
-- on 当成where使用,进行条件顾虑 select * from employee t1 join employee_address t2 on t1.id = t2.id and salary> 30000; select * from employee t1 left join employee_address t2 on t1.id = t2.id; select * from employee t1 right join employee_address t2 on t1.id = t2.id; -- 实现内关联的效果 select * from employee,employee_address where employee.id = employee_address.id;
union的行关联
将select查询计算后的结果表合并
-- union合并 select 'tb_stu',count(*) from tb_stu where name is not null union select 'tb_stu2', count(*) from tb_stu2 where name is not null;-- 保留重复数据 select id,name from tb_stu union all select id,name from tb_stu2;
三、窗口聚合
默认没有窗口函数进行计算时全表数据获取计算
根据指定的窗口范围计算数据,将计算结果单独呈现一列展示,不会因为聚合改变行数
聚合使用,取值函数,排序函数 over(partition by 分组字段 order by 排序字段 rows between 起始行 and 结束行) rows 指定计算的行范围
3-1 聚合窗口
-- 按照性别分组统计年龄和 select sid,sname,age,gander,province,tuition,sum(age) over(partition by gander) from stu; select sid,sname,age,gander,province,tuition,sum(age) over(partition by province,gander) from stu; -- order by 排序后会将前面的数据进行累加 select sid,sname,age,gander,province,tuition,sum(tuition) over(partition by gander order by age) from stu; select sid,sname,age,gander,province,tuition,avg(tuition) over(partition by gander order by age) from stu;
3-2 取值窗口
-- 向上一行取值 select empno,ename,lag(ename) over() from emp; -- 向上两行行取值 select empno,ename,lag(ename,2) over() from emp; -- 去不到值给默认值 select empno,ename,lag(ename,2,'itcast') over() from emp; -- 向下一行取值 select empno,ename,lead(ename) over() from emp; -- 向下两行行取值 select empno,ename,lead(ename,2) over() from emp; -- 去不到值给默认值 select empno,ename,lead(ename,2,'itcast') over() from emp;-- 分组后只进行组内查找 select *,lag(ename) over(partition by job) from emp;-- 取第一个值 select *,first_value(ename)over(partition by job order by sal desc ) from emp;
3-3 排序窗口
按照指定字段排序后生成序号
-- 排序 select *,rank() over (order by sal) as rnk, -- 如果有并列生成序号是不连续的dense_rank() over (order by sal) as dernk, -- 生成连续序号row_number() over (order by sal) as rw -- 生成行号 from emp;-- 查找薪资前三 select * from ( select *,dense_rank() over (order by sal desc ) as dernk -- 生成连续序号 from emp) tb1 where dernk <=3;
相关文章:

HiveSQL基础Day03
回顾总结 hive表的类型 :内部表和外部表 删除内部表会删除表的所有数据 删除外部表只会删除表的元数据,hdfs上的行数据会保留 表的分区和分桶 本质都是对表数据的拆分存储 分区的方式 是通过创建不同的目录来拆分数据 ,根据数据本身的内容最为…...

houdini 学习过程
1.基础界面操作了解 当初通过 朱峰上的界面 工具栏操作入门的,现在B站上应该也比较多 houdini pdf早期的 2.节点操作 B站视频 教程 3.vex B站捷佳 4.BILIBILI ENTAGMA CGWIKI YOUTUBE 5.节点功能的深入,属性了解,或其它节点扩充 常用&…...
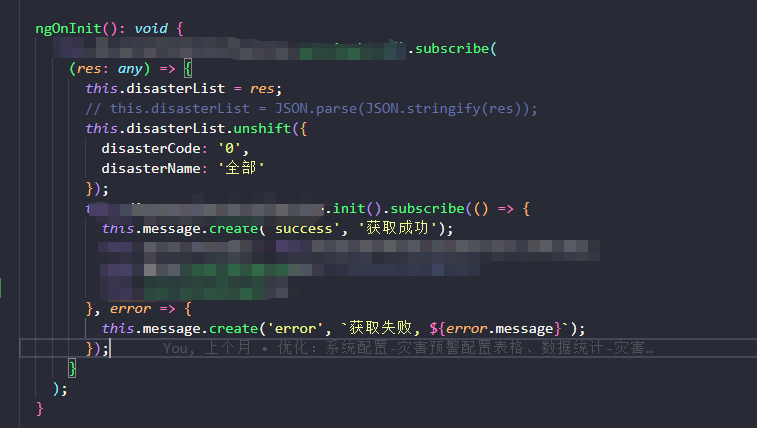
Angular学习第四天--问题记录及父子组件问题
问题一、 拉取完项目,使用npm install命令的时候遇到的。 解决办法: 在查找网上五花八门的解决方案之后,发现都不能解决。 我的解决办法是: 1. 把package-lock.json给删掉; 2. 把package.json中公司自己库的包给删除掉…...
如何拿捏2024年的B端设计?(附工具推荐)
伴随着2019年前的互联网人口红利时代结束,科技行业的基本面发生了巨大的变化,以普通消费者为目标的C端需求大幅萎缩,面向企业的B端需求成为行业热点。 在2024年的今天,设计师应该如何理解B端设计的实质,并真正驾驭B端产…...

【蓝桥杯】2024年第15届真题题目
试题 A: 握手问题 本题总分: 5 分 【问题描述】 小蓝组织了一场算法交流会议,总共有 50 人参加了本次会议。在会议上, 大家进行了握手交流。按照惯例他们每个人都要与除自己以外的其他所有人进 行一次握手(且仅有一次&a…...
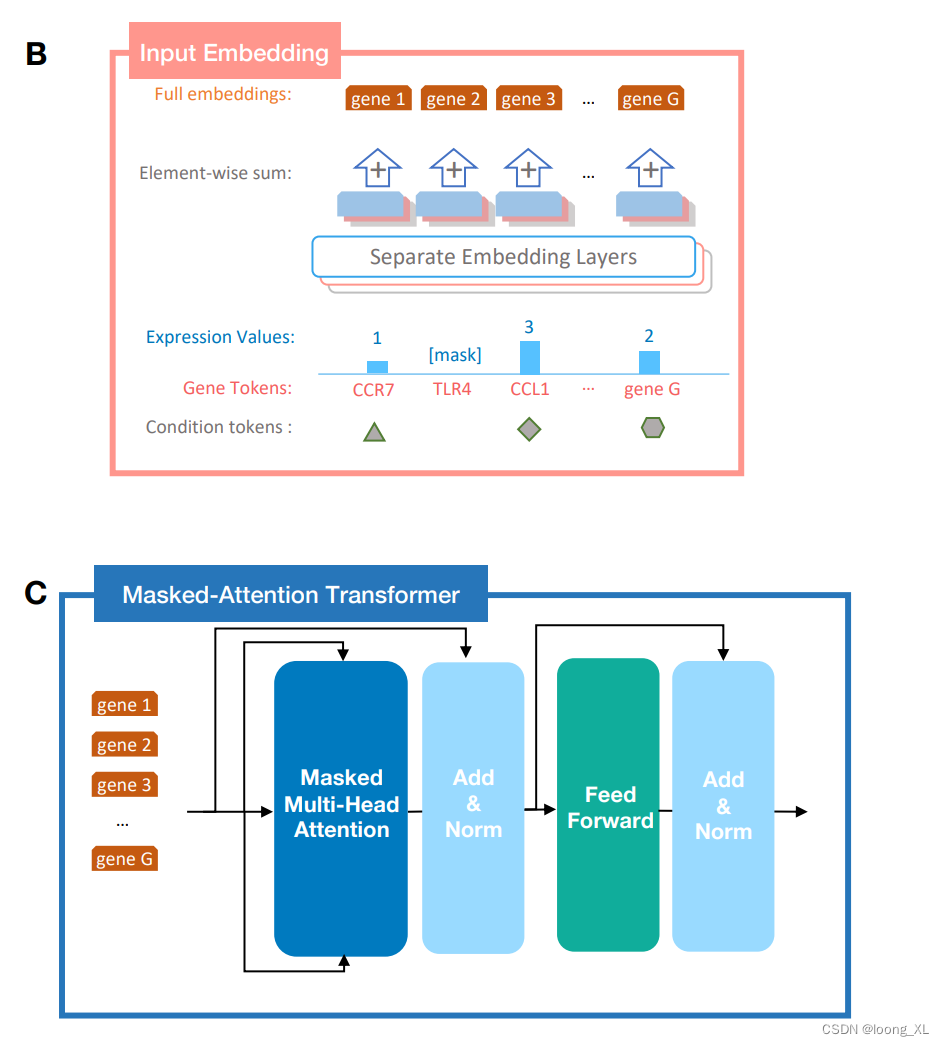
LLM生成模型在生物单细胞single cell的应用:scGPT
参考: https://github.com/bowang-lab/scGPT https://www.youtube.com/watch?vXhwYlgEeQAs 相关算法: 主要是把单细胞测序出来的基因表达量的拼接起来构建成的序列,这里不是用的基因的ATCG,是直接用的基因名称 训练数据&#x…...

力扣15题. 三数之和
题目: 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复…...

项目经理好还是产品经理好?入行必读!
在现代项目管理领域,产品经理Product Manager和项目经理Project Manager,两者虽都是PM,但两者在实际操作中却有着显著的区别,在各自的领域中承担着不同的岗位职责和工作。 项目经理跟产品经理两个证都挺受市场欢迎的,…...
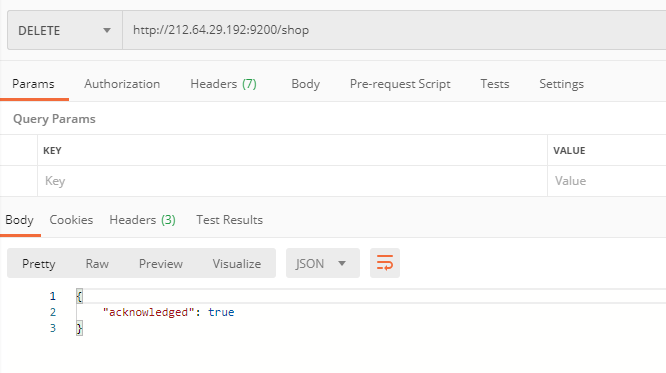
Elastic安装后 postman对elasticsearch进行测试
一、创建索引和mapping //id 字段自增id //good_sn 商品SKU //good_name 商品名称 //good_introduction 商品简介 //good_descript 商品详情 PUT http://IP:9200/shop { "mappings":{ "good":{ "properties":{ …...

JPA (Java Persistence API)
一、Jpa的介绍 JPA ,是一套Sun公司Java官方制定的ORM 规范。 ORM,即 对象关系映射 (Object Relational Mapping),是一种程序技术,用于 在关系数据库和业务实体对象之间做映射 。ORM 框架的存在,…...

实战要求下,如何做好资产安全信息管理
文章目录 一、资产安全信息管理的重要性二、资产安全信息管理的痛点三、如何做好资产安全信息管理1、提升资产安全信息自动化、集约化管理能力,做到资产全过程管理2、做好资产的安全风险识别3、做好互联网暴露面的测绘与管空4、做好资产安全信息的动态稽核管理 “摸…...
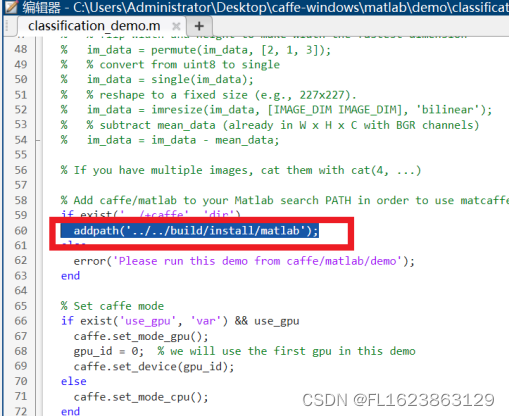
[matlab]matcaffe在matlab2023a安装和配置过程
测试环境: caffe-windows-cpu-py35-matlab2018b-vs2015-20220321 matlab2023a 注意:由于matlab新版本不允许添加特殊目录,比如有和private目录,添加后也会警告,但是可以忽略。因此可以使用我研发的matlab环境添加工具…...

【word2pdf】Springboot word转pdf(自学使用)
文章目录 概要整体介绍具体实现官网pom文件增加依赖 遇到的问题本地运行OK,发布到Linux报错还是本地OK,但是Linux能运行的,但是中文乱码 小结 概要 Springboot word 转 pdf 整体介绍 搜了一下,发现了能实现功能的方法有四种 U…...
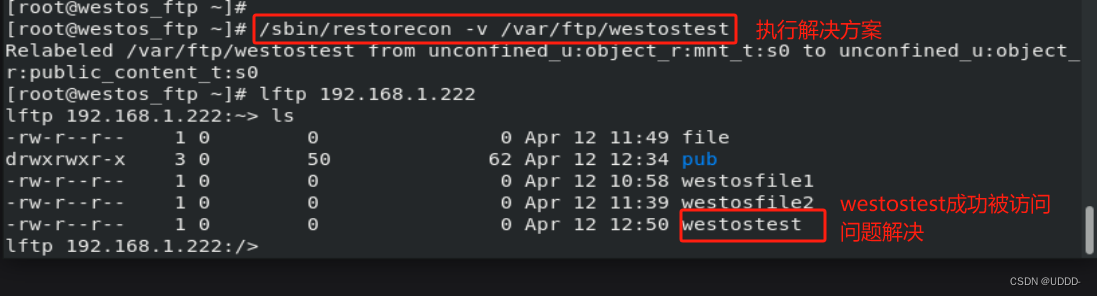
3_2Linux中内核级加强型火墙的管理
### 一.Selinux的功能 ### 观察现象 ①当Selinux未开启时 在/mnt中建立文件被移动到/var/ftp下可以被vsftpd服务访问 匿名用户可以通过设置后上传文件 当使用ls -Z /var/ftp查看文件时显示"?" ps auxZ | grep vsftpd 时显示: - root 8546 0.0 0.0 26952 …...

PCB工艺规范及PCB设计安规原则
一、目的 规范产品的PCB工艺设计,规定PCB工艺设计的相关参数,使得PCB的设计满足可生产性、可测试性、安规、EMC、EMI等的技术规范要求,在产品设计过程中构建产品的工艺、技术、质量、成本优势。 二、适用范围 本规范适用于所有电了产品的PCB工…...
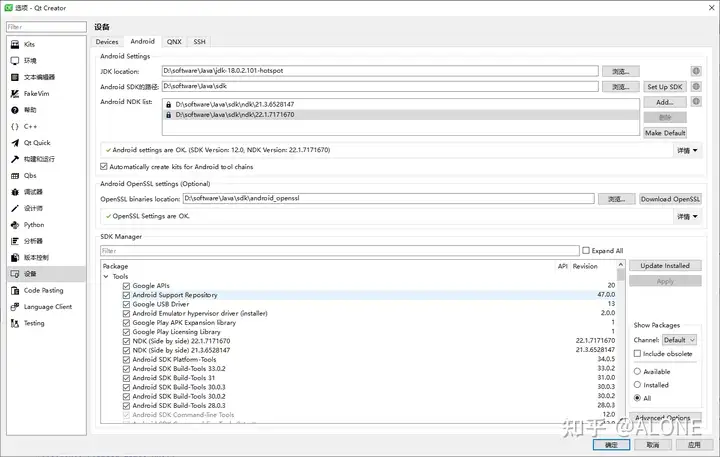
Qt for Android 开发环境
在搭建环境时开始感觉还挺顺利的,从 Qt 配置的环境里面看并没有什么问题,可真正编译程序的时候发现全是错误。 最开始的时候安装了 JDK21 最新版本,然后根据 JDK21 安装 ndk, build-tools, Platform-Tools 和 Gradle,但是不管这么…...
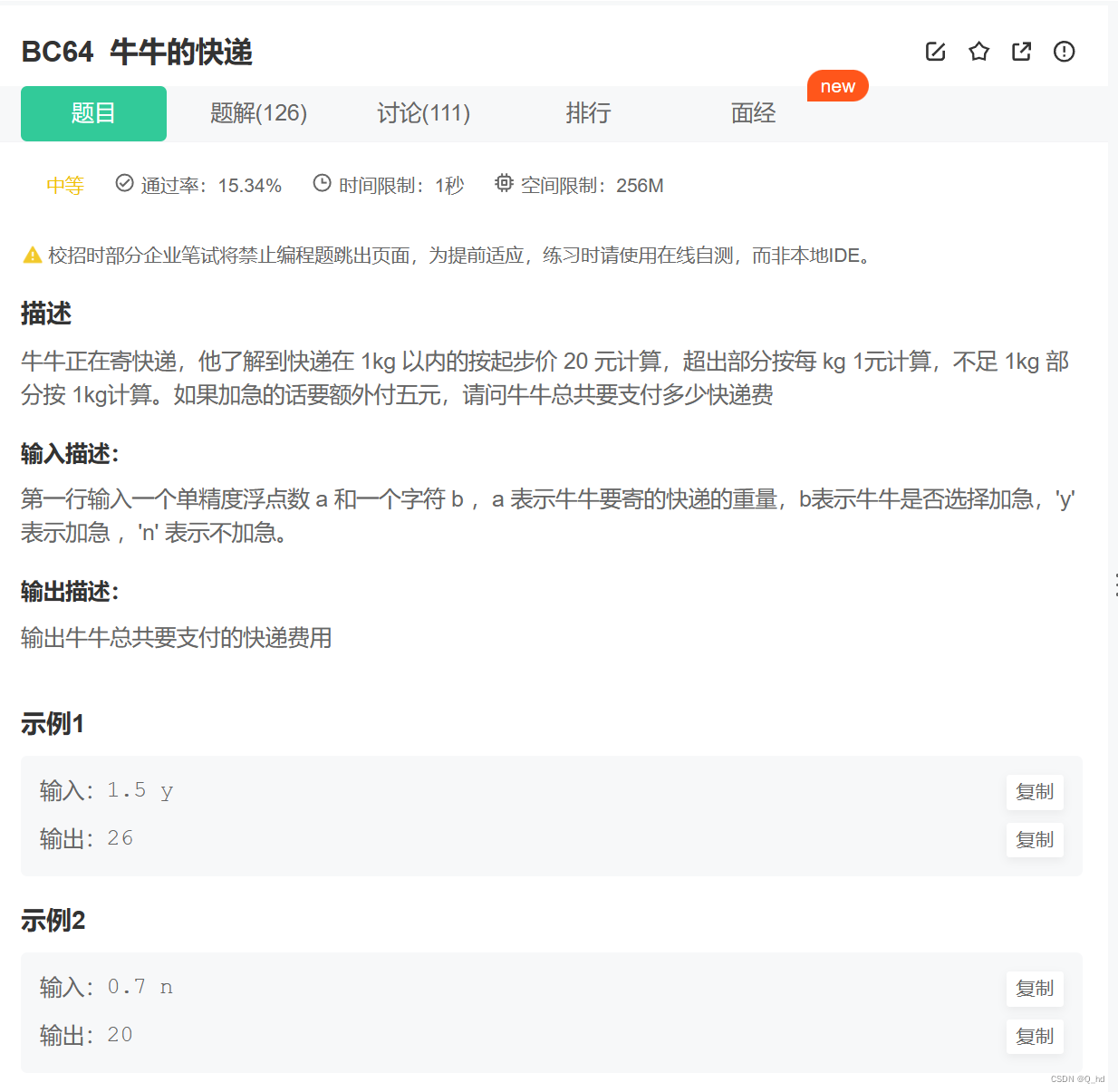
【题解】BC64 牛牛的快递(C++)
#include <iostream> #include<string> #include<math.h> using namespace std;int main() {int c0;string b;float a;cin>>a>>b;if(a>1)c20ceil(a-1);elsec20;if(b"y")c5;cout<<c; }在C中,ceil() 函数用于返回大…...

C++(运算符重载+赋值拷贝函数+日期类的书写)
目录 运算符重载运算赋值重载和运算赋重载前置和后置<,<,>,>,,!运算符重载日期类的实现<<流插入和>>流提取的运算符重载总结 运算符重载 C为了增强代码的可读性引入了运算符重载,运算符重载是具有特殊函数名的函数,也具有其 返回…...

【介绍下负载均衡原理及算法】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

CESS 受邀出席香港Web3.0标准化协会第一次理事会议,共商行业未来
2024 年 4 月 5 日,CESS(Cumulus Encrypted Storage System)作为香港 Web3.0 标准化协会的副理事会成员,于香港出席了 2024 年度第一次理事会会议。此次会议汇聚了来自不同领域的知名企业和专家(参会代表名单见文末&am…...

告别Let‘s Encrypt:用开源XCA构建私有CA,签发全站浏览器信任的SSL证书
1. 为什么你需要私有CA? 每次看到浏览器里那个"不安全"的红色警告,我就浑身难受。以前我也和大家一样用Lets Encrypt,直到有次紧急发布时遇到证书续期失败,整个团队熬夜排查到凌晨三点。从那天起,我就开始研…...
)
NotebookLM无法识别PDF表格?手把手复现Google Research 2024最新LayoutParser适配方案(附可运行Colab脚本)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM无法识别PDF表格?手把手复现Google Research 2024最新LayoutParser适配方案(附可运行Colab脚本) NotebookLM 默认使用轻量级 PDF 解析器(如 Py…...

AI辅助编程工具Cursor在经济学研究中的应用与实战指南
1. 从零开始:为什么经济学家需要AI辅助编程工具 如果你是一名经济学研究者、研究生或者研究助理,我猜你肯定经历过这样的场景:为了清洗一份来自世界银行或国家统计局的复杂面板数据,你对着Stata或者R的代码文档反复调试࿰…...

从零开始使用Taotoken CLI工具一键配置多款开发环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始使用Taotoken CLI工具一键配置多款开发环境 对于需要接入多个大模型服务的开发者而言,管理不同项目的API密钥、…...

为什么你的Windows桌面总是乱糟糟?NoFences免费桌面分区终极解决方案
为什么你的Windows桌面总是乱糟糟?NoFences免费桌面分区终极解决方案 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱无章的桌面图标而烦恼吗ÿ…...

Android Studio报错救星:一招永久优化Gradle下载,告别‘Could not install’
Android Studio开发环境深度优化:根治Gradle下载问题的系统方案 每次新建Android项目时,看着进度条卡在"Downloading Gradle"动弹不得,你是否也经历过这种绝望?Gradle下载失败堪称Android开发者入门的第一道坎ÿ…...
 函数)
C语言(8) 函数
第五章 函数一段功能代码,被称为函数1. 为了避免代码的重复。 复用性。 开发不用从头开始(库函数)。 2. 模块化的思想 。 大问题,分解成小问题,逐个解决。 设计函数 ,高内聚,低耦合。 功能越单一越好 ,对外…...

网页布局基石----盒子模型
目录 一:盒模型的构成 二:盒模型的核心属性 三:标准盒子模型代码实例 CSS控制网页样式是通过盒子模型去实现的,日常中我们所看到的网页上所以标签都可以视为一个盒子。所以网页都是放在盒子里面的。因此,我们首先要…...

LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换
LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为学术论文中复杂的数…...

从RNN的“失忆症”到LSTM的“记忆宫殿”:图解三个门控单元如何拯救梯度消失
从RNN的"失忆症"到LSTM的"记忆宫殿":图解三个门控单元如何拯救梯度消失 想象一下,你正在阅读一本精彩的小说,但每翻过一页就会忘记前一页的大部分内容——这就是标准RNN神经网络面临的困境。在自然语言处理和时间序列分析…...