笔记本电脑上的聊天机器人: 在英特尔 Meteor Lake 上运行 Phi-2

对应于其强大的能力,大语言模型 (LLM) 需要强大的算力支撑,而个人计算机上很难满足这一需求。因此,我们别无选择,只能将它们部署至由本地或云端托管的性能强大的定制 AI 服务器上。
为何需要将 LLM 推理本地化
如果我们可以在典配个人计算机上运行最先进的开源 LLM 会如何?好处简直太多了:
增强隐私保护: 私有数据不需要发送至外部 API 进行推理。
降低延迟: 节省网络往返的次数。
支持离线工作: 用户可以在没有网络连接的情况下使用 LLM (常旅客的梦想!)。
降低成本: 无需在 API 调用或模型托管上花一分钱。
可定制: 每个用户都可以找到最适合他们日常工作任务的模型,甚至可以对其进行微调或使用本地检索增强生成 (RAG) 来提高适配度。
这一切的一切都太诱人了!那么,为什么我们没有这样做呢?回到我们的开场白,一般典配笔记本电脑没有足够的计算能力来运行具有可接受性能的 LLM。它们既没有数千核的 GPU,也没有快如闪电的高内存带宽。
接受失败,就此放弃?当然不!
为何现在 LLM 推理本地化有戏了
聪明的人类总能想到法子把一切东西变得更小、更快、更优雅、更具性价比。近几个月来,AI 社区一直在努力在不影响其预测质量的前提下缩小模型。其中,有三个领域的进展最振奋人心:
硬件加速: 现代 CPU 架构内置了专门用于加速最常见的深度学习算子 (如矩阵乘或卷积) 的硬件,这使得在 AI PC 上使能新的生成式 AI 应用并显著提高其速度和效率成为可能。
小语言模型 (Small Language Models,SLMs): 得益于在模型架构和训练技术上的创新,这些小模型的生成质量与大模型相当甚至更好。同时,由于它们的参数较少,推理所需的计算和内存也较少,因此非常适合资源受限的设备。
量化: 量化技术通过减少模型权重和激活的位宽来降低内存和计算要求,如将权重和激活从 16 位浮点 (
fp16) 降至 8 位整型 (int8)。减少位宽意味着模型推理时的内存需求更少,因而能加速内存受限步骤 (如文本生成的解码阶段) 的延迟。此外,权重和激活量化后,能充分利用 AI 加速器的整型运算加速模块,因而可以加速矩阵乘等运算。
本文,我们将综合利用以上三种技术对微软 Phi-2 模型进行 4 比特权重量化,随后在搭载英特尔 Meteor Lake CPU 的中端笔记本电脑上进行推理。在此过程中,我们主要使用集成了英特尔 OpenVINO 的 Hugging Face Optimum Intel 库。
Phi-2https://hf.co/microsoft/phi-2
Optimum Intel 仓库地址https://github.com/huggingface/optimum-intel
注意: 如果你想同时量化权重和激活的话,可参阅 该文档。
Optimum Intel 文档https://hf.co/docs/optimum/main/en/intel/optimization_ov#static-quantization
我们开始吧。
英特尔 Meteor Lake
英特尔 Meteor Lake 于 2023 年 12 月推出,现已更名为 Core Ultra,其是一个专为高性能笔记本电脑优化的全新 架构。
Core Ultrahttps://www.intel.com/content/www/us/en/products/details/processors/core-ultra.html
架构介绍https://www.intel.com/content/www/us/en/content-details/788851/meteor-lake-architecture-overview.html
Meteor Lake 是首款使用 chiplet 架构的英特尔客户端处理器,其包含:
高至 16 核的 高能效 CPU,
集成显卡 (iGPU): 高至 8 个 Xe 核心,每个核心含 16 个 Xe 矢量引擎 (Xe Vector Engines,XVE)。顾名思义,XVE 可以对 256 比特的向量执行向量运算。它还支持 DP4a 指令,该指令可用于计算两个宽度为 4 字节的向量的点积,将结果存储成一个 32 位整数,并将其与另一个 32 位整数相加。
**神经处理单元 (Neural Processing Unit,NPU)**,是英特尔架构的首创。NPU 是专为客户端 AI 打造的、高效专用的 AI 引擎。它经过优化,可有效处理高计算需求的 AI 计算,从而释放主 CPU 和显卡的压力,使其可处理其他任务。与利用 CPU 或 iGPU 运行 AI 任务相比,NPU 的设计更加节能。
为了运行下面的演示,我们选择了一台搭载了 Core Ultra 7 155H CPU 的 中端笔记本电脑。现在,我们选一个可爱的小语言模型到这台笔记本电脑上跑跑看吧!
Core Ultra 7 155H CPUhttps://www.intel.com/content/www/us/en/products/sku/236847/intel-core-ultra-7-processor-155h-24m-cache-up-to-4-80-ghz/specifications.html
MSI Prestige Evo 笔记本电脑https://www.amazon.com/MSI-Prestige-Evo-Laptop-A1MG-029US/dp/B0CP9Y8Q6T/
注意: 要在 Linux 上运行此代码,请先遵照 此说明 安装 GPU 驱动。
说明文档https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-gpu.html
微软 Phi-2 模型
微软于 2023 年 12 月 发布 了 Phi-2 模型,它是一个 27 亿参数的文本生成模型。
Phi-2 发布博文https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
微软给出的基准测试结果表明,Phi-2 并未因其较小的尺寸而影响生成质量,其表现优于某些最先进的 70 亿参数和 130 亿参数的 LLM,甚至与更大的 Llama-2 70B 模型相比也仅有一步之遥。
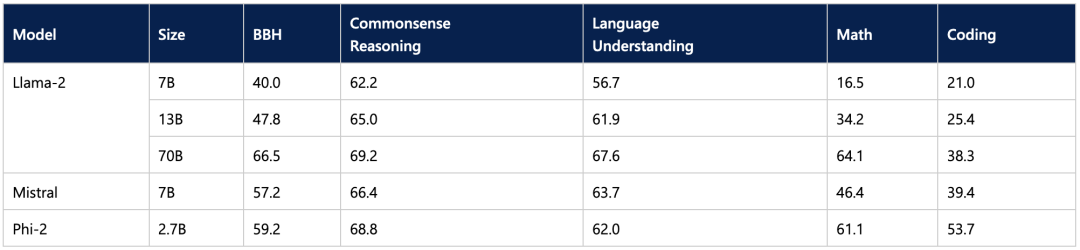
这使其成为可用于笔记本电脑推理的有利候选。另一个候选是 11 亿参数的 TinyLlama 模型。
TinyLlamahttps://hf.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
现在,让我们看看如何缩小模型以使其更小、更快。
使用英特尔 OpenVINO 和 Optimum Intel 进行量化
英特尔 OpenVINO 是一个开源工具包,其针对许多英特尔硬件平台对 AI 推理工作负载进行优化 (Github、文档),模型量化是其重要特性之一。
OpenVINO Github 仓库https://github.com/openvinotoolkit/openvino
OpenVINO 文档https://docs.openvino.ai/2024/home.html
我们与英特尔合作,将 OpenVINO 集成至 Optimum Intel 中,以加速 Hugging Face 模型在英特尔平台上的性能 (Github,文档)。
Optium Intel Github 仓库https://github.com/huggingface/optimum-intel
Optimum Intel 文档https://hf.co/docs/optimum/intel/index
首先,请确保你安装了最新版本的 optimum-intel 及其依赖库:
pip install --upgrade-strategy eager optimum[openvino,nncf]optimum-intel 支持用户很容易地把 Phi-2 量化至 4 比特。我们定义量化配置,设置优化参数,并从 Hub 上加载模型。一旦量化和优化完成,我们可将模型存储至本地。
from transformers import AutoTokenizer, pipeline
from optimum.intel import OVModelForCausalLM, OVWeightQuantizationConfigmodel_id = "microsoft/phi-2"
device = "gpu"
# Create the quantization configuration with desired quantization parameters
q_config = OVWeightQuantizationConfig(bits=4, group_size=128, ratio=0.8)# Create OpenVINO configuration with optimal settings for this model
ov_config = {"PERFORMANCE_HINT": "LATENCY", "CACHE_DIR": "model_cache", "INFERENCE_PRECISION_HINT": "f32"}tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(model_id,export=True, # export model to OpenVINO format: should be False if model already exportedquantization_config=q_config,device=device,ov_config=ov_config,)# Compilation step : if not explicitly called, compilation will happen before the first inference
model.compile()
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
results = pipe("He's a dreadful magician and")save_directory = "phi-2-openvino"
model.save_pretrained(save_directory)
tokenizer.save_pretrained(save_directory)ratio 参数用于控制将多少权重量化为 4 比特 (此处为 80%),其余会量化至 8 比特。group_size 参数定义了权重量化组的大小 (此处为 128),每个组都具有独立的缩放因子。减小这两个值通常会提高准确度,但同时会牺牲模型尺寸和推理延迟。
你可以从我们的 文档 中获取更多有关权重量化的信息。
注意: 你可在 Github 上 找到完整的文本生成示例 notebook。
Github Notebook 地址https://github.com/huggingface/optimum-intel/blob/main/notebooks/openvino/quantized_generation_demo.ipynb
那么,在我们的笔记本电脑上运行量化模型究竟有多快?请观看以下视频亲自体验一下!播放时,请选择 1080p 分辨率以获得最大清晰度。
在第一个视频中,我们向模型提了一个高中物理问题: “ Lily has a rubber ball that she drops from the top of a wall. The wall is 2 meters tall. How long will it take for the ball to reach the ground? ”
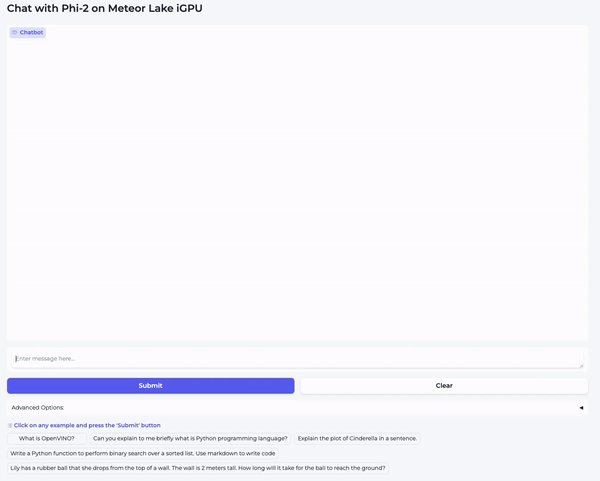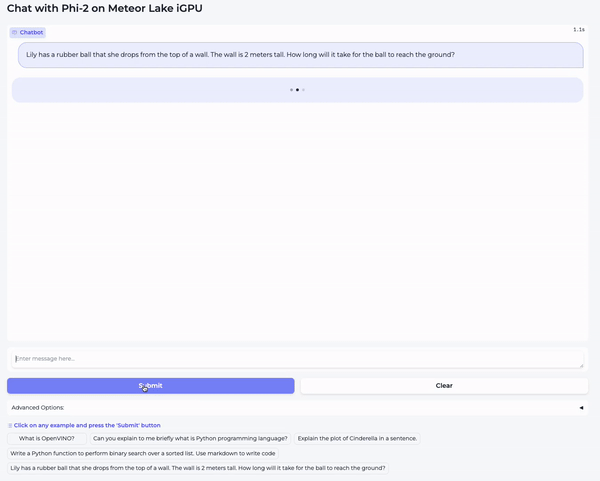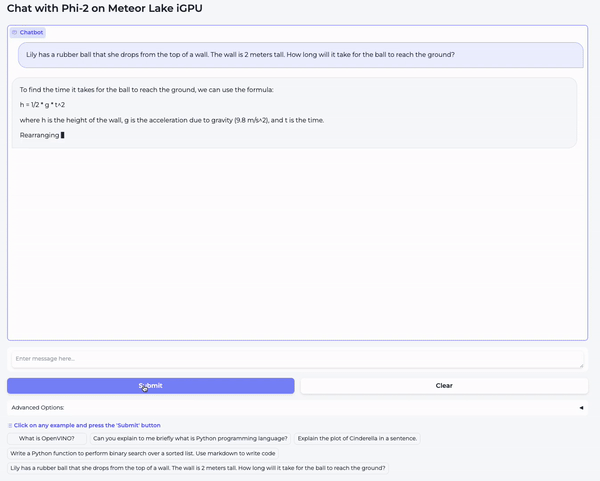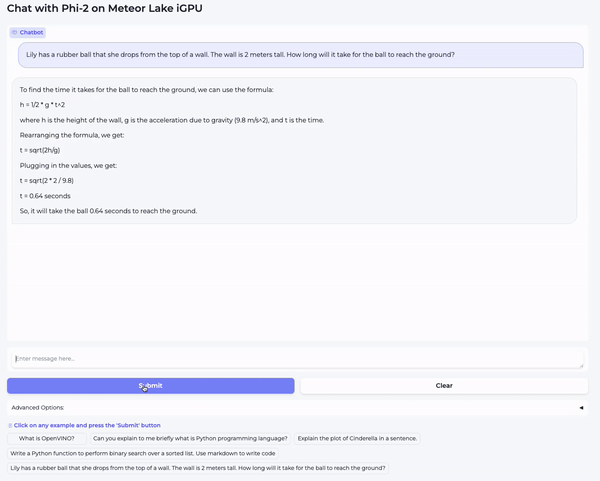
在第二个视频中,我们向模型提了一个编码问题: “ Write a class which implements a fully connected layer with forward and backward functions using numpy. Use markdown markers for code. ”
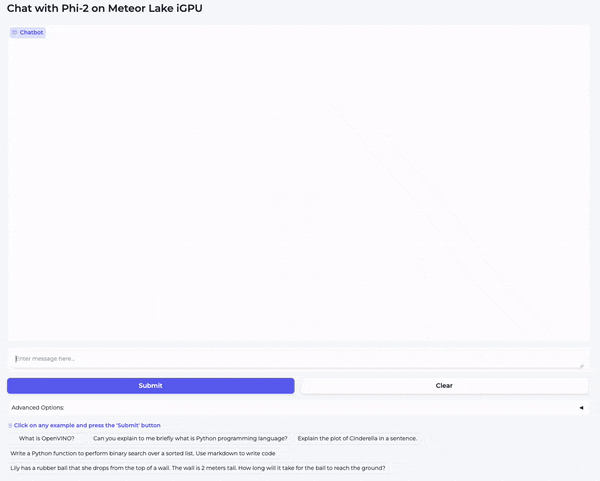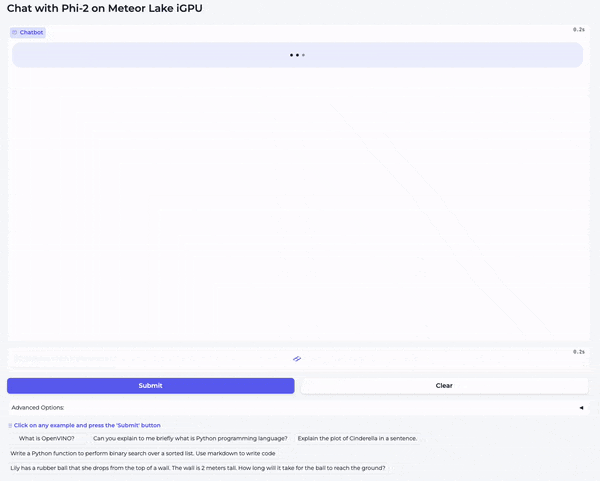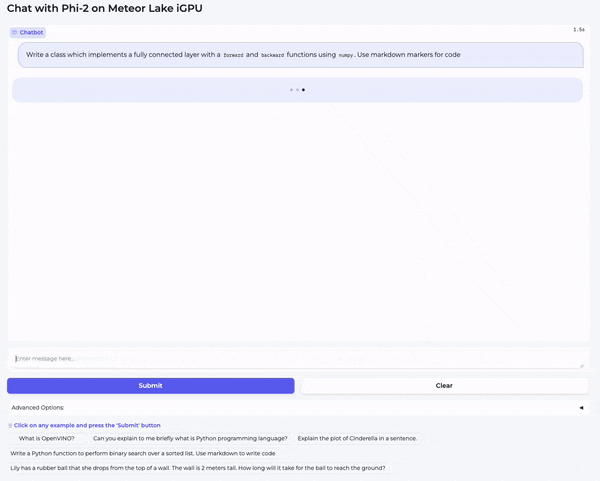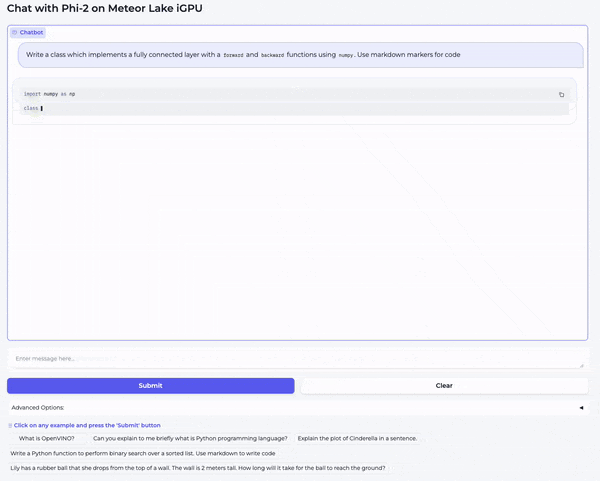
如你所见,模型对这两个问题生成的答案质量都非常高。量化加快了生成速度,但并没有降低 Phi-2 的质量。我本人很愿意在我的笔记本电脑上每天使用这个模型。
总结
借助 Hugging Face 和英特尔的工作,现在你可以在笔记本电脑上运行 LLM,并享受本地推理带来的诸多优势,如隐私、低延迟和低成本。我们希望看到更多好模型能够针对 Meteor Lake 平台及其下一代平台 Lunar Lake 进行优化。Optimum Intel 库使得在英特尔平台上对量化模型变得非常容易,所以,何不试一下并在 Hugging Face Hub 上分享你生成的优秀模型呢?多多益善!
下面列出了一些可帮助大家入门的资源:
Optimum Intel 文档https://hf.co/docs/optimum/main/en/intel/inference
来自英特尔及 Hugging Face 的 开发者资源https://www.intel.com/content/www/us/en/developer/partner/hugging-face.html
深入探讨模型量化的视频: 第 1 部分、第 2 部分https://youtu.be/kw7S-3s50ukhttps://youtu.be/fXBBwCIA0Ds
如若你有任何问题或反馈,我们很乐意在 Hugging Face 论坛 上解答。
论坛地址https://discuss.huggingface.co/
感谢垂阅!
英文原文: https://hf.co/blog/phi2-intel-meteor-lake
原文作者: Julien Simon,Ella Charlaix,Ofir Zafrir,Igor Margulis,Guy Boudoukh,Moshe Wasserblat
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
相关文章:
笔记本电脑上的聊天机器人: 在英特尔 Meteor Lake 上运行 Phi-2
对应于其强大的能力,大语言模型 (LLM) 需要强大的算力支撑,而个人计算机上很难满足这一需求。因此,我们别无选择,只能将它们部署至由本地或云端托管的性能强大的定制 AI 服务器上。 为何需要将 LLM 推理本地化 如果我们可以在典配…...
【Web】陇原战“疫“2021网络安全大赛 题解
目录 CheckIN eaaasyphp EasyJaba CheckIN 拿到附件,贴出关键代码 func getController(c *gin.Context) {cmd : exec.Command("/bin/wget", c.QueryArray("argv")[1:]...)err : cmd.Run()if err ! nil {fmt.Println("error: ", …...
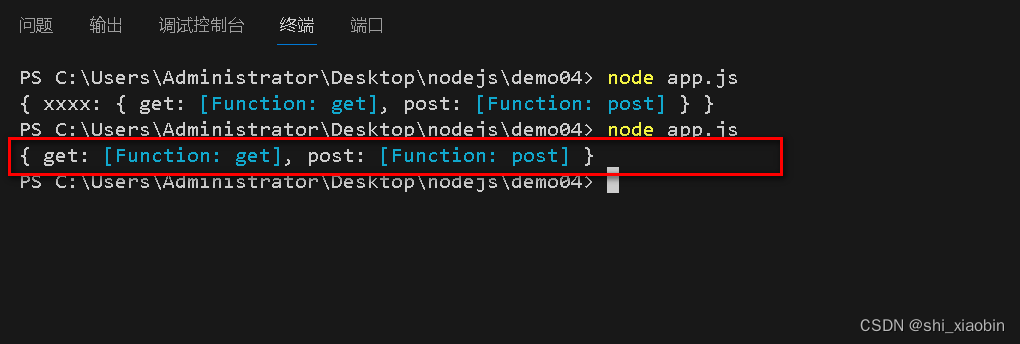
010Node.js自定义模块通过exports的使用,两种暴露的方法及区别(二)
module/request.js var obj{get:function(){console.log(从服务器获取数据);},post:function(){console.log(提交数据);} }exports.xxxxobj;//方法一 { xxxx: { get: [Function: get], post: [Function: post] } }//module.exportsobj;//方法二 //{ get: [Function: g…...
【CVE-2010-2883】进行钓鱼攻击的研究
最近作业中研究APT攻击,了解到2011年前后披露的LURID-APT,其中敌手利用了各种版本的文件查看器的漏洞实现攻击。CVE-2010-2883就是其中被利用的一个adobe reader的漏洞。特此复现,更好的研究和防范APT攻击。 本文仅仅是对相关漏洞利用的学习…...

【Python】如何在Ubuntu上设置Python脚本开机自启
你不知道我为什么狠下心 盘旋在你看不见的高空里 多的是 你不知道的事 蝴蝶眨几次眼睛 才学会飞行 夜空洒满了星星 但几颗会落地 我飞行 但你坠落之际 很靠近 还听见呼吸 对不起 我却没捉紧你 🎵 王力宏《你不知道的事》 前置要求 确保你的Ub…...

计算机视觉——OpenCV Python基于颜色识别的目标检测
1. 计算机视觉中的颜色空间 颜色空间在计算机视觉领域的应用非常广泛,它们在图像和视频处理、物体检测等任务中扮演着重要角色。颜色空间的主要作用是将颜色以数值形式表示出来,这样计算机算法就能够对其进行处理和分析。不同的颜色空间有着不同的特点和…...

2024中国内燃机展-北京汽车发动机零部件展
2024第二十三届中国国际内燃机与零部件展览会 由中国内燃机工业协会主办、中国机床专用技术设备有限公司、汽车工艺装备成套开发集团协办的2024中国国际内燃机及动力装备博览会(简称“动博会”)将于2024年10月11日-13日在亦创国际会展中心隆重举办。本届…...
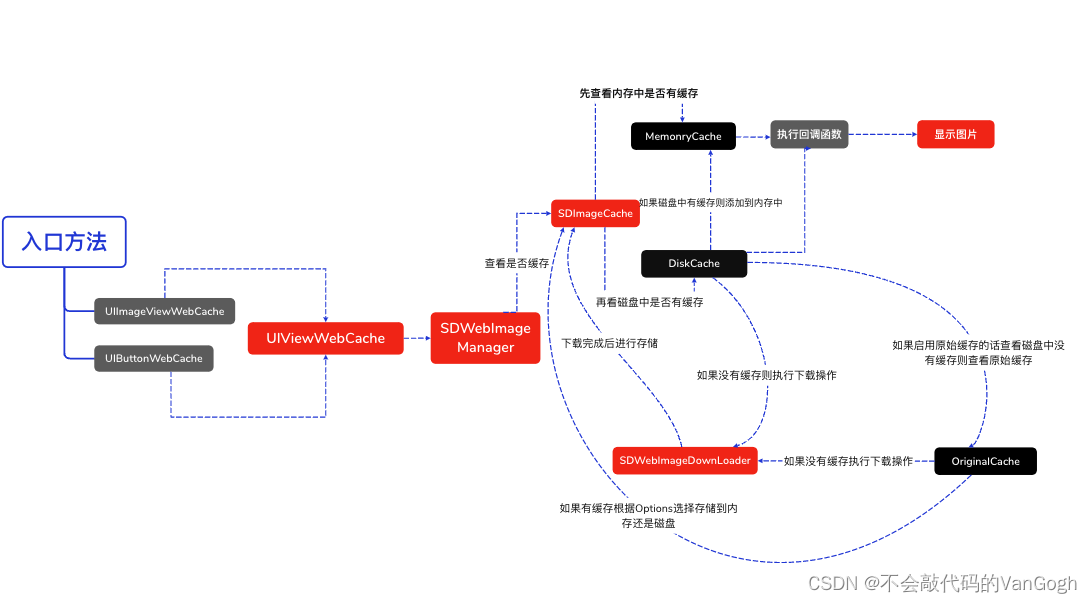
【iOS】——SDWebImage源码学习
文章目录 一、SDWebIamge简介二、SDWebImage的调用流程SDWebImage源码分析1.UIImageViewWebCache层2.UIViewWebCache层3.SDWebManager层4.SDWebCache层5.SDWebImageDownloader层 一、SDWebIamge简介 SDWebImage是iOS中提供图片加载的第三方库,可以给UIKit框架中的控…...

树和二叉树(一)
一、树 非线性数据结构,在实际场景中,存在一对多,多对多的情况。 树( tree)是n (n>0)个节点的有限集。当n0时,称为空树。 在任意一个非空树中,有如下特点。 1.有且仅有一个特定的称为根的节点…...
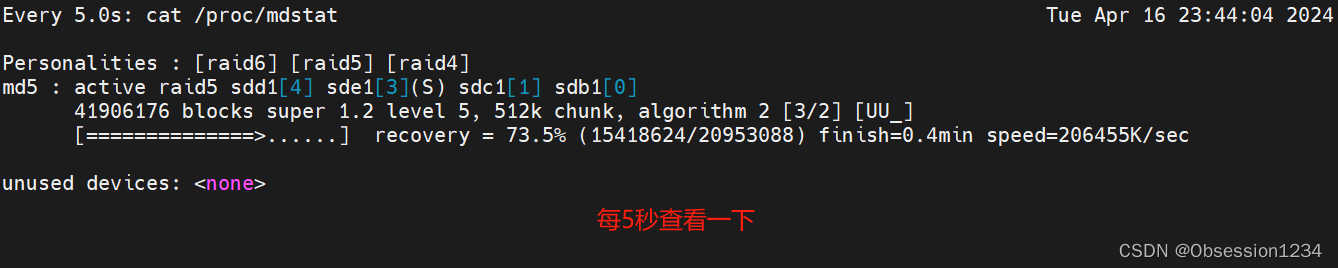
RAID 磁盘阵列及RAID配置实战
目录 一.RAID磁盘阵列介绍 二.常用的RAID磁盘阵列的介绍 1.RAID 0 (条带化存储) 2.RAID 1(镜像存储) 3.RAID 5 4.RAID 6 5.RAID 10(先做镜像,再做条带) 6.RAID 01 (先做条带…...
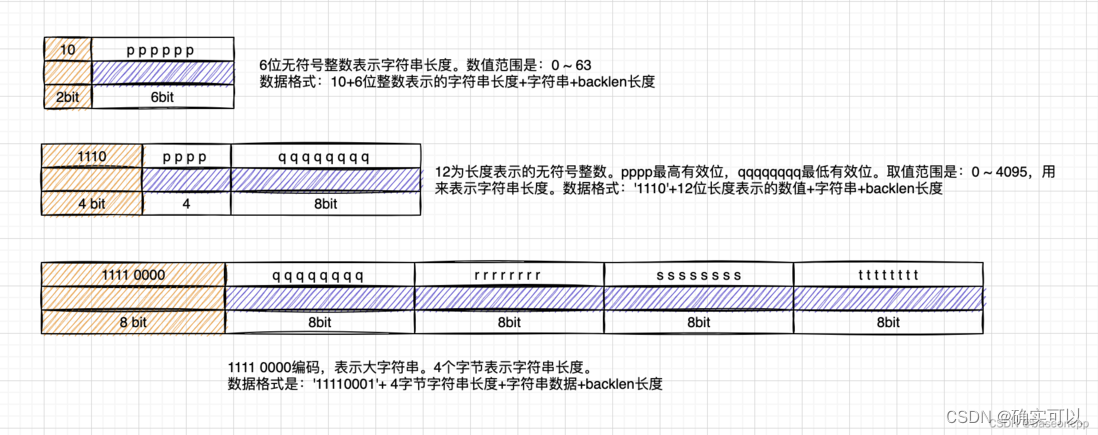
listpack
目录 为什么有listpack? listpack结构 listpack的节点entry 长度length encoding编码方式 listpack的API 1.创建listpack 2.遍历操作 正向遍历 反向遍历 3.查找元素 4.插入/替换/删除元素 总结 为什么有listpack? ziplist是存储在连续内存空间,节省…...

Web3与社会契约:去中心化治理的新模式
在数字化时代,技术不断为我们提供新的可能性,而Web3技术作为一种基于区块链的创新,正在引领着互联网的下一波变革。它不仅改变了我们的经济模式和商业逻辑,还对社会契约和权力结构提出了全新的挑战和思考。本文将深入探讨Web3的基…...

实体类List重复校验
如果实体类有多个属性,并且你希望根据所有属性的组合来进行重复校验,你可以考虑以下几种方法: 使用集合存储已经出现过的实体对象: 将每个实体对象放入一个 Set 中进行重复校验。在 Set 中元素的比较可以使用自定义的 equals 方法…...

loadash常用的函数方法
Lodash是一个JavaScript实用工具库,提供了很多常用的函数方法来简化开发过程。以下是一些常用的Lodash函数方法: _.map(array, iteratee):对数组中的每个元素应用一个函数,并返回结果数组。_.filter(collection, predicate)&…...

【零基础入门TypeScript】模块
目录 内部模块 内部模块语法(旧) 命名空间语法(新) 两种情况下生成的 JavaScript 是相同的 外部模块 选择模块加载器 定义外部模块 句法 例子 文件:IShape.js 文件:Circle.js 文件:…...

Scala 之数组
可变数组与不可变数组 import scala.collection.mutable.ArrayBuffer// 不可变数组。 长度不可变,但是元素的值可变 object Demo1 {def main(args: Array[String]): Unit {// 不可变数组定义方式// 未初始化有默认值 Int > 0val arr1 : Array[Int] new Arr…...

【Phytium】飞腾D2000 UEFI/EDK2 适配 RTC(IIC SD3077)
文章目录 0. env1. 软件2. 硬件 10. 需求1. 硬件2. 软件 20. DatasheetCPURTC 30. 调试步骤1. 硬件环境搭建2. UEFI 开发环境搭建3. 修改步骤1. UEFI 中使能RTC驱动、配置RTC信息等1.1 使能RTC驱动1.2 修改RTC对应的IIC配置信息1.3 解决驱动冲突1.4 验证波形 2. 修改对应RTC驱动…...
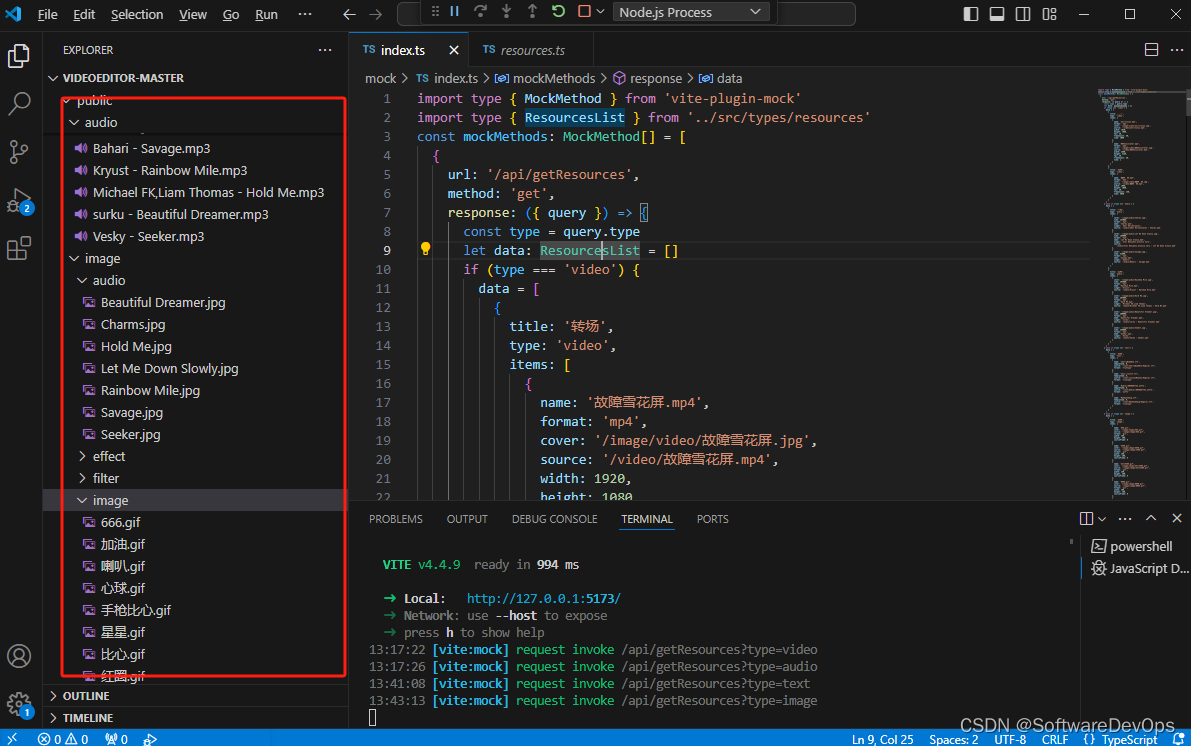
如何利用纯前端技术,实现一个网页版视频编辑器?
纯网页版视频编辑器 一、前言二、功能实现三、所需技术四、部分功能实现4.1 素材预设4.2 多轨道剪辑 一、前言 介绍:本篇文章打算利用纯前端的技术,来实现一个网页版的视频编辑器。为什么突然想做一个这么项目来呢,主要是最近一直在利用手机…...

stm32实现hid键盘
前面的cubelmx项目配置参考 stm32实现hid鼠标-CSDN博客https://blog.csdn.net/anlog/article/details/137814494?spm1001.2014.3001.5502两个项目的配置完全相同。 代码 引用 键盘代码: 替换hid设备描述符 先屏蔽鼠标设备描述符 替换为键盘设备描述符 修改宏定…...

【单例模式】饿汉式、懒汉式、静态内部类--简单例子
单例模式是⼀个单例类在任何情况下都只存在⼀个实例,构造⽅法必须是私有的、由⾃⼰创建⼀个静态变量存储实例,对外提供⼀个静态公有⽅法获取实例。 目录 一、单例模式 饿汉式 静态内部类 懒汉式 反射可以破坏单例 道高一尺魔高一丈 枚举 一、单例…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...
提升你的图表专业度?)
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度?
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度? 在数据驱动的决策时代,图表不仅是科研论文中的证据载体,更是商业汇报中的说服工具。我曾见证一位生物统计学家将同一组临床试验数据呈现给三种不同受众&…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析
D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 当…...
:openclaw agent 如何触发一次 Agent 运行?)
OpenClaw 源码解析(六):openclaw agent 如何触发一次 Agent 运行?
1. 本期要解决的问题 前几期我们已经从项目整体结构、CLI 命令体系、配置加载、Gateway 运行机制等角度理解了 OpenClaw 的基础框架。到了这一期,可以进一步进入 OpenClaw 最核心的使用动作:用户在终端中执行一条 openclaw agent --message "...&q…...