【代码】Python3|Requests 库怎么继承 Selenium 的 Headers (2024,Chrome)
本文使用的版本:
- Chrome 124
- Python 12
- Selenium 4.19.0
版本过旧可能会出现问题,但只要别差异太大,就可以看本文,因为本文对新老版本都有讲解。
文章目录
- 1 难点解析和具体思路
- 2 注意事项
- 2.1 PDF 资源获取时注意事项
- 2.2 Capabilities 写法
- 2.3 get_log("performance") 写法
- 3 完整代码
1 难点解析和具体思路
这个难点主要是 Chrome 和 Selenium 的版本更新太快了。
首先,如果要继承 Selenium 的 Headers,有两种思路:
- 从 Selenium 对于 Chromedriver的参数入手,即 arguments[0]这样的东西。参考示例代码如下:
具体driver是什么我也不解释了,总之就是这个其实就是个人工配置项,arguments[0]里根本就不会自带一个headers键值。arguments里面可能存在的所有参数可以看这篇文章:List of Chromium Command Line Switches,https://peter.sh/experiments/chromium-command-line-switches/。# Execute JavaScript to retrieve headers headers = driver.execute_script("""var headersObj = {};var headers = new Map(Object.entries(arguments[0].headers));headers.forEach(function(value, key) {headersObj[key] = value;});return headersObj; """, driver.execute_script("return window.navigator")) - 从 Selenium 抓的包入手,即使用 network 相关的,在 Selenium 里面是
get_log("performance")。这个方式在 Selenium 4.10 之后有所改变,具体改变见下文。
2 注意事项
我这篇文章需要继承 headers 是因为网络上有些资源是需要登录注册的,但是每次都自己重新获取 Cookie 是很麻烦的。我这里以一个随便找的 PDF 资源(https://www.sigmaaldrich.cn/CN/zh/sds/aldrich/488488)的获取为例。
2.1 PDF 资源获取时注意事项
具体可以看【记录】Python|Selenium 下载 PDF 不预览不弹窗(2024年),代码的解释也写了,这部分就不展开说了,本文的最后面贴了完整的代码。
2.2 Capabilities 写法
参考:How to Capture Network Traffic When Scraping with Selenium & Python
在 Chrome 75 之后这部分出现了改变。Chrome 和 chromedriver 的版本很重要。版本 75 左右的日志记录功能发生了变化,以适应 W3C 合规性。如果您卡在 Chrome/chromedriver 版本 75 以下,则需要在下面的第一个代码片段中使用loggingPrefs而不是goog:loggingPrefs。
caps = DesiredCapabilities.CHROME
# capabilities["loggingPrefs"] = {"performance": "ALL"} # chromedriver < ~75
caps['goog:loggingPrefs'] = {'performance': 'ALL'}
2.3 get_log(“performance”) 写法
参考:Getting TypeError: WebDriver.init() got an unexpected keyword argument ‘desired_capabilities’ when using Appium with Selenium 4.10-Stackoverflow
在 Selenium 4.10 之后这部分出现了改变。
Selenium 4.10 之前:
driver = webdriver.Chrome(service=s, options=options, desired_capabilities=caps) # selenium < 4.10
Selenium 4.10 之后:
options.set_capability('goog:loggingPrefs', {'performance': 'ALL'})
driver = webdriver.Chrome(service=s, options=options)
3 完整代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Optionsfrom selenium.webdriver.common.desired_capabilities import DesiredCapabilitiescaps = DesiredCapabilities.CHROME
# capabilities["loggingPrefs"] = {"performance": "ALL"} # chromedriver < ~75
caps['goog:loggingPrefs'] = {'performance': 'ALL'}options = Options()
# options.add_argument(
# "user-agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'") # UA
# options.add_argument("user-data-dir=C:/Users/User/AppData/Local/Google/Chrome/User Data/Default")
s = Service("D:/software/chromedriver.exe")
# Disable the built-in PDF viewer
options.add_experimental_option('prefs', {"download.prompt_for_download": True,'plugins.always_open_pdf_externally': False})
# desired_capabilities has been removed according to this post,so the newest way looks like this : options = webdriver.ChromeOptions() options.set_capability('goog:loggingPrefs', {'performance': 'ALL'})
# driver = webdriver.Chrome(service=s, options=options, desired_capabilities=caps) # selenium < 4.10
options.set_capability('goog:loggingPrefs', {'performance': 'ALL'})
driver = webdriver.Chrome(service=s, options=options)pdf_url = 'https://www.sigmaaldrich.cn/CN/zh/sds/aldrich/488488'# get driver log
driver.get(pdf_url)
print(driver.log_types)
network_logs = driver.get_log("performance")import json
# Extract headers from the network logs
headers = {}
for log in network_logs:log_message = json.loads(log['message'])['message'] # Parse log message as JSONif 'params' in log_message and 'request' in log_message['params']:request_params = log_message['params']['request']if 'headers' in request_params:headers = request_params['headers']break # Exit loop after finding headersimport requests# Use requests to download the PDF file with headers
response = requests.get(pdf_url, headers=headers)# Check if the request was successful
if response.status_code == 200:# Save the PDF filewith open("output.pdf", "wb") as f:f.write(response.content)print("PDF file downloaded successfully.")
else:print("Failed to download the PDF file.")# Close the Selenium WebDriver
driver.quit()
这样子写代码就不需要 Selenium 去 sleep 等待下载了,也可以很好地解决一部分 Requests 库的反爬虫问题,不过对于防止重放攻击的反爬虫手段还是无效。
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_46106285/article/details/137891147。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。
相关文章:
【代码】Python3|Requests 库怎么继承 Selenium 的 Headers (2024,Chrome)
本文使用的版本: Chrome 124Python 12Selenium 4.19.0 版本过旧可能会出现问题,但只要别差异太大,就可以看本文,因为本文对新老版本都有讲解。 文章目录 1 难点解析和具体思路2 注意事项2.1 PDF 资源获取时注意事项2.2 Capabiliti…...
JAVA程序设计-对象设计
无论是根据某马还是某谷的适配教程做项目时候,发现了大部分都是重复的crud,大部分只要做好笔记复习即可,但是却往往忘记了编码设计,所以这里开始复习编码设计,对象设计中,长期使用Mp的那一套导致就是Service Mapper,一套梭哈完了,这样很容易忘记基本功夫 POJO: 简单…...

蓝桥杯2024年第十五届省赛真题-R 格式
找到规律后如下,只需要用高精度加法和四舍五入(本质也是高精度加法就能做),如果没有找到规律,就得自己写高精度乘法和加法,不熟练很容易错。 //#include<bits/stdc.h> #include<iostream> #i…...
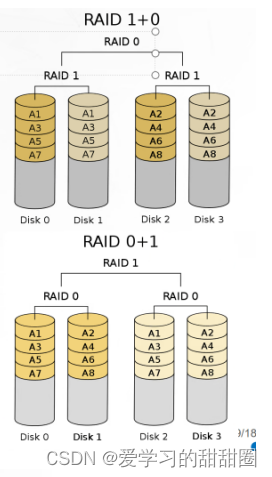
Linux服务器硬件及RAID配置
一、服务器硬件 塔式服务器:最初的服务器形态之一,类似于传统的台式电脑,但具有更强的处理能力和稳定性,适合小型企业或部门使用。 机架式服务器:设计为可安装在标准化机架内的模块化单元,可以有效地节省空…...

前端 vue单页面中请求数量过多问题 控制单页面请求并发数
需求背景: 页面中需要展示柜子,一个柜子需要调用 详情接口以及状态接口 也就是说有一个柜子就需要调用两个接口,在项目初期,接手的公司项目大概也就4-5个柜子,最多的也不超过10个,但是突然进来一个项目&a…...

HarmonyOS开发实例:【分布式手写板】
介绍 本篇Codelab使用设备管理及分布式键值数据库能力,实现多设备之间手写板应用拉起及同步书写内容的功能。操作流程: 设备连接同一无线网络,安装分布式手写板应用。进入应用,点击允许使用多设备协同,点击主页上查询…...
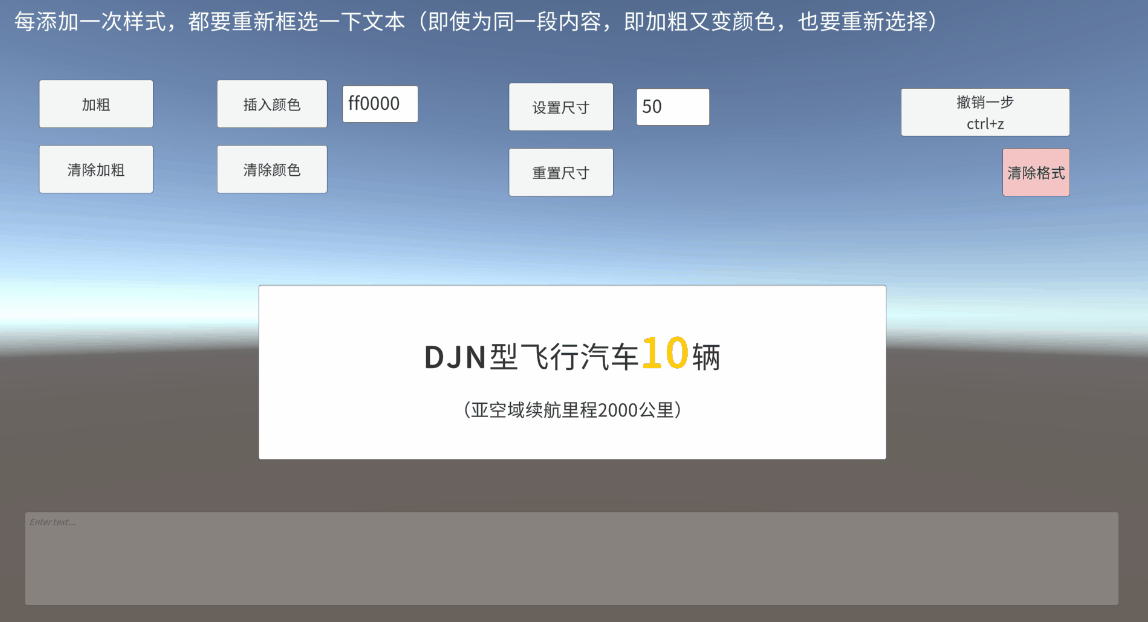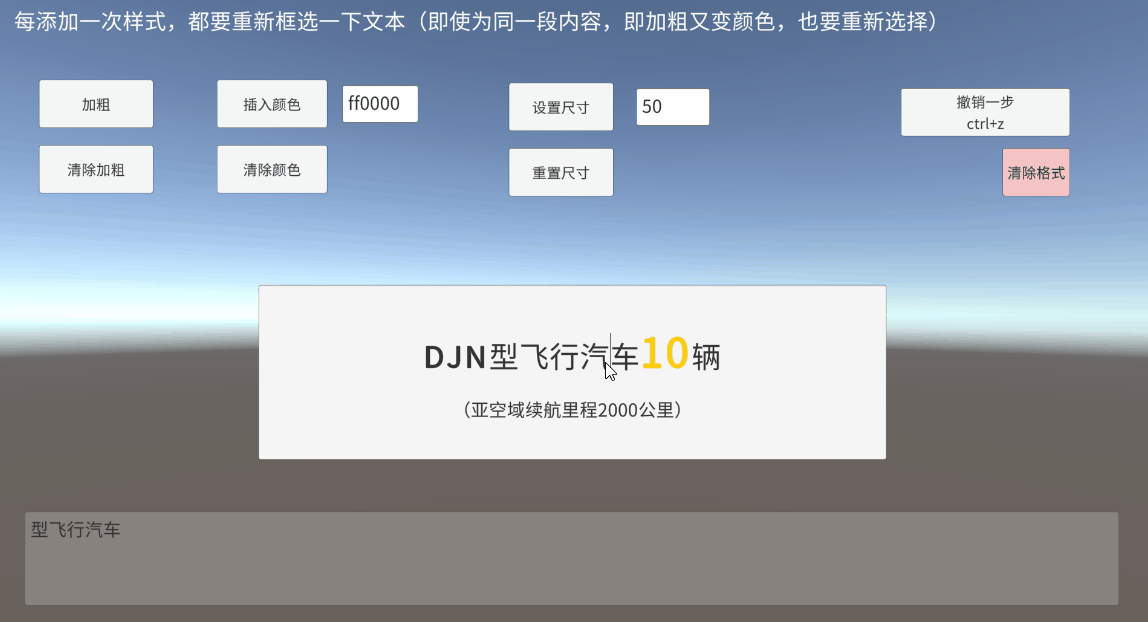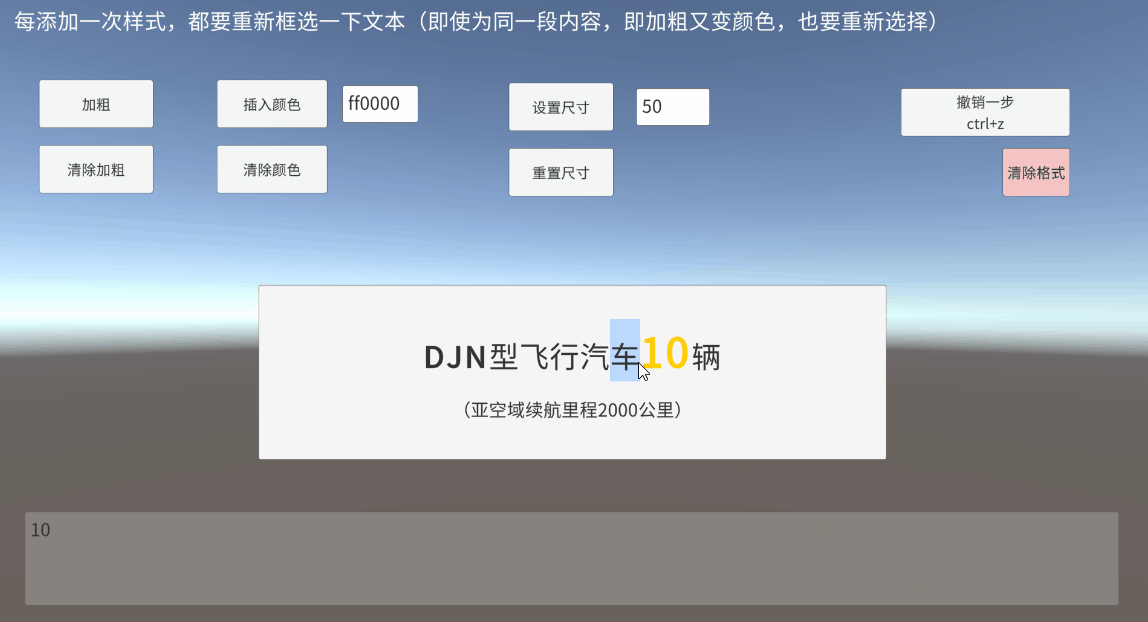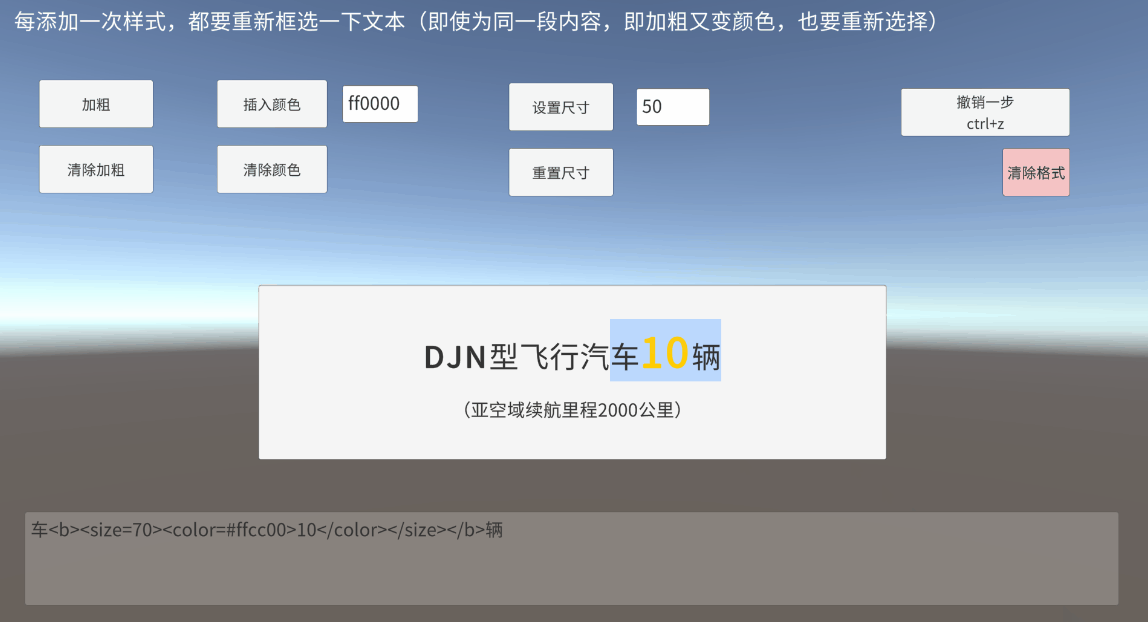
Unity TMP Inputfield 输入框 框选 富文本 获取真实定位
一、带富文本标签的框选是什么 UGUI的InputField提供了selectionAnchorPosition和selectionFocusPosition,开始选择时的光标下标和当前光标下标 对于未添加富文本标签时,直接通过以上两个值,判断一下框选方向(前向后/后向前&…...

如何在原生项目中集成flutter
两个前提条件: 从flutter v1.17版本开始,flutter module仅支持AndroidX的应用在release模式下flutter仅支持一下架构:x84_64、armeabi-v7a、arm6f4-v8a,不支持mips和x86;所以引入flutter前需要在app/build.gradle下配置flutter支持的架构 a…...

【设计模式】策略模式
目录 什么是策略模式 代码实现 什么是策略模式 策略模式是一种行为型设计模式,它定义了一系列算法,将每个算法封装成一个独立的对象,使得它们可以相互替换。 在策略模式中,通常有三个角色: 环境类(Cont…...

Java面试八股之Iterator和ListIterator的区别是什么
Iterator和ListIterator的区别是什么 这道题也是考查我们对迭代器相关的接口的了解程度,从代码中我们可以看出后者是前者的子接口,在此基础上做了一些增强,并且只用于List集合类型。 定义与基本概念 Iterator: 定义:…...
服务器中毒怎么办?企业数据安全需重视
互联网企业: 广义的互联网企业是指以计算机网络技术为基础,利用网络平台提供服务并因此获得收入的企业。广义的互联网企业可以分为:基础层互联网企业、服务层互联网企业、终端层互联网企业。 狭义的互联网企业是指在互联网上注册域名,建立网…...

k8s使用harbor私有仓库镜像 —— 筑梦之路
官方文档: Secret | Kubernetes ImagePullSecrets的设置是kubernetes机制的另一亮点,习惯于直接使用Docker Pull来拉取公共镜像,但非所有容器镜像都是公开的。此外,并不是所有的镜像仓库都允许匿名拉取,也就是说需要身份认证&…...
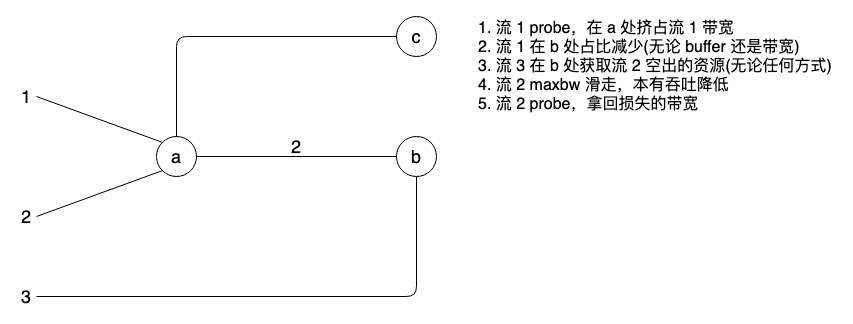
tcp bbr pacing 的对与错
前面提到 pacing 替代 burst 是大势所趋,核心原因就是摩尔定律逐渐失效,主机带宽追平交换带宽,交换机不再能轻易吸收掉主机突发,且随着视频类流量激增,又不能以大 buffer 做带宽后备。因此,主机必须 pacing…...

MySQL学习-非事务相关的六大日志、InnoDB的三大特性以及主从复制架构
一. 六大日志 慢查询日志:记录所有执行时间超过long_query_time的查询,方便定位并优化。 # 查询当前慢查询日志状态 SHOW VARIABLES LIKE slow_query_log; #启用慢查询日志 SET GLOBAL slow_query_log ON; #设置慢查询文件位置 SET GLOBAL slow_query_log_file …...
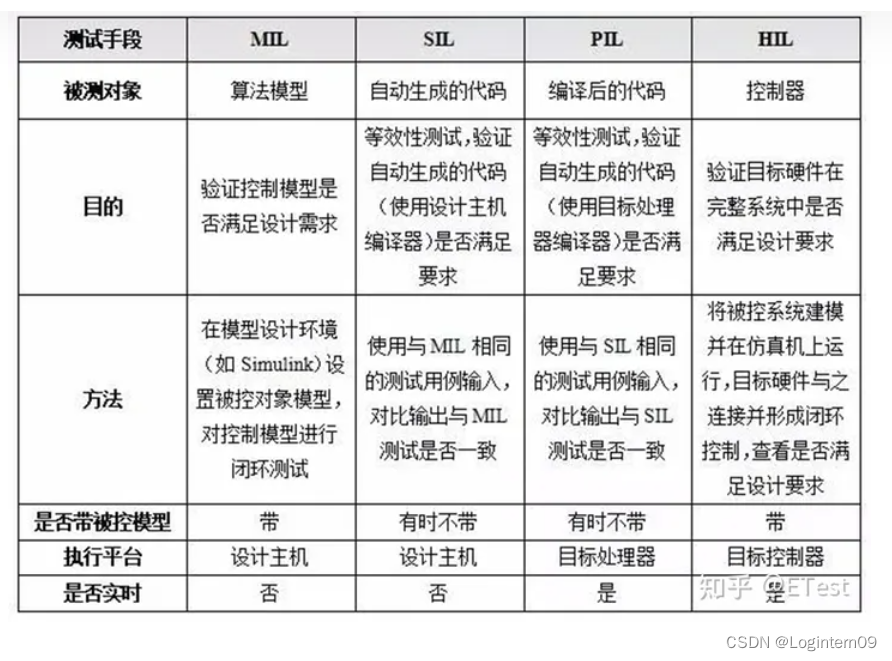
【软件测试】MIL/HIL/PIL/SIL测试
V字型开发流程 引用文章:汽车行业V模型开发详解 V模型开发(V-Model Development)是一种广泛应用于汽车行业的系统开发方法。它以字母“V”形状的图表形式展示了开发过程中不同阶段之间的关系,从需求分析到系统整合和验证&#x…...

WebKit结构深度解析:打造高效与安全的浏览器引擎
WebKit结构深度解析:打造高效与安全的浏览器引擎 在现代网络世界中,浏览器作为连接用户与互联网信息的桥梁,其背后的技术架构至关重要。WebKit,作为当今最流行的开源浏览器引擎之一,其结构设计和功能实现对于提升浏览…...

SQLSERVER对等发布问题处理
问题1: 无法对 数据库Sast_Business 执行 删除,因为它正用于复制。 (.Net SqlClient Data Provider) 处理: USE [master]; GO EXEC sp_replicationdboption dbname NSast_Business, optname Npublish, value Nfalse; EXEC sp_replica…...

CentOS 7 中时间快了 8 小时
1.查看系统时间 1.1 timeZone显示时区 [adminlocalhost ~]$ timedatectlLocal time: Mon 2024-04-15 18:09:19 PDTUniversal time: Tue 2024-04-16 01:09:19 UTCRTC time: Tue 2024-04-16 01:09:19Time zone: America/Los_Angeles (PDT, -0700)NTP enabled: yes NTP synchro…...

itext7 pdf转图片
https://github.com/thombrink/itext7.pdfimage 新建asp.net core8项目,安装itext7和system.drawing.common 引入itext.pdfimage核心代码 imageListener下有一段不安全的代码 unsafe{for (int y 0; y < image.Height; y){byte* ptrMask (byte*)bitsMask.Scan…...

搜维尔科技:Manus Xsens Metagloves新一代手指捕捉
Manus Xsens Metagloves新一代手指捕捉 搜维尔科技:Manus Xsens Metagloves新一代手指捕捉...

保姆级教程:用Lumerical FDTD参数扫描功能,分析WO3薄膜厚度对反射率的影响
从零到精通:Lumerical FDTD参数扫描在薄膜光学设计中的实战指南 在光电材料研究和器件设计中,薄膜厚度的精确控制往往直接影响器件的光学性能。以三氧化钨(WO₃)薄膜为例,其厚度变化会显著改变反射光谱特性,…...

Vibe Annotations:AI编程时代的视觉反馈工具,精准沟通前端修改意图
1. 项目概述:一个为AI编程时代量身定制的视觉反馈工具如果你和我一样,每天都在和AI编程助手(比如Cursor、Claude Code)打交道,那你肯定遇到过这个痛点:想让它帮你改一个网页按钮的颜色,或者调整…...

OpenClaw本地控制台:一站式图形化管理AI助手工作流
1. 项目概述:一个为本地OpenClaw工作流量身打造的控制台如果你和我一样,在Windows上折腾过OpenClaw,那你肯定经历过这种“精神分裂”式的管理体验:想启动服务,得切到终端敲命令;要改个模型配置,…...

Windows 11安卓子系统WSA:在电脑上流畅运行手机应用的完整指南
Windows 11安卓子系统WSA:在电脑上流畅运行手机应用的完整指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 你是否曾想过在Windows电脑上直接…...

API集成管理之核心产品核心能力与数据盘点
API集成管理是企业数字化转型中的核心基础设施,它解决的是系统之间如何高效、安全、可控地进行数据交换与业务协同的问题。一套完善的API集成管理方案,能够帮助企业打通数据孤岛、实现能力复用、构建开放生态。本文基于公开资料,对五款代表性…...

VSCode毛玻璃效果实现:CSS backdrop-filter原理与性能调优指南
1. 项目概述:当代码编辑器遇上毛玻璃美学如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(以下简称VSCode)中度过的,那么你肯定不止一次地折腾过它的主题和外观。从默认的深色主题到各种炫酷的Material D…...

ARM GIC中断控制器架构与关键寄存器详解
1. ARM GIC中断控制器架构概述ARM通用中断控制器(GIC)是现代ARM处理器中负责中断管理的核心组件,它实现了复杂的中断分发和处理机制。GIC架构从v2版本发展到现在的v4版本,功能不断增强,支持多核处理、虚拟化扩展和安全隔离等高级特性。GIC主要…...

2篇3章3节:Trae 的高效小说创作与文件管理实操
在人工智能辅助小说创作的过程中,工具操作方式、内容生成逻辑与文件管理体系,直接决定写作效率与文稿质量。Trae作为适配小说创作的专业工具,不仅支持单章、全章智能化生成正文内容,适配短篇、长篇不同创作场景,还具备多屏拆分、标签页管理、规范化文件收纳等实用功能。熟…...

告别TwinCAT:手把手教你用LinuxCNC+IGH搭建开源EtherCAT运动控制平台
告别商业软件束缚:LinuxCNCIGH开源运动控制平台实战指南 在工业自动化和运动控制领域,商业软件长期占据主导地位,但高昂的授权费用和封闭的生态系统让许多工程师和创客望而却步。开源运动控制平台的出现打破了这一局面,为追求灵活…...

谷歌seo付费外链是什么? 深度拆解5种主流的外链买卖方式
在目前的搜索环境下,想要让网站在没有外部引荐的情况下出现在搜索结果前排,难度不亚于在一座无人的深山里开店却希望客流量爆满。链接建设,或者说大家心照不宣的“外链买卖”,已经变成了提升排名的必经之路。一、 揭开付费外链的真…...