百面算法工程师 | 支持向量机——SVM
文章目录
- 15.1 SVM
- 15.2 SVM原理
- 15.3 SVM解决问题的类型
- 15.4 核函数的作用以及特点
- 15.5 核函数的表达式
- 15.6 SVM为什么引入对偶问题
- 15.7 SVM使用SGD及步骤
- 15.8 为什么SVM对缺失数据敏感
- 15.9 SVM怎么防止过拟合
欢迎大家订阅我的专栏一起学习共同进步
祝大家早日拿到offer! let’s go
🚀🚀🚀http://t.csdnimg.cn/dfcH3🚀🚀🚀
15.1 SVM
支持向量机(Support Vector Machine,SVM)是一种机器学习算法,广泛应用于分类和回归分析中。其基本原理是找到一个最优的超平面,将不同类别的数据分开,同时最大化分类边界的间隔。SVM的核心思想是通过将低维空间的数据映射到高维空间,从而使得数据线性可分。在高维空间中,SVM寻找一个能够最大化间隔的超平面,这个超平面被称为最优超平面。
SVM在分类问题中的工作原理是将输入数据映射到一个高维特征空间中,并找到一个能够将不同类别的数据分开的超平面。为了找到这个最优超平面,SVM通过最大化间隔(样本到超平面的距离)来确保分类的鲁棒性和泛化能力。在实际应用中,由于数据通常不是线性可分的,因此SVM引入了核函数来将数据映射到高维空间,从而使得数据在高维空间中线性可分。
SVM的优点包括:
- 在高维空间中处理非线性问题:通过使用核函数,SVM可以将数据映射到高维空间,从而处理非线性问题。
- 泛化能力强:由于SVM最大化间隔,因此具有很好的泛化能力,对于新数据的分类效果较好。
- 可解释性强:最优超平面是由支持向量决定的,这些支持向量是最靠近超平面的数据点,因此SVM具有较强的可解释性。
然而,SVM也存在一些缺点,包括:
- 对参数调节和核函数的选择较为敏感。
- 训练时间较长,特别是在大规模数据集上。
- 在处理噪声较多的数据集时,可能会出现过拟合的问题。
- 用SVM解决多分类问题存在困难
总的来说,SVM是一种强大的机器学习算法,在许多分类和回归问题中都有良好的表现。
15.2 SVM原理
以下是支持向量机(SVM)的推导过程
支持向量机(SVM)推导
- 基本概念
假设我们有一个数据集 ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) {(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)} (x1,y1),(x2,y2),...,(xn,yn),其中 x i x_i xi 是输入特征, y i y_i yi 是对应的类别标签。对于二分类问题, y i y_i yi 可以是 − 1 -1 −1 或 + 1 +1 +1。
- SVM的目标
SVM的目标是找到一个超平面,可以最大化类别之间的间隔,并且使得所有的数据点都被正确分类。超平面可以表示为 w ⋅ x + b = 0 w \cdot x + b = 0 w⋅x+b=0,其中 w w w 是法向量, b b b 是偏置项。
- 最大间隔分类器
我们定义超平面到最近的数据点的距离为间隔(margin)。最大间隔分类器的目标是最大化这个间隔。这可以形式化为以下优化问题:
maximize 2 ∥ w ∥ subject to y i ( w ⋅ x i + b ) ≥ 1 , for all i \text{maximize} \quad \frac{2}{\lVert w \rVert} \\ \text{subject to} \quad y_i(w \cdot x_i + b) \geq 1, \quad \text{for all } i maximize∥w∥2subject toyi(w⋅xi+b)≥1,for all i
这是一个凸二次优化问题。
- 对偶问题
通过拉格朗日乘子法,我们可以将原始问题转化为对偶问题。我们引入拉格朗日乘子 α i ≥ 0 \alpha_i \geq 0 αi≥0,并定义拉格朗日函数:
L ( w , b , α ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 n α i [ y i ( w ⋅ x i + b ) − 1 ] L(w, b, \alpha) = \frac{1}{2}\lVert w \rVert^2 - \sum_{i=1}^{n} \alpha_i [y_i(w \cdot x_i + b) - 1] L(w,b,α)=21∥w∥2−i=1∑nαi[yi(w⋅xi+b)−1]
然后对 w w w 和 b b b 求偏导并令其等于零,得到:
w = ∑ i = 1 n α i y i x i ∑ i = 1 n α i y i = 0 w = \sum_{i=1}^{n} \alpha_i y_i x_i \\ \sum_{i=1}^{n} \alpha_i y_i = 0 w=i=1∑nαiyixii=1∑nαiyi=0
将这些结果代入拉格朗日函数,我们得到对偶问题:
maximize W ( α ) = ∑ i = 1 n α i − 1 2 ∑ i , j = 1 n α i α j y i y j x i ⋅ x j subject to α i ≥ 0 , ∑ i = 1 n α i y i = 0 \text{maximize} \quad W(\alpha) = \sum_{i=1}^{n} \alpha_i - \frac{1}{2} \sum_{i,j=1}^{n} \alpha_i \alpha_j y_i y_j x_i \cdot x_j \\ \text{subject to} \quad \alpha_i \geq 0, \quad \sum_{i=1}^{n} \alpha_i y_i = 0 maximizeW(α)=i=1∑nαi−21i,j=1∑nαiαjyiyjxi⋅xjsubject toαi≥0,i=1∑nαiyi=0
这是一个凸二次优化问题,其解决方案给出了最优的超平面。
- 从对偶问题中得到分离超平面
通过解决对偶问题,我们得到了一组拉格朗日乘子 α i ∗ \alpha_i^* αi∗。然后,我们可以使用它们来计算权重向量 w w w:
w = ∑ i = 1 n α i ∗ y i x i w = \sum_{i=1}^{n} \alpha_i^* y_i x_i w=i=1∑nαi∗yixi
并且选择任意一个支持向量 x i x_i xi 来计算偏置项 b b b:
b = y i − w ⋅ x i b = y_i - w \cdot x_i b=yi−w⋅xi
- 非线性SVM
对于非线性问题,我们可以使用核函数将输入空间映射到更高维的特征空间。这样,我们就可以在特征空间中找到一个线性超平面来分隔数据。
支持向量机是一种强大的分类器,通过最大化间隔来优化超平面位置,从而提高了分类的鲁棒性。通过解决对偶问题,我们可以得到优雅的解决方案,并且通过核函数,SVM可以处理非线性问题。
15.3 SVM解决问题的类型
支持向量机(SVM)是一种非常强大的监督学习算法,它在许多问题领域都有广泛的应用。以下是SVM能够解决的一些主要问题:
-
二分类问题:SVM最初是用于二分类问题的,它可以有效地将数据划分为两个类别,并找到最优的超平面以实现最大间隔分类。
-
多分类问题:虽然SVM最初是为二分类设计的,但可以使用一些技巧来扩展它以解决多分类问题,例如一对一(One-vs-One)或一对其他(One-vs-Rest)策略。
-
线性可分问题:当数据可以通过一个超平面完全分割成两个类别时,SVM表现最好。
-
线性不可分问题:通过使用核函数,SVM可以处理线性不可分的情况,将数据映射到更高维的特征空间中,使其变得线性可分。
-
回归问题:SVM也可以用于解决回归问题。通过引入一个适当的损失函数和辅助变量,SVM可以拟合数据并找到一个最优的超平面,以尽量减小预测值与真实值之间的误差。
-
异常检测:SVM在异常检测中也有应用。它可以识别与其他样本不同的样本,这些样本可能是异常值或异常行为。
-
文本分类:SVM在文本分类问题中也非常常见,例如垃圾邮件检测、情感分析等。
-
图像分类:SVM也可以用于图像分类任务,例如图像识别、人脸识别等。
总的来说,SVM是一种多功能的机器学习算法,适用于多种类型的问题,尤其在高维空间中或者数据量较小的情况下表现良好。
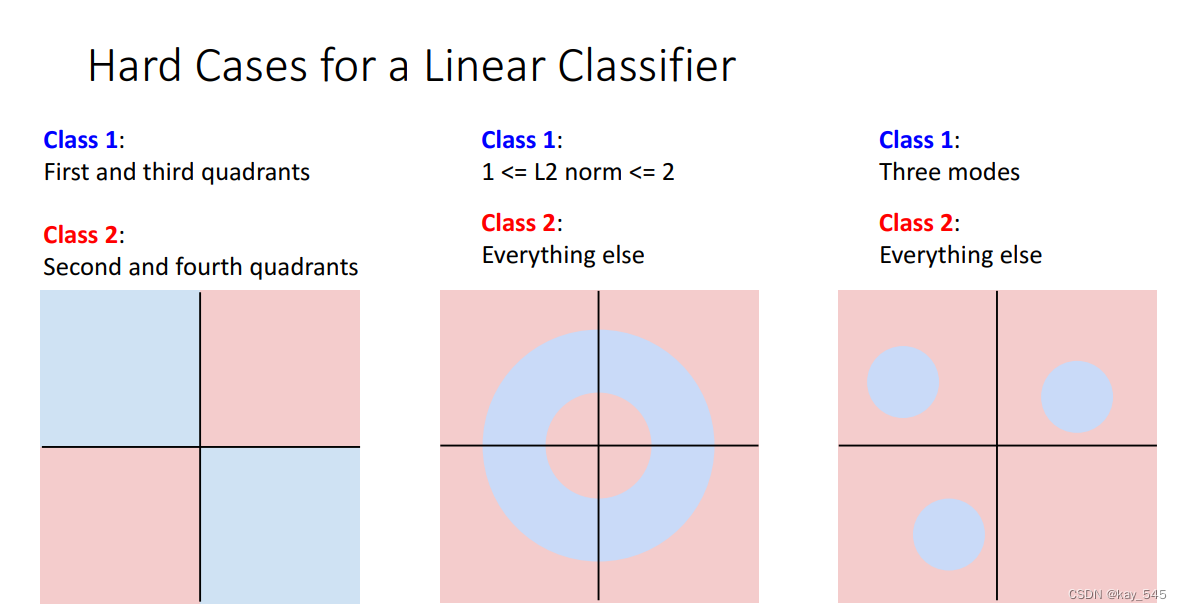
15.4 核函数的作用以及特点
支持向量机(SVM)通过核函数将输入空间映射到更高维的特征空间,这使得SVM能够解决非线性分类问题。核函数在SVM中具有重要的作用和特点,让我们来详细看看:
作用:
-
处理非线性问题:核函数允许SVM在高维特征空间中构建线性分割超平面,即使在原始输入空间中不存在线性分割的情况下也能有效分类。
-
提高分类性能:通过核技巧,SVM可以利用更复杂的超平面进行分类,这通常可以提高分类器的性能。
-
减少特征工程的需求:在不使用核函数时,为了使数据线性可分,通常需要手动进行特征工程来提取更高维度的特征。而使用核函数,可以直接在原始数据上进行操作,减少了特征工程的需求。
-
处理高维数据:核函数使得SVM在高维特征空间中能够更好地处理数据,这在许多现实世界的问题中非常有用,例如图像分类或自然语言处理。
特点:
-
计算高效性:良好的核函数可以大幅提高SVM的计算效率。一些核函数,如线性核函数和径向基函数(RBF)核函数,计算效率较高,适用于大规模数据集。
-
拟合能力:不同的核函数对数据的拟合能力不同。一些核函数可能对某些类型的数据更适用,因此在选择核函数时需要考虑数据的特点和问题的需求。
-
通用性:一些核函数在不同的问题领域中都表现良好,具有较强的通用性,例如RBF核函数。而有些核函数可能更适合特定类型的数据或特定的问题。
-
超参数调节:核函数通常有一些超参数需要调节,例如RBF核函数的 γ \gamma γ 参数。调节这些超参数可以影响SVM的性能和泛化能力,因此需要进行适当的调优。
总的来说,核函数是SVM的关键组成部分,它们允许SVM在高维空间中进行有效的分类,并且可以适应各种类型的数据和问题。选择合适的核函数以及调节相应的参数对于SVM的性能和表现至关重要。
15.5 核函数的表达式
当谈到支持向量机(SVM)时,有几种常见的核函数,每种核函数都有其独特的特点和适用范围。以下是一些常见的核函数及其表达式,以Markdown格式列出:
| 核函数名称 | 表达式 |
|---|---|
| 线性核函数 (Linear Kernel) | K ( x , x ′ ) = x T x ′ K(x, x') = x^T x' K(x,x′)=xTx′ |
| 多项式核函数 (Polynomial Kernel) | K ( x , x ′ ) = ( x T x ′ + c ) d K(x, x') = (x^T x' + c)^d K(x,x′)=(xTx′+c)d |
| 高斯核函数 (Gaussian Kernel, RBF) | K ( x , x ′ ) = e − γ ∣ x − x ′ ∣ 2 K(x, x') = e^{-\gamma |x - x'|^2} K(x,x′)=e−γ∣x−x′∣2 |
| Sigmoid核函数 (Sigmoid Kernel) | K ( x , x ′ ) = tanh ( α x T x ′ + c ) K(x, x') = \tanh(\alpha x^T x' + c) K(x,x′)=tanh(αxTx′+c) |
这些是最常见的核函数之一。线性核函数适用于线性可分的情况,多项式核函数和高斯核函数可以处理非线性问题,而Sigmoid核函数有时也被用于一些特定的情况。每种核函数都有其自己的一组参数,如多项式核函数中的 (c) 和 (d),以及高斯核函数中的 (\gamma)。选择合适的核函数和参数对于SVM的性能和泛化能力至关重要。
15.6 SVM为什么引入对偶问题
SVM 引入对偶问题是为了解决原始问题在优化过程中可能面临的一些挑战,以及为了更好地理解和优化问题。
主要原因包括:
-
计算效率:原始问题通常涉及对权重向量和偏置项的优化,这样的问题通常是一个带有约束的凸二次规划问题。解决这样的问题可能需要复杂的数值优化技术,计算量较大。而对偶问题通过引入拉格朗日乘子,可以将原始问题转化为一个更简单的形式,使得更容易求解。
-
理论分析:对偶问题在理论分析上更容易处理。通过对对偶问题进行分析,我们可以得到一些关于原始问题的性质和解的性质的洞见,例如 KKT 条件。这有助于更深入地理解问题的本质和解的特性。
-
核方法的应用:对偶问题的形式使得核方法(kernel methods)更容易应用。在对偶问题中,内积的计算被表示为核函数的形式,这使得我们可以将数据映射到更高维的特征空间中进行处理,而无需显式地计算出映射后的特征向量。
-
解决线性不可分问题:对偶问题形式使得引入核函数变得自然和方便。通过核函数,我们可以将原始问题中的特征空间映射到更高维的空间中,从而使得线性不可分的问题变为线性可分的问题。
综上所述,引入对偶问题能够简化优化问题的求解过程,同时也有助于更深入地理解问题的本质和应用核方法进行高效的非线性分类。
15.7 SVM使用SGD及步骤
支持向量机(SVM)可以用随机梯度下降(SGD)进行训练。SGD是一种优化算法,用于寻找损失函数的最小值,其每次更新参数时只使用一个样本或一小批样本,而不是全部数据。虽然SGD通常用于训练大规模数据集上的模型,但也可以应用于SVM的优化过程中。
SGD在SVM中的应用通常涉及以下几个步骤:
-
定义损失函数:首先需要定义SVM的损失函数,通常使用hinge loss(合页损失)。
-
随机抽样:从训练数据中随机抽取一个样本或一小批样本。
-
计算梯度:根据当前参数和选取的样本,计算损失函数关于参数的梯度。
-
更新参数:使用计算得到的梯度来更新参数,减小损失函数的值。
-
迭代:重复执行2至4步,直到达到停止条件(例如达到最大迭代次数或损失函数收敛)。
虽然SGD可以用于SVM的训练,但与传统的优化方法(如序列最小优化算法)相比,它可能收敛速度较慢,并且需要更仔细地调整学习率和其他超参数以获得良好的性能。此外,SGD在处理非线性核函数时可能需要更多的技巧和调整。
总的来说,尽管SVM可以使用SGD进行训练,但在实践中可能需要更多的调优和注意事项,以确保收敛性和性能。
15.8 为什么SVM对缺失数据敏感
支持向量机(SVM)对于缺失数据的敏感性主要源自其优化目标和核函数的计算方式。
-
优化目标的定义:SVM的优化目标是找到一个最大间隔超平面,使得所有数据点都被正确分类。如果数据中存在缺失值,这可能导致超平面的位置被不完整的数据影响,从而使得最终分类效果受到影响。
-
核函数的计算:在使用核函数时,SVM通常会涉及计算数据点之间的内积,例如在高斯核函数中。如果存在缺失值,计算数据点之间的内积将会受到影响,因为无法直接计算缺失值的内积。即使在填充缺失值后,由于填充的值可能并不准确或合理,计算出的内积也可能不具备合适的特征。
-
缺失数据处理:在实践中,SVM通常要求输入数据是完整的,因为SVM本身并不具备处理缺失值的机制。因此,处理缺失数据可能需要先进行填充或者删除操作,这可能导致数据信息的丢失或者不准确性。
综上所述,SVM对于缺失数据敏感是由于其对数据完整性的要求以及核函数计算的特性。在应用SVM时,需要注意处理缺失数据的方法,以确保模型的性能和稳定性。
15.9 SVM怎么防止过拟合
支持向量机(SVM)是一种强大的分类器,但同样也容易受到过拟合的影响。以下是一些防止SVM过拟合的方法:
-
正则化参数调节:SVM有一个正则化参数 ( C ),它控制着模型的复杂度。增加 ( C ) 的值会导致模型更倾向于对训练数据拟合,可能会增加过拟合的风险。因此,可以通过交叉验证等方法来调节 ( C ) 的值,以避免过拟合。
-
数据预处理:数据预处理是防止过拟合的重要步骤之一。包括特征缩放、特征选择和降维等技术。通过对数据进行预处理,可以减少特征的数量,降低模型的复杂度,从而降低过拟合的风险。
-
交叉验证:使用交叉验证可以评估模型的泛化能力,并且选择合适的超参数。通过将数据划分为训练集和验证集,并在不同的训练集上训练模型,然后在验证集上评估模型性能,可以更好地了解模型在未见过数据上的表现。
-
核函数选择:选择合适的核函数也是防止过拟合的重要因素。一些核函数,如高斯核函数(RBF),可能更容易导致过拟合,因为它们有更多的自由度。在选择核函数时,应该根据数据的特性和问题的需求进行权衡。
-
减少特征维度:如果特征空间过于庞大,可能会增加过拟合的风险。因此,可以通过特征选择、降维或者正则化等方法来减少特征维度,从而降低模型的复杂度。
-
集成学习方法:使用集成学习方法,如随机森林或梯度提升树等,可以降低单个模型过拟合的风险。通过组合多个模型的预测结果,可以减少单个模型的偏差和方差,提高整体的泛化能力。
相关文章:
百面算法工程师 | 支持向量机——SVM
文章目录 15.1 SVM15.2 SVM原理15.3 SVM解决问题的类型15.4 核函数的作用以及特点15.5 核函数的表达式15.6 SVM为什么引入对偶问题15.7 SVM使用SGD及步骤15.8 为什么SVM对缺失数据敏感15.9 SVM怎么防止过拟合 欢迎大家订阅我的专栏一起学习共同进步 祝大家早日拿到offer&#x…...

关于YOLO8学习(一)环境搭建,官方检测模型部署到手机
一,环境的搭建 环境 win10 python 3.11 cmake pytorch pycharm 过程 首先安装好一个pycharm,这里就不一一叙述了。 其次,选择好一个python版本,是关键所在。有些YOLO的版本,并不支持很高的python版本,博主选用的是python3.11版本。经过实际的测试,这个版本比较合适。…...
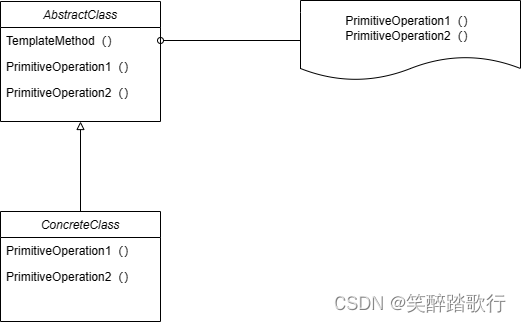
3.10设计模式——Template Method 模版方法模式(行为型)
意图 定义一个操作中的算法骨架,而将一些步骤延迟到子类中,Template Method 使得子类可以不改变一个算法的结构即可重新定义该算法的某些特定步骤。 结构 AbstractClass(抽象类)定义抽象的原语操作,具体的子类将重定…...

SQL 基础 | UNION 用法介绍
在SQL中,UNION操作符用于合并两个或多个SELECT语句的结果集,形成一个新的结果集。 使用UNION时,合并的结果集列数必须相同,并且列的数据类型也需要兼容。 默认情况下,UNION会去除重复的行,只保留唯一的行。…...

学习如何使用PyQt5实现notebook功能
百度搜索“pyqt5中notebook控件”,AI自动生成相应例子的代码。在 PyQt5 中,QTabWidget 类被用作 Notebook 控件。以下是一个简单的示例,展示如何创建一个带有两个标签的 Notebook 控件,并在每个标签中放置一些文本。 import sys f…...

Python氮氧甲烷乙烷乙烯丙烯气体和固体热力学模型计算
🎯要点 🎯固体和粒子:计算二态系统、简谐振子和爱因斯坦固体的内能和比热,比较爱因斯坦固体和德拜固体。模拟多个粒子的一维和二维随机游走,在数值上确认方差的线性趋势,模拟多个粒子的梯度下降࿰…...

2024-04-30 区块链-以太坊-相关文档
摘要: 2024-04-30 区块链-以太坊-文档 以太坊-相关文档: https://github.com/ethereum/go-ethereum https://geth.ethereum.org/ https://geth.ethereum.org/docs https://ethereum.org/zh/ 以太坊开发文档 | ethereum.org 以太坊开发文档_w3cschool 以太坊开发文档 基础主题 …...

你用过最好用的AI工具有哪些?
你用过最好用的AI工具有哪些? 人工智能(AI)工具正在逐渐成为我们日常生活中不可或缺的助手,它们通过提供智能化服务,极大地提升了我们的工作效率和生活质量。以下是一些广泛使用的AI工具和应用,以及它们所…...
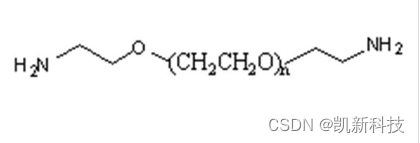
Amine-PEG-Amine,956496-54-1在生物成像、生物传感器等领域具有广泛的应用
【试剂详情】 英文名称 Amine-PEG-Amine,NH2-PEG-NH2 中文名称 氨基-聚乙二醇-氨基,氨基PEG氨基, 双端氨基聚乙二醇 CAS号 956496-54-1 外观性状 由分子量决定,液体或者固体 分子量 0.4k,0.6k,1k&…...
”)
为什么深度学习中减小泛化误差称为“正则化(Regularization)”
深度学习的一个重要方面是正则化(Regularization),Ian Goodfellow在《Deep Learning 》称正则化(Regularization)就是减小泛化误差。那么,为什么减小泛化误差称为正则化呢? 首先看正则化——Re…...
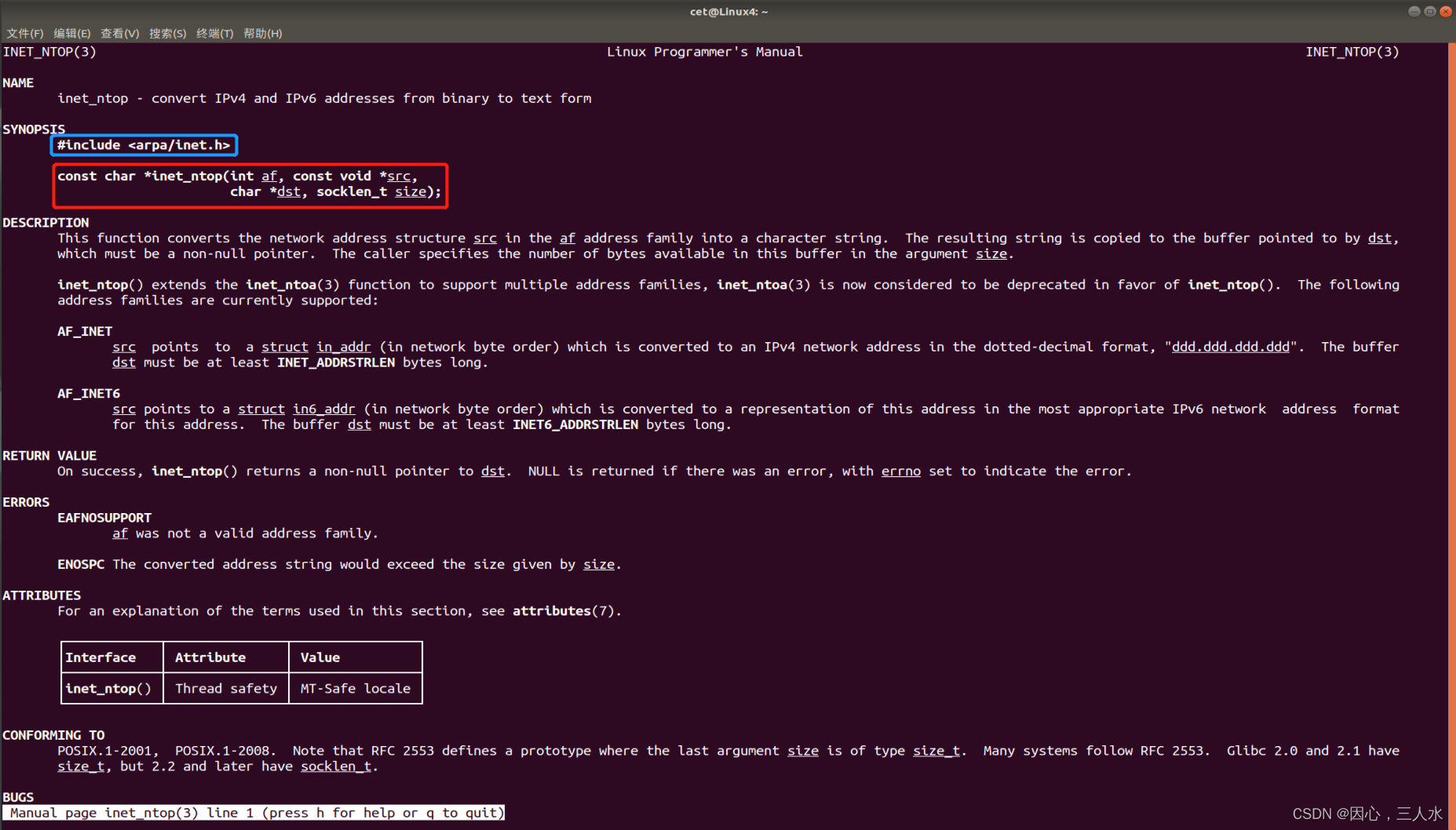
【Linux网络编程】2.套接字、网络字节序、IP地址转换函数
目录 网络套接字 网络字节序 网络字节序和主机字节序的转换 IP地址转换函数 inet_pton 参数af 参数src 参数dst 返回值 inet_ntop 参数af 参数src 参数dst 参数size 返回值 网络套接字 socket,一个文件描述符指向一个套接字,该套接字内部…...
代码签名证书的工作原理和申请流程
随着软件分发渠道的多样化和黑客攻击手段的不断升级,确保软件的真实性和完整性变得尤为重要。这正是代码签名证书(Code Signing Certificate)发挥关键作用的领域。本文将深入探讨代码签名证书的基础概念、工作原理、重要性以及申请和使用流程…...

Python中的yield
文章目录 1. Python中的yield1.1 一个简单的示例1.2 示例的每一步含义 2. yield 和return的区别2.1 一个简单的示例2.2 示例中每一步的含义 3. yield中的send()方法3.1 一个简单的示例3.2 示例中每一步的含义 4. yield中的throw()方法4.1 一个简单的示例4.2 示例中每一步的含义…...

【Linux】基于 Jenkins+shell 实现更新服务所需文件 -->两种方式:ssh/Ansible
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支…...

5月4(信息差)
🎄 HDMI ARC国产双精度浮点dsp杜比数码7.1声道解码AC3/dts/AAC环绕声光纤、同轴、USB输入解码板KC33C 🌍 国铁集团回应高铁票价将上涨 https://finance.eastmoney.com/a/202405043066422773.html ✨ 源代码管理平台GitLab发布人工智能编程助手DuoCha…...

【Spring】1.Spring中IOC与DI全解析
本节将详细介绍Spring框架的两个核心概念:控制反转(IOC)和依赖注入(DI)。首先,我们会探讨IOC和DI的定义,实现原理,优点和缺点。然后,我们将介绍如何在Spring中使用IOC和D…...
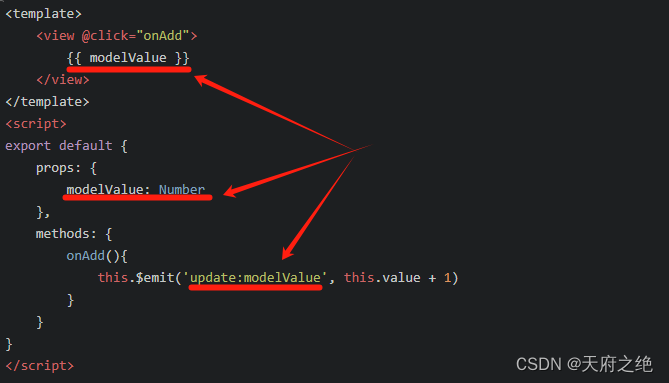
vue2迁移到vue3,v-model的调整
项目从vue2迁移到vue3,v-model不能再使用了,需要如何调整? 下面只提示变化最小的迁移,不赘述vue2和vue3中的常规写法。 vue2迁移到vue3,往往不想去调整之前的代码,以下就使用改动较小的方案进行调整。 I…...

【C语言】解决不同场景字符串问题:巧妙运用字符串函数
🌈个人主页:是店小二呀 🌈C语言笔记专栏:C语言笔记 🌈C笔记专栏: C笔记 🌈喜欢的诗句:无人扶我青云志 我自踏雪至山巅 文章目录 一、字符函数1.1 字符分类函数1.1.1 islower1.1.2 isupper 1.…...

android 如何显示网络地址对应的图片
1.android 如何显示网络地址对应的图片 在Android中显示网络地址对应的图片,通常有多种方法可以实现。以下是几种常见的方法: 1. 使用ImageView和Picasso库 Picasso是一个强大的图片加载库,它可以方便地加载网络图片并显示到ImageView中。 …...
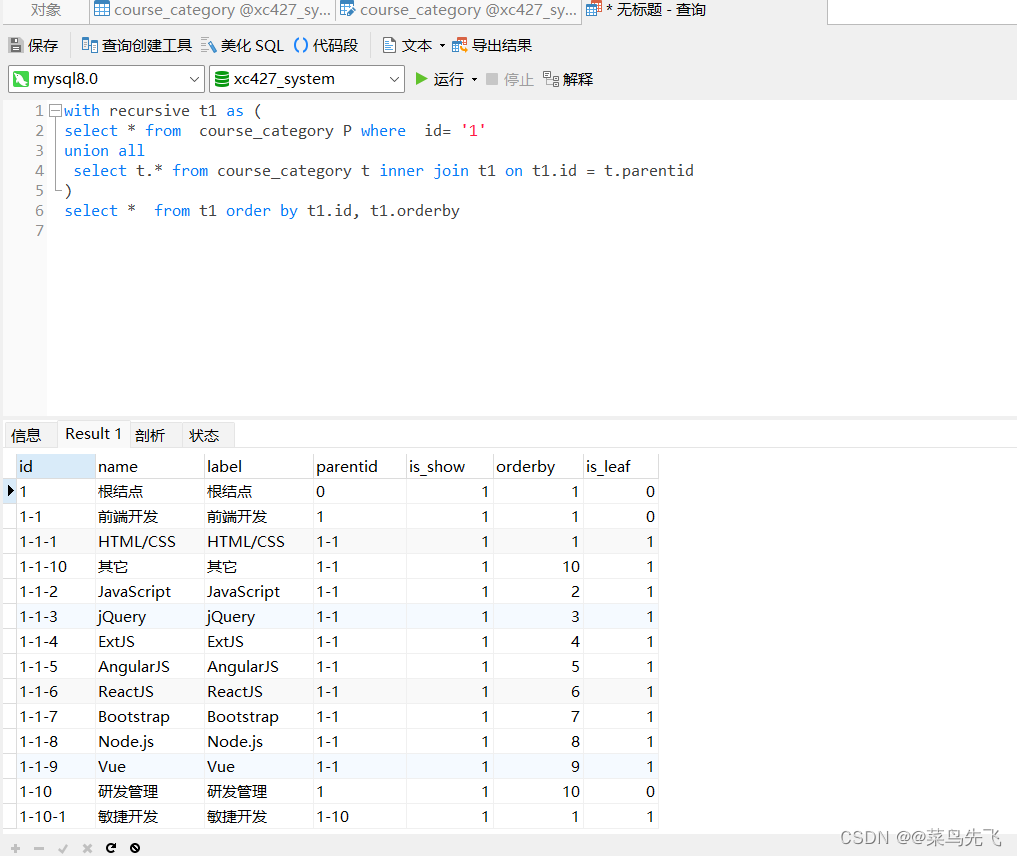
【项目学习01_2024.05.02_Day04】
学习笔记 4 课程分类查询4.1需求分析4.2 接口定义4.3 接口开发4.3.1 树型表查询4.3.2 开发Mapper 4 课程分类查询 4.1需求分析 有课程分类的需求 course_category课程分类表的结构 这张表是一个树型结构,通过父结点id将各元素组成一个树。 利用mybatis-plus-gen…...

Wan2.2-I2V-A14B部署教程:NVIDIA MPS多进程服务共享GPU资源方案
Wan2.2-I2V-A14B部署教程:NVIDIA MPS多进程服务共享GPU资源方案 1. 镜像概述与核心特性 Wan2.2-I2V-A14B是一款专为文本生成视频任务优化的私有部署镜像,特别针对RTX 4090D 24GB显存显卡进行了深度优化。这个镜像最大的特点是内置了完整的运行环境和模…...

TinyUPnP:嵌入式设备轻量级UPnP端口映射实现
1. TinyUPnP:面向嵌入式平台的轻量级UPnP IGD客户端实现 TinyUPnP 是一个专为资源受限嵌入式系统设计的极简 UPnP(Universal Plug and Play)Internet Gateway Device(IGD)客户端库,核心目标是 在无用户干预…...

SpringAI集成Ollama实战:从零构建本地AI对话服务
1. 环境准备:搭建Ollama本地AI模型服务 想要在本地运行AI对话服务,首先需要部署Ollama这个轻量级的大模型运行环境。Ollama最大的优势在于它能让开发者在普通配置的电脑上就能运行各种开源大模型,而不需要昂贵的GPU服务器。 安装过程非常简单…...

终极OpenCore EFI自动化配置指南:OpCore-Simplify让你15分钟完成专业级黑苹果配置
终极OpenCore EFI自动化配置指南:OpCore-Simplify让你15分钟完成专业级黑苹果配置 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复…...

别再为MoveIt安装发愁了!Ubuntu 20.04 + ROS Noetic 保姆级配置全流程
别再为MoveIt安装发愁了!Ubuntu 20.04 ROS Noetic 保姆级配置全流程 刚接触ROS和机械臂控制时,MoveIt的安装过程就像一道难以逾越的门槛。记得我第一次尝试配置时,整整两天都卡在依赖报错和环境变量设置上。本文将带你用最稳妥的方式&#x…...

3步搞定电脑风扇噪音!FanControl风扇控制软件完全指南,让你的电脑从此安静如新!
3步搞定电脑风扇噪音!FanControl风扇控制软件完全指南,让你的电脑从此安静如新! 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项…...

Qwerty Learner设计系统构建:组件库与样式指南终极指南
Qwerty Learner设计系统构建:组件库与样式指南终极指南 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https://gi…...

免费开源AI绘画工具推荐:Z-Image-Turbo,照片级质量,消费级显卡友好
免费开源AI绘画工具推荐:Z-Image-Turbo,照片级质量,消费级显卡友好 1. 为什么选择Z-Image-Turbo 在众多开源AI绘画工具中,Z-Image-Turbo以其独特的优势脱颖而出。作为阿里巴巴通义实验室开源的高效文生图模型,它完美…...
)
别再硬编码了!用注解+工厂模式,5分钟为你的Java应用扩展一个新PLC协议(ModbusTCP/S7为例)
工业物联网中Java协议扩展的优雅实践:注解驱动与工厂模式深度整合 工业物联网(IIoT)平台的开发者们经常面临一个棘手问题:如何在不重构核心代码的情况下,快速接入各种PLC设备协议?想象一下这样的场景:你的系统已经稳定…...

安装lsaac lab
在 Ubuntu 22.04 环境下,使用 Conda 管理 Isaac Lab 是最稳妥的方案,因为它可以完美隔离 Isaac Sim 所需的特定 Python 版本环境。以下是基于 Conda 的保姆级安装步骤:第一步:创建 Conda 环境Isaac Sim 4.x 需要 Python 3.10&…...