OpenAI发布GPT-4.0使用指南
大家好,ChatGPT 自诞生以来,凭借划时代的创新,被无数人一举送上生成式 AI 的神坛。在使用时,总是期望它能准确理解我们的意图,却时常发现其回答或创作并非百分之百贴合期待。这种落差可能源于我们对于模型性能的过高期望,亦或者在使用时未能找到最有效的沟通途径。
正如探险者需要时间适应新的地形,与 ChatGPT 的互动也需要耐心和技巧,此前 OpenAI 官方发布了 GPT-4 使用指南 Prompt engineering,这里面记载了驾驭 GPT-4 的六大策略,本文将对其进行介绍,助力与 ChatGPT 的交互沟通。
1.写出清晰指令
描述详细的信息
ChatGPT 无法判断我们隐含的想法,所以应该尽可能明确告知要求,如回复的长短、写作的水平、输出的格式等。越少让 ChatGPT 去猜测和推断意图,输出结果满足要求的可能性越大。例如,当让他写一篇心理学的论文,给出的提示词应该长这样:
请帮助我撰写一篇有关「抑郁症的成因及治疗方法」的心理学论文,要求:需要查询相关文献,不能抄袭或剽窃;需要遵循学术论文格式,包括摘要、引言、正文、结论等部分;字数 2000 字以上。

让模型扮演某个角色
术业有专攻,指定模型扮演专门的角色,它输出的内容会显得更加专业。
例如:请你扮演一名警探小说家,用柯南式推理描述一起离奇命案。要求:需匿名处理,字数 1000 字以上,剧情跌宕起伏。
使用分隔符清楚地划分不同部分
三引号、XML 标签、节标题等分隔符可以帮助划分需要区别对待的文本节,帮助模型更好地消除歧义。

指定完成任务所需的步骤
将部分任务拆成一系列条例清晰的步骤,这样更有利于模型执行这些步骤。

提供示例
提供适用于所有示例的一般性说明通常比通过示例演示更有效,但在某些情况下提供示例可能更容易。
如果告诉模型要学会游泳,只需要踢腿和摆动手臂,这就是一个一般性的说明。而如果给模型展示一个游泳的视频,展示踢腿和摆动手臂的具体动作,那就是通过示例来说明。
指定输出长度
我们可以告诉模型,希望它生成的输出有多长,这个长度可以以单词、句子、段落、要点等方式进行计数。
受限于模型内部机制和语言复杂性的影响,最好还是按照段落、要点来划分,这样效果才会比较好。
2.提供参考文本
让模型使用参考文本回答
假如我们手头上有更多参考信息,可以「喂」给模型,并让模型使用提供的信息来回答。

让模型引用参考文本来回答
如果输入中已经包含了相关的知识文档,用户可以直接要求模型通过引用文档中的段落来为其答案添加引用,尽可能减少模型胡说八道的可能性。
在这种情况下,输出中的引用还可以通过编程方式验证,即通过对所提供文档中的字符串进行匹配来确认引用的准确性。

3.复杂任务拆分简单子任务
使用意图分类来识别与用户查询最相关的指令
处理那些需要很多不同操作的任务时,可以采用一个比较聪明的方法。首先把问题分成不同的类型,看看每一种类型需要什么操作,这就好像在整理东西时,先把相似的东西放到一起。
接着可以给每个类型定义一些标准的操作,就像给每类东西贴上标签一样,这样一来,就可以事先规定好一些常用的步骤,比如查找、比较、了解等。
而这个处理方法可以一层层地递进,如果想提出更具体的问题,就可以根据之前的操作再进一步细化。这么做的好处是,每次回答用户问题时,只需要执行当前步骤需要的操作,而不是一下子把整个任务都做了。这不仅可以减少出错的可能性,还能更省事,因为一次性完成整个任务的代价可能比较大。

处理很长对话应用场景的简化
模型在处理对话时,受制于固定的上下文长度,不能记住所有的对话历史。想要解决这个问题,其中一种方法是对之前的对话进行总结,当输入的对话长度达到一定的限制时,系统可以自动总结之前的聊天内容,将一部分信息作为摘要显示,或者可以在对话进行的同时,在后台悄悄地总结之前的聊天内容。
另一种解决方法是在处理当前问题时,动态地选择与当前问题最相关的部分对话,这个方法涉及到一种叫做「使用基于嵌入的搜索来实现高效的知识检索」的策略。
简单来说,就是根据当前问题的内容,找到之前对话中与之相关的部分。这样可以更有效地利用之前的信息,让对话变得更有针对性。
分段总结长文档并递归构建完整摘要
由于模型只能记住有限的信息,不能直接用来总结很长的文本,为了总结长篇文档,可以采用一种逐步总结的方法。
就像阅读一本书时,可以通过一章又一章地提问来总结每个部分。每个部分的摘要可以串联起来,形成对整个文档的概括。这个过程可以一层一层地递归,一直到总结整个文档为止。
如果需要理解后面的内容,可能会用到前面的信息。在这种情况下,另一个有用的技巧是在阅读到某一点之前,先看一下摘要,并了解这一点的内容。
4.给模型时间思考
指示模型得出结论前提供解决方案
有时直接让模型判断学生的答案,它可能判断不准确,为了让模型更准确,可以先让模型自己做一下这个数学题,先算出模型自己的答案来,然后再让模型对比一下学生的答案和模型自己的答案。
先让模型自己计算,它就更容易判断出答案,让模型从最基本的第一步开始思考,而不是直接判断答案,可以提高模型的判断准确度。

使用内心独白隐藏模型的推理过程
有时候在回答特定问题时,模型详细地推理问题是很重要的。但对于一些应用场景,模型的推理过程可能不适合与用户共享。
为了解决这个问题,有一种策略叫做内心独白。这个策略的思路是告诉模型把原本不想让用户看到的部分输出整理成结构化的形式,然后在呈现给用户时,只显示其中的一部分,而不是全部。
例如,假设我们在教某个学科,要回答学生的问题,如果直接把模型的所有推理思路都告诉学生,学生就不用自己琢磨了,所以我们可以用内心独白这个策略:先让模型完整思考问题,把解决思路都想清楚,然后只选择模型思路中的一小部分,用简单的语言告诉学生。
或者可以设计一系列的问题:先只让模型自己想整个解决方案,不让学生回答,然后根据模型的思路,给学生出一个简单的类似问题,学生回答后,让模型评判学生的答案对不对。最后模型用通俗易懂的语言,给学生解释正确的解决思路,这样就既训练了模型的推理能力,也让学生自己思考,不会把所有答案直接告诉学生。

询问模型是否遗漏内容
假设让模型从一个很大的文件里,找出跟某个问题相关的句子,模型会将句子告诉我们。但有时候模型判断失误,在本来应该继续找相关句子的时候就停下来了,导致后面还有相关的句子被漏掉。
这个时候,就可以询问模型是否还有其他相关的句子,接着它就会继续查询相关句子,模型就能找到更完整的信息。
5.使用外部工具
使用基于嵌入的搜索实现高效的知识检索
如果在模型的输入中添加一些外部信息,模型就能更聪明地回答问题。比如,用户问有关某部电影的问题,可以把电影的一些重要信息(比如演员、导演等)输入到模型里,这样模型就能给出更准确的答案。
文本嵌入是一种能够度量文本之间关系的向量。相似或相关的文本向量更接近,而不相关的文本向量则相对较远,这意味着我们可以利用嵌入来高效地进行知识检索。
具体来说,我们可以把文本语料库切成块,对每个块进行嵌入和存储。然后,我们可以对给定的查询进行嵌入,并通过矢量搜索找到在语料库中最相关的嵌入文本块(即在嵌入空间中最接近查询的文本块)。
使用代码执行准确计算或调用外部 API
语言模型并不总是能够准确地执行复杂的数学运算或需要很长时间的计算,在这种情况下可以告诉模型写一些代码来完成任务,而不是让它自己去做计算。
具体做法是,可以指导模型把需要运行的代码按照一定的格式写下,比如用三重反引号包围起来。当代码生成结果后,提取出来并执行。
最后,可以把代码执行引擎(比如 Python 解释器)的输出当作模型下一个问题的输入,这样就能更有效地完成一些需要计算的任务。

另一个很好的使用代码执行的例子是使用外部 API(应用程序编程接口),如果告诉模型如何正确使用某个 API,它就可以写出能够调用该 API 的代码。
可以给模型提供一些展示如何使用 API 的文档或者代码示例,引导模型学会利用这个 API。简单说,通过给模型提供一些关于 API 的指导,它就能够创建代码,实现更多的功能。

警告:执行由模型生成的代码本质上是不安全的,任何尝试执行此操作的应用程序都应该采取预防措施,需要使用沙盒代码执行环境来限制不受信任的代码可能引起的潜在危害。
让模型提供特定功能
通过 API 请求,向模型传递一个描述功能的清单,进而能够根据提供的模式生成函数参数。生成的函数参数将以 JSON 格式返回,再利用它来执行函数调用。
把函数调用的输出反馈到下一个请求中的模型里,就可以实现一个循环,这就是使用 OpenAI 模型调用外部函数的推荐方式。
6.系统测试变更
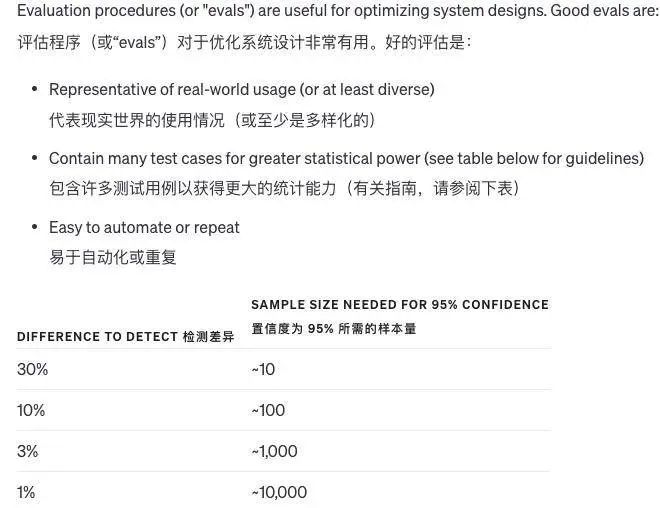
对一个系统做修改时,很难判断这些修改是好是坏,有时候修改在某些情况下是好的,在其他情况下是坏的。
为了评价系统输出的质量,若问题只有一个标准答案,计算机可以自动判断对错,没有标准答案可以用其他模型来判断质量。
此外可以让人工来评价主观的质量,又或者计算机和人工结合评价当问题的答案很长时,不同的答案质量差别不大,这时就可以让模型来评价质量。
随着模型变得更先进,可以自动评价的内容会越来越多,需要人工评价的越来越少,评价系统的改进非常难,结合计算机和人工是最好的方法。
在和 ChatGPT 人机交流的过程中,提示词看似简单,却又是最为关键的存在。在数字时代,提示词是拆分需求的起点,通过设计巧妙的提示词,我们可以将整个任务拆分成一系列简明的步骤。
这样的分解不仅有助于模型更好地理解用户的意图,同时也为用户提供了更为清晰的操作路径,就好像给定了一个线索,引导一步步揭开问题的谜底。
你我的需求如同涌动的江河,而提示词就像是调节水流方向的水闸,它扮演着枢纽的角色,连接着用户的思维与机器的理解。毫不夸张地说,一个好的提示词既是对用户深度理解的洞察,也是一种人机沟通的默契。
当然,要想真正掌握提示词的使用技巧,仅依靠 Prompt engineering 还远远不够,但 OpenAI 官方的使用指南总归提供了宝贵的入门指引。
相关文章:
OpenAI发布GPT-4.0使用指南
大家好,ChatGPT 自诞生以来,凭借划时代的创新,被无数人一举送上生成式 AI 的神坛。在使用时,总是期望它能准确理解我们的意图,却时常发现其回答或创作并非百分之百贴合期待。这种落差可能源于我们对于模型性能的过高期…...

【WEEK11】学习目标及总结【Spring Boot】【中文版】
学习目标: 学习SpringBoot 学习内容: 参考视频教程【狂神说Java】SpringBoot最新教程IDEA版通俗易懂员工管理系统 页面国际化登录功能展示员工列表增加员工修改员工信息删除及404处理 学习时间及产出: 第十一周MON~SAT 2024.5.6【WEEK11】…...
Unity 性能优化之图片优化(八)
提示:仅供参考,有误之处,麻烦大佬指出,不胜感激! 文章目录 前言一、可以提前和美术商量的事1.避免内存浪费(UI图片,不是贴图)2.提升图片性能 二、图片优化1.图片Max Size修改&#x…...
C++类细节,面试题02
文章目录 2. 虚函数vs纯虚函数3. 重写vs重载vs隐藏3.1. 为什么C可以重载? 4. 类变量vs实例变量5. 类方法及其特点6. 空类vs空结构体6.1. 八个默认函数:6.2. 为什么空类占用1字节 7. const作用7.1 指针常量vs常量指针vs常量指针常量 8. 接口vs抽象类9. 浅…...

Stylus的引入
Stylus是一个CSS预处理器,它允许开发者使用更高级的语法来编写CSS,并提供了一些额外的功能来简化和增强CSS的编写过程。以下是关于Stylus的详解和引入方法的详细介绍: 一、Stylus的详解 特点和功能: 变量:允许你定义…...
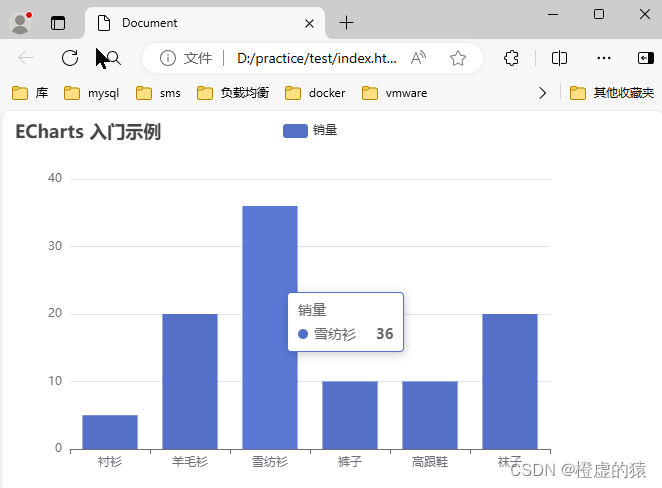
前端框架-echarts
Echarts 项目中要使用到echarts框架,从零开始在csdn上记笔记。 这是一个基础的代码,小白入门看一下 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" co…...
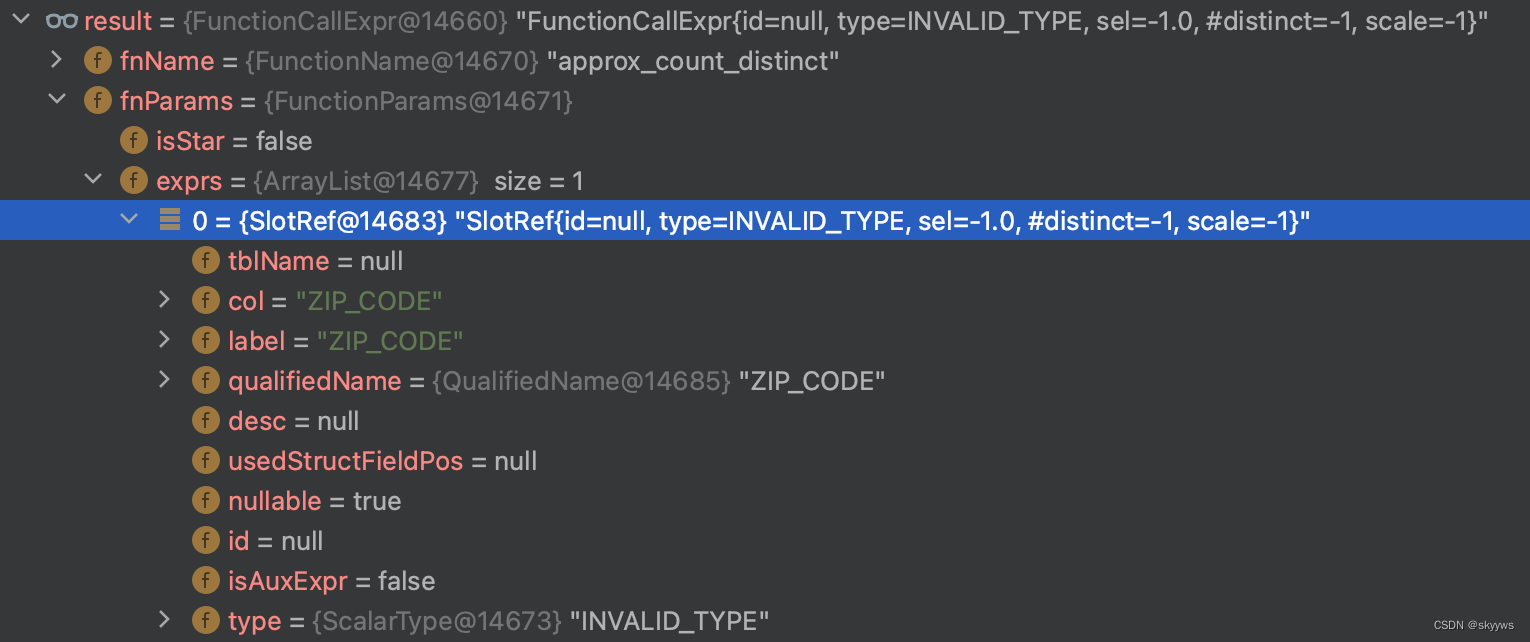
【StarRocks系列】 Trino 方言支持
我们在之前的文章中,介绍了 Doris 官方提供的两种方言转换工具,分别是 sql convertor 和方言 plugin。StarRocks 目前同样也提供了类似的方言转换功能。本文我们就一起来看一下这个功能的实现与 Doris 相比有何不同。 一、Trino 方言验证 我们可以通过…...
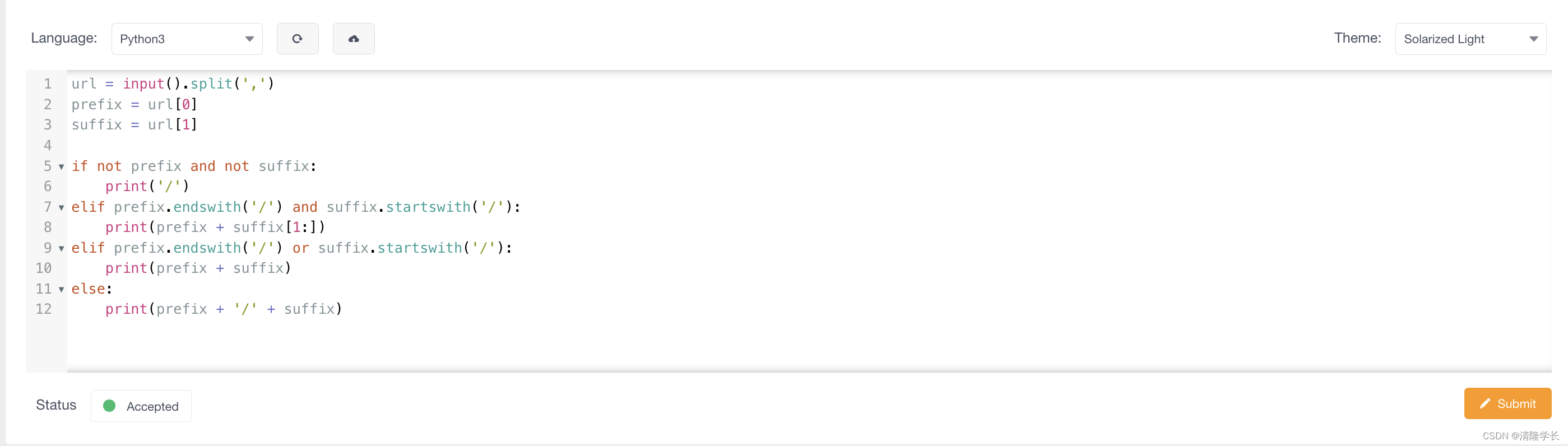
【2024最新华为OD-C卷试题汇总】URL拼接 (100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 文章目录 前…...

【ARM 嵌入式 C 字符串系列 23.7 -- C 实现函数 isdigit 和 isxdigit】
请阅读【嵌入式开发学习必备专栏 】 文章目录 isdigit 和 isxdigit C代码实现实现 isdigit实现 isxdigit使用示例 isdigit 和 isxdigit C代码实现 在C语言中,isdigit和isxdigit函数用于检查一个字符是否分别为十进制数字或十六进制数字。以下是这两个函数的简单实现…...
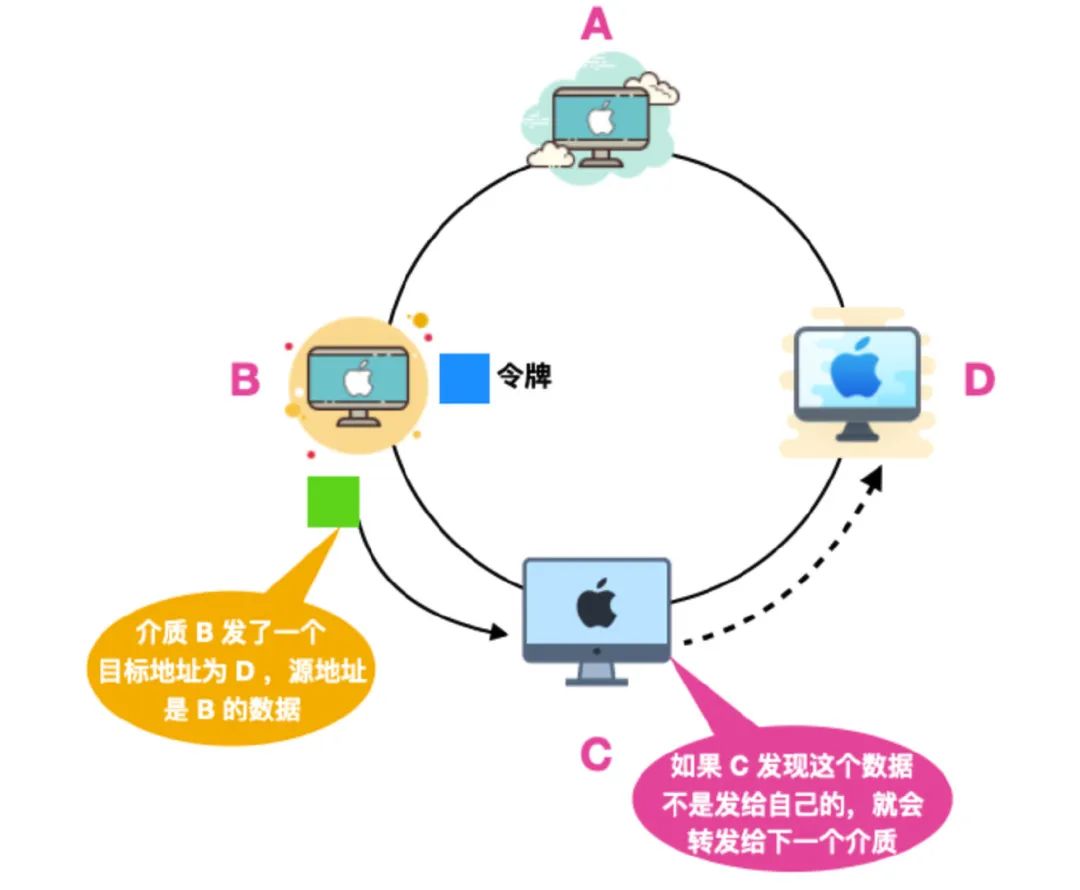
三分钟了解计算机网络核心概念-数据链路层和物理层
计算机网络数据链路层和物理层 节点:一般指链路层协议中的设备。 链路:一般把沿着通信路径连接相邻节点的通信信道称为链路。 MAC 协议:媒体访问控制协议,它规定了帧在链路上传输的规则。 奇偶校验位:一种差错检测方…...

数据结构===堆
文章目录 概要堆2条件大顶堆小顶堆 堆的实现插入元素删除堆顶元素 堆代码小结 概要 堆,有趣的数据结构。 那么,如何实现一个堆呢? 堆 堆,有哪些重点: 满足2条件大顶堆小顶堆 2条件 2条件: 堆是一个…...
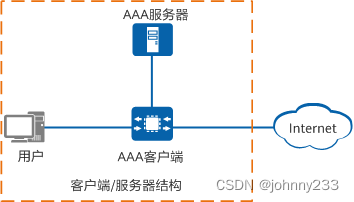
AAA、RADIUS、TACACS、Diameter协议介绍
准备软考高级时碰到的一个概念,于是搜集网络资源整理得出此文。 概述 AAA是Authentication、Authorization、Accounting的缩写简称,即认证、授权、记帐。Cisco开发的一个提供网络安全的系统。AAA协议决定哪些用户能够访问服务,以及用户能够…...
)
Nacos高频面试题及参考答案(2万字长文)
目录 Nacos是什么?它的主要功能有哪些? Nacos在微服务架构中扮演什么角色?...

CMakeLists.txt语法规则:条件判断中表达式说明四
一. 简介 前面学习了 CMakeLists.txt语法中的 部分常用命令,常量变量,双引号的使用。 前面几篇文章也简单了解了 CMakeLists.txt语法中的条件判断,文章如下: CMakeLists.txt语法规则:条件判断说明一-CSDN博客 CMa…...
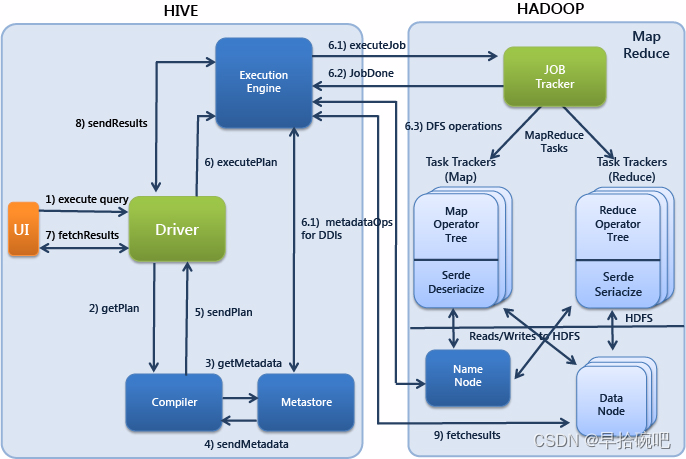
Hive概述
Hive简介 Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据. 它是Facebook在2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL(HiveSQL)语句作为数据访问接口. Hive可以做复查统计分析之类的工作; 利用hdfs的存储空间,进行结构化数据的存储; 利…...
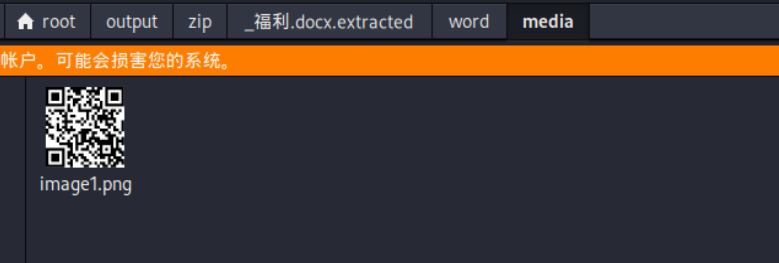
buuctf-misc-33.[BJDCTF2020]藏藏藏1
33.[BJDCTF2020]藏藏藏1 题目:藏了很多层,一层一层的剥开 常规思路,先使用010打开一下看看 binwalk不行用foremost 发现是pk文件也就是压缩包,并且包含了docx文件 这不binwalk分离一下文件?虽然可以看出有隐藏文件&…...

golang 基础知识细节回顾
之前学习golang的速度过于快,部分内容有点囫囵吞枣的感觉,写gorm过程中有很多违反我常识的地方,我通过复习去修正了我之前认知错误和遗漏的地方。 itoa itoa自增的作用在编辑error code时候作用很大,之前编辑springboot的error c…...

递归陷阱七例
目录 栈溢出 无限递归 大常数参数 递归深度过大 重复计算 函数调用开销 递归与迭代的选择 总结 递归是一种强大的编程技术,它允许函数调用自身。递归在很多情况下可以简化代码,使问题更容易理解和解决。然而,递归也容易导致一些常见的…...
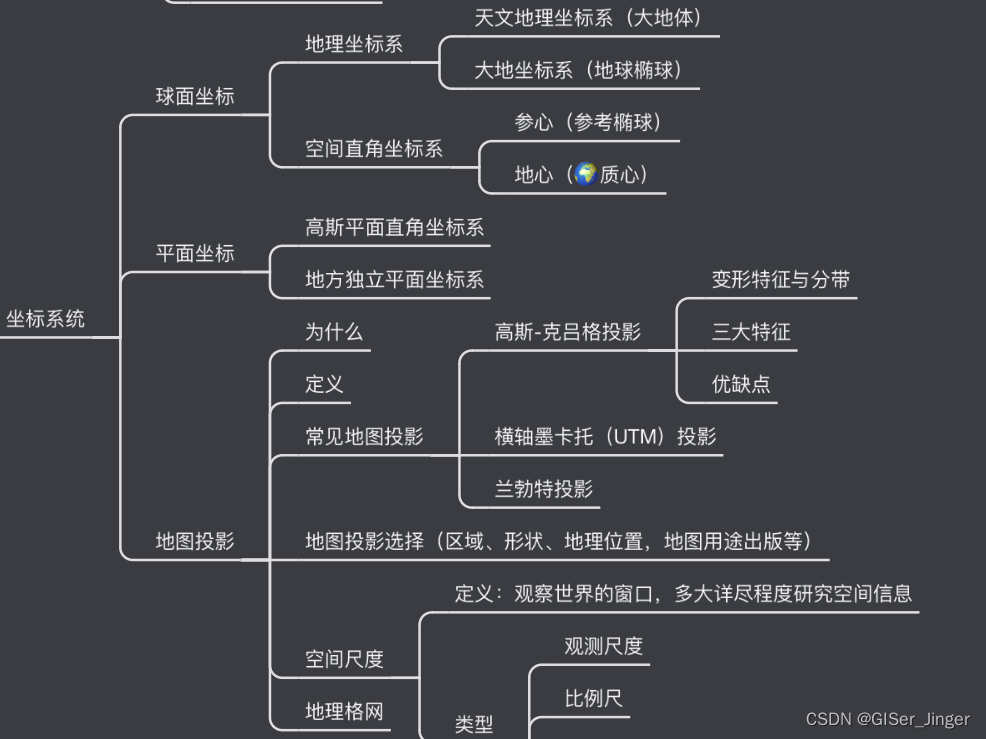
【3D基础】坐标转换——地理坐标投影到平面
汤国安版GIS原理第二章重点 1.常见投影方式 https://download.csdn.net/blog/column/9283203/83387473 Web Mercator投影(Web Mercator Projection): 优点: 在 Web 地图中广泛使用,易于显示并与在线地图服务集成。在…...

颈椎锻炼方式
1. 颈部伸展运动:坐直,慢慢将头向前伸展,直到感到轻微的拉伸,保持数秒钟,然后缓慢放松。重复10次。 2. 颈部旋转运动:坐直,慢慢将头向一侧转动,直到感到轻微的拉伸,保持…...

学Simulink——基于储能系统参与电网一次调频的下垂控制仿真示例
目录 手把手教你学Simulink——基于储能系统参与电网一次调频的下垂控制仿真示例 一、 引言:当“新能源浪潮”遇见“频率崩塌”——储能如何化身电网的“速效救心丸”? 二、 问题本质:一次调频的“核心挑战”与“协同逻辑” 1. 核心挑战 …...

如何用SketchUp STL插件轻松实现3D打印:从设计到实物的完整指南
如何用SketchUp STL插件轻松实现3D打印:从设计到实物的完整指南 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 你…...

嵌入式GUI设计:硬件选型与OpenGL优化实战
1. 嵌入式GUI设计的核心价值与市场驱动力在智能设备爆发的时代,嵌入式图形用户界面(GUI)已经从"锦上添花"变成了"不可或缺"的核心竞争力。我亲历过多个项目,那些仅关注硬件性能而忽视交互体验的产品ÿ…...
选型指南:从业务问题出发的指标匹配方法)
网络中心性(Centrality)选型指南:从业务问题出发的指标匹配方法
1. 为什么 centrality 不是“算出来就行”,而是网络分析的命脉所在在 R 里敲下centr_degree(g)或closeness(g),几毫秒就出结果——但如果你真以为这就完成了“节点重要性评估”,那大概率会在后续建模、解释或决策中栽跟头。我带过七届数据科学…...

异构无人机群与主动SLAM技术解析
1. 异构无人机群与主动SLAM技术概述在机器人自主导航领域,主动SLAM(Simultaneous Localization and Mapping)技术正逐渐成为解决动态环境感知与决策的关键方法。这项技术的核心在于让智能体不仅被动地构建环境地图,还能主动规划最…...
,错过再等18个月!)
仅限首批200家认证机构获取:SITS2026兼容性评估矩阵V1.2(含LLM微调知识注入适配表),错过再等18个月!
更多请点击: https://intelliparadigm.com 第一章:AI研发知识管理:SITS2026专题 在AI研发加速演进的背景下,知识管理正从文档归档转向语义化、可执行、可追溯的智能中枢。SITS2026(Semantic Intelligence for Technic…...
)
奇点不是预言,是进度条:SITS 2026公布的87项技术里程碑中,已有23项进入工信部信创适配目录(附完整清单速查表)
更多请点击: https://intelliparadigm.com 第一章:CSDN主办SITS 2026:2026奇点智能技术大会亮点全解析 SITS 2026(Singularity Intelligence Technology Summit)由CSDN联合中国人工智能学会、中科院自动化所共同主办&…...

罗技PUBG压枪宏技术深度解析:硬件级输入控制的演进与挑战
罗技PUBG压枪宏技术深度解析:硬件级输入控制的演进与挑战 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在FPS游戏竞技生态中&#…...

终极显卡驱动清理指南:如何彻底解决驱动残留问题
终极显卡驱动清理指南:如何彻底解决驱动残留问题 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstaller …...

Taotoken用量看板如何帮助团队精细化管控API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队精细化管控API成本 对于依赖大模型API进行开发的团队而言,成本控制是一个持续存在的挑战…...