基于Flask的岗位就业可视化系统(一)
🌟欢迎来到 我的博客 —— 探索技术的无限可能!
🌟博客的简介(文章目录)
前言
-
本项目综合了基本数据分析的流程,包括数据采集(爬虫)、数据清洗、数据存储、数据前后端可视化等
-
推荐阅读顺序为:数据采集——>数据清洗——>数据库存储——>基于Flask的前后端交互,有问题的话可以留言,有时间我会解疑~
-
感谢阅读、点赞和关注
开发环境
- 系统:Window 10 家庭中文版。
- 语言:Python(3.9)、MySQL。
- Python所需的库:pymysql、pandas、numpy、time、datetime、requests、etree、jieba、re、json、decimal、flask(没有的话pip安装一下就好)。
- 编辑器:jupyter notebook、Pycharm、SQLyog。
(如果下面代码在jupyter中运行不完全,建议直接使用Pycharm中运行)
文件说明
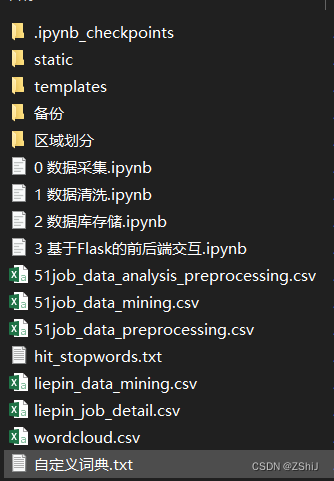
本项目下面有四个.ipynb的文件,下面分别阐述各个文件所对应的功能:(有py版本 可后台留言)
-
数据采集:分别从前程无忧网站和猎聘网上以关键词数据挖掘爬取相关数据。其中,前程无忧上爬取了270页,有超过1万多条数据;而猎聘网上只爬取了400多条数据,主要为岗位要求文本数据,最后将爬取到的数据全部储存到csv文件中。
-
数据清洗:对爬取到的数据进行清洗,包括去重去缺失值、变量重编码、特征字段创造、文本分词等。
-
数据库存储:将清洗后的数据全部储存到MySQL中,其中对文本数据使用jieba.analyse下的extract_tags来获取文本中的关键词和权重大小,方便绘制词云。
-
基于Flask的前后端交互:使用Python一个小型轻量的Flask框架来进行Web可视化系统的搭建,在static中有css和js文件,js中大多为百度开源的ECharts,再通过自定义controller.js来使用ajax调用flask已设定好的路由,将数据异步刷新到templates下的main.html中。
技术栈
- Python爬虫:(requests和xpath)
- 数据清洗:详细了解项目中数据预处理的步骤,包括去重去缺失值、变量重编码、特征字段创造和文本数据预处理 (pandas、numpy)
- 数据库知识:select、insert等操作,(增删查改&pymysql) 。
- 前后端知识:(HTML、JQuery、JavaScript、Ajax)。
- Flask知识:一个轻量级的Web框架,利用Python实现前后端交互。(Flask)
一、数据采集(爬虫)
1.前程无忧数据爬虫
前程无忧反爬最难的地方应该就是在点击某个网页进入之后所得到的具体内容,这部分会有个滑动验证码,只要使用Python代码爬数据都会被监视到,用selenium自动化操作也会被监视
这里使用猎聘网站上数据挖掘的岗位要求来代替前程无忧
import requests
import re
import json
import time
import pandas as pd
import numpy as np
from lxml import etree
通过输入岗位名称和页数来爬取对应的网页内容
job_name = input('请输入你想要查询的岗位:')
page = input('请输入你想要下载的页数:')
浏览器伪装
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
# 每个页面提交的参数,降低被封IP的风险
params = {'lang': 'c','postchannel': '0000','workyear': '99','cotype': '99','degreefrom': '99','jobterm': '99','companysize': '99','ord_field': '0','dibiaoid': '0'
}
href, update, job, company, salary, area, company_type, company_field, attribute = [], [], [], [], [], [], [], [], []
为了防止被封IP,下面使用基于redis的IP代理池来获取随机IP,然后每次向服务器请求时都随机更改我们的IP(该ip_pool搭建相对比较繁琐,此处省略搭建细节)
假如不想使用代理IP的话,则直接设置下方的time.sleep,并将proxies参数一并删除
proxypool_url = 'http://127.0.0.1:5555/random'
# 定义获取ip_pool中IP的随机函数
def get_random_proxy():proxy = requests.get(proxypool_url).text.strip()proxies = {'http': 'http://' + proxy}return proxies
使用session的好处之一便是可以储存每次的cookies,注意使用session时headers一般只需放上user-agent
session = requests.Session()
# 查看是否可以完成网页端的请求
session.get('https://www.51job.com/', headers = headers, proxies = get_random_proxy())
爬取每个页面下所有数据
for i in range(1, int(page) + 1):url = f'https://search.51job.com/list/000000,000000,0000,00,9,99,{job_name},2,{i}.html'response = session.get(url, headers = headers, params = params, proxies = get_random_proxy())# 使用正则表达式提取隐藏在html中的岗位数据ss = '{' + re.findall(r'window.__SEARCH_RESULT__ = {(.*)}', response.text)[0] + '}'# 加载成json格式,方便根据字段获取数据s = json.loads(ss)data = s['engine_jds']for info in data:href.append(info['job_href'])update.append(info['issuedate'])job.append(info['job_name'])company.append(info['company_name'])salary.append(info['providesalary_text'])area.append(info['workarea_text'])company_type.append(info['companytype_text'])company_field.append(info['companyind_text'])attribute.append(' '.join(info['attribute_text']))
# time.sleep(np.random.randint(1, 2))
遍历每个链接,爬取对应的工作职责信息
可以发现有些页面点击进去需要进行滑动验证,这可能是因为频繁爬取的缘故,需要等待一段时间再进行数据的抓取,在不想要更换IP的情况下,可以选择使用time模块
for job_href in href:job_response = session.get(job_href)job_response.encoding = 'gbk'job_html = etree.HTML(job_response.text)content.append(' '.join(job_html.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div//p/text()')[1:]))time.sleep(np.random.randint(1, 3))
保存数据到DataFrame
df = pd.DataFrame({'岗位链接': href, '发布时间': update, '岗位名称': job, '公司名称': company, '公司类型': company_type, '公司领域': company_field, '薪水': salary, '地域': area, '其他信息': attribute})
df.head()
看一下爬到了多少条数据
len(job)
保存数据到csv文件中
df.to_csv('./51job_data_mining.csv', encoding = 'gb18030', index = None)
2.爬取猎聘网站数据
浏览器伪装和相关参数
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
job, salary, area, edu, exp, company, href, content = [], [], [], [], [], [], [], []
session = requests.Session()
session.get('https://www.liepin.com/zhaopin/', headers = headers)
通过输入岗位名称和页数来爬取对应的网页内容
job_name = input('请输入你想要查询的岗位:')
page = input('请输入你想要下载的页数:')
遍历每一页上的数据
for i in range(int(page)):url = f'https://www.liepin.com/zhaopin/?key={job_name}&curPage={i}'time.sleep(np.random.randint(1, 2))response = session.get(url, headers = headers)html = etree.HTML(response.text)for j in range(1, 41):job.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/h3/@title')[0])info = html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/p[1]/@title')[0]ss = info.split('_')salary.append(ss[0])area.append(ss[1])edu.append(ss[2])exp.append(ss[-1])company.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[2]/p[1]/a/text()')[0])href.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/h3/a/@href')[0])
每页共有40条岗位信息
遍历每一个岗位的数据
for job_href in href:time.sleep(np.random.randint(1, 2))# 发现有些岗位详细链接地址不全,需要对缺失部分进行补齐if 'https' not in job_href:job_href = 'https://www.liepin.com' + job_hrefresponse = session.get(job_href, headers = headers)html = etree.HTML(response.text)content.append(html.xpath('//section[@class="job-intro-container"]/dl[1]//text()')[3])
保存数据
df = pd.DataFrame({'岗位名称': job, '公司': company, '薪水': salary, '地域': area, '学历': edu, '工作经验': exp, '岗位要求': content})
df.to_csv('./liepin_data_mining.csv', encoding = 'gb18030', index = None)
df.head()
相关文章:
基于Flask的岗位就业可视化系统(一)
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 前言 本项目综合了基本数据分析的流程,包括数据采集(爬虫)、数据清洗、数据存储、数据前后端可视化等 推荐…...
)
嵌入式学习68-C++(运算符重载和虚函数)
知识零碎: cin >> n 相当于scanf C系统提供的6种基本函数 …...

UVA1048/LA3561 Low Cost Air Travel
UVA1048/LA3561 Low Cost Air Travel 题目链接题意输入格式输出格式 分析AC 代码 题目链接 本题是2006年ICPC世界总决赛的A题 题意 很多航空公司都会出售一种联票,要求从头坐,上飞机时上缴机票,可以在中途任何一站下飞机。比如,假…...
学习和分析各种数据结构所要掌握的一个重要知识——CPU的缓存利用率(命中率)
什么是CPU缓存利用率(命中率),我们首先要把内存搞清楚。 硬盘是什么,内存是什么,高速缓存是什么,寄存器又是什么? 我们要储存数据就要运用到上面的东西。首先里面的硬盘是可以无电存储的&#…...

IOS自动化—将WDA打包ipa批量安装驱动
前言 CSDN: ios自动化-Xcode、WebDriverAgent环境部署 ios获取原生系统应用的包 如果Mac电脑没有配置好Xcode相关环境,可以参考以上文章。 必要条件 Mac电脑,OS版本在12.4及以上(低于这个版本无法安装Xcode14,装不了Xcode14就…...
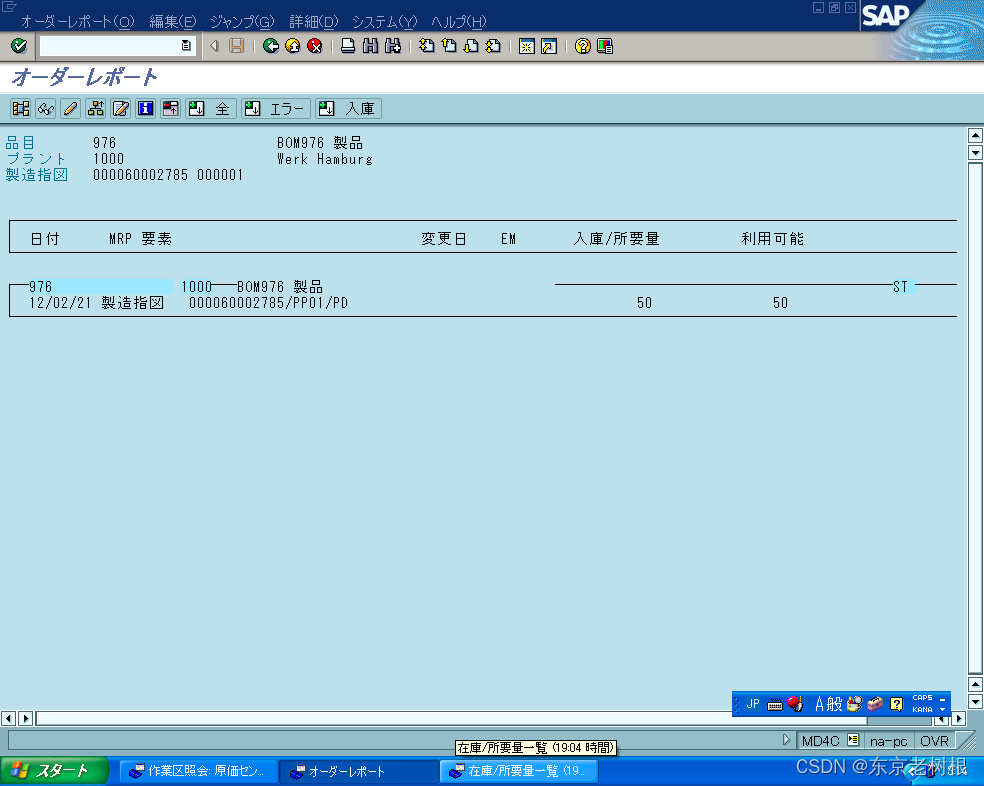
SAP PP学习笔记12 - 评估MRP的运行结果
上一章讲了MRP的概念,参数,配置等内容。 SAP PP学习笔记11 - PP中的MRP相关概念,参数,配置-CSDN博客 本章来讲 MRP跑完之后呢,要怎么评估这个MRP的运行结果。 1,Stock/Requirements List and MRP List 在…...
AndroidStudio的Iguana版的使用
1.AndroidStudio介绍 Android Studio 是用于开发 Android 应用的官方集成开发环境 (IDE)。Android Studio 基于 IntelliJ IDEA 强大的代码编辑器和开发者工具,还提供更多可提高 Android 应用构建效率的功能,例如: 基于 Gradle 的灵活构建系统…...

通过方法引用获取属性名的底层逻辑是什么?
很多小伙伴可能都用过 MyBatis-Plus,这里边我们构造 where 条件的时候,可以直接通过方法引用的方式去指定属性名: LambdaQueryWrapper<Book> qw new LambdaQueryWrapper<>(); qw.eq(Book::getId, 2); List<Book> list bo…...

自学错误合集--项目打包报错,运行报错持续更新中
java后端自学错误总结 一.项目打包报错2.项目打包之后运行报错 二.项目运行报错 一.项目打包报错 javac: �Ҳ����ļ�: E:\xx\xx\xx\docer-xx\src\main\java\xx\xx\xx\xx\xx\xx.java �ÿ…...
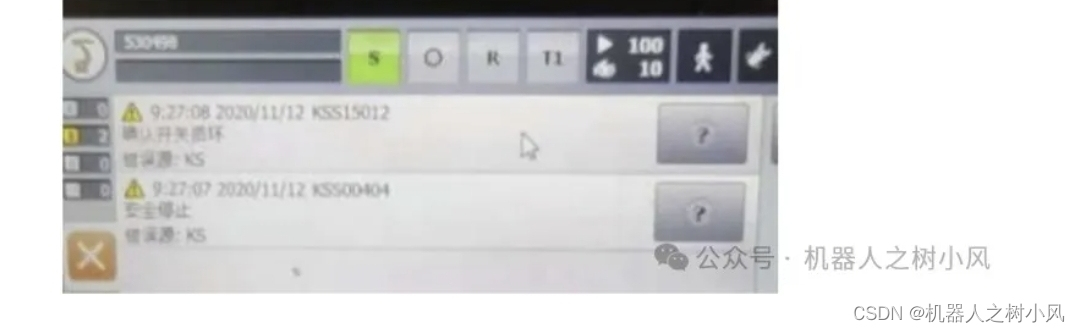
KUKA机器人故障报警信息处理(一)
1、KSS00276 机器人参数不等于机器人类型 ①登录专家模式 ②示教器操作:【菜单】—【显示】—【变量】—【单个】 ③名称输入:$ROBTRAFO[] 新值:TRAFONAME[] ④点击【设定值】。 2、电池报警: ①“充电电池警告-发现老化的蓄电池…...
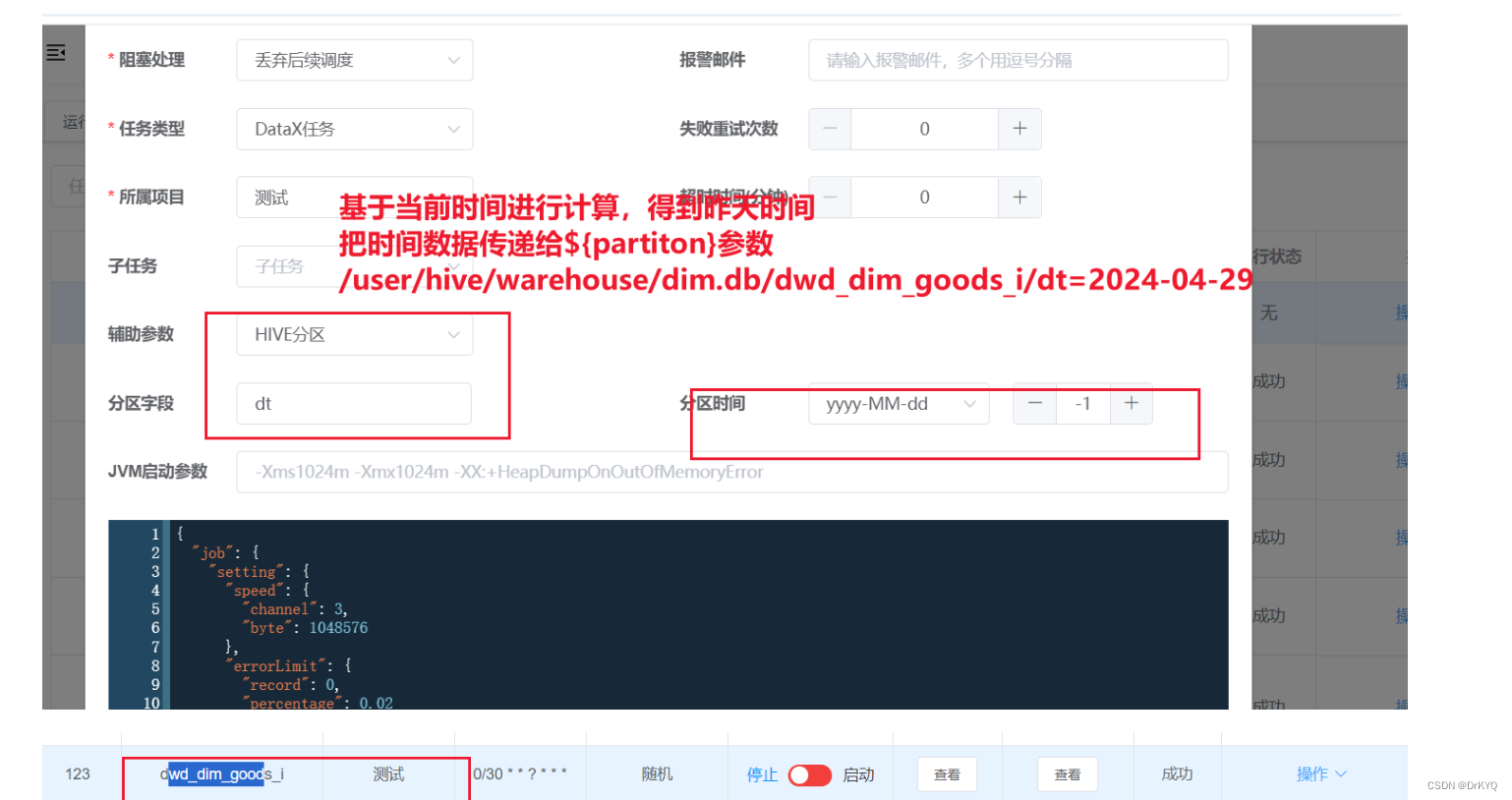
数仓开发:DIM层数据处理
一、了解DIM层 这个就是数仓开发的分层架构 我们现在是在DIM层,从ods表中数据进行加工处理,导入到dwd层,但是记住我们依然是在DIM层,而非是上面的ODS和DWD层。 二、处理维度表数据 ①先确认hive的配置 -- 开启动态分区方案 -- …...
echars设置渐变颜色的方法
在我们日常的开发中,难免会遇到有需求,需要使用echars设置渐变的图表,如果我们需要设置给图表设置渐变颜色的话,我们只需要在 series 配置项中 添加相应的属性配置项即可。 方式一:colorStops type:‘lin…...
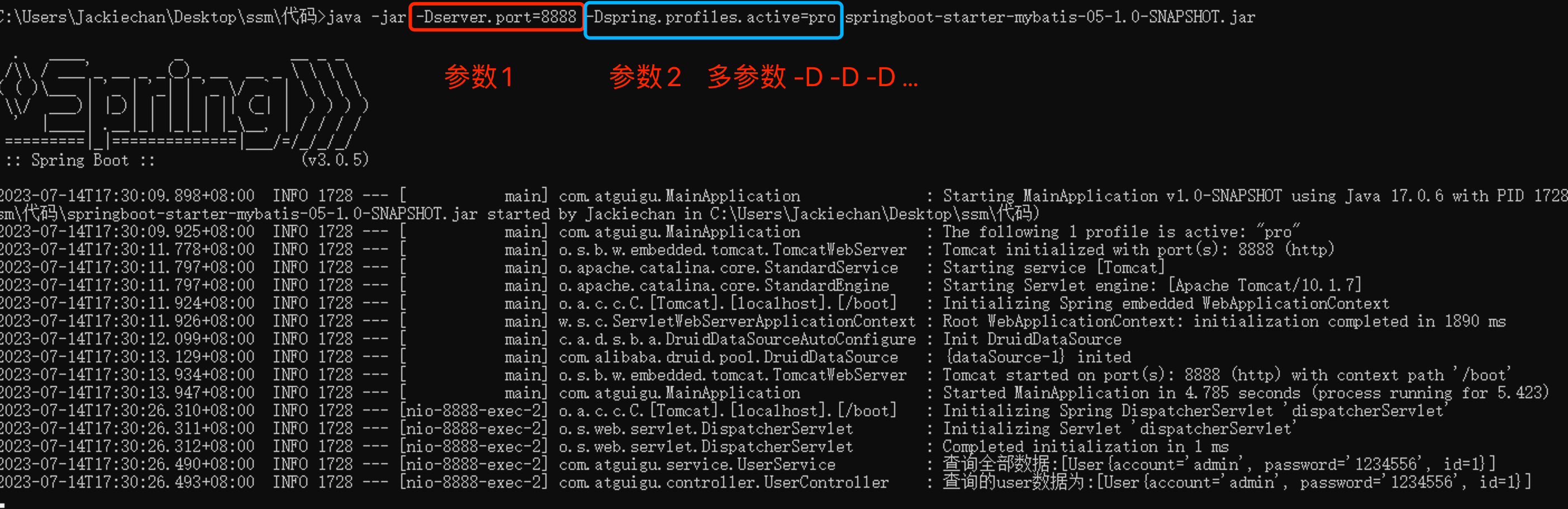
SpringBoot3项目打包和运行
六、SpringBoot3项目打包和运行 6.1 添加打包插件 在Spring Boot项目中添加spring-boot-maven-plugin插件是为了支持将项目打包成可执行的可运行jar包。如果不添加spring-boot-maven-plugin插件配置,使用常规的java -jar命令来运行打包后的Spring Boot项目是无法找…...

Spring Cloud Gateway的部署
不要将 Spring Cloud Gateway 部署到 Tomcat 可以将Spring Cloud Gateway打成jar包,并通过jar包部署,步骤: 1. 修改构建配置 确保你的pom.xml文件中的打包方式为jar。 <packaging>jar</packaging> 2 打包项目 mvn clean pack…...

算法提高之树的最长路径
算法提高之树的最长路径 核心思想:树形dp 枚举路径的中间节点用f1[i] 表示i的子树到i的最长距离,f2[i]表示次长距离最终答案就是max(f1[i]f2[i]) #include <iostream>#include <cstring>#include <algorithm>using namespace std;const int N …...
git/gerrit使用遇到的问题
Push时出现的多个问题及其解决 branch【...】not found 这个错误通常出现在 Git 命令中指定的分支名称中包含特殊字符或者语法错误时。需要确保指定的分支名称是正确的,并且没有任何不支持的字符。 例如,如果分支名称是 feature/branch,应该…...

机器学习第二天(监督学习,无监督学习,强化学习,混合学习)
1.是什么 基于数据寻找规律从而建立关系,进行升级,如果是以前的固定算式那就是符号学习了 2.基本框架 3.监督学习和无监督式学习: 监督学习:根据正确结果进行数据的训练; 在监督式学习中,训练数据包括输…...

Rust 解决循环引用
导航 循环引用一、现象二、解决 循环引用 循环引用出现的一个场景就是你指向我,我指向你,导致程序崩溃 解决方式可以通过弱指针,而Rust中的弱指针就是Weak 在Rc中,可以实现,对一个变量,持有多个不可变引…...

ICC2:如何解决pin density过高引起的绕线问题
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧? 拾陆楼知识星球入口 为了追求极致的利用率,综合往往会使用大量的AOI/OAI等多pin cell,然而后端实现过程中,工具为了解决绕线难题,又会通过降低local density的方法实现反向奔赴,即便如此,绕线后仍会残留不少问题,…...

Buuctf-Misc题目练习
打开后是一个gif动图,可以使用stegsolve工具进行逐帧看。 File Format:文件格式 Data Extract:数据提取 Steregram Solve:立体试图 可以左右控制偏移 Frame Browser:帧浏览器 Image Combiner:拼图,图片拼接 所以可以知道我们要选这个Frame Browser …...

OFDM-QPSK系统仿真避坑指南:如何正确设置SNR并解读星座图与误码率曲线
OFDM-QPSK系统仿真避坑指南:如何正确设置SNR并解读星座图与误码率曲线 在无线通信系统的仿真实践中,OFDM-QPSK组合因其抗多径干扰和频谱效率高的特点,成为研究者常用的验证模型。但许多初学者在MATLAB仿真中常遇到结果与理论不符的情况——星…...

从Pikachu靶场看CSRF Token防护:为什么你的Token机制可能被绕过?聊聊设计缺陷与加固思路
从Pikachu靶场看CSRF Token防护:为什么你的Token机制可能被绕过?聊聊设计缺陷与加固思路 在Web安全领域,CSRF(跨站请求伪造)攻击一直是开发者需要重点防范的威胁之一。而CSRF Token作为最常用的防护手段,其…...

麒麟系统上跑32位老程序,别再折腾了!用这个离线打包法,5分钟搞定依赖
麒麟系统32位程序兼容方案:离线依赖打包全流程指南 在国产化操作系统迁移浪潮中,许多企业面临一个共同难题——那些关键业务依赖的32位遗留程序如何在仅支持64位的新系统上运行?本文将以麒麟系统为例,详解一套经过实战检验的离线依…...

社会风气何以如此?渡劫未彻底,继续渡劫。从为人民服务到为节点服务
社会风气何以如此?渡劫未彻底,继续渡劫。从为人民服务到为节点服务。 Jianbing Zhu 1 1 ECT-OS-JiuHuaShan 文明实践室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20302480 Email: ect-os-jiuhuashanzohomail.cn 预印本提交:202…...

别再折腾gcc版本了!Ubuntu 20.04下用Docker一键搞定OLLVM编译环境
用Docker容器化技术快速搭建OLLVM混淆编译环境 在逆向工程和移动安全研究领域,代码混淆是一项基础而重要的技术。传统搭建OLLVM环境需要处理复杂的依赖关系、版本冲突等问题,往往让初学者望而却步。本文将介绍如何利用Docker技术,在Ubuntu 20…...

大数据之安装zookeeper
下载 官方下载地址:https://archive.apache.org/dist/zookeeper/ 解压 tar -zxvf zookeeper-3.4.13.tar.gz 创建目录 日志目录和数据目录 cd zookeeper-3.4.13/ # 数据目录 mkdir data # 数据目录的目录 mkdir data-log # 日志目录 mkdir logs 修改配置 日志…...

金蝶发布企业AI操作系统“灵基”,引领企业进入AI原生时代
5月20日,金蝶AI峰会2026在深圳成功举办,本次峰会通过线上线下同步召开,汇聚产学研先锋力量,共探智能未来。会上,金蝶正式发布企业AI操作系统“灵基(Lingee)”。这不仅是金蝶AI战略的全面跃迁,更是驱动企业管…...

保姆级教程:用HACS给追觅扫地机装Home Assistant插件,实现iPhone家庭App远程分区清扫
零门槛实现追觅扫地机HomeKit分区控制:HACS插件全流程指南 在智能家居生态中,苹果HomeKit以其出色的隐私保护和流畅的跨设备联动体验,成为许多iPhone用户的首选。但对于使用追觅X10/X20等型号扫地机的用户来说,官方App并未提供与…...

AnyKernel3:Android内核刷机终极指南 - 5分钟构建通用刷机包
AnyKernel3:Android内核刷机终极指南 - 5分钟构建通用刷机包 【免费下载链接】AnyKernel3 AnyKernel, Evolved 项目地址: https://gitcode.com/gh_mirrors/an/AnyKernel3 在Android设备定制化领域,内核刷机是提升性能、扩展功能的关键步骤。AnyKe…...

LM317电源模块的“隐藏参数”与实战避坑:为什么你的空载电压总是不稳?
LM317电源模块的“隐藏参数”与实战避坑:为什么你的空载电压总是不稳? 在电子设计领域,LM317作为经典的可调线性稳压器,几乎出现在每个工程师的备件库中。但当你按照标准电路搭好原型,却发现空载时输出电压飘忽不定——…...