Pytorch中utils.data 与torchvision简介
Pytorch中utils.data 与torchvision简介
- 1 数据处理工具概述
- 2 utils.data简介
- 3 torchvision简介
- 3.1 transforms
- 3.2 ImageFolder
1 数据处理工具概述
Pytorch涉及数据处理(数据装载、数据预处理、数据增强等)主要工具包及相互关系如下图所示,主要使用torch.utils.data 与 torchvision:
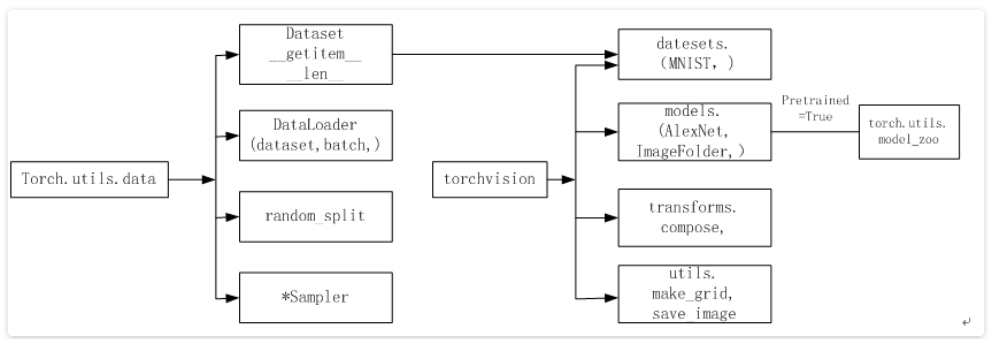
torch.utils.data工具包,它包括以下三个类:
(1)Dataset:是一个抽象类,其它数据集需要继承这个类,并且覆写其中的两个方法(getitem、len)。
(2)DataLoader:定义一个新的迭代器,实现批量(batch)读取,打乱数据(shuffle)并提供并行加速等功能。
(3)random_split:把数据集随机拆分为给定长度的非重叠新数据集。
(4)*sampler:多种采样函数。
可视化处理工具torchvision:Pytorch的一个视觉处理工具包,独立于Pytorch,需要另外安装,使用pip或conda安装即可,包含四个类:
(1)datasets:提供常用的数据集加载,设计上都是继承torch.utils.data.Dataset,主要包括MMIST、CIFAR10/100、ImageNet、COCO等。
(2)models:提供深度学习中各种经典的网络结构以及训练好的模型(如果选择pretrained=True),包括AlexNet, VGG系列、ResNet系列、Inception系列等。
(3)transforms:常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
(4)utils:含两个函数,一个是make_grid,它能将多张图片拼接在一个网格中;另一个是save_img,它能将Tensor保存成图片。
2 utils.data简介
utils.data包括Dataset和 DataLoader 。
-
torch.utils.data.Dataset:为抽象类。自定义数据集需要继承这个类,并实现两个函数。一个是__len__,另一个是__getitem__,前者提供数据的大小(size),后者通过给定索引获取数据和标签。
-
由于__getitem__一次只能获取一个数据,所以通过torch.utils.data.DataLoader来定义一个新的迭代器,实现batch读取。
下面通过举例,来比较Dataset 和DataLoader
- 1,导入相关模块
import torch
from torch.utils import data
import numpy as np
- 2,定义获取数据集的类,该类继承基类Dataset,自定义一个数据集及对应标签。
class TestDataset(data.Dataset):#继承Datasetdef __init__(self):self.Data=np.asarray([[1,2],[3,4],[2,1],[3,4],[4,5]])#一些由2维向量表示的数据集self.Label=np.asarray([0,1,0,1,2])#这是数据集对应的标签def __getitem__(self, index):#把numpy转换为Tensortxt=torch.from_numpy(self.Data[index])label=torch.tensor(self.Label[index])return txt,label def __len__(self):return len(self.Data)
- 3,获取数据集中数据
Test=TestDataset()
print(Test[2]) #相当于调用__getitem__(2)
print(Test.__len__())#輸出:
#(tensor([2, 1]), tensor(0))
#5
上面使用Dataset的方式,每次只返回一个样本。如果希望批处理,同时还要shuffle和并行加速等操作,可选择DataLoader。
data.DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,batch_sampler=None,num_workers=0,collate_fn=,pin_memory=False,drop_last=False,timeout=0,worker_init_fn=None,
)
主要参数说明:
dataset: 加载的数据集;
batch_size: 批大小;
shuffle:是否将数据打乱;
sampler:样本抽样
num_workers:使用多进程加载的进程数,0代表不使用多进程;
collate_fn:如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可;
pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些;
drop_last:dataset 中的数据个数可能不是 batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃。
test_loader = data.DataLoader(Test,batch_size=2,shuffle=False,num_workers=2)
for i,traindata in enumerate(test_loader):print('i:',i)Data,Label=traindataprint('data:',Data)print('Label:',Label)
从这个结果可以看出,这是批量读取。我们可以像使用迭代器一样使用它,如对它进行循环操作。不过它不是迭代器,我们可以通过iter命令转换为迭代器。
一般用data.Dataset处理同一个目录下的数据。如果数据在不同目录下,不同目录代表不同类别(这种情况比较普遍),使用data.Dataset来处理就不很方便。
不过,可以使用Pytorch另一种可视化数据处理工具(即torchvision)就非常方便,不但可以自动获取标签,还提供很多数据预处理、数据增强等转换函数。
3 torchvision简介
torchvision有4个功能模块,
- model:
- datasets:
- transforms:如何使用transforms对源数据进行预处理、增强等
- utils:
3.1 transforms
transforms提供了对PIL Image对象和Tensor对象的常用操作
(1)对PIL Image的常见操作如下:
Scale/Resize: 调整尺寸,长宽比保持不变;
CenterCrop、RandomCrop、RandomSizedCrop:裁剪图片,CenterCrop和RandomCrop在crop时是固定size,RandomResizedCrop则是random size的crop;
Pad: 填充;
ToTensor: 把一个取值范围是[0,255]的PIL.Image 转换成 Tensor。形状为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloatTensor。
RandomHorizontalFlip:图像随机水平翻转,翻转概率为0.5;
RandomVerticalFlip: 图像随机垂直翻转;
ColorJitter: 修改亮度、对比度和饱和度。
(2)对Tensor的常见操作如下:
Normalize: 标准化,即减均值,除以标准差;
ToPILImage:将Tensor转为PIL Image。
如果要对数据集进行多个操作,可通过Compose将这些操作像管道一样拼接起来,类似于nn.Sequential。以下为示例代码
transforms.Compose([#将给定的 PIL.Image 进行中心切割,得到给定的 size,#size 可以是 tuple,(target_height, target_width)。#size 也可以是一个 Integer,在这种情况下,切出来的图片形状是正方形。 transforms.CenterCrop(10),#切割中心点的位置随机选取transforms.RandomCrop(20, padding=0),#把一个取值范围是 [0, 255] 的 PIL.Image 或者 shape 为 (H, W, C) 的 numpy.ndarray,#转换为形状为 (C, H, W),取值范围是 [0, 1] 的 torch.FloatTensortransforms.ToTensor(),#规范化到[-1,1]transforms.Normalize(mean = (0.5, 0.5, 0.5), std = (0.5, 0.5, 0.5))
])
3.2 ImageFolder
当文件依据标签处于不同文件下时,如:

可以利用 torchvision.datasets.ImageFolder 来直接构造出 dataset,代码如下:
loader = datasets.ImageFolder(path)
loader = data.DataLoader(dataset)
ImageFolder 会将目录中的文件夹名自动转化成序列,那么DataLoader载入时,标签自动就是整数序列了。
下面我们利用ImageFolder读取不同目录下图片数据,然后使用transorms进行图像预处理,预处理有多个,我们用compose把这些操作拼接在一起。然后使用DataLoader加载。
对处理后的数据用torchvision.utils中的save_image保存为一个png格式文件,然后用Image.open打开该png文件,详细代码如下:
from torchvision import transforms, utils
from torchvision import datasets
import torch
import matplotlib.pyplot as plt
%matplotlib inlinemy_trans=transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor()
])
train_data = datasets.ImageFolder('./data/torchvision_data', transform=my_trans)
train_loader = data.DataLoader(train_data,batch_size=8,shuffle=True,)for i_batch, img in enumerate(train_loader):if i_batch == 0:print(img[1])fig = plt.figure()grid = utils.make_grid(img[0])plt.imshow(grid.numpy().transpose((1, 2, 0)))plt.show()utils.save_image(grid,'test01.png')break
其他功能模块待更新!
参考:python深度学习-基于pytorch
相关文章:
Pytorch中utils.data 与torchvision简介
Pytorch中utils.data 与torchvision简介1 数据处理工具概述2 utils.data简介3 torchvision简介3.1 transforms3.2 ImageFolder1 数据处理工具概述 Pytorch涉及数据处理(数据装载、数据预处理、数据增强等)主要工具包及相互关系如下图所示,主…...
学习 Python 之 Pygame 开发魂斗罗(十)
学习 Python 之 Pygame 开发魂斗罗(十)继续编写魂斗罗1. 解决敌人不开火的问题2. 创建爆炸效果类3. 为敌人跳入河中增加爆炸效果4. 玩家击中敌人继续编写魂斗罗 在上次的博客学习 Python 之 Pygame 开发魂斗罗(九)中,…...

Keepalive+LVS群集部署
KeepaliveLVS群集部署一、Keepalive概述1、什么是Keepalive2、Keepalive工作原理3、Keepalive主要模块及作用4、Keepalived 服务重要功能(1)管理 LVS 负载均衡软件(2)支持故障自动切换(3)实现 LVS 负载调度…...
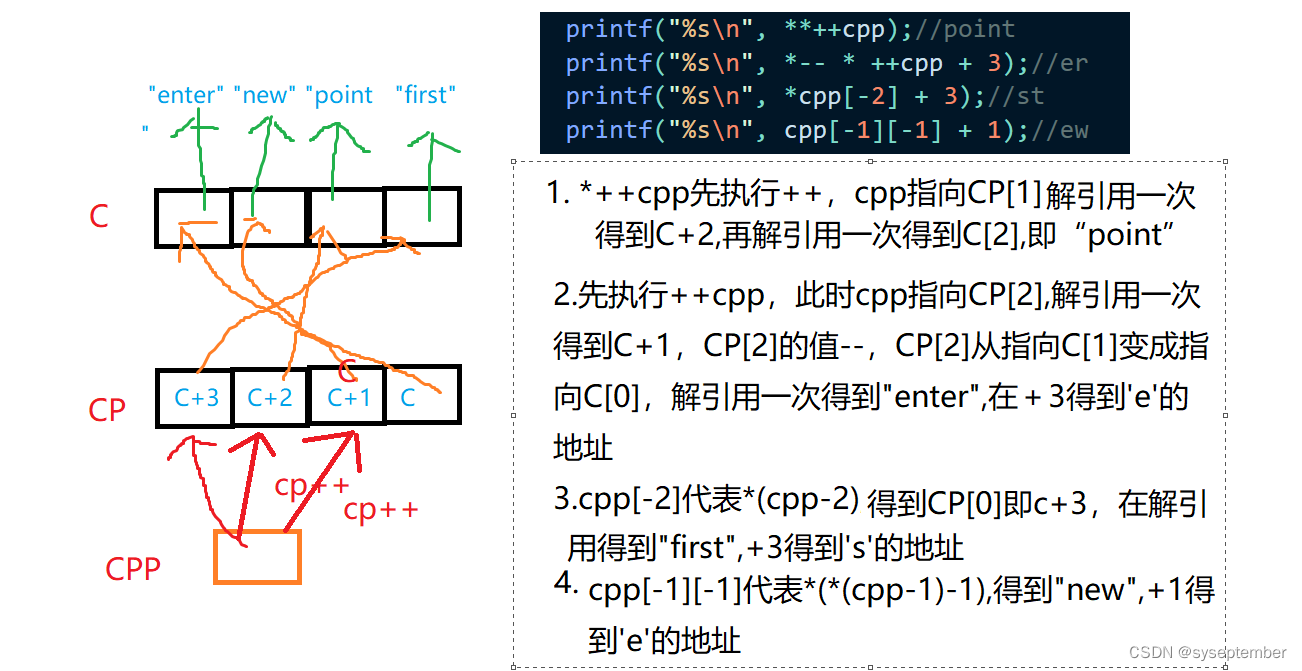
数组、指针总结【面试题】
文章目录0. 补充知识数组笔试题1. 一维数组1.1 字符数组1.1.1 sizeof1.1.2 strlen1.2 二维数组2. 指针笔试题0. 补充知识 在进入数组与指针的练习时,我们先来复习以下以下的知识点,这可以帮助我们更好的理解下面练习 数组是一组能存放相同类型的类型的元…...

七色电子标签
机种名 电子会议桌牌 型号 ESL_7color_7.3_D 外观尺寸 176.2x137.15x80mm 产品重量 268g 可视区域 163.297.92mm 外观颜色 银色 供电方式 锂电池供电2300mAh(Type-C 接口可充电) 显示技术 E-INK电子纸,双屏 像素 800x480 像…...
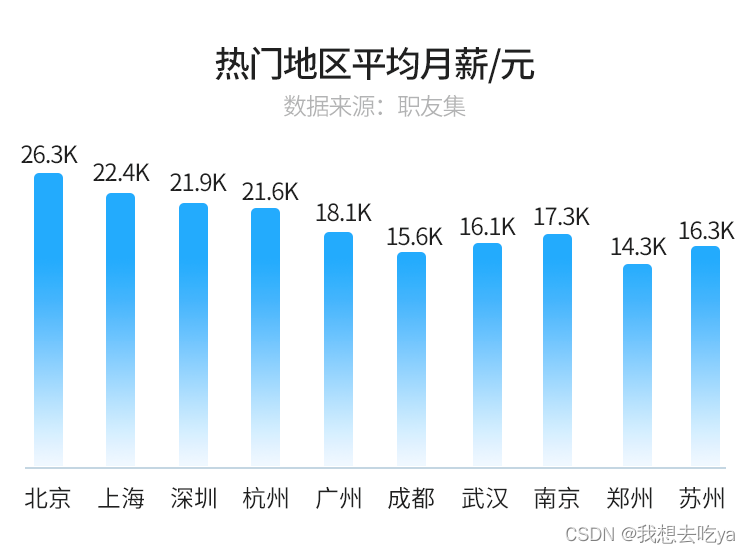
大数据是什么?发展前景怎么样
关于大数据的解释,比较官方的定义是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。简单来说,大数据就是结构化…...

MYSQL必知必会 | 查询相关
汇总数据 聚集函数 有时只需要汇总数据,并不需要把数据实际检索出来,所以MySql提供了专门的函数 聚集函数:运行在行组上,计算和返回单个值的函数 函数说明AVG()返回某列平均值COUNT()返回某列的行数MAX()返回某列最大值MIN()返…...

Java学习环境一站说明(保姆级详细教学)
1.Java开发环境搭建官网下载www.oracle.com2.安装注意:1.选择安装位置时尽量不要安装到C盘,路径中不要有空格以及中文的存在2.开发人员安装的jdk中包含了jre,所以不需要单独安装jre3.环境变量配置打开高级系统设置2.点击环境变量3.在系统变量…...
05-Oracle中的对象(视图,索引,同义词,系列)
本章主要内容: 1.视图管理:视图新增,修改,删除; 2.索引管理:索引目的,创建,修改,删除; 3.同义词管理:同义词的作用,创建࿰…...
如何通过websoket实现即时通讯+断线重连?
本篇博客只是一个demo,具体应用还要结合项目实际情况,以下是目录结构: 1.首先通过express搭建一个本地服务器 npm install express 2.在serve.js中自定义测试数据 const express require(express); const app express(); const http req…...

爽,我终于掌握了selenium图片滑块验证码
因为种种原因没能实现愿景的目标,在这里记录一下中间结果,也算是一个收场吧。这篇文章主要是用selenium解决滑块验证码的个别案列。 思路: 用selenium打开浏览器指定网站 将残缺块图片和背景图片下载到本地 对比两张图片的相似地方&#x…...
二、SpringMVC注解式开发
1. RequestMapping注解 此注解就是来映射服务器访问的路径 可加在方法上,是为此方法注册一个可以访问的名称(路径) 可以加在类上,相当于是包名(虚拟路径),区分不同类中相同的action的名称 可区分get请求和post请求 package com.powernode.controller;import org.springframe…...

Java容器面试知识点总结
容器 java容器有哪些? String,数组以及Java.util 下面的集合类 List:存放有序,列表存储,元素可重复 ArrayList LinkedList Vector Set:无序,元素不可重复 HashSet TreeSet Map: 无序,元素可重复…...

增长:2023 IT运维发展趋势前瞻
根据IDC和智研咨询数据等平台公开数据显示,从2018年至2022年,全球ITOM行业市场规模以8.58%的年均复合增长率高速增长。其中,中国ITOM市场在2020-2023年的年复合增长率为10.7%,到2023年市场规模将达到165.7亿元。012022中国IT运维解…...
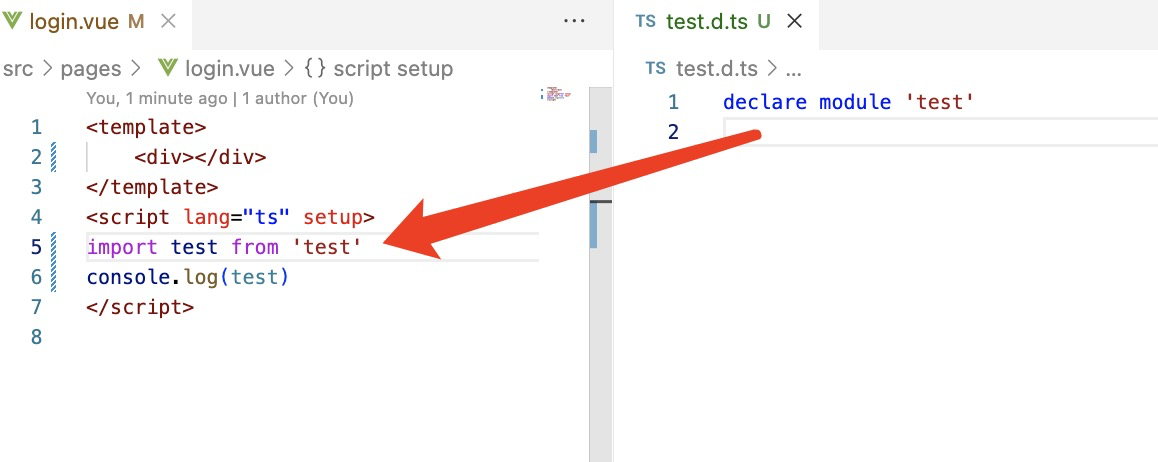
自己定义typescript的类型声明文件xx.d.ts
****内容预警***菜鸟新手内容,大佬请绕道,不对的请指出我们在使用typescript的使用,如果安装一个包没有相应的类型声明文件,ts的类型检查就会报错,所以我们经常会安装npm包对应的types类型声明包,比如uuid …...
数据分析方法及名词解释总结_(面试2)
1、用户画像 1.1、什么是用户画像?如何构建用户画像? - 知乎提到用户画像, 很多人都可能存在的错误认知,即把用户画像简单理解成用户各种特征,比如说姓名、性别、…https://www.zhihu.com/question/372802348/answer/2…...

【FLY】Java知识点总结
目录认识Java概念图名词解释历史版本基础知识编程规范关键字数据类型运算符数组Stringequals与流程控制引用数据结构常用数据结构HashMapLinkedHashMapWeakHashMapIdentityHashMapEnumMapTreeMapCopyOnWriteArrayList面向对象类反射注解IO异常线程EffectiveJava8JVM运行时数据区…...

SpringMVC-0307
三、RequestMapping注解1、RequestMapping注解的功能从注解名称上我们可以看到,RequestMapping注解的作用就是将请求和处理请求的控制器方法关联起来,建立映射关系。SpringMVC 接收到指定的请求,就会来找到在映射关系中对应的控制器方法来处理…...
【独家】)
华为OD机试 - 九宫格按键输入(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:九宫格按…...

Oracle 11g RAC群集部署
Oracle 11g RAC群集部署 1.环境介绍: 操作系统:Oracle Enterprise Linux 6.5 Oracle数据库:Oracle 11.2.0.4 集群软件:Oracle Grid Infrastructure 11.2.0.4 2.所需介质: p13390677_112040_Linux-x86-64_1of7 p133…...

N_m3u8DL-RE深度解析:现代流媒体下载引擎的架构设计与实战应用
N_m3u8DL-RE深度解析:现代流媒体下载引擎的架构设计与实战应用 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8…...

GetQzonehistory:免费永久保存QQ空间说说的终极解决方案
GetQzonehistory:免费永久保存QQ空间说说的终极解决方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾担心QQ空间里那些珍贵的青春记忆会随着时间流逝而消失&…...

PVZ Toolkit终极指南:如何用专业工具解锁植物大战僵尸无限可能
PVZ Toolkit终极指南:如何用专业工具解锁植物大战僵尸无限可能 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 你是否曾在植物大战僵尸的战场上为资源不足而苦恼?是否想体验…...

从注册到第一笔消费Taotoken新手指南与核心功能全景
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从注册到第一笔消费:Taotoken 新手指南与核心功能全景 应用场景类,面向完全新接触 Taotoken 平台的用户&am…...

基于Arduino与浅层神经网络的低成本肌电仿生手设计与实现
1. 项目概述:用技术为生活重启一扇门在康复工程与人机交互的交叉领域,肌电信号控制技术正悄然改变着许多人的生活。想象一下,当一个人因故失去手部功能,他大脑中“握紧水杯”或“挥手告别”的意图,依然会通过神经信号传…...

Monitorian终极指南:Windows多显示器亮度自动化管理完整教程
Monitorian终极指南:Windows多显示器亮度自动化管理完整教程 【免费下载链接】Monitorian A Windows desktop tool to adjust the brightness of multiple monitors with ease 项目地址: https://gitcode.com/gh_mirrors/mo/Monitorian 你是否曾经为Windows系…...

Mac Mouse Fix技术架构深度解析:如何通过系统级事件拦截实现鼠标功能增强
Mac Mouse Fix技术架构深度解析:如何通过系统级事件拦截实现鼠标功能增强 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 在macOS生…...

ContextMenuManager:Windows右键菜单终极优化指南
ContextMenuManager:Windows右键菜单终极优化指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 我们每天都要和Windows右键菜单打交道几十次&#…...

BG3 Mod Manager:轻松管理《博德之门3》模组的高效工具
BG3 Mod Manager:轻松管理《博德之门3》模组的高效工具 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager BG3 Mod Manager 是一款专为《博…...

YCB数据集入门指南:从下载到3D模型可视化,手把手教你用Blender和Python搞定
YCB数据集实战指南:从零掌握3D模型处理全流程在机器人抓取、计算机视觉和增强现实领域,YCB数据集已成为行业标准之一。这个包含日常物品高精度3D模型的资源库,为算法开发提供了可靠的测试基准。但对于刚接触的研究者来说,从数据下…...