Redis核心数据结构——跳表(生成数据到文件和从文件中读取数据、模块合并、)
生成文件和从文件中读取数据。
需求如下:
你的任务是实现 SkipList 类中的数据持久化成员函数和数据加载成员函数。
持久化数据成员函数签名:void dump_file();
该成员函数负责将存储引擎内的数据持久化到文件中。数据的持久化格式是将每个键值对写入文件的单独一行,采用key:value的格式。这种方式不仅确保了数据格式的一致性,还便于数据的恢复和解析。
读取数据成员函数签名:void load_file();
此成员函数的目的是从文件中读取之前持久化的数据,并将其加载到存储引擎中。读取的数据格式遵循每行一个key:value键值对的规则。在数据加载过程中,成员函数还需确保跳表的索引能够被正确地重建,以保持数据的快速访问和检索性能。
其实看起来蛮简单的,就是把原本数据按照一定格式读入到文件中,和从文件中读取数据再调用insert_element函数就行了。但实现起来还是遇到了几个坑的。
首先是文件读写,这个网上版本很多,随意选择一种就行。
包含如下头文件:
#include <fstream>
#include <iostream>在要编写的dump_file函数里写明绝对路径,然后修改下print拿过来用就行了。代码如下:
void dump_file() {std::ofstream out("D:\\dev_c++\\destination\\out.txt");if (out.is_open()) {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];while (cur) {out << cur->getKey() << ":" << cur->get_value() << '\n';cur = cur->forwards[curlevel];}curlevel--;}out.close();}}这个在在线判题系统里似乎修改不了,需要用本地C++编译器。然后还会在time(0)出报错,需要加上如下头文件:
#include <sys/time.h>
实现效果如图,还用的删除跳表那里的输入输出数据
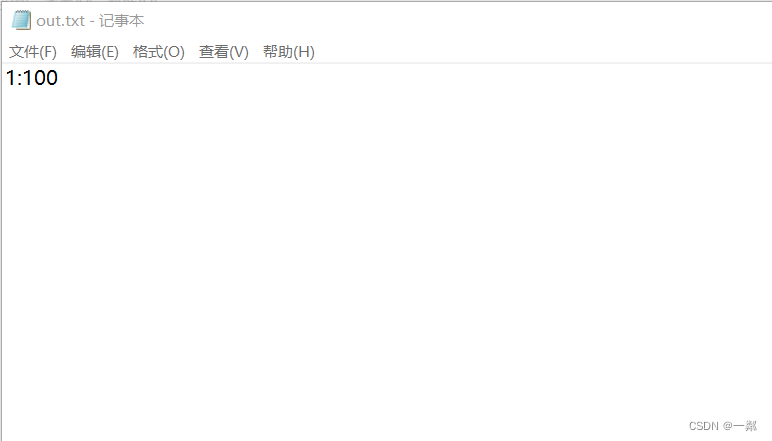
再来看读入数据:
这个首先要判断是否打开了文件,没打开直接报错,在线判题网上里就是直接报错的。所以我们还是要用编译器。之后就是对输入字符串进行处理,循环遍历找到':'下标作为分隔符下标,以此为依据调用substr函数即可。
代码如下:
void load_file() {std::ifstream in("D:\\dev_c++\\destination\\out.txt");char buffer[256];if (!in.is_open()) {std::cout << "open error";} else {while (!in.eof()) {std::string s;in >> s;int index = 0;if (s.size() == 0) return; for (int i = 0; i < s.length(); i++) {if (s[i] == ':') {index = i;break;}}
// std::cout << s << ' ';std::string s1 = s.substr(0, index);std::string s2 = s.substr(index + 1, s.length() - 1 - index); //下标从index+1开始std::cout << s1 << s2 << std::endl;
// int key = std::stoi(s1);int value = std::stoi(s2);insert_element(key, value);}}}这个实现的就只是int类型的读取文件。
运行效果如图:


由于我们采用的是随机层数的机制,所以每次结果层数会不一致,也很正常。这也是跳表好玩的地方之一了。
整体代码如下:
#include<stdlib.h>
#include <iostream>
#include <cstring>
#include <fstream>
#include <iostream>
#include <string>
#include <sys/time.h>template<typename K, typename V>
class Node {
private:K key;V val;int node_level;public:Node** forwards;public:Node(K inkey, V value, int level): key(inkey), val(value), node_level(level),forwards(nullptr) {this->forwards = new Node<K, V>*[node_level+1];memset(this->forwards, 0, sizeof(Node<K,V>*)*(node_level+1));}~Node(){delete forwards;};K getKey() const {return key;}V get_value() const {return val;}int getLevel() const {return node_level;}void set_value(V value) {val = value;}};template<typename K, typename V>
class SkipList {
private:Node<K,V>* HeadNode = nullptr;int _maxlevel = 0;int temp_level = 0;
public:SkipList(int maxlevel = 500) {_maxlevel = maxlevel;HeadNode = new Node<K, V>(K(),V(),maxlevel);}~SkipList() { delete HeadNode; _maxlevel = 0; temp_level = 0; }int getRandomLevel() {srand((int)time(0));int k = 1;while (rand() % 2) {k++;}k = (k < _maxlevel) ? k : _maxlevel;return k;}int insert_element(const K key, const V value) {int flag = 0;Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode;while (cur) {if (cur->getKey() == key) {flag = 1;cur->set_value(value);}cur = cur->forwards[curlevel]; }curlevel--;}if (flag == 1) return 1;Node<K, V>* newNode = new Node<K,V>(key, value, getRandomLevel());if (temp_level < newNode->getLevel()) temp_level = newNode->getLevel();curlevel = newNode->getLevel();while (curlevel) {Node<K,V>* prev = HeadNode;cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() > newNode->getKey()) {prev->forwards[curlevel] = newNode;newNode->forwards[curlevel] = cur;break;} cur = cur->forwards[curlevel];prev = prev->forwards[curlevel];} if (!cur)prev->forwards[curlevel] = newNode;curlevel--;}return 0;}bool search_element(K key) {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() == key) return true;cur = cur->forwards[curlevel]; }curlevel--;}return false;}void delete_element(K key) {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {Node<K,V>* prev = HeadNode;cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() == key) {prev->forwards[curlevel] = cur->forwards[curlevel];break;}cur = cur->forwards[curlevel];prev = prev->forwards[curlevel];}curlevel--;}}void print() {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];std::cout << "Level " << curlevel-1 << ": ";while (cur) {std::cout << cur->getKey() << ":" << cur->get_value() << ';';cur = cur->forwards[curlevel];}std::cout << std::endl;curlevel--;}}void dump_file() {std::ofstream out("D:\\dev_c++\\destination\\out.txt");if (out.is_open()) {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];while (cur) {out << cur->getKey() << ":" << cur->get_value() << '\n';cur = cur->forwards[curlevel];}curlevel--;}out.close();}}void load_file() {std::ifstream in("D:\\dev_c++\\destination\\out.txt");char buffer[256];if (!in.is_open()) {std::cout << "open error";} else {while (!in.eof()) {std::string s;in >> s;int index = 0;if (s.size() == 0) return; for (int i = 0; i < s.length(); i++) {if (s[i] == ':') {index = i;break;}}
// std::cout << s << ' ';std::string s1 = s.substr(0, index);std::string s2 = s.substr(index + 1, s.length() - 1 - index);
// std::cout << s1 << s2 << std::endl;int key = std::stoi(s1);int value = std::stoi(s2);insert_element(key, value);}}}
};int main() {SkipList<int, int> mySkipList;// 插入删除数据 int n,k,m;std::cin >> n >> k >> m;while (n--) {int key, v, r;std::cin >> key >> v;r = mySkipList.insert_element(key,v);if (r == 0) std::cout << "Insert Success" << std::endl;else std::cout << "Insert Failed" << std::endl;}while (k--) {int key;std::cin >> key;mySkipList.delete_element(key);}while (m--) {int k;std::cin >> k;if (mySkipList.search_element(k)) std::cout << "Search Success" << std::endl;else std::cout << "Search Failed" << std::endl;}mySkipList.dump_file();// 读文件并展示 mySkipList.load_file();mySkipList.print();
}模块合并
需求如下:
你的任务是创建一个 skiplist.h 的头文件,包含前面所有章节介绍的 Node 类和 SkipList 类,用以在其他程序中进行引用
其实主要也就是引入了锁,加上如下头文件:
#include <mutex> 并且在插入删除数据函数前后分别加锁和解锁就行了,伪代码如下:
// 只有在插入和删除的时候,才会进行加锁
template <typename K, typename V>
int SkipList<K, V>::insert_element(const K key, const V value) {mtx.lock(); // 在函数第一句加锁// ... 算法过程(省略)if (current != NULL && current->get_key() == key) {std::cout << "key: " << key << ", exists" << std::endl;// 在算法流程中有一个验证 key 是否存在的过程// 在此处需要提前 return,所以提前解锁mtx.unlock();return 1;}// ... mtx.unlock(); // 函数执行完毕后解锁return 0;
}template <typename K, typename V>
void SkipList<K, V>::delete_element(K key) {mtx.lock(); // 加锁// ... 算法过程(省略)mtx.unlock(); // 解锁return;
}最终代码如下:
#include<stdlib.h>
#include <iostream>
#include <cstring>
#include <fstream>
#include <iostream>
#include <string>
#include <mutex>
#include <sys/time.h>std::mutex mtx; template<typename K, typename V>
class Node {
private:K key;V val;int node_level;public:Node** forwards;public:Node(K inkey, V value, int level): key(inkey), val(value), node_level(level),forwards(nullptr) {this->forwards = new Node<K, V>*[node_level+1];memset(this->forwards, 0, sizeof(Node<K,V>*)*(node_level+1));}~Node(){delete forwards;};K getKey() const {return key;}V get_value() const {return val;}int getLevel() const {return node_level;}void set_value(V value) {val = value;}};template<typename K, typename V>
class SkipList {
private:Node<K,V>* HeadNode = nullptr;int _maxlevel = 0;int temp_level = 0;
public:SkipList(int maxlevel = 500) {_maxlevel = maxlevel;HeadNode = new Node<K, V>(K(),V(),maxlevel);}~SkipList() { delete HeadNode; _maxlevel = 0; temp_level = 0; }int getRandomLevel() {srand((int)time(0));int k = 1;while (rand() % 2) {k++;}k = (k < _maxlevel) ? k : _maxlevel;return k;}int insert_element(const K key, const V value) {mtx.lock();int flag = 0;Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode;while (cur) {if (cur->getKey() == key) {flag = 1;cur->set_value(value);}cur = cur->forwards[curlevel]; }curlevel--;}if (flag == 1) return 1;Node<K, V>* newNode = new Node<K,V>(key, value, getRandomLevel());if (temp_level < newNode->getLevel()) temp_level = newNode->getLevel();curlevel = newNode->getLevel();while (curlevel) {Node<K,V>* prev = HeadNode;cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() > newNode->getKey()) {prev->forwards[curlevel] = newNode;newNode->forwards[curlevel] = cur;break;} cur = cur->forwards[curlevel];prev = prev->forwards[curlevel];} if (!cur)prev->forwards[curlevel] = newNode;curlevel--;}mtx.unlock();return 0;}bool search_element(K key) {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() == key) return true;cur = cur->forwards[curlevel]; }curlevel--;}return false;}void delete_element(K key) {mtx.lock();Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {Node<K,V>* prev = HeadNode;cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() == key) {prev->forwards[curlevel] = cur->forwards[curlevel];break;}cur = cur->forwards[curlevel];prev = prev->forwards[curlevel];}curlevel--;}mtx.unlock();}void print() {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];std::cout << "Level " << curlevel-1 << ": ";while (cur) {std::cout << cur->getKey() << ":" << cur->get_value() << ';';cur = cur->forwards[curlevel];}std::cout << std::endl;curlevel--;}}void dump_file() {std::ofstream out("D:\\dev_c++\\destination\\out.txt");if (out.is_open()) {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];while (cur) {out << cur->getKey() << ":" << cur->get_value() << '\n';cur = cur->forwards[curlevel];}curlevel--;}out.close();}}void load_file() {std::ifstream in("D:\\dev_c++\\destination\\out.txt");char buffer[256];if (!in.is_open()) {std::cout << "open error";} else {while (!in.eof()) {std::string s;in >> s;int index = 0;if (s.size() == 0) return; for (int i = 0; i < s.length(); i++) {if (s[i] == ':') {index = i;break;}}
// std::cout << s << ' ';std::string s1 = s.substr(0, index);std::string s2 = s.substr(index + 1, s.length() - 1 - index);
// std::cout << s1 << s2 << std::endl;int key = std::stoi(s1);int value = std::stoi(s2);insert_element(key, value);}}}
};int main() {SkipList<int, int> mySkipList;// 插入删除数据 int n,k,m;std::cin >> n >> k >> m;while (n--) {int key, v, r;std::cin >> key >> v;r = mySkipList.insert_element(key,v);if (r == 0) std::cout << "Insert Success" << std::endl;else std::cout << "Insert Failed" << std::endl;}while (k--) {int key;std::cin >> key;mySkipList.delete_element(key);}while (m--) {int k;std::cin >> k;if (mySkipList.search_element(k)) std::cout << "Search Success" << std::endl;else std::cout << "Search Failed" << std::endl;}mySkipList.dump_file();// 读文件并展示 mySkipList.load_file();mySkipList.print();
}压力测试
测试结果如图
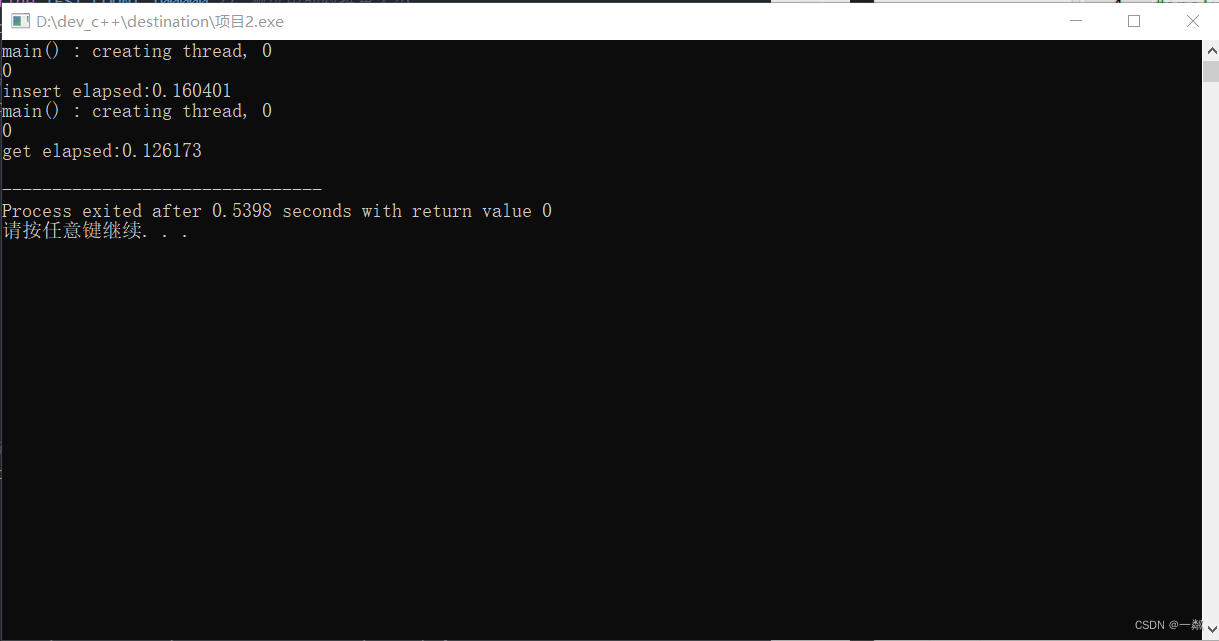
这一模块是要编写代码对所做项目进行测试,所用代码文件如下:
// 引入必要的头文件
#include <iostream> // 用于输入输出流
#include <chrono> // 用于高精度时间测量
#include <cstdlib> // 包含一些通用的工具函数,如随机数生成
#include <pthread.h> // 用于多线程编程
#include <time.h> // 用于时间处理函数
#include "./skiplist.h" // 引入自定义的跳表实现// 定义宏常量
#define NUM_THREADS 1 // 线程数量
#define TEST_COUNT 100000// 测试用的数据量大小
SkipList<int, std::string> skipList(18); // 创建一个最大层级为18的跳表实例// 插入元素的线程函数
void *insertElement(void* threadid) {long long tid; // 线程IDtid = (long long)threadid; // 将void*类型的线程ID转换为long型std::cout << tid << std::endl; // 输出线程IDint tmp = TEST_COUNT/NUM_THREADS; // 计算每个线程应该插入的元素数量// 循环插入元素for (int i=tid*tmp, count=0; count<tmp; i++) {count++;skipList.insert_element(rand() % TEST_COUNT, "a"); // 随机生成一个键,并插入带有"a"的元素}pthread_exit(NULL); // 退出线程
}// 检索元素的线程函数
void *getElement(void* threadid) {long long tid; // 线程IDtid = (long long)threadid; // 将void*类型的线程ID转换为long型std::cout << tid << std::endl; // 输出线程IDint tmp = TEST_COUNT/NUM_THREADS; // 计算每个线程应该检索的元素数量// 循环检索元素for (int i=tid*tmp, count=0; count<tmp; i++) {count++;skipList.search_element(rand() % TEST_COUNT); // 随机生成一个键,并尝试检索}pthread_exit(NULL); // 退出线程
}int main() {srand(time(NULL)); // 初始化随机数生成器{pthread_t threads[NUM_THREADS]; // 定义线程数组int rc; // 用于接收pthread_create的返回值int i; // 循环计数器auto start = std::chrono::high_resolution_clock::now(); // 开始计时// 创建插入元素的线程for( i = 0; i < NUM_THREADS; i++ ) {std::cout << "main() : creating thread, " << i << std::endl;rc = pthread_create(&threads[i], NULL, insertElement, (void *)i); // 创建线程if (rc) {std::cout << "Error:unable to create thread," << rc << std::endl;exit(-1); // 如果线程创建失败,退出程序}}void *ret; // 用于接收pthread_join的返回值// 等待所有插入线程完成for( i = 0; i < NUM_THREADS; i++ ) {if (pthread_join(threads[i], &ret) != 0 ) {perror("pthread_create() error");exit(3); // 如果线程等待失败,退出程序}}auto finish = std::chrono::high_resolution_clock::now(); // 结束计时std::chrono::duration<double> elapsed = finish - start; // 计算耗时std::cout << "insert elapsed:" << elapsed.count() << std::endl; // 输出插入操作耗时}// 下面的代码块与上面类似,用于创建并管理检索操作的线程{pthread_t threads[NUM_THREADS];int rc;int i;auto start = std::chrono::high_resolution_clock::now();for( i = 0; i < NUM_THREADS; i++ ) {std::cout << "main() : creating thread, " << i << std::endl;rc = pthread_create(&threads[i], NULL, getElement, (void *)i);if (rc) {std::cout << "Error:unable to create thread," << rc << std::endl;exit(-1);}}void *ret;for( i = 0; i < NUM_THREADS; i++ ) {if (pthread_join(threads[i], &ret) != 0 ) {perror("pthread_create() error");exit(3);}}auto finish = std::chrono::high_resolution_clock::now();std::chrono::duration<double> elapsed = finish - start;std::cout << "get elapsed:" << elapsed.count() << std::endl;}pthread_exit(NULL); // 主线程退出return 0;
}我们还需要新建一个项目工程文件,将之前写的代码重命名成skiplist.h,编译运行进行测试,编译链接要按照如下指令来:
g++ --std=c++11 main.cpp -o stress -pthreaddev_c++里面点进这里修改这个即可。
但在测试过程中,我发现即便是很少的数据量比如4,运行黑框仍旧会卡住,一直无法出来。自己检查代码后才发现,是我在插入数据函数加锁时只在return 0的情况下加了锁,因此在return 1 的情况下,系统就陷入了死锁局面!

加上去之后就好了。
修改后代码如下:
//skiplist.h
#include<stdlib.h>
#include <iostream>
#include <cstring>
#include <fstream>
#include <iostream>
#include <string>
#include <mutex>
#include <sys/time.h>std::mutex mtx; template<typename K, typename V>
class Node {
private:K key;V val;int node_level;public:Node** forwards;public:Node(K inkey, V value, int level): key(inkey), val(value), node_level(level),forwards(nullptr) {this->forwards = new Node<K, V>*[node_level+1];memset(this->forwards, 0, sizeof(Node<K,V>*)*(node_level+1));}~Node(){delete forwards;};K getKey() const {return key;}V get_value() const {return val;}int getLevel() const {return node_level;}void set_value(V value) {val = value;}};template<typename K, typename V>
class SkipList {
private:Node<K,V>* HeadNode = nullptr;int _maxlevel = 0;int temp_level = 0;
public:SkipList(int maxlevel = 500) {_maxlevel = maxlevel;HeadNode = new Node<K, V>(K(),V(),maxlevel);}~SkipList() { delete HeadNode; _maxlevel = 0; temp_level = 0; }int getRandomLevel() {srand((int)time(0));int k = 1;while (rand() % 2) {k++;}k = (k < _maxlevel) ? k : _maxlevel;return k;}int insert_element(const K key, const V value) {mtx.lock();int flag = 0;Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode;while (cur) {if (cur->getKey() == key) {flag = 1;cur->set_value(value);}cur = cur->forwards[curlevel]; }curlevel--;}if (flag == 1) {mtx.unlock();return 1;}Node<K, V>* newNode = new Node<K,V>(key, value, getRandomLevel());if (temp_level < newNode->getLevel()) temp_level = newNode->getLevel();curlevel = newNode->getLevel();while (curlevel) {Node<K,V>* prev = HeadNode;cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() > newNode->getKey()) {prev->forwards[curlevel] = newNode;newNode->forwards[curlevel] = cur;break;} cur = cur->forwards[curlevel];prev = prev->forwards[curlevel];} if (!cur)prev->forwards[curlevel] = newNode;curlevel--;}mtx.unlock();return 0;}bool search_element(K key) {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() == key) return true;cur = cur->forwards[curlevel]; }curlevel--;}return false;}void delete_element(K key) {mtx.lock();Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {Node<K,V>* prev = HeadNode;cur = HeadNode->forwards[curlevel];while (cur) {if (cur->getKey() == key) {prev->forwards[curlevel] = cur->forwards[curlevel];break;}cur = cur->forwards[curlevel];prev = prev->forwards[curlevel];}curlevel--;}mtx.unlock();}void print() {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];std::cout << "Level " << curlevel-1 << ": ";while (cur) {std::cout << cur->getKey() << ":" << cur->get_value() << ';';cur = cur->forwards[curlevel];}std::cout << std::endl;curlevel--;}}void dump_file() {std::ofstream out("D:\\dev_c++\\destination\\out.txt");if (out.is_open()) {Node<K,V>* cur = HeadNode;int curlevel = temp_level;while (curlevel) {cur = HeadNode->forwards[curlevel];while (cur) {out << cur->getKey() << ":" << cur->get_value() << '\n';cur = cur->forwards[curlevel];}curlevel--;}out.close();}}void load_file() {std::ifstream in("D:\\dev_c++\\destination\\out.txt");char buffer[256];if (!in.is_open()) {std::cout << "open error";} else {while (!in.eof()) {std::string s;in >> s;int index = 0;if (s.size() == 0) return; for (int i = 0; i < s.length(); i++) {if (s[i] == ':') {index = i;break;}}
// std::cout << s << ' ';std::string s1 = s.substr(0, index);std::string s2 = s.substr(index + 1, s.length() - 1 - index);
// std::cout << s1 << s2 << std::endl;int key = std::stoi(s1);int value = std::stoi(s2);insert_element(key, value);}}}
};跳表项目总结
这次完整做完了一个小项目,花了几天。最后才发现测试时会有一些不测试就发现不了的小bug,所以说测试还是蛮重要的。
相关文章:
Redis核心数据结构——跳表(生成数据到文件和从文件中读取数据、模块合并、)
生成文件和从文件中读取数据。 需求如下: 你的任务是实现 SkipList 类中的数据持久化成员函数和数据加载成员函数。 持久化数据成员函数签名:void dump_file(); 该成员函数负责将存储引擎内的数据持久化到文件中。数据的持久化格式是将每个键值对写入文…...

微信小程序下载文件详解
在微信小程序中,下载文件通常涉及使用 wx.downloadFile API。这个 API 可以将网络资源下载到本地临时文件路径,然后你可以使用 wx.saveFile 将临时文件保存到本地持久存储位置。下面是一个下载文件的详细过程: 使用 wx.downloadFile 下载文件…...

2024 概率论和数理统计/专业考试/本科考研/论文/重点公式考点汇总
## 列表http://www.deepnlp.org/equation/category/statistics ## 均匀分布http://www.deepnlp.org/equation/uniform-distribution ## t-分布http://www.deepnlp.org/equation/student-t-distribution ## 伯努利分布http://www.deepnlp.org/equation/bernoulli-distributio…...

四川易点慧电子商务抖音小店:潜力无限的新零售风口
在当今数字化浪潮中,电子商务已经成为推动经济发展的重要引擎。四川易点慧电子商务有限公司凭借其敏锐的市场洞察力和创新精神,成功在抖音小店这一新兴平台上开辟出一片新天地。本文将探讨四川易点慧电子商务抖音小店的潜力及其在新零售领域的影响力。 一…...

Seal^_^【送书活动第3期】——《Hadoop大数据分析技术》
Seal^_^【送书活动第3期】——《Hadoop大数据分析技术》 一、参与方式二、作者荐语三、图书简介四、本期推荐图书4.1 前 言4.2 本书内容4.3 本书目的4.4 本书适合的读者4.5 配套源码、PPT课件等资源下载 五、目 录六、🛒 链接直达 Hadoop框架入门书,可当…...
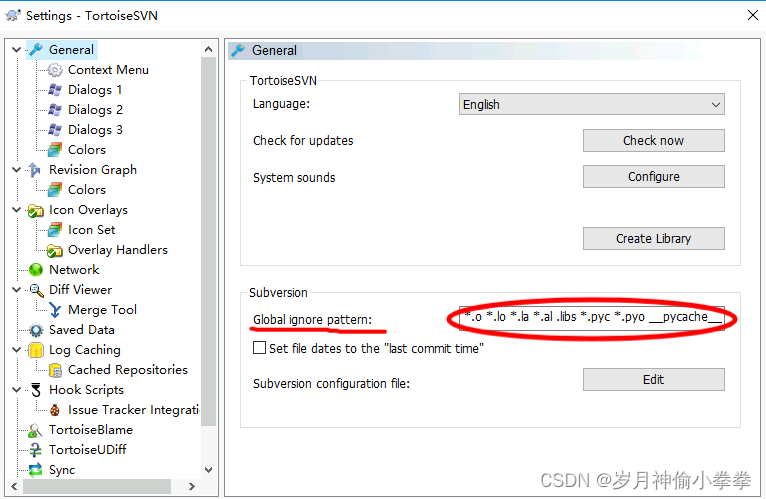
win10下,svn上传.so文件失败
问题:win10下使用TortoiseSVN,svn上传.so文件失败 解决:右键,选择Settings,Global ignore pattern中删除*.so,保存即可。...
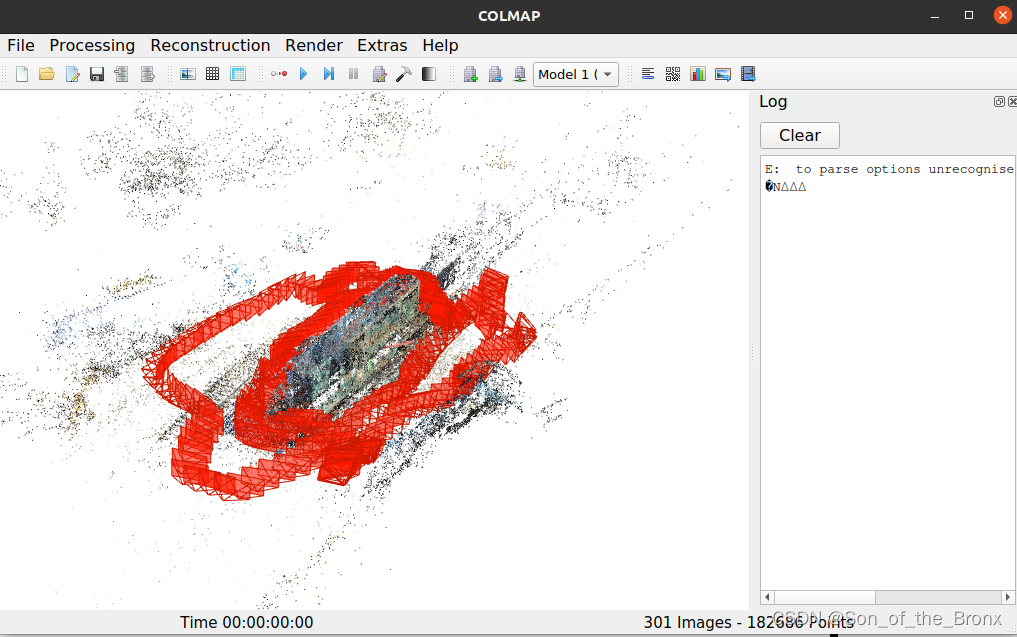
ubuntu20安装colmap
系统环境 ubuntu20 ,cuda11.8 ,也安装了anaconda。因为根据colmap的官方文档说的,如果根据apt-get安装的话,默认是非cuda版本的,而我觉得既然都安装了cuda11.8了,自然也要安装cuda版本的colmap。 安装步骤…...
kubeflow简单记录
kubeflow 13.7k star 1、Training Operator 包括PytorchJob和XGboostJob,支持部署pytorch的分布式训练 2、KFServing快捷的部署推理服务 3、Jupyter Notebook 基于Web的交互式工具 4、Katib做超参数优化 5、Pipeline 基于Argo Workflow提供机器学习流程的创建、编排…...

ARM的工作模式
ARM处理器设计有七种工作模式,这些模式允许处理器在不同的情境下以不同的权限级别执行任务,下面是这七大工作模式的概述: 用户模式(User,USR): 这是非特权模式,大多数应用程序在此…...
为家庭公网IP配置DDNS域名
文章目录 域名配置域名更新frp配置修改 在成功完成frp改造Windows笔记本实现家庭版免费内网穿透之后,某天我突然发现内网穿透失效了,一番排查之后原来是路由器对应的公网IP更换了。果然我分到的并不是固定的公网IP,而是会定期变化的。为了免受…...

QT-TCP通信
网上的资料太过于书面化,所以看起来有的让人云里雾里,看不懂C-tcpsockt和S-tcpsocket的关系 所以我稍微画了一下草图帮助大家理解两个套接字之间的关系。字迹有的飘逸勉强看看 下面是代码 服务端: MainWindow::MainWindow(QWidget *parent) …...

SparkSQL优化
SparkSQL优化 优化说明 缓存数据到内存 Spark SQL可以通过调用spark.sqlContext.cacheTable("tableName") 或者dataFrame.cache(),将表用一种柱状格式( an inmemory columnar format)缓存至内存中。然后Spark SQL在执行查询任务…...
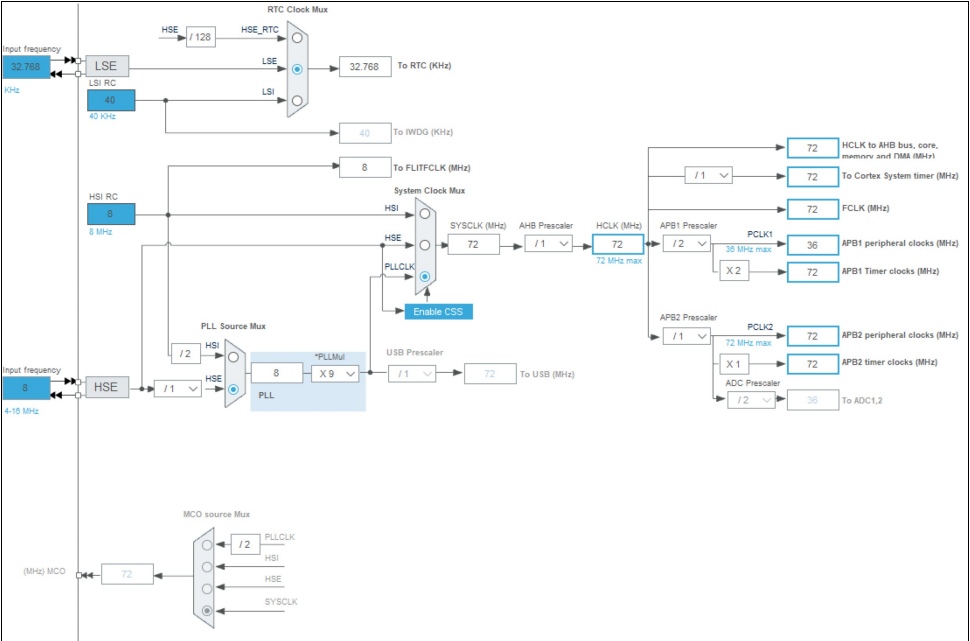
STM32——基础篇
技术笔记! 一、初识STM32 1.1 ARM内核系列 A 系列:Application缩写。高性能应用,比如:手机、电脑、电视等。 R 系列:Real-time缩写。实时性强,汽车电子、军工、无线基带等。 M 系列:Microcont…...
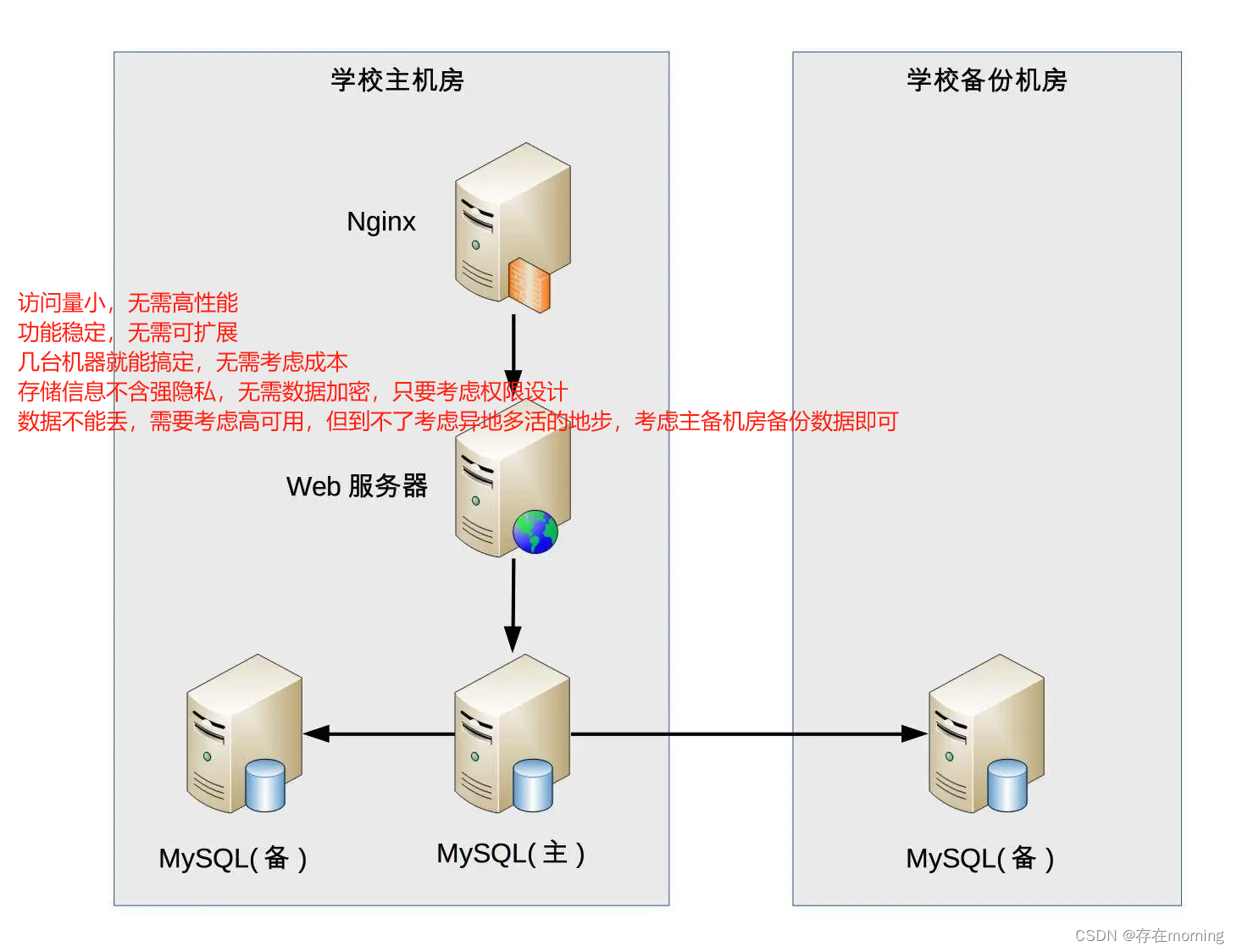
【从零开始学架构 架构基础】架构设计的本质、历史背景和目的
本文是《从零开始学架构》的第一篇学习笔记,主要理解架构的设计的本质定义、历史背景以及目的。 架构设计的本质 分别从三组概念的区别来理解架构设计。 系统与子系统 什么是系统,系统泛指由一群有关联的个体组成,根据某种规则运作&#…...

Learning C# Programming with Unity 3D
作者:Alex Okita 源码地址:GitHub - badkangaroo/UnityProjects: A repo for all of the projects found in the book. 全书 686 页。...

北京车展现场体验商汤DriveAGI自动驾驶大模型展现认知驱动新境界
在2024年北京国际汽车展的舞台上,众多国产车型纷纷亮相,各自展示着独特的魅力。其中,小米SUV7以其精美的外观设计和宽敞的车内空间,吸引了无数目光,成为本届车展上当之无愧的明星。然而,车辆的魅力并不仅限…...
企业终端安全管理软件有哪些?终端安全管理软件哪个好?
终端安全的重要性大家众所周知,关系到生死存亡的东西。 各类终端安全管理软件应运而生,为企业提供全方位、多层次的终端防护。 有哪些企业终端安全管理软件? 一、主流企业终端安全管理软件 1. 域智盾 域智盾是一款专为企业打造的全面终端…...
媒体驱动框架整理--HDMI框架(2))
Linux内核--设备驱动(七)媒体驱动框架整理--HDMI框架(2)
目录 一、引言 二、drm框架 ------>2.1、画布( FrameBuffer ) ------>2.2、绘图现场(CRTC) ------>2.3、输出转换器(Encoder ) ------>2.4、连接器 (Connector ) ------>2.5、显示面(Planner) 三、VOP部分详解 ------>3.1、dts ------>3.2、v…...

3.3 Gateway之自定义过滤器
1.Gateway过滤器种类 过滤器种类描述GatewayFilter路由过滤器,作用于任意指定的路由。默认不生效,要配置到路由后生效GlobalFilter全局过滤器,作用范围是所有路由。声明后自定生效 2.Gateway过滤器参数 参数描述ServerWebExchangeGateway内…...
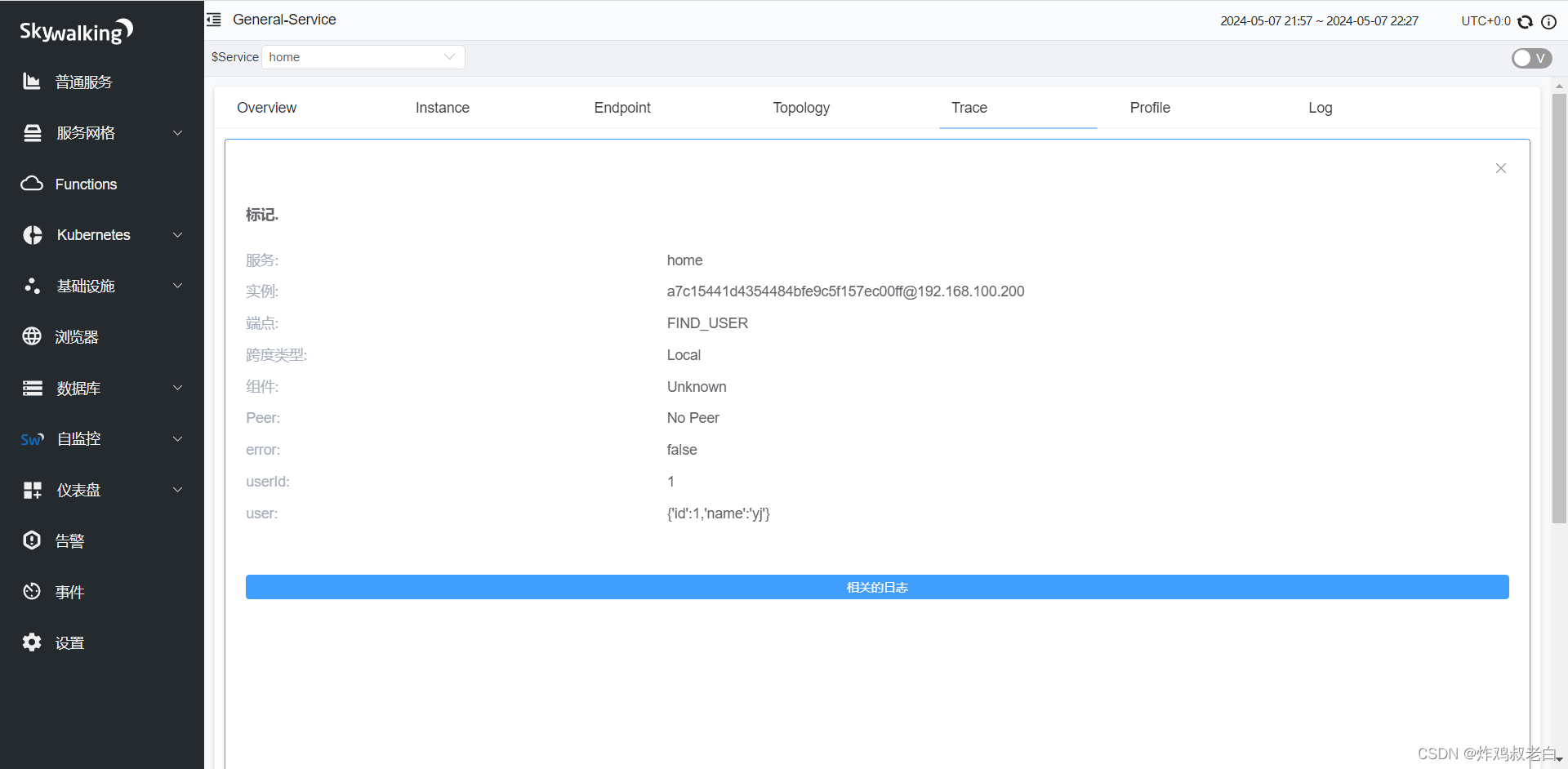
Skywalking数据持久化与自定义链路追踪
学习本篇文章之前首先要了解一下Sky walking的基础知识 分布式链路追踪工具Skywalking详解 一,Sky walking数据持久化 Sky walking提供了es,MySQL等数据持久化方案,默认使用h2基于内存的数据库,重启之后数据即会丢失。 在实际工…...
)
嵌入式网络硬件设计避坑指南:如何为你的SOC选配合适的PHY芯片与接口(MII/RMII实战解析)
嵌入式网络硬件设计避坑指南:如何为你的SOC选配合适的PHY芯片与接口(MII/RMII实战解析) 在嵌入式系统设计中,网络功能已成为现代智能设备的标配需求。无论是工业控制、物联网终端还是消费电子产品,稳定可靠的网络连接往…...

5步快速上手!罗技鼠标宏终极压枪教程:告别手残轻松吃鸡
5步快速上手!罗技鼠标宏终极压枪教程:告别手残轻松吃鸡 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生…...

纯音乐制作难题,智能创作轻松化解
前言:音乐人的创作困境,真的太戳心了 你有没有过这样的时刻?脑子里突然冒出一段超有感觉的旋律,想把它做成完整纯音乐,却被现实难题卡住:不懂编曲,不知道怎么搭配乐器;不会用专业软…...
】的实战应用与局限)
一文掌握【行为克隆 (Behavior Cloning)】的实战应用与局限
1. 行为克隆是什么?从模仿人类到AI决策 想象一下教小朋友骑自行车的情景。你不会先讲解力学原理,而是亲自示范如何保持平衡、如何踩踏板。孩子通过观察和模仿你的动作,逐渐掌握骑行技巧——这就是行为克隆(Behavior Cloning&#…...

Linux CoreDump实战指南:从原理到容器化环境配置与自动化分析
1. 项目概述:为什么我们需要一份CoreDump实战指南?在服务器运维和后台开发领域,最让人头疼的瞬间之一,莫过于半夜被电话叫醒,被告知线上服务“挂了”。登录服务器一看,进程消失得无影无踪,只留下…...

区块链跨链桥接:原理与实现
区块链跨链桥接:原理与实现 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊区块链跨链桥接这个重要话题。作为一个Web3探索者,跨链技术是连接不同区块链生态的关键。今天就来分享一下跨链桥接的原理和实现方式。 什…...

VCSA底层网络配置实战:从IP修改到SSH登录的运维指南
1. 环境准备与基础概念 刚接触VMware vCenter Server Appliance(VCSA)的朋友可能会觉得底层配置有点神秘。其实就像给新买的智能手机设置Wi-Fi一样,我们需要根据实际网络环境调整它的"网络身份"。VCSA本质上是个预配置的Linux虚拟机…...

Next.js Monorepo包管理:使用Yarn Workspace的10个最佳实践指南
Next.js Monorepo包管理:使用Yarn Workspace的10个最佳实践指南 【免费下载链接】nextjs-monorepo-example Collection of monorepo tips & tricks 项目地址: https://gitcode.com/gh_mirrors/ne/nextjs-monorepo-example 在现代前端开发中,…...

如何高效使用Display Driver Uninstaller:显卡驱动清理终极指南
如何高效使用Display Driver Uninstaller:显卡驱动清理终极指南 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uni…...

NLP-Models-Tensorflow在情感分析中的应用:79种分类器的全面评估
NLP-Models-Tensorflow在情感分析中的应用:79种分类器的全面评估 【免费下载链接】NLP-Models-Tensorflow Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 < Tensorflow < 2.0 项目地址: https://gitcode.com/gh_mi…...