【C++学习】栈 | 队列 | 优先级队列 | 反向迭代器
🐱作者:一只大喵咪1201
🐱专栏:《C++学习》
🔥格言:你只管努力,剩下的交给时间!

栈 | 队列 | 优先级队列 | 反向迭代器
- 😼容器适配器
- 🙈什么是适配器
- 🙈STL标准库中stack和queue的底层结构
- 简单了解deque
- 😼stack
- 🙈模拟实现
- 😼queue
- 🙈模拟实现
- 😼priority_queue
- 🙈仿函数(函数对象)
- 🙈模拟实现
- 😼反向迭代器
- 😼总结
这篇文章主要讲解的是栈和队列以及优先级队列的模拟实现,要像模拟实现,必须先了解容器适配器。
😼容器适配器
🙈什么是适配器
适配器是一种设计模式,设计模式是指:一套反复使用的,多人知晓的,经过分类编目的,代码设计经验的总结。
我们之前就接触过一种设计模式,叫做迭代器,再加上现在的适配器,一共是两种设计模式。
- 迭代器:不暴露底层细节,封装后提供统一的方式访问容器的一种模式。
- 适配器:将一个类的接口转换成客户希望的另外一个接口的模式。

就像我们生活中使用的电源适配器一样,已经有的接口是家里的插口,它是220V的,而我们经常使用的电子设备用到的电压远没有这么高,所以就需要将电压进行转换,转换成我们能用的低电压。
比如手机充电器,它就将220V电压转换到了手机能承受的低电压。
🙈STL标准库中stack和queue的底层结构
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为stack和queue列只是对其他容器的接口进行了包装。

红色框中的是容器类型,也就是被改造容器,栈和队列使用的容器是双端队列(deque),优先级队列使用的是vector。栈和队列就是将这些已有容器的接口进行改造,符合我们的要求,这种改造容器出来的结构就是容器适配器。
简单了解deque
- deque(双端队列):是一种双开口的"连续"空间的数据结构。
- 可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。

这是它的成员函数。

它的逻辑结构如上图所示,但实际上并不是连续的空间,而是由多段连续的小空间拼接成的。

- 中控指针数组中存放着多段小连续数组空间的地址,所以它是一个指针数组。
- 连续数据空间的地址是从中控数组的中间位置开始存放的,之后开辟的小连续数组空间的地址向右或者向左存放。
- 当小连续数组被放满数据以后,就会开辟新的小连续数组。
- 如果是尾插,则将新的小连续数组的指针放在中控指针数组中间位置的右边,并且将元素从小连续数组的头部开始插入,直到满了。
- 如果是头插,则将新的小连续数组的指针放在中控指针数组中间位置的坐标,并且将元素从小连续数组的尾部开始插入,直到满了。
- 当中控指针数组存满数据以后,就会将中控指针数组进行扩容,用了存放更多小连续数组的指针。
大概知道了它的存储结构以后,将deque与vector和list作个对比。
- 与vector比较:deque在头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,只需要搬移指针就行,因此其效率是比vector高的。
- 与list比较:deque的底层是连续空间,空间利用率比较高,高速缓存命中率高,而且不需要存储额外字段,最重要的是deque支持下标随机访问。
- 但是,deque有一个致命缺陷:不适合遍历。
- 因为在遍历时deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下。
- 除此之外,在使用下标随机访问时,还需要根据下标计算出这个下标在哪个小连续数组中,有一定的消耗,速度没有vcetor快。
- 而且在中间插入删除时,虽然没有挪动大量的数据,但也是有一定的消耗,速度没有list快。
虽然deque结合了vector和list的优点,但是都没有做到vector和list那么极致,所以在实际中,需要线性结构时,大多数情况下优先考虑vector和list。
deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构进行改造。
😼stack

stack是一个后进先出的数据结构,它不是容器,而是容器适配器。
常用成员函数:

有了string,vector,list的基础,看到这些接口应该会非常熟悉,并且知道它们怎么用。
本喵简单演示下怎么使用:
#include <stack>
#include <iostream>
using namespace std;int main()
{stack<int> st1;st1.push(1);st1.push(2);st1.push(3);st1.push(4);st1.push(5);while (!st1.empty()){cout << st1.top() << " ";st1.pop();}cout << endl;return 0;
}

入栈顺序是12345,出栈顺序是54321。
🙈模拟实现

使用泛型编程,将适配器要改造的容器类型设置成模板参数Container,并且给它一个缺省参数,如果没有指定被改造容器类型就使用deque。
- stack容器适配器就是要将已有的容器接口进行改造,从而符合我们对要求,所以成员变量只有一个容器类型。
stack类中不需要有显式的构造函数,因为编译器自动生成的默认构造函数就能满足要求。
- 自动生成的默认构造函数对自定义类型调用它的默认构造函数。
- 对内置类型不做处理。
我们这里没有内置类型,只有一个自定义类型,而这个自定义类型还是一个已有的容器,所以会调用它的默认构造函数来进行初始化。
接下来就是改造已有容器的接口,让它符合我们对要求。

上图所示代码就是stack那些接口的模拟实现。这些接口都是根据栈的特性来写的。
- 栈的特性:先进后出,插入数据时尾插,出数据时尾删,访问数据只能访问栈顶数据,也就是尾部的数据。
改造的已有容器我们使用的是模板,给了它一个缺省值,默认使用deque作为被改造容器。
既然是模板参数,而且是一个缺省值,那么我们也可以指定被改造的容器类型。
| 被改造容器必有接口 | 改造后的接口 |
|---|---|
| push_back() | push() |
| pop_back() | pop() |
| back() | top() |
| empty() | empty() |
| size() | empty() |
有这些接口的容器,目前我们接触到的而且比较合适的也就是vector,list以及deque。

使用默认deque的容器适配器stack。

使用指定vector的容器适配器stack。

使用指定list的容器适配器stack。
虽然STL标准库中默认的也是deque,但是我们在使用的时候也可以像上面一样指定被改造的容器,对于栈来说,只要能接受它扩容造成的空间浪费,是可以使用vector的。
😼queue

queue是一个先进先出的结构,他同样是一个容器适配器。
常用接口:

简单演示:
void Queue_test()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);while (!q.empty()){cout << q.front() << " ";q.pop();}cout << endl;
}

进队列的顺序是1234,出队列的顺序也是1234。
🙈模拟实现

和栈一样,同样使用模板,被改造的容器给一个确实值,默认使用deque,成员变量只有被改造的容器。
同样不需要显式构造函数,编译器自动生成的默认构造函数就能够满足需求。
下面实现它的各种接口:

同样是对已有容器的接口进行改造。
| 已有容器必有接口 | 改造后接口 |
|---|---|
| push_back() | push() |
| pop_front | pop() |
| back() | back() |
| front() | front() |
| empty() | empty() |
| size() | size() |
和栈一样,有这些接口的容器,我们学习过的,并且合适的只有list和deque,vector是没有front()接口的。

默认使用deque的容器适配器queue。

指定list的容器适配器queue。
queue和satck有一点不同的是,queue不能使用vector作为被改造的容器,因为vector中没有front()接口,而queue是需要用到这个接口的。
虽然STL中使用的默认容器是deque,但是也可以指定list,但是使用list的话就得接受它的缺点,所以说使用deque更好。
😼priority_queue

优先级队列其实就是我们曾经学过的堆,关于堆的内容,在本喵的文章堆的使用原理中有详细介绍,有兴趣的小伙伴可以去看看。
- 优先队列是一种容器适配器,根据严格的排序标准,它的第一个元素总是它所包含的元素中最大或者最小的。
- 此结构类似于堆,在堆中可以随时插入元素,并且只能检索最大或者最小堆元素(优先队列中位于顶部的元素)。
- 同样也是容器适配器,它默认采用的容器是vector。
我们知道,堆的物理结构是数组,而逻辑结构是一个完全二叉树,所以说,vector是最适合优先级队列的已有容器。
常用接口:

简单使用:
void Priority_queue_test()
{priority_queue<int> pq;pq.push(3);pq.push(5);pq.push(6);pq.push(2);pq.push(1);while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;
}

- 在将数据插入优先队列的时候,时乱序插入的。
- 输出到时候,这些数据按照从大到小的顺序输出。
优先级队列是一个堆,按照输出结果来看,第一个堆顶数据是6,第二个堆顶的数据时5,第三个是3以此类推。
还原一下这几个数据入队列后的堆结构:

可以看到,这是一个大根堆。
- 优先级队列,默认情况下是按照大根堆的方式构建的。
那么怎么让它成为小根堆呢?

输出结果中,第一个堆顶数据是1,第二个是2,以此类推。
来看它的堆结构:

可以看到这是一个小根堆。
- 在创建priority_queue时,模板实例化传了三个参数。
- 第一个是插入的数据类型。
- 第二个是底层容器的类型。
- 第三个是仿函数。
是大根堆还是小根堆,主要的依据就这个仿函数,它决定了内部的比较方式。
🙈仿函数(函数对象)

- 红色框中,是一个比较函数,两个数相比,如果第一个比第二个大,则返回真。
- 在Func_test函数中,调用上面的比较函数来进行两个数比较,站在这个函数的角度,它不知道比较的方式是什么,只是使用它的结果。

在主函数中,调用Func_test函数的时候,还需要将比较函数当作实参传过去。也就是主函数告诉子函数用Greater去比较,但是不告诉子函数具体的比较细节。
- 这种方式就是我们自己学习过的回调函数。
- 在子函数中,通过函数指针的方式来调用这个比较函数。
此时,比较函数的两个形参类型是确定的,只能是int类型,如果要比较别的类型就不行了。
而且函数指针的使用感觉不是很方便,这属于C语言的糟粕,所以C++为了弥补,就有了仿函数。
- 仿函数:可以像函数一样使用,但是不是真的函数。
template<class T>
class greater
{
public:bool operator()(const T& x, const T& y) const{return x > y;}
};
写这样的一个类模板,第一个数比第二个大时返回真。
- 使用泛型编程,编译器自动推演数据类型。
- 类中没有成员变量,只有一个成员函数,类对象大小为1字节。
- 使用operator重载函数运算符括号。

此时使用仿函数同样实现了函数指针的功能,而且还支持不同类型的数据,比函数指针好用。
template<class T>
class less
{
public:bool operator()(const T& x, const T& y) const{return x < y;}
};
趁热打铁,将第一个数小于第二个数时返回真的仿函数也写出来。
🙈模拟实现

优先队列也是容器适配器,所以和前面的成员变量一样,只是默认的被改造容器使用的vector。
除此之外,还有一个模板参数是仿函数,默认使用less,也就是第一个数比第二个数小返回真,因为优先级队列要建堆,涉及到了比较,所以要给它一个比较依据。
因为要建大根堆和小根堆,所以就需要向上调整和向下调整数据,先来实现一下这两个函数。
向上调整:
void adjust_up(size_t child)
{Compare com;size_t parent = (child - 1) / 2;while (child > 0){if (com(_con[parent], _con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}elsebreak;}
}
假设仿函数使用less,建立的是大根堆。
- 父节点比子节点小,父子节点交换位置。
- 交换后父节点成为新的子节点,再和他的父节点进行比较。
- 直到子节点到了根的位置,说明这次的向上调整结束。
向下调整:
void adjust_down(size_t parent)
{Compare com;size_t child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && com(_con[child],_con[child + 1])){child++;}if (com(_con[parent], _con[child])){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}elsebreak;}
}
假设仿函数使用less,建立的是大根堆。
- 父节点比子节点小,父子节点交换位置。
- 交换后的子节点成为新的父节点,继续和它的子节点比较。
- 直到子节点的下标超出数组size,说明这次向下调整结束。
这里简单说明一下,详细内容可看本喵另一篇文章堆的使用原理。

可以看到,priority_queue是有构造函数的,所以要实现一下。

使用迭代器区间初始化的构造函数,在初始化列表中,将底层容器初始化以后,它是无序的,而堆是有序的,所以采用向下调整建堆。
- 使用向下调整建堆,时间复杂度是O(N*logN)。
- 这里必须要显式写一个无参的构造函数。
因为已经有使用迭代器区间的构造函数了,此时编译器就不会自动生成无参的默认构造函数了,如果不用迭代器区间初始化去创建一个优先级队列对象,就会导致没有构造函数可掉,会报错没有合适的构造函数。

这是其他接口的模拟实现。
| 底层容器必有接口 | 改造后接口 |
|---|---|
| push_back() | push() |
| pop_back() | pop() |
| operator[] | top() |
| empty() | empty() |
| size() | size() |
在向堆中插入数据和删除数据时,都需要重新调整堆结构,使其符合大堆或者小堆。
插入数据堆调整:
- 新插入数据实际上进行了尾插,插入到了数组的最后一个位置,也就是二叉树最后一个元素。
- 要想继续符合堆结构,就需要将这个新的数据进行向上调整,让它位于正确的位置。
删除数据堆调整:
- 删除数据删除的是数组的第一个元素,如果直接删除掉,不仅破环了堆结构,而且还需要进行大量的数据挪动。
- 所以将第一个元素和最后一个元素的位置互换,进行尾删,然后将第一个元素向下调整,让它位于正确的位置。

默认使用的底层容器是vector,默认使用的仿函数是less。

指定底层结构是vector,知道仿函数是less,和默认情况一样。

指定底层容器vector,指定仿函数greater。
说明:

priority_queue类模板的三个参数中,只有第一个不是缺省值,后两个都是缺省值。
- 虽然只需要给第一个和第三个传参就行。
- 但是和函数一样,给带有缺省参数的函数或模板传参时,只能从左向右传。
所以要想指定仿函数,还需要指定底层容器。
😼反向迭代器
我们模拟实现string,vector,list等结构的时候,都没有模拟实现过反向迭代器,是因为反向迭代器最好的实现方式也是使用适配器。
既然是适配器,那么它改造的是谁呢?改造的是正向的迭代器,无论是普通反向迭代器还是const反向迭代器,改造的都是普通正向迭代器。

改造的底层容器是正向迭代器,所以第一个模板参数是一个迭代器,具体是list迭代器还是vector迭代器,并不知道,所以采用的是泛型编程。
第二个和第三个模板参数和list中迭代器一样,是为了简化const反向迭代器的代码而加的模板参数。

| 被改造容器接口 | 改造后的接口 |
|---|---|
| operator*() | operator*() |
| operator–() | operator++() |
| operator++() | operator–() |
| operator!=() | operator!=() |
- 反向迭代器需要构造函数,因为迭代器都是迭代器来初始化的。

在进行解引用运算符重载的时候,先进行了减减,然后才进行的解引用。

无论是链表还是vector,它们的正向迭代器和反向迭代器都是对称的。
- begin()和rend()指向同一个位置。
- end()和rbegin()指向同一个位置。
当解引用rbegin()的时候,此时得到的内容并不是结构中的内容,所以要先进行end()减减,再解引用。
当解引用rend()的时候,此时得到的是首元素的内容,但是我们要的是结构之外的第一个内容,所以要进行begin()减减,在解引用。
所以说,反向迭代器的解引用,要将底层容器的迭代器先减减,再解引用。
在list中验证:

在我们曾经写的list中,将reverse_iterator和const_reverse_iterator定义出来,和普通迭代器一样,如上图中红色框中所示。

再在list中写获得rbegin,rend以及crbegin,crend的接口,根据前面的分析,是用正向迭代器对称初始化的,如上图所示。

可以和标准库中的反向迭代器一样使用。

可以和标准库中的const反向迭代器一样使用。

const的迭代器同样不可以被修改。
在vector中验证:

在我们之前写的vector中,定义俩种反向迭代器,如上图中红色框中所示。

和list一样,写对应的接口函数,如上图中所示。

和标准库中的反向迭代器一样,可以正常使用。

修改const迭代器指向的内容时,也会报常量不可修改的错误。
- 反向迭代器我们只写了一份。
- 底层容器是list迭代器和vector的迭代器都可以正常使用。
😼总结
这篇文章主要讲解的就是适配器模式,无论是stack,queue,priority_queue,还是迭代器,它们都是容器适配器,这是底层的容器不一样,而且我们也发现,适配器是真的好用。
相关文章:
【C++学习】栈 | 队列 | 优先级队列 | 反向迭代器
🐱作者:一只大喵咪1201 🐱专栏:《C学习》 🔥格言:你只管努力,剩下的交给时间! 栈 | 队列 | 优先级队列 | 反向迭代器😼容器适配器🙈什么是适配器ὤ…...

Python—看我分析下已经退市的 可转债 都有什么特点
分析 需求分析 可转债退市原因的种类与占比是多少 强赎与非强赎导致的退市可转债 存续时间 维度占比 强赎与非强赎导致的退市可转债 发行资金 规模占比 强赎与非强赎导致的退市可转债 各个评级 的占比 强赎与非强赎导致的退市可转债 各个行业(一级行业…...

【第八课】空间数据基础与处理——数据结构转化
一、前言 数据结构即指数据组织的形式,是适合于计算机存储、管理和处理的数据逻辑结构。对空间数据则是地理实体的空间排列方式和相互关系的抽象描述。它是对数据的一种理解和解释,不说明数据结构的数据是毫无用处的,不仅用户无法理解,计算机程序也不能正确地处理,对同样一组数…...

MATLAB绘制三Y轴坐标图:补充坐标轴及字体设置
三轴坐标图 1 函数 MATLAB绘制三轴图函数可见MATLAB帮助-multiplotyyy 基础图形绘制是很简单,但坐标轴及字体设置该如何实现呢? 本文以以下几个例子为例,希望可以解决在利用MATLAB绘制三轴坐标图时常见的疑惑。 2 案例 2.1 案例1…...
springboot项目中Quartz
下面内容大家可在自己创建的 springboot项目中 玩1 定时清理垃圾图片定时任务组件Quartz,可以根据我们设定的周期,定时执行目标任务计划1.1 Quartz介绍(了解)Quartz是Job scheduling(作业调度)领域的一个开源项目&…...
Presto本地开发,plugin的设置
1. 新的问题 之前搭建Presto的本地开发环境时,一直使用config.properties中的plugin.bundles配置项定义需要加载的plugin模块,详细可以参考博客《win10基于IDEA,搭建Presto开发环境》presto服务启动时,指定加载哪些组件ÿ…...

2023年3月西安/杭州/深圳/东莞NPDP产品经理认证考试报名
产品经理国际资格认证NPDP是国际公认的唯一的新产品开发专业认证,集理论、方法与实践为一体的全方位的知识体系,为公司组织层级进行规划、决策、执行提供良好的方法体系支撑。 【认证机构】 产品开发与管理协会(PDMA)成立于1979年…...

Vue3笔记01 创建项目,Composition API,新组件,其他
Vue3 创建Vue3项目 vue-cli //查看vue/cli版本,确保在4.5.0以上 vue --version //安装或升级vue/cli npm install -g vue/cli //创建项目 vue create new_project //启动 cd new_project npm run serve 也可以通过vue ui进入图形化界面进行创建 vite 新一代前端…...
pandas数据分析(二)
文章目录DataFrame数据处理与分析读取Excel文件中的数据筛选符合特定条件的数据查看数据特征和统计信息按不同标准对数据排序使用分组与聚合对员工业绩进行汇总DataFrame数据处理与分析 部分数据如下 这个数据百度可以搜到,就是下面这个 读取Excel文件中的数据 …...

Spring实现[拦截器+统一异常处理+统一数据返回]
Spring拦截器 1.实现一个普通拦截器 关键步骤 实现 HandlerInterceptor 接口重写 preHeadler 方法,在方法中编写自己的业务代码 Component public class LoginInterceptor implements HandlerInterceptor {/*** 此方法返回一个 boolean,如果为 true …...
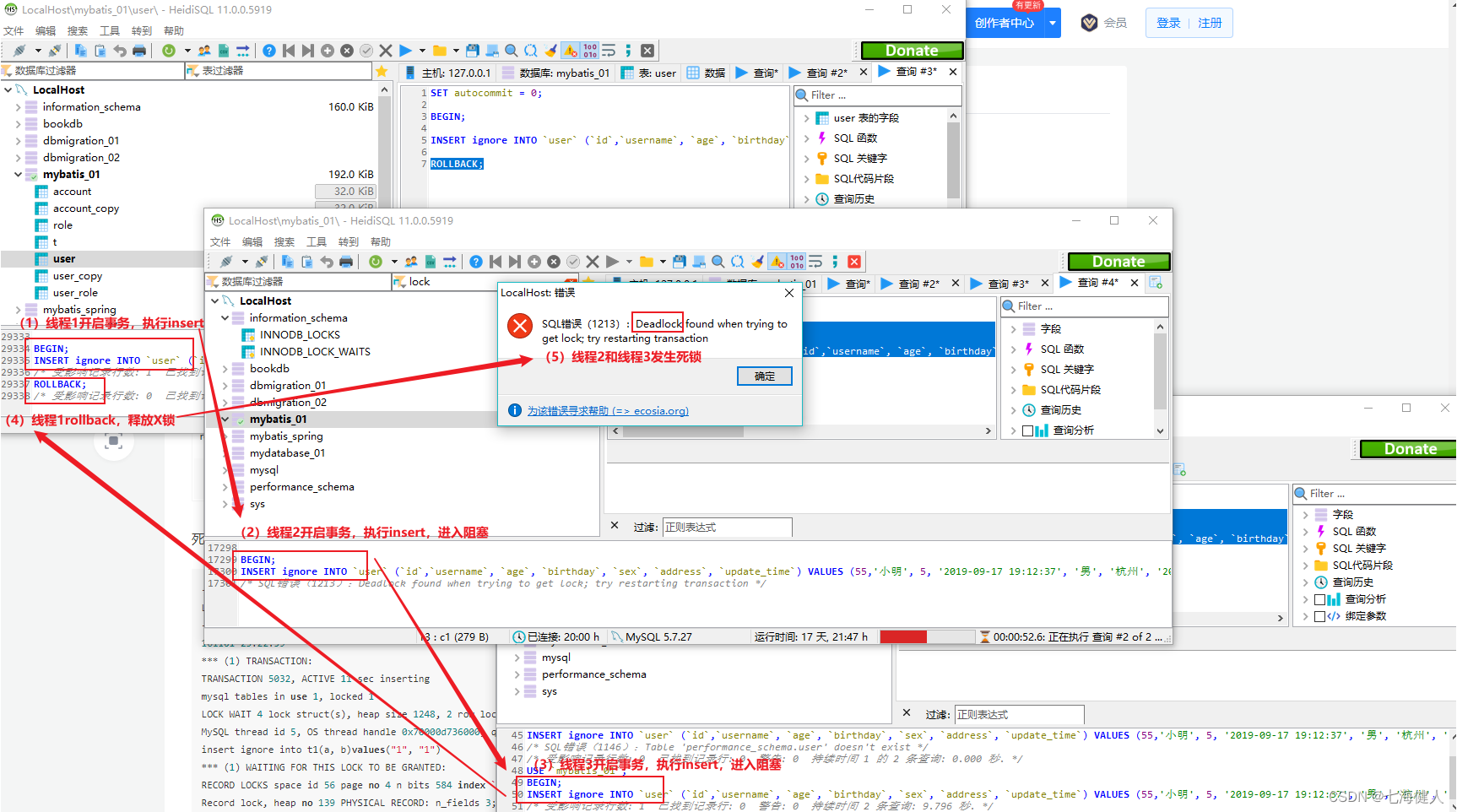
MySQL——插入加锁/唯一索引插入死锁/批量插入效率
本篇主要介绍MySQL跟加锁相关的一些概念、MySQL执行插入Insert时的加锁过程、唯一索引下批量插入可能导致的死锁情况,以及分别从业务角度和MySQL配置角度介绍提升批量插入的效率的方法;MySQL跟加锁相关的一些概念在介绍MySQL执行插入的加锁过程之前&…...

【专项训练】数组、链表
数组array: list = []链表linked list # Definition for singly-linked list. class ListNode:def __init__(self, x):self.val = xself.next =...
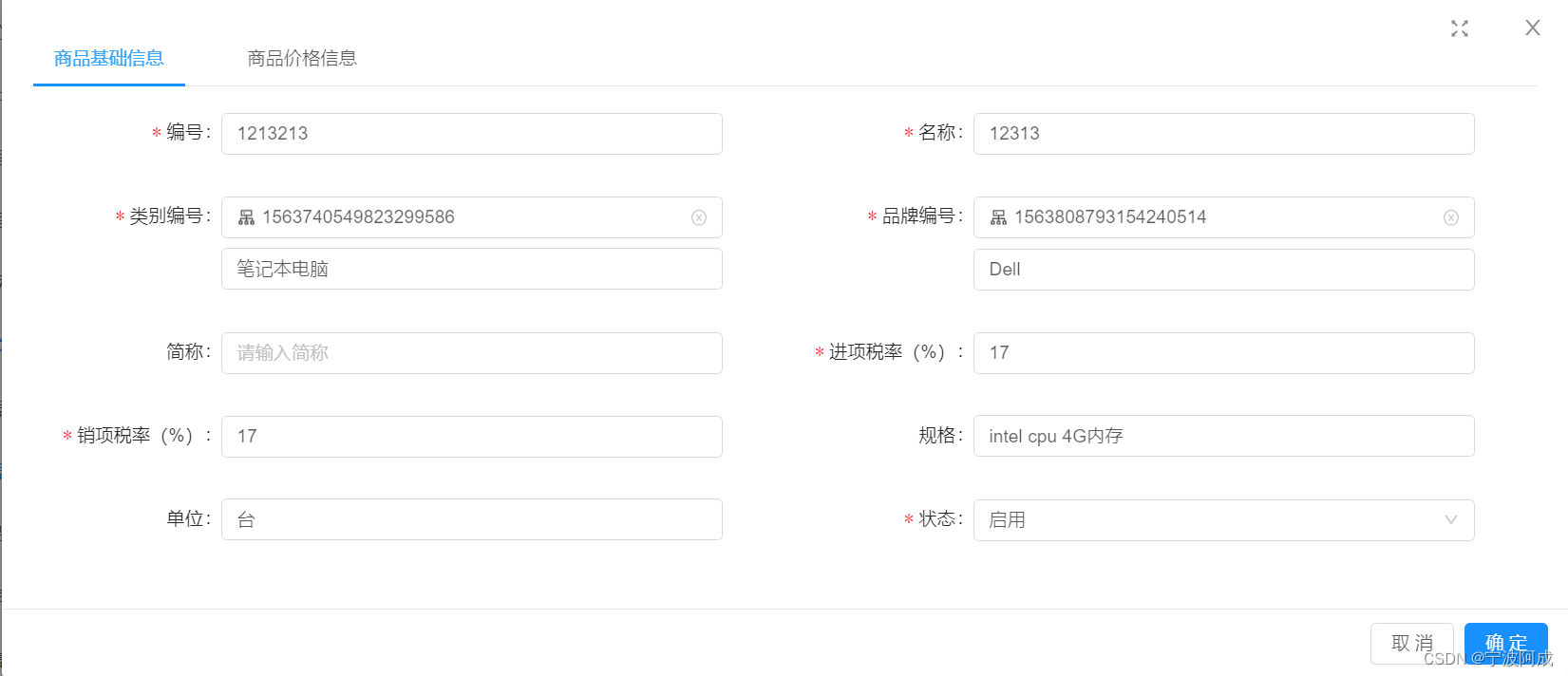
基于Jeecgboot前后端分离的ERP系统开发代码生成(六)
商品信息原先生成的不符合要求,重新生成,包括一个附表商品价格信息表 一、采用TAB主题一对多的模式 因为主键,在online表单配置是灰的,所以不能进行外键管理,只能通过下面数据库进行关联录入,否则online界面…...

什么?同步代码块失效了?-- 自定义类加载器引起的问题
一、背景 最近编码过程中遇到了一个非常奇怪的问题,基于单例对象的同步代码块似乎失效了,百思不得其姐。 下面给出模拟过程和最终的结论。 二、场景描述和模拟 2.1 现象描述 Database实现单例,在 init 方法中使用同步代码块来保证 data不…...

CHAPTER 4 文件共享 - Samba
文件共享 - Samba1 Samba1.1 Samba的软件架构1.2 搭建Samba服务器1.3 samba用户管理1. 添加用户2. 修改用户密码3. 删除用户和密码4. 查看samba用户列表5. 查看samba服务器状态1.4 samba共享设置(配置文件详解)1.5 访问共享目录1. windows访问2. linux客…...
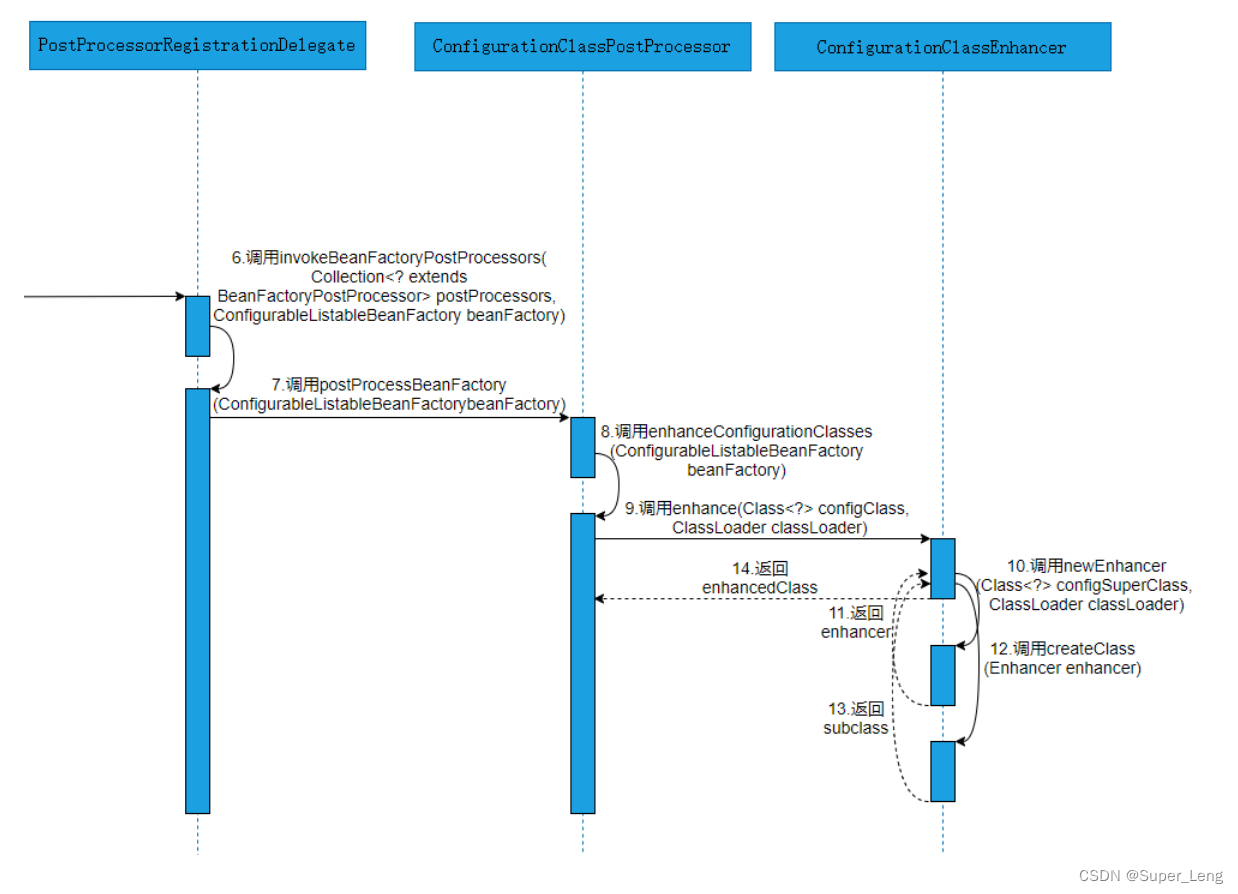
深入分析@Configuration源码
文章目录一、源码时序图1. 注册ConfigurationClassPostProcessor流程源码时序图2. 注册ConfigurationAnnotationConfig流程源码时序图3. 实例化流程源码时序图二、源码解析1. 注册ConfigurationClassPostProcessor流程源码解析(1)运行案例程序启动类Conf…...

Unity 代码优化 内存管理优化
项目遇到了卡顿的情况 仔细检查了代码没检查出有误的地方 仔细的总结了一下可以优化的东西 解决了卡顿 记录一下 1 协程 项目之前写的关于倒计时之类的东西 都是开了个协程 虽然协程是消耗很小的线程 , 可是还是有额外消耗 而且 有很多用携程来检测销毁预制体的操作 也都放到U…...
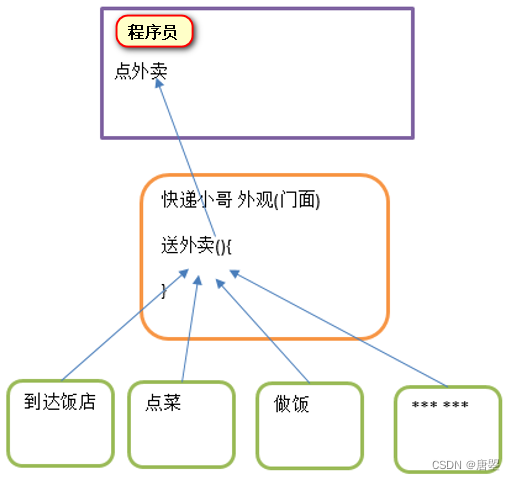
设计模式~门面(外观)模式(Facade)-08
目录 (1)优点 (2)缺点 (3)使用场景 (4)注意事项: (5)应用实例: (6)源码中的经典应用 代码 外观模式&am…...

C++面向对象编程之一:封装
C面向对象编程三大特性为:封装,继承,多态。C认为万事万物皆为对象,对象有属性和行为。比如:游戏里的地图场景可以看作是长方形对象,属性场景id,有长,有宽,可能有NPC&…...

IDEA插件系列(3):Maven Helper插件
一、引言在写Java代码的时候,我们可能会出现Jar包的冲突的问题,这时候就需要我们去解决依赖冲突了,而解决依赖冲突就需要先找到是那些依赖发生了冲突,当项目比较小的时候,还比较依靠IEDA的【Diagrams】查看依赖关系&am…...

MeritOpt:动态权重聚合算法在低资源NLP任务中的应用与实现
1. 项目概述与核心挑战在自然语言处理领域,低资源语言任务一直是个棘手的问题。想象一下,你手头只有几千条某个小语种的翻译对,却要训练一个能流畅翻译的模型,这就像试图用几块砖头盖起一栋大楼。传统的做法要么是“闭门造车”&am…...

K210开发板固件烧录终极指南:kflash_gui完全使用手册
K210开发板固件烧录终极指南:kflash_gui完全使用手册 【免费下载链接】kflash_gui Cross platform GUI wrapper for kflash.py (download(/burn) tool for k210) 项目地址: https://gitcode.com/gh_mirrors/kf/kflash_gui 你是否正在为K210开发板固件烧录而烦…...

VMware Workstation Pro 17免费许可证密钥终极指南:快速搭建专业虚拟化环境
VMware Workstation Pro 17免费许可证密钥终极指南:快速搭建专业虚拟化环境 【免费下载链接】VMware-Workstation-Pro-17-Licence-Keys Free VMware Workstation Pro 17 full license keys. Weve meticulously organized thousands of keys, catering to all major …...
)
别再只用体素网格了!PCL点云降采样实战:4种方法对比与选型指南(附Python/Open3D代码)
点云降采样实战指南:4种核心方法深度解析与工程选型点云数据处理中,降采样往往是预处理环节的关键一步。面对海量的三维点云数据,如何在不丢失重要几何特征的前提下,有效减少数据量?这直接关系到后续算法的效率和精度。…...

突破小红书反爬:5个User-Agent伪装策略与实战指南
突破小红书反爬:5个User-Agent伪装策略与实战指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...
)
别再为DBSCAN调参发愁了!用Python的sklearn轻松上手OPTICS聚类(附实战代码)
用OPTICS算法告别DBSCAN调参噩梦:Python实战全解析当面对不规则形状或密度不均的数据集时,密度聚类算法往往能大显身手。DBSCAN作为其中最著名的代表,却让无数数据科学家又爱又恨——它的表现极度依赖两个关键参数ε和MinPts的选择࿰…...

Z变换与数字滤波器设计:从零极点分析到Python实战
1. 从理论到代码:Z变换如何成为数字信号处理的“瑞士军刀”如果你刚开始接触数字信号处理,可能会觉得Z变换是个有点抽象的数学工具。但在我十多年的音频算法和通信系统开发经历里,Z变换远不止是教科书上的公式——它是我们设计、分析和调试数…...

建筑项目进度延误率下降37%的秘密:一个轻量化AI Agent工作流,已在12个EPC项目中闭环验证
更多请点击: https://codechina.net 第一章:建筑项目进度延误率下降37%的秘密:一个轻量化AI Agent工作流,已在12个EPC项目中闭环验证 在某头部工程总承包(EPC)企业落地的轻量化AI Agent工作流,…...

从λκ观测量到喷注鉴别:探索夸克与胶子分类的最优尺度
1. 项目概述与核心问题在大型强子对撞机(LHC)上,我们每秒要处理数以亿计的质子-质子对撞事件。这些对撞产生的绝大多数产物,是量子色动力学(QCD)主导的强子化过程所形成的“喷注”——即高度准直的强子流。…...

ES 模块:JavaScript 模块化的标准方案
ES 模块:JavaScript 模块化的标准方案 什么是 ES 模块? ES 模块(ES Modules,简称 ESM)是 ECMAScript 2015(ES6)引入的官方模块化规范。 ES 模块 vs CommonJS 特性CommonJSES Modules加载方式同步…...