向量数据库:PGVector
一、PGVector 介绍
PGVector 是一个基于 PostgreSQL 的扩展插件,为用户提供了一套强大的向量存储和查询的功能:
- 精确和近似最近邻搜索
- 单精度(Single-precision)、半精度(Half-precision)、二进制(Binary)和稀疏向量(Sparse Vectors)
- L2 距离(L2 Distance)、内积(Inner Product)、余弦距离(Cosine Distance)、L1 距离(L1 Distance)、汉明距离(Hamming Distance)和 Jaccard 距离(Jaccard Distance)
- 支持 ACID 事务、点时间恢复、JOIN 操作,以及 Postgres 所有的其他优秀特性
二、安装 PGVector
2.1 安装 PostgreSQL
PGVector是基于PostgreSQL的扩展插件,要使用PGVector需要先安装PostgreSQL(支持Postgres 12以上),PostgreSQL具体安装操作可参考:PostgreSQL基本操作。
2.2 安装 PGVector
# 1.下载
git clone --branch v0.7.0 https://github.com/pgvector/pgvector.git
# 2.进入下载目录
cd pgvector# 3.编译安装
make && make install
2.3 启用 PGVector
登录PostgreSQL数据库,执行以下命令启用PGVector:
CREATE EXTENSION IF NOT EXISTS vector;

三、PGVector 日常使用
3.1 存储数据
创建向量字段:
#建表时,创建向量字段
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
#已有表,新增向量字段
ALTER TABLE items ADD COLUMN embedding vector(3);
插入向量数据:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
更新向量数据:
UPDATE items SET embedding = '[1,2,3]' WHERE id = 1;
删除向量数据:
DELETE FROM items WHERE id = 1;
3.2 查询数据
| 操作符 | 函数 | 距离类型 |
|---|---|---|
| <-> | l2_distance | 两个向量相减得到的新向量的长度 |
| <#> | vector_negative_inner_product | 两个向量内积的负值 |
| <=> | cosine_distance | 两个向量夹角的cos值 |
| <+> |
Get the nearest neighbors to a vector
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
Get the nearest neighbors to a row
SELECT * FROM items WHERE id != 1 ORDER BY embedding <-> (SELECT embedding FROM items WHERE id = 1) LIMIT 5;
Get rows within a certain distance
SELECT * FROM items WHERE embedding <-> '[3,1,2]' < 5;
Get the distance
SELECT embedding <-> '[3,1,2]' AS distance FROM items;
For inner product, multiply by -1 (since <#> returns the negative inner product)
SELECT (embedding <#> '[3,1,2]') * -1 AS inner_product FROM items;
For cosine similarity, use 1 - cosine distance
SELECT 1 - (embedding <=> '[3,1,2]') AS cosine_similarity FROM items;
Average vectors
SELECT AVG(embedding) FROM items;
Average groups of vectors
SELECT category_id, AVG(embedding) FROM items GROUP BY category_id;
3.3 HNSW 索引
HNSW索引创建了一个多层图。在速度-召回权衡方面,它的查询性能优于IVFFlat,但构建时间较慢且占用更多内存。另外,由于没有像IVFFlat那样的训练步骤,可以在表中没有数据的情况下创建索引。
Supported types are:
- vector - up to 2,000 dimensions
- halfvec - up to 4,000 dimensions (added in 0.7.0)
- bit - up to 64,000 dimensions (added in 0.7.0)
- sparsevec - up to 1,000 non-zero elements (added in 0.7.0)
L2 distance
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops);
Inner product
CREATE INDEX ON items USING hnsw (embedding vector_ip_ops);
Cosine distance
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops);
L1 distance - added in 0.7.0
CREATE INDEX ON items USING hnsw (embedding vector_l1_ops);
Hamming distance - added in 0.7.0
CREATE INDEX ON items USING hnsw (embedding bit_hamming_ops);
Jaccard distance - added in 0.7.0
CREATE INDEX ON items USING hnsw (embedding bit_jaccard_ops);
3.4 IVFFlat 索引
IVFFlat索引将向量划分为列表,然后搜索最接近查询向量的那些列表的子集。它的构建时间比HNSW快,且占用更少内存,但查询性能(就速度-召回权衡而言)较低。
Supported types are:
- vector - up to 2,000 dimensions
- halfvec - up to 4,000 dimensions (added in 0.7.0)
- bit - up to 64,000 dimensions (added in 0.7.0)
L2 distance
CREATE INDEX ON items USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
Inner product
CREATE INDEX ON items USING ivfflat (embedding vector_ip_ops) WITH (lists = 100);
Cosine distance
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
Hamming distance - added in 0.7.0
CREATE INDEX ON items USING ivfflat (embedding bit_hamming_ops) WITH (lists = 100);
相关文章:
向量数据库:PGVector
一、PGVector 介绍 PGVector 是一个基于 PostgreSQL 的扩展插件,为用户提供了一套强大的向量存储和查询的功能: 精确和近似最近邻搜索单精度(Single-precision)、半精度(Half-precision)、二进制ÿ…...

redux实现原理
Redux 是一个用于 JavaScript 应用程序状态管理的库。它被设计用来管理整个应用程序的状态,并且与 React 结合使用时非常流行。Redux 的实现原理可以简要概括为以下几个关键概念: 单一数据源 (Single Source of Truth):Redux 应用程序的所有状…...
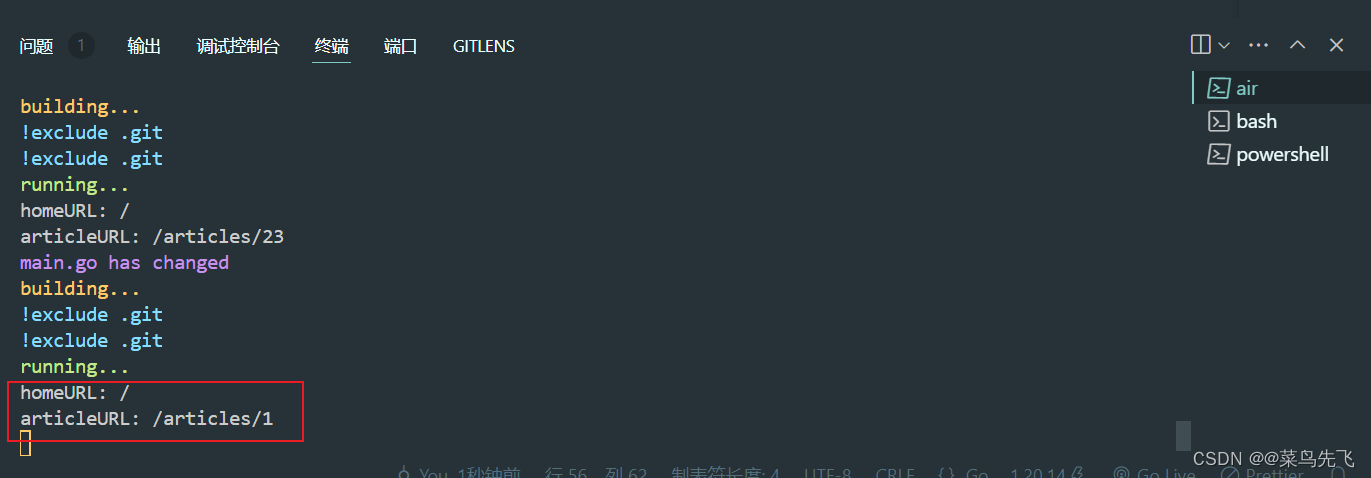
【go项目01_学习记录04】
学习记录 1 集成 Gorilla Mux1.1 为什么不选择 HttpRouter?1.2 安装 gorilla/mux1.3 使用 gorilla/mux1.4 迁移到 Gorilla Mux1.4.1 新增 homeHandler1.4.2 指定 Methods () 来区分请求方法1.4.3 请求路径参数和正则匹配1.4.4 命名路由与链接生成 1 集成 Gorilla Mu…...
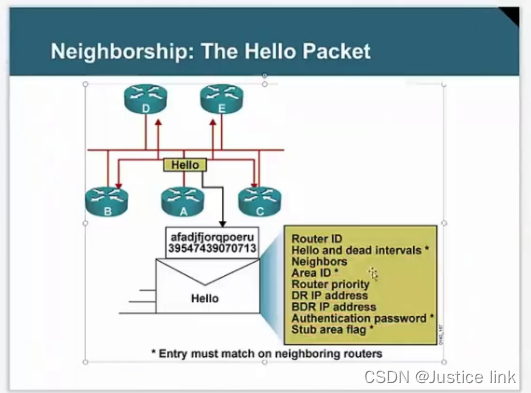
HCIP第二节
OSPF:开放式最短路径协议(属于IGP-内部网关路由协议) 优点:相比与静态可以实时收敛 更新方式:触发更新:224.0.0.5/6 周期更新:30min 在华为设备欸中,默认ospf优先级是10&#…...
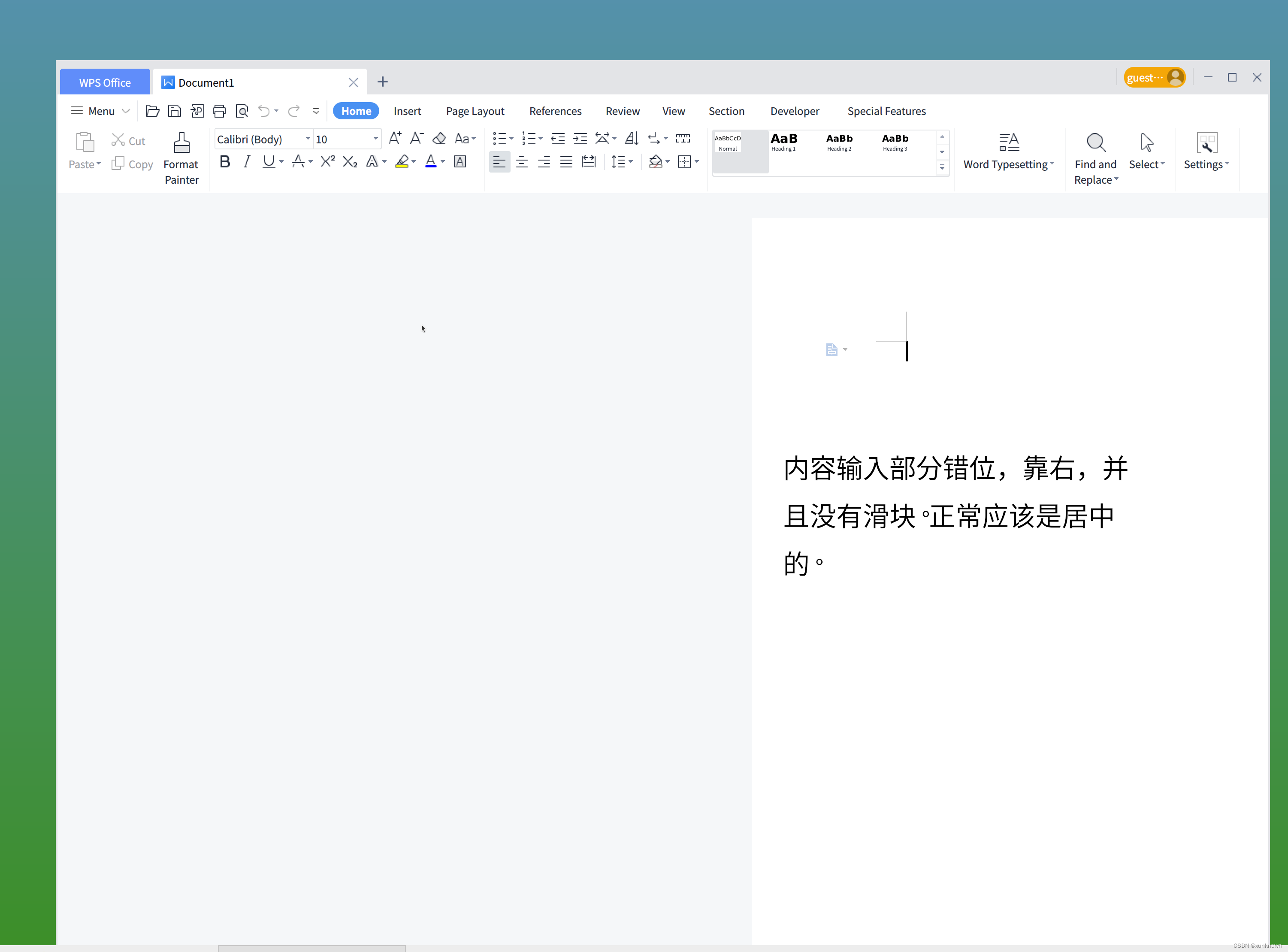
Ubuntu MATE系统下WPS显示错位
系统:Ubuntu MATE 22.04和24.04,在显示器设置200%放大的情况下,显示错位。 显示器配置: WPS显示错位: 这个问题当前没有找到好的解决方式。 因为4K显示屏设置4K分辨率,图标,字体太小ÿ…...

Mysql进阶-索引篇
Mysql进阶 存储引擎前言特点对比 索引介绍常见的索引结构索引分类索引语法sql分析索引使用原则索引失效的几种情况sql提示覆盖索引前缀索引索引设计原则 存储引擎 前言 Mysql的体系结构: 连接层 最上层是一些客户端和链接服务,主要完成一些类似于连接…...
【算法系列】哈希表
目录 哈希表总结 leetcode题目 一、两数之和 二、判定是否互为字符重排 三、存在重复元素 四、存在重复元素 II 五、字母异位词分组 六、在长度2N的数组中找出重复N次的元素 七、两个数组的交集 八、两个数组的交集 II 九、两句话中的不常见单词 哈希表总结 1.存储数…...
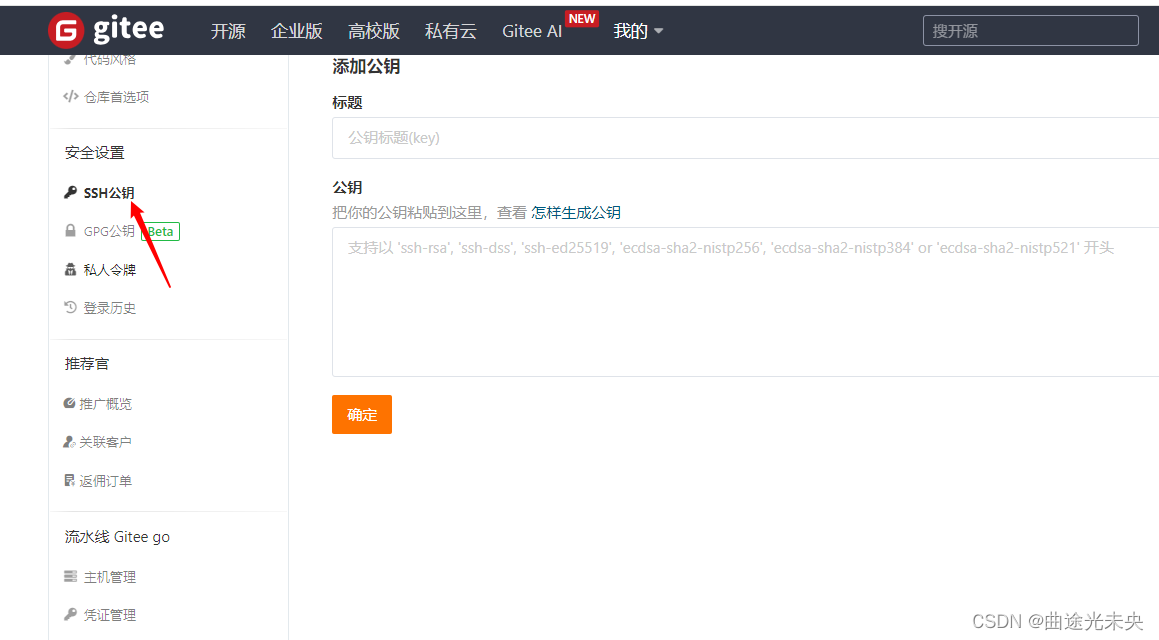
Git推送本地项目到gitee远程仓库
Git 是一个功能强大的分布式版本控制系统,它允许多人协作开发项目,同时有效管理代码的历史版本。开发者可以克隆一个公共仓库到本地,进行更改后将更新推送回服务器,或从服务器拉取他人更改,实现代码的同步和版本控制。…...

一键复制:基于vue实现的tab切换效果
需求:顶部栏有切换功能,内容区域随顶部切换而变化 目录 实现效果实现代码使用示例在线预览 实现效果 如下 实现代码 组件代码 MoTab.vue <template><div class"mo-tab"><divv-for"item in options"class"m…...
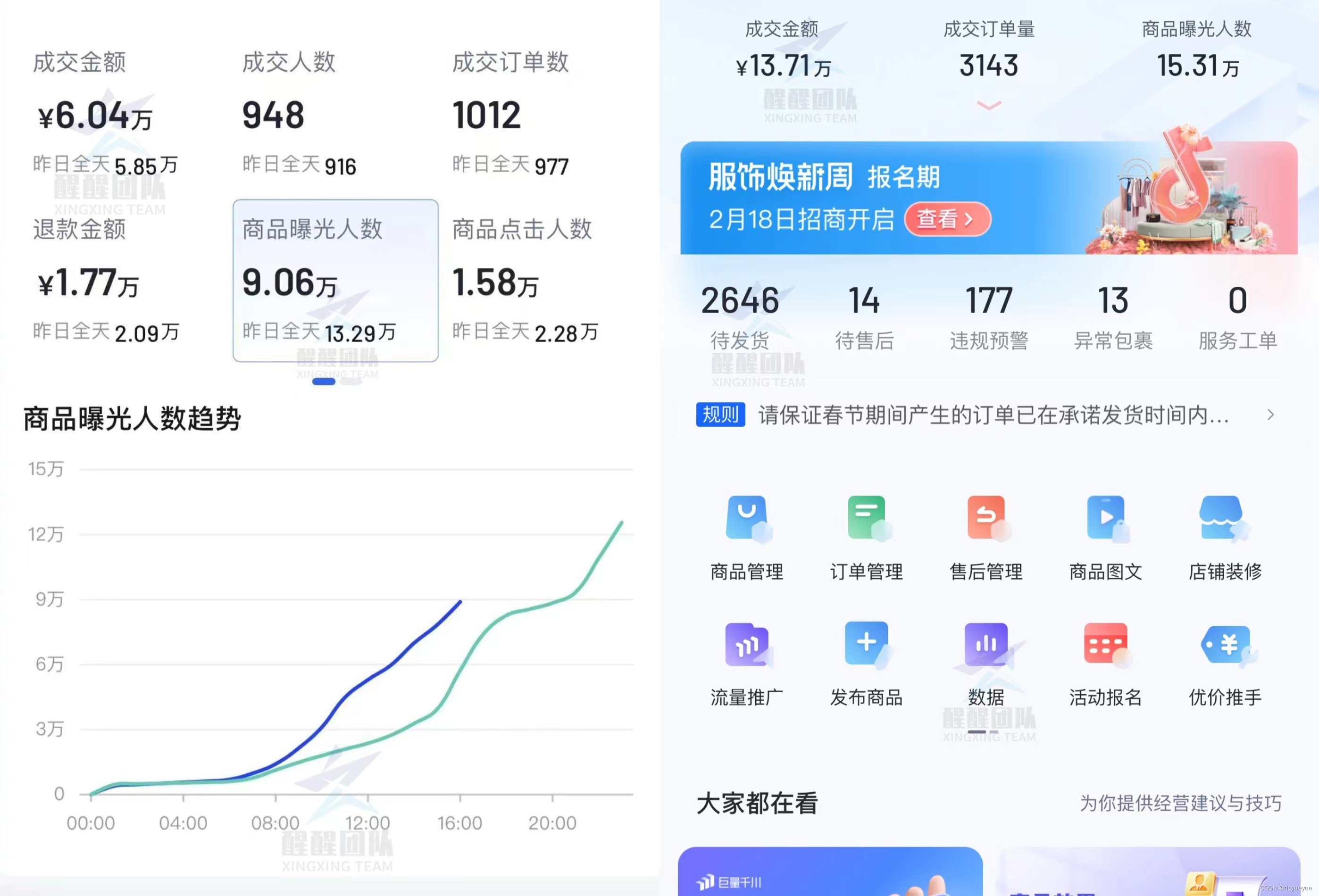
新手做抖音小店,卖什么最容易出单?抖音必爆类目来了!
哈喽!我是电商月月 新手做抖音小店没有经验,也不了解市场需求,最好奇的就是:卖什么商品最容易出单,还在犹豫的朋友可以看看这五种类目,在2024年下半年必定火爆一次 一.生活电器类 天气炎热&a…...

男人圣经 10
男人圣经 10 行业基因 你在对行业、客户群体、事情、核心优势上的高感知力 行业基因 你在对行业、客户群体、事情、核心优势上的高感知力 灵性,我感觉是对人、对事情、对行业的感知力,这就是你的天赋程度。 比如情圣,他比女人更懂自己&am…...
ip)
如何让路由器分配固定网段(网络号)ip
一.wan和lan wan广域网,负责连接互联网 lan局域网,负责保证一个区域内的设备可以互相通讯,比如wife就是让所有连接设备处于同一网段下 一.问题导入 1.我们平时在虚拟机和实体机通信时 必须让它们位于同一ip网段下。 通过winscp等软件进行…...
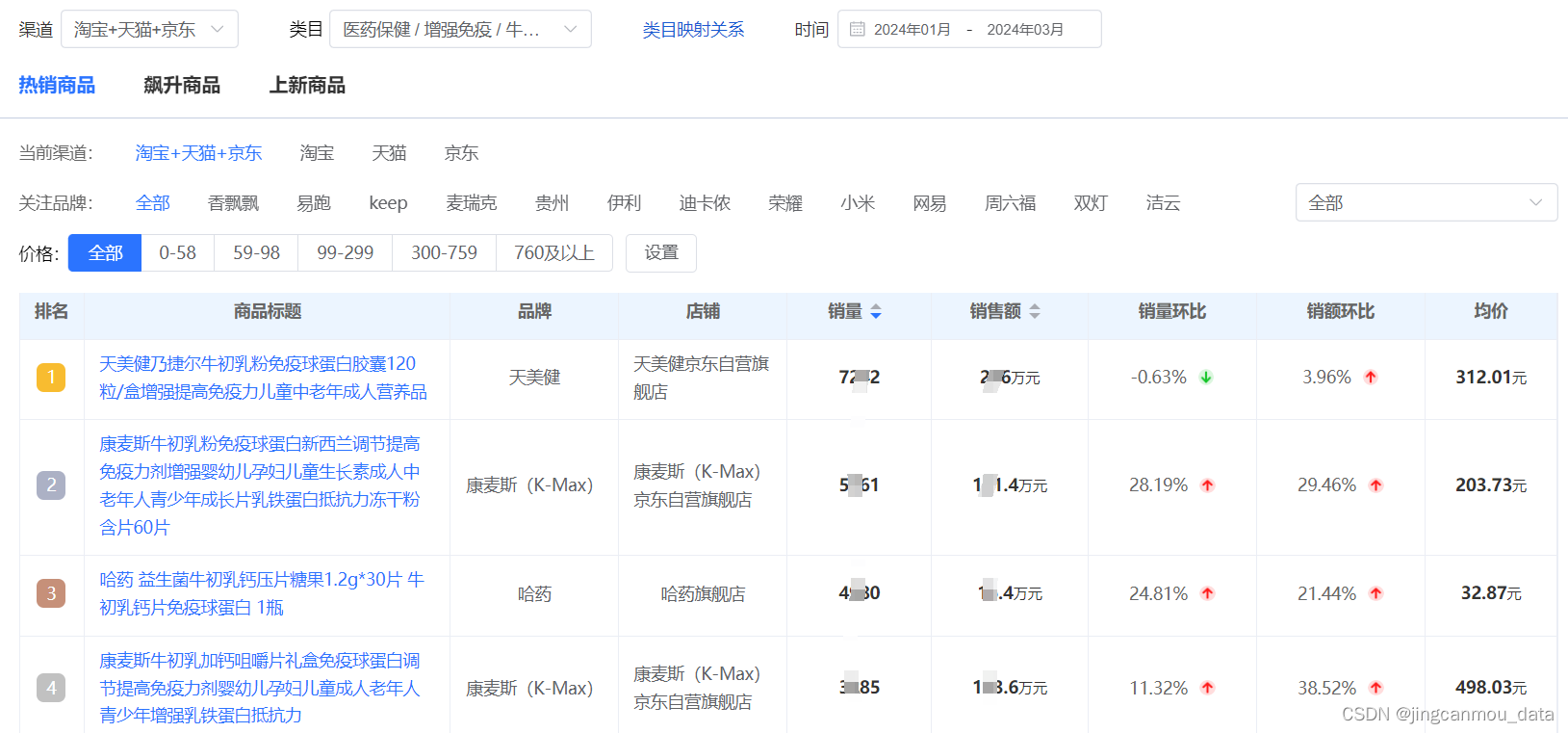
Q1保健品线上市场分析(三):牛初乳市场扩张,同比去年增长54%
近几年,牛初乳在多项科学研究支撑下,其卓越的“肠道免疫力”正得到越来越多的挖掘、验证和商业化尝试。因此,随着人们对健康饮食的重视,牛初乳产品的需求量也在逐年增加,市场潜力巨大。 根据鲸参谋数据显示࿰…...
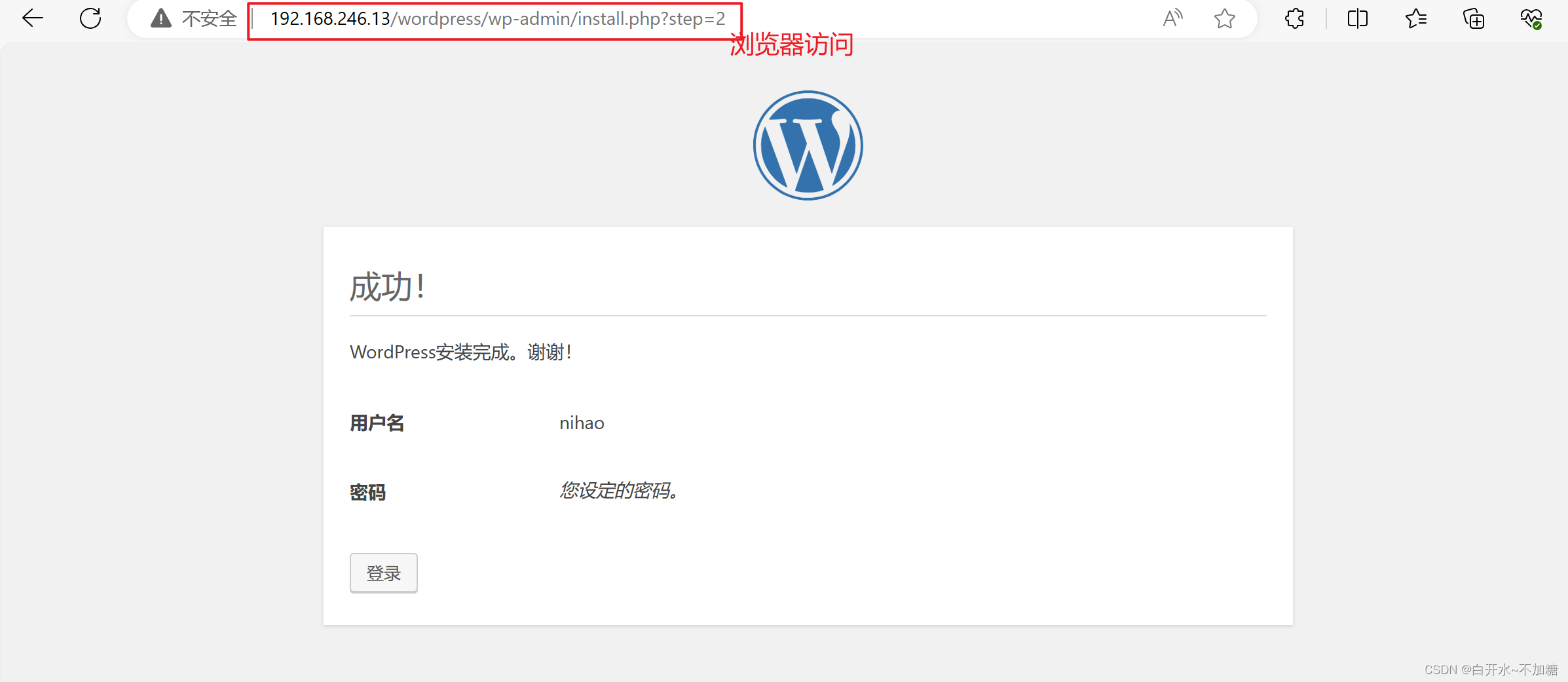
使用docker-compose编排Lnmp(dockerfile) 完成Wordpress
目录 一、 Docker-Compose 1.1Docker-Compose介绍 1.2环境准备 1.2.1准备容器目录及相关文件 1.2.2关闭防火墙关闭防护 1.2.3下载centos:7镜像 1.3Docker-Compose 编排nginx 1.3.1切换工作目录 1.3.2编写 Dockerfile 文件 1.3.3修改nginx.conf配置文件 1.4Docker-Co…...
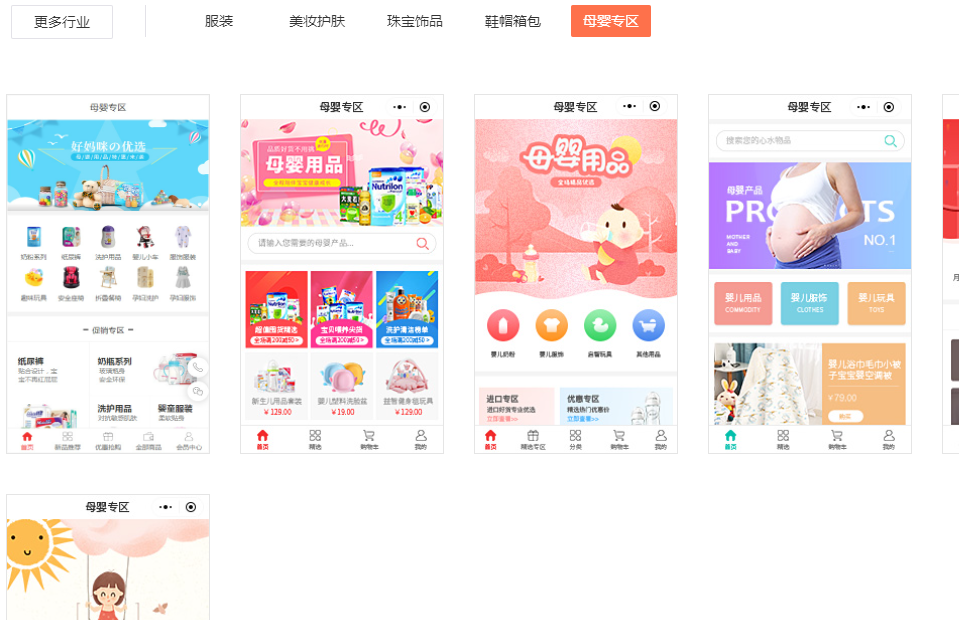
母婴店运用商城小程序店铺的效果是什么
母婴市场规模高,还可与不少行业无缝衔接,尤其是以90后、00后为主的年轻人,在备孕生育和婴儿护理前后等整体流程往往不惜重金且时间长,母婴用品无疑是必需品,商家需要多方面拓展全面的客户及打通场景随时消费路径。 运…...

大数据技术概述_2.大数据面临的5个方面的挑战
1. 大数据面临着5个主要问题 2012年冬季,来自IBM、微软、谷歌、HP、MIT、斯坦福、加州大学伯克利分校、UIUC等产业界和学术界的数据库领域专家通过在线的方式共同发布了一个关于大数据的白皮书。该白皮书首先指出大数据面临着5个主要问题,分别是异构性&a…...
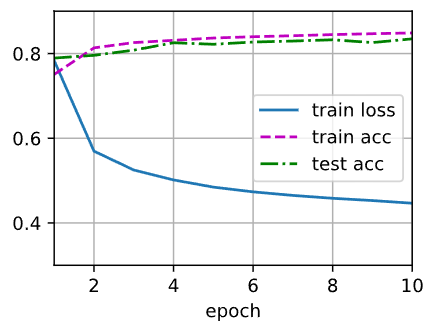
《动手学深度学习(Pytorch版)》Task03:线性神经网络——4.29打卡
《动手学深度学习(Pytorch版)》Task03:线性神经网络 线性回归基本元素线性模型损失函数随机梯度下降 正态分布与平方损失 线性回归的从零开始实现读取数据集初始化模型参数定义模型定义损失函数定义优化算法训练 线性回归的简洁实现读取数据集…...
机器学习(二) ----------K近邻算法(KNN)+特征预处理+交叉验证网格搜索
目录 1 核心思想 1.1样本相似性 1.2欧氏距离(Euclidean Distance) 1.3其他距离 1.3.1 曼哈顿距离(Manhattan Distance) 1.3.2 切比雪夫距离(Chebyshev distance) 1.3.3 闵式距离(也称为闵…...

This error originates from a subprocess, and is likely not a problem with pip.
Preparing metadata (setup.py) ... errorerror: subprocess-exited-with-error python setup.py egg_info did not run successfully.│ exit code: 1╰─> [63 lines of output]WARNING: The repository located at mirrors.aliyun.com is not a trusted or secure host a…...

Python中关于子类约束的开发规范
Python中关于子类约束的开发规范 我们知道,在java和C#中有一种接口的类型,用来约束实现该接口的类,必须要定义接口中指定的方法 而在python中,我们可以基于父类子类异常来仿照着实现这个功能 class Base:def func():raise NotI…...

LyricsX深度解析:macOS平台终极歌词解决方案的技术实现与高级应用
LyricsX深度解析:macOS平台终极歌词解决方案的技术实现与高级应用 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的终极歌词应用,通过…...

BlueDot BME280库深度解析:嵌入式多传感器驱动实践
1. BlueDot BME280 库技术解析:面向嵌入式工程师的多传感器驱动实践指南BME280 是博世(Bosch)推出的高精度环境传感器,集成温度、相对湿度与气压三参数测量能力,广泛应用于气象站、IoT终端、无人机姿态补偿及室内环境监…...

Ext2Read:Windows用户如何轻松读取Linux分区文件
Ext2Read:Windows用户如何轻松读取Linux分区文件 【免费下载链接】ext2read A Windows Application to read and copy Ext2/Ext3/Ext4 (With LVM) Partitions from Windows. 项目地址: https://gitcode.com/gh_mirrors/ex/ext2read 你是否遇到过这样的情况&a…...

SpringBoot项目整合Redisson实战:从连接池报错到Redis集群健康检查的完整避坑指南
SpringBoot整合Redisson深度实践:连接池优化与集群健康监控全解析 Redis作为分布式系统的核心组件,其Java客户端Redisson的高阶用法一直是开发者关注的焦点。去年某电商平台大促期间,因Redis集群节点闪断导致的分布式锁失效事故,让…...

如何通过内置实时地图彻底解决黑神话悟空中的迷路问题:终极导航指南
如何通过内置实时地图彻底解决黑神话悟空中的迷路问题:终极导航指南 【免费下载链接】wukong-minimap 黑神话内置实时地图 / Black Myth: Wukong Built-in real-time map 项目地址: https://gitcode.com/gh_mirrors/wu/wukong-minimap 在《黑神话:…...

分布式爬虫安全:构建高可用代理池的架构与实践指南
分布式爬虫安全:构建高可用代理池的架构与实践指南 【免费下载链接】scylla Intelligent proxy pool for Humans™ to extract content from the internet and build your own Large Language Models in this new AI era 项目地址: https://gitcode.com/gh_mirror…...

技术赋能B端拓客:号码核验行业的破局与价值深耕,氪迹科技法人股东核验筛选系统,阶梯式价格
2026年,B端市场进入存量竞争的深水区,“精准获客、降本增效”不再是企业的加分项,而是生存发展的必选项。号码核验作为B端拓客流程的前置筛选环节,直接决定了线索质量、人力效能与投入回报比,成为影响企业拓客竞争力的…...

OpenClaw对话日志分析:GLM-4.7-Flash任务执行成功率提升
OpenClaw对话日志分析:GLM-4.7-Flash任务执行成功率提升 1. 为什么需要分析对话日志 上个月我把本地部署的OpenClaw智能体从Qwen切换到了GLM-4.7-Flash模型,本以为会获得更好的任务执行效果,结果却遇到了意想不到的问题。每天早上打开电脑&…...

3大核心策略构建平台化电商生态:Lilishop多商户SaaS架构深度解析
3大核心策略构建平台化电商生态:Lilishop多商户SaaS架构深度解析 【免费下载链接】lilishop 商城 JAVA电商商城 多语言商城 uniapp商城 微服务商城 项目地址: https://gitcode.com/gh_mirrors/li/lilishop 在数字化转型浪潮中,平台化电商已成为企…...

智能工作流引擎:多智能体系统任务编排的高效解决方案
智能工作流引擎:多智能体系统任务编排的高效解决方案 【免费下载链接】agno High-performance runtime for multi-agent systems. Build, run and manage secure multi-agent systems in your cloud. 项目地址: https://gitcode.com/GitHub_Trending/ag/agno …...