Imagine Flash、StyleMamba 、FlexControl、Multi-Scene T2V、TexControl
本文首发于公众号:机器感知
Imagine Flash、StyleMamba 、FlexControl、Multi-Scene T2V、TexControl

You Only Cache Once: Decoder-Decoder Architectures for Language Models
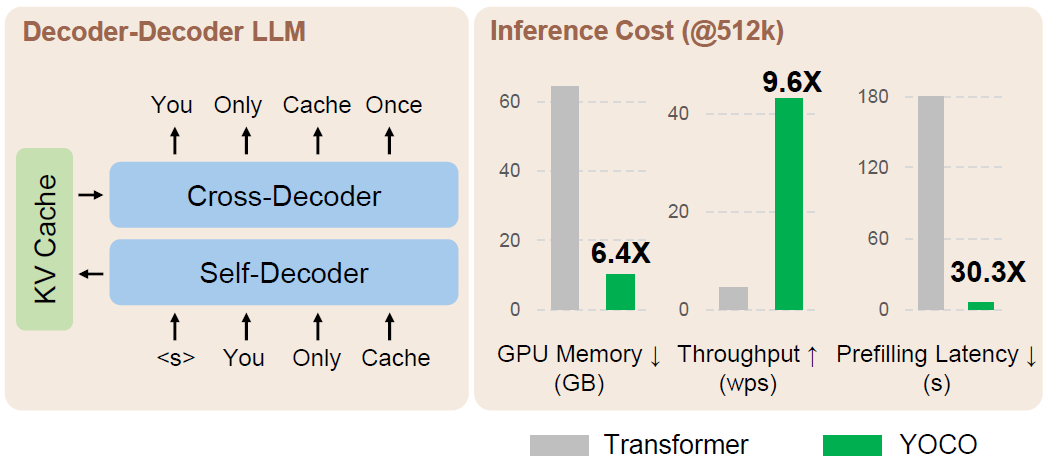
We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, p......
Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models

Diffusion Models (DMs) have exhibited superior performance in generating high-quality and diverse images. However, this exceptional performance comes at the cost of expensive architectural design, particularly due to the attention module heavily used in leading models. Existing works mainly adopt a retraining process to enhance DM efficiency. This is computationally expensive and not very scalable. To this end, we introduce the Attention-driven Training-free Efficient Diffusion Model (AT-EDM) framework that leverages attention maps to perform run-time pruning of redundant tokens, without the need for any retraining. Specifically, for single-denoising-step pruning, we develop a novel ranking algorithm, Generalized Weighted Page Rank (G-WPR), to identify redundant tokens, and a similarity-based recovery method to restore tokens for the convolution operation. In addition, we propose a Denoising-Steps-Aware Pruning (DSAP) approach to adjust the pruning budget across different den......
Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
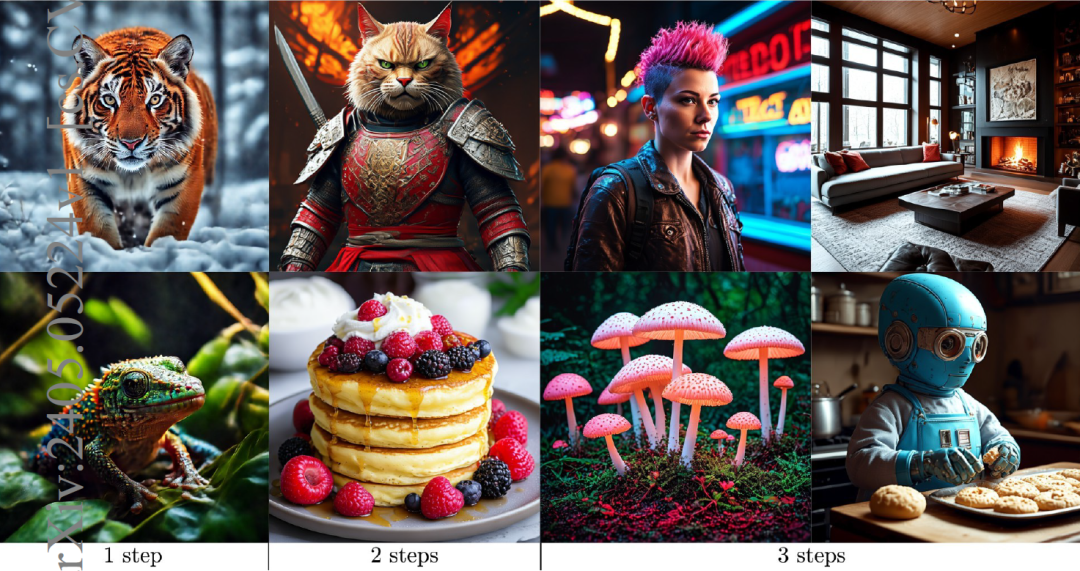
Diffusion models are a powerful generative framework, but come with expensive inference. Existing acceleration methods often compromise image quality or fail under complex conditioning when operating in an extremely low-step regime. In this work, we propose a novel distillation framework tailored to enable high-fidelity, diverse sample generation using just one to three steps. Our approach comprises three key components: (i) Backward Distillation, which mitigates training-inference discrepancies by calibrating the student on its own backward trajectory; (ii) Shifted Reconstruction Loss that dynamically adapts knowledge transfer based on the current time step; and (iii) Noise Correction, an inference-time technique that enhances sample quality by addressing singularities in noise prediction. Through extensive experiments, we demonstrate that our method outperforms existing competitors in quantitative metrics and human evaluations. Remarkably, it achieves performance comparable......
Reviewing Intelligent Cinematography: AI research for camera-based video production
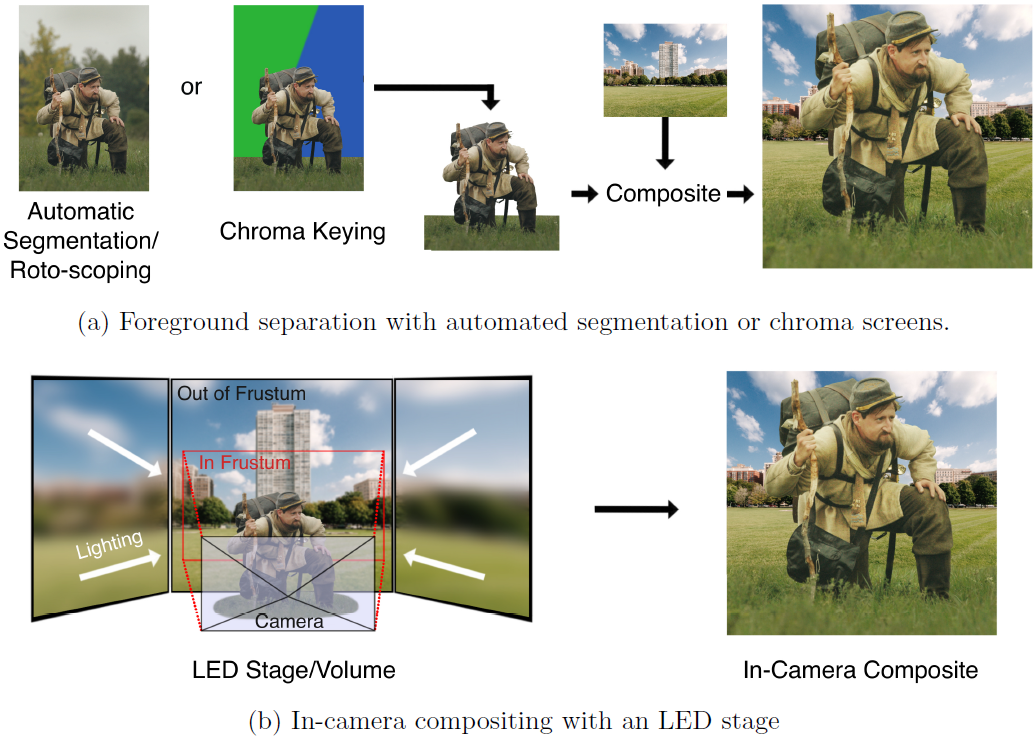
This paper offers a comprehensive review of artificial intelligence (AI) research in the context of real camera content acquisition for entertainment purposes and is aimed at both researchers and cinematographers. Considering the breadth of computer vision research and the lack of review papers tied to intelligent cinematography (IC), this review introduces a holistic view of the IC landscape while providing the technical insight for experts across across disciplines. We preface the main discussion with technical background on generative AI, object detection, automated camera calibration and 3-D content acquisition, and link explanatory articles to assist non-technical readers. The main discussion categorizes work by four production types: General Production, Virtual Production, Live Production and Aerial Production. Note that for Virtual Production we do not discuss research relating to virtual content acquisition, including work on automated video generation, like Stable Di......
StyleMamba : State Space Model for Efficient Text-driven Image Style Transfer

We present StyleMamba, an efficient image style transfer framework that translates text prompts into corresponding visual styles while preserving the content integrity of the original images. Existing text-guided stylization requires hundreds of training iterations and takes a lot of computing resources. To speed up the process, we propose a conditional State Space Model for Efficient Text-driven Image Style Transfer, dubbed StyleMamba, that sequentially aligns the image features to the target text prompts. To enhance the local and global style consistency between text and image, we propose masked and second-order directional losses to optimize the stylization direction to significantly reduce the training iterations by 5 times and the inference time by 3 times. Extensive experiments and qualitative evaluation confirm the robust and superior stylization performance of our methods compared to the existing baselines.......
FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation

Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate imag......
TALC: Time-Aligned Captions for Multi-Scene Text-to-Video Generation

Recent advances in diffusion-based generative modeling have led to the development of text-to-video (T2V) models that can generate high-quality videos conditioned on a text prompt. Most of these T2V models often produce single-scene video clips that depict an entity performing a particular action (e.g., `a red panda climbing a tree'). However, it is pertinent to generate multi-scene videos since they are ubiquitous in the real-world (e.g., `a red panda climbing a tree' followed by `the red panda sleeps on the top of the tree'). To generate multi-scene videos from the pretrained T2V model, we introduce Time-Aligned Captions (TALC) framework. Specifically, we enhance the text-conditioning mechanism in the T2V architecture to recognize the temporal alignment between the video scenes and scene descriptions. For instance, we condition the visual features of the earlier and later scenes of the generated video with the representations of the first scene description (e.g., `a red pan......
TexControl: Sketch-Based Two-Stage Fashion Image Generation Using Diffusion Model
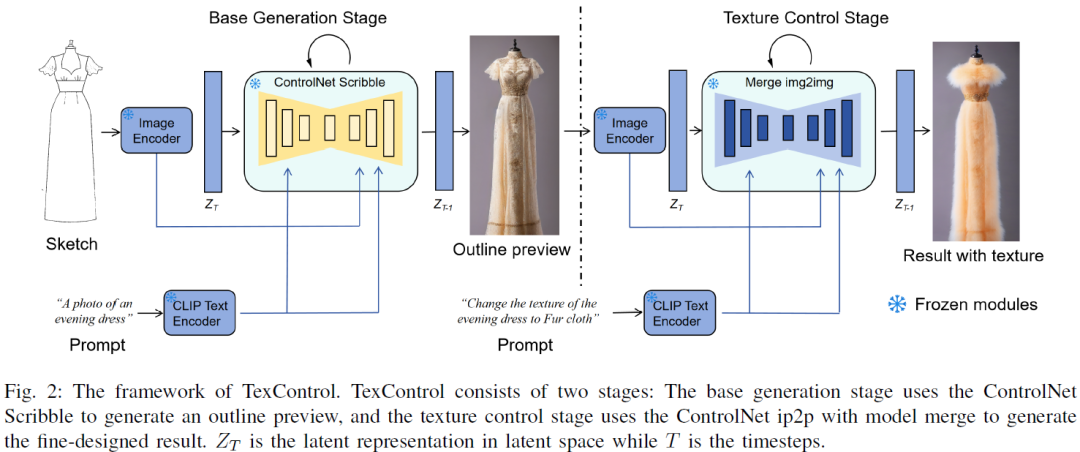
Deep learning-based sketch-to-clothing image generation provides the initial designs and inspiration in the fashion design processes. However, clothing generation from freehand drawing is challenging due to the sparse and ambiguous information from the drawn sketches. The current generation models may have difficulty generating detailed texture information. In this work, we propose TexControl, a sketch-based fashion generation framework that uses a two-stage pipeline to generate the fashion image corresponding to the sketch input. First, we adopt ControlNet to generate the fashion image from sketch and keep the image outline stable. Then, we use an image-to-image method to optimize the detailed textures of the generated images and obtain the final results. The evaluation results show that TexControl can generate fashion images with high-quality texture as fine-grained image generation.......
相关文章:
Imagine Flash、StyleMamba 、FlexControl、Multi-Scene T2V、TexControl
本文首发于公众号:机器感知 Imagine Flash、StyleMamba 、FlexControl、Multi-Scene T2V、TexControl You Only Cache Once: Decoder-Decoder Architectures for Language Models We introduce a decoder-decoder architecture, YOCO, for large language models, …...
 方法详解)
Java Collections.emptyList() 方法详解
前言 在Java开发的日常中,我们常常需要处理集合数据结构,而这其中就免不了要面对“空集合”的场景。传统的做法可能是直接返回 null,但这往往会引入空指针异常的风险,降低了代码的健壮性。幸运的是,Java为我们提供了一…...
Vue前端环境准备
vue-cli Vue-cli是Vue官方提供的脚手架,用于快速生成一个Vue项目模板 提供功能: 统一的目录结构 本地调试 热部署 单元测试 集成打包上线 依赖环境:NodeJs 安装NodeJs与Vue-Cli 1、安装nodejs(已经安装就不用了) node-…...

代码随想录算法训练营第四十二天| 01背包问题(二维、一维)、416.分割等和子集
系列文章目录 目录 系列文章目录动态规划:01背包理论基础①二维数组②一维数组(滚动数组) 416. 分割等和子集①回溯法(超时)②动态规划(01背包)未剪枝版剪枝版 动态规划:01背包理论基…...

故障——蓝桥杯十三届2022国赛大学B组真题
问题分析 这道题纯数学,考察贝叶斯公式 AC_Code #include <bits/stdc.h> using namespace std; typedef pair<int,double> PI; bool cmp(PI a,PI b){if(a.second!b.second)return a.second>b.second;return a.first<b.first; } int main() {i…...

SSD存储基本知识
存储技术随着时间的推移经历了显著变化,新兴的存储介质正逐步挑战已经成为行业标准的硬盘驱动器(HDD)。在众多竞争者中,固态硬盘(SSD)是最广泛采用且最有潜力占据主导地位的——它们速度快、运行安静&#…...
buuctf-misc题目练习二
ningen 打开题目后是一张图片,放进winhex里面 发现PK,PK是压缩包ZIP 文件的文件头,下一步是想办法进行分离 Foremost可以依据文件内的文件头和文件尾对一个文件进行分离,或者识别当前的文件是什么文件。比如拓展名被删除、被附加…...
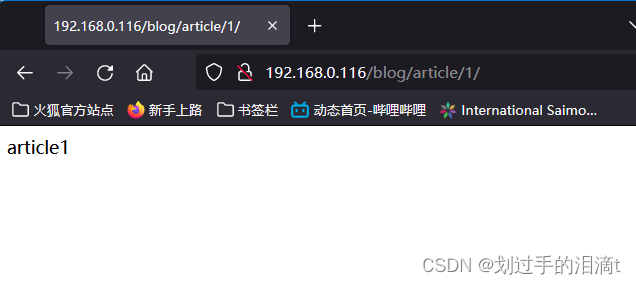
Nginx rewrite项目练习
Nginx rewrite练习 1、访问ip/xcz,返回400状态码,要求用rewrite匹配/xcz a、访问/xcz返回400 b、访问/hello时正常访问xcz.html页面server {listen 192.168.99.137:80;server_name 192.168.99.137;charset utf-8;root /var/www/html;location / {root …...

2024,AI手机“元年”? | 最新快讯
文 | 伯虎财经,作者 | 铁观音 2024年,小米、荣耀、vivo、一加、努比亚等品牌的AI手机新品如雨后春笋般涌现。因此,这一年也被业界广泛视为AI手机的“元年” 试想,当你轻触屏幕,你的手机不仅响应你的指令,更…...

5月9(信息差)
🌍 可再生能源发电量首次占全球电力供应的三成 🎄马斯克脑机接口公司 Neuralink 计划将 Link 功能扩展至现实世界,实现控制机械臂、轮椅等 马斯克脑机接口公司 Neuralink 计划将 Link 功能扩展至现实世界,实现控制机械臂、轮椅等…...

leetcode203-Remove Linked List Elements
题目 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例 1: 输入:head [1,2,6,3,4,5,6], val 6 输出:[1,2,3,4,5] 示例 2: 输入&…...

2024付费进群系统,源码及搭建变现视频课程(教程+源码)
自从我做资源站项目盈利稳定后,我越来越对网站类项目感兴趣了,毕竟很多网站类项目还是需要一定技术门槛的,可以过滤掉一些人,很多新人做项目就只盯着短视频,所以网站类项目也就没那么的卷。 这个付费进群系统…...

深入理解Django:中间件与信号处理的艺术
title: 深入理解Django:中间件与信号处理的艺术 date: 2024/5/9 18:41:21 updated: 2024/5/9 18:41:21 categories: 后端开发 tags: Django中间件信号异步性能缓存多语言 引言 在当今的Web开发领域,Django以其强大的功能、简洁的代码结构和高度的可扩…...

rk3588局域网推流
最近无意间看见在网上有使用MediaMtx插件配合ffmpeg在Windows来进行推流,然后在使用其他软件进行拉流显示数据图像的,既然windows都可以使用 ,我想linux应该也可以,正好手上也有一块RK3588的开发板,就测试了一下&#…...

Android虚拟机机制
目录 一、Android 虚拟机 dalvik/art(6版本后)二、Android dex、odex、oat、vdex、art区别 一、Android 虚拟机 dalvik/art(6版本后) 每个应用都在其自己的进程中运行,都有自己的虚拟机实例。ART通过执行DEX文件可在设…...

【触摸案例-手势解锁案例-按钮高亮 Objective-C语言】
一、我们来说这个self.btns,这个问题啊,为什么不用_btns, 1.我们说,在懒加载里边儿,经常是写下划线啊,_btns,为什么不写,首先啊,这个layoutSubviews:我们第一次,肯定会去执行这个layoutSubviews: 然后呢,去懒加载这个数组, 然后呢,接下来啊,走这一句话, 第一次…...
ChatPPT开启高效办公新时代,AI赋能PPT创作
目录 一、前言二、ChatPPT的几种用法1、通过在线生成2、通过插件生成演讲者模式最终成品遇到问题改进建议 三、ChatPPT其他功能 一、前言 想想以前啊,为了做个PPT,我得去网上找各种模板,有时候还得在某宝上花钱买。结果一做PPT,经…...

【C语言项目】贪吃蛇(上)
个人主页 ~ gitee仓库~ 欢迎大家来到C语言系列的最后一个篇章–贪吃蛇游戏的实现,当我们实现了贪吃蛇之后,我们的C语言就算是登堂入室了,基本会使用了,当然,想要更加熟练地使用还需要多多练习 贪吃蛇 一、目标二、需要…...
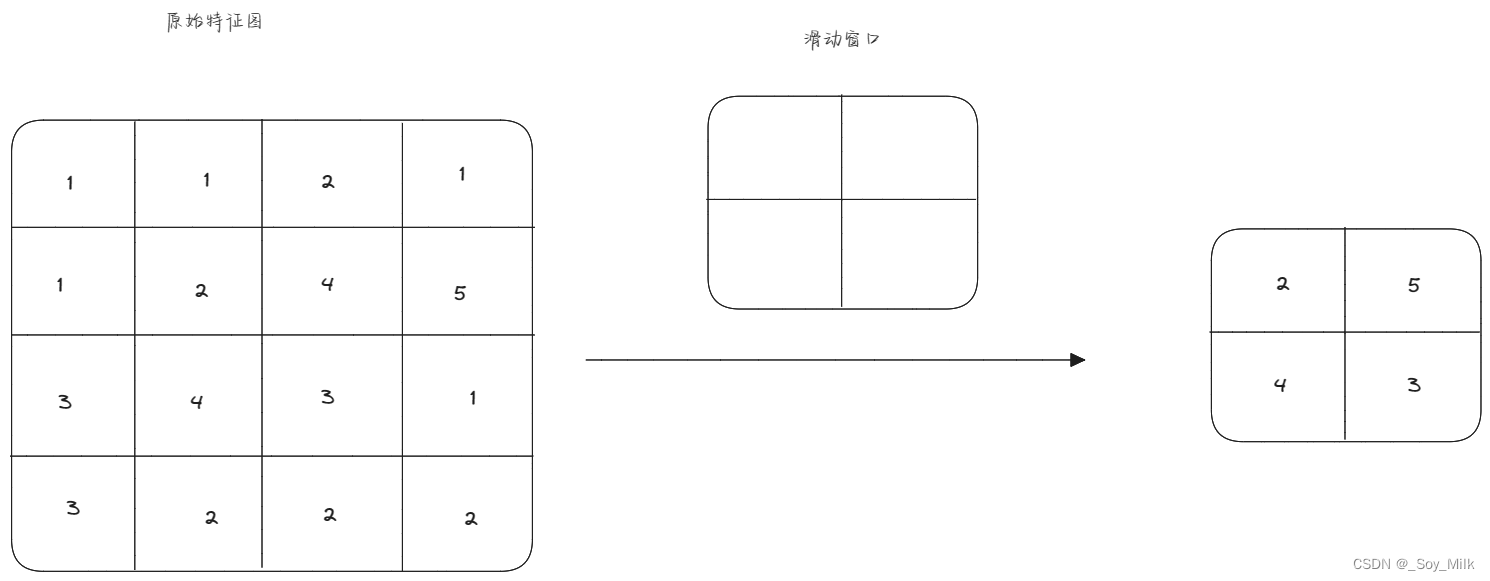
LeNet-5上手敲代码
LeNet-5 LeNet-5由Yann LeCun在1998年提出,旨在解决手写数字识别问题,被认为是卷积神经网络的开创性工作之一。该网络是第一个被广泛应用于数字图像识别的神经网络之一,也是深度学习领域的里程碑之一。 LeNet-5的整体架构: 总体…...
javaWeb入门(自用)
1. vue学习 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><script src"https://unpkg.com/vue2"></script> </head> <body><div id"…...

FlareLine Flutter:开源跨平台管理后台模板开发与部署指南
1. 项目概述:一个为现代应用而生的Flutter仪表盘模板如果你正在寻找一个能快速启动你的下一个Web、Android或iOS项目后台管理界面的方案,并且希望这个方案足够现代、功能齐全,同时又能让你完全掌控代码,那么FlareLine Flutter这个…...

条件生成对抗网络实现可控人脸老化建模
1. 项目概述:用条件生成对抗网络实现可控的人脸老化模拟“Face Aging Using Conditional GANs”——这个标题一出现,我就知道它不是那种调个预训练模型跑个demo的轻量级练习。它直指一个在计算机视觉与人机交互交叉领域里既经典又棘手的问题:…...

深度学习在系外行星探测中的应用:ExoDNN框架解析与实践
1. 项目概述:当深度学习遇见星空系外行星探测,这个听起来就充满科幻感的领域,在过去二十年里彻底改变了我们对宇宙的认知。从最初通过“凌星法”和“径向速度法”发现几颗气态巨行星,到如今TESS、开普勒等太空望远镜的海量数据中&…...

AI如何重塑科学创新:从构思成本坍塌到知识组合爆炸
1. 科学创新的范式转移:从“不确定性”到“风险”在过去的科研实践中,我们常常面临一个根本性的困境:不确定性。这并非指我们不知道某个实验的结果,而是指我们连可能的结果是什么、其发生的概率有多大,都无从知晓。这就…...
 深度诊断与流量整形方案)
lsyncd rsyncssh同步中断:Broken pipe (32) 深度诊断与流量整形方案
1. 问题现象与初步诊断 最近在帮客户部署lsyncdrsyncssh方案时,遇到了一个典型问题:同步25GB目录时,总是在传输4GB左右中断。日志里反复出现"Broken pipe (32)"错误,就像下面这样: packet_write_wait: Conne…...

Taotoken提供的审计日志功能如何满足企业级安全与合规需求
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken提供的审计日志功能如何满足企业级安全与合规需求 1. 企业引入大模型能力后的审计挑战 当企业将大模型API能力整合到内部…...

FastAPI + 异步 SQLAlchemy 实战:从零搭建图书管理 CRUD 项目
前言 本篇将从零开始,带你搭建一个完整的异步图书管理 CRUD 项目,覆盖环境搭建、数据库连接、模型定义、12 种核心接口实现。献给和博主一样刚踏入SQLAlchemy的新手小白们。 注意:本文基础知识较多,不需要的大佬可直接跳到具体操…...

用OpenMV4 H7 PLUS做个智能分拣小车:颜色识别实战项目从硬件选型到代码集成
智能分拣小车实战:OpenMV4 H7 PLUS颜色识别与嵌入式系统集成 在创客竞赛和毕业设计中,智能分拣系统一直是热门选题。传统方案往往面临识别精度不足、响应延迟高或硬件兼容性差等问题。OpenMV4 H7 PLUS凭借其强大的图像处理能力和丰富的硬件接口ÿ…...

AI推广的核心原理是什么?
理解AI推广的原理,你才能知道该做什么、不该做什么,而不是盲目操作。一句话概括AI推广的核心原理:让AI在回答用户问题时,选择引用你的内容。就这么简单。但要做到这件事,你需要理解AI是怎么"选择"的。AI回答…...

音频AI DSP:低功耗边缘智能的硬件架构与实现
1. 项目概述:当音频AI遇见边缘DSP几年前,如果有人告诉我,一个比指甲盖还小的芯片,能在不到1毫瓦的功耗下,持续监听环境声音、识别特定关键词,甚至能分辨出你是在嘈杂的餐厅还是在安静的办公室,我…...