Chronos:学习时间序列的大语言模型(代码解析)
前言
- 《Chronos: Learning the Language of Time Series》原文地址,Github开源代码地址
- Chronos:学习时间序列的大语言模型(论文解读)CSDN地址
- GitHub项目地址Some-Paper-CN。本项目是译者在学习长时间序列预测、CV、NLP和机器学习过程中精读的一些论文,并对其进行了中文翻译。还有部分最佳示例教程。
- 如果有帮助到大家,请帮忙点亮Star,也是对译者莫大的鼓励,谢谢啦~
- 本文代码已同步至项目Some-Paper-CN,后续可能会根据热度发布使用
LoRA微调Chronos模型教程,浅浅期待一下吧~
先验知识
- 建议先阅读
Chronos论文解读篇,对大致原理有所了解,阅读代码效果会更好。 - 在论文解读篇中,我们已经知道了
Chronos是基于Google的开源模型T5(Huggingface)。因受篇幅影响,有关T5模型的解析不在本次讨论范围内,感兴趣的小伙伴可以去查询相关资料。 - 论文基于
Transformers框架,在阅读代码前,最好有一定Transformers库的基础知识。 - 虽然本文模型为时间序列模型,但不管是在模型架构、训练方式还是数据组织上都与大语言模型几乎一致,在阅读代码前,最好有一定大语言模型领域的知识,比如术语
tonken、tokenizer。
代码解析
- 将开源代码从Github上下载到本地,关键文件在
chronos-forecasting/src/chronos下,chronos.py文件。 - 类
ChronosConfig用于加载模型参数(注意!是参数不是权重),类ChronosTokenizer用于加载模型Tokenizer,类ChronosModel用于根据模型参数构建模型。上述类为Transformers库基础类,这里不多赘述。 - 论文中的核心在类
MeanScaleUniformBins用于数据均值缩放和量化分箱,类ChronosPipeline用于构架数据预测管道。
MeanScaleUniformBins
class MeanScaleUniformBins(ChronosTokenizer):def __init__(self, low_limit: float, high_limit: float, config: ChronosConfig) -> None:self.config = config# 线性平分向量torch.linspace(start, end, steps)self.centers = torch.linspace(low_limit,high_limit,config.n_tokens - config.n_special_tokens - 1,)# 首尾元素分别为-1e20、1e20# self.centers[1:]除第1个元素外的所有元素# self.centers[:-1]除最后1个元素外的所有元素# (self.centers[1:] + self.centers[:-1]) / 2表示相邻元素平均值self.boundaries = torch.concat((torch.tensor([-1e20], device=self.centers.device),(self.centers[1:] + self.centers[:-1]) / 2,torch.tensor([1e20], device=self.centers.device),))def input_transform(self, context: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:batch_size, length = context.shapeif length > self.config.context_length:# 保留最后context_length个元素context = context[..., -self.config.context_length :]# 空值的反向布尔值attention_mask = ~torch.isnan(context)# context绝对值和attention_mask的点积,除以attention_mask的和scale = torch.nansum(torch.abs(context) * attention_mask, dim=-1) / torch.nansum(attention_mask, dim=-1)# scale是0或空值设为1.0scale[~(scale > 0)] = 1.0# 将context按scale缩放scaled_context = context / scale.unsqueeze(dim=-1)# torch.bucketize根据边界值将输入映射到相应bucket(桶)中token_ids = (torch.bucketize(input=scaled_context,boundaries=self.boundaries,right=True,)+ self.config.n_special_tokens)# 不需要关注的地方使用paddingtoken_ids[~attention_mask] = self.config.pad_token_id# 如果需要在末尾添加eos符if self.config.use_eos_token:eos_tokens = torch.full((batch_size, 1), fill_value=self.config.eos_token_id)token_ids = torch.concat((token_ids, eos_tokens), dim=1)# mask置为trueeos_mask = torch.full((batch_size, 1), fill_value=True)attention_mask = torch.concat((attention_mask, eos_mask), dim=1)return token_ids, attention_mask, scaledef output_transform(self, samples: torch.Tensor, scale: torch.Tensor) -> torch.Tensor:# 将scale扩展两个维度scale_unsqueezed = scale.unsqueeze(-1).unsqueeze(-1)# 将值限制在0和centers长度间,确保索引值不超出centersindices = torch.clamp(samples - self.config.n_special_tokens,min=0,max=len(self.centers) - 1,)# 返回在原始context缩放级别下分桶值return self.centers[indices] * scale_unsqueezed
-
low_limit和high_limit包含在模型参数中,根据论文分别为-15和15。 -
在
input_transform函数中scale = torch.nansum(torch.abs(context) * attention_mask, dim=-1) / torch.nansum(attention_mask, dim=-1)看上去非常复杂,实际上在没有空值的情况下,相当于对序列求平均值。 -
在
input_transform函数中分箱函数torch.bucketize的使用可以参考官方文档。 -
在
input_transform函数中空值使用padding填充,并使用mask进行遮掩,是大语言模型训练的常用操作。 -
在论文中,作者表示为了保持与大语言模型训练方式保持一致,会在序列结束后放置
eos标识符,所以模型参数use_eos_token是为True的。 -
output_transform函数是input_transform函数的反操作,需要注意的是torch.clamp函数,确保token_id在词表中,否则就无法反归一化得到正常的值了。
ChronosPipeline
from_pretrained函数用于加载模型预训练权重,这里不在过多赘述,关键在于predict函数。
def predict(self,context: Union[torch.Tensor, List[torch.Tensor]],prediction_length: Optional[int] = None,num_samples: Optional[int] = None,temperature: Optional[float] = None,top_k: Optional[int] = None,top_p: Optional[float] = None,limit_prediction_length: bool = True,) -> torch.Tensor:"""Get forecasts for the given time series.Parameters----------contextInput series. This is either a 1D tensor, or a listof 1D tensors, or a 2D tensor whose first dimensionis batch. In the latter case, use left-padding with``torch.nan`` to align series of different lengths.prediction_lengthTime steps to predict. Defaults to what specifiedin ``self.model.config``.num_samplesNumber of sample paths to predict. Defaults to whatspecified in ``self.model.config``.temperatureTemperature to use for generating sample tokens.Defaults to what specified in ``self.model.config``.top_kTop-k parameter to use for generating sample tokens.Defaults to what specified in ``self.model.config``.top_pTop-p parameter to use for generating sample tokens.Defaults to what specified in ``self.model.config``.limit_prediction_lengthForce prediction length smaller or equal than thebuilt-in prediction length from the model. True bydefault. When true, fail loudly if longer predictionsare requested, otherwise longer predictions are allowed.Returns-------samplesTensor of sample forecasts, of shape(batch_size, num_samples, prediction_length)."""context_tensor = self._prepare_and_validate_context(context=context)if prediction_length is None:prediction_length = self.model.config.prediction_lengthif prediction_length > self.model.config.prediction_length:msg = (f"We recommend keeping prediction length <= {self.model.config.prediction_length}. ""The quality of longer predictions may degrade since the model is not optimized for it. ")if limit_prediction_length:msg += "You can turn off this check by setting `limit_prediction_length=False`."raise ValueError(msg)warnings.warn(msg)predictions = []remaining = prediction_lengthwhile remaining > 0:# 根据MeanScaleUniformBins类对数据进行缩放和分箱token_ids, attention_mask, scale = self.tokenizer.input_transform(context_tensor)# 输入模型得到结果samples = self.model(token_ids.to(self.model.device),attention_mask.to(self.model.device),min(remaining, self.model.config.prediction_length),num_samples,temperature,top_k,top_p,)prediction = self.tokenizer.output_transform(samples.to(scale.device), scale)predictions.append(prediction)remaining -= prediction.shape[-1]# 判断是否预测完if remaining <= 0:break# 拼接操作context_tensor = torch.cat([context_tensor, prediction.median(dim=1).values], dim=-1)return torch.cat(predictions, dim=-1)
- 作者建议将
prediction length保持在64以下,因为模型没有针对较长的预测长度进行优化,因此预测质量可能会下降。 - 预测过程为:根据
MeanScaleUniformBins类中input_transform函数对数据进行缩放和分箱,得到token_id、掩码矩阵attention_mask, 均值scale;将token_id和掩码矩阵attention_mask输入模型,得到输出samples。根据MeanScaleUniformBins类中output_transform函数和均值scale将输出samples反归一化得到实际值。 remaining变量用于检验prediction length是否全部预测完。
left_pad_and_stack_1D
- 上述代码中函数
predict调用了_prepare_and_validate_context函数,本质是left_pad_and_stack_1D函数。
def left_pad_and_stack_1D(tensors: List[torch.Tensor]):# tensors中最长元素的长度max_len = max(len(c) for c in tensors)padded = []# 遍历tensors中元素for c in tensors:assert isinstance(c, torch.Tensor)# c为一维张量assert c.ndim == 1# 填充torch.nanpadding = torch.full(size=(max_len - len(c),), fill_value=torch.nan, device=c.device)# 拼接(c长度被扩展为max_len),并添加到列表padded中padded.append(torch.concat((padding, c), dim=-1))# 将padded列表中的所有元素沿着新维度折叠,形成二维张量return torch.stack(padded)
- 该函数是大语言模型训练过程中为了补齐长度做的操作,如果不理解也没事,只要明白在干什么就行。
测试Demo
- 如果想要进一步了解代码,还是希望大家用一个轻量的测试
Demo从头到尾Debug一下。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
from chronos import ChronosPipelinepipeline = ChronosPipeline.from_pretrained("amazon/chronos-t5-tiny",device_map="cpu",torch_dtype=torch.float16,
)df = pd.read_csv("AirPassengers.csv")# context must be either a 1D tensor, a list of 1D tensors,
# or a left-padded 2D tensor with batch as the first dimension
context = torch.tensor(df["#Passengers"])
prediction_length = 12
forecast = pipeline.predict(context,prediction_length,num_samples=20,temperature=1.0,top_k=50,top_p=1.0,
) # forecast shape: [num_series, num_samples, prediction_length]# visualize the forecast
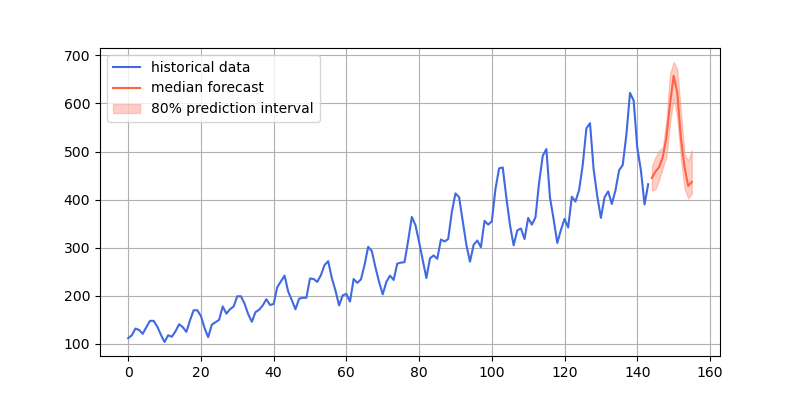
forecast_index = range(len(df), len(df) + prediction_length)
low, median, high = np.quantile(forecast[0].numpy(), [0.1, 0.5, 0.9], axis=0)plt.figure(figsize=(8, 4))
plt.plot(df["#Passengers"], color="royalblue", label="historical data")
plt.plot(forecast_index, median, color="tomato", label="median forecast")
plt.fill_between(forecast_index, low, high, color="tomato", alpha=0.3, label="80% prediction interval")
plt.legend()
plt.grid()
plt.show()
- 预测结果效果图
相关文章:
Chronos:学习时间序列的大语言模型(代码解析)
前言 《Chronos: Learning the Language of Time Series》原文地址,Github开源代码地址Chronos:学习时间序列的大语言模型(论文解读)CSDN地址GitHub项目地址Some-Paper-CN。本项目是译者在学习长时间序列预测、CV、NLP和机器学习…...

云南区块链商户平台优化开发
背景 云南区块链商户平台是全省统一区块链服务平台。依托于云南省发改委、阿里云及蚂蚁区块链的国内首个省级区块链平台——云南省区块链平台同步上线,助力数字云南整体升级。 网页版并不适合妈妈那辈人使用,没有记忆功能,于是打算自己开发…...

深圳六西格玛培训:引领职场“薪”途无限
在追求职业发展和薪资增长的道路上,不断学习和提升自我是至关重要的。深圳,这座充满活力和创新精神的城市,为职场人士提供了众多学习和提升的机会。其中,六西格玛培训以其独特的价值,吸引了众多职场人士的目光。张驰咨…...
Spark云计算平台Databricks使用,创建workspace和Compute计算集群(Spark集群)
Databricks,是属于 Spark 的商业化公司,由美国加州大学伯克利 AMP 实验室的 Spark 大数据处理系统多位创始人联合创立。Databricks 致力于提供基于 Spark 的云服务,可用于数据集成,数据管道等任务。 1 创建workspace 点击创建wor…...

银河麒麟服务器系统audit服务组件升级、进程彻底关闭介绍
银河麒麟服务器系统audit服务组件升级、进程彻底关闭介绍 一 系统环境二 组件升级2.1 联网升级audit2.1.1 配置外网源(默认配置如下,不用修改)2.1.2 通过dnf命令进行升级(未指定版本的话会升级到最新se.12版本,建议升级…...
)
设计模式——装饰者模式(Decorator)
装饰者模式(Decorator Pattern)是一种结构型设计模式,它允许你动态地给一个对象添加一些额外的职责,就增加功能来说,装饰者模式相比生成子类更为灵活。在装饰者模式中,一个装饰类会包装一个对象(…...

力扣:406. 根据身高重建队列
406. 根据身高重建队列 假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。 请你重新构…...

Docker 怎么将映射出的路径设置为非root用户权限
在Docker中,容器的根文件系统默认是由root用户拥有的。如果想要在映射到宿主机的路径时设置为非root用户权限,可以通过以下几种方式来实现: 1. 使用具有特定UID和GID的非root用户运行容器: 在运行容器时,你可以使用-u…...

Linux——进程的优先级、ACL
一、系统性能调优 Redhat7和centos7默认安装并启动了tuned服务 实验 [rootuser ~]# tuned-adm list //查看所有的调优方案 [rootuser ~]# tuned-adm recommend // 查看推荐的调优方案 virtual-guest 适用于作为虚拟机客户机运行的设备࿰…...
【C++】STL-list模拟实现
目录 1、本次需要实现的3个类即接口总览 2、list的模拟实现 2.1 链表结点的设置以及初始化 2.2 链表的迭代器 2.3 容量接口及默认成员函数 1、本次需要实现的3个类即接口总览 #pragma once #include<iostream> #include<assert.h> using namespace std; templ…...

Java 7大排序
🐵本篇文章将对数据结构中7大排序的知识进行讲解 一、插入排序 有一组待排序的数据array,以升序为例,从第二个数据开始(用tmp表示)依次遍历整组数据,每遍历到一个数据都再从tmp的前一个数据开始࿰…...

vue3 - 图灵
目录 vue3简介整体上认识vue3项目创建Vue3工程使用官方脚手架创建Vue工程[推荐] 主要⼯程结构 数据双向绑定vue2语法的双向绑定简单表单双向绑定复杂表单双向绑定 CompositionAPI替代OptionsAPICompositionAPI简单不带双向绑定写法CompositionAPI简单带双向绑定写法setup简写⽅…...

java设计模式八 享元
享元模式(Flyweight Pattern)是一种结构型设计模式,它通过共享技术有效地支持大量细粒度的对象。这种模式通过存储对象的外部状态在外部,而将不经常变化的内部状态(称为享元)存储在内部,以此来减…...

ELK原理详解
ELK原理详解 一、引言 在当今日益增长的数据量和复杂的系统环境中,日志数据的收集、存储、分析和可视化成为了企业运营和决策不可或缺的一部分。ELK(Elasticsearch、Logstash、Kibana)堆栈凭借其高效的性能、灵活的扩展性和强大的功能&…...
多线程学习Day09
10.Tomcat线程池 LimitLatch 用来限流,可以控制最大连接个数,类似 J.U.C 中的 Semaphore 后面再讲 Acceptor 只负责【接收新的 socket 连接】 Poller 只负责监听 socket channel 是否有【可读的 I/O 事件】 一旦可读,封装一个任务对象&#x…...

第33次CSP认证Q1:词频统计
🍄题目描述 在学习了文本处理后,小 P 对英语书中的 𝑛n 篇文章进行了初步整理。 具体来说,小 P 将所有的英文单词都转化为了整数编号。假设这 𝑛n 篇文章中共出现了 𝑚m 个不同的单词,则把它们…...
pytorch加载模型出现错误
大概的错误长下面这样: 问题出现的原因: 很明显,我就是犯了第一种错误。 网上的修改方法: 我觉得按道理哈,确实,蓝色部分应该是可以把问题解决了的。但是我没有解决,因为我犯了另外一个错…...
如何在Mac上恢复格式化硬盘的数据?
“嗨,我格式化了我的一个Mac硬盘,而没有使用Time Machine备份数据。这个硬盘被未知病毒感染了,所以我把它格式化为出厂设置。但是,我忘了备份我的文件。现在,我想恢复格式化的硬盘驱动器并恢复我的文档,您能…...

华为OD机试 - 手机App防沉迷系统(Java 2024 C卷 100分)
华为OD机试 2024C卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷C卷)》。 刷的越多,抽中的概率越大,每一题都有详细的答题思路、详细的代码注释、样例测试…...
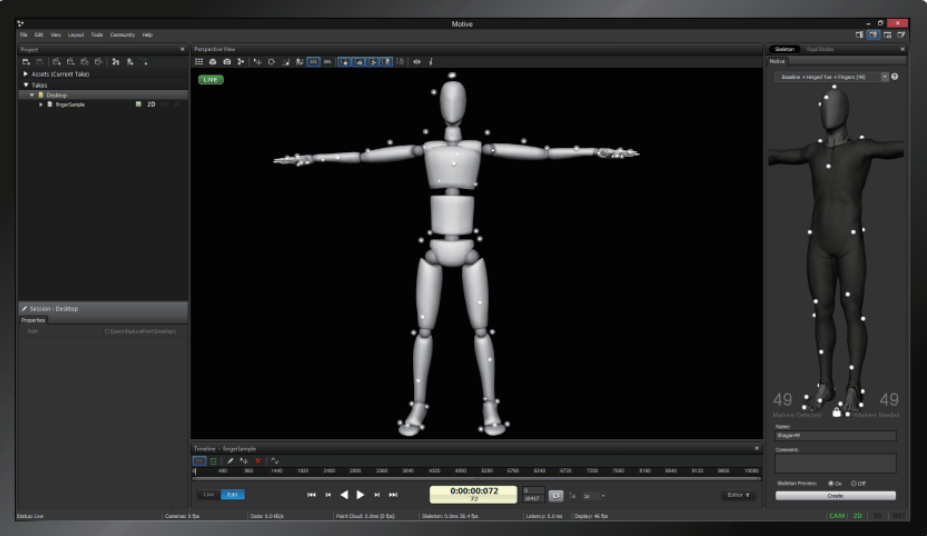
搜维尔科技:光学动作捕捉系统用于城市公共安全智慧感知实验室
用户名称:西安科技大学 主要产品:Optitrack Priime41 光学动作捕捉系统(8头) 在6米8米的空间内,通过8个Optitrack Priime41光学动作捕捉镜头,对人体动作进行捕捉,得到用户想要的人体三维空间坐…...

永强数据恢复硬盘设备加密数据专业解锁恢复服务
在当今数字化时代,数据的重要性不言而喻。无论是个人用户存储的珍贵照片、视频,还是企业存储的关键商业数据,一旦丢失,都可能带来巨大的损失。而硬盘设备加密数据的丢失或无法解锁,更是让人头疼不已。北京永强数据恢复…...
附Matlab代码)
基于瞬态三角哈里斯鹰算法TTHHO实现多无人机协同集群避障路径规划(目标函数:最低成本:路径、高度、威胁、转角)附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...

从零打造专属机械键盘:基于CircuitPython的USB HID输入设备实践
1. 项目概述:打造你的专属“一键”键盘如果你对市面上千篇一律的键盘感到厌倦,或者一直想亲手制作一个独一无二的输入设备,那么这个项目就是为你准备的。今天,我们不谈那些复杂的全尺寸客制化键盘,而是从一个精巧、有趣…...

6种专业计时模式!OBS高级计时器插件让你的直播时间管理精准到秒
6种专业计时模式!OBS高级计时器插件让你的直播时间管理精准到秒 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 还在为直播时间控制而烦恼吗?OBS Advanced Timer计时器插件就是你的救星&…...

NodeJS-Learning包管理艺术:npm高级用法与私有仓库搭建
NodeJS-Learning包管理艺术:npm高级用法与私有仓库搭建 【免费下载链接】NodeJS-Learning This page contains collection of curated links to blog posts, articles, videos, tutorials, books, frameworks, modules, IDEs, testing tools, hosting providers, et…...

ThinkPad风扇控制终极指南:TPFanCtrl2让笔记本更安静高效
ThinkPad风扇控制终极指南:TPFanCtrl2让笔记本更安静高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否经常被ThinkPad风扇的噪音打扰?…...
)
手把手教你用TTL线刷救活咪咕MGV3200盒子(GK6323V100C芯片/安卓9系统)
咪咕MGV3200盒子救砖全指南:从TTL焊接到底层刷机实战 当你的咪咕MGV3200电视盒子因为一次鲁莽的卡刷操作变成"砖头",指示灯不再亮起,屏幕一片漆黑时,那种绝望感只有经历过的人才能体会。不同于普通刷机教程,…...

数字人能给短视频带来什么?这4点说出了真相
数字人能给短视频带来什么?这4点说出了真相 “数字人能给短视频带来什么?”“AI时代短视频创作有什么变化?”"数字人为什么是2026年博主的必备工具?"这些问题困扰着无数想要在短视频领域有所突破的创作者。今天一次说清…...

在Taotoken模型广场根据任务与预算挑选合适模型的实践心得
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务与预算挑选合适模型的实践心得 作为一名日常需要与各类大模型打交道的开发者,模型选型是项…...

2026春招AI人才争夺战白热化!小白程序员如何抓住13万高薪机遇?速收藏!
2026年春招显示AI领域岗位量同比增长8.7倍,成为职场新风口。具身智能岗位薪资暴增,AI科学家月薪高达13.2万元。高薪AI岗位紧缺,程序员需拥抱AI工具提升竞争力,否则面临被替代风险。AI能力已成为职场基础设施,不学AI可能…...