京东手势验证码-YOLO姿态识别+Bézier curve轨迹拟合
这次给老铁们带来的是京东手势验证码的识别。
目标网站:https://plogin.m.jd.com/mreg/index
验证码如下图:

当第一眼看到这个验证码的时候,就头大了,这玩意咋识别???
静下心来细想后的一个方案,就是直接用yolo的目标检测去硬刚,方案如下:
根据曲线的特征,提取较特殊的
- 起末点(1)
- 转折点(2)
- 相较点(3)
进行打标提取几个点的位置,然后根据曲线斜率和长度的关系进行连接,得到曲线的轨迹,但是这种我感觉成功率可能不会很高,就没有试了,不过肯定也是可行的,感兴趣的可以自行尝试哈。


于是我便寻找下一种方案,辗转反侧,夜不能寐,终于看到一篇文章介绍了
yolo8-pose姿态检测模型

可以通过目标图关键点实现骨架连接,那么同理我们的手势曲线,也可利用关键点检测实现轨迹连接。

话不多说直接开干
yolo8仓库地址:https://github.com/ultralytics/ultralytics
然后下载labelme标注软件,图片可存放在ultralytics目录下新建的imgs文件夹。
yolo8-pose 需要进行目标框选和关键点匹配,进行如下形式的标注,
这里一开始的关键点我只用了4个,训练出来的效果极差,后面加到了10个相对好很多。
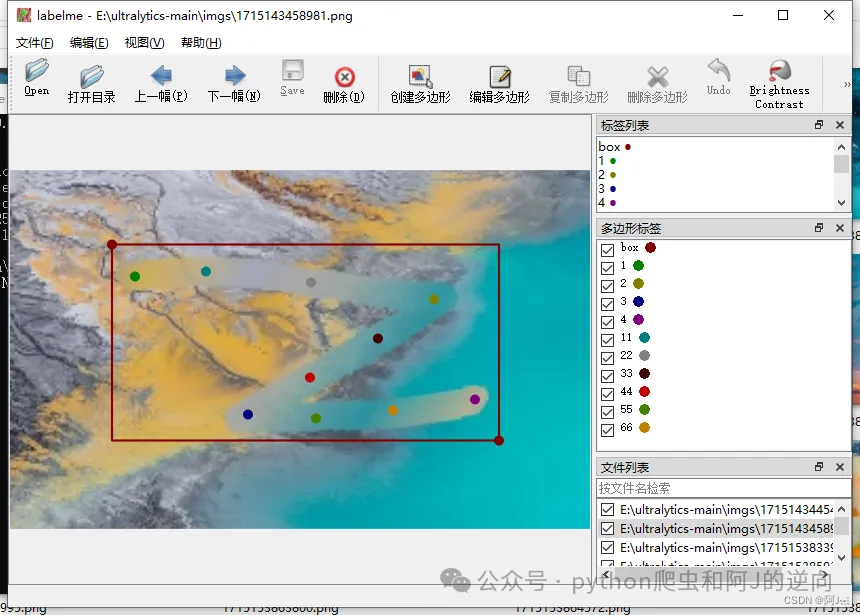
打标完成后会生成json文件,我们要转换成yolo可以识别txt文件
这里需要注意这些参数
- class_list 是你框选的名称
- keypoint_list 是关键点名称,要按顺序来,不然连接的时候会乱
- img_list = glob.glob(“imgs/*.png”) 图片加载路径
# -*-coding:utf-8 -*-"""
# File : labelme_to_yolo.py
# Time : 2024/5/8 16:40
# Author : 阿J
# version : 2024
# Description:
"""
# 将labelme标注的json文件转为yolo格式
import cv2
import glob
import json
import tqdm# 物体类别class_list = ["box"]
# 关键点的顺序
keypoint_list = ["1",'11','22', "2",'33','44', "3",'55','66', "4"]def json_to_yolo(img_data, json_data):h, w = img_data.shape[:2]# 步骤:# 1. 找出所有的矩形,记录下矩形的坐标,以及对应group_id# 2. 遍历所有的head和tail,记下点的坐标,以及对应group_id,加入到对应的矩形中# 3. 转为yolo格式rectangles = {}# 遍历初始化for shape in json_data["shapes"]:label = shape["label"] # pen, head, tailgroup_id = shape["group_id"] # 0, 1, 2, ...points = shape["points"] # x,y coordinatesshape_type = shape["shape_type"]# 只处理矩形,读矩形if shape_type == "rectangle":if group_id not in rectangles:rectangles[group_id] = {"label": label,"rect": points[0] + points[1], # Rectangle [x1, y1, x2, y2]"keypoints_list": []}# 遍历更新,将点加入对应group_id的矩形中,读关键点,根据group_id匹配for keypoint in keypoint_list:for shape in json_data["shapes"]:label = shape["label"]group_id = shape["group_id"]points = shape["points"]# 如果匹配到了对应的keypointif label == keypoint:rectangles[group_id]["keypoints_list"].append(points[0])# else:# rectangles[group_id]["keypoints_list"].append([0,0])# 转为yolo格式yolo_list = []for id, rectangle in rectangles.items():result_list = []if rectangle['label'] not in class_list:continuelabel_id = class_list.index(rectangle["label"])# x1,y1,x2,y2x1, y1, x2, y2 = rectangle["rect"]# center_x, center_y, width, heightcenter_x = (x1 + x2) / 2center_y = (y1 + y2) / 2width = abs(x1 - x2)height = abs(y1 - y2)# normalizecenter_x /= wcenter_y /= hwidth /= wheight /= h# 保留6位小数center_x = round(center_x, 6)center_y = round(center_y, 6)width = round(width, 6)height = round(height, 6)# 添加 label_id, center_x, center_y, width, heightresult_list = [label_id, center_x, center_y, width, height]# 添加 p1_x, p1_y, p1_v, p2_x, p2_y, p2_vfor point in rectangle["keypoints_list"]:x, y = pointx, y = int(x), int(y)x /= wy /= h# 保留2位小数x = round(x, 2)y = round(y, 2)result_list.extend([x, y, 2])# if len(rectangle["keypoints_list"]) == 4:# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])## if len(rectangle["keypoints_list"]) == 2:# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])# result_list.extend([0, 0, 0])yolo_list.append(result_list)return yolo_listimport os
print(os.getcwd())
# 获取所有的图片
img_list = glob.glob("imgs/*.png")
for img_path in tqdm.tqdm(img_list):img = cv2.imread(img_path)print(img_path)json_file = img_path.replace('png', 'json')with open(json_file) as json_file:json_data = json.load(json_file)yolo_list = json_to_yolo(img, json_data)yolo_txt_path = img_path.replace('png', 'txt')with open(yolo_txt_path, "w") as f:for yolo in yolo_list:for i in range(len(yolo)):if i == 0:f.write(str(yolo[i]))else:f.write(" " + str(yolo[i]))f.write("\n")执行上面的代码后就会生成txt文件
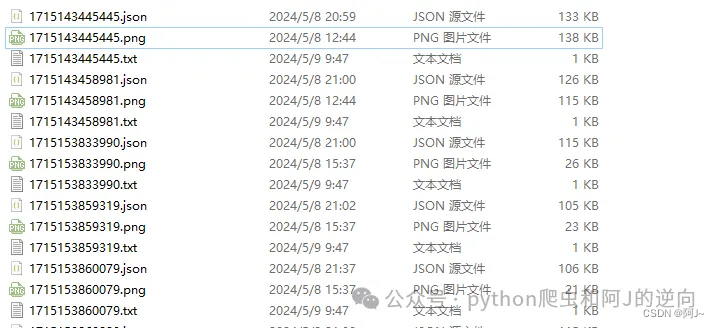
然后我们在ultralytics目录下的ultralytics/data新建images、labels文件夹,目录格式如下,然后对imges图片和labels标签(txt)进行分类即可
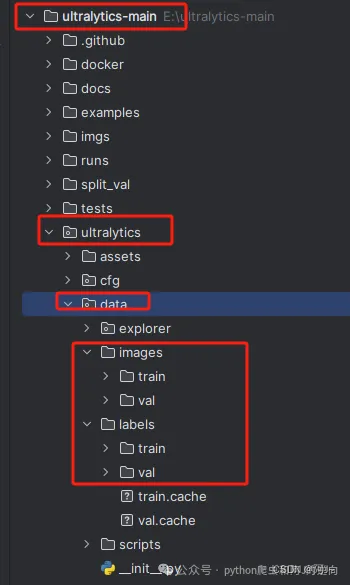
接着是修改yaml文件,如下图所示
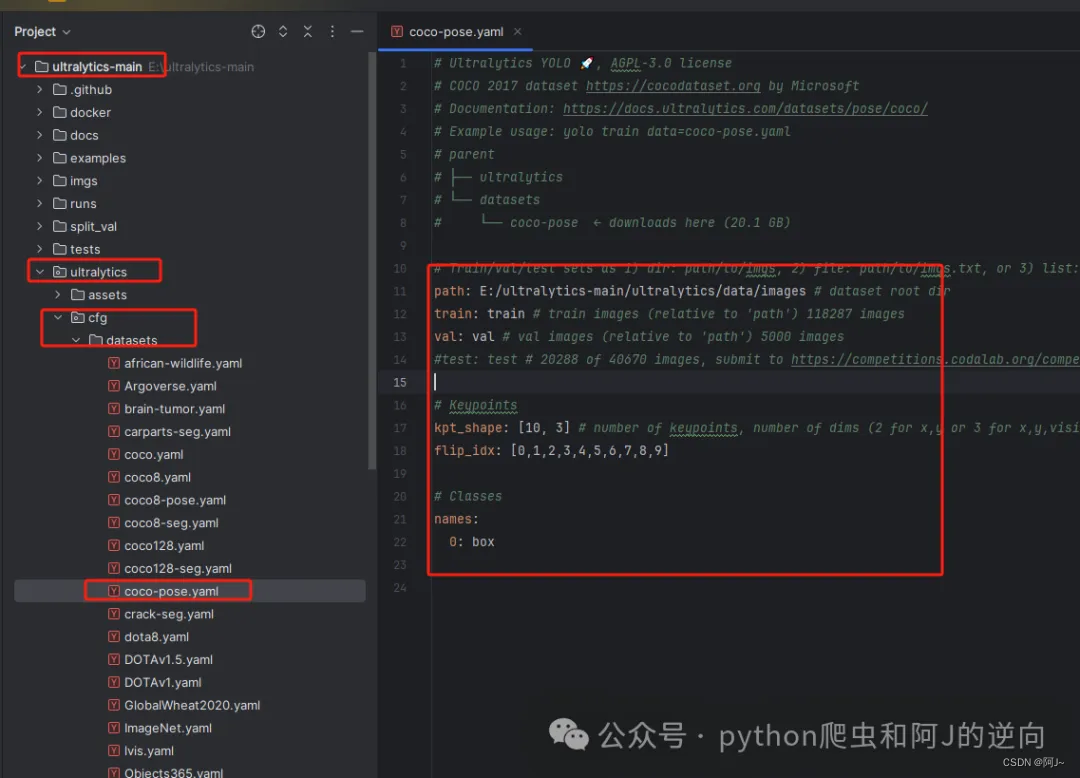
当然还需要下载预训练模型yolov8s-pose.pt,在官网的这个位置
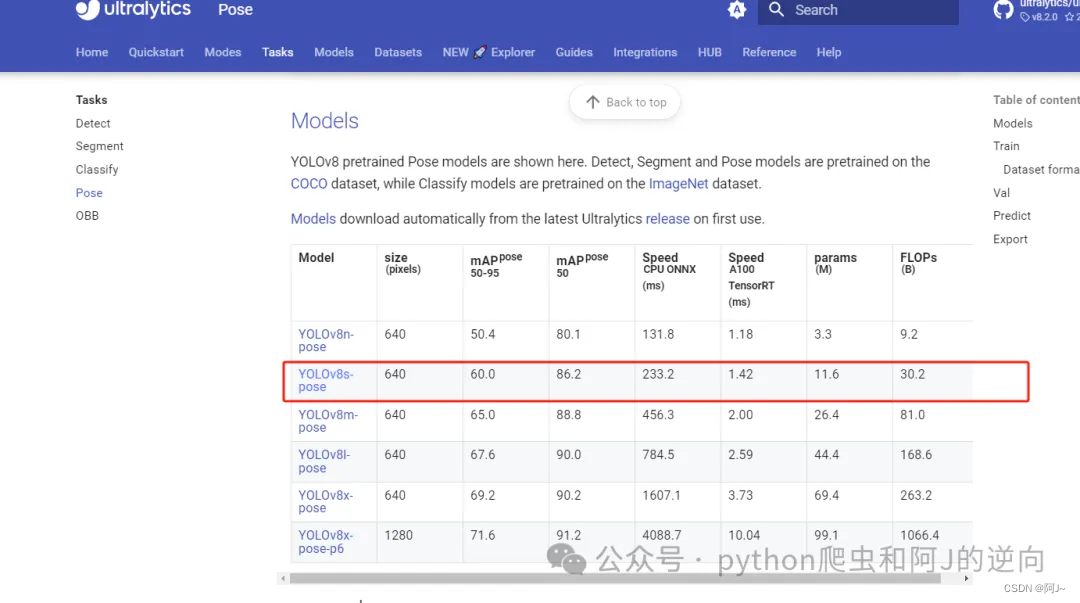
最后新建一个my_train.py文件,对应填入yaml、model的路径即可开始训练
# -*-coding:utf-8 -*-"""
# File : my_train.py
# Time : 2024/5/8 16:55
# Author : 阿J
# version : 2024
# Description:
"""
#训练代码
from ultralytics import YOLO# Load a model
model = YOLO(r'E:\ultralytics-main\ultralytics\weight\yolov8s-pose.pt')# Train the model
results = model.train(data=r'E:\ultralytics-main\ultralytics\cfg\datasets\coco-pose.yaml', epochs=300, imgsz=320)# # 验证代码
# from ultralytics import YOLO
#
# # Load a model
# model = YOLO(r'E:\ultralytics-main\runs\pose\train4\weights\last.pt')
#
# # Val the model
# results = model.val(data=r'E:\ultralytics-main\ultralytics\cfg\datasets\coco-pose.yaml',imgsz=320,batch=6,workers=8)左边是目标检测,右边是关键点检测(map50会慢慢上去)
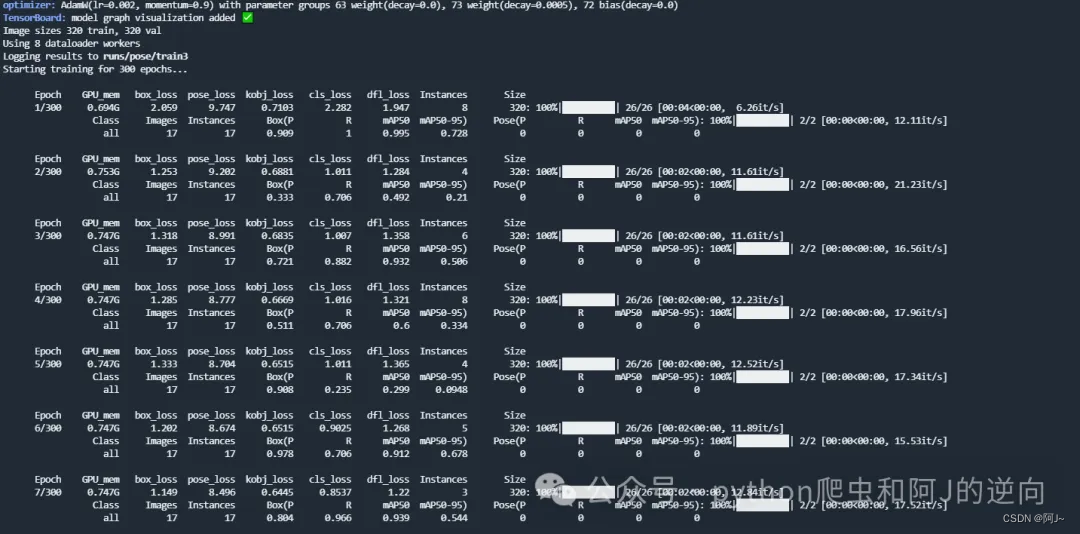
训练好后,可以用上面的的验证代码进行验证一下,模型路径在runs\pose\train
打标图片

验证图片

也可用以下代码进行推理
# -*-coding:utf-8 -*-"""
# File : 推理.py
# Time : 2024/5/8 17:59
# Author : 阿J
# version : 2024
# Description:
"""
import io# 测试图片
from ultralytics import YOLO
import cv2
import numpy as np
import time# 读取命令行参数
# weight_path = r'E:\ultralytics-main\runs\pose\train4\weights\last.pt'
weight_path = 'best.pt'
# media_path = "img/1715153883102.png"
# media_path = "xxx.png"
media_path = "img.png"time1 = time.time()
# 加载模型
model = YOLO(weight_path)
print("模型加载时间:", time.time() - time1)
# 获取类别
objs_labels = model.names # get class labels
# print(objs_labels)# 类别的颜色
class_color = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0),(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0),(255, 0, 0), (0, 255, 0)]
# 关键点的顺序
class_list = ["box"]# 关键点的颜色
keypoint_color = [(255, 0, 0), (0, 255, 0),(255, 0, 0), (0, 255, 0),(255, 0, 0), (0, 255, 0),(255, 0, 0), (0, 255, 0),(255, 0, 0), (0, 255, 0)]def cv2_imread_buffer(buffer):# 假设buffer是一个字节流对象buffer = io.BytesIO(buffer)# 将buffer转换为numpy数组arr = np.frombuffer(buffer.getvalue(), np.uint8)# 使用cv2.imdecode函数将numpy数组解码为图像img = cv2.imdecode(arr, cv2.IMREAD_COLOR)return imgdef pose_ocr(img):# 读取图片if isinstance(img,str):frame = cv2.imread(img)else:frame = cv2_imread_buffer(img)# frame = cv2.resize(frame, (280, 280))# 检测result = list(model(frame, conf=0.5, stream=True))[0] # inference,如果stream=False,返回的是一个列表,如果stream=True,返回的是一个生成器boxes = result.boxes # Boxes object for bbox outputsboxes = boxes.cpu().numpy() # convert to numpy array# 遍历每个框for box in boxes.data:l, t, r, b = box[:4].astype(np.int32) # left, top, right, bottomconf, id = box[4:] # confidence, classid = int(id)# 绘制框cv2.rectangle(frame, (l, t), (r, b), (0, 0, 255), 1)# 绘制类别+置信度(格式:98.1%)cv2.putText(frame, f"{objs_labels[id]} {conf * 100:.1f}", (l, t - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5,(0, 0, 255), 2)# 遍历keypointskeypoints = result.keypoints # Keypoints object for pose outputskeypoints = keypoints.cpu().numpy() # convert to numpy arraypose_point = []# draw keypoints, set first keypoint is red, second is bluefor keypoint in keypoints.data:pose_point = [[round(x),round(y)] for x,y,c in keypoint]for i in range(len(keypoint)):x, y ,_ = keypoint[i]x, y = int(x), int(y)cv2.circle(frame, (x, y), 3, (0, 255, 0), -1)#cv2.putText(frame, f"{keypoint_list[i]}", (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, keypoint_color[i], 2)if len(keypoint) >= 2:# draw arrow line from tail to half between head and tailx0, y0 ,_= keypoint[0]x1, y1 ,_= keypoint[1]x2, y2 ,_= keypoint[2]x3, y3 ,_= keypoint[3]x4, y4 ,_= keypoint[4]x5, y5 ,_= keypoint[5]x6, y6 ,_= keypoint[6]x7, y7 ,_= keypoint[7]x8, y8 ,_= keypoint[8]x9, y9 ,_= keypoint[9]cv2.line(frame, (int(x0), int(y0)), (int(x1), int(y1)), (255, 0, 255), 5)cv2.line(frame, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 255), 5)cv2.line(frame, (int(x2), int(y2)), (int(x3), int(y3)), (255, 0, 255), 5)cv2.line(frame, (int(x3), int(y3)), (int(x4), int(y4)), (255, 0, 255), 5)cv2.line(frame, (int(x4), int(y4)), (int(x5), int(y5)), (255, 0, 255), 5)cv2.line(frame, (int(x5), int(y5)), (int(x6), int(y6)), (255, 0, 255), 5)cv2.line(frame, (int(x6), int(y6)), (int(x7), int(y7)), (255, 0, 255), 5)cv2.line(frame, (int(x7), int(y7)), (int(x8), int(y8)), (255, 0, 255), 5)cv2.line(frame, (int(x8), int(y8)), (int(x9), int(y9)), (255, 0, 255), 5)#center_x, center_y = (x1 + x2) / 2, (y1 + y2) / 2# cv2.arrowedLine(frame, (int(x2), int(y2)), (int(center_x), int(center_y)), (255, 0, 255), 4,# line_type=cv2.LINE_AA, tipLength=0.1)# save imagecv2.imwrite("result.jpg", frame)# print("save result.jpg")return pose_pointif __name__ == '__main__':img = './img.png'res = pose_ocr(img)print(res)效果如下,输出的是关键点坐标
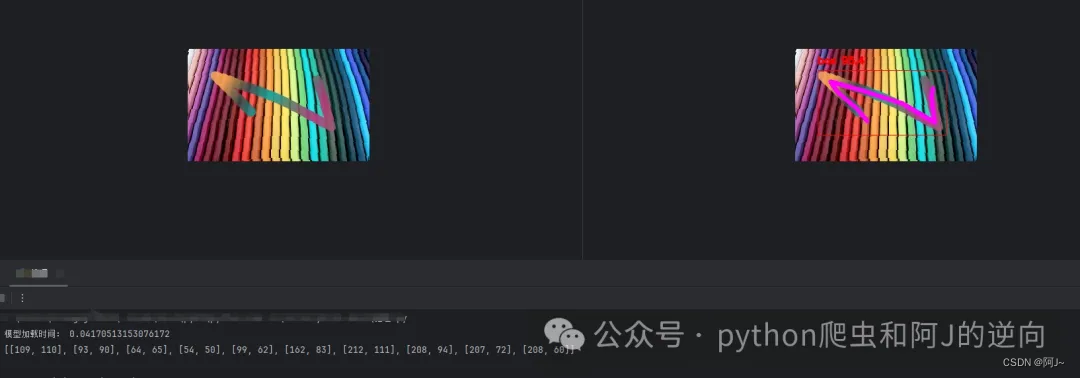
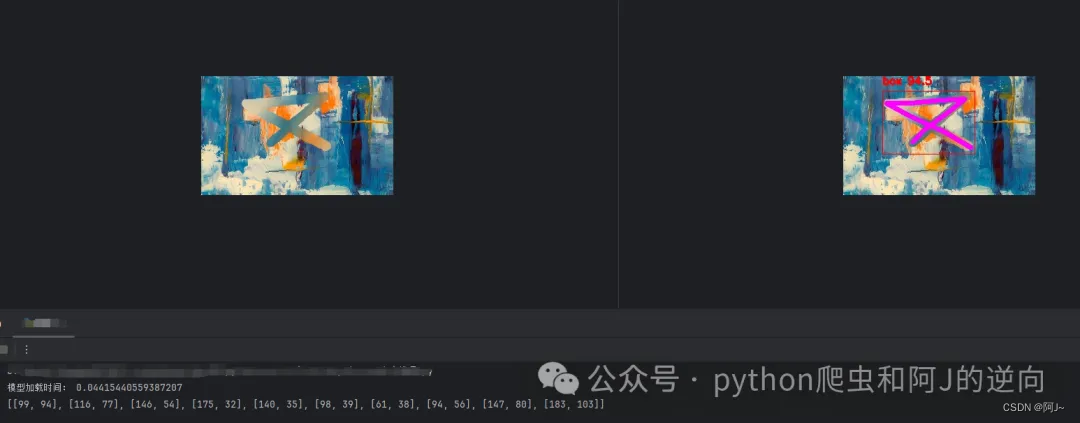
后面就是代入到验证码的识别验证接口,具体参数加密这里就不叙述,主要就是调wasm即可。
接下来讲的是如何实现这个曲线的轨迹,众所周知京东的轨迹是一向比较恶心的。
我用的方法是贝塞尔曲线的方式,通过对输入的坐标,实现一个轨迹的拟合效果。
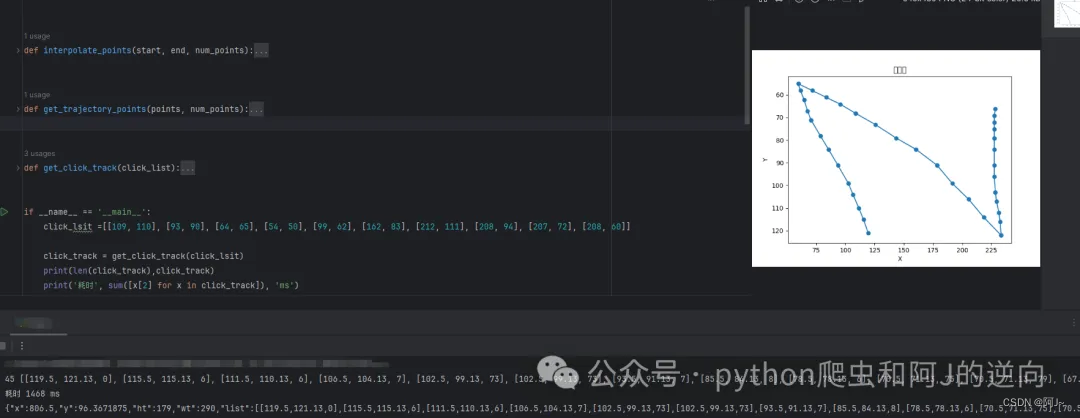
经过一系列的参数调整,终于得到一个成功率相对可以的(60-80%)轨迹生成函数,弄的时候发现在转折点时,停留时间需长一点!
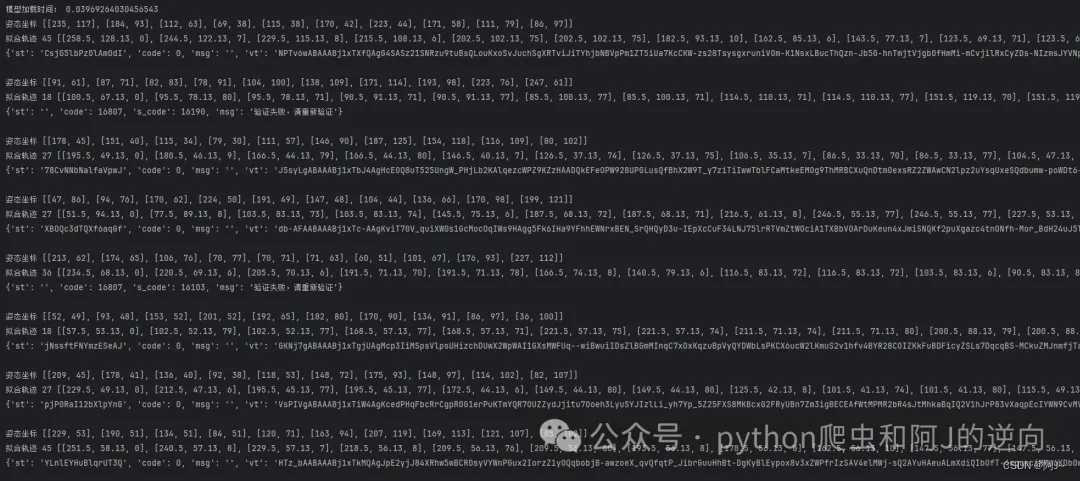
轨迹代码已上传星球,感兴趣的可以加一下哦!vx私聊我有优惠~
同时已建群,在外流浪的老铁私信我进群了(星球付费群),每天都会讨论各种技术问题(ali、tx、dx)等各种热门验证码~
wx:scorpio_a_j

相关文章:
京东手势验证码-YOLO姿态识别+Bézier curve轨迹拟合
这次给老铁们带来的是京东手势验证码的识别。 目标网站:https://plogin.m.jd.com/mreg/index 验证码如下图: 当第一眼看到这个验证码的时候,就头大了,这玩意咋识别??? 静下心来细想后的一个方案…...

亚马逊是如何铺设多个IP账号实现销量大卖的?
一、针对亚马逊平台机制,如何转变思路? 众所周知,一个亚马逊卖家只能够开一个账号,一家店铺,这是亚马逊平台明确规定的。平台如此严格限定,为的就是保护卖家,防止卖家重复铺货销售相同的产品&a…...
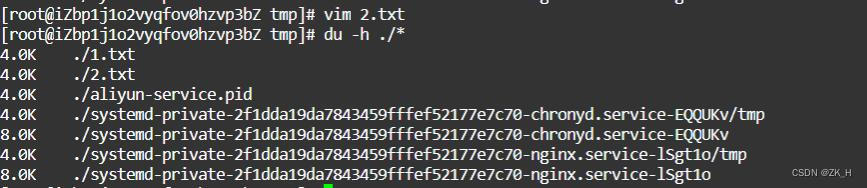
linux学习笔记——硬盘原理以及linux中的sector与block
在计算机硬盘中,最小的存储单位叫做扇区sector,0.5kb,多个连续扇区组合在一起形成了块block,最小的块包含8个扇区,4kb 我们可以在linux中印证 创建一个新的文件2.txt,查看文件大小为0k 在文件中添加字符后…...

【OceanBase诊断调优】—— 磁盘性能问题导致卡合并和磁盘写入拒绝排查
适用版本 OceanBase 数据库 V3.x、V4.x 版本。 问题现象 OceanBase 集群合并一直未完成,同时 tsar 和 iostat 显示从凌晨 2:30 开始磁盘使用率一直是 100%。怀疑合并导致 IO 上升,IO 可能存在问题,observer.log 的确有大量报错 disk is hu…...
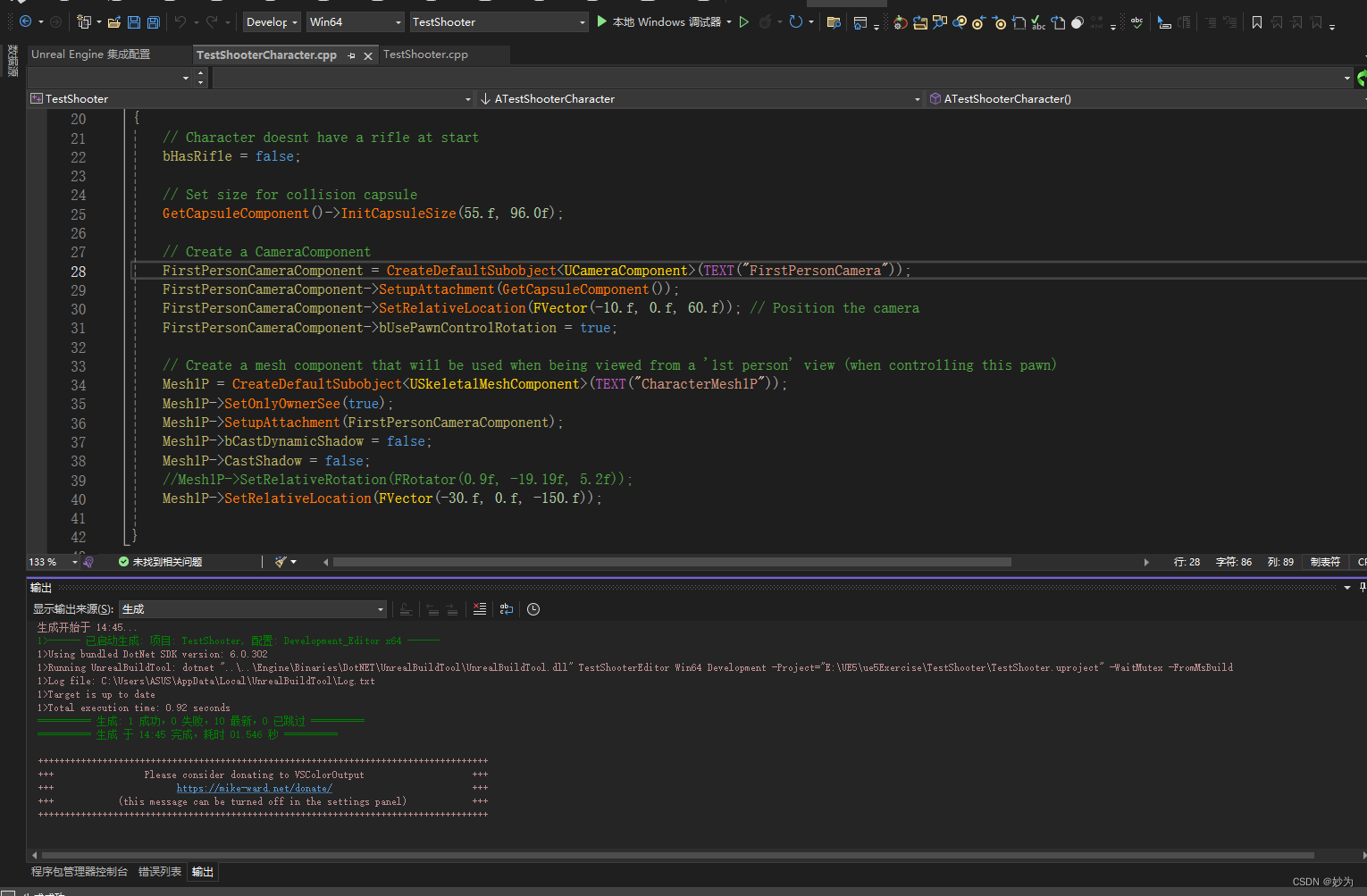
使用unreal engine5.3.2创建c++第一人称游戏
UE5系列文章目录 文章目录 UE5系列文章目录前言一、NuGet 简介二、解决方法: 前言 为了使用unreal engine5.3.2创建c第一人称游戏,今天安装了Visual Studio 2022专业版。在ue5中创建c工程,结果编译器报错: 严重性 代码 说明 项目…...

关系型数据库的一种自动测评方式
关系型数据库在如今已经是一门比较常用以及重要的技术,现在的大部分应用程序系统都构建于关系型数据库系统之上,数据库技能也是每个IT从业人员的必备技能之一,因此一些高校、培训学校等机构都把数据库课程作为必修课程之一。这就牵涉到考核的问题了,对于学生是否掌握该门技…...

速盾:服务器cdn加速的具体实现方式?
CDN(Content Delivery Network)即内容分发网络,是一种通过分布在各个地理位置的边缘节点服务器来缓存和传输网络内容的技术。CDN的主要目标是提高用户访问网站的速度和性能,并减轻源服务器的负载。 CDN加速是通过以下几个步骤来实…...

【QT教程】QT6音视频处理权威指南 QT音视频
QT6音视频处理权威指南 使用AI技术辅助生成 QT界面美化视频课程 QT性能优化视频课程 QT原理与源码分析视频课程 QT QML C扩展开发视频课程 免费QT视频课程 您可以看免费1000个QT技术视频 免费QT视频课程 QT统计图和QT数据可视化视频免费看 免费QT视频课程 QT性能优化视频免费…...
cmd输入mysql -u root -p无法启动
问题分析:cmd输入mysql -u root -p无法启动 解决方法:配置系统环境变量 1.找到mysql安装文件下的bin文件:(复制改文件地址,如下图所示) 2.电脑桌面下方直接搜索环境变量并进入,如下图 3.点击环境变量&a…...
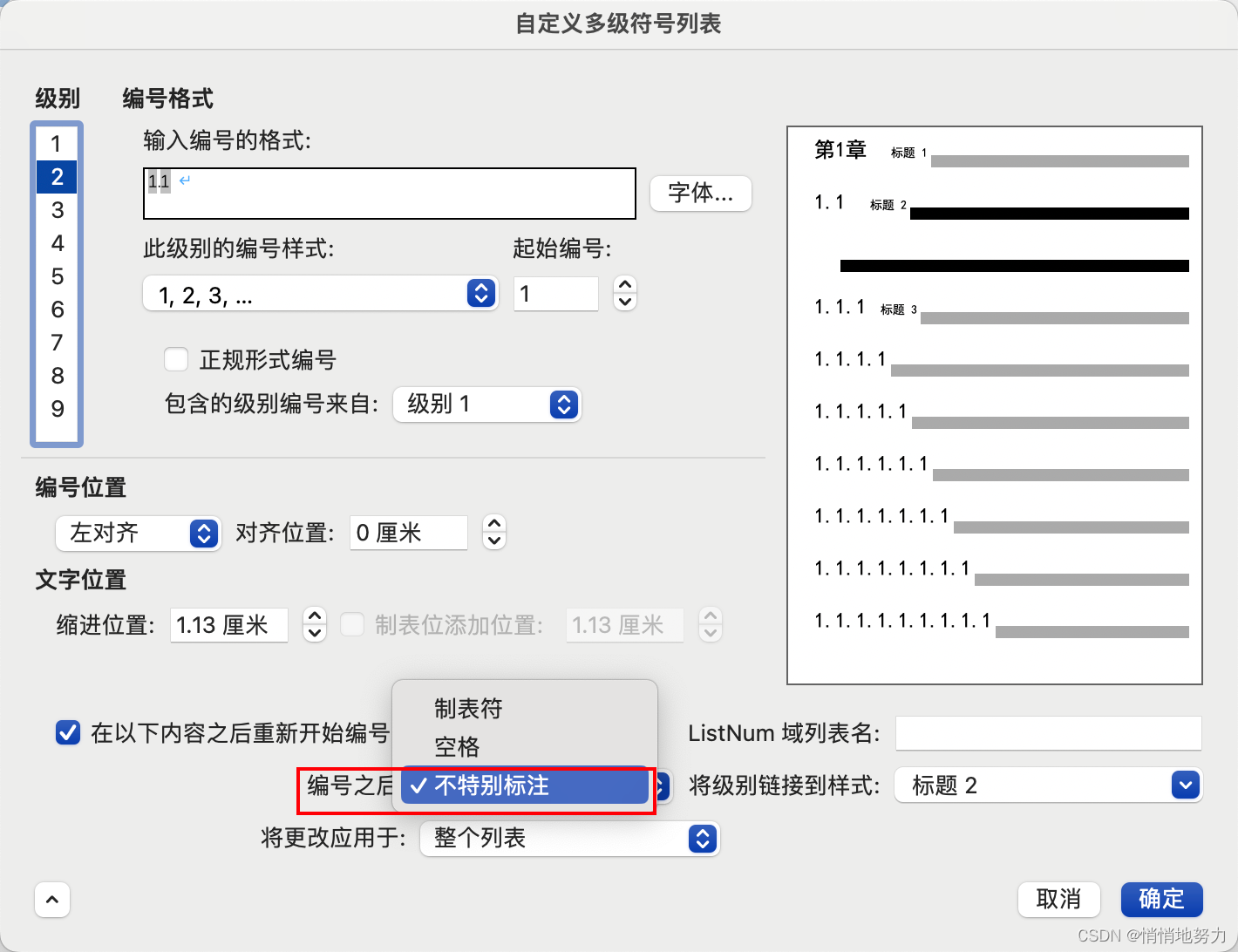
word 毕业论文格式调整
添加页眉页脚 页眉 首先在页面上端页眉区域双击,即可出现“页眉和页脚”设置页面: 页眉左右两端对齐 如果想要页眉页脚左右两端对齐,可以选择添加三栏页眉,然后将中间那一栏删除,即可自动实现左右两端对齐&#x…...

移动UI瓷片区能有多漂亮?要多漂亮就多漂亮。
移动UI的瓷片区(Tile area)是指移动应用或移动网页的界面布局中的一个区域,通常用于展示独立的信息块或功能块,每个块都是一个可点击的图标或瓷片,用于快速访问相关功能或查看相关信息。 瓷片区的设计灵感来源于Window…...

SpringCloud Config 分布式配置中心
SpringCloud Config 分布式配置中心 概述分布式系统面临的——配置问题ConfigServer的作用 Config服务端配置Config客户端配置 可以有一个非常轻量级的集中式管理来协调这些服务 概述 分布式系统面临的——配置问题 微服务意味着要将单体应用中的业务拆分成一个个字服务&…...
Java入门基础学习笔记2——JDK的选择下载安装
搭建Java的开发环境: Java的产品叫JDK(Java Development Kit: Java开发者工具包),必须安装JDK才能使用Java。 JDK的发展史: LTS:Long-term Support:长期支持版。指的Java会对这些版…...
基于FPGA的去雾算法
去雾算法的原理是基于图像去模糊的原理,通过对图像中的散射光进行估计和去除来消除图像中的雾霾效果。 去雾算法通常分为以下几个步骤: 1. 导引滤波:首先使用导引滤波器对图像进行滤波,目的是估计图像中散射光的强度。导引滤波器…...
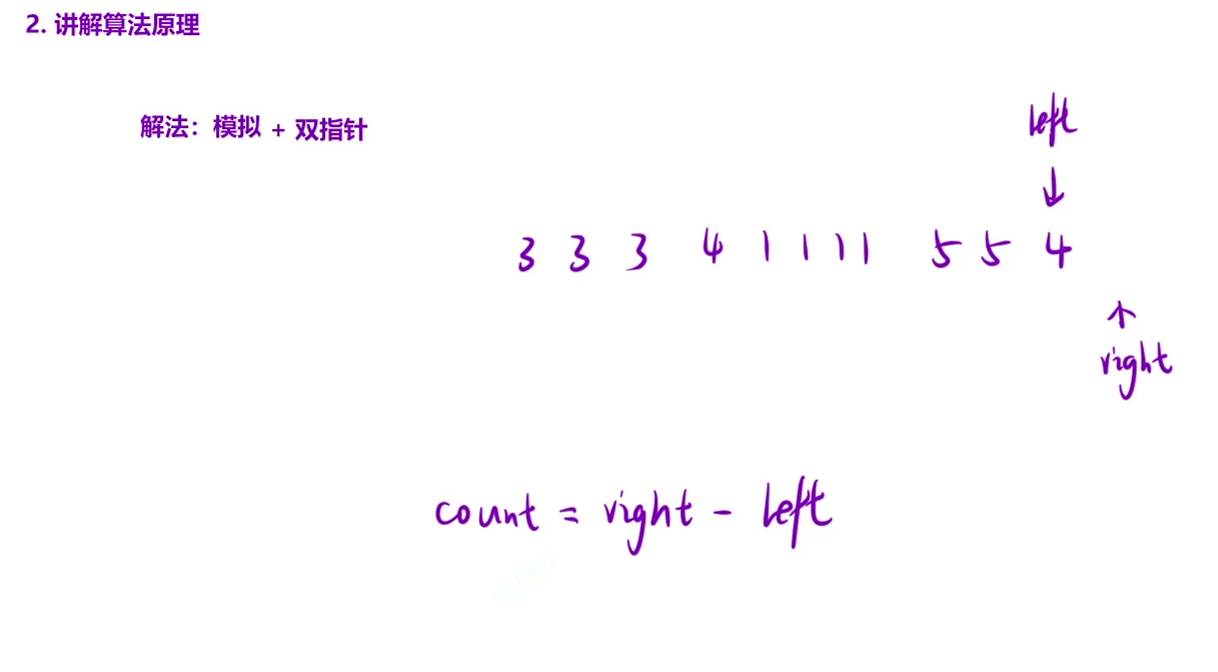
专题六_模拟(2)
目录 6. Z 字形变换 解析 题解 38. 外观数列 解析 题解 6. Z 字形变换 6. Z 字形变换 - 力扣(LeetCode) 解析 题解 class Solution { public:string convert(string s, int numRows) {// 42.专题六_模拟_N 字形变换_C// 处理边界情况if (numRows …...

[qnx] 通过zcu104 SD卡更新qnx镜像的步骤
0. 概述 本文演示如果给Xlinx zcu104开发板刷入自定义的qnx镜像 1.将拨码开关设置为SD卡启动 如下图所示,将1拨到On,2,3,4拨到Off,即为通过SD启动。 2.准备SD卡中的内容 首先需要将SD格式化为FAT32的(如果已经是FAT32格式,则…...
论文AIGC检测让毕业生头疼,如何有效降低AI查重率!
在准备毕业论文的过程中,不知道大家有没有跟我一样,遇到这样棘手的问题。我们都知道在撰写完论文后,进行论文查重是我们必不可少的一步。于是,我拿着论文进行了论文重复率的检测,发现重复率只有2.8%,看到这…...
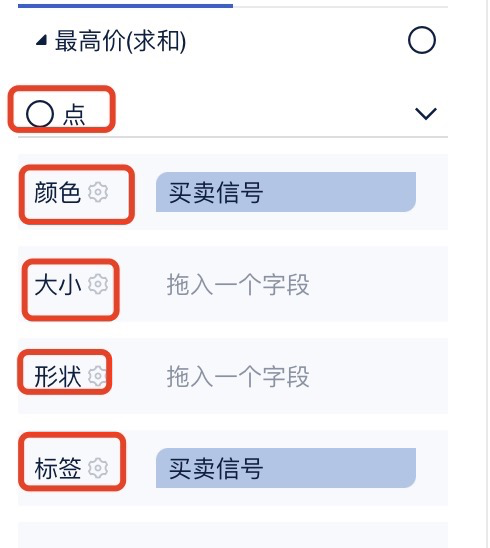
FineBI学习:K线图
效果图 底表结构:日期、股票代码、股票名称、开盘价、收盘价、最高价、最低价 步骤: 横轴:日期 纵轴:开盘价、最低价 选择【自定义图表】,或【瀑布图】 新建字段:价差(收盘-开盘…...
Chronos:学习时间序列的大语言模型(代码解析)
前言 《Chronos: Learning the Language of Time Series》原文地址,Github开源代码地址Chronos:学习时间序列的大语言模型(论文解读)CSDN地址GitHub项目地址Some-Paper-CN。本项目是译者在学习长时间序列预测、CV、NLP和机器学习…...

云南区块链商户平台优化开发
背景 云南区块链商户平台是全省统一区块链服务平台。依托于云南省发改委、阿里云及蚂蚁区块链的国内首个省级区块链平台——云南省区块链平台同步上线,助力数字云南整体升级。 网页版并不适合妈妈那辈人使用,没有记忆功能,于是打算自己开发…...

Git提交规范与自动化实践:从Conventional Commits到团队协作
1. 项目概述与核心价值最近在整理团队代码仓库时,发现一个挺普遍的问题:提交记录五花八门,什么“fix bug”、“update”、“test”之类的信息满天飞。这种混乱的提交历史,不仅让后续的代码审查和问题追溯变得异常困难,…...

机器人遥测系统设计:从数据采集到可视化监控的工程实践
1. 项目概述:从开源代码仓库到可观测性实践最近在梳理一些开源机器人项目时,遇到了一个名为jizb880/openclaw_telemetry的仓库。乍一看,这个标题由两部分组成:一个可能是作者的用户名jizb880,以及一个极具指向性的项目…...

【CTF】【Misc 文件类型】工具与流程
工具准备 本人为方便 CTF 部分 Misc 类型的解题,制作如下集成软件。本软件集成常用功能,能一站式解决大多数 Misc 文件类问题,省去切换工具的繁琐流程,大大提高解题效率,且界面简洁易用。且预留了拓展接口,…...

GitHub下载太慢?3分钟学会Fast-GitHub加速插件的终极解决方案
GitHub下载太慢?3分钟学会Fast-GitHub加速插件的终极解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 作为一名…...

如何自动化监控线上问题
要实现线上问题的自动化监控,不能仅停留在工具的堆砌,而需要从体系规划、数据采集、智能告警、动态诊断到流程规范进行全盘设计。以下是基于行业最佳实践的自动化监控构建指南:一、 体系规划与监控点梳理构建自动化监控的第一步是明确“监控什…...

在Taotoken模型广场根据任务与预算挑选合适模型的实践心得
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务与预算挑选合适模型的实践心得 作为一名日常需要与各类大模型打交道的开发者,模型选型是项…...

Postman便携版终极指南:绿色免安装的Windows API测试工具
Postman便携版终极指南:绿色免安装的Windows API测试工具 【免费下载链接】postman-portable 🚀 Postman portable for Windows 项目地址: https://gitcode.com/gh_mirrors/po/postman-portable Postman便携版是一款专为Windows用户设计的绿色免安…...

基于RAG的LLM知识库构建:从智能分块到检索增强生成实战
1. 项目概述:一个为大型语言模型量身定制的知识库构建工具如果你和我一样,经常和大型语言模型打交道,无论是用它们来辅助编程、分析文档,还是构建问答系统,那你一定遇到过这个核心痛点:如何让模型精准地理解…...

图像超分新SOTA:DAT模型凭什么在效果和效率上双赢?深入对比SwinIR、EDSR等经典方案
DAT模型:图像超分辨率领域的效率与效果平衡术 当一张模糊的老照片在算法处理后突然变得清晰可辨时,这种"魔法"背后是图像超分辨率技术的精妙演化。在这个领域,Transformer架构近年来展现出惊人的潜力,却也面临着计算复…...

Taotoken Token Plan套餐为高频用户带来的长期成本优势感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan套餐为高频用户带来的长期成本优势感知 对于高频使用大模型API的开发者或团队而言,项目开发中的模…...