【量化交易笔记】3.实现数据库保存数据
上一节,我们通过下载相关的 pandas 数据保存为 本地csv文件,这一节将上节的数据以数据库方式保存。
数据库保存
采集数据部分前一节已做说明,这里就直接用采用前面的内容。这里着重说明的事数据库连接。对与 python 相连接的数据库有很多,作为开放操作性及性能首选 mysql 。(MYSQL的安装这里不做说明),在使用之前,需要安装一个pymysql库,如果没有安装过,用以下命令进行安装,另外一个库sqlalchemy ,一般是默认安装好的。
库安装
pip install pymysql
定义一个数据库连接函数,返回连接对象,以下并非原创,感觉挺好用的,就引用来的。
数据库的连接
def conn():# 引擎参数信息host = 'localhost'user = 'root'passwd = 'root'port = '3306'db = 'quant'# 创建数据库引擎对象mysql_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}'.format(user, passwd, host, port),poolclass=sqlalchemy.pool.NullPool)# 如果不存在数据库db_quant则创建mysql_engine.execute("CREATE DATABASE IF NOT EXISTS {0} ".format(db))# 创建连接数据库db_quant的引擎对象db_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}/{4}?charset=utf8'.format(user, passwd, host, port, db),pool_size=80, max_overflow=80, pool_timeout=50)# 返回引擎对象return db_engine
上述代码,已很清晰的表述,返回的是数据库连接对象。
而数据表的有两种形式,一种将所有数据股票数据放在一张表里,好处是读写操作方便,缺点表的记录太大了,读取和写入效率非常低。因此将采取另一种方式,每一支股票一张表,那样的话,数据表大概有4000多,读取效率会很快,数据表名即股票名,例如“600001_sh”。通过to_sql()函数写入数据库。
# 写入数据库
table_name = '{}_{}'.format(code[3:], code[:2])
out_df.to_sql(name=table_name, con=engine, if_exists='replace', index=True, index_label='id')
首次执行
完整代码如下
# 第一次执行
import baostock as bs
import pandas as pd
import gc
import timebs.login()stock_df = bs.query_all_stock().get_data()
# 筛选股票数据,上证和深证股票代码在sh.600000与sz.39900之间
stock_df = stock_df[(stock_df['code'] >= 'sh.600000') & (stock_df['code'] < 'sz.399000')]
bs.logout()
stocks=stock_df['code'].to_list()lg = bs.login()
i=0
#数据库连接
engine = conn()
for code in stocks: rs = bs.query_history_k_data_plus(code,"date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,isST",start_date='2020-01-01', end_date='2023-3-1', #实际应用开始时间选2000-1-1 或更早frequency="d", adjustflag="1")df=rs.get_data()# 剔除停盘数据if df.shape[0]:df = df[(df['volume'] != '0') & (df['volume'] != '')]# 如果数据为空,则不创建if not df.shape[0]:continue# 删除重复数据df.drop_duplicates(['date'], inplace=True)# 日线数据少于250,则不创建if df.shape[0] < 250:continue# 将数值数据转为float型,便于后续处理convert_list = ['open', 'high', 'low', 'close', 'preclose', 'volume', 'amount', 'turn', 'pctChg']df[convert_list] = df[convert_list].astype(float)#df.to_csv("./data/daily/{0}.csv".format(code), index=False)# 写入数据库table_name = '{}_{}'.format(code[3:], code[:2])df.to_sql(name=table_name, con=engine, if_exists='replace', index=True, index_label='id')i=i+1if i%100==0 :gc.collect()print('已完成',i)time.sleep(2)
bs.logout()
与上节的代码的区别,增加了数据库连接,将写csv文件修改为写入数据库。
执行完毕,打开数据库查看如下图。
日常执行
# 日常执行
import baostock as bs
import pandas as pd
import gc
import time
import datetimetodate=datetime.date.today().strftime('%Y-%m-%d')bs.login()
stock_df = bs.query_sz50_stocks().get_data() # bs.query_all_stock().get_data()# 筛选股票数据,上证和深证股票代码在sh.600000与sz.39900之间
stock_df = stock_df[(stock_df['code'] >= 'sh.600000') & (stock_df['code'] < 'sz.399000')]
bs.logout()
stock=stock_df['code'].to_list()lg = bs.login()
i=0#数据库连接
engine = conn()for code in stocks: rs = bs.query_history_k_data_plus(code,"date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,isST",start_date=todate, end_date=todate, #选择当天frequency="d", adjustflag="1")df=rs.get_data()# 剔除停盘数据if df.shape[0]:df = df[(df['volume'] != '0') & (df['volume'] != '')]# 如果数据为空,则不创建if not df.shape[0]:continue# 将数值数据转为float型,便于后续处理convert_list = ['open', 'high', 'low', 'close', 'preclose', 'volume', 'amount', 'turn', 'pctChg']df[convert_list] = df[convert_list].astype(float)#df.to_csv("./data/daily/{0}.csv".format(code), mode='a', index=False, header=False) # 写入数据库table_name = '{}_{}'.format(code[3:], code[:2])df.to_sql(name=table_name, con=engine, if_exists='append', index=True, index_label='id')i=i+1 if i%500==0 :gc.collect()print('已完成',i)time.sleep(2)
bs.logout()
同样,将首次执行中将日期修改当天日期,写入数据方式,由原来的“repalce”修改为了“append”,以完成追加。
总结
至此,我们用两种方式将数据本地化,有了数据我们就可以进行相关的操作。从下一讲开始介绍数据的相关处理。
相关文章:
【量化交易笔记】3.实现数据库保存数据
上一节,我们通过下载相关的 pandas 数据保存为 本地csv文件,这一节将上节的数据以数据库方式保存。 数据库保存 采集数据部分前一节已做说明,这里就直接用采用前面的内容。这里着重说明的事数据库连接。对与 python 相连接的数据库有很多&a…...

[数据结构]:15-堆排序(顺序表指针实现形式)(C语言实现)
目录 前言 已完成内容 堆排序实现 01-开发环境 02-文件布局 03-代码 01-主函数 02-头文件 03-PSeqListFunction.cpp 04-SortCommon.cpp 05-SortFunction.cpp 结语 前言 此专栏包含408考研数据结构全部内容,除其中使用到C引用外,全为C语言代码…...

蓝桥 卷“兔”来袭编程竞赛专场-02破解曾公亮密码 题解
赛题介绍 挑战介绍 曾公亮编撰的《武经总要》中记载了一套严谨的军事通信密码,这也是目前发现我国古代战争中最早使用的军用密码表。将战场上可能常用到的情况,用 40 个短语归纳表示,且每个短语前编有固定的数字代码,这 40 个短…...

CSS定位
🍓个人主页:bit.. 🍒系列专栏:Linux(Ubuntu)入门必看 C语言刷题 数据结构与算法 HTML和CSS3 目录 1.1为什么需要定位? 1.2定位组成 1.3静态定位static(了解) 1.4相对定位 relative …...

python sympy库
sympy库是python的符号运算库,是电脑辅助简单数学函数计算的好工具。本文简单记录了一下有关sympy的方法。建议使用jupyter notebook,这样输出的函数很好看。 文章目录sympy基础安装自变量(Symbols)函数表达式(Expr&am…...

达梦数据库统计信息的导出导入
一、统计信息对象统计信息描述了对象数据的分布特征。统计信息是优化器的代价计算的依据,可以帮助优化器较精确地估算成本,对执行计划的选择起着至关重要的作用。统计信息的收集频率是一把双刃剑,频率太低导致统计信息滞后,频率太…...

信息系统基本知识(六)
大纲 信息系统与信息化信息系统开发方法常规信息系统集成技术软件工程新一代信息技术信息系统安全技术信息化发展与应用信息系统服务管理信息系统服务规划企业首席信息管及其责任 1.7 信息化发展与应用 我国在“十三五”规划纲要中,将培育人工智能、移动智能终端…...

<C++>智能指针
1. 智能指针 #define _CRT_SECURE_NO_WARNINGS #include<iostream> #include<memory> using namespace std;int div() {int a, b;cin >> a >> b;if (b 0)throw invalid_argument("除0错误");return a / b; }void func() {int* p1 new in…...

1.分析vmlinux可执行文件是如何生成的? 2.整理内核编译流程:uImage/zImage/Image/vmlinx之间关系
一、分析vmlinux可执行文件是如何生成的? 1、分析内核的底层 makefile 如下: vmlinux: scripts/link-vmlinux.sh vmlinux_prereq $(vmlinux-deps) FORCE$(call if_changed,link-vmlinux)vmlinux_prereq: $(vmlinux-deps) FORCE发现vmlinux的生成主要依…...
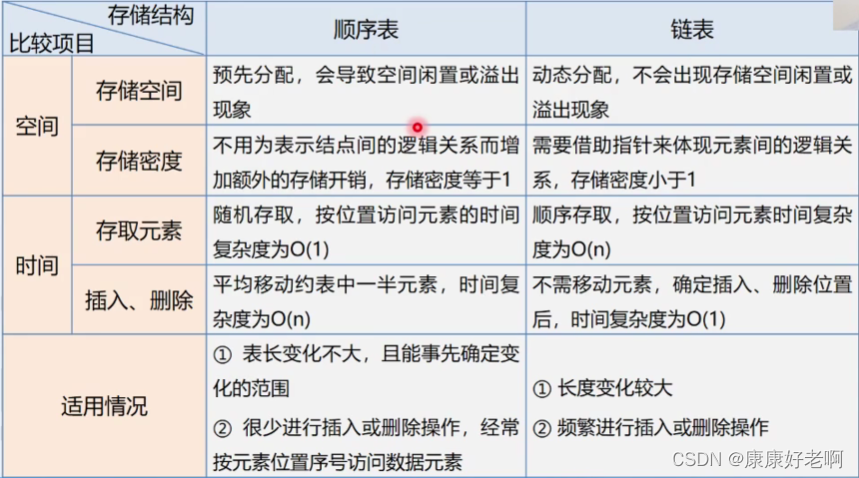
数据结构4——线性表3:线性表的链式结构
基本概念 链式存储结构用一组物理位置任意的存储单元来存放线性表的数据元素。 这组存储单元既可以是连续的又可以是不连续的甚至是零散分布在任意位置上的。所以链表中元素的逻辑次序和物理次序不一定相同。而正是因为这一点,所以我们要利用别的方法将这些…...

weblogic 忘记密码重置密码
解决:weblogic 忘记密码 weblogic安装后,很久不用,忘记访问控制台的用户名或者密码,可通过以下步骤来重置用户名密码。 版本:WebLogic Server 11g 说明:%DOMAIN_HOME%:指WebLogic Server 域(…...

安卓开发之动态设置网络访问地址
之前开发程序联测测接口的时候,因为要和不同的后台人员调接口,所以经常要先把程序里的ip地址改成后台人员给我的。每次都要先修改ip地址,之后编译运行一下,才能测试。但要是换了个后台人员,或者同时和2个后台人员测接口…...

深度学习模型训练工作汇报(3.8)
进行数据的初始整理的准备 主要是进行伪序列字典的设置,以及训练数据集的准备。 期间需要的一些问题包括在读取文件信息的时候,需要跳过文件的第一行或者前两行,如果使用循环判断的话,会多进行n次的运算,这是不划算的…...

【ns-3】添加nr(5G-LENA)模块
文章目录前言1. 下载5G-LENA源代码2. 配置并重新构建ns-3项目参考文献前言 本篇以ns-3.37为例介绍如何在ns-3中添加nr(5G-LENA)模块 [1]。5G-LENA是一个由Mobile Networks group CTTC(Centre Tecnolgic de Telecomunicacions de Catalunya&a…...
(模拟)(前缀和)(数组模拟哈希)(可二分)1236. 递增三元组)
(枚举)(模拟)(前缀和)(数组模拟哈希)(可二分)1236. 递增三元组
目录 题目链接 一些话 流程 套路 ac代码 题目链接 1236. 递增三元组 - AcWing题库 一些话 int f[N]; memset(f,0,sizeof f)影响不到f[N] 所以尽量不要对f[N]赋值,不要用f[N]操作 流程 //由三重暴力i,j,k因为三重暴力底下是分别用i和j,j和k作比较…...
)
mysql五种索引类型(实操版本)
为什么使用索引 最近学习了Mysql的索引,索引对于Mysql的高效运行是非常重要的,正确的使用索引可以大大的提高MySql的检索速度。通过索引可以大大的提升查询的速度。不过也会带来一些问题。比如会降低更新表的速度(因为不但要把保存数据还要保…...

微服务进阶之 SpringCloud Alibaba
文章目录微服务进阶🍓SpringCloud 有何劣势?🍓SpringCloud Alibaba 提供了什么?提示:以下是本篇文章正文内容,SpringCloud 系列学习将会持续更新 微服务进阶 🍓SpringCloud 有何劣势࿱…...

前端性能优化笔记2 第二章 度量
相关 Performance API 都在 window.performance 对象下 performance.now() 方法 精度精确到微妙获取的是把页面打开时间点作为基点的相对时间,不依赖操作系统的时间。 部分浏览器不支持 performance.now() 方法,可以用 Date.now() 模拟 performance.n…...
关于new和delete的一些思考,为什么不能在析构函数中调用delete释放对象的内存空间,new和delete的原理
最近在写代码的时候,觉得每次new出来的对象都需要去delete好麻烦,于是直接把delete写到了析构函数中,在析构函数里面写了句delete this,结果调用析构函数的时候死循环了,不是很理解原因,于是去研究了一下。…...

一场以数字技术深度影响和改造传统实业的新风口,正在开启
当数字经济的浪潮开始上演,一场以数字技术深度影响和改造传统实业的新风口,正在开启。对于诸多在互联网时代看似业已走入死胡同的物种来讲,可以说是打开了新的天窗。对于金融科技来讲,同样如此。以往,谈及金融科技&…...

大数据+大模型=乘法效应?6个场景告诉你,大模型如何让你的数据平台“活”起来!
本文探讨了大数据与大模型的关系,提出大模型是大数据平台的“发动机”。文章重点介绍了六个必须使用大模型才能解放双手的场景,包括数据血缘解析、Text2SQL、数据质量智能巡检、调度任务智能运维、元数据管理和报告自动生成。这些场景展示了大模型如何通…...

GPS测速仪SpeedView 3.2.0汉化版 精准速度 实时测速工具
一款实时测速应用程序,英文名为“SpeedView”,安装到手机上就能够在开车的时候查看仪表盘车辆的速度是否准确 实时测速:通过GPS精准定位,实时显示当前速度、平均速度和最高速度,支持多种单位切换(km/h、mp…...

Rust 环境搭建指南
Rust 环境搭建指南 引言 Rust 是一种系统编程语言,以其高性能、内存安全和并发特性而闻名。在本文中,我们将详细讲解如何搭建 Rust 开发环境,包括安装 Rust 语言、配置编辑器以及使用 Rust 包管理器 Cargo。 安装 Rust 系统要求 在开始之前,请确保您的计算机满足以下系…...

【光学】偏振光线追迹Matlab仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...
)
Codex CLI 接 Gemini 3.5 Flash 实测:代码生成、推理速度、价格三维度横评(2026)
上周 Google 发了 Gemini 3.5 Flash,我当天晚上就拿 Codex CLI 接上跑了几个项目里的真实任务。原因很简单——我们团队最近 token 开销涨得太快,老板让我找个"又快又便宜还不太拉胯"的模型顶日常编码场景。Claude Sonnet 4.6 质量没话说但贵&…...

瑞芯微RK3568与RK3566芯片选型指南:从接口差异到应用场景深度解析
1. 项目概述:为何要深挖这两颗“芯”?在嵌入式开发和智能硬件选型的圈子里,瑞芯微(Rockchip)的RK3568和RK3566是近两年曝光率极高的两颗“明星”芯片。很多刚接触的朋友第一眼看去,会觉得它们很像ÿ…...

汽车12V电源保护:TVS二极管选型、应用与EMC测试实战
1. 项目概述:为什么汽车12V电源线需要“特种保镖”?在汽车电子系统里,那根看似普通的12V DC电源线,其实是个“压力山大”的角色。它不仅要给车机、仪表、传感器、ECU(电子控制单元)这些“大脑”和“神经”稳…...

基于RK3399核心板的智能PCR仪开发:从嵌入式系统到高精度温控
1. 项目概述:当PCR仪遇上高性能核心板在分子生物学实验室里,PCR仪(聚合酶链式反应仪)是当之无愧的“C位”设备。从基础的病原体检测、基因分型,到前沿的基因编辑、高通量测序文库构建,几乎每一个实验环节都…...

GQA:多查少算的 Attention 头组合
本文基于昇腾CANN和昇腾NPU,围绕 ops-transformer 仓库的相关技术展开。 MHA(Multi-Head Attention)每个 Head 一套 QKV——8 个 Head 就是 8 组。MQA 省过头了——8 个 Head 共享 K、V。GQA(Grouped Query Attention)…...

Taotoken 的 Token Plan 套餐如何帮助我们预测并锁定开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 Token Plan 套餐如何帮助我们预测并锁定开发成本 作为项目管理者,确保研发预算的可预测性是保障项目平稳推…...