YOLOv5-7.0改进(四)添加EMA注意力机制
前言
关于网络中注意力机制的改进有很多种,本篇内容从EMA注意力机制开始!
往期回顾
YOLOv5-7.0改进(一)MobileNetv3替换主干网络
YOLOv5-7.0改进(二)BiFPN替换Neck网络
YOLOv5-7.0改进(三)添加损失函数EIoU、AlphaIoU、SIoU、WIoU、MPDIoU、NWD
目录
- 一、EMA简介
- 二、Neck端添加EMA
- 第一步:在common.py中添加EMA模块
- 第二步:在yolo.py中的parse_model函数加入类名
- 第三步:制作模型配置文件
- 第四步:验证新加入的Neck网络
- 三、C3中添加EMA
- 第一步:在common.py中添加EMA模块
- 第二步:在yolo.py中的parse_model函数加入类名
- 第三步:制作模型配置文件
- 第四步:验证新加入的Neck网络
一、EMA简介
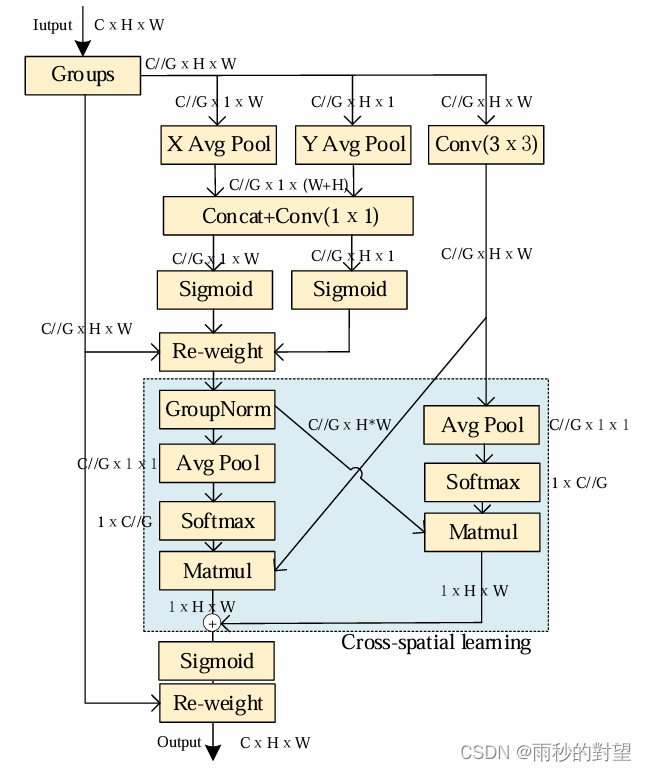
论文题目:Efficient Multi-Scale Attention Module with Cross-Spatial Learning
EMA注意力机制:基于跨空间学习的高效多尺度注意力机制,该模块首先将部分通道维度重塑为批量维度,以避免通用卷积进行某种形式的降维,接着在每个并行子网络中构建局部的跨通道交互,利用一种新的跨空间学习方法融合两个并行子网络的输出特征图,设计了一个多尺度并行子网络来建立长短依赖关系。
网络结构:
二、Neck端添加EMA
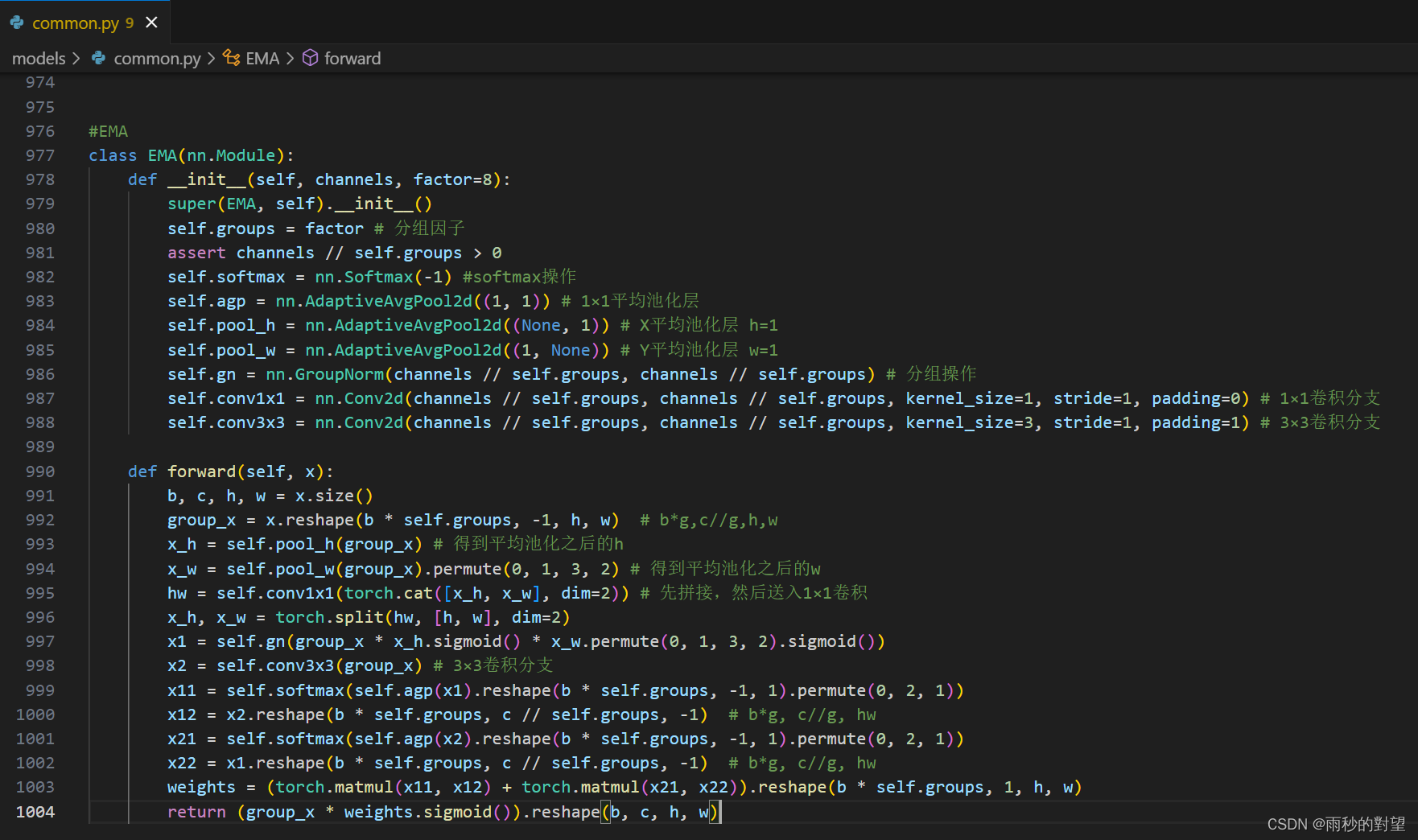
第一步:在common.py中添加EMA模块
代码如下:
#EMA
class EMA(nn.Module):def __init__(self, channels, factor=8):super(EMA, self).__init__()self.groups = factor # 分组因子assert channels // self.groups > 0self.softmax = nn.Softmax(-1) #softmax操作self.agp = nn.AdaptiveAvgPool2d((1, 1)) # 1×1平均池化层self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # X平均池化层 h=1self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # Y平均池化层 w=1self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups) # 分组操作self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0) # 1×1卷积分支 self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1) # 3×3卷积分支def forward(self, x):b, c, h, w = x.size()group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,wx_h = self.pool_h(group_x) # 得到平均池化之后的hx_w = self.pool_w(group_x).permute(0, 1, 3, 2) # 得到平均池化之后的whw = self.conv1x1(torch.cat([x_h, x_w], dim=2)) # 先拼接,然后送入1×1卷积x_h, x_w = torch.split(hw, [h, w], dim=2)x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())x2 = self.conv3x3(group_x) # 3×3卷积分支x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hwx21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hwweights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)return (group_x * weights.sigmoid()).reshape(b, c, h, w)
插入效果:
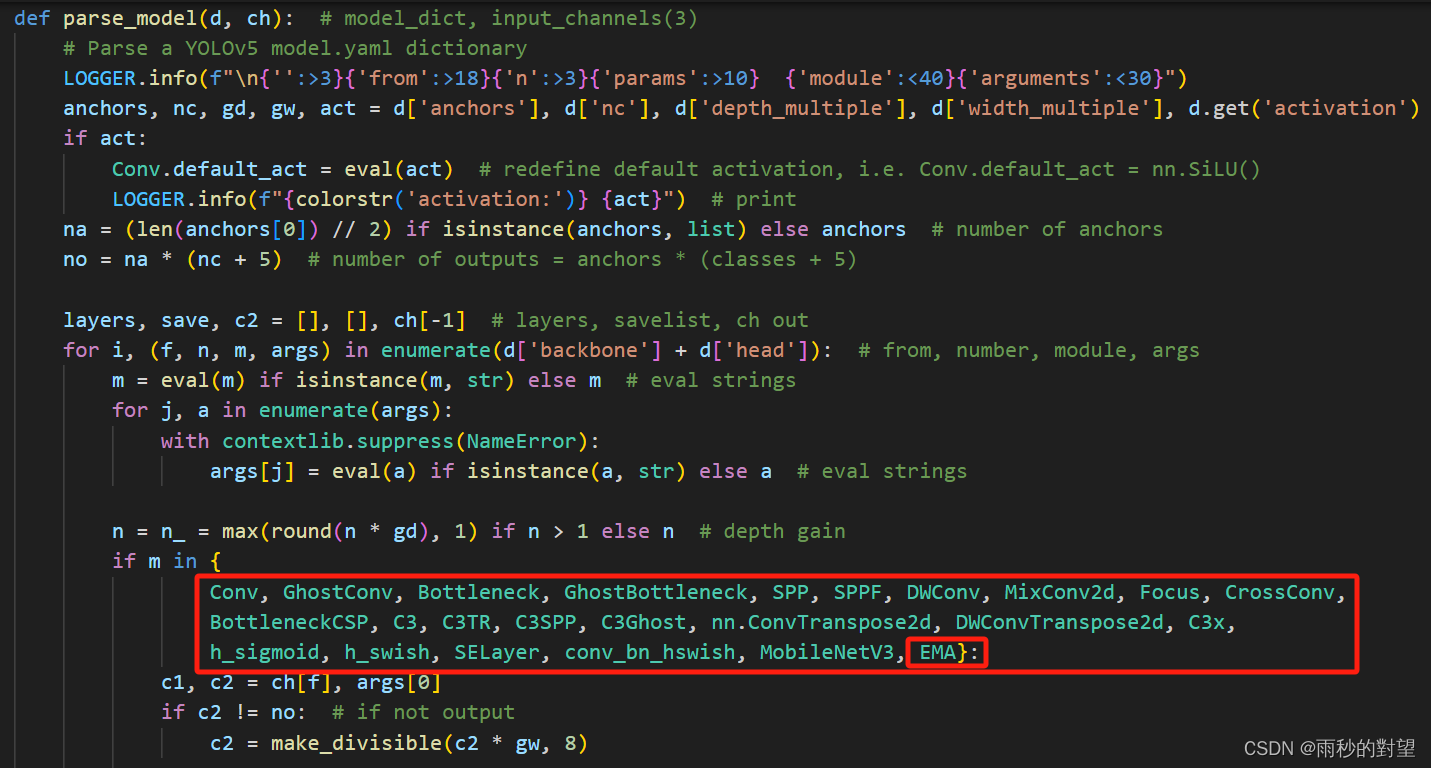
第二步:在yolo.py中的parse_model函数加入类名
将EMA类名添加到注册表中,效果如下:
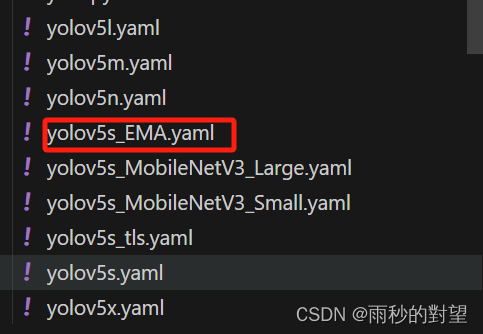
第三步:制作模型配置文件
1、复制models/yolov5s.yaml文件,并重命名
2、将以下代码复制到新创建的yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 12 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, EMA, [256]], # 加入到小目标层后[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, EMA, [512]], # 加入到中目标层后[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[-1, 1, EMA, [1024]], # 加入到大目标层后[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
第四步:验证新加入的Neck网络
1、修改yolo.py中以下两个地方
(1)DetectionModel函数下的cfg
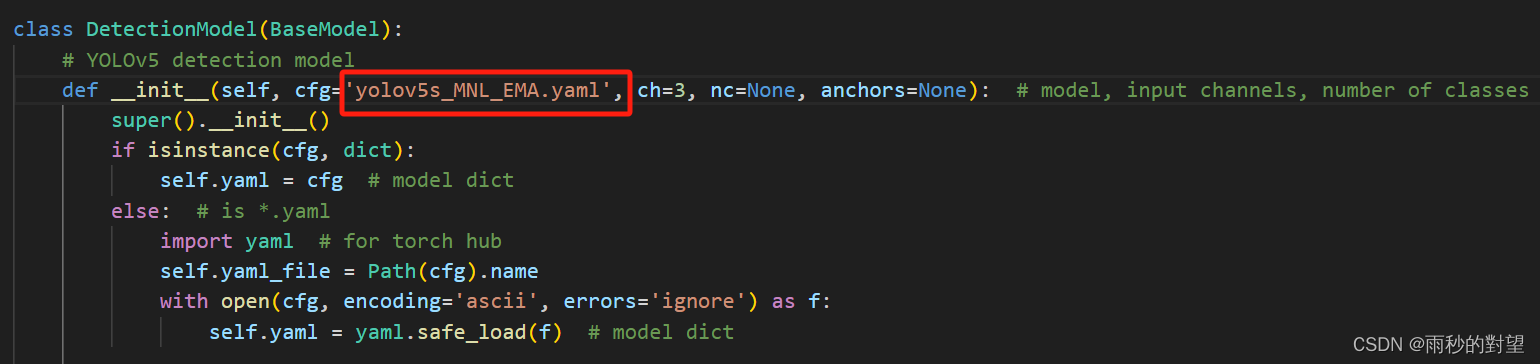
(2)parser = argparse.ArgumentParser()下的cfg
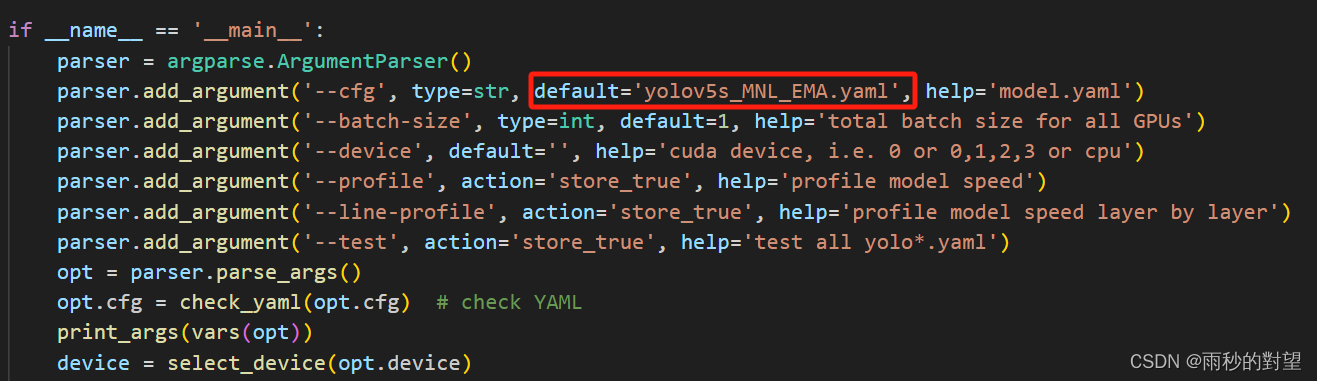
2、运行yolo.py
(1)yolov5s_EMA.yaml
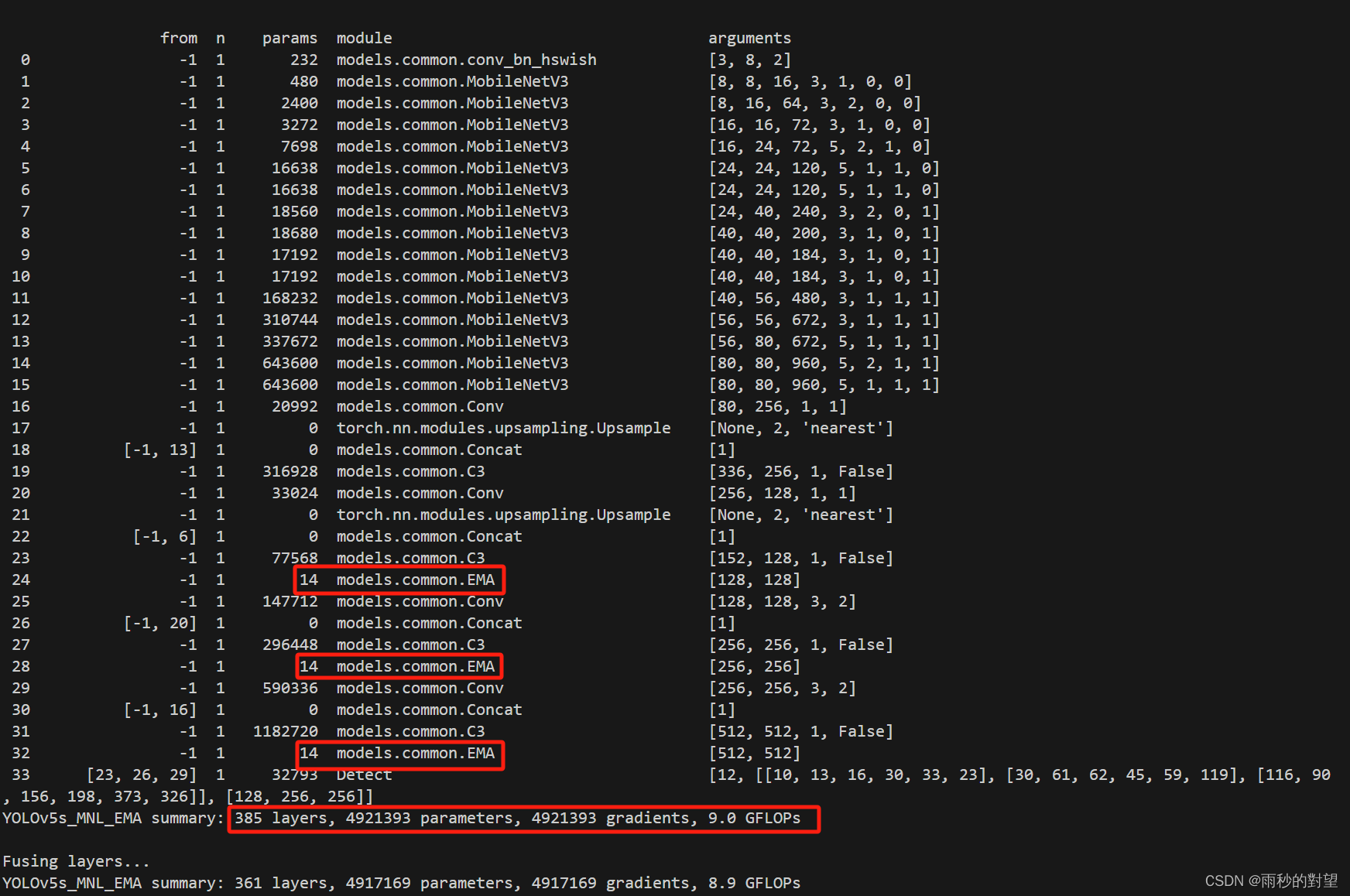
好了,到这一步在Neck端添加EMA基本完成,接下就可以开始训练~
三、C3中添加EMA
第一步:在common.py中添加EMA模块
代码如下:
#EMA
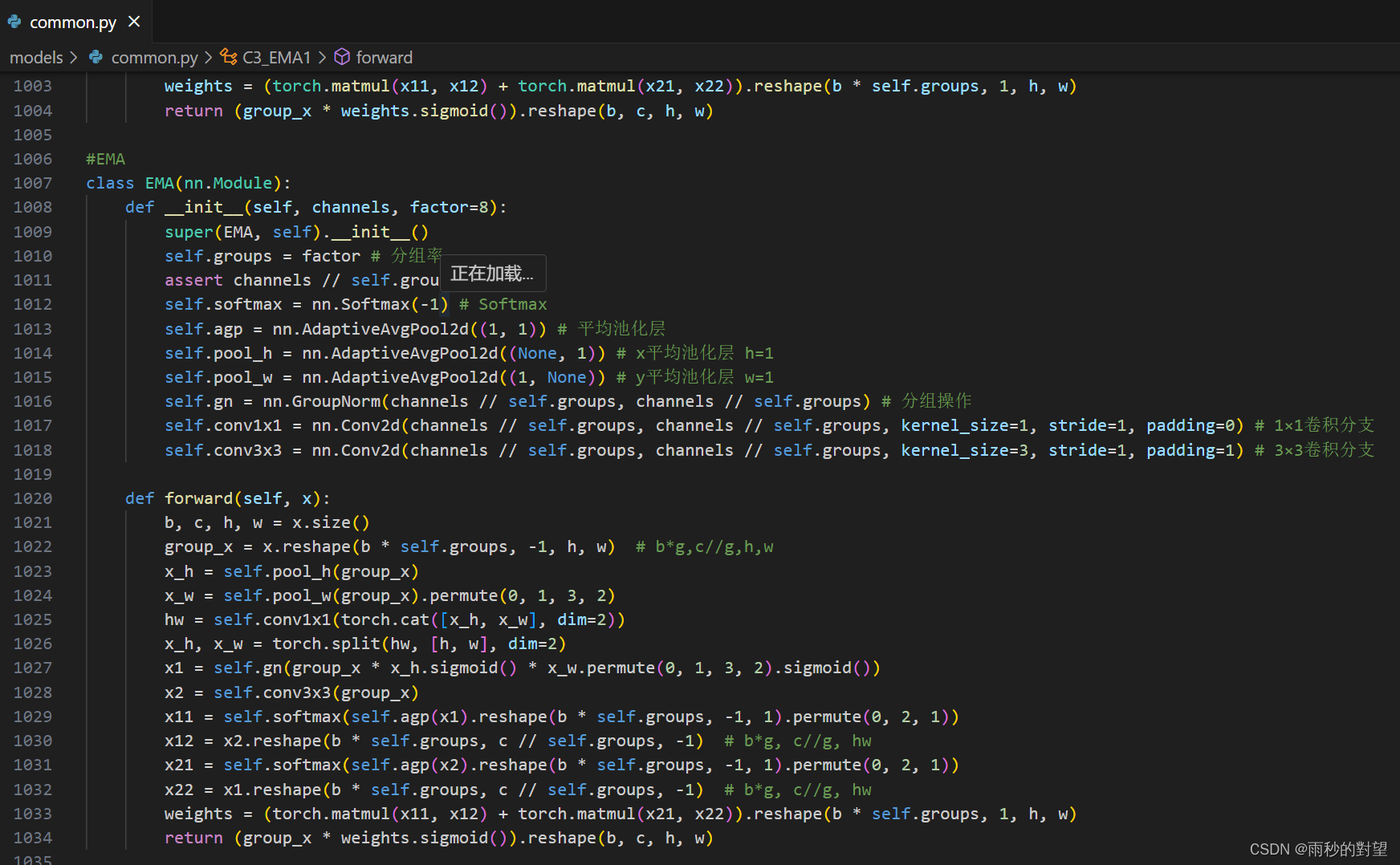
class EMA(nn.Module):def __init__(self, channels, factor=8):super(EMA, self).__init__()self.groups = factor # 分组率assert channels // self.groups > 0self.softmax = nn.Softmax(-1) # Softmaxself.agp = nn.AdaptiveAvgPool2d((1, 1)) # 平均池化层self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # x平均池化层 h=1self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # y平均池化层 w=1self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups) # 分组操作self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0) # 1×1卷积分支self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1) # 3×3卷积分支def forward(self, x):b, c, h, w = x.size()group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,wx_h = self.pool_h(group_x)x_w = self.pool_w(group_x).permute(0, 1, 3, 2)hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))x_h, x_w = torch.split(hw, [h, w], dim=2)x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())x2 = self.conv3x3(group_x)x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hwx21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hwweights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)return (group_x * weights.sigmoid()).reshape(b, c, h, w)class C3_EMA3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))self.m1 = nn.ModuleList([EMA(2 * c_)]) # 添加在最后一个卷积之前def forward(self, x):return self.cv3(self.m1[0](torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1)))class C3_EMA2(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))self.m1 = nn.ModuleList([EMA(c1)]) # 添加在最后一个卷积之前def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(self.m1[0](x))), 1))class C3_EMA1(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))self.m1 = nn.ModuleList([EMA(c_)]) # 添加在最后一个卷积之前def forward(self, x):return self.cv3(torch.cat((self.m(self.m1[0](self.cv1(x))), self.cv2(x)), 1))
效果如下:
第二步:在yolo.py中的parse_model函数加入类名
将以下类名添加到注册表中
EMA, C3_EMA1, C3_EMA2, C3_EMA3
效果如下:
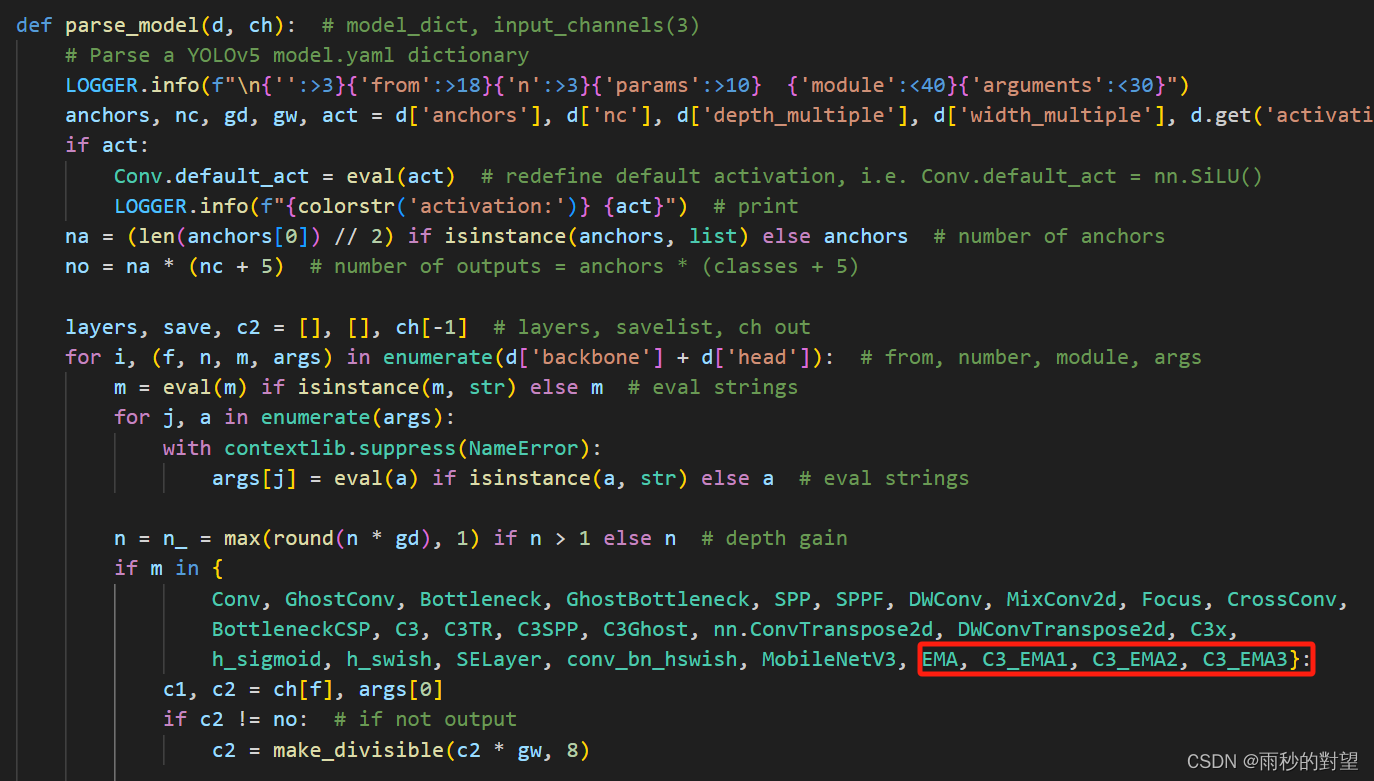
第三步:制作模型配置文件
将以下代码复制到yaml文件中
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 12 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3_EMA1, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
第四步:验证新加入的Neck网络
1、运行yolo.py
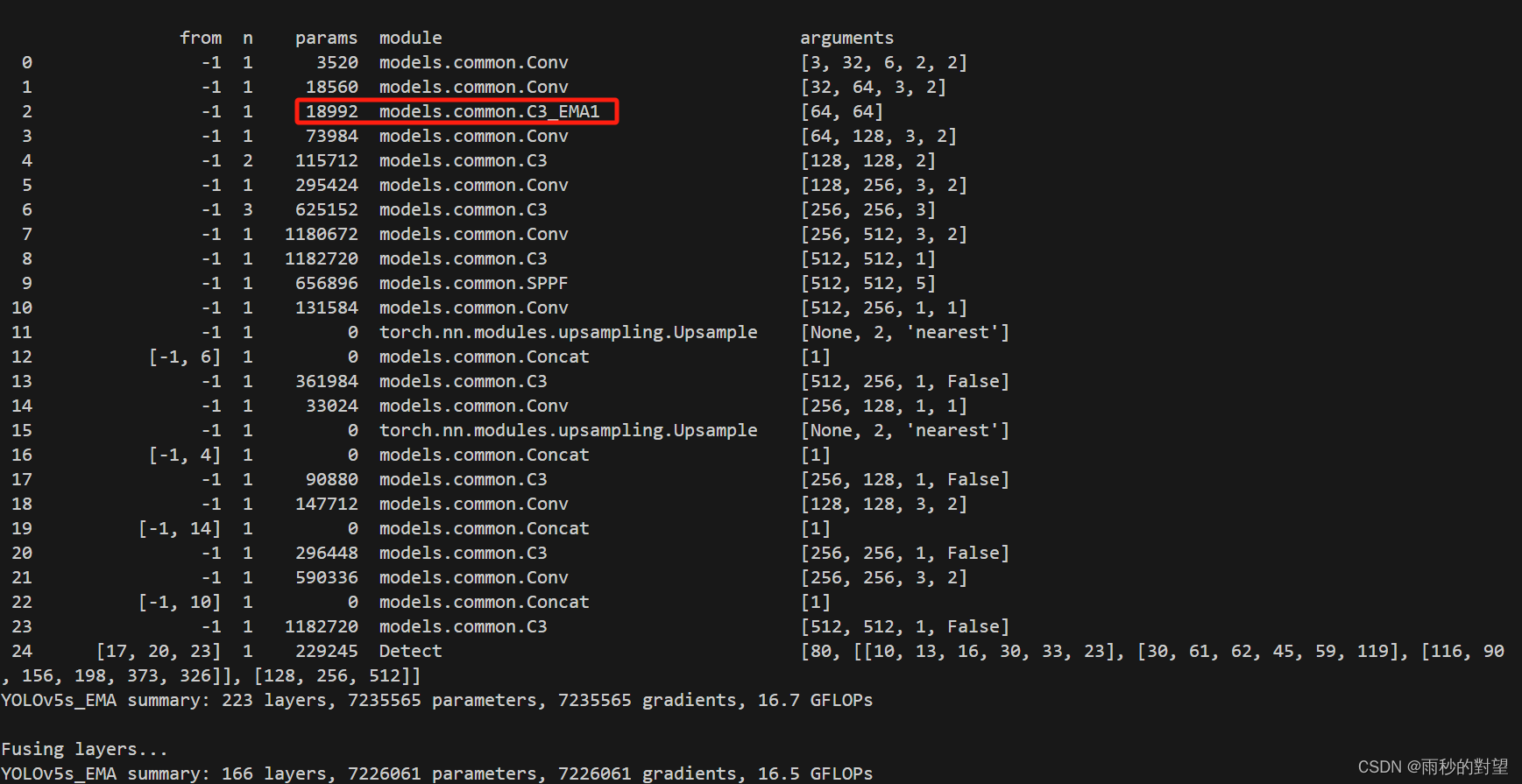
接下来也是对这个模型进行训练,需要注意的是这是在主干网络部分改进~
相关文章:
YOLOv5-7.0改进(四)添加EMA注意力机制
前言 关于网络中注意力机制的改进有很多种,本篇内容从EMA注意力机制开始! 往期回顾 YOLOv5-7.0改进(一)MobileNetv3替换主干网络 YOLOv5-7.0改进(二)BiFPN替换Neck网络 YOLOv5-7.0改进(三&…...
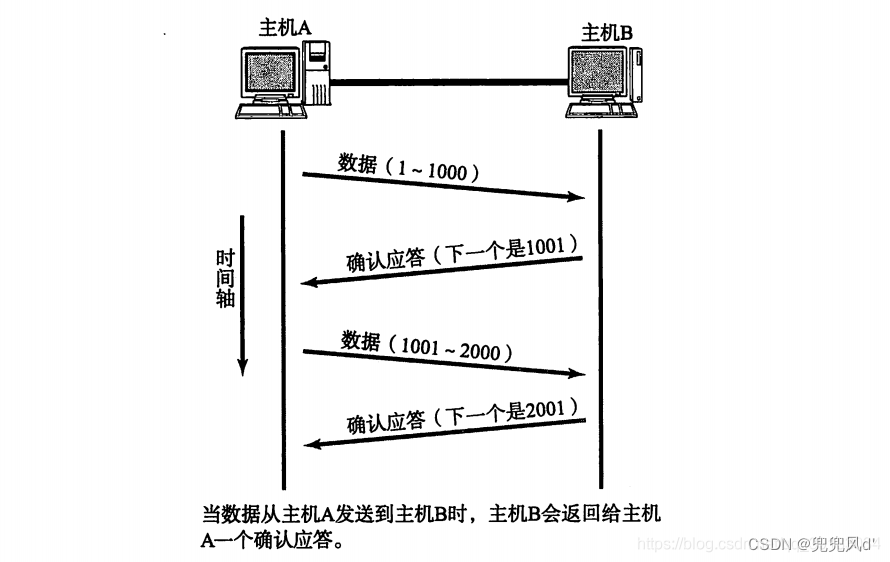
TCP协议的确认应答机制
TCP(Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层协议,它在网络通信中扮演着至关重要的角色。其中,确认应答机制是TCP协议中的一个核心概念,它确保了数据的可靠传输。本文将详细介绍J…...
【论文阅读笔记】MAS-SAM: Segment Any Marine Animal with Aggregated Features
1.论文介绍 MAS-SAM: Segment Any Marine Animal with Aggregated Features MAS-SAM:利用聚合特征分割任何海洋动物 Paper Code(空的) 2.摘要 最近,分割任何模型(SAM)在生成高质量的对象掩模和实现零拍摄图像分割方面表现出卓越…...

C语言中的精确宽度类型
概述 在 C 语言标准库 <stdint.h> 中定义了一系列精确宽度的整数类型,这些类型保证了它们的位数宽度,从而允许编写跨平台的可移植代码。以下是一些常用的精确宽度整数类型: int8_t: 8位有符号整数uint8_t: 8位无符号整数int16_t: 16位…...

大数据比赛-环境搭建(一)
1、安装VMware Workstation 链接:https://pan.baidu.com/s/1IvSFzpnQFl3svWyCGRtEmg 提取码:ukpo 内有安装包及破解方式,安装教程。 2、下载Ubuntu系统 阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区 (aliyun.com) 点击下载ÿ…...
微信小程序原生组件使用
1、video组件使用 <view class"live-video"><video id"myVideo" src"{{videoSrc}}" bindplay"onPlay" bindfullscreenchange"fullScreenChange" controls object- fit"contain"> </video&g…...

[数据集][目标检测]纸箱子检测数据集VOC+YOLO格式8375张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):8375 标注数量(xml文件个数):8375 标注数量(txt文件个数):8375 标注…...
2024HW Linux应急响应基础学习
首先展示关于Linux的关键目录,这是应急响应查看的关键: 常用命令 top //查看进程资源的占用情况 ps -aux //查看进程 直接写ps aux也可以 netstat -antpl //查看网络连接 ls -alh /proc/pid //查看某个pid对应的可执行程序 pid记得修改 lsof /…...

烽火三十六技丨网络资产安全治理平台新版本发布,一文看懂四大核心优势
云计算、移动互联网、物联网等技术飞速发展,网络环境愈发开放互联,原有的资产管理方式已难以适应当下的变化。同时,网络资产需求的突发性和人为疏忽,也时常导致资产数量不明、类型模糊、安全漏洞检查不全面等问题。因此࿰…...
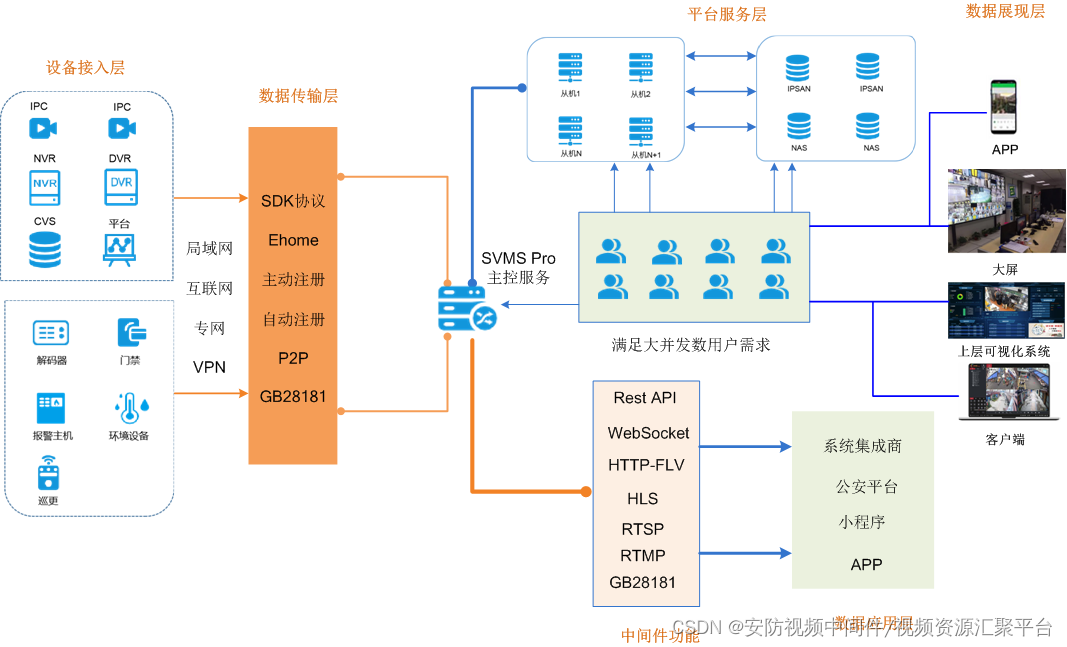
视频资源汇聚平台常见的几种接入方式
视频资源汇聚平台 视频汇聚平台可以实现海量资源的接入、汇聚、存储、处理、分析、运维等,平台具备轻量化接入能力,可支持多协议方式接入,包括主流标准协议GB28181、RTSP、ONVIF、RTMP、FLV、WEBSOCKET等,以及厂家私有协议与SDK接…...

LeetCode 212.单词搜索II
https://leetcode.cn/problems/word-search-ii/description/?envTypestudy-plan-v2&envIdtop-interview-150 文章目录 题目描述解题思路代码实现 题目描述 给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二…...

android 蓝牙技术 学习记录
一 。蓝牙介绍 蓝牙可以分为 经典蓝牙-----》传统蓝牙(BT 1.0/2.0/2.1)和高速蓝牙(BT3.0) 低功耗蓝牙 ----》BLE(BLE 4.0/4.1/4.2/5.0./5.1/5.2)和 Bluetooth Mesh 关于蓝牙协议。除开Mesh大致可以分为3层: App:上层协议有很多,例如ANP,HOGP,FTMP 等等 host:中…...

2024数维杯数学建模B题完整论文讲解(含每一问python代码+结果+可视化图)
大家好呀,从发布赛题一直到现在,总算完成了2024数维杯数学建模挑战赛生物质和煤共热解问题的研究完整的成品论文。 本论文可以保证原创,保证高质量。绝不是随便引用一大堆模型和代码复制粘贴进来完全没有应用糊弄人的垃圾半成品论文。 B题论…...
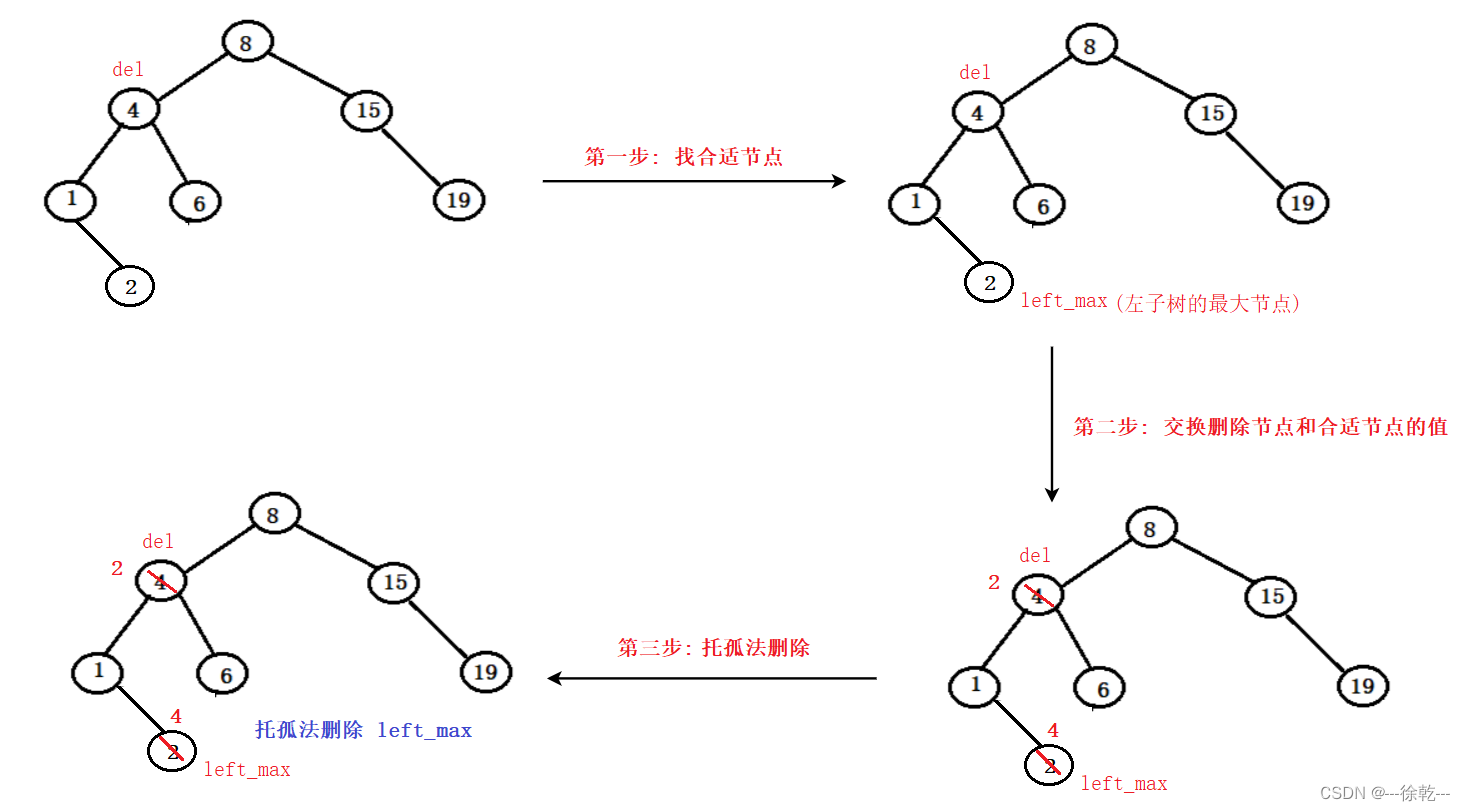
二叉树进阶 --- 中
目录 1. find 的递归实现 2. insert 的递归实现 3. erase 的递归实现 3.1. 被删除的节点右孩子为空 3.2. 被删除的节点左孩子为空 3.3. 被删除的节点左右孩子都不为空 4. 析构函数的实现 5. copy constructor的实现 6. 赋值运算符重载 7. 搜索二叉树的完整实现 1. fi…...

ChatGPT DALL-E绘图,制作各种表情包,实现穿衣风格的自由切换
DALL-E绘图功能探索: 1、保持人物形象一致,适配更多的表情、动作 2、改变穿衣风格 3、小女孩的不同年龄段展示 4、不同社交平台的个性头像创作 如果不会写代码,可以问GPT。使用地址:我的GPT4 视频,B站会发&#…...

程序环境和预处理、编译链接过程、编译的几个阶段、运行环境、预定义符号等的介绍
文章目录 前言一、程序的翻译环境和执行环境二、编译链接过程三、编译的几个阶段四、运行环境五、预定义符号总结 前言 程序环境和预处理、编译链接过程、编译的几个阶段、运行环境、预定义符号的介绍。 一、程序的翻译环境和执行环境 在 ANSI C 的任何一种实现中,…...

MySQL导入导出详细教程
导出 语法 mysqldump [OPTIONS] database [tables] mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...] mysqldump [OPTIONS] --all-databases [OPTIONS]导出所有数据库 mysqldump -uroot -proot --all-databases >/tmp/all.sql导出db1、db2两个数据库的所有数…...

STM32F103学习笔记 | 8. 二,八,十,十六进制表示方式
文章目录 进制基本信息参考文献 进制基本信息 C语言中的表示,前缀加0表示八进制数,前缀加0x表示十六进制数 基数数码名称描述代码和书本中的表示举例20 和 1二进制逢二进一,几乎所有的电子计算机内部都使用二进位制,分别为“0”…...

ROS2 工作空间
文章目录 ROS2 工作空间创建工作空间自动安装依赖编译工作空间设置环境变量参考链接 ROS2 工作空间 工作空间可以简单理解为工程目录。 ROS 系统中一个典型的工作空间结构如图所示: dev_ws: 根目录,里面会有四个子目录(子空间&a…...
基于CCS5.5的双音多频(DTMF)信号检测仿真实验(①检测型音频文件②输入生成音频并检测)
DTMF的优点 我们知道,DTMF根本上仍然是频谱分析,基础还是DFT,但DFT通常需要对一整段数据做变换,而DTMF不同,每输入一个采样点就计算一次,更有利于硬件实现。 基于CCS的双音多频(DTMF)信号检测原理 公式详细推导 详细的公式推导在下面这篇博客中已经进行了详细的描述,…...

告别空转!用RT-Thread PM组件给你的IoT设备省电:从投票机制到外设管理的完整指南
告别空转!用RT-Thread PM组件给你的IoT设备省电:从投票机制到外设管理的完整指南 在电池供电的物联网设备开发中,功耗优化往往成为决定产品成败的关键因素。想象一下,一个部署在偏远地区的环境监测节点,如果因为功耗问…...

TlbbGmTool:从数据库小白到《天龙八部》单机版管理大师的蜕变之旅
TlbbGmTool:从数据库小白到《天龙八部》单机版管理大师的蜕变之旅 【免费下载链接】TlbbGmTool 某网络游戏的单机版本GM工具 项目地址: https://gitcode.com/gh_mirrors/tl/TlbbGmTool 你是否曾经面对《天龙八部》单机版数据库的复杂结构感到无从下手&#x…...

2026 流量卡办理全攻略:从下单、激活到售后,新手一遍看懂不踩坑
现在人人都离不开手机流量,不管是日常刷视频、追剧观影,还是备用机上网冲浪,一张划算又正规的通用流量卡,已经成为大众刚需。但很多新手第一次在线办理优惠号卡,普遍一头雾水:分不清流量卡是否正规靠谱、办…...

大模型动态计算:按需推理更高效
一种让大语言模型更智能地思考难题的方法 这项新技术使大语言模型能够根据问题的难度,动态调整用于推理的计算量。 为了使大语言模型在回答较难问题时更加准确,研究人员可以让模型花费更多时间来思考潜在解决方案。但是,赋予大语言模型这种能…...
)
壁纸引擎安卓版(wallpaper engine安卓版免费下载)
wallpaper engine安卓版是Steam上的Wallpaper Engine官方的安卓应用程序。 Wallpaper Engine Android 应用程序是免费的,支持将现有 Wallpaper Engine 壁纸合集无线传输到您的 Android 移动设备。 ————————————————————————————————…...

航模电调XXD2212的“坑”与“宝”:从欠压报警到堵转丢步的实战避坑指南
XXD2212电调实战指南:从欠压保护到电机匹配的深度解析 1. 揭开XXD2212电调的神秘面纱 XXD2212作为航模圈内广为人知的入门级电调,以其极高的性价比吸引了大量无人机和机器人爱好者。这款电调采用新唐科技MS51FB9AE作为主控芯片,搭配六MOS管组…...

BlueArchive-Cursors:开源鼠标主题的技术实现与扩展应用指南
BlueArchive-Cursors:开源鼠标主题的技术实现与扩展应用指南 【免费下载链接】BlueArchive-Cursors Custom mouse cursor theme based on the school RPG Blue Archive. 项目地址: https://gitcode.com/gh_mirrors/bl/BlueArchive-Cursors BlueArchive-Curso…...

从结构设计认识组合梁结构
从结构设计认识组合梁结构 概念:由两种不同材料结合或不同工序结合而成的梁称为组合梁,亦称联合梁。 今天咱们从《钢标》第十四章来认识组合梁,本文只适合不直接承受动力荷载的组合梁结构设计。 (一)基本规定...

HEIF Utility:Windows平台HEIF格式兼容性完整解决方案实战
HEIF Utility:Windows平台HEIF格式兼容性完整解决方案实战 【免费下载链接】HEIF-Utility HEIF Utility - View/Convert Apple HEIF images on Windows. 项目地址: https://gitcode.com/gh_mirrors/he/HEIF-Utility 对于使用iPhone或iPad的Windows用户而言&a…...

BFD与NQA:网络故障检测与性能分析的协同之道
1. BFD与NQA:网络运维的双子星 刚入行做网络运维那会儿,最怕半夜接到告警电话。记得有次凌晨三点,核心交换机突然丢包,传统Ping检测像老牛拉车,等定位到光纤模块故障时,业务已经中断了17分钟。直到后来用上…...