中科院突破:TalkingGaussian技术实现3D人脸动态无失真,高效同步嘴唇运动!
DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
引言:探索高质量3D对话头像的新方法
在数字媒体和虚拟互动领域,高质量的3D对话头像技术正变得日益重要。这种技术能够在虚拟现实、电影制作、视频会议以及各种人机交互场景中找到广泛应用。尽管传统的基于神经辐射场(NeRF)的方法在生成高保真度的3D对话头像方面取得了一定的成功,但这些方法往往面临着成本高昂和面部特征易扭曲的问题。为了解决这些问题,本文提出了一种新的基于3D高斯投影(3DGS)的变形框架——TalkingGaussian,它通过对持久头部结构进行变形来生成对话头像,从而显著提高了面部动作的精确度和图像的整体质量。
论文标题: TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting
机构:
- School of Computer Science and Engineering, State Key Laboratory of Complex & Critical Software Environment, Jiangxi Research Institute, Beihang University
- Institute of Semiconductors, Chinese Academy of Sciences
- School of Information and Communication Technology, Griffith University
- RIKEN AIP
- The University of Tokyo
论文链接: https://arxiv.org/pdf/2404.15264.pdf
项目地址: 未提供
通过引入3DGS和面部-口部解耦技术,TalkingGaussian不仅能够在不牺牲动态表现力的前提下,提供更稳定和准确的头部结构,还能够有效避免传统方法中常见的面部特征扭曲问题。此外,该方法还采用了增量采样策略,优化了变形学习过程,进一步提升了模型的学习效率和生成头像的质量。通过广泛的实验验证,TalkingGaussian在客观评估和人类判断中均优于现有的最先进方法,显示出其在实际应用中的巨大潜力。
3D高斯喷溅技术简介
3D高斯喷溅(3D Gaussian Splatting, 3DGS) 是一种用于表达三维空间信息的技术,通过一组3D高斯原始数据来实现。这些高斯原始数据包括中心位置、缩放因子、旋转四元数、不透明度和颜色特征。在渲染过程中,根据相机模型信息,这些高斯原始数据被用来计算观察视图下的像素颜色。
3DGS的核心优势在于其明确的空间表达和优化策略。通过梯度下降法优化高斯原始数据的参数,结合密集化策略控制原始数据的增长,并剪除不必要的数据,从而实现高效的颜色监督。这种方法继承了颜色监督的优化策略,有效提高了渲染效率和质量。
TalkingGaussian框架详解
TalkingGaussian 是一个基于3DGS的变形驱动的talking head合成框架。该框架的核心思想是通过多个平滑的变形来表达复杂和细粒度的面部动作,简化学习任务,从而提高面部保真度和合成质量。
持久化高斯场(Persistent Gaussian Fields)
持久化高斯场保留了具有规范参数的持久化高斯原始数据。这一模块最初通过静态3DGS初始化,随后与基于网格的运动场(Grid-based Motion Fields)共同进行优化。
基于网格的运动场(Grid-based Motion Fields)
尽管持久化高斯场能有效代表正确的3D头部结构,但由于其完全显式的空间结构,缺乏区域位置编码。考虑到大多数面部动作在区域上是平滑和连续的,我们采用了一个高效且富有表现力的三平面哈希编码器和MLP解码器来构建连续的变形空间。
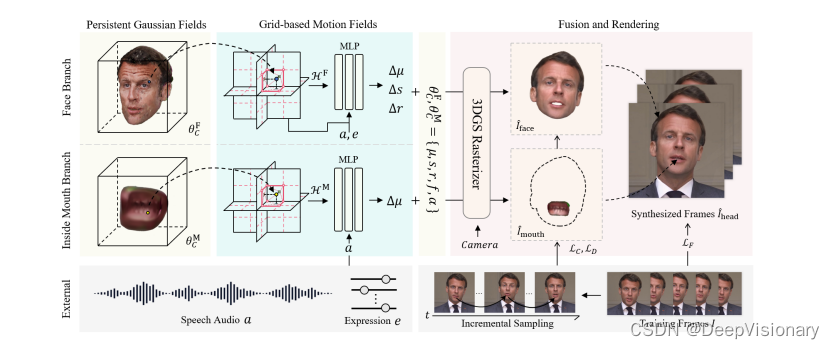
面部-口内分解(Face-Mouth Decomposition)
尽管基于网格的运动场可以预测任意位置的点状变形,但这种表示仍然存在由面部和口内运动不一致引起的粒度问题。为了解决这一问题,我们在3D空间中将这两个区域分解,并构建两个单独的优化分支。
训练细节
我们保留了基本的3DGS优化策略来训练我们的框架。整个过程分为三个阶段,前两个阶段分别应用于两个分支,最后一个阶段用于融合。在动态学习阶段,我们将运动场的预测变形加入训练,并通过3DGS光栅化器渲染输出图像。最后,进行颜色微调阶段,以更好地融合头部和口内分支。
通过这种方法,TalkingGaussian框架能够有效地解决由不准确的外观预测引起的面部扭曲问题,生成高质量、高保真的talking head视频。
面部与口内运动的分解
在TalkingGaussian框架中,我们提出了一个面部与口内运动的分解模块,以解决这两个区域在动态表达时的运动不一致问题。传统的方法中,由于面部和口内区域的运动在空间上非常接近但并不总是同步进行,这种运动的不一致性常常导致在单一的运动场中相互干扰,从而影响了整体的动态表现和静态结构的重建质量。
为了解决这一问题,我们在3D空间中对这两个区域进行了分解,并为每个区域构建了独立的优化分支。具体来说,我们首先使用现成的面部解析模型获取2D空间中的口内区域语义掩模。然后,我们将口内区域的掩膜图像和剩余的表面区域(包括面部、头发和其他头部部分)分别用于训练两个独立的可变形高斯场,作为我们框架的两个分支。
面部分支:面部分支主要负责拟合除口内运动外的所有面部运动。在这个分支中,我们采用了区域注意力机制来促进由音频特征和上半脸表情特征驱动的条件变形的学习。为了完全解耦这两种条件,上半脸表情特征由7个与口部无关的动作单元组成,通过区域注意力机制中的注意力向量与音频和表情特征进行运算,从而计算出每个位置的区域感知特征。
口内分支:口内分支则代表音频驱动的动态口内区域。考虑到口内运动相对简单,并且仅由音频驱动,我们在这个分支中使用了一个轻量级的可变形高斯场。特别地,我们仅预测由音频特征条件化的第i个原始的平移变化。
通过这种面部与口内的分解,我们的方法不仅在动态表现上有了显著提升,也在静态结构的重建质量上得到了改善。最终的合成头像是通过将两个分支渲染的面部和口内图像融合而成。根据物理结构,我们假设口内分支的渲染结果位于面部分支的后面,从而实现了更高保真度的合成效果。
实验设置与基线比较
在我们的实验中,我们收集了四个高清晰度的说话视频剪辑,包括三个男性肖像和一个女性肖像,用于构建视频数据集。这些视频剪辑平均长度约为6500帧,帧率为25 FPS,其中三个(“May”,“Macron”和“Lieu”)被裁剪并调整大小为512×512,一个(“Obama”)调整为450×450。
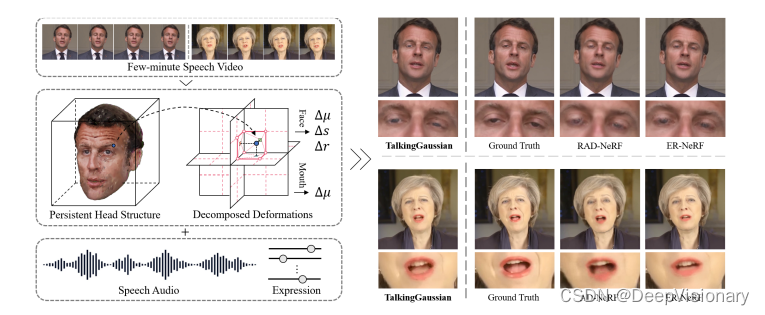
在实验中,我们主要将我们的方法与最相关的NeRF基方法(如AD-NeRF、DFRF、RAD-NeRF、GeneFace和ER-NeRF)进行比较,这些方法通过使用说话视频训练的个人特定辐射场来渲染说话头像。此外,我们还将我们的方法与最先进的2D生成模型(如Wav2Lip、IP-LAP和DINet)进行了比较,这些模型不需要个人特定的训练。
在所有实验中,我们的方法在静态图像质量、动态运动质量和效率方面均表现最佳。特别是在动态质量方面,我们的方法在所有指标上都优于所有NeRF方法。值得注意的是,TalkingGaussian在Sync-C得分方面甚至高于生成方法IP-LAP和DINet,展示了我们方法的强大建模能力。尽管Wav2Lip在Sync-C得分最高,但其在保持个人说话风格方面的不足导致了较差的AUE-L和LMD得分。此外,由于3DGS带来的效率提升,我们的方法在所有基线中达到了最快的训练和推理速度。

定量评估与用户研究
1. 定量评估
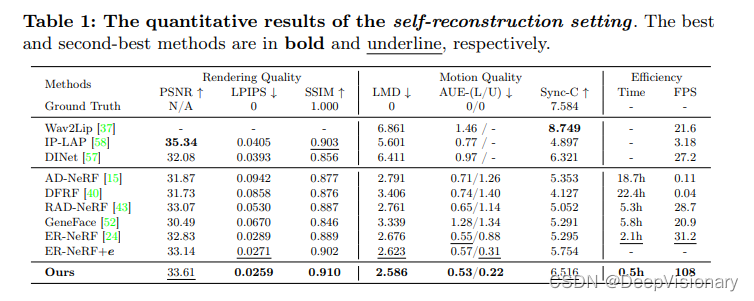
在定量评估方面,我们采用了多种度量标准来评估TalkingGaussian方法在合成高质量、高保真度的3D说话头像方面的表现。这些度量标准包括PSNR、LPIPS和SSIM,用于评估图像质量;以及Sync-C和Sync-D,用于评估唇部同步的准确性。此外,我们还使用了动作单元误差(AUE-U和AUE-L)来分别评估上半脸和嘴部动作的准确性。
在自我重建设置中,TalkingGaussian在所有指标上均表现优异,尤其是在LPIPS和SSIM上,显示出其在细节渲染和结构保真度上的优势。此外,我们的方法在训练和推理速度上也是所有对比方法中最快的,显示了其高效性。
在唇部同步设置中,尽管面临跨性别和跨语言的挑战,TalkingGaussian仍然展示了出色的泛化性能,特别是在处理不同性别的音频输入时,表现出了较高的鲁棒性和适应性。
2. 用户研究
为了更好地评估TalkingGaussian在实际应用中的表现,我们进行了用户研究。在这项研究中,我们邀请了16名参与者对由8种不同方法生成的32个说话头像视频进行评分,从唇同步准确性、视频真实感和图像质量三个方面进行评价。
结果显示,TalkingGaussian在所有三个方面均获得了最高评分,验证了其在生成高质量说话头像视频方面的潜力和实用性。

讨论与未来工作
TalkingGaussian通过采用3D高斯飞溅技术和面部-口内解构模块,成功地解决了以往基于NeRF方法在动态区域产生的面部特征扭曲问题。通过将动态说话头部的表示简化为纯粹的形变,我们的方法不仅提高了面部保真度,还改善了唇部同步的精确度。
尽管我们的方法在多个方面表现优异,但仍存在一些限制和未来的改进方向。例如,尽管增量采样策略提高了优化过程的稳定性,但在3DGS的密集化操作中仍可能偶尔出现噪声原语,这有时会影响图像质量。未来,我们计划引入更多的约束来更好地控制原语的生长。
此外,尽管面部和口内分支通过音频特征进行了对齐,但这种连接在某些跨域情况下可能不够紧密。为了解决这个问题,我们将探索更好的两部分间的感知机制,以增强未来方法的鲁棒性。
总之,TalkingGaussian为高质量的3D说话头像合成提供了一种有效的解决方案,为数字媒体产业的发展提供了新的技术支持。同时,我们也呼吁负责任地使用这项技术,以防止其被用于恶意目的。
结论
本文提出了一种新颖的基于变形的框架——TalkingGaussian,用于高质量的3D说话头部合成。通过维持一个持久的头部结构并采用高斯溅射技术,我们的方法在合成更精确、清晰的说话头部方面超越了以往的方法。通过将面部和口内的动作分解为不同的空间,TalkingGaussian有效地解决了由于快速变化的外观预测不准确而导致的“面部扭曲”问题,实现了在合成真实和准确的说话头部视频方面的卓越性能。
1. 技术优势和应用潜力
TalkingGaussian通过3D高斯溅射(3DGS)技术,保持了头部结构的持久性,并通过变形而非外观修改来表示面部动作,这一策略显著提高了面部细节的准确性和动态表现的自然性。此外,我们的方法在多个基准测试中显示出优越的视觉质量和效率,尤其是在唇部同步和面部保真度方面,均优于当前最先进的方法。
2. 道德考量和使用建议
尽管TalkingGaussian为数字媒体行业的发展提供了强大的技术支持,但我们也必须警惕其潜在的滥用风险。为防止技术被用于制造虚假信息,我们建议在使用此技术时确保所有数据主体的明确同意,并在合成产品中明确披露使用了深度伪造技术。此外,我们将致力于开发深度伪造检测技术,以促进该技术的负责任使用。
3. 限制与未来工作
虽然TalkingGaussian在多个方面表现出色,但仍存在一些限制。例如,3DGS的密集化操作有时可能导致噪声原始图形的随机出现,尽管通过增量采样策略可以在一定程度上缓解这一问题。未来,我们计划引入更多约束来更好地控制原始图形的生长,以及增强面部和口内分支之间的连接,提高模型在跨域输入下的鲁棒性和准确性。
总之,TalkingGaussian框架的提出,不仅推动了3D说话头部合成技术的发展,也为相关领域的研究和应用提供了新的思路和工具。我们期待该技术在未来能够在更广泛的应用场景中展现其价值,同时也呼吁社会各界共同努力,确保新技术的健康发展和负责任的使用。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!
相关文章:
中科院突破:TalkingGaussian技术实现3D人脸动态无失真,高效同步嘴唇运动!
DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息! 引言:探索高质量3D对话头像的新方法 在数字媒体和虚拟互动领域,高质量的3D对话头像技术正变得日益重要。这种技术能够在虚拟现实、电影…...

fastText-文本分类
fastText介绍 fastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点: 1、fastText在保持高精度的情况下加快了训练速度和测试速度 2、fastText不需要预训练好的词向量,fastText会自己训练词向量 3、fastText两个重要的优化:Hierarchical Softmax、N-gr…...

【nodejs 命令行交互神器 - inquirer.js】
需求 大家在开发时,有时需要从命令行读取用户的输入,或者让用户选择。在nodejs中,这个怎么实现? 原生实现 ❌ process.stdin.setEncoding(utf8);process.stdin.on(readable, () > {let chunk;// 使用循环确保我们读取所有的可用输入wh…...
)
Liunx软件包管理(上)
目录 一.前言 二.rpm RPM 包的结构 安装与升级 卸载 查询 验证 信息输出 三.yum Yum 的特点 安装和卸载 查询和信息 仓库管理 维护和调试 常用选项 四.更换镜像源 常用的镜像源 更换镜像源基础操作 一.前言 Linux 的软件包管理是指在 Linux 操作系统中安…...
华为eNSP中型企业局域网网络规划设计(下)
→b站传送门,感谢大佬← →华为eNSP中型企业局域网网络规划设计(上)← →拓扑图传送门,可以自己配置着玩← 配置ospf AR3 [AR3]ospf 1 router-id 3.3.3.3 //出口默认路由 [AR3-ospf-1]default-route-advertise always #area…...
C语言(指针)1
Hi~!这里是奋斗的小羊,很荣幸各位能阅读我的文章,诚请评论指点,关注收藏,欢迎欢迎~~ 💥个人主页:小羊在奋斗 💥所属专栏:C语言 本系列文章为个人学习笔记&#x…...

perl:用 MIDI::Simple 生成midi文件,用 pygame 播放 mid文件
在 csdn.net 下载 strawberry-perl-5.32.1.1-64bit.zip 解压安装在 D:\Strawberry\ 运行 cpan install MIDI::Simple D:\Strawberry\c\bin\gmake.exe test -- OK Running make install for CONKLIN/MIDI-Perl-0.84.tar.gz Installing D:\Strawberry\perl\site\lib\MIDI.pm I…...

数据库-脏读
脏读(Dirty Read)是数据库并发控制中的一个概念,指的是一个事务读取了另一个尚未提交的事务的修改。由于另一个事务的修改可能最终会被撤销(即发生回滚操作),因此,当前事务读取到的数据可能是“…...

react 用合计项
在React中,如果你想要计算一个数组中的所有项目,你可以使用reduce方法。这是一个JavaScript内置的数组方法,它允许你累计数组中的值。 以下是一个简单的React组件示例,它计算一个商品列表中所有商品的总价: import…...

IP 地址追踪工具促进有效的 IP 管理
网络 IP 地址空间的结构、扫描和管理方式因组织的规模和网络需求而异,网络越大,需要管理的 IP 就越多,IP 地址层次结构就越复杂。因此,如果没有 IP 地址管理(IPAM)解决方案,IP 资源过度使用和地…...

快手蓝V商家电话采集软件操作教程
抖音作为全球最受欢迎的短视频平台之一,拥有庞大的用户基础。其中不乏拥有蓝V认证的大V用户,他们的手机号码对于一些市场营销人员来说是非常有价值的。但是,抖音并没有公开这些大V用户的手机号码,怎样采集到他们的手机号码呢&…...

工业机器人应用实践之玻璃涂胶(篇二)
工业机器人 接上篇文章,浅谈一下实践应用,具体以玻璃涂胶为例: 了解工业机器人在玻璃涂胶领域的应用认识工具坐标系的标定方法掌握计时指令的应用掌握人机交互指令的应用掌握等待类指令用法(WaitDI、WaitUnitl 等)认…...

C++ 455. 分发饼干
文章目录 一、题目描述二、参考代码 一、题目描述 示例 1: 输入: g [1,2,3], s [1,1] 输出: 1 解释: 你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。 虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩…...

未来娱乐新地标?气膜球幕影院的多维体验—轻空间
在中国,一座独特的娱乐场所正在崭露头角:气膜球幕影院。这个融合了气膜建筑与激光投影技术的创新场所,不仅令人惊叹,更带来了前所未有的科幻娱乐体验。让我们一起探索这个未来的娱乐空间,感受其中的多维魅力。 现场演出…...

工业机器人应用实践之玻璃涂胶(篇三)
工业机器人 接上篇文章,浅谈一下实践应用,具体以玻璃涂胶为例: 了解工业机器人在玻璃涂胶领域的应用 认识工具坐标系的标定方法 掌握计时指令的应用 掌握人机交互指令的应用 掌握等待类指令用法(WaitDI、WaitUnitl 等࿰…...
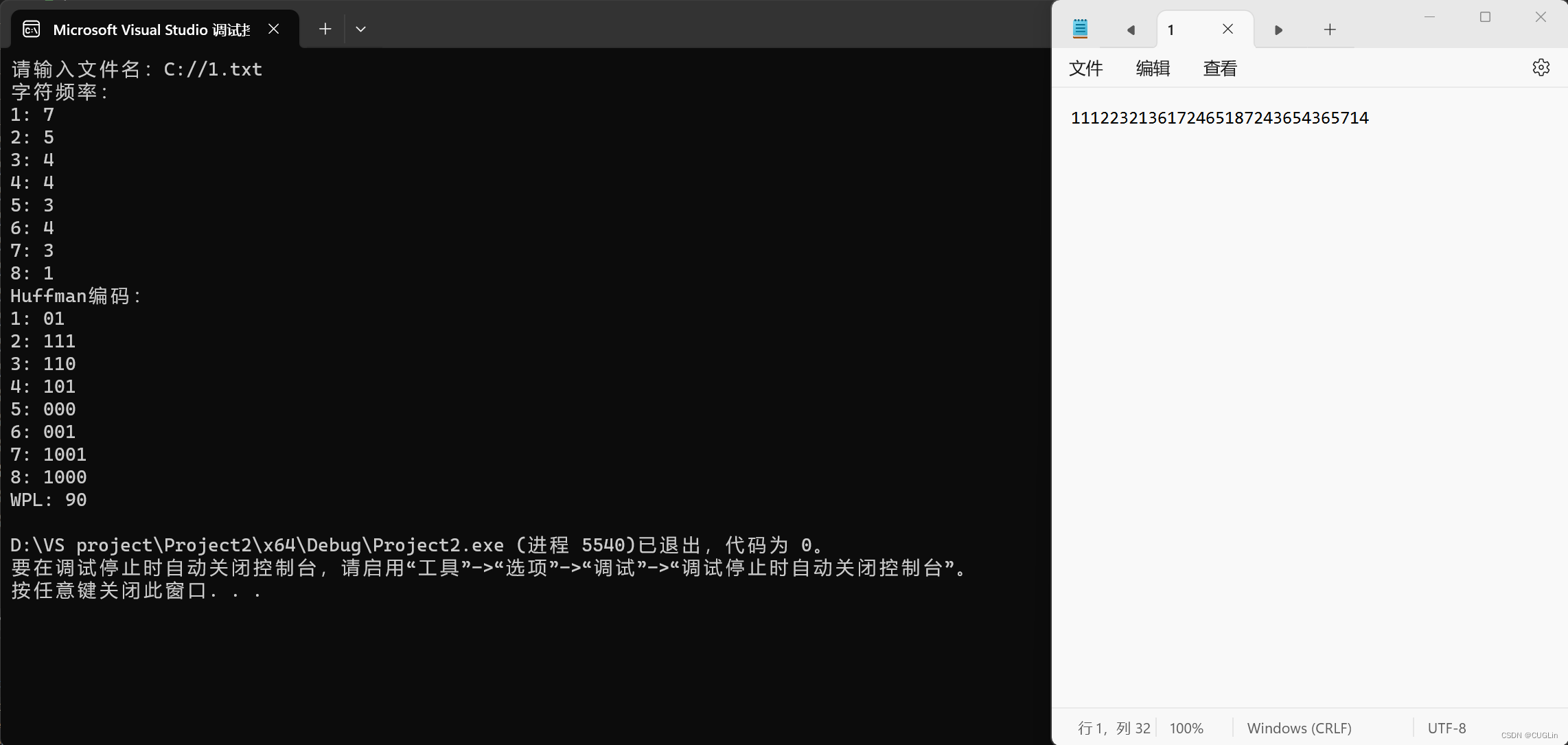
基于Huffman编码的字符串统计及WPL计算
一、问题描述 问题概括: 给定一个字符串或文件,基于Huffman编码方法,实现以下功能: 1.统计每个字符的频率。 2.输出每个字符的Huffman编码。 3.计算并输出WPL(加权路径长度)。 这个问题要求对Huffman编码算…...
scanf报错问题(3种))
处理VS2022中(C/C++)scanf报错问题(3种)
#pragma warning(disable:4996)//第一种:处理scanf在VS2022中报错 #define _CRT_SECURE_NO_WARNINGS//第二种:处理scanf在VS2022中报错 #include<bits/stdc.h> using namespace std; int main() { int a, b; scanf(“%d %d”, &a, &b);//第三种&…...

C#面:Session 喜欢丢值且占内存,Cookis不安全,请问 C# 可以用什么办法代替这两种原始的方法
可以使用 用 ViewState,stateserver。 在 C# 中,ViewState、StateServer 和 Session 都是用于在 Web 应用程序中存储和管理状态信息的机制。它们可以用来在不同的页面之间传递数据或者在同一页面的不同请求之间保持数据的持久性。 ViewState࿱…...

Python并发编程 05 锁、同步条件、信号量、线程队列、生产者消费者模型
文章目录 一、基础概念二、同步锁三、线程死锁和递归锁四、同步条件(event)五、信号量六、线程队列(queue)1、常用方法2、queue模块的三种模式(1)FIFO队列(2)LIFO队列(3&…...

UIKit之UIButton
功能需求: 点击按钮切换按钮的文字和背景图片,同时点击上下左右可以移动图片位置,点击加或减可以放大或缩小图片。 分析: 实现一个UIView的子类即可,该子类包含多个按钮。 实现步骤: 使用OC语言…...

Linux内核工程师面试高频问题解析
1. Linux内核工程师面试核心问题解析作为一名在Linux内核领域摸爬滚打多年的老手,我经历过无数次技术面试的洗礼。今天就把阿里云这类一线大厂在Linux内核工程师岗位上的高频面试题做个系统梳理,并附上我个人的解题思路和实战经验。这些题目看似基础&…...

中小企业SEO推广应该投入多少费用
<h2>中小企业SEO推广应该投入多少费用</h2> <p>在数字化时代,网络已经成为企业推广和销售的重要渠道之一。特别是对于中小企业来说,通过优化搜索引擎(SEO)来提升网站的自然流量,是非常有效且相对经济…...

实战复盘——从日志到后门:一次完整的Linux挖矿病毒kswapd0应急响应
1. 异常告警:CPU占用300%的紧急响应 那天下午3点27分,监控系统突然弹出一条红色告警:某台核心服务器的CPU使用率飙升至300%。作为安全工程师,我立刻放下手中的咖啡,开始排查这个异常情况。这种CPU异常飙升通常只有两种…...

ai赋能开发:让快马平台智能生成mpu6050手势识别代码
最近在做一个基于MPU6050传感器的手势识别项目,发现用传统方式开发效率太低,于是尝试了InsCode(快马)平台的AI辅助开发功能。整个过程让我深刻体会到,AI如何改变硬件开发的效率瓶颈。 数据采集模块的智能生成 当我输入"用Arduino持续读取…...

AMD显卡AI部署实战指南:ROCm模型运行与性能优化
AMD显卡AI部署实战指南:ROCm模型运行与性能优化 【免费下载链接】ollama-for-amd Get up and running with Llama 3, Mistral, Gemma, and other large language models.by adding more amd gpu support. 项目地址: https://gitcode.com/gh_mirrors/ol/ollama-for…...

从GlobeLand30数据到统计报表:QGIS分区统计+Excel,打造你的地表覆盖分析工作流
从GlobeLand30到专业报表:QGISExcel高效地表覆盖分析全流程 地表覆盖数据是理解区域生态环境、规划土地利用的重要基础。GlobeLand30作为30米分辨率的全球地表覆盖数据集,为研究者提供了高精度的分析素材。但如何将这些数据转化为可操作的见解࿱…...
SAP增强开发实战:如何用STARTING NEW TASK避免BAPI_TRANSACTION_COMMIT的坑?
SAP增强开发实战:如何用STARTING NEW TASK避免BAPI_TRANSACTION_COMMIT的坑? 在SAP标准增强开发中,当我们需要在出口函数里调用BAPI修改或创建业务单据时,总会遇到一个经典难题:如何在增强点安全地提交事务?…...
在线获取任意区域DEM高程数据)
告别数据下载烦恼:5分钟用GEE(Google Earth Engine)在线获取任意区域DEM高程数据
告别数据下载烦恼:5分钟用GEE在线获取任意区域DEM高程数据 在科研和工程实践中,数字高程模型(DEM)是地形分析的基础数据。传统获取方式往往需要经历数据搜索、分幅下载、格式转换、多图拼接等一系列繁琐步骤,对于非GI…...

faster-whisper-GUI架构设计与性能优化:构建高效语音识别工作流的技术实践
faster-whisper-GUI架构设计与性能优化:构建高效语音识别工作流的技术实践 【免费下载链接】faster-whisper-GUI faster_whisper GUI with PySide6 项目地址: https://gitcode.com/gh_mirrors/fa/faster-whisper-GUI 在语音识别技术快速发展的今天࿰…...

ClickHouse配置优化实战:关键参数详解与性能调优指南
1. ClickHouse配置优化的核心逻辑 ClickHouse作为一款高性能的OLAP数据库,其配置优化需要遵循三个黄金法则:资源隔离、瓶颈定位和场景适配。我见过太多团队一上来就盲目调整参数,结果反而导致性能下降。正确的做法应该是先理解系统行为&#…...