【大数据·Hadoop】从词频统计由浅入深介绍MapReduce分布式计算的设计思想和原理
一、引入:词频统计问题
假如我们有一亿份文档,需要统计这一亿份文档的词频。我们会怎么做,有以下思路
- 使用单台PC执行:能不能存的下不说,串行计算,一份一份文档读,然后进行词频统计,需要运行很长时间
- 多台PC:把文档分布到多台PC上处理,每个PC处理一部分文件,最后合并。——听起来很简单,但是实际实现的话还是有很多问题的。
对于第二种方法,有以下几种方法,我们来分别分析一下:

可以看到,我们把数据分布到多台主机上,然后让每台主机并行扫描文档,将读取到的单词发送给一台中央主机,由中央主机统一进行词频统计。
这样有哪些问题:
- 小粒度通信->网络通信瓶颈:所有子PC分别将一个个单词(超级无敌多)通过网络同时发送 给一台中央主机, 必定造成网络IO通信堵塞
- 中央主机的负载过重: 虽然数据分布到了多台子PC上进行扫描读取处理,的确和之前的单台PC相比(一个一个文档依次往后读)能节约时间,但是处理时间其实还是差不多的。
- 缺乏容错机制: 在这种单中央主机的设计思想下,一旦子PC中有一台出错,必定导致整个结果错误。
- 数据一致性和同步问题: 你想一想,像上图,多个子PC同时对比如
dog这个单词进行写入,这是一个并发操作,必须要加锁保证数据一致性。 - 扩展性问题: 随着数据量的增加,中央主机处理的数据量和计算负载也会线性增长,最终可能超过中央主机的处理能力。扩展系统可能需要更换更强大的中央主机,这不仅成本高昂,而且存在物理限制。
OK,我们先别一下子跳到MapReduce,看看基于上面这个方法我们还能怎么改进:
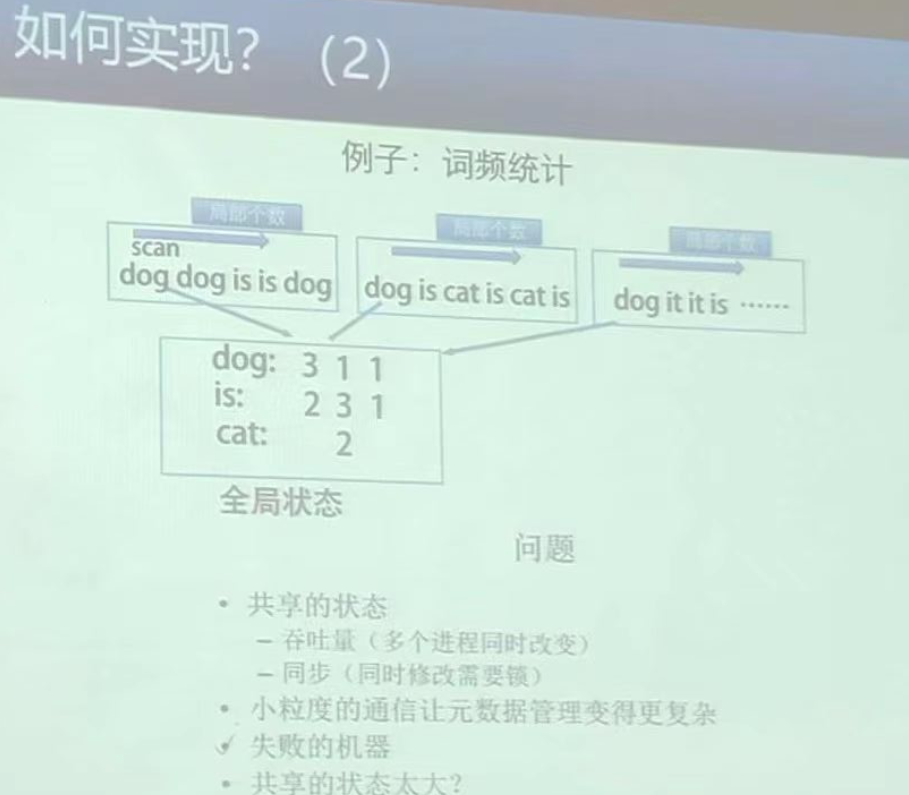
其实说实话这个基本上没啥改善,就是改了一下单台PC自己在发送词频之前先做了个预处理统计,这样能够稍微渐缓一下网络IO,但是其实还是没啥用。
那么还有什么其他可以改善的地方的吗?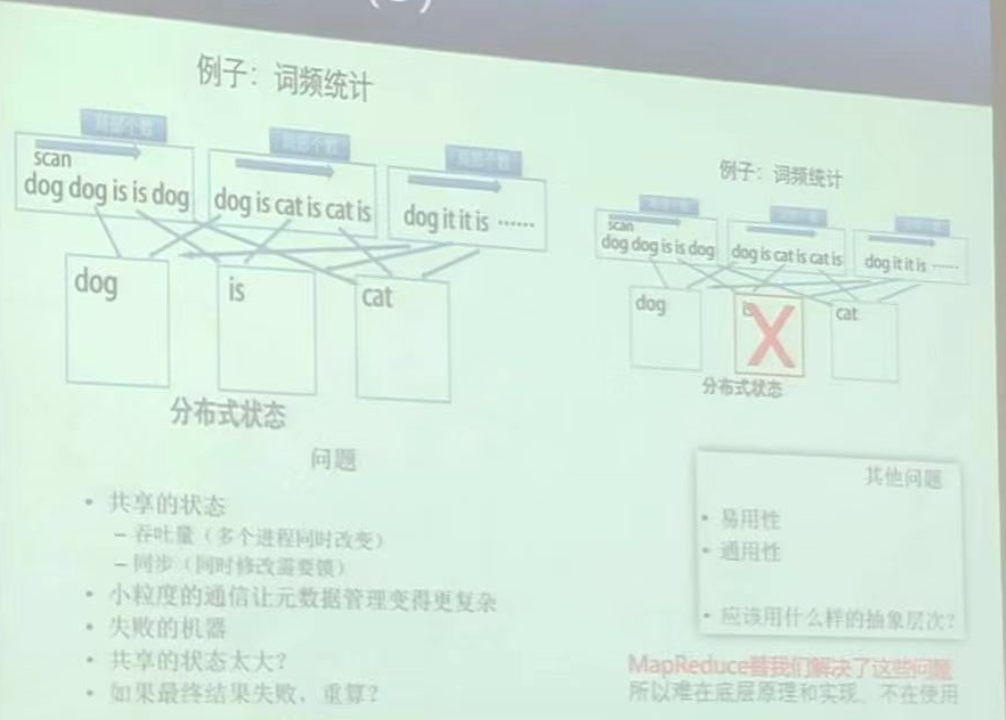
没错,上面不是说主机压力太大了吗?那么我们现在一个主机就处理一个单词,这样OK了把?其实还是有问题的,或者说带来了新的问题:
- 网络通信问题:这样一个个单词发,或者统计好了(也就是先做计算嘛)(其实很多时候不能先做计算,比如算整体学生的最大成绩差)再发,还是通信粒度太小了
- 负载不均衡:一些常见的单词(如“the”、“is”等)可能会导致某些主机负载过重,而其他主机负载轻松。
- 扩展性问题: 你看,我现在统计单词,那我统计汉字呢?计算主机的数量是不是需要改变??可扩展性还是很差的
其实在实现上还有很多细节问题:
- 数据怎么分呢?人工?手动分割数据并分配给多台机器处理,这个过程不仅繁琐而且难以管理和扩展。
- 开发者需要手动管理数据的分发、任务的执行、结果的汇总以及故障的处理等,这不仅增加了编程的复杂性,也增加了出错的几率。
- 处理分布式数据需要开发者对分布式系统的底层细节有深入的了解,如数据分布、通信机制、容错机制等
下面我们来看看MapReduce的思想,看看它是如何解决了这些问题,在这之中也可以看到:数据结构、算法、数学等知识的融合。
二、MapReduce介绍
2.1:设计思想
MapReduce的算法核心思想是: 分治
学过算法的同学应该会学到分治算法,所谓分治,就是把原问题分解为规模更小的问题,进行处理,最后将这些子问题的结果合并,就可以得到原问题的解。MapReduce这种分布式计算框架的核心就是:分治。
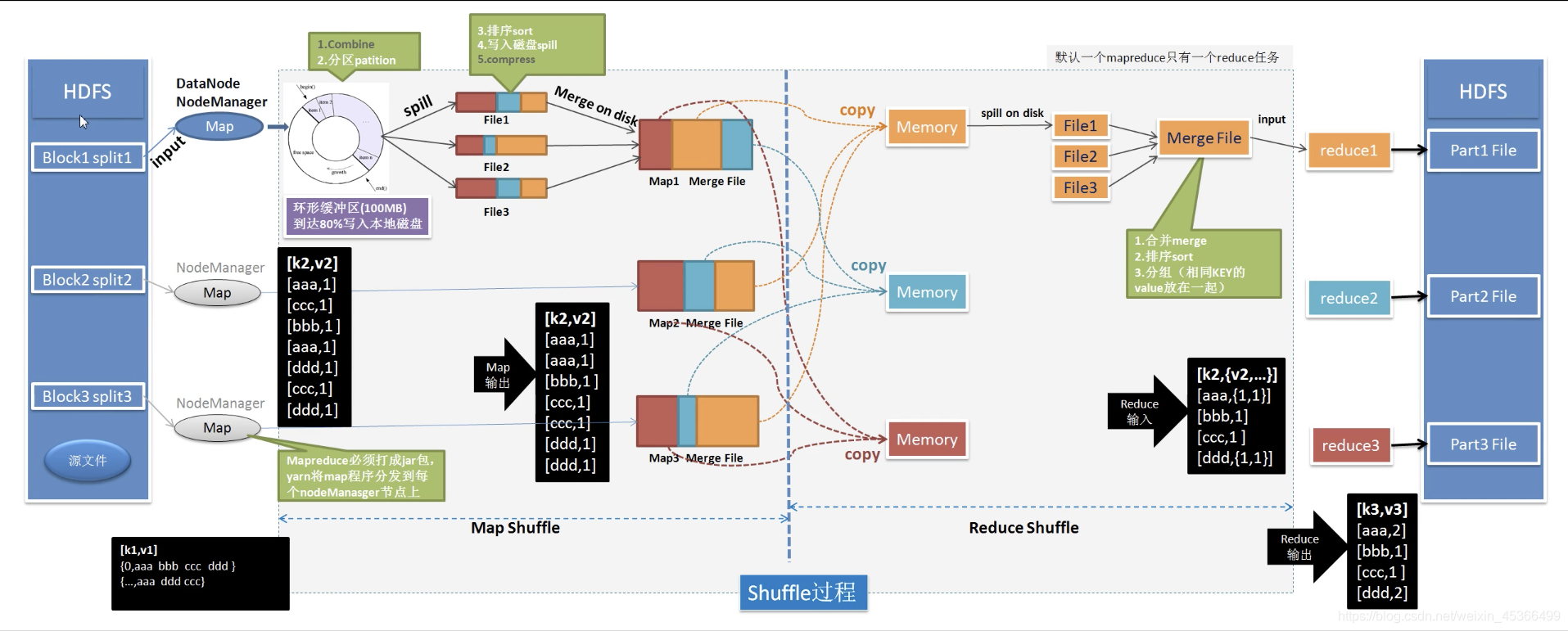
上图是MapReduce的处理流程图,可以看到,MapReduce的整个过程主要分为:
-
Map:
- 输入:来自存储在hdfs上的文件block进行分块(split)后,并且进行读取数据处理的分块数据的键值对(key-value)形式。—— 输入数据被分成一系列的数据块,被称为“input splits”。MapReduce框架尽量保持每个split的大小相同,这样每个Map任务处理的数据量就大致相等。这是负载均衡的第一步。
- 输出:进行扫描后的(单词,词频)的键值对形式
- 分析:Map任务通常在存储相应数据分片的节点上执行,这样可以减少网络传输。如果某些节点因为硬件性能好或者当前负载轻而完成任务更快,MapReduce可以把新的Map任务分配给这些节点,从而提高资源的利用率。MapReduce框架会自动管理数据的分片和分发,无需用户手动干预,从而提高数据分发效率。
-
Shuffle与Sort阶段
- 处理完数据后,Map任务的输出会进入Shuffle阶段。在这个阶段,框架负责将所有Map任务输出的键值对根据键进行排序和分组(还有combine,根据项目需要可选,减少网络io)。只有排序和分组后的数据会被发送到Reduce任务,这减少了网络传输的数据量,从而缓解网络通信瓶颈,同时,由于
shuffle阶段对所有的Map任务进行了排序和分组,也就是说,一组数据只分发给一个reduce,这样也不会来自多个map对同一个reduce同时写入的并发,即消除了并发风险,保证了数据一致性。
- 处理完数据后,Map任务的输出会进入Shuffle阶段。在这个阶段,框架负责将所有Map任务输出的键值对根据键进行排序和分组(还有combine,根据项目需要可选,减少网络io)。只有排序和分组后的数据会被发送到Reduce任务,这减少了网络传输的数据量,从而缓解网络通信瓶颈,同时,由于
-
Reduce任务的智能分配
- Reduce任务是根据Map阶段的输出键值对自动分配(默认是哈希,可以手写更优的分配算法)的。MapReduce尝试均匀地分配负载,确保每个Reduce任务处理相似数量的键值对。如果某个Reduce任务处理得更快,它可以接受更多的数据,从而实现动态的负载均衡。
从上面这个处理流程可以看出,MapReduce还有很多其他优点:
- 容错机制(解决容错和恢复机制问题)
MapReduce具备强大的容错机制。如果一个Map或Reduce任务失败,框架会自动在另一个节点上重新调度这个任务。此外,中间数据会被写入磁盘,这允许在节点故障后从最后一个检查点恢复,而不是从头开始。 - 水平扩展(解决扩展性问题)
MapReduce支持水平扩展。当数据量增加时,可以简单地增加更多的节点到集群中。MapReduce框架会自动利用这些新节点,无需对现有的应用程序做任何修改,这使得扩展性得到了极大的提高。
2.2:设计理念:移动计算而非移动数据
其实在开篇讲到的三种分布式计算统计词频的方法中,它们的想法核心都是移动数据,把数据移动到中央主机进行计算,这样带来很明显的问题:网络IO,带宽。
而MapReduce, 它将计算任务(Map和Reduce操作)分布到存储实际数据的节点上,这样就可以在数据存储的地方直接进行计算。这种方法减少了大量数据在网络中的移动,因为只有中间结果和最终结果需要在节点之间传输,这些比原始数据小得多。
这种做法不仅提高了网络传输的效率,也增强了系统的容错性。因为MapReduce框架会将Map任务的输出写入磁盘(中间结果),在发生故障时,可以从这些已经写入磁盘的中间结果恢复,而不需要从头开始处理数据。这意味着即使在节点失败的情况下,作业的执行仍然可以继续,从而保证了计算的连续性和完整性。
总结来说,MapReduce通过**“移动计算而非移动数据”**的设计理念,有效地解决了传统分布式计算方法中的网络效率和容错性问题。
相关文章:
【大数据·Hadoop】从词频统计由浅入深介绍MapReduce分布式计算的设计思想和原理
一、引入:词频统计问题 假如我们有一亿份文档,需要统计这一亿份文档的词频。我们会怎么做,有以下思路 使用单台PC执行:能不能存的下不说,串行计算,一份一份文档读,然后进行词频统计࿰…...
win10建立共享文件夹和ipad共享文件
win10端设置 查看自己的局域网IP 在任意地方新建一个文件夹 打开文件夹的属性,点到共享的地方 点击高级共享 然后点击应用,确认 再回到之前哪个地方,点击共享 把Everyone的权限改为读取/写入 最后点击共享就欧克了 失败的可能原因 ipad端设置 然后回出现一个要输入用户名和…...
手机在网状态多方面重要性
手机在网状态的重要性体现在多个方面,它是现代社会中人们保持联系、获取信息以及进行日常活动不可或缺的一部分。以下是一些关于手机在网状态重要性的详细解释: 通信联系: 手机是在现代社会中进行通信联系的主要工具。当手机处于在网状态时&…...

Multitouch for Mac:手势自定义,提升工作效率
Multitouch for Mac作为一款触控板手势增强软件,其核心功能在于手势的自定义和与Mac系统的深度整合。通过Multitouch,用户可以轻松设置各种手势,如三指轻点、四指左右滑动等,来执行常见的任务,如打开应用、切换窗口、滚…...
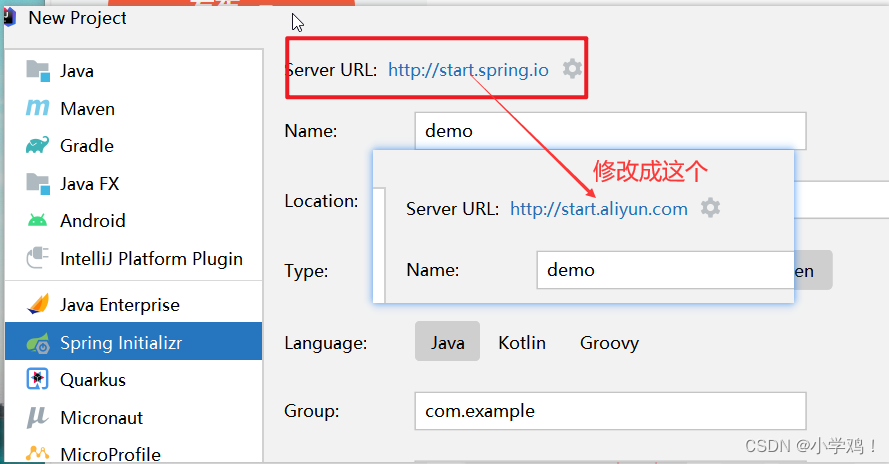
IDEA创建springboot项目时不能选择java 8或者java 11等等版本的问题,解决方案
文章目录 1. Project JDK 和 Java 的区别2. 没有 java 8 或 java 11 等版本2.1 方案一2.2 方案二2.3 方案三 1. Project JDK 和 Java 的区别 我们在利用 idea 创建 spring boot 项目时,会有以上两个选项,这两个选项有什么区别? 答ÿ…...
SpringCloudAlibaba:4.3云原生网关higress的JWT 认证
概述 简介 JWT是一种用于双方之间传递安全信息的简洁的、URL安全的声明规范。 定义了一种简洁的,自包含的方法用于通信双方之间以Json对象的形式安全的传递信息,特别适用于分布式站点的单点登录(SSO)场景 session认证的缺点 1.安…...

【机器学习】Reinforcement Learning-强化学习基本概念
1、Q值与V值 1.1 Q值和V值的定义 Q值:也称为动作价值函数,评估动作的价值,它代表了智能体选择这个动作后,一直到最终状态奖励总和的期望,表示为Q(s, a),其中 s是状态,a是动作。 V值ÿ…...
vim编辑器介绍?)
vim编辑器---(1)vim编辑器介绍?
(1)vim编辑器介绍? 1 目录 (a)IC简介 (b)vim简介 (c)Verilog简介 (d)vim编辑器介绍? (e)结束 1 IC简介…...

解密 Unix 中的 “rc“ 后缀:自定义你的工作环境
在文件名中,rc 通常表示 “run commands”(运行命令)或者 “runtime configuration”(运行时配置)。这种命名惯例源自早期的 Unix 系统,用于指示这些文件包含了一系列要在程序运行时执行的命令或配置选项。…...
)
Java使用csv导出多字段大数据文件(无需写实体映射,自动遍历)
csv工具类CsvUtils 此处使用LinkedHashMap链表哈希表,实现键值中值为空时仍存在数据以及保证顺序与sql顺序一致。 package com.xxx.xxx.utils;import lombok.val; import org.springframework.util.CollectionUtils; import javax.servlet.http.HttpServletRespons…...

Redis 本机无法访问
问题 我在服务器上有两个 Redis 实例,服务端口号分别是 6379 和 6380,Redis 服务器地址假设为 10.0.0.12。其中 6379 这个实例不需要密码即可访问,6380 需要密码访问。 在正常使用几天后,本机突然无法访问 6379 这个实例&#x…...

【论文笔记】Training language models to follow instructions with human feedback B部分
Training language models to follow instructions with human feedback B 部分 回顾一下第一代 GPT-1 : 设计思路是 “海量无标记文本进行无监督预训练少量有标签文本有监督微调” 范式;模型架构是基于 Transformer 的叠加解码器(掩码自注意…...

stm32——OLED篇
技术笔记! 一、OLED显示屏介绍(了解) 1. OLED显示屏简介 二、OLED驱动原理(熟悉) 1. 驱动OLED驱动芯片的步骤 2. SSD1306工作时序 三、OLED驱动芯片简介(掌握) 1. 常用SSD1306指令 2. …...

重卡生产流程的可视化管理与优化
重卡车间可视化是一个将车间内部生产流程、设备状态及人员配置直观展现的技术手段,确保制造过程的每个环节都在最优状态下运行。 在重卡制造领域,从底盘组装、车身焊接、涂装到最终的总装和检验,每一个工作过程都至关重要,对于保…...

软考-软件工程
软件工程概述 软件工程指的是应用计算机科学、数学及管理科学等原理,以工程化的原则和方法来解决软件 问题的工程,目的是提高软件生产率、提高软件质量、降低软件成本。 概述: 软件开发模型:指导软件开发的体系 需求分析确定软件…...

Agent AI智能体:未来社会的角色、发展路径与挑战
目录 引言 一、Agent AI智能体的发展路径 1. 技术进步与智能化水平提升 2. 应用场景拓展与普及 二、Agent AI智能体在未来社会中的角色 1. 提高生产效率与生活品质 2. 促进社会进步与发展 三、Agent AI智能体可能带来的挑战 1. 隐私与安全问题 2. 就业与社会结构变革 …...

Vue 3.x组件生命周期
一、Vue 2 VS Vue 3 从 Vue 2 升级到 Vue 3 ,在保留对 Vue 2 的生命周期支持的同时,Vue 3 也带来了一定的调整。Vue 2 的生命周期写法名称是 Options API (选项式 API ), Vue 3 新的生命周期写法名称是 Composition API (组合式 API )。 Vue 3 组件默认支持 Options A…...
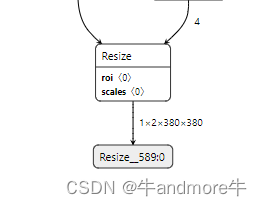
onnx模型截取部分
这个是有需求的,比如有多个输入节点,我只用其中几个,或有多个输出节点,我只用其中几个。 比如这个输入,我们可以直接把transpose去掉,用类pytorch的N,C,H,W的格式输入。 还有如下输出: tran…...
中职智慧校园建设内容规划
1. 渠道先行 1) IT根底设施渠道是支撑智慧学校使用体系所必需的运转环境,是首要需求建造的内容,但是要遵从有用准则,IT设备开展很快,更新很快,不要片面追求全而新; 2) 使用根底渠道是支撑智慧学校使用体系作…...
)
GitLab CI/CD的原理及应用详解(一)
本系列文章简介: 在当今快速变化的软件开发环境中,持续集成(Continuous Integration, CI)和持续交付(Continuous Delivery, CD)已经成为提高软件开发效率、确保代码质量以及快速响应市场需求的重要手段。Gi…...

Cat-Catch浏览器资源嗅探扩展深度解析:高性能流媒体捕获架构揭秘
Cat-Catch浏览器资源嗅探扩展深度解析:高性能流媒体捕获架构揭秘 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch Cat-Catch作为一款专业…...

2026年多Agent协作实战:用CrewAI搭建5角色AI开发团队
前言上一篇我们学习了MCP协议,掌握了AI与工具交互的标准化方法。本文将更进一步,探讨如何让多个AI Agent协同工作——就像组建一个AI开发团队,每个Agent负责不同的角色,通过协作完成复杂任务。—## 一、为什么需要多Agent协作&…...

CARTGen-IR: Synthetic Tabular Data Generation for Imbalanced Regression——基于CART的表格数据不平衡回归合成采样方法
一、研究问题与背景 1.1 问题定义 不平衡回归:在连续目标变量中,极端值(高值或低值)样本稀少,导致模型偏向预测平均值,忽略重要极端情况。 应用场景:极端天气预测、海面温度异常、药物敏感性检…...

告别重启!3DSlicer 5.6.0 下 Python Extension 热重载调试指南
告别重启!3DSlicer 5.6.0 下 Python Extension 热重载调试指南 在3DSlicer的Python扩展开发中,最令人沮丧的莫过于每次修改代码后都需要重启整个应用才能看到效果。这种开发模式不仅效率低下,还会打断开发者的思路。本文将深入探讨如何在3DSl…...

Excel MCP Server 完整部署指南:无需安装Excel的自动化数据处理解决方案
Excel MCP Server 完整部署指南:无需安装Excel的自动化数据处理解决方案 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server Excel MCP Server…...

华为昇腾Atlas200边缘设备开箱即用指南:从CANN环境到YOLOv8模型部署的保姆级避坑教程
华为昇腾Atlas200边缘设备实战:YOLOv8模型部署全流程避坑指南 第一次拿到华为昇腾Atlas200边缘计算设备时,那种既兴奋又忐忑的心情记忆犹新。作为一款专为AI推理设计的边缘设备,Atlas200凭借其强大的算力和紧凑的体型,在智能安防…...

论Serverless 架构模式
serverless架构随着云计算技术的迭代与微服务架构的普及,企业对 IT 系统的弹性伸缩、成本优化及运维效率提出了更高要求 —— 既需快速响应业务峰值需求,又需降低闲置资源消耗,同时减少基础设施运维负担。Serverless 架构模式(无服…...

中间件简单题目教学
题目1:环境搭建与简单模式使用 Docker 启动 RabbitMQ 4.x 容器,用户 guest,密码 123456,映射管理端口 15672。编写 Java 原生生产者,向队列 test_queue 发送消息 "Hello Exam"。编写 Java 原生消费者&#x…...

北光恒电:安捷伦6812B/6813B电源不开机、输出不正常故障排查
安捷伦6812B/6813B电源作为高精度交流电源/功率分析仪,广泛应用于电源测试、UPS测试、航空电子ATE等场景,凭借稳定性能成为实验室和生产线上的核心设备。长期使用或操作不当,不开机、输出不正常等故障频发,影响测试效率。常见故障…...

拒绝“拍脑袋“备货:武汉丝路云如何利用Flink实时计算打造跨境供应链的“数据大脑“?
前言 在之前的文章中(如《揭秘跨境供应链的高并发架构》),我们探讨了如何通过微服务架构保证系统在"黑五"大促时不崩溃。但很多客户反馈了一个更深层的问题: "系统确实不崩了,但库存还是积压。要么备货…...