NLP(14)--文本匹配任务
前言
仅记录学习过程,有问题欢迎讨论
* 1. 输入问题
* 2. 匹配问题库(基础资源,FAQ)
* 3. 返回答案
文本匹配算法:
-
编辑距离算法(缺点)
- 字符之间没有语义相似度;
受无关词/停用词影响大;
受语序影响大
- 字符之间没有语义相似度;
-
Jaccard相似度(元素的交集/元素的并集)、
-
词向量(基于窗口;解决了语义相似的问题;文本转为数字,计算cos值来判断相似度)
-
深度学习-表示型(问题匹配问题比较合适,因为二者都是问题,所以转向量也方便)
两个话使用同一个Encoder向量 语义相似的score = 1,类似二分类- (Triplet Loss):
使得相同标签的样本再Embedding空间尽量接近(anchor和positive接近 away negative) - loss = max((D(p,a)-D(p,n)+margin,0)
- 优点:训练好的模型可以对知识库内的问题计算向量,在实际查找过程中,只对输入文本做一次向量化
- 缺点:在向量化的过程中不知道文本重点
- (Triplet Loss):
-
深度学习-交互型
- 输入一句话,但是两个样本拼接,利用attention机制来判断是否匹配(Q&A拼接去学习)
- 优点:通过对比把握句子重点
- 缺点:每次计算需要都需要两个输入
-
对比学习
- 输入一个样本,通过函数把样本改动,但还是相似,得到两个相似样本,进行bertEconder,pooling操作
-
海量向量查找:
- 可以用开源写好的库^^ Faiss Pinecore
- 避免遍历,避免和所有向量做距离计算(空间切割KD树,Kmeans方式切割)
代码
实现一个智能问答demo
"""
配置参数信息
"""
Config = {"model_path": "./output/","model_name": "model.pt","schema_path": r"D:\NLP\video\第八周\week8 文本匹配问题\data\schema.json","train_data_path": r"D:\NLP\video\第八周\week8 文本匹配问题\data\data.json","valid_data_path": r"D:\NLP\video\第八周\week8 文本匹配问题\data\valid.json","vocab_path": r"D:\NLP\video\第七周\data\vocab.txt","model_type": "rnn",# 正样本比例"positive_sample_rate": 0.5,"use_bert": False,# 文本向量大小"char_dim": 32,# 文本长度"max_len": 20,# 词向量大小"hidden_size": 128,# 训练 轮数"epoch_size": 15,# 批量大小"batch_size": 32,# 训练集大小"simple_size": 300,# 学习率"lr": 1e-3,# dropout"dropout": 0.5,# 优化器"optimizer": "adam",# 卷积核"kernel_size": 3,# 最大池 or 平均池"pooling_style": "max",# 模型层数"num_layers": 2,"bert_model_path": r"D:\NLP\video\第六周\bert-base-chinese",# 输出层大小"output_size": 2,# 随机数种子"seed": 987
}load.py j加载数据文件
"""
数据加载
"""
import json
from collections import defaultdict
import randomimport torch
import torch.utils.data as Data
from torch.utils.data import DataLoader
from transformers import BertTokenizer# 获取字表集
def load_vocab(path):vocab = {}with open(path, 'r', encoding='utf-8') as f:for index, line in enumerate(f):word = line.strip()# 0留给padding位置,所以从1开始vocab[word] = index + 1vocab['unk'] = len(vocab) + 1return vocab# 数据预处理 裁剪or填充
def padding(input_ids, length):if len(input_ids) >= length:return input_ids[:length]else:padded_input_ids = input_ids + [0] * (length - len(input_ids))return padded_input_ids# 文本预处理
# 转化为向量
def sentence_to_index(text, length, vocab):input_ids = []for char in text:input_ids.append(vocab.get(char, vocab['unk']))# 填充or裁剪input_ids = padding(input_ids, length)return input_idsclass DataGenerator:def __init__(self, data_path, config):# 加载json数据self.load_know_base(config["train_data_path"])# 加载schema 相当于答案集self.schema = self.load_schema(config["schema_path"])self.data_path = data_pathself.config = configif self.config["model_type"] == "bert":self.tokenizer = BertTokenizer.from_pretrained(config["bert_model_path"])self.vocab = load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.train_flag = Noneself.load_data()def __len__(self):if self.train_flag:return self.config["simple_size"]else:return len(self.data)# 这里需要返回随机的样本def __getitem__(self, idx):if self.train_flag:# return self.random_train_sample() # 随机生成一个训练样本# triplet loss:return self.random_train_sample_for_triplet_loss()else:return self.data[idx]# 针对获取的文本 load_know_base = {target : [questions]} 做处理# 传入两个样本 正样本为相同target数据 负样本为不同target数据# 训练集和验证集不一致def load_data(self):self.train_flag = self.config["train_flag"]dataset_x = []dataset_y = []self.knwb = defaultdict(list)if self.train_flag:for target, questions in self.target_to_questions.items():for question in questions:input_id = sentence_to_index(question, self.config["max_len"], self.vocab)input_id = torch.LongTensor(input_id)# self.schema[target] 下标 把每个question转化为向量append放入一个target下self.knwb[self.schema[target]].append(input_id)else:with open(self.data_path, encoding="utf8") as f:for line in f:line = json.loads(line)assert isinstance(line, list)question, target = lineinput_id = sentence_to_index(question, self.config["max_len"], self.vocab)# input_id = torch.LongTensor(input_id)label_index = torch.LongTensor([self.schema[target]])# self.data.append([input_id, label_index])dataset_x.append(input_id)dataset_y.append(label_index)self.data = Data.TensorDataset(torch.tensor(dataset_x), torch.tensor(dataset_y))return# 加载知识库def load_know_base(self, know_base_path):self.target_to_questions = {}with open(know_base_path, encoding="utf8") as f:for index, line in enumerate(f):content = json.loads(line)questions = content["questions"]target = content["target"]self.target_to_questions[target] = questionsreturn# 加载schema 相当于答案集def load_schema(self, param):with open(param, encoding="utf8") as f:return json.loads(f.read())# 训练集随机生成一个样本# 依照一定概率生成负样本或正样本# 负样本从随机两个不同的标准问题中各随机选取一个# 正样本从随机一个标准问题中随机选取两个def random_train_sample(self):target = random.choice(list(self.knwb.keys()))# 随机正样本:# 随机正样本if random.random() <= self.config["positive_sample_rate"]:if len(self.knwb[target]) <= 1:return self.random_train_sample()else:question1 = random.choice(self.knwb[target])question2 = random.choice(self.knwb[target])# 一组# dataset_x.append([question1, question2])# # 二分类任务 同一组的question target = 1# dataset_y.append([1])return [question1, question2, torch.LongTensor([1])]else:# 随机负样本:p, n = random.sample(list(self.knwb.keys()), 2)question1 = random.choice(self.knwb[p])question2 = random.choice(self.knwb[n])# dataset_x.append([question1, question2])# dataset_y.append([-1])return [question1, question2, torch.LongTensor([-1])]# triplet_loss随机生成3个样本 锚样本A, 正样本P, 负样本Ndef random_train_sample_for_triplet_loss(self):target = random.choice(list(self.knwb.keys()))# question1锚样本 question2为同一个target下的正样本 question3 为其他target下样本question1 = random.choice(self.knwb[target])question2 = random.choice(self.knwb[target])question3 = random.choice(self.knwb[random.choice(list(self.knwb.keys()))])return [question1, question2, question3]# 用torch自带的DataLoader类封装数据
def load_data_batch(data_path, config, shuffle=True):dg = DataGenerator(data_path, config)if config["train_flag"]:dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)else:dl = DataLoader(dg.data, batch_size=config["batch_size"], shuffle=shuffle)return dlif __name__ == '__main__':from config import ConfigConfig["train_flag"] = True# dg = DataGenerator(Config["train_data_path"], Config)dataset = load_data_batch(Config["train_data_path"], Config)# print(len(dg))# print(dg[0])for index, dataset in enumerate(dataset):input_id1, input_id2, input_id3 = datasetprint(input_id1)print(input_id2)print(input_id3)main.py 主方法
import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer, SiameseNetwork
from loader import load_data_batch
from evaluate import Evaluator# [DEBUG, INFO, WARNING, ERROR, CRITICAL]logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型训练主程序
"""
# 通过设置随机种子来复现上一次的结果(避免随机性)
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)def main(config):# 保存模型的目录if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])# 加载数据dataset = load_data_batch(config["train_data_path"], config)# 加载模型model = SiameseNetwork(config)# 是否使用gpuif torch.cuda.is_available():logger.info("gpu可以使用,迁移模型至gpu")model.cuda()# 选择优化器optim = choose_optimizer(config, model)# 加载效果测试类evaluator = Evaluator(config, model, logger)for epoch in range(config["epoch_size"]):epoch += 1logger.info("epoch %d begin" % epoch)epoch_loss = []# 训练模型model.train()for batch_data in dataset:if torch.cuda.is_available():batch_data = [d.cuda() for d in batch_data]# x, y = dataiter# 反向传播optim.zero_grad()s1, s2, s3 = batch_data # 输入变化时这里需要修改,比如多输入,多输出的情况# 计算梯度loss = model(s1, s2, s3)# 梯度更新loss.backward()# 优化器更新模型optim.step()# 记录损失epoch_loss.append(loss.item())logger.info("epoch average loss: %f" % np.mean(epoch_loss))# 测试模型效果acc = evaluator.eval(epoch)# 可以用model_type model_path epoch 三个参数来保存模型model_path = os.path.join(config["model_path"], "epoch_%d_%s.pth" % (epoch, config["model_type"]))torch.save(model.state_dict(), model_path) # 保存模型权重returnif __name__ == "__main__":from config import ConfigConfig["train_flag"] = Truemain(Config)# for model in ["cnn"]:# Config["model_type"] = model# print("最后一轮准确率:", main(Config), "当前配置:", Config["model_type"])# 对比所有模型# 中间日志可以关掉,避免输出过多信息# 超参数的网格搜索# for model in ["gated_cnn"]:# Config["model_type"] = model# for lr in [1e-3, 1e-4]:# Config["learning_rate"] = lr# for hidden_size in [128]:# Config["hidden_size"] = hidden_size# for batch_size in [64, 128]:# Config["batch_size"] = batch_size# for pooling_style in ["avg"]:# Config["pooling_style"] = pooling_style# 可以把输出放入文件中 便于查看# print("最后一轮准确率:", main(Config), "当前配置:", Config)evaluate.py 评估模型文件
"""
模型效果测试
"""
import torch
from loader import load_data_batchclass Evaluator:def __init__(self, config, model, logger):self.config = configself.model = modelself.logger = logger# 选择验证集合config['train_flag'] = Falseself.valid_data = load_data_batch(config["valid_data_path"], config, shuffle=False)config['train_flag'] = Trueself.train_data = load_data_batch(config["train_data_path"], config)self.stats_dict = {"correct": 0, "wrong": 0} # 用于存储测试结果def eval(self, epoch):self.logger.info("开始测试第%d轮模型效果:" % epoch)self.stats_dict = {"correct": 0, "wrong": 0} # 清空前一轮的测试结果self.model.eval()self.knwb_to_vector()for index, batch_data in enumerate(self.valid_data):if torch.cuda.is_available():batch_data = [d.cuda() for d in batch_data]input_id, labels = batch_data # 输入变化时这里需要修改,比如多输入,多输出的情况with torch.no_grad():test_question_vectors = self.model(input_id) # 不输入labels,使用模型当前参数进行预测self.write_stats(test_question_vectors, labels)self.show_stats()returndef write_stats(self, test_question_vectors, labels):assert len(labels) == len(test_question_vectors)for test_question_vector, label in zip(test_question_vectors, labels):# 通过一次矩阵乘法,计算输入问题和知识库中所有问题的相似度# test_question_vector shape [vec_size] knwb_vectors shape = [n, vec_size]res = torch.mm(test_question_vector.unsqueeze(0), self.knwb_vectors.T)hit_index = int(torch.argmax(res.squeeze())) # 命中问题标号hit_index = self.question_index_to_standard_question_index[hit_index] # 转化成标准问编号if int(hit_index) == int(label):self.stats_dict["correct"] += 1else:self.stats_dict["wrong"] += 1return# 将知识库中的问题向量化,为匹配做准备# 每轮训练的模型参数不一样,生成的向量也不一样,所以需要每轮测试都重新进行向量化def knwb_to_vector(self):self.question_index_to_standard_question_index = {}self.question_ids = []for standard_question_index, question_ids in self.train_data.dataset.knwb.items():for question_id in question_ids:# 记录问题编号到标准问题标号的映射,用来确认答案是否正确self.question_index_to_standard_question_index[len(self.question_ids)] = standard_question_indexself.question_ids.append(question_id)with torch.no_grad():question_matrixs = torch.stack(self.question_ids, dim=0)if torch.cuda.is_available():question_matrixs = question_matrixs.cuda()self.knwb_vectors = self.model(question_matrixs)# 将所有向量都作归一化 v / |v|self.knwb_vectors = torch.nn.functional.normalize(self.knwb_vectors, dim=-1)returndef show_stats(self):correct = self.stats_dict["correct"]wrong = self.stats_dict["wrong"]self.logger.info("预测集合条目总量:%d" % (correct + wrong))self.logger.info("预测正确条目:%d,预测错误条目:%d" % (correct, wrong))self.logger.info("预测准确率:%f" % (correct / (correct + wrong)))self.logger.info("--------------------")return correct / (correct + wrong)model.py
import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from transformers import BertModel"""
建立网络模型结构
"""class TorchModel(nn.Module):def __init__(self, config):super(TorchModel, self).__init__()hidden_size = config["hidden_size"]vocab_size = config["vocab_size"] + 1output_size = config["output_size"]model_type = config["model_type"]num_layers = config["num_layers"]self.use_bert = config["use_bert"]self.emb = nn.Embedding(vocab_size + 1, hidden_size, padding_idx=0)if model_type == 'rnn':self.encoder = nn.RNN(input_size=hidden_size, hidden_size=hidden_size, num_layers=num_layers,batch_first=True)elif model_type == 'lstm':# 双向lstm,输出的是 hidden_size * 2(num_layers 要写2)self.encoder = nn.LSTM(hidden_size, hidden_size, num_layers=num_layers)elif self.use_bert:self.encoder = BertModel.from_pretrained(config["bert_model_path"])# 需要使用预训练模型的hidden_sizehidden_size = self.encoder.config.hidden_sizeelif model_type == 'cnn':self.encoder = CNN(config)elif model_type == "gated_cnn":self.encoder = GatedCNN(config)elif model_type == "bert_lstm":self.encoder = BertLSTM(config)# 需要使用预训练模型的hidden_sizehidden_size = self.encoder.config.hidden_sizeself.classify = nn.Linear(hidden_size, output_size)self.pooling_style = config["pooling_style"]self.loss = nn.functional.cross_entropy # loss采用交叉熵损失def forward(self, x, y=None):if self.use_bert:# 输入x为[batch_size, seq_len]# bert返回的结果是 (sequence_output, pooler_output)# sequence_output:batch_size, max_len, hidden_size# pooler_output:batch_size, hidden_sizex = self.encoder(x)[0]else:x = self.emb(x)x = self.encoder(x)# 判断x是否是tupleif isinstance(x, tuple):x = x[0]# 池化层if self.pooling_style == "max":# shape[1]代表列数,shape是行和列数构成的元组self.pooling_style = nn.MaxPool1d(x.shape[1])elif self.pooling_style == "avg":self.pooling_style = nn.AvgPool1d(x.shape[1])x = self.pooling_style(x.transpose(1, 2)).squeeze()y_pred = self.classify(x)if y is not None:return self.loss(y_pred, y.squeeze())else:return y_pred# 定义孪生网络 (计算两个句子之间的相似度)
class SiameseNetwork(nn.Module):def __init__(self, config):super(SiameseNetwork, self).__init__()self.sentence_encoder = TorchModel(config)# 使用的是cos计算# self.loss = nn.CosineEmbeddingLoss()# 使用triplet_lossself.triplet_loss = self.cosine_triplet_loss# 计算余弦距离 1-cos(a,b)# cos=1时两个向量相同,余弦距离为0;cos=0时,两个向量正交,余弦距离为1def cosine_distance(self, tensor1, tensor2):tensor1 = torch.nn.functional.normalize(tensor1, dim=-1)tensor2 = torch.nn.functional.normalize(tensor2, dim=-1)cosine = torch.sum(torch.mul(tensor1, tensor2), axis=-1)return 1 - cosine# 3个样本 2个为一类 另一个一类 计算triplet lossdef cosine_triplet_loss(self, a, p, n, margin=None):ap = self.cosine_distance(a, p)an = self.cosine_distance(a, n)if margin is None:diff = ap - an + 0.1else:diff = ap - an + margin.squeeze()return torch.mean(diff[diff.gt(0)]) # greater than# 使用triplet_lossdef forward(self, sentence1, sentence2=None, sentence3=None, margin=None):vector1 = self.sentence_encoder(sentence1)# 同时传入3 个样本if sentence2 is None:if sentence3 is None:return vector1# 计算余弦距离else:vector3 = self.sentence_encoder(sentence3)return self.cosine_distance(vector1, vector3)else:vector2 = self.sentence_encoder(sentence2)if sentence3 is None:return self.cosine_distance(vector1, vector2)else:vector3 = self.sentence_encoder(sentence3)return self.triplet_loss(vector1, vector2, vector3, margin)# CosineEmbeddingLoss# def forward(self,sentence1, sentence2=None, target=None):# # 同时传入两个句子# if sentence2 is not None:# vector1 = self.sentence_encoder(sentence1) # vec:(batch_size, hidden_size)# vector2 = self.sentence_encoder(sentence2)# # 如果有标签,则计算loss# if target is not None:# return self.loss(vector1, vector2, target.squeeze())# # 如果无标签,计算余弦距离# else:# return self.cosine_distance(vector1, vector2)# # 单独传入一个句子时,认为正在使用向量化能力# else:# return self.sentence_encoder(sentence1)# 优化器的选择
def choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["lr"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)# 定义CNN模型
class CNN(nn.Module):def __init__(self, config):super(CNN, self).__init__()hidden_size = config["hidden_size"]kernel_size = config["kernel_size"]pad = int((kernel_size - 1) / 2)self.cnn = nn.Conv1d(hidden_size, hidden_size, kernel_size, bias=False, padding=pad)def forward(self, x): # x : (batch_size, max_len, embeding_size)return self.cnn(x.transpose(1, 2)).transpose(1, 2)# 定义GatedCNN模型
class GatedCNN(nn.Module):def __init__(self, config):super(GatedCNN, self).__init__()self.cnn = CNN(config)self.gate = CNN(config)# 定义前向传播函数 比普通cnn多了一次sigmoid 然后互相卷积def forward(self, x):a = self.cnn(x)b = self.gate(x)b = torch.sigmoid(b)return torch.mul(a, b)# 定义BERT-LSTM模型
class BertLSTM(nn.Module):def __init__(self, config):super(BertLSTM, self).__init__()self.bert = BertModel.from_pretrained(config["bert_model_path"], return_dict=False)self.rnn = nn.LSTM(self.bert.config.hidden_size, self.bert.config.hidden_size, batch_first=True)def forward(self, x):x = self.bert(x)[0]x, _ = self.rnn(x)return xif __name__ == "__main__":from config import ConfigConfig["vocab_size"] = 10Config["max_length"] = 4model = SiameseNetwork(Config)s1 = torch.LongTensor([[1, 2, 3, 0], [2, 2, 0, 0]])s2 = torch.LongTensor([[1, 2, 3, 4], [3, 2, 3, 4]])l = torch.LongTensor([[1], [0]])y = model(s1, s2, l)print(y)相关文章:
--文本匹配任务)
NLP(14)--文本匹配任务
前言 仅记录学习过程,有问题欢迎讨论 步骤: * 1. 输入问题 * 2. 匹配问题库(基础资源,FAQ) * 3. 返回答案文本匹配算法: 编辑距离算法(缺点) 字符之间没有语义相似度; 受无关词/停用词影响大; 受语序影响大 Jaccar…...

MySQL——系统变量
使用 #最大连接用户数 select MAX_CONNECTIONS; #临时存放构成每次事务的SQL的缓冲区长度 select BINLOG_CACHE_SIZE; #SQL Server的版本信息 select VERSION; 查询结果...

「 网络安全常用术语解读 」漏洞利用预测评分系统EPSS详解
1. 概览 EPSS(Exploit Prediction Scoring System,漏洞利用预测评分系统) 提供了一种全新的高效、数据驱动的漏洞管理功能。EPSS是一项数据驱动的工作,使用来自 CVE 的当前威胁信息和现实世界的漏洞数据。 EPSS 模型产生 0 到 1&…...

理解python中的Iterator 和 Iterable 迭代器和可迭代对象
为什么有些对象可以用for … in 循环 我们先看一段代码: list [1, 2, 3, 4, 5]for i in list:logger.info(i)这代码定义了1个数组object list, 然后用 for … in 来遍历这个list 看起来合理没什么值得注意 但其实 for … in 后面对象还可以是个String for i in …...

C语言实现动态加载.so动态库,使用,错误捕获以及卸载
动态库 概述 动态库的扩展名是.so。 动态库是被加载,调用的时候是根据内存地址去调用,而不是将代码复制到文件中。 动态库可以同时被多个进程使用。 实战案例:构建 libmath.so 动态库 准备源文件 calc.h 定义加法:int add…...
《动手学深度学习》V2(11-18)
文章目录 十一、二 模型选择与过拟合和欠拟合1、模型的选择2、过拟合和欠拟合3、估计模型容量4、线性分类器的VC维5、过拟合欠拟合的代码实现 :fire:①生成数据集②定义评估损失③定义训练函数④三阶多项式函数拟合⑤线性函数拟合(欠拟合)⑤高阶多项式函数拟合(过拟合) 十三、权…...

web前端之excel转pdf、小黄人发送请求、base64、jspdf、xlsx
MENU 前言方案一方案二结束语 前言 在前端将Excel转换为PDF有多种方案,本文介绍两种简单方案。 方案一 使用jspdf库,先将Excel文件转成Base64格式,然后再使用jspdf库将其转换为PDF格式,最后使用saveAs函数下载PDF文件。 步骤一: 安…...
)
【面试题】音视频流媒体高级开发(2)
面试题6 衡量图像重建好坏的标准有哪些?怎样计算? 参考答案 SNR(信噪比) PSNR10*log10((2n-1)2/MSE) (MSE是原图像与处理图像之间均方误差,所以计算PSNR需要2幅图像的数据!) SSIM…...
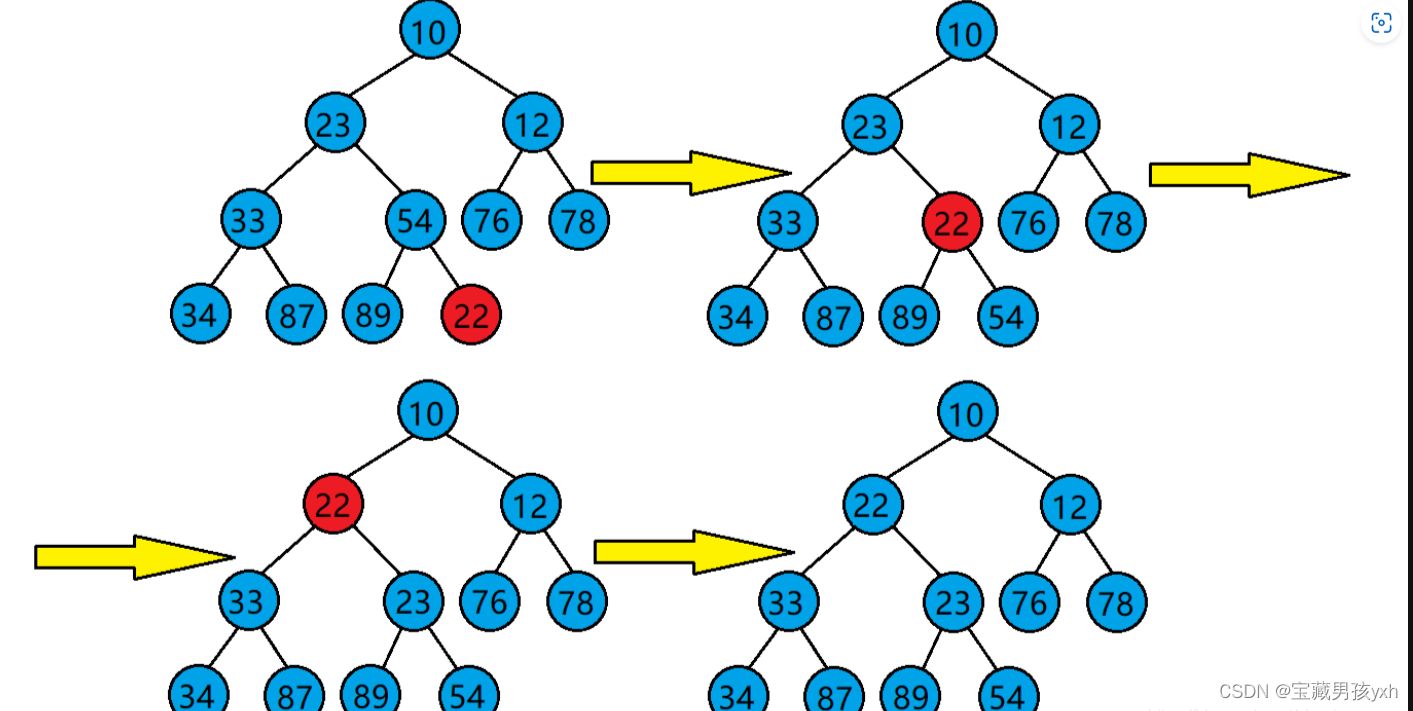
数据与结构--堆
堆 堆的概念 堆:如果有一个关键码的集合K{k0,k1,k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足ki<k2i1且ki<k2i2(或满足ki>k2i1且ki>k2i2),其中i0,1,2,…...
Github的使用教程(下载项目、寻找开源项目和上传项目)
根据『教程』一看就懂!Github基础教程_哔哩哔哩_bilibili 整理。 1.项目下载 1)直接登录到源码链接页或者通过如下图的搜索 通过编程语言对搜索结果进一步筛选。 如何去找开源项目:(Github 新手够用指南 | 全程演示&个人找项目技巧放…...
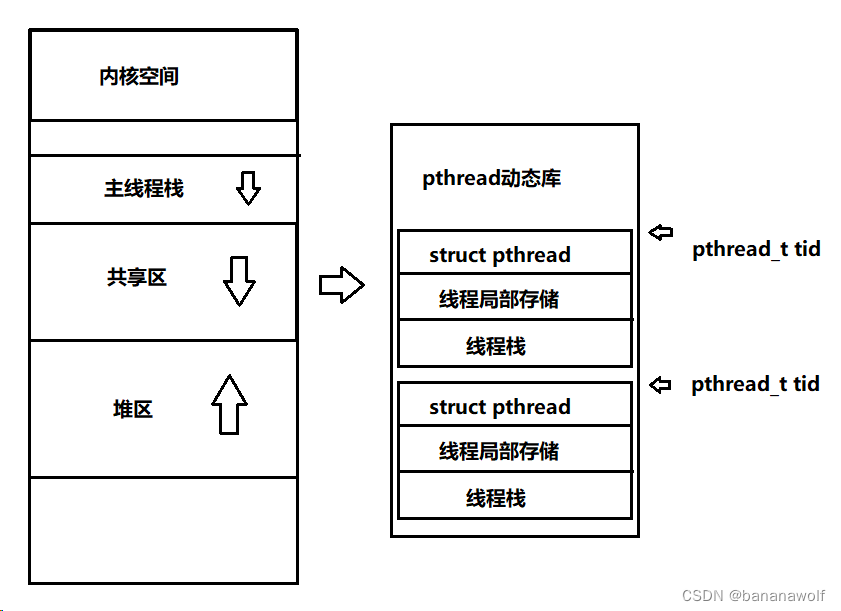
Linux-线程概念
1. 线程概念 线程:轻量级进程,在进程内部执行,是OS调度的基本单位;进程内部线程共用同一个地址空间,同一个页表,以及内存中的代码和数据,这些资源对于线程来说都是共享的资源 进程:…...

js的桶排序
桶排序(Bucket Sort)是一种分布式排序算法,它将元素分散到一系列桶中,然后对每个桶中的元素进行排序,并将所有的桶合并起来得到最终的排序结果。桶排序适用于输入的元素均匀分布在一个范围内的情况,它的时间…...
解决ubuntu无法上网问题
发现是网络配置成了Manual手动模式,现在都改成自动分配DHCP模式 打开后,尝试上网还是不行,ifconfig查看ip地址还是老地址,怀疑更改没生效,于是重启试试。 重启后,ip地址变了,可以打开网页了 …...

使用nvm管理多版本node.js
使用nvm(Node Version Manager)安装Node.js是一个非常方便的方法,因为它允许你在同一台机器上管理多个Node.js版本。以下是使用nvm安装Node.js的基本步骤: Linux 安装nvm 根据你的操作系统,安装命令可能会有所不同。以…...
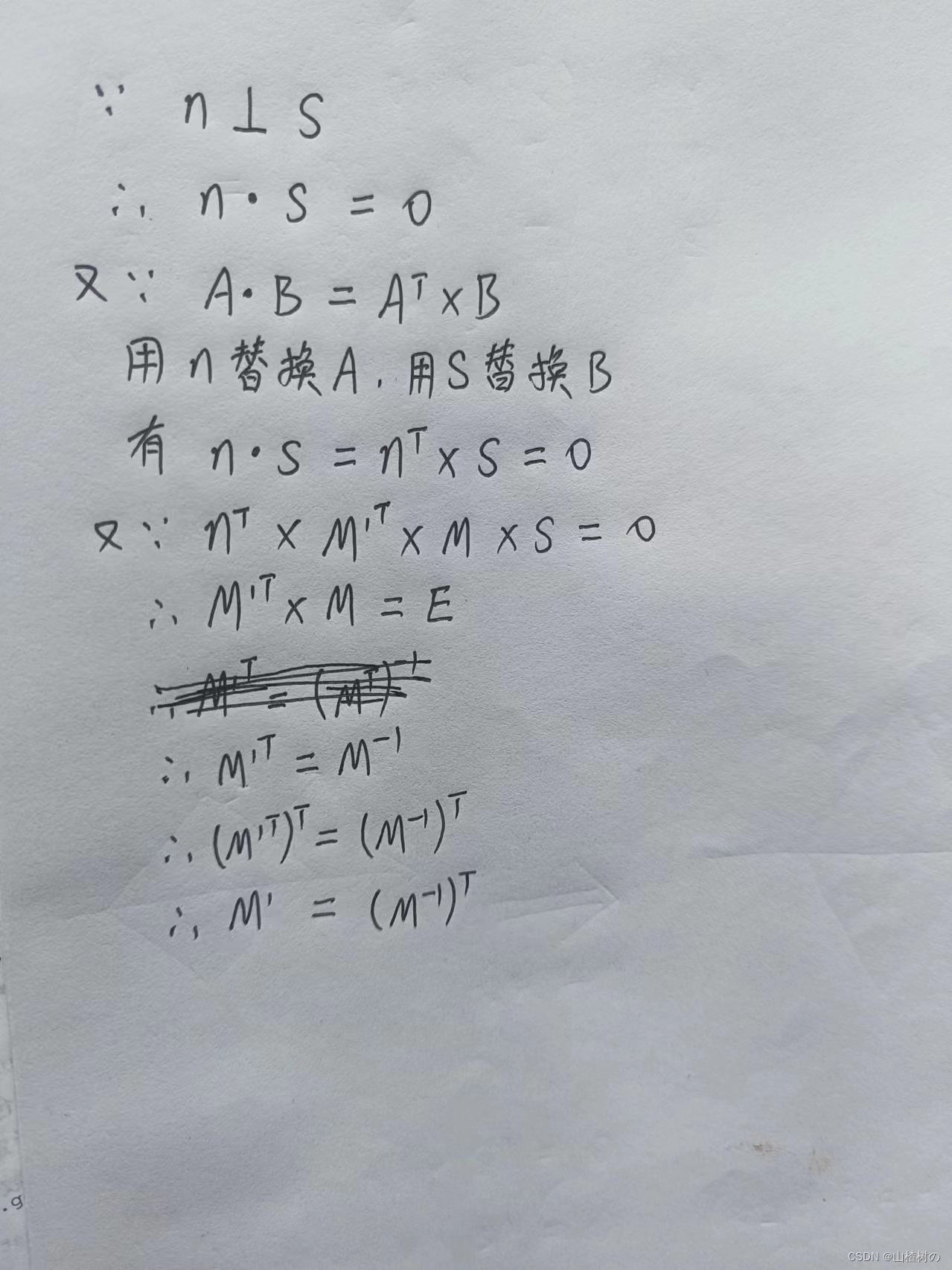
推导 模型矩阵的逆转置矩阵求运动物体的法向量
一个物体表面的法向量如何随着物体的坐标变换而改变,取决于变换的类型。使用逆转置矩阵,可以安全地解决该问题,而无须陷入过度复杂的计算中。 法向量变化规律 平移变换不会改变法向量,因为平移不会改变物体的方向。 旋转变换会改…...
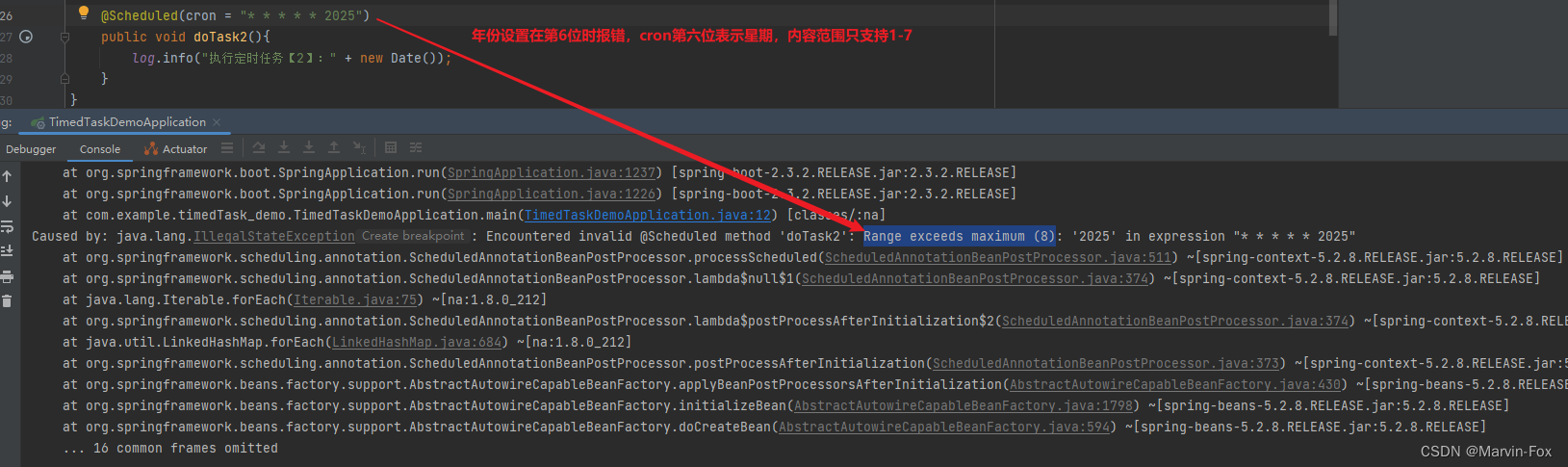
定时任务的几种实现方式
定时任务实现的几种方式: 1、JDK自带 (1)Timer:这是java自带的java.util.Timer类,这个类允许你调度一个java.util.TimerTask任务。使用这种方式可以让你的程序按照某一个频度执行,但不能在指定时间运行。…...

docker部署springboot+Vue项目
项目介绍:后台springboot项目,该项目环境mysql、redis 。前台Vue:使用nginx反向代理 方法一:docker run 手动逐个启动容器 1.docker配置nginx代理 将vue项目打包上传到服务器上。创建文件夹存储数据卷,html存放打包…...
Llama3-Tutorial(Llama 3 超级课堂)-- 笔记
第1节—Llama 3 本地 Web Demo 部署 端口转发 vscode里面设置端口转发 https://a-aide-20240416-b4c2755-160476.intern-ai.org.cn/proxy/8501/ ssh -CNg -L 8501:127.0.0.1:8501 rootssh.intern-ai.org.cn -p 43681参考 https://github.com/SmartFlowAI/Llama3-Tutorial/b…...

【备战软考(嵌入式系统设计师)】12 - 嵌入式系统总线接口
我们嵌入式系统的总线接口可以分为两类,一类是并行接口,另一类是串行接口。 并行通信就是用多个数据线,每条数据线表示一个位来进行传输数据,串行接口就是一根数据线可以来一位一位地传递数据。 从上图也可以看出,并行…...

【一刷《剑指Offer》】面试题 18:树的子结构
力扣对应题目链接:LCR 143. 子结构判断 - 力扣(LeetCode) 牛客对应题目链接:树的子结构_牛客题霸_牛客网 (nowcoder.com) 核心考点:二叉树理解,二叉树遍历。 一、《剑指Offer》对应内容 二、分析问题 二叉…...

抖音视频批量下载工具终极指南:3分钟实现高效无水印下载
抖音视频批量下载工具终极指南:3分钟实现高效无水印下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback sup…...

终极指南:3步快速掌握日语漫画OCR识别神器MangaOCR
终极指南:3步快速掌握日语漫画OCR识别神器MangaOCR 【免费下载链接】manga-ocr Optical character recognition for Japanese text, with the main focus being Japanese manga 项目地址: https://gitcode.com/gh_mirrors/ma/manga-ocr 你是否曾经面对日文漫…...

储能BMS HiL测试:原理、价值与工程实践全解析
1. 储能BMS HiL测试:为什么它是研发验证的“必选项”?在储能系统,尤其是大规模电池储能电站的研发过程中,电池管理系统(BMS)的可靠性与安全性是决定整个项目成败的基石。然而,传统的BMS测试方法…...

Sora之后的真相:2026年真正落地的8款工业级AI视频引擎,含API吞吐量、帧间PSNR均值与商用SLA承诺明细
更多请点击: https://intelliparadigm.com 第一章:Sora之后的真相:2026年真正落地的8款工业级AI视频引擎,含API吞吐量、帧间PSNR均值与商用SLA承诺明细 Sora发布两年后,工业界已摒弃“演示即产品”的幻觉。截至2026年…...

Ormar 性能优化:10 个提升数据库查询效率的技巧
Ormar 性能优化:10 个提升数据库查询效率的技巧 【免费下载链接】ormar python async orm with fastapi in mind and pydantic validation 项目地址: https://gitcode.com/gh_mirrors/or/ormar Ormar 是一个专为 FastAPI 设计的 Python 异步 ORM,…...

基于YOLO+DeepSeek的病虫害检测与环境监测一体化解决方案
智慧农业智能云平台 定位:基于YOLODeepSeek的病虫害检测与环境监测一体化解决方案🌾 核心识别能力 • 支持作物:9种 作物 作物 作物 🌽 玉米 🌾 小麦 🌾 水稻 🍅 番茄 🥔 马铃薯 &am…...

如何从视频中智能提取PPT内容:3步完成自动化内容转换
如何从视频中智能提取PPT内容:3步完成自动化内容转换 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 你是否曾经花费数小时观看会议录像或教学视频,只为手动截…...

AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程
AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

5个关键步骤掌握B站视频下载神器DownKyi:从新手到高手
5个关键步骤掌握B站视频下载神器DownKyi:从新手到高手 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#…...
)
别再只用MSE了!PyTorch中SmoothL1Loss的保姆级使用指南(附代码对比)
深度学习回归任务中SmoothL1Loss的实战应用与MSE对比解析 在目标检测、房价预测等回归任务中,选择合适的损失函数往往决定了模型的收敛速度和最终性能。许多初学者会习惯性选择最熟悉的均方误差(MSE)损失函数,但当数据中存在离群点时,MSE的二…...