栈与队列的实现
前言
本次博客将要实现一下栈和队列,好吧
他们两个既可以使用动态数组也可以使用链表来实现
本次会有详细的讲解
栈的实现
栈的基础知识
什么是栈呢?
栈的性质是后进先出
来画个图来理解

当然可不可以出一个进一个呢,当然可以了
比如先进1 2 3再出一个
还剩下 1 2 再进一个5
最后出完所有元素
那么出的元素为 3 5 2 1
但是进入的顺序为1 2 3 5
所以先进后出也是相对而言的
我们上面的图只是让大家理解后入先出的概念
ok接下来我们开始来选择用什么结构来实现栈
分析
数组实现
很明显我们知道,栈是后入先出,所以它是需要进行尾插尾删的
而数组的尾插尾删,只需要将大小也就是size++或者-- 就可以实现,
在取栈顶的数据时也可以直接调用,取栈底时也可以直接调用
链表实现
当然链表也可以实现,但是普通的链表需要找尾,才可以尾插
我们可以多用一个指针来指向这个尾,这样可以解决问题
但是尾删怎么办?
如果要尾删,我们还是要再加一个指针指向这个尾的前一个才好尾删呀
然后取栈底栈顶可以通过头结点以及尾来找到
这样也可以实现,但是很麻烦
所以这个普通的单链表是不好实现链表的
但我们就是要搞事情
解决方法一
使用双向链表,这个就不多说了,多加个尾,尾插尾删,很简单
解决方法二
反过来看链表
看图吧

是不是实现的方法有很多种
我们这次要干大的,把这三种都敲一敲,当然在敲的过程中一定要注意细节
本次博客还会把细节交代清楚
1数组实现栈
我们先来看看头文件吧
#pragma once
#include<stdlib.h>
#include<stdio.h>
#include<stdbool.h>
#include<assert.h>
//这里是动态数组的定义
typedef int DataType;
typedef struct Stack {DataType* a;int top;int capacity;
}ST;
//初始化栈
void InitStack(ST* st);
//取栈顶
DataType TopStack(ST* st);
//入栈
void PushStack(ST* st, DataType x);
//出栈
void PopStack(ST* st);
//取栈的大小
int SizeStack(ST* st);
//取栈底
DataType BottomStack(ST* st);
//销毁栈
void DestroyStack(ST* st);
//栈的判空
bool EmptyStack(ST* st);细节1
注意我们这里定义了一个int top;
栈顶 在这里其实可以有两种写法,1 top初始值为0 2 top初始值为-1
第一种是top指向栈顶元素的下一个 第二种为top指向栈顶元素
其实就是因为数组的元素是以0开始的
这两种不同的写法,会导致后序的函数实现有一些差别
比如取栈的大小时,第一种是 返回top的值 第二种是返回top+1
本次博客使用第一种
细节2
在动态开辟数组时还有一个问题
就是一开始要不要给容量的问题,如果不给容量的话
在push操作中就会多一个判断,给容量的话一开始在Init(初始化)就要开辟空间
这也是细节之一这两种写法也有所不同 ,本次博客使用一开始不给容量
另外还有注意在满容量时的扩容,是扩二倍还是扩定量
搞清楚这几个细节就可以敲代码了
我们直接看吧
#include"stack.h"
void InitStack(ST* st)
{assert(st);st->a = NULL;st->capacity = 0;st->top = 0;
}
DataType TopStack(ST* st)
{assert(st);assert(st->top > 0);return st->a[st->top - 1];
}
void PushStack(ST* st, DataType x)
{assert(st);if (st->a == NULL){st->a=(DataType*)malloc(sizeof(DataType)*4);st->capacity = 4;st->a[st->top++] = x;}else{if (st->capacity == st->top){DataType* temp = (DataType*)realloc(st->a, sizeof(DataType) * 2 * st->capacity);if (temp != NULL){st->a =temp;st->capacity *= 2;}}st->a[st->top++] = x;}
}
void PopStack(ST* st)
{assert(st);assert(st->top > 0);st->top--;
}
int SizeStack(ST* st)
{return st->top;
}
DataType BottomStack(ST* st)
{assert(st);assert(st->top > 0);return st->a[0];
}
void DestroyStack(ST* st)
{free(st->a);st->a = NULL;st->capacity = 0;st->top = 0;
}
bool EmptyStack(ST* st)
{return st->top == 0;
}测试的话,大家自行去看,反正我是已经测试过了
2单链表实现栈
当然先看头文件
再来说说细节之处
#pragma once
#include<stdlib.h>
#include<stdio.h>
#include<stdbool.h>
#include<assert.h>
typedef struct Stack2_ {struct Stack2* next;DataType value;
}ST2_;
typedef struct Stack2 {ST2_* top;ST2_* bottom;int size;
}ST2;
//初始化
void InitStack2(ST2* st);
//栈顶
DataType TopStack2(ST2* st);
//入栈
void PushStack2(ST2* st, DataType x);
//出栈
void PopStack2(ST2* st);
//返回栈的大小
int SizeStack2(ST2* st);
//栈底
DataType BottomStack2(ST2* st);
//销毁栈
void DestroyStack2(ST2* st);
//判空
bool EmptyStack2(ST2* st);细节1
我们是使用了嵌套结构体避免了空间的浪费
比如如果使用一个结构体
那么每一个结构体都要有栈底,栈底,大小,还有下一个成员指针next,以及值value
而且对于不带头的单链表来说必须使用二级指针,很麻烦
这里是一定不能带头的
如果带头结点的话,那么我们有怎么头插呢,是不是,所以这里可是可以不写两个
结构体,但是要使用二级指针,来搞定第一个结点的情况
而且,它本质上浪费了空间
OK看看.c文件
void InitStack2(ST2* st)
{assert(st);st->top = st->bottom = NULL;st->size = 0;
}
DataType TopStack2(ST2* st)
{assert(st->top);return st->top->value;
}
void PushStack2(ST2* st, DataType x)
{assert(st);ST2_* temp = (ST2_*)malloc(sizeof(ST2_));if (temp == NULL)return;temp->value = x;if (st->top == NULL){st->bottom = st->top = temp;temp->next = NULL;}else{temp->next = st->top;st->top = temp;}st->size++;
}
void PopStack2(ST2* st)
{assert(st);assert(st->top);if (st->bottom == st->top){free(st->top);st->bottom = st->top = NULL;}else{ST2_ *temp = st->top->next;free(st->top);st->top = temp;}st->size--;
}
int SizeStack2(ST2* st)
{return st->size;
}
DataType BottomStack2(ST2* st)
{assert(st->top);return st->bottom->value;
}
void DestroyStack2(ST2* st)
{assert(st);while (!EmptyStack2(st)){PopStack2(st);}st->size = 0;
}
bool EmptyStack2(ST2* st)
{return st->size == 0;
}再来看看下一个,真挺累的,哈哈哈哈
3双链表实现栈
其实原理是一样的,但是这个结构会使操作更加简单
这个就直接看代码就好
void InitStack3(ST3* st);
DataType TopStack3(ST3* st);
void PushStack3(ST3* st, DataType x);
void PopStack3(ST3* st);
int SizeStack3(ST3* st);
DataType BottomStack3(ST3* st);
void DestroyStack3(ST3* st);
bool EmptyStack3(ST3* st);void InitStack3(ST3* st)
{st->size = 0;st->bottom = NULL;
}
DataType TopStack3(ST3* st)
{assert(st);assert(st->bottom);return st->bottom->prev->value;
}
void PushStack3(ST3* st, DataType x)
{assert(st);ST3_* temp = (ST3_*)malloc(sizeof(ST3_));temp->value = x;if (st->bottom == NULL){st->bottom = temp;temp->prev = temp;temp->next = temp;}else{ST3_* tem = st->bottom->prev;tem->next = temp;temp->next = st->bottom;temp->prev = tem;st->bottom->prev = temp;}st->size++;
}
void PopStack3(ST3* st)
{assert(st);assert(st->bottom);//st->bottom->next == st->bottom->prev//只有两个节点时也会有上式成立//下面是解决方法//st->bottom==st->bottom->next//SizeStack3(st)==1if (SizeStack3(st) == 1){free(st->bottom);st->bottom = NULL;}else{ST3_* tem = st->bottom->prev;st->bottom->prev = tem->prev;tem->prev->next = st->bottom;free(tem);}st->size--;
}
int SizeStack3(ST3* st)
{return st->size;
}
DataType BottomStack3(ST3* st)
{assert(st);assert(st->bottom);return st->bottom->value;
}
void DestroyStack3(ST3* st)
{while (!EmptyStack3(st)){PopStack3(st);}st->size = 0;
}
bool EmptyStack3(ST3* st)
{assert(st);return st->size == 0;
}哎呀,写的过程还是有些小问题,但都是小问题
OK,下面来看看队列
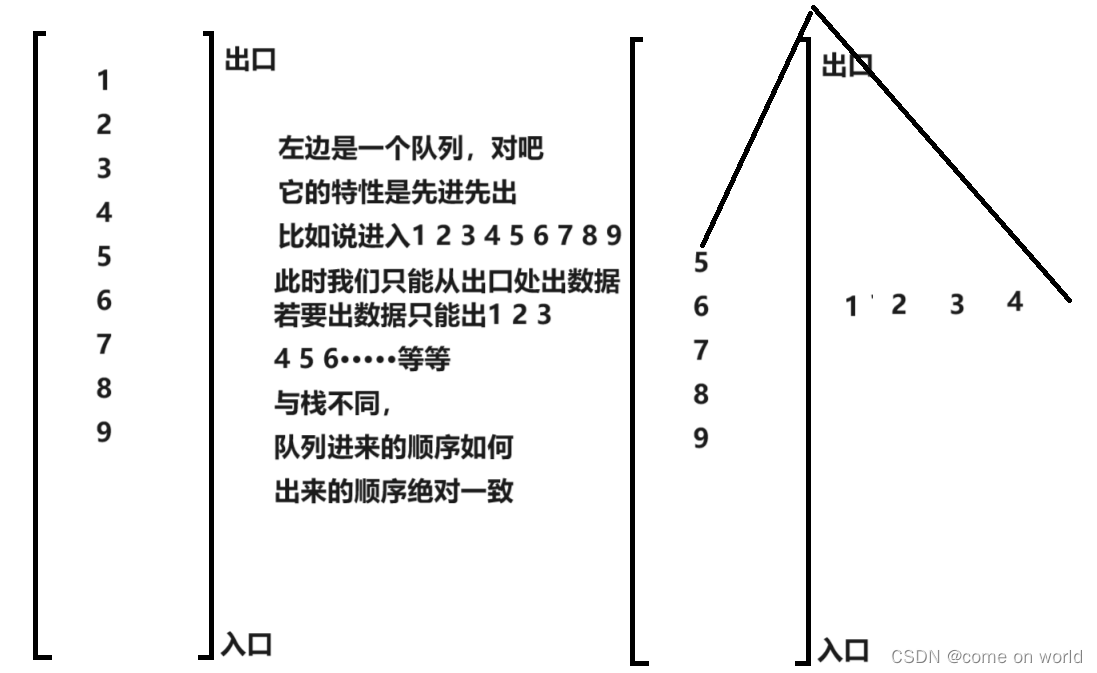
队列的实现
队列的特性与栈正好相反
他是先入先出
看图吧
当然了
队列的实现与栈的实现大差不差
队列也可以通过数组和链表来实现
分析
首先队列是需要从入口进,出口出的,
对于数组来说,他需要尾插和头删,
尾插很简单,只需要再接一个元素即可
但是头插,很麻烦需要整体左移然后size--时间复杂为o(n)
所以用数组实现有硬伤,因为其顺序结构,所以必然如此
对于链表来说
我们先使用单链表,要进行尾插以及头删
我们需要使用尾插,一般的单链表进行尾插的时间复杂度为o(n)
头删很简单,复杂度为o(1)
但是,我们可以使用一个指针来指向尾,这样就可以直接使尾插的复杂度变为o(1)
ok,从结构来讲,单链表最适合
但是,咱么都干了!!!
1数组实现队列
直接看代码吧
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int DataType;
typedef struct Queue {DataType* a;int size;int capacity;
}Que;
void InitQue(Que*que)
{que->a = (DataType*)malloc(sizeof(DataType)*4);que->capacity = 4;que->size = 0;
}
void QuePush(Que* que, DataType x)
{if (que->size == que->capacity){DataType* temp = (DataType*)realloc(que->a,sizeof(DataType)*que->capacity*2);if (temp == NULL){printf("realloc fail\n");return;}else{que->a = temp;que->capacity *= 2;}}que->a[que->size++] = x;
}
void QuePop(Que* que)
{assert(que->size != 0);for (int i = 1; i < que->size; i++){que->a[i - 1] = que->a[i];}que->size--;
}
bool QueEmpty(Que* que)
{return que->size == 0;
}DataType QueBack(Que* que)
{assert(que);assert(que->size > 0);return que->a[que->size-1];
}DataType QueFront(Que* que)
{return que->a[0];
}
void QueDestroy(Que* que)
{free(que->a);que->capacity = 0;que->size = 0;
}上面的代码,基本实现的逻辑与栈相差无几,甚至可以说跟简单
OK
看看更加实用的链表实现
2单链表实现队列
这里的注意点与用栈实现栈也是一样的
但是有一个注意点还是要讲一讲的
这里差点漏了
注意点1
就是在pop队列时
如果只有一个结点时,此时请你一定要把tail指针置空
上面的链表实现栈是也会有这个问题,
大家要注意,不然你就会被自己幽默到,看到nullter被调用 哈哈哈哈哈
OK大家看代码呗
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int DataType;
typedef struct Queue_2 {struct Queue2* next;DataType data;
}Que_2;
typedef struct Queue2 {Que_2* a;Que_2* tail;int size;
}Que2;
void InitQue2(Que2* que);
void QuePush2(Que2* que, DataType x);
void QuePop2(Que2* que);
bool QueEmpty2(Que2* que);
DataType QueFront2(Que2* que);
void QueDestroy2(Que2* que);
int QueSize2(Que2* que);
DataType QueBack2(Que2* que);
void InitQue2(Que2* que)
{assert(que);que->tail=que->a = NULL;que->size = 0;
}
void QuePush2(Que2* que, DataType x)
{Que_2* temp = (Que_2*)malloc(sizeof(Que_2));if (temp == NULL){printf("malloc fail\n");return;}temp->next = NULL;temp->data = x;if (que->a == NULL){que->tail=que->a= temp;}else{que->tail->next = temp;que->tail = temp;}que->size++;
}
void QuePop2(Que2* que)
{assert(que->a);Que_2* temp = que->a->next;free(que->a);que->a = temp;if (que->a == NULL)que->tail = NULL;que->size--;
}
bool QueEmpty2(Que2* que)
{return que->a == NULL;
}
DataType QueFront2(Que2* que)
{assert(que->a);return que->a->data;
}
DataType QueBack2(Que2* que)
{assert(que->a);return que->tail->next;
}
void QueDestroy2(Que2* que)
{assert(que->a);while (que->a){Que_2* temp = que->a->next;free(que->a);que->a = temp;}que->tail = NULL;que->size = 0;
}
int QueSize2(Que2* que)
{return que->size;
}总结
额,终于算是肝完了,这里的代码的重复性很高,不要看字很多
很多都是重复的!好吧,栈和队列这个基础数据结构的各项实现方法算是都敲了一遍
当然,我们还有一个循环队列没有实现,对吧
下一次再来,搞一搞oj题
加油!
相关文章:
栈与队列的实现
前言 本次博客将要实现一下栈和队列,好吧 他们两个既可以使用动态数组也可以使用链表来实现 本次会有详细的讲解 栈的实现 栈的基础知识 什么是栈呢? 栈的性质是后进先出 来画个图来理解 当然可不可以出一个进一个呢,当然可以了 比如…...
线性集合:ArrayList,LinkedList,Vector/Stack
共同点:都是线性集合 ArrayList ArrayList 底层是基于数组实现的,并且实现了动态扩容(当需要添加新元素时,如果 elementData 数组已满,则会自动扩容,新的容量将是原来的 1.5 倍),来…...
llama3 发布!大语言模型新选择 | 开源日报 No.251
meta-llama/llama Stars: 53.0k License: NOASSERTION llama 是用于 Llama 模型推理的代码。 提供了预训练和微调的 Llama 语言模型,参数范围从 7B 到 70B。可以通过下载脚本获取模型权重和 tokenizer。支持在本地快速运行推理,并提供不同规格的模型并…...

SpringBoot 具体是做什么的?
Spring Boot是一个用于构建独立的、生产级别的、基于Spring框架的应用程序的开源框架。它的目标是简化Spring应用程序的开发和部署过程,通过提供一种快速、便捷的方式来创建Spring应用程序,同时保持Spring的灵活性和强大特性。 1. 简化Spring应用程序开…...

Debian常用命令
Debian是一个开源的Unix-like操作系统,提供了大量的软件包供用户安装和使用。在Debian系统中,命令行界面(CLI)是用户与系统进行交互的重要工具。以下是Debian中一些常用的命令及其详细解释: 文件和目录操作命令&#x…...

常见的前端框架
常用的前端框架有以下几种: 模型 React:由Facebook开发的一款前端框架,采用虚拟DOM的概念,可高效地更新页面。Vue.js:一款轻量级的前端框架,易学易用,支持组件化开发和双向数据绑定。AngularJ…...
初学者如何选择ARM开发硬件?
在开始前我有一些资料,是我根据网友给的问题精心整理了一份「ARM的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!如果你没有ARM开发经验࿰…...
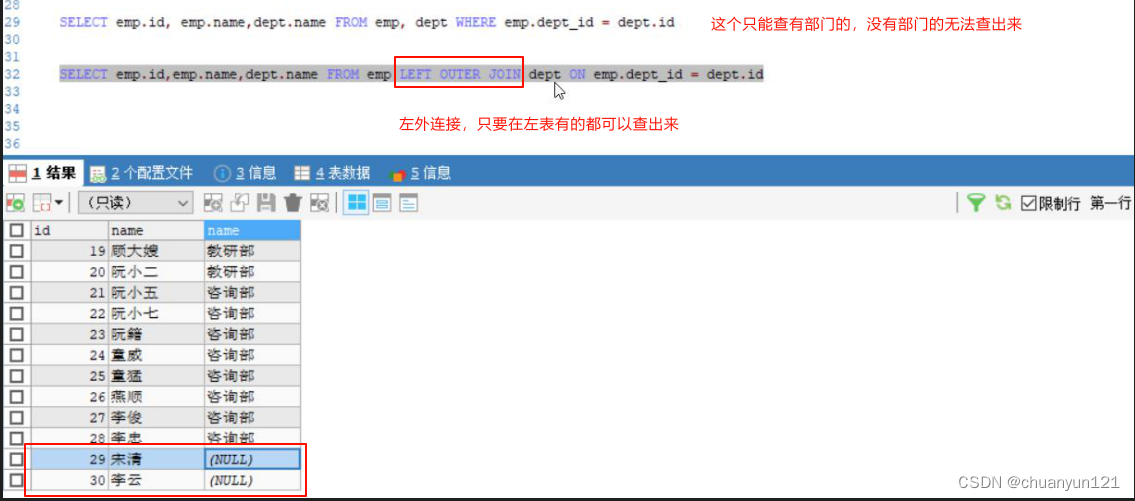
Mysql 多表查询,内外连接
内连接: 隐式内连接 使用sql语句直接进行多表查询 select 字段列表 from 表1 , 表2 where 条件 … ; 显式内连接 将‘,’改为 inner join 连接两个表的 on select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 … ; select emp.id, emp.name, …...
【C语言】函数
目录 一、函数的概念 二、库函数 2.1 ❥ 标准库 2.2 ❥ 库函数的使用方法 三、自定义函数 四、形参和实参 4.1 ❥ 实参(实际参数) 4.2 ❥ 形参(形式参数) 五、return语句 六、函数的调用 6.1 ❥ 传值调用 6.2 ❥ 传址调…...
【LeetCode】每日一题 2024_5_13 腐烂的橘子(经典多源 BFS)
文章目录 LeetCode?启动!!!题目:找出不同元素数目差数组题目描述代码与解题思路 每天进步一点点 LeetCode?启动!!! 好久没写每日一题题解了,今天重新起航 干…...
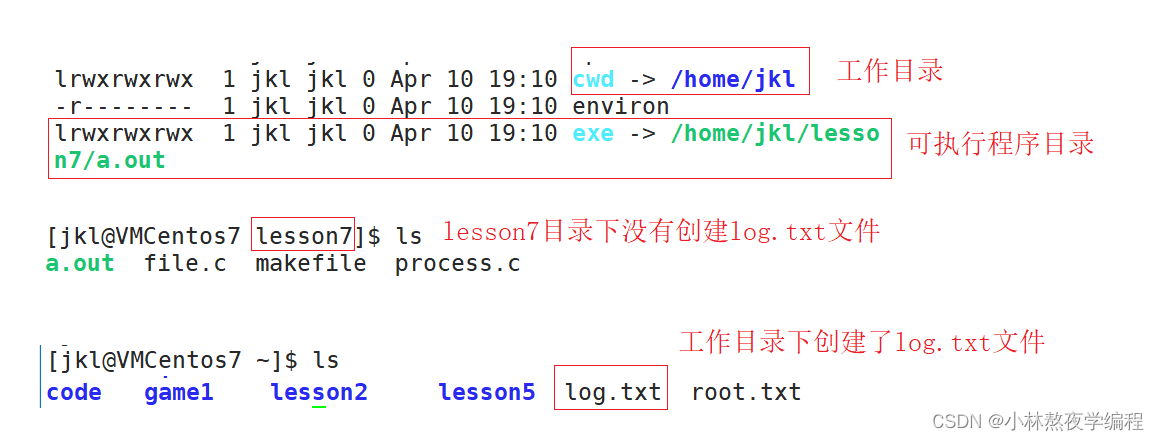
【Linux系统编程】第十七弹---进程理解
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】【Linux系统编程】 目录 1、进程的基本概念 2、描述进程-PCB 2.1、什么是PCB 2.2、为什么要有PCB 3、task_ struct 3.1、启动进程 3.2、创建进程…...

【网络安全入门】你必须要有的学习工具(附安装包)零基础入门到进阶,看这一篇就够了!
工欲善其事必先利其器 在新入门网络安全的小伙伴而言。这些工具你必须要有所了解。本文我们简单说说这些网络安全工具吧! Web安全类 Web类工具主要是通过各种扫描工具,发现web站点存在的各种漏洞如sql注入、xss等。从而获取系统权限,常用的…...
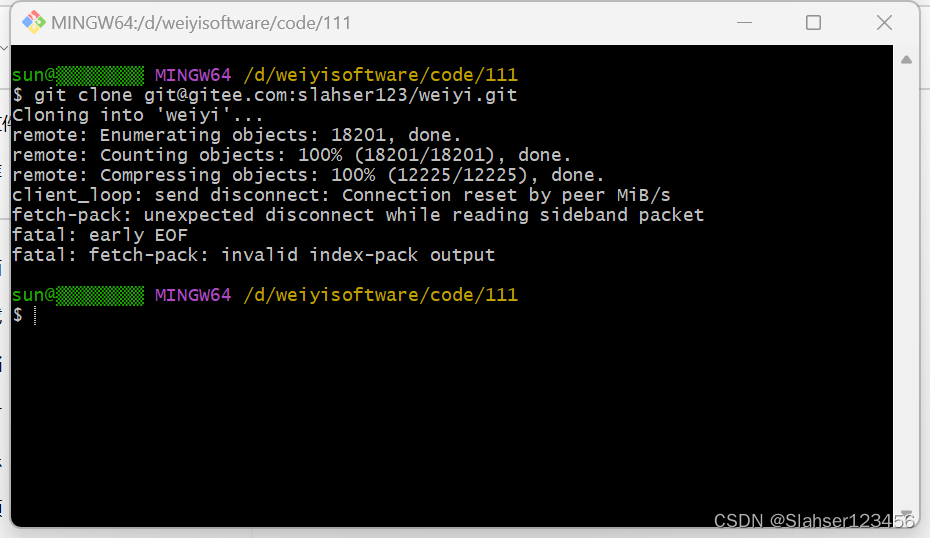
【解决】:git clone项目报错fatal: fetch-pack: invalid index-pack output
象:之前一直使用gitee将个人学习和工作相关记录上传到个人gitee仓库,一直没出现过问题。直到有一天换电脑重新拉取代码发现出了问题,具体如下图: 原因分析: 经过查询发现主要原因是因为git clone的远程仓库的项目过大…...
python随机显示四级词汇
python实现一个浮动窗口随机显示四级单词在桌面跑来跑去 实现一个浮动窗体随机显示四级单词在windows桌面置顶移动 tkinter库来创建窗口和显示单词,以及random库来随机选择单词。 使用after方法来定时更新窗口的位置,实现单词窗口的慢慢移动效果 使用…...

vuerouter声明式导航
声明式导航-跳转传参数 1.查询参数传参 语法:to /path?参数名值 2.对应页面组件接受传来的值 $router.query.参数名 2.动态路由传参 1.配置动态路由 2.配置导航连接 to/path/参数值 3.对应页面组件接收传递过来的值 #route.params.参数名 多个参数传递&…...
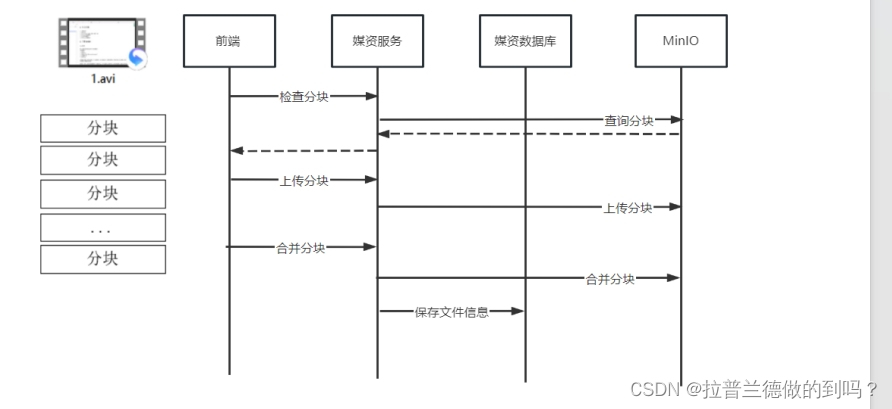
视频断点上传
什么是断点续传 通常视频文件都比较大,所以对于媒资系统上传文件的需求要满足大文件的上传要求。http协议本身对上传文件大小没有限制,但是客户的网络环境质量、电脑硬件环境等参差不齐,如果一个大文件快上传完了网断了没有上传完成…...

清华团队开发首个AI医院小镇模拟系统;阿里云发布通义千问 2.5:超越GPT-4能力;Mistral AI估值飙升至60亿美元
🦉 AI新闻 🚀 清华团队开发首个AI医院小镇模拟系统 摘要:来自清华的研究团队最近开发出了一种创新的模拟系统,名为"Agent Hospital",该系统能够完全模拟医患看病的全流程,其中包括分诊、挂号、…...

React Suspense与Concurrent Mode:探索异步渲染的新范式
React的Suspense和Concurrent Mode是两个强大的特性,它们共同改变了React应用处理异步数据加载和UI渲染的方式。下面我将通过一个简化的代码示例来展示如何使用这两个特性。 Concurrent Mode 和 Suspense 的基本用法 首先,确保你使用的是支持这些特性的…...

算法训练营day37
动态规划 1.斐波那契数 1.使用数组存储子问题结果 class Solution {public int fib(int N) {if (N 0) return 0;int[] dp new int[N 1];// base casedp[0] 0; dp[1] 1;// 状态转移for (int i 2; i < N; i) {dp[i] dp[i - 1] dp[i - 2];}return dp[N];} }2.使用变…...

基础ArkTS组件:帧动画,内置动画组件,跑马灯组件(HarmonyOS学习第三课【3.6】)
帧动画 帧动画也叫序列帧动画,其原理就是在时间轴的每帧上逐帧绘制不同的内容,使其连续播放而成动画。ArkUI开发框架提供了 ImageAnimator 组件实现帧动画能力,本节笔者介绍一下 ImageAnimator 组件的简单使用。 官方文献 说明 该组件从A…...

Blender 3MF插件终极指南:如何在Blender中实现3D打印文件的完美导入导出
Blender 3MF插件终极指南:如何在Blender中实现3D打印文件的完美导入导出 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 想要在Blender中高效处理3D打印文件吗…...

泉州某卫浴GEO优化实战:四标融合+场景化方法论,从搜索不可见到AI优先引用
我们在服务制造业企业的过程中发现一个根本性变化:过去大家关心“怎么让用户搜到我”,现在AI直接生成答案,企业真正的挑战变成了“怎么让AI准确信任我、优先引用我”。传统SEO在AI的“黑箱”面前越来越失效,企业必须重新建立一套可…...

可定制尺寸的工业烤盘公司
江苏台烁是专注为大中型食品生产企业提供可定制尺寸全品类工业烤盘的专业厂商,核心竞争优势为全尺寸高精度定制能力搭配智能生产体系,可提供节能耐用、适配产线的工业化烘焙器具解决方案。核心优势与关键数据生产与资质基础:拥有4.8万㎡智能工…...

告别内存焦虑!手把手教你读懂中科蓝讯AB530X的ram.ld文件,精准控制RAM复用
告别内存焦虑!手把手教你读懂中科蓝讯AB530X的ram.ld文件,精准控制RAM复用 第一次打开中科蓝讯AB530X的ram.ld文件时,那些密密麻麻的符号和数字让我头皮发麻。作为一款主打性价比的蓝牙芯片,AB530X的RAM资源相当有限——就像在寸土…...

【信息科学与工程学】【物理/化学科学和工程技术】知识体系 第四十一篇 数据中心基础设施领域中的力学知识 01
编号:001 类别 结构力学 (静力学与动力学) 领域 计算基础设施 / 机房设施 力学模型配方 将服务器机架简化为一个底部固定、顶部自由的悬臂梁模型。在地震激励下,该模型转化为一个单自由度阻尼受迫振动系统。主要考虑水平方向的地震力作用。 数学分析 通过建立运动微分…...
)
别再手动发邮件了!用Power Automate为SharePoint列表搭建自动化审批流(保姆级教程)
别再手动发邮件了!用Power Automate为SharePoint列表搭建自动化审批流(保姆级教程) 在快节奏的现代办公环境中,手动处理审批流程已成为效率的隐形杀手。想象一下:员工提交的请假申请需要HR手动转发邮件,采购…...

JPEG2000在Matlab中的实现源码
JPEG2000在Matlab中的实现源码 【下载地址】JPEG2000在Matlab中的实现源码 JPEG2000在Matlab中的实现源码欢迎来到JPEG2000的Matlab实现资源页面 项目地址: https://gitcode.com/open-source-toolkit/0665cd 欢迎来到JPEG2000的Matlab实现资源页面。本资源旨在提供一套完…...
)
【亲测免费】 探索VBA编程的利器:VBA参考手册(CHM)
探索VBA编程的利器:VBA参考手册(CHM) 【下载地址】VBA参考手册chm 本仓库提供了一个VBA参考手册的下载资源,文件格式为CHM(Compiled HTML Help)。该手册是学习和使用VBA(Visual Basic for Applications)的重…...

3分钟上手Mermaid Live Editor:零代码绘制专业图表的终极解决方案
3分钟上手Mermaid Live Editor:零代码绘制专业图表的终极解决方案 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-…...

Tracy安全最佳实践:开发与生产环境的安全配置指南
Tracy安全最佳实践:开发与生产环境的安全配置指南 【免费下载链接】tracy 😎 Tracy: the addictive tool to ease debugging PHP code for cool developers. Friendly design, logging, profiler, advanced features like debugging AJAX calls or CLI s…...