【爬虫】爬取股票历史K线数据写入数据库(三)

前几天有写过两篇:
【爬虫】爬取A股数据写入数据库(二)
【爬虫】爬取A股数据写入数据库(一)
现在继续完善,分析及爬取股票的历史K线数据通过ORM形式批量写入数据库。
2024/05,本文主要内容如下:
- 对东方财富官网进行分析,并作数据爬取,使用python,使用pip install requests 模拟http数据请求,获取数据。
- 将爬取的数据写入通过 sqlalchemy ORM 写入 sqlite数据库。
- 记录爬取股票的基本信息,如果库中已存在某个股票代码,则进行更新。
- 后续计划:会不断完善,最终目标是做出一个简单的股票查看客户端。
- 本系列所有源码均无偿分享,仅作交流无其他,供大家参考。
python依赖环境如下:
pip install requests==2.31.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas==2.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install jsonpath==0.8.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install sqlalchemy==2.0.30 -i https://pypi.tuna.tsinghua.edu.cn/simple
1. 对东方财富官网历史K线数据分析
网页地址:https://quote.eastmoney.com/sz002224.html?jump_to_web=true#fullScreenChart
通过分析网页,发现https://push2his.eastmoney.com/api/qt/stock/kline/get?请求后面带着一些参数即可以获取到相应数据,我们不断调试,模拟这类请求即可。分析过程如下图所示,F12调出调试框,不断尝试:
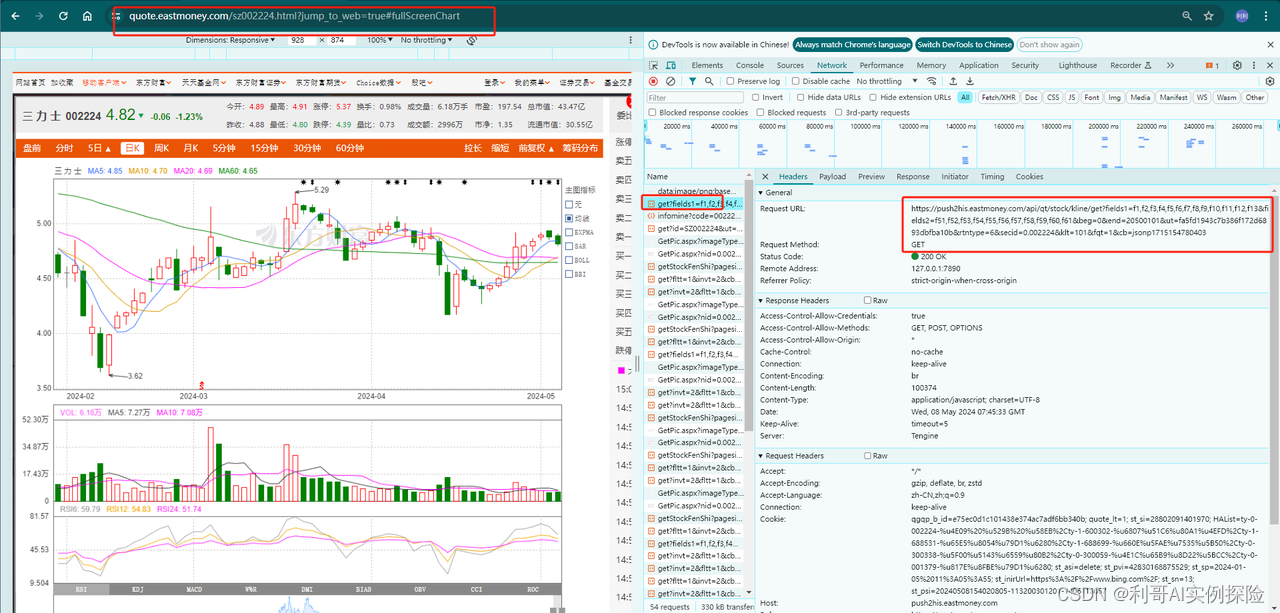
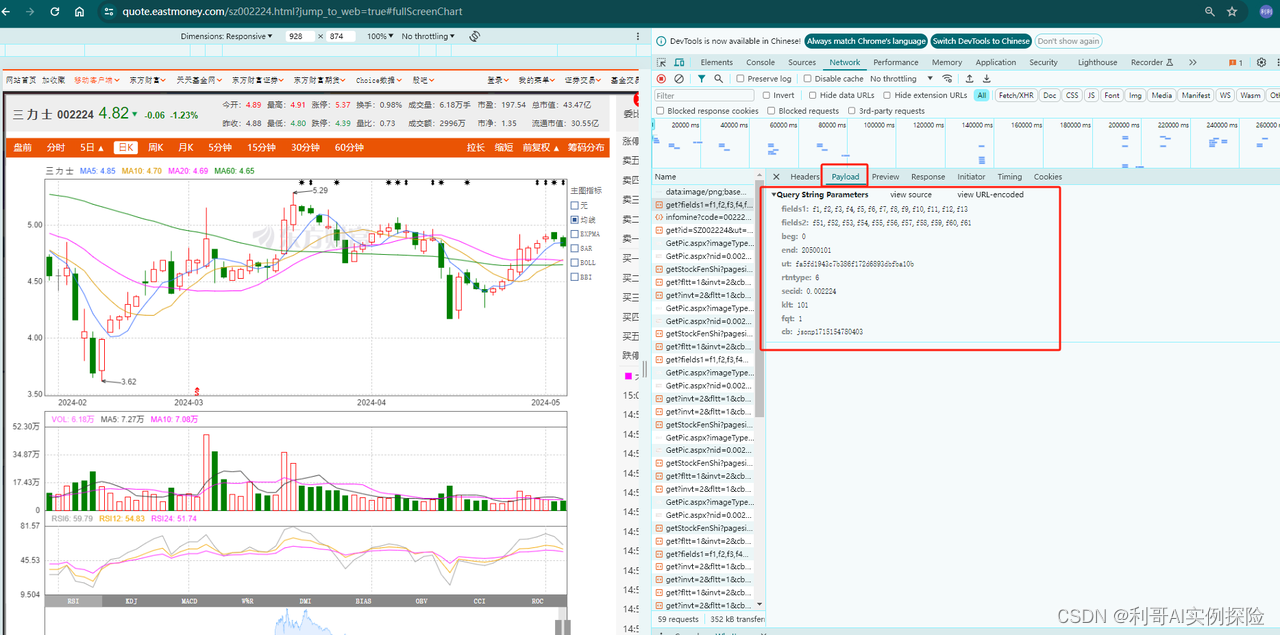
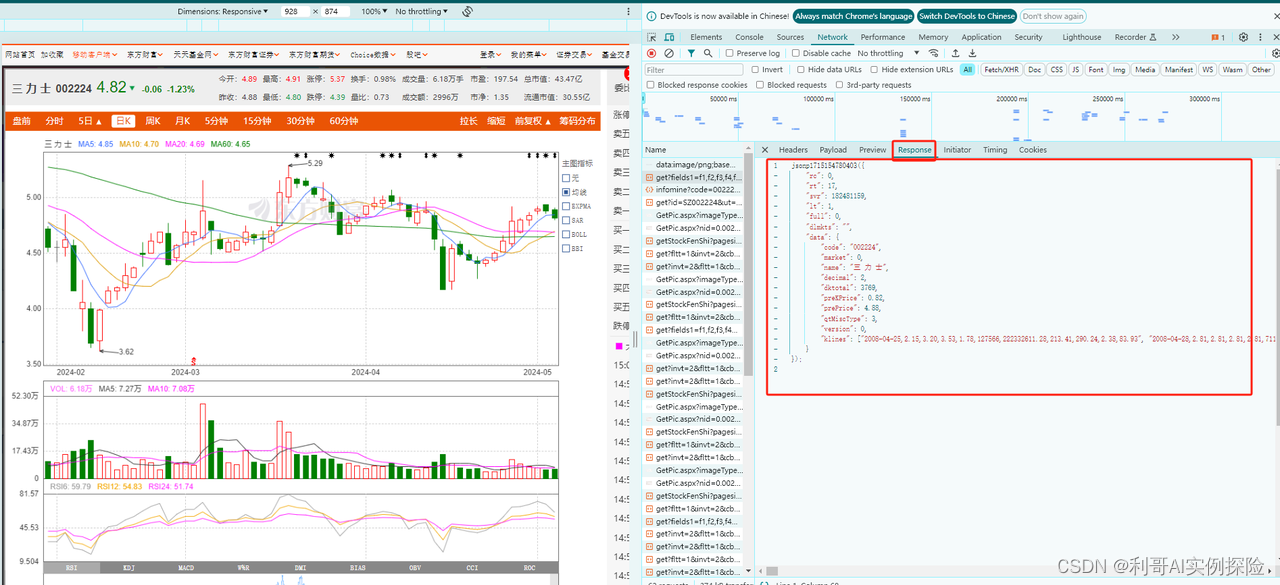
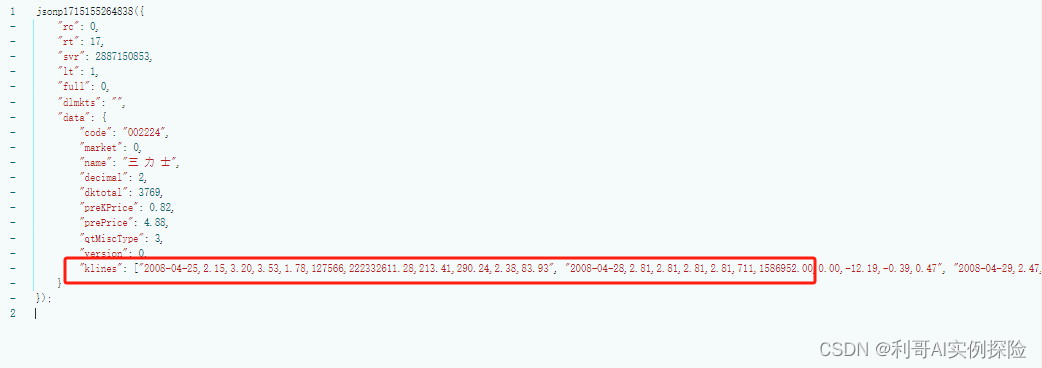
2. 爬取数据代码逻辑
如下即爬取数据的可运行代码,复制后直接能跑:
import pandas as pd
from typing import List
import requests
from jsonpath import jsonpathclass CustomedSession(requests.Session):def request(self, *args, **kwargs):kwargs.setdefault('timeout', 60)return super(CustomedSession, self).request(*args, **kwargs)
session = CustomedSession()
adapter = requests.adapters.HTTPAdapter(pool_connections = 50, pool_maxsize = 50, max_retries = 5)
session.mount('http://', adapter)
session.mount('https://', adapter)# 请求地址
QEURY_URL = 'http://push2his.eastmoney.com/api/qt/stock/kline/get'
# HTTP 请求头
EASTMONEY_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
}"""
获取单只股票的历史K线数据
"""
def get_k_history_data(stock_codes: str, # 股票代码beg: str = '19000101', # 开始日期,19000101,表示 1900年1月1日end: str = '20500101', # 结束日期klt: int = 101, # 行情之间的时间间隔 1、5、15、30、60分钟; 101:日; 102:周; 103:月fqt: int = 1, # 复权方式,0 不复权 1 前复权 2 后复权
):try:# 生成东方财富专用的secidif stock_codes[:3] == '000': # 沪市指数secid = f'1.{stock_codes}'elif stock_codes[:3] == '399': # 深证指数secid = f'0.{stock_codes}'if stock_codes[0] != '6': # 沪市股票secid = f'0.{stock_codes}'else:secid = f'1.{stock_codes}' # 深市股票EASTMONEY_KLINE_FIELDS = {'f51': '日期', 'f52': '开盘', 'f53': '收盘', 'f54': '最高', 'f55': '最低','f56': '成交量', 'f57': '成交额', 'f58': '振幅', 'f59': '涨跌幅', 'f60': '涨跌额', 'f61': '换手率',}fields = list(EASTMONEY_KLINE_FIELDS.keys())# columns = list(EASTMONEY_KLINE_FIELDS.values())fields2 = ",".join(fields)params = (('fields1', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13'),('fields2', fields2),('beg', beg),('end', end),('rtntype', '6'),('secid', secid),('klt', f'{klt}'),('fqt', f'{fqt}'),)code = secid.split('.')[-1]json_response = session.get(QEURY_URL, headers=EASTMONEY_REQUEST_HEADERS, params=params, verify=False).json()data_list = []klines: List[str] = jsonpath(json_response, '$..klines[:]')if not klines:return data_listname = json_response['data']['name']rows = [kline.split(',') for kline in klines]# 0 1 2 3 4 5 6 7 8 9 10# 日期, 开盘, 收盘, 最高, 最低, 成交量, 成交额, 振幅, 涨跌幅, 涨跌额, 换手率# 2024-05-08, 4.89, 4.82, 4.91, 4.80, 61811, 29955564.00, 2.25, -1.23, -0.06, 0.98# data_list = [{'code': '002224', 'name': '三力士', 'time': '2024-05-08', 'info': '0,1,2,3,4,5,6,7,8,9,10'}]for row in rows:time, open, close, high, low, vol, quota, mm, change, range, tun = rowline_str = f'{open},{close},{high},{low},{vol},{quota},{mm},{change},{range},{tun}'data_list.append({'id': None,'code': code, 'name': name, 'time': time, 'info': line_str})return data_listexcept Exception as e:print('get_k_history_data error-----------------------', str(e))return data_listif __name__ == "__main__":data = get_k_history_data(stock_codes='002224', beg='20240507', end='20500101')print('----', data)
3. 将爬取的数据通过ORM形式写入数据库
数据库表设计:
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Float, Index, Table
from sqlalchemy.orm import declarative_base, sessionmaker, scoped_session
from sqlalchemy.schema import UniqueConstraint
from datetime import datetime# 声明一个基类,所有的ORM类都将继承自这个基类
DBBase = declarative_base()# 创建引擎
engine = create_engine('sqlite:///a.db', echo=False)
# 绑定引擎
Session = sessionmaker(bind=engine)
# 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象conn
db_session = scoped_session(Session)'''
股票K线信息表
0 1 2 3 4 5 6 7 8 9 10
日期, 开盘, 收盘, 最高, 最低, 成交量, 成交额, 振幅, 涨跌幅, 涨跌额, 换手率
2024-05-08, 4.89, 4.82, 4.91, 4.80, 61811, 29955564.00, 2.25, -1.23, -0.06, 0.98
data_list = [{'code': '002224', 'name': '三力士', 'time': '2024-05-08', 'info': '1,2,3,4,5,6,7,8,9,10'}]
'''
class tb_k(DBBase):__tablename__ = 'tb_k'id = Column(Integer, primary_key=True, autoincrement=True)code = Column(String, nullable=False, comment="股票代码")name = Column(String, comment="股票名称")time = Column(String, comment="时间")info = Column(String, comment="开盘,收盘,最高,最低,成交量,成交额,振幅,涨跌幅,涨跌额,换手率")__table_args__ = (Index('unique_index', 'code', 'time', unique=True),)
# 创建表, 创建所有class xx(DBBase)
DBBase.metadata.create_all(engine)
写入数据库的逻辑:
# 查询某个股票最近更新K线的日期
def query_latast_K_data(code):result = db_session.query(tb_k).filter(tb_k.code==code).order_by(desc(tb_k.time)).first()if result is None:return '19000101'return str(result.time).replace('-','')# 批量插入或更新某只股票的历史K线数据
def insert_or_update_stock_k(data_list):if len(data_list) <= 0:returntry:db_session.bulk_insert_mappings(tb_k, data_list)db_session.commit()except Exception as e:print('insert_or_update_stock_k error=', str(e))
4. 整体逻辑流程
步骤:
- 输入某个股票代码爬取该股票的历史K线数据
- 将返回结果组成数组,批量写入数据库
- 每次写入前,会根据该股票代码,查询最新的同步日期,从该日期开始进行追加同步
# 更新某个股票的最新日K线数据到数据库
def update_k_info_db(code='002224'):# 根据 code 查询库中已存在的某个股票日K线数据的最近日期,作为开始日期,向后获取beg_time = db_orm.query_latast_K_data(code)data_list = stock.get_k_history_data(stock_codes=code, beg=beg_time, end='20500101')if len(data_list) > 0:db_orm.insert_or_update_stock_k(data_list)if __name__ == "__main__":update_base_info_db()
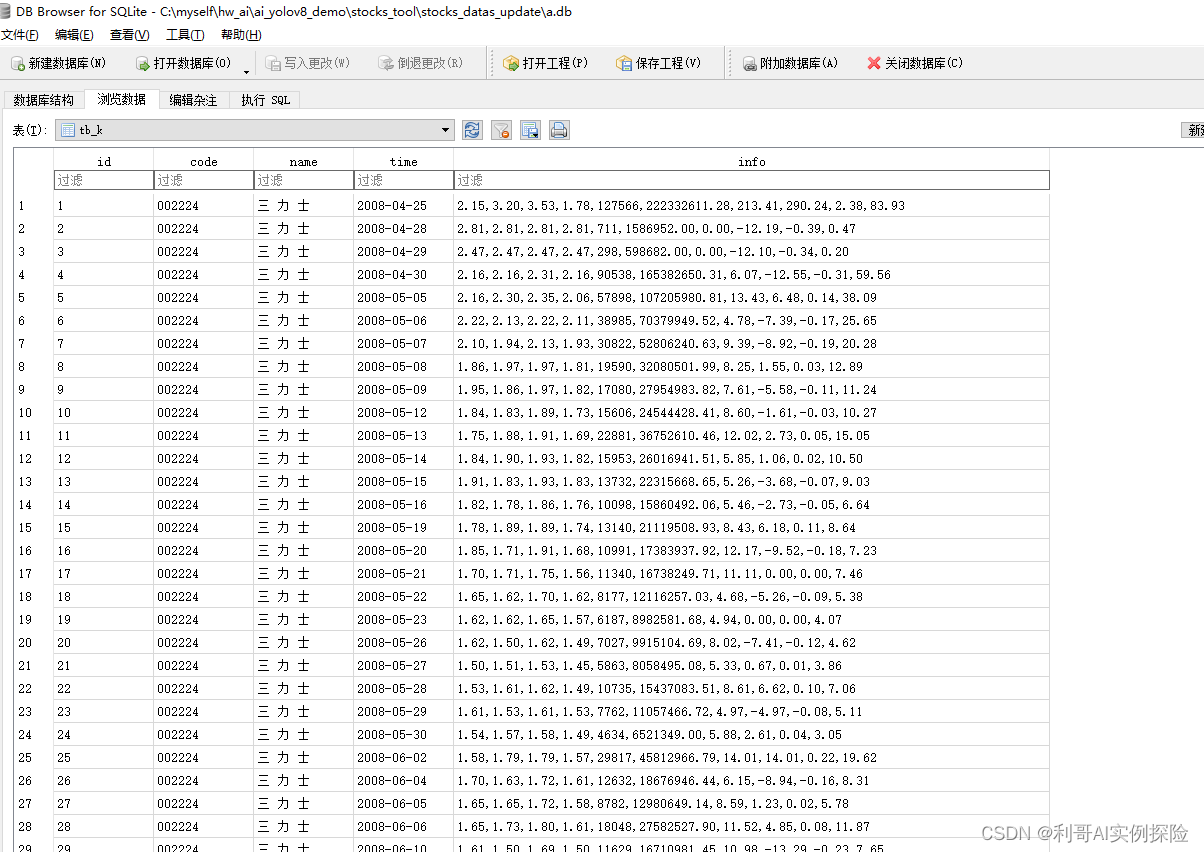
最终结果保存在 a.db中,例如:
更多内容可关注我,后续源码包均在上面回复下载:
【爬虫】爬取A股数据系列工具
相关文章:
【爬虫】爬取股票历史K线数据写入数据库(三)
前几天有写过两篇: 【爬虫】爬取A股数据写入数据库(二) 【爬虫】爬取A股数据写入数据库(一) 现在继续完善,分析及爬取股票的历史K线数据通过ORM形式批量写入数据库。 2024/05,本文主要内容如下…...

文心一言指令
文心一言(ERNIE Bot)是百度公司开发的人工智能语言模型,它可以接收各种指令来执行不同的任务。以下是一些可能的指令示例: 知识问答: 指令:“请问什么是人工智能?”文心一言会回答关于人工智能…...

常用的命令技巧总结
java命令执行 如下编码网站: Runtime.exec Payload Generater | AresXs Blogjava.lang.Runtime.exec() Payload Workarounds - Jackson_Thttps://www.bugku.net/runtime-exec-payloads/ 手动编码操作 bash -c {echo,cGluZyAxMjcuMC4wLjE7ZWNobyAxID50ZXN0LnR4dA}|…...

T97燃脂咖啡招商模式,私域分销模式设计
t97燃脂咖啡招商模式,希柔T97微商模式,社交电商系统 坐标:厦门,我是易创客肖琳 深耕社交新零售行业10年,主要提供新零售系统工具及顶层商业模式设计、全案策划运营陪跑等。 低卡咖啡第一品牌“T97”,突然…...
触摸OpenNJet,感悟云原生
小程一言 云原生使得应用充分利用云计算、容器化和微服务架构等现代技术来构建和运行应用程序。 云原生技术的用处在于提高应用程序的可靠性、可伸缩性和灵活性,加快开发和部署速度,降低成本,提升整体的效率和竞争力。通过采用云原生技术&a…...
UE4 自定义shader获取灯光位置
UE4.26:How to get the direction of specific directional lights in custom node material? - #4 by Arkiras - Rendering - Epic Developer Community Forums 获取灯光位置的shader,应该是这个了...
机器学习(五) ----------决策树算法
目录 1 核心思想 2 决策树算法主要步骤 3 决策树算法的分类 3.1 ID3算法(Iterative Dichotomiser 3): 3.1.1 基本步骤 3.1.2 原理 信息增益 3.1.3 注意事项 3.2 C4.5算法: 3.2.1. 信息增益率 计算公式 3.2.2. 构建决策…...

Redis的数据完全是存在内存中的吗?
是的,Redis的数据完全是存储在内存中的。这也是Redis能够提供非常高速的读写性能的主要原因,尤其适用于需要快速响应的应用场景。然而,虽然Redis将所有数据存储在内存中,但它也提供了持久化机制,可以将数据异步地保存到…...
Linux开发--Linux设备驱动核心
Author: cpu_codeDate: 2020-06-30 16:15:35LastEditTime: 2020-07-01 17:59:23FilePath: \md\Linux\6818_Linux驱动.mdGitee: https://gitee.com/cpu_codeCSDN: https://blog.csdn.net/qq_44226094 Linux设备驱动核心概念 Linux内核中断处理 Linux操作系统下同裸机程序一样…...

vue3引入vant完整步骤
在Vue 3中引入Vant(一个基于Vue的移动端UI组件库)的完整步骤通常包括以下几个部分: 安装Vue CLI(如果你还没有安装的话): npm install -g vue/cli 创建一个新的Vue项目: 假设你希望项目名为my…...

C语言——文件缓冲区
一、用户缓冲区和系统缓冲区 缓冲区的概念确实可以分为多个层次,其中最常见的两个层次是用户缓冲区和系统缓冲区。 这里的用户缓冲区和系统缓冲区都包括输入输出缓冲区。 1、用户缓冲区(User-space Buffer) 用户缓冲区是指由用户程序&…...
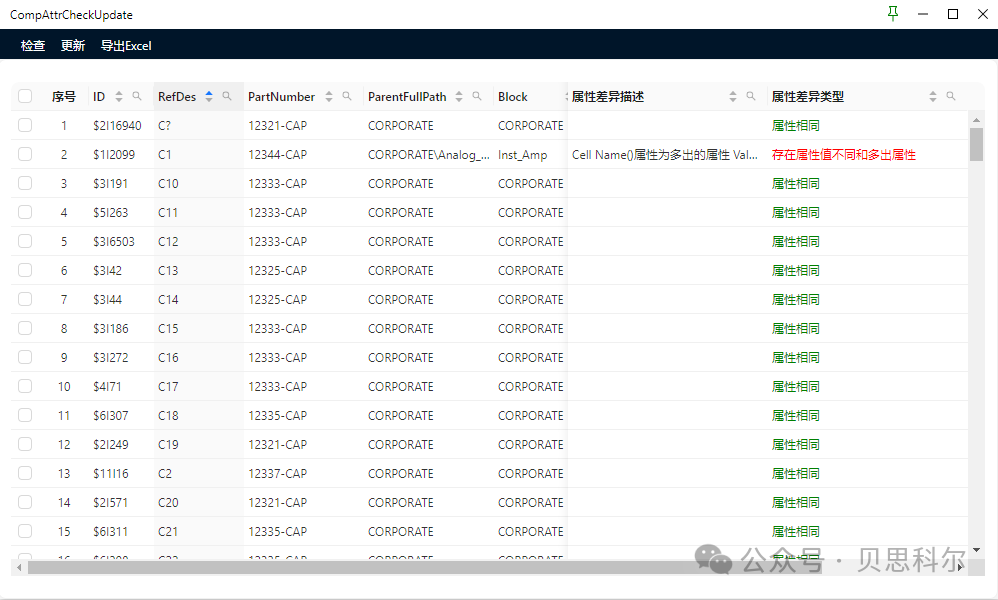
如何快速检测原理图中的元器件与PLM系统的一致性,提高原理图设计准确性
背景介绍 保证原理图中的元器件来源于公司的PLM系统、ERP系统的,是输出有效BOM的根源,初始BOM的准确率,能大大降低ECN的数量,提高生产备料的时效,缩短采购周期。 然而,原理图设计过程中,由于…...

英特尔处理器排行
英特尔的处理器性能排行通常是根据其发布的不同代数和型号来划分的,以下是一些高性能的英特尔处理器: Intel 酷睿 i9 14900K:这是目前英特尔桌面平台中的旗舰处理器之一,提供了极高的性能,适合高端游戏和专业工作负载…...

【日志革新】在ThinkPHP5中实现高效TraceId集成,打造可靠的日志追踪系统
问题背景 最近接手了一个骨灰级的项目,然而在项目中遇到了一个普遍的挑战:由于公司采用 ELK(Elasticsearch、Logstash、Kibana)作为日志收集和分析工具,追踪生产问题成为了一大难题。尽管 ELK 提供了强大的日志分析功…...
)
英译汉早操练-(二十)
hello大家好,这篇跟随十九,继续真题学习。如果想看全部请返回到第十九篇。 英译汉早操练-(十九)-CSDN博客 The political upheaval in Libya and elsewhere in North Africa has opened the way for thousands of new migrants to…...
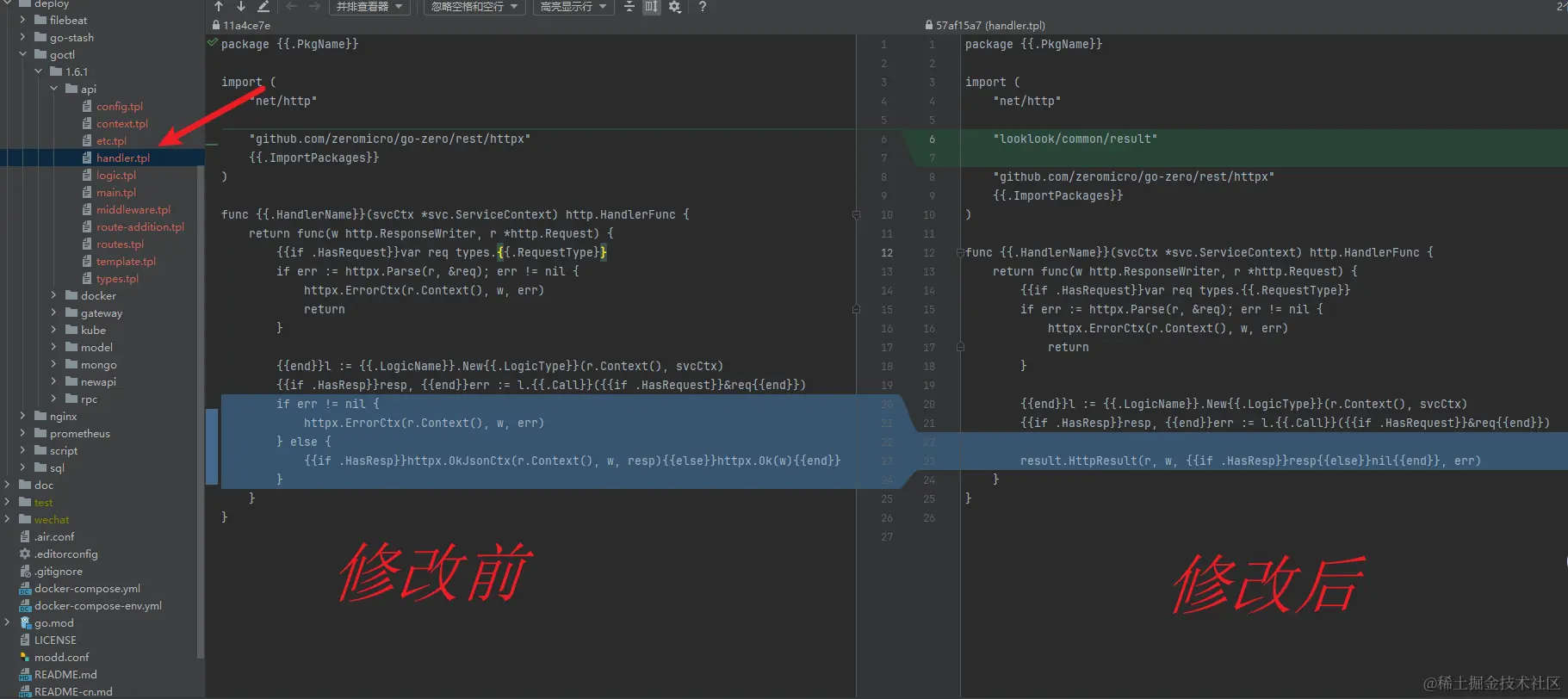
Go-Zero自定义goctl实战:定制化模板,加速你的微服务开发效率(四)
前言 上一篇文章带你实现了Go-Zero和goctl:解锁微服务开发的神器,快速上手指南,本文将继续深入探讨Go-Zero的强大之处,并介绍如何使用goctl工具实现模板定制化,并根据实际项目业务需求进行模板定制化实现。 通过本文…...

(五)STM32F407 cubemx IIC驱动OLED(1)IIC协议篇
(五)STM32F407 cubemx IIC驱动OLED(1)IIC协议篇 这篇文章主要是个人的学习经验,想分享出来供大家提供思路,如果其中有不足之处请批评指正哈。 废话不多说直接开始主题,本人是基于STM32F407V…...

OpenCV特征匹配总结
1.概述 在深度学习出现之前,图像中的特征匹配方法主要有 2.理论对比 3.代码实现 #include <iostream> #include <opencv2/opencv.hpp>int main(int argc, char** argv) {if(argc ! 3) {std::cerr << "Usage: " << argv[0] <…...
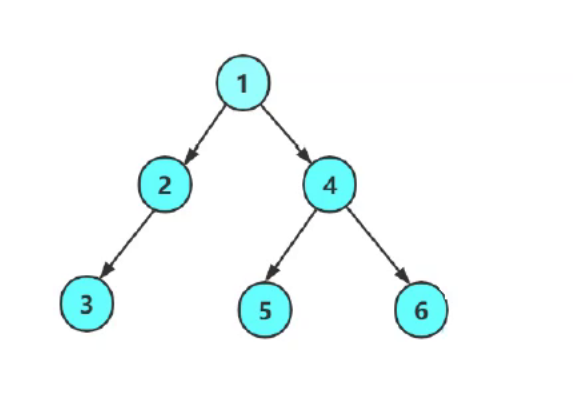
二叉树的四种遍历代码实现
二叉树的遍历大致能分为以下几种 1.前序:根 左 右 2.中序:左 根 右 3.后序:左 右 根 4.层序:从根开始一层一层的向下 如上图访问顺序: 前序:1 2 3 N N N 4 5 N N 6 N N 中序:N 3 N 2 N 1 N 5 N 4 N …...

系统和功能测试:确保软件的功能和易用性
目录 概述 功能测试 LOSED 模型 用例的设计 等价类划分 边界值分析 循环结构测试的综合方法 因果图 决策表 功能图 正交实验设计 易用性测试 内部易用性测试 外部易用性测试 功能性测试 正向功能性测试 负向功能性测试 功能性测试工具 结语 概述 在软件开发…...

BG3 Mod Manager终极指南:如何轻松管理《博德之门3》模组
BG3 Mod Manager终极指南:如何轻松管理《博德之门3》模组 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经因为《博德之门3》模…...

一行环境变量,给 Claude Code 省下 90% 成本
一行环境变量,给 Claude Code 省下 90% 成本 你以为是模型太贵,其实是缓存“漏风”了 🧊💸最近不少开发者发现一个诡异现象: 用了 Claude Code 接国内模型,比如 DeepSeek、Kimi、智谱 AI 后,突然…...

Linux Ext 调度器核心原理:BPF 驱动的自定义调度革命
简介 Linux 内核调度器自诞生以来,始终以通用公平调度(CFS)与硬实时调度(SCHED_DEADLINE/SCHED_FIFO)为核心,支撑服务器、桌面、嵌入式等全场景负载。但传统调度框架存在硬耦合、难扩展、定制成本极高的痛…...

【NotebookLM研究问题生成避坑白皮书】:从0到1构建可复现、可评估、可审计的问题生成工作流
更多请点击: https://intelliparadigm.com 第一章:NotebookLM研究问题生成的定义与核心价值 NotebookLM 是 Google 推出的面向研究者与知识工作者的实验性 AI 工具,其“研究问题生成”(Research Question Generation, RQG&#x…...

别再手动改参数了!用Fluent 2023R1的Parametric模块,5分钟搞定N个工况的批量仿真
Fluent 2023R1参数化模块实战:从单点仿真到智能设计空间探索 在计算流体动力学(CFD)领域,工程师们常常需要面对一个现实困境:如何高效完成数十种工况的参数扫描?传统手动修改边界条件的方式不仅耗时费力&am…...
)
NotebookLM引用格式生成失效真相:Google官方未公开的citation token截断限制(含绕过验证方案)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM引用格式生成失效真相:Google官方未公开的citation token截断限制(含绕过验证方案) NotebookLM 在处理长篇 PDF 或网页源时,常出现引用标记&am…...

STC8单片机按键事件处理代码实现
STC8单片机按键事件处理代码实现 【下载地址】STC8单片机按键事件处理代码实现 本仓库提供了一个用于STC8单片机的按键事件处理代码实现,支持按键的单击、双击和长按事件。该代码设计简洁,易于理解和移植,可以方便地应用于其他单片机平台。 …...

高维光谱数据分析研究与光谱型纳米流式检测系统数据采集处理软件的开发与化学生物学应用【附代码】
✨ 长期致力于光谱型纳米流式检测技术、光谱解耦算法、降维算法、免疫分型、细菌自发荧光研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于泊松回归…...

Magisk:重新定义Android系统定制边界的技术框架
Magisk:重新定义Android系统定制边界的技术框架 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为Android系统定制领域的革命性框架,以其独特的"无系统"&#…...

Warcraft Helper完整指南:让经典魔兽争霸3在现代Windows系统焕发新生
Warcraft Helper完整指南:让经典魔兽争霸3在现代Windows系统焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在Wi…...