【机器学习与实现】K近邻算法
目录
- 一、KNN算法简介
- (一)KNN算法包括三个步骤
- (二)超参数K的影响
- 二、距离度量
- 三、邻近点的搜索算法
- 四、KNN算法的特点
- 五、KNN常用的参数及其说明
- 六、分类算法的性能度量
- (一)混淆矩阵及相关概念
- (二)F1_score和其他度量指标
一、KNN算法简介
想一想:下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类?

1968年,Cover和Hart提出了最初的近邻算法。
(一)KNN算法包括三个步骤
- 算距离:给定测试样本,计算它与训练集中的每个样本的距离;
- 找邻居:圈定距离最近的k个训练样本,作为测试样本的近邻;
- 做分类:根据这k个近邻归属的主要类别,来对测试样本分类。
k值的选择、距离度量和分类决策规则是KNN的3个基本要素。
(二)超参数K的影响

K值取3时,判断绿色点的类别为蓝色; K值取5时,判断绿色点的类别为红色为了能得到较优的K值,可以采用交叉验证和网格搜索的办法分别尝试不同K值下的分类准确性。

当增大k值时,一般错误率会先降低,因为有周围更多的样本可以借鉴了。但当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。

左图为k选取不同值时对鸢尾花分类影响。当k逐步增大时,局部噪音样本对边界的影响逐渐减小,边界形状趋于平滑。较大的k是会抑制噪声的影响,但是使得分类界限不明显。举个极端例子,如果选取k值为训练样本数量,即k=n,采用等权重投票,这种情况不管查询点q在任何位置,预测结果仅有一个(分类结果只能是样本数最多的那一类,kNN这一本来与空间位置相关的算法因此失去了作用)。这种训练得到的模型过于简化,忽略样本数据中有价值的信息。
二、距离度量
1、欧氏距离(Euclidean Distance)
n n n 维空间点 a ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n}) a(x11,x12,...,x1n) 与 b ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},...,x_{2n}) b(x21,x22,...,x2n) 间的欧氏距离(两个 n n n维向量): d 12 = ∑ k = 1 n ( x 1 k − x 2 k ) 2 d_{12}=\sqrt{\sum_{k=1}^n(x_{1k}-x_{2k})^2} d12=k=1∑n(x1k−x2k)2
2、曼哈顿距离(Manhattan Distance)
曼哈顿距离(Manhattan Distance)是指两点在南北方向上的距离加上在东西方向上的距离。
n n n 维空间点 a ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n}) a(x11,x12,...,x1n) 与 b ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},... ,x_{2n}) b(x21,x22,...,x2n) 的曼哈顿距离为 d 12 = ∑ k = 1 n ∣ x 1 k − x 2 k ∣ d_{12}=\sum_{k=1}^n|x_{1k}-x_{2k}| d12=k=1∑n∣x1k−x2k∣

图中两点间的绿线代表的是欧式距离 。红线,蓝线和黄线代表的都是曼哈顿距离,由此可见在两点间曼哈顿距离相等的情况下,线路有多种情况。
3、余弦距离(Cosine Distance)
两个 n n n 维样本点 a ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n}) a(x11,x12,...,x1n) 和 b ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},...,x_{2n}) b(x21,x22,...,x2n) 的夹角余弦为: c o s ( θ ) = a ⋅ b ∣ a ∣ ∣ b ∣ cos(\theta)=\frac{a\cdot b}{|a||b|} cos(θ)=∣a∣∣b∣a⋅b 即 c o s ( θ ) = ∑ n k = 1 x 1 k x 2 k ∑ n k = 1 x 1 k 2 ∑ n k = 1 x 2 k 2 cos(\theta)=\frac{\sum_n^{k=1}x_{1k}x_{2k}}{\sqrt{\sum_n^{k=1}x_{1k}^2\sum_n^{k=1}x_{2k}^2}} cos(θ)=∑nk=1x1k2∑nk=1x2k2∑nk=1x1kx2k
4、切比雪夫距离(Chebyshev Disatance)

切比雪夫距离(Chebyshev Disatance)是指二个点之间的距离定义是其各坐标数值差绝对值的最大值。
D C h e b y s h e v ( p , q ) = max i ( ∣ p i − q i ∣ ) D_{Chebyshev}(p,q)=\max_{i}(|p_i-q_i|) DChebyshev(p,q)=imax(∣pi−qi∣)
这也等于以下 L p L_p Lp 度量的极限: lim k → ∞ ( ∑ i = 1 n ∣ p i − q i ∣ k ) 1 k \lim_{k\to \infty}\left(\sum_{i=1}^n|p_i-q_i|^k\right)^{\frac{1}{k}} k→∞lim(i=1∑n∣pi−qi∣k)k1 因此切比雪夫距离也称为 L ∞ L_{\infty} L∞ 度量(无穷范数)。
国际象棋棋盘上二个位置间的切比雪夫距离是指王要从一个位子移至另一个位子需要走的步数。由于王可以往斜前或斜后方向移动一格,因此可以较有效率的到达目的的格子。上图是棋盘上所有位置距 f 6 f6 f6 位置的切比雪夫距离。
5、闵可夫斯基距离(Minkowski Distance)
闵氏距离的定义:两个 n n n 维变量 a ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n}) a(x11,x12,...,x1n) 与 b ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},...,x_{2n}) b(x21,x22,...,x2n) 间的闵可夫斯基距离定义为: d 12 = ∑ k = 1 n ∣ x 1 k − x 2 k ∣ p p d_{12}=\sqrt[p]{\sum_{k=1}^n\left|x_{1k}-x_{2k}\right|^p} d12=pk=1∑n∣x1k−x2k∣p 其中 p p p 是一个变参数:
- 当 p = 1 p=1 p=1 时,就是曼哈顿距离;
- 当 p = 2 p=2 p=2 时,就是欧氏距离;
- 当 p → ∞ p→\infty p→∞ 时,就是切比雪夫距离。
KNN算法默认使用闵可夫斯基距离。
三、邻近点的搜索算法
KNN算法需要在中搜索与x最临近的k个点,最直接的方法是逐个计算x与中所有点的距离,并排序选择最小的k个点,即线性扫描。
当训练数据集很大时,计算非常耗时,以至于不可行。实际应用中常用的是kd-tree (k-dimension tree) 和ball-tree这两种方法。ball-tree是对kd-tree的改进,在数据维度大于20时,kd-tree性能急剧下降,而ball-tree在高维数据情况下具有更好的性能。
kd-tree以空间换时间,利用训练样本集中的样本点,沿各维度依次对k维空间进行划分,建立二叉树,利用分治思想大大提高算法搜索效率。
样本集不平衡时的影响:
观察下面的例子,对于位置样本X,通过KNN算法,显然可以得到X应属于红点,但对于位置样本Y,通过KNN算法我们似乎得到了Y应属于蓝点的结论,而这个结论直观来看并没有说服力。

由上面的例子可见:该算法在分类时有个重要的不足是,当样本不平衡时,即:一个类的样本容量很大,而其他类样本容量很小时,很有可能导致当输入一个未知样本时,该样本的K个邻居中大数量类的样本占多数。
解决方法:采用权值的方法来改进。和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,避免因一个类别的样本过多而导致误判。
四、KNN算法的特点
优点:
- KNN 理论简单,容易实现;
- 既可以用来做分类也可以用来做回归,还可以用于非线性分类;
- 新数据可以直接加入数据集而不必进行重新训练;
- 对离群点不敏感。
缺点:
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)效果差;
- 不适合高维数据,对于样本容量大的数据集计算量比较大(体现在距离计算上);
- KNN 每一次分类都会重新进行一次全局运算;
- K值不好确定;
- 各属性的权重相同,影响准确率。
五、KNN常用的参数及其说明
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform',algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None,n_jobs=1,**kwargs)
| 参数名称 | 说明 |
|---|---|
| n_neighbors | 接收int。表示近邻点的个数,即K值。默认为5。 |
| weights | 接收str或callable,可选参数有“uniform”和“distance”。表示近邻点的权重,“uniform”表示所有的邻近点权重相等;“distance”表示距离近的点比距离远的点的权重大。默认为“uniform”。 |
| algorithm | 接收str,可选参数有“auto”“ball_tree”“kd_tree”和“brute”。表示搜索近邻点的算法。默认为“auto”,即自动选择。 |
| leaf_size | 接收int。表示kd树和ball树算法的叶尺寸,它会影响树构建的速度和搜索速度,以及存储树所需的内存大小。默认为30。 |
| p | 接收int。表示距离度量公式,1是曼哈顿距离公式;2是欧式距离。默认为2。 |
| metric | 接收str或callable。表示树算法的距离矩阵。默认为“minkowski”。 |
| metric_params | 接收dict。表示metric参数中接收的自定义函数的参数。默认为None。 |
| n_jobs | 接收int。表示并行运算的(CPU)数量,默认为1,-1则是使用全部的CPU。 |
六、分类算法的性能度量
(一)混淆矩阵及相关概念


说明:
(1)结论中的正例、反例以预测值为准,而前面的定语真、假以真实值为准;
(2)预测值与真实值一致,则定语为真,预测值与真实值不一致则定语为假;
(3)主对角线表示预测值与真实值相符,副对角线表示预测值与真实值不符。
相关概念:
- 准确率ACCuracy:全部预测中,预测正确的比例(即主对角线的占比)
- 查准率Precision :预测的正例中,预测正确(真正例)的比例
- 查全率或找回率Recall:真实正例中,预测正确(真正例)的比例
准确率 A C C = T P + T N T P + T N + F N + F P 准确率ACC=\frac{TP+TN}{TP+TN+FN+FP} 准确率ACC=TP+TN+FN+FPTP+TN 查准率 P = T P T P + F P 查准率P=\frac{TP}{TP+FP} 查准率P=TP+FPTP 查全率 R = T P T P + F N 查全率R=\frac{TP}{TP+FN} 查全率R=TP+FNTP
(二)F1_score和其他度量指标
y_true = [1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0]
y_pred = [1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0]

查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往会偏低,查全率高时,查准率往往会偏低。而F1-Score指标综合了Precision与Recall的产出的结果,是F1是基于查准率与查重率的调和平均。F1-Score的取值范围从0到1,1代表模型的输出最好,0代表模型的输出结果最差。
准确率 A C C = 2 + 3 2 + 4 + 3 + 3 = 5 12 准确率ACC=\frac{2+3}{2+4+3+3}=\frac{5}{12} 准确率ACC=2+4+3+32+3=125 查准率 P r e c i s i o n = 3 4 + 3 = 3 7 查准率Precision=\frac{3}{4+3}=\frac{3}{7} 查准率Precision=4+33=73 查全率 R e c a l l = 3 3 + 3 = 3 6 查全率Recall=\frac{3}{3+3}=\frac{3}{6} 查全率Recall=3+33=63 1 F 1 _ s c o r e = 1 2 ⋅ ( 1 P + 1 R ) ⇒ F 1 _ s c o r e = 2 ⋅ P ⋅ R P + R \frac{1}{F1\_score}=\frac{1}{2}\cdot(\frac{1}{P}+\frac{1}{R})\Rightarrow F1\_score=\frac{2\cdot P\cdot R}{P+R} F1_score1=21⋅(P1+R1)⇒F1_score=P+R2⋅P⋅R F 1 _ s c o r e = 2 × 3 7 × 3 6 3 7 + 3 6 = 6 13 F1\_score=\frac{2×\frac{3}{7}×\frac{3}{6}}{\frac{3}{7}+\frac{3}{6}}=\frac{6}{13} F1_score=73+632×73×63=136
此外,还有P-R曲线、ROC曲线、 AUC值等分类性能的指标。
相关文章:
【机器学习与实现】K近邻算法
目录 一、KNN算法简介(一)KNN算法包括三个步骤(二)超参数K的影响 二、距离度量三、邻近点的搜索算法四、KNN算法的特点五、KNN常用的参数及其说明六、分类算法的性能度量(一)混淆矩阵及相关概念(…...
【Python探索之旅】初识Python
目录 发展史: 环境安装: 入门案例: 变量类型 标准数据类型 数字类型: 字符串: 全篇总结: 前言: Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python 的设…...

MongoDB和AI 赋能行业应用:制造业和汽车行业
欢迎阅读“MongoDB和AI 赋能行业应用”系列的第一篇。 本系列重点介绍AI应用于不同行业的关键用例,涵盖制造业和汽车行业、金融服务、零售、电信和媒体、保险以及医疗保健行业。 随着人工智能(AI)在制造业和汽车行业的集成,传统…...

FileZilla一款免费开源的FTP软件,中文正式版 v3.67.0
01 软件介绍 FileZilla 客户端是一个高效且可信的跨平台应用程序,支持 FTP、 FTPS 和 SFTP 协议,其设计宗旨在于为用户提供一个功能丰富且直观的图形界面。此客户端的核心特性包括一个站点管理器,该管理器能有效地存储和管理用户连接详情及登…...

44.WEB渗透测试-信息收集-域名、指纹收集(6)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于: 易锦网校会员专享课 上一个内容: web指纹: 每一个网站,前端开发语言,后端语言&#…...

【面经】Linux
一、高频 1、Linux常见的指令 路径/目录类 cd, mkdir, rmdir, pwd ,ls等重要指令;rmdir 仅能删除空目录,要删除非空目录需使用“ rm -r ”指令;文件类 创建:mkdir文件夹,touch文件移动mv复制cp修改名字mv…...

TriCore:Interrupt 2
今天继续来看看 IR 模块。 名词缩写 缩写全称说明IRInterrupt Router SRService Request 包括: 1. External Resource 2. Internal Resource 3.SW(Software) SPService Privoder 包括: 1. CPU 2. DMA SRNService Request NodeS…...
ollama api只能局域网访问,该怎么破?
安装ollama: ollama离线安装,在CPU运行它所支持的那些量化的模型-CSDN博客文章浏览阅读178次,点赞2次,收藏6次。ollama离线安装,在CPU运行它所支持的哪些量化的模型 总共需要修改两个点,第一:Ollama下载地址;第二:Ollama安装包存放目录。第二处修改,修改ollama安装目…...

规则引擎drools Part5
规则引擎drools Part5 Drools Workbench Drools Workbench是可视化的规则编辑器,用来授权和管理业务规则。workbench的war包下载地址,安装到tomcat中就可以运行了。使用workbench可以在浏览器中创建数据对象、规则文件、测试场景并把规则部署到maven仓…...

API设计之争:一个接口一个职能还是一个页面所需字段?
在软件开发中,设计API接口是一个重要而且复杂的任务。在设计API接口时,一个常见的问题是,是按照每个接口的职能来设计,还是按照每个页面所需的字段来设计? 本文将对这两种设计方法进行比较,并探讨它们的优…...

第一天复习Qt文件读取
Qt文件操作: 1、QFile QTextStream操作文件案例: 1、打开文件 QFile file(absolute filepath | relative path); file.readLine()返回内容长度,如果为-1就是读取失败 file. Close()读取后关闭 file.errorString()返回文件打开发生的错误2、…...
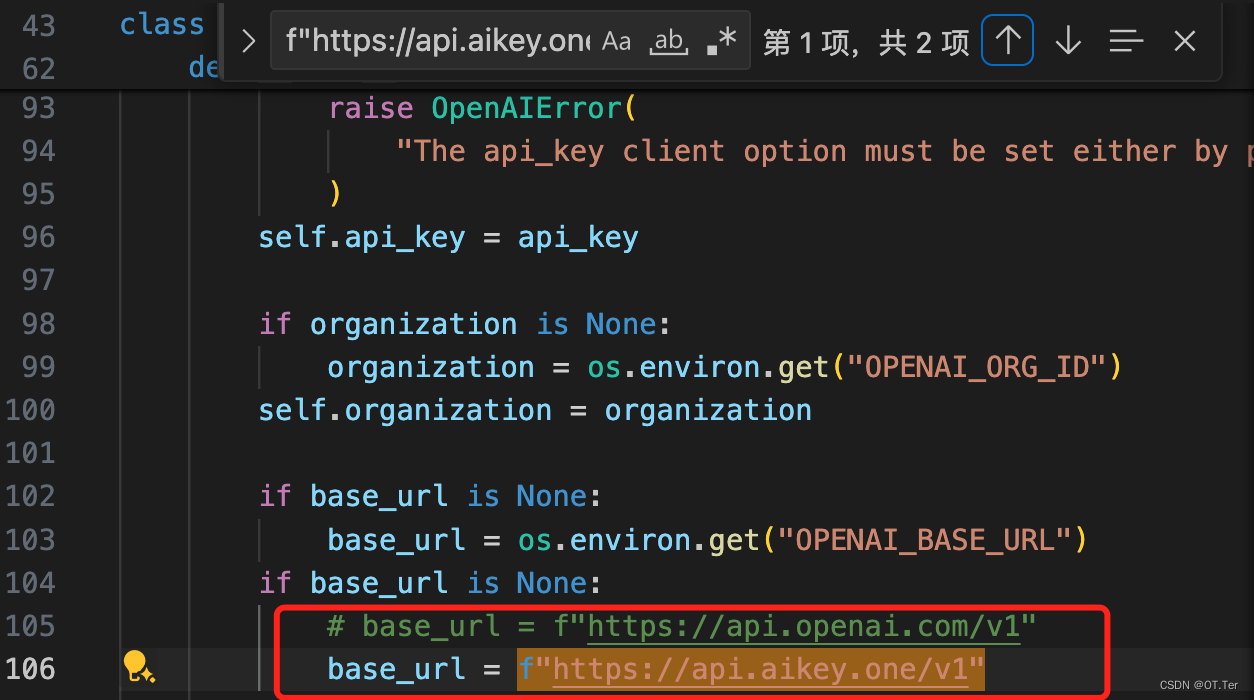
使用非官网购买Chatgpt的api调用
测试代码 from openai import OpenAI client OpenAI(api_key用户密钥) import json import os import timeclass ChatGPT:def __init__(self, user):self.user userself.messages [{"role": "system", "content": "Agent"}]def as…...

通过 Java 操作 redis -- hash 哈希表基本命令
目录 使用命令 hset,hget 使用命令 hexists 使用命令 hdel 使用命令 hkeys,hvals 使用命令 hmget,hmset 关于 redis hash 哈希表类型的相关命令推荐看Redis - hash 哈希表 要想通过 Java 操作 redis,首先要连接上 redis 服务…...

Unity 性能优化之遮挡剔除(Occlusion Culling)(六)
提示:仅供参考,有误之处,麻烦大佬指出,不胜感激! 文章目录 前言一、遮挡剔除是什么?二、静态遮挡剔除的使用步骤1.标记为遮挡剔除对象2.创建Occlusion Area组件3.烘焙4.Occlusion窗口Bake的参数Smallest Oc…...

android——关于app性能优化篇
前言 应用性能优化是指通过各种技术手段和优化策略,提高应用程序的性能,使其能够更高效地运行和响应用户操作。 下面介绍一些常见的应用性能优化方法 一、布局优化 1、减少嵌套 嵌套层数尽量少,使用ConstaintLayout能使层级大大降低尽量使…...

单链表经典算法LeetCode--203.移除链表元素(两种方法解)
1.链接:. - 力扣(LeetCode)【点击即可跳转】 分析此题提供两种思路: 1.遍历原链表,将值为val的节点释放掉(双指针法) 定义一个pcur指针指向头节点,定义一个prev指针指向NULL 需要注…...

MySQL—子查询
目录 ▐ 子查询概述 ▐ 准备工作 ▐ 标量子查询 ▐ 列子查询 ▐ 表子查询 ▐ 多信息嵌套 ▐ 子查询概述 • 子查询也称嵌套查询,即在一个查询语句中又出现了查询语句 • 子查询可以出现在from 后面 或where后面 • 出现在 from 后称表子查询,结…...

ffmpeg 读取流报错: Non-monotonous DTS in output stream
在处理媒体文件时,我们可能会遇到各种错误,其中之一就是“Non-monotonous DTS in output stream 0:1; previous: 36963866, current: 36611997; changing to 36963867. This may result in incorrect timestamps in the output file.”这个错误通常发生在…...

yo!这里是socket网络编程相关介绍
目录 前言 基本概念 源ip&&目的ip 源端口号&&目的端口号 udp&&tcp初识 socket编程 网络字节序 socket常见接口 socket bind listen accept connect 地址转换函数 字符串转in_addr in_addr转字符串 套接字读写函数 recvfrom&&a…...

polars学习-03 数据类型转换
背景 polars学习系列文章,第3篇 数据类型转换。 该系列文章会分享到github,大家可以去下载jupyter文件 仓库地址:https://github.com/DataShare-duo/polars_learn 小编运行环境 import sysprint(python 版本:,sys.version.spli…...

Windows资源管理器STL缩略图革命:3D模型可视化管理的终极解决方案
Windows资源管理器STL缩略图革命:3D模型可视化管理的终极解决方案 【免费下载链接】STL-thumbnail Shellextension for Windows File Explorer to show STL thumbnails 项目地址: https://gitcode.com/gh_mirrors/st/STL-thumbnail 还在为海量STL文件的管理而…...

从零到发刊:NotebookLM在有机合成路线设计中的7步闭环工作法,北大化学院实验室内部培训材料首次公开
更多请点击: https://codechina.net 第一章:NotebookLM化学研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为深度阅读、知识整合与推理设计。在化学研究场景中,它可高效处理文献 PDF、实验记录、光谱数据报告及教…...

Windows上安装Android应用的终极指南:告别模拟器,开启全新跨平台体验
Windows上安装Android应用的终极指南:告别模拟器,开启全新跨平台体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾在Windows电脑上渴…...

5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐
5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

FastGithub终极加速指南:3步解决GitHub访问卡顿难题
FastGithub终极加速指南:3步解决GitHub访问卡顿难题 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub GitHub加速是每个国内开发者都关心的话题。你是否经常因…...
)
手把手教你用kafka-storage.sh修复Kafka KRaft模式启动报错(附UUID生成与格式化全流程)
手把手教你用kafka-storage.sh修复Kafka KRaft模式启动报错(附UUID生成与格式化全流程) 当Kafka集群从ZooKeeper模式迁移到KRaft模式时,技术人员常会遇到因元数据问题导致的启动失败。本文将深入解析kafka-storage.sh工具的核心功能ÿ…...

如何让GBFR-Logs成为你的碧蓝幻想Relink战斗分析利器
如何让GBFR-Logs成为你的碧蓝幻想Relink战斗分析利器 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr-logs 你是否在《碧蓝幻…...

对比直接使用厂商 API 通过 Taotoken 聚合调用的账单清晰度差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 与通过 Taotoken 聚合调用的账单清晰度差异 在集成多个大语言模型到业务中时,开发者通常会面临一…...

PUBG终极雷达系统免费搭建:从战场盲人到战术大师的完整指南
PUBG终极雷达系统免费搭建:从战场盲人到战术大师的完整指南 【免费下载链接】PUBG-maphack-map this is a working copy online-map from jussihi/PUBG-map-hack, use nodejs webserver instead of firebase. 项目地址: https://gitcode.com/gh_mirrors/pu/PUBG-m…...

初创公司如何借助Taotoken管理多模型API调用与成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何借助Taotoken管理多模型API调用与成本 对于资源有限的初创技术团队而言,快速迭代产品并集成多种AI能力是常…...