Python 正则表达式(一)
文章目录
- 概念
- 正则函数
- `match`函数
- 正则表达式修饰符
- 意义:
- 常用匹配符
- 限定符
- 原生字符串
- 边界字符
概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑(可以用来做检索,截取或者替换操作)。
作用
给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”)。
可以通过正则表达式,从字符串中获取我们想要的特定部分。
还可以对目标字符串进行替换操作。
Python语言通过标准库中的re模块支持正则表达式。re模块提供了一些根据正则表达式进行查找、替换、分隔字符串的函数,这些函数使用一个正则表达式作为第一个参数。
正则函数
| 函数 | 描述 |
|---|---|
match(pattern,string,flags=0) | 根据pattern从string的头部开始匹配字符串,只返回第1次匹配成功的对象;否则,返回None |
findall(pattern,string,flags=0) | 根据pattern在string中匹配字符串。如果匹配成功,返回包含匹配结果的列表;否则,返回空列表。当pattern中有分组时,返回包含多个元组的列表,每个元组对应1个分组。flags表示规则选项,规则选项用于辅助匹配。 |
sub(pattern,repl,string,count=0) | 根据指定的正则表达式,替换源字符串中的子串。pattern是一个正则表达式,repl是用于替换的字符串,string是源字符串。如果count等于0,则返回string中匹配的所有结果;如果count大于0,则返回前count个匹配结果 |
subn(pattern,repl,string,count=0) | 作用和sub()相同,返回一个二元的元组。第1个元素是替换结果,第2个元素是替换的次数 |
search(pattern,string,flags=0) | 根据pattern在string中匹配字符串,只返回第1次匹配成功的对象。如果匹配失败,返回None |
compile(pattern,flags=0) | 编译正则表达式pattern,返回1个pattern的对象 |
split(pattern,string,maxsplit=0) | 根据pattern分隔string,maxsplit表示最大的分隔数 |
escape(pattern) | 匹配字符串中的特殊字符,如*、+、?等 |
match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。语法格式如下:
re.match(pattern, string, flags=0)
| 参数 | 描述 |
|---|---|
pattern | 匹配的正则表达式 |
string | 要匹配的字符串。 |
flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。如下表列出正则表达式修饰符 - 可选参数 |
正则表达式修饰符
| 修饰符 | 描述 |
|---|---|
re.I | 使匹配对大小写不敏感 |
re.L | 做本地化识别(locale-aware)匹配 |
re.M | 多行匹配,影响 ^ 和 $ |
re.S | 使 . 匹配包括换行在内的所有字符 |
re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
意义:
re.match是用来进行正则匹配检查的方法,如果字符串开头的0个或多个字符匹配正则表达式模式,则返回相应的match对象。如果字符串不匹配模式,返回None(注意不是空字符串"")
匹配对象Match Object具有group()方法, 用来返回字符串的匹配部分,具有span()方法。返回匹配字符串的位置(元组存储开始,结束位置),具有start(),end()方法,存储匹配数据的开始和结束位置。(也可以通过对象的dir(对象查看对象的方法))
如果想在目标字符串的任意位置查找,需要使用search
示例
import re
s='hello python'
pattern='hello'
v=re.match(pattern,s)
print(v)
print(v.group()) #group函数接受一个参数,表示要获取第几个子字符串,默认为0,表示获取整个匹配到的字符串。
print(v.span()) #span() 是 re 模块中的一个函数,它用于在字符串中搜索模式并返回匹配的起始和结束位置
输出结果
<re.Match object; span=(0, 5), match=‘hello’>
hello
(0, 5)
import re
s = 'hello Python!'
m=re.match('hello python',s,re.I) #忽略大小写
if m is not None:print('匹配成功结果是:',m.group())
else:print('匹配失败')
输出结果
匹配成功结果是: hello Python
常用匹配符
| 符号 | 描述 |
|---|---|
. | 匹配任意一个字符(除了\n) |
[] | 匹配列表中的字符 |
\w | 匹配字母、数字、下划线,即az,AZ,0~9 |
\W | 匹配不是字母、数字、下划线 |
\s | 匹配空白字符,即空格(\n,\t) |
\S | 匹配不是空白的字符 |
\d | 匹配数字,即0~9 |
\D | 匹配非数字的字符 |
一个正则表达式是由**字母、数字和特殊字符(括号、星号、问号等)**组成。正则表达式中有许多特殊的字符,这些特殊字符是构成正则表达式的要素。
import re
pattern='.' #匹配任意一个字符(除了\n)
s='a'
print('匹配字符a:',re.match(pattern,s))
s='C'
print('匹配字符C:',re.match(pattern,s))
s='_'
print('匹配字符_:',re.match(pattern,s))
s='\n'
print('匹配字符\\n:',re.match(pattern,s))
输出结果
匹配字符a: <re.Match object; span=(0, 1), match=‘a’>
匹配字符C: <re.Match object; span=(0, 1), match=‘C’>
匹配字符_: <re.Match object; span=(0, 1), match=‘_’>
匹配字符\n: None
import re
pattern='\d' #匹配数字,即0-9
s='9'
print('匹配数字9:',re.match(pattern,s))
s='4'
print('匹配数字4:',re.match(pattern,s))
s='a'
print('匹配字符a:',re.match(pattern,s))
s='_'
print('匹配字符_:',re.match(pattern,s))
输出结果
匹配数字9: <re.Match object; span=(0, 1), match=‘9’>
匹配数字4: <re.Match object; span=(0, 1), match=‘4’>
匹配字符a: None
匹配字符_: None
限定符
如果要匹配手机号码,按上面的理解需要形如“\d\d\d\d\d\d\d\d\d\d\d”这样的正则表达式。其中表现了11次“\d”,表达方式烦琐。正则表达式作为一门小型的语言,还提供了对表达式的一部分进行重复处理的功能。例如,“*”可以对正则表达式的某个部分重复匹配多次。这种匹配符号称为限定符。
| 符号 | 描述 | 符号 | 描述 |
|---|---|---|---|
| * | 匹配零次或多次 | {m} | 重复m次 |
+ | 匹配一次或多次 | {m,n} | 重复m到n次,其中n可以省略,表示m到任意次 |
? | 匹配一次或零次 | {m,} | 至少m次 |
import re
print('------*匹配零次或多次--------')
pattern='\d*' #0次或多次
s='123abc'
print('匹配123abc:',re.match(pattern,s)) ## 结果是123
s='abc' #这时候不是None而是''
print('匹配abc:',re.match(pattern,s)) ## 结果是''
print('-----+匹配一次或多次---------')
pattern='\d+' #1次或多次
s='123abc'
print('匹配123abc:',re.match(pattern,s)) ##结果是123
s='abc' #这时候是None
print('匹配abc:',re.match(pattern,s))
print('-----?匹配一次或零次---------')
pattern='\d?' #0次或1次
s='123abc'
print('匹配123abc:',re.match(pattern,s))
s='abc' #这时候是空
print('匹配abc:',re.match(pattern,s))
import re
print('-----{m}重复m次---------')
pattern='\d{3}' #匹配数字,出现3次
s='123abc'
print('pattern为\\d{3}匹配123abc结果:',re.match(pattern,s))
pattern='\d{4}' #匹配数字,出现4次,这时候结果为空
print('pattern为\\d{4}匹配123abc结果:',re.match(pattern,s))
print('-----{m,}至少m次---------')
s='1234567abc'
pattern='\d{3,}' #重复大于3次 尽可能满足的都返回 这时候结果为1234567
print('pattern为\\d{3,}匹配1234567abc结果:\n',re.match(pattern,s))
print('-----{m,n}重复m到n次---------')
pattern='\d{2,4}' #重复2到4次,这时候结果为1234
print('pattern为\\d{2,4}匹配1234567abc结果:\n',re.match(pattern,s))
【示例】匹配出一个字符串首字母为大写字符,后边都是小写字符,这些小写字母可有可无
pattern='[A-Z][a-z]*'
s='Hello world'
s='HEllo world'
v=re.match(pattern,s)
print(v) #输出结果为 <re.Match object; span=(0, 1), match='H'>匹配出有效的变量名,开头以字母、下划线开始变量名为有效变量名,其余不是
import re
pattern='[A-Za-z_][0-9A-Za-z_]*'
print('pattern为[A-Za-z_][0-9A-Za-z_]*')
s='a'
print('匹配变量名a的结果:',re.match(pattern,s))
s='ab'
print('匹配变量名ab的结果:',re.match(pattern,s))
s='_ab'
print('匹配变量名_ab的结果:',re.match(pattern,s))
s='2ab'
print('匹配变量名2ab的结果:',re.match(pattern,s))
print('pattern为[A-Za-z_]\w*')
pattern='[A-Za-z_]\w*'
s='a'
print('匹配变量名a的结果:',re.match(pattern,s))
s='ab'
print('匹配变量名ab的结果:',re.match(pattern,s))
s='_ab'
print('匹配变量名_ab的结果:',re.match(pattern,s))
s='2ab'
print('匹配变量名2ab的结果:',re.match(pattern,s))
匹配1-99的数字
import re
pattern='[1-9]\d?' #匹配1-9的数字或0~9,匹配1次或0次
s='1'
print('匹配数字1:',re.match(pattern,s))
s='55'
print('匹配数字55:',re.match(pattern,s))
s='99'
print('匹配数字99:',re.match(pattern,s))
s='199'
print('匹配数字199:',re.match(pattern,s))
匹配数字1: <re.Match object; span=(0, 1), match=‘1’>
匹配数字55: <re.Match object; span=(0, 2), match=‘55’>
匹配数字99: <re.Match object; span=(0, 2), match=‘99’>
匹配数字199: <re.Match object; span=(0, 2), match=‘19’>
【示例】匹配出一个随机密码8-20位以内 (大写字母 小写字母 下划线 数字)
import re
pattern='\w{8,20}'
m='m1548_1223'
print("匹配结果:",re.match(pattern,m))
原生字符串
和大多数编程语言相同,正则表达式里使用“\”作为转义字符,这就可以能造成反斜杠困扰。
s = 'c:\\a\\b\\c'
print(s) # 结果是 c:\a\b\c
s = '\n123'
print(s) #结果是 换行 123
s = '\\n123'
print(s)#结果是 \n123
假如你需要匹配文本中的字符“\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠“\\”:前面两个和后两个分别用于在编程语
言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,使用Python的r前缀。例如匹配一个数字的“\d”可以写成r“\d”。有了原生字符串,再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
import re
s = r'\n123'
print(s) #输出结果是 \n123
#目标字符串
s = '\\n123'
pattern = '\\n\d{3}'
print(re.match(pattern,s)) #返回None
#如果想匹配两个反斜杠需要使用两个反斜杠作为转义,即正则中要写四个反斜杠
pattern = '\\\\n\d{3}'
print(re.match(pattern,s))
#使用原生字符串r比较方便
pattern = r'\\n\d{3}'
print(re.match(pattern,s))
边界字符
| 字符 | 功能 |
|---|---|
^ | 匹配字符串开头 |
$ | 匹配字符串结尾 |
\b | 匹配一个单词的边界 |
\B | 匹配非单词的边界 |
$的使用
import re
#匹配qq邮箱, 5-10位
print('未限制结尾'.center(30,'-'))
pattern = '[\d]{5,10}@qq.com'
print('正确的邮箱匹配结果:\n',re.match(pattern,'12345@qq.com'))
print('不正确的邮箱匹配结果:\n',re.match(pattern,'12345@qq.comabc'))
print('限制结尾'.center(30,'-'))
pattern = '[1-9]\d{4,9}@qq.com$'
print('正确的邮箱匹配结果:\n',re.match(pattern,'12345@qq.com'))
print('不正确的邮箱匹配结果:\n',re.match(pattern,'12345@qq.comabc'))
------------未限制结尾-------------
正确的邮箱匹配结果:
<re.Match object; span=(0, 12), match=‘12345@qq.com’>
不正确的邮箱匹配结果:
<re.Match object; span=(0, 12), match=‘12345@qq.com’>
-------------限制结尾-------------
正确的邮箱匹配结果:
<re.Match object; span=(0, 12), match=‘12345@qq.com’>
不正确的邮箱匹配结果:
None
\b的使用
pattern = r'.*\bab'
#ab左边界的情况
v = re.match(pattern,'123 abr')
print(v)
pattern = r'.*ab\b'
#ab为右边界的情况
v = re.match(pattern,'wab')
print(v)
<re.Match object; span=(0, 6), match=‘123 ab’>
<re.Match object; span=(0, 3), match=‘wab’>
相关文章:
)
Python 正则表达式(一)
文章目录 概念正则函数match函数正则表达式修饰符意义: 常用匹配符限定符原生字符串边界字符 概念 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个…...

Cocos Creator 3.8.x报错:5302
在小游戏加载某个bundle后,如果报以下错误: 5302:Can not find class %s 说明bundle中某个预制件*.prefab引用了未加载的bundle的资源。 解决方法有两个: 1、将引用的资源移到预制件*.prefab相同的bundle下; 2、将…...

网页如何集成各社区征文活动
Helllo , 我是小恒 由于我需要腾讯云社区,稀土掘金以及CSDN的征文活动RSS,找了一下没发现,所以使用GET 请求接口对网页定时进行拉取清洗,甚至无意间做了一个简单的json格式API 最终网址:hub.liheng.work API:http://hub.liheng.wo…...

【知识碎片】2024_05_13
本文记录了两道代码题【自除数】和【除自身以外数组的乘积】(利用了前缀积和后缀积,值得再看),第二部分记录了关于指针数组和逗号表达式的两道选择题。 每日代码 自除数 . - 力扣(LeetCode) /*** Note: T…...

Day53代码随想录动态规划part13:300.最长递增子序列、674. 最长连续递增序列、718. 最长重复子数组
Day52 动态规划part13 300.最长递增子序列 leetcode链接:300. 最长递增子序列 - 力扣(LeetCode) 题意:给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。子序列是由数组派生而来的序列,删除&a…...

自己动手为wordpress注册一个Carousel轮播区块
要为WordPress注册一个Carousel轮播区块,你可以创建一个自定义Gutenberg块。以下是一个简单的示例,说明如何创建一个Carousel轮播区块: 1. 在你的主题目录中创建一个名为carousel-block的子文件夹。在这个文件夹中,创建一个名为c…...

基于Springboot的实习生管理系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的实习生管理系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构&a…...
良心实用的电脑桌面便利贴,好用的便利贴便签小工具
在日常办公中,上班族经常需要记录临时任务、重要提醒或者突发的灵感。比如,在紧张的项目会议中,忽然想到一个改进的点子,或者是在处理邮件时,需要记下对某个客户的回复要点。在这些场景下,如果能直接在电脑…...
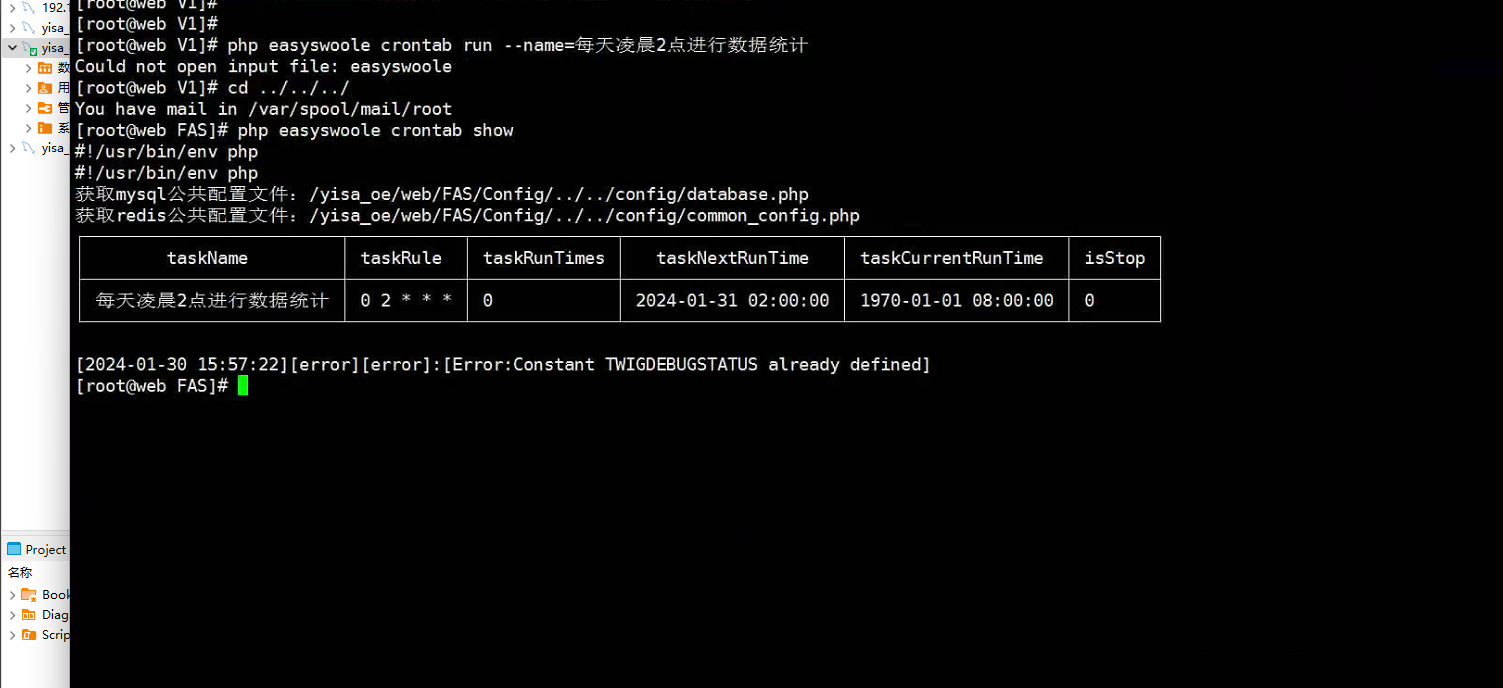
Eayswoole 报错 crontab info is abnormal
在执行一个指定的定时任务时 如 php easyswoole crontab show 报错 crontab info is abnormal 如下图所示: 查询了半天 修改了如下配置: 旧的 // 创建定时任务实例 $crontab new \EasySwoole\Crontab\Crontab($crontabConfig); 修改后&#…...

移动 App 入侵与逆向破解技术-iOS 篇
如果您有耐心看完这篇文章,您将懂得如何着手进行app的分析、追踪、注入等实用的破解技术,另外,通过“入侵”,将帮助您理解如何规避常见的安全漏洞,文章大纲: 简单介绍ios二进制文件结构与入侵的原理介绍入…...

2024服贸会,参展企业媒体宣传报道攻略
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 2024年中国国际服务贸易交易会(简称“服贸会”)是一个重要的国际贸易平台,对于参展企业来说,有效的媒体宣传报道对于提升品牌知名度、扩大…...
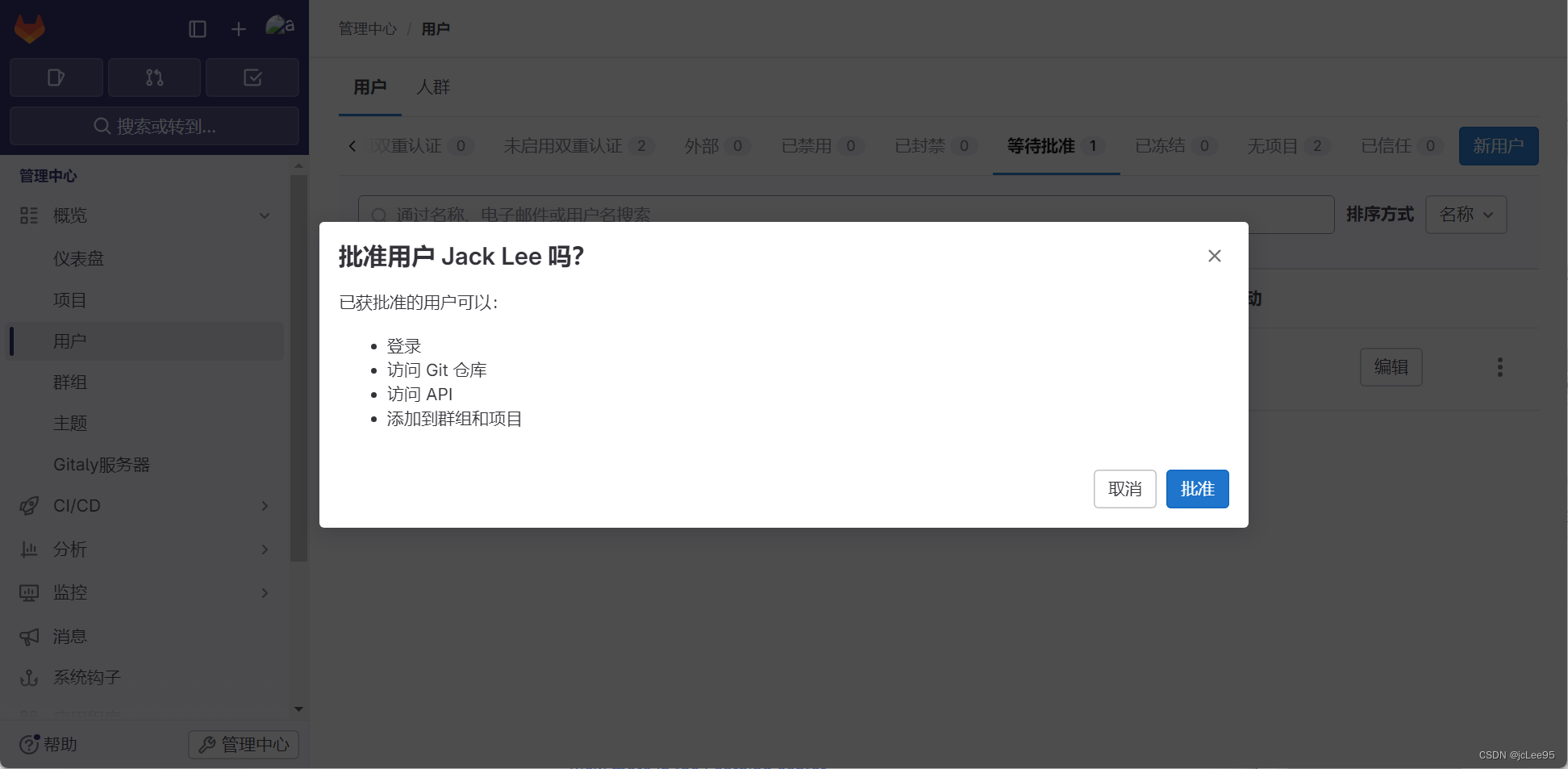
CI/CD笔记.Gitlab系列.新用户管理
CI/CD笔记.Gitlab系列 新用户管理 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/qq_285502…...

前端 JS 经典:JS 基础类型和 typeof
前言:JS 基础类型就 8 种,这是官方确定的,毋庸置疑。其中原始类型 7 种,对象类型 1 种。而 typeof 关键字是用来判断数据是属于什么类型的。 1. 原始类型 Number、Boolean、String、BigInt、symbol、Undefined、null typeof 18…...
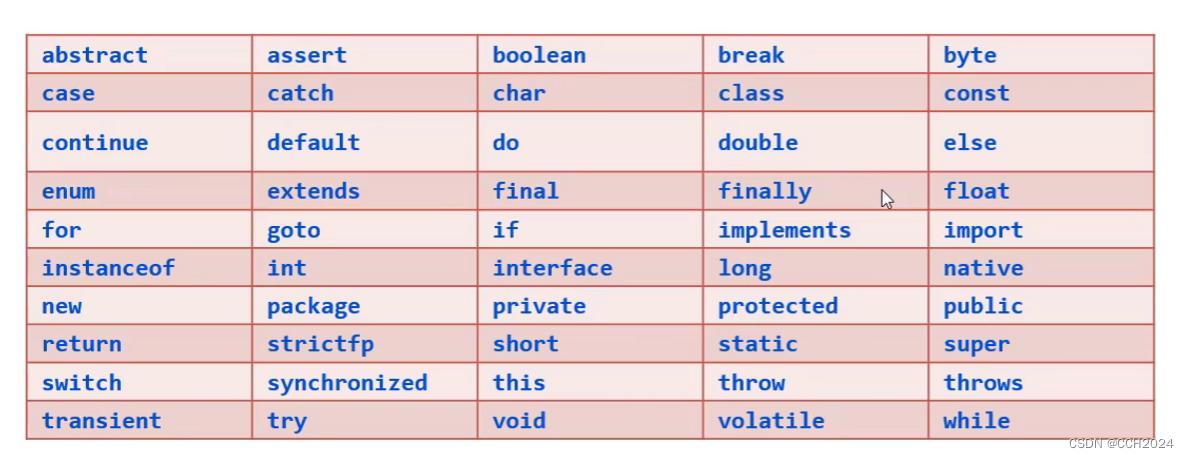
Java入门基础学习笔记11——关键字和标识符
1、关键字 关键字是java中已经被赋予特定意义的,有特殊作用的一些单词,不可以把这些单词作为标识符来使用。 注意:关键字是java用了的,我们就不能用来作为:类名、变量名、否则会报错。 标识符: 标识符就是…...

设计模式-解释器模式(Interpreter)
1. 概念 解释器模式(Interpreter Pattern)是一种行为型设计模式,它用于定义一个语言的文法,并解析语言中的表达式。具体来说,解释器模式通过定义一个解释器来解释语言中的表达式,从而实现对语言的解析和执…...
机器视觉任务中语义分割方法的进化历史
机器视觉任务中语义分割方法的进化历史 一、基于传统方法的图像分割二、基于卷积神经网络的图像分割三、基于Attention机制的图像分割四、语义分割模型的挑战与改进 在图像处理领域,传统图像分割技术扮演着重要角色。 一、基于传统方法的图像分割 这些方法包括大津…...
Java并发编程: Synchronized锁升级
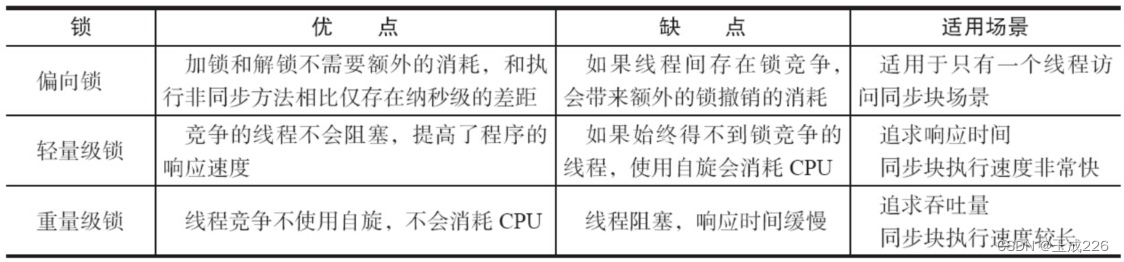
文章目录 一、jdk8 markword实现表二、使用工具来查看锁升级三、默认synchronized(o) 一、jdk8 markword实现表 为什么有自旋锁还需要重量级锁: 自旋消耗CPU资源,如果锁的时间长,或者自旋线程多,CPU会被大量消耗。重量…...

Atcoder C - Routing
https://atcoder.jp/contests/arc177/tasks/arc177_c 思路:该问题可以归约为最短路问题,问题中的条件1和条件2是相互独立的,可以分开考虑,从地图中的一个点,沿上下左右四个方向走,所花费的代价为࿱…...

升级! 测试萌新Python学习之连通数据库Pymsql增删改及封装(四)
pymysql 数据库概述python对数据库的增删改查pymysql核心操作事务事务操作pymysql工具类封装每日复习ChatGPT的回答 数据库概述 分类 关系型数据库: 安全 如, mysql oracle SQLite…database tables 行列 非关系型数据库: 高效 如, redis mongoDB…数据存储结构多样 键值对…...

【大数据】containered学习笔记
文章目录 1. Containerd安装1.1 YUM方式安装 【后端&网络&大数据&数据库目录贴】 1. Containerd安装 1.1 YUM方式安装 获取YUM源 获取阿里云YUM源 wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 查…...

5个高效Adobe Illustrator脚本,让你的设计效率提升300%
5个高效Adobe Illustrator脚本,让你的设计效率提升300% 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Adobe Illustrator中的重复性设计任务烦恼吗?你…...

Super IO:Blender剪贴板导入导出神器,让3D工作流效率翻倍
Super IO:Blender剪贴板导入导出神器,让3D工作流效率翻倍 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io 你是否厌倦了在Blender中反复点击文件菜单、浏览文件夹…...

Mac应用彻底清理指南:使用Pearcleaner免费开源工具释放存储空间
Mac应用彻底清理指南:使用Pearcleaner免费开源工具释放存储空间 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是不是经常发现Mac电脑的存储空…...

如何高效解决Windows游戏控制器兼容性问题:ViGEmBus驱动完整指南
如何高效解决Windows游戏控制器兼容性问题:ViGEmBus驱动完整指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款专业的Windows内…...

HarmonyOS 6学习:水平仪气泡移动方向错误的完整分析与修复方案
从"反向移动"到"精准指向":一次完整的传感器应用开发经历在HarmonyOS 6应用开发中,我最近负责开发一个建筑工具应用,其中包含一个水平仪功能。这个功能对建筑工人和DIY爱好者来说非常实用——通过手机传感器检测设备倾斜…...

2026年5月21隔夜暗盘挂单排行榜
推荐好文:每年节约五六千交易费不香吗如何获取龙虎榜是否有量化参与如何获取股东减持信息大A有5400多只股票, 这里面只有不到10%, 约500只由资金投票, 剩余的都是杂毛, 炒股看龙头找主线. 从隔夜挂单里选择, 再叠加我们之前分享的如何判断是否有大股东减持, 是否有融资融券参与…...

城通网盘下载速度慢?3分钟学会ctfileGet终极免费提速方案
城通网盘下载速度慢?3分钟学会ctfileGet终极免费提速方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经被城通网盘的龟速下载折磨得抓狂?面对50KB/s的限速、无尽的验…...

嵌入式开发新趋势:从硬件参数到场景方案,AI与可靠性成关键
1. 展会现场与行业风向初探上周,我作为飞凌嵌入式的一名老员工,亲身参与了2024上海国际嵌入式展。这不仅仅是一次简单的产品展示,更像是一场行业同仁的“华山论剑”。从人头攒动的展台到技术论坛上激烈的讨论,你能清晰地感受到&am…...

无风扇嵌入式主板:静默革命,如何重塑工业自动化与边缘计算的可靠性?
1. 项目概述:为什么嵌入式主板要“静悄悄”?在工业自动化、智能终端、医疗设备这些对稳定性和可靠性要求极高的领域里,你经常会听到设备内部风扇“呼呼”作响的声音。这声音背后,是传统工控机或PC架构主板为了散热而不得不做的妥协…...

手把手教你把Windows虚拟内存文件pagefile.sys从C盘挪走,给SSD系统盘腾出几十G空间
彻底解放C盘空间:Windows虚拟内存文件迁移全指南 你是否遇到过这样的场景:刚装完系统时C盘还剩下大半空间,用着用着却突然弹出"磁盘空间不足"的警告?打开资源管理器一看,一个名为pagefile.sys的"巨无霸…...