《TAM》论文笔记(上)
原文链接
[2005.06803] TAM: Temporal Adaptive Module for Video Recognition (arxiv.org)
原文代码
GitHub - liu-zhy/temporal-adaptive-module: TAM: Temporal Adaptive Module for Video Recognition
原文笔记
What:
TAM: Temporal Adaptive Module for Video Recognition
根据视频帧的不同的特征图自适应的生成卷积核:两阶段自适应方案
模型有点:体积小,可插拔,适应性强,效果好
Why:
由于相机运动、速度变化和不同活动等因素,视频数据具有复杂的时间动态。为了有效地捕捉这种多样化的运动模式,本文提出了一种新的时间自适应模块(TAM),根据自己的特征图生成视频特定的时间核。
视频理解的深度学习研究进展相对较慢,部分原因是视频数据的高度复杂性。视频理解的核心技术问题是设计一个有效的时间模块,该模块有望能够以高灵活性捕获复杂的时间结构,同时以低计算量实现对高维视频数据的高效处理
上述所有方法都有一个共同的见解,即它们是视频不变的,而忽略了视频中固有的时间多样性。
3D卷积神经网络(3D CNN)[15,34]已被证明是视频建模的主流架构[1,8,36,27]。3D卷积(时间卷积)仅仅通过使用固定数量的固定参数的视频卷积核可能缺乏足够的表示能力来描述运动多样性,
3D 卷积是2D卷积的直接扩展,并为视频识别提供了一个可学习的算子。然而,这种简单的扩展缺乏对视频数据中的时间属性的特定考虑,并且也可能导致高计算成本。因此,最近的方法旨在通过将轻量级时间模块与 2D CNN 相结合来提高效率(例如 TSN [40]、TSM [23])或设计一个专用时间模块来更好地捕获时间关系(例如,非本地网络 [41]、ARTNet [38]、STM [17]、TDN [39])。然而,如何设计一个具有高效率和强大灵活性的时间模块仍然是一个未解决的问题。因此,我们的目标是沿着这个方向推进当前的视频架构。
Challenge:
如何设计一个有效的时间模块,
1、该模块有望能够以高灵活性捕获复杂的时间结构
2、同时以低计算量实现对高维视频数据的高效处理
Idea:
对于Challenge1:
作者提出根据视频的特征图生成特定的时间核
为了处理视频中如此复杂的时间变化,我们认为每个视频的自适应时间核是有效的,也是描述运动模式所必需的。
我们提出了一种两级自适应建模方案,将视频特定的时间核分解为
1、位置敏感重要性图(location sensitive importance map)专注于从局部视角增强有区别的时间信息,(本文一直说location sensitive importance map,局部分支的作用就是生成这个包含局部信息的全局map,以逐元素点乘的方式将信息聚合到特征里边,详细说明见(下)篇)
2、位置不变(也是视频自适应)聚合核。(location invariant(also viseo adaptive)aggregation kernel)能够通过输入视频序列的全局视角捕获时间依赖性。(作者通过FC层来学习卷积核,所以卷积核都拥有了全局视野,通过卷积操作把信息融入特征中,作者的的 TANet(TANet是将TAMblock整合到网络模块中的网络的统称)通过简单地堆叠更多的 TAM 来捕获长期依赖关系(本质上就是有更多fc层嘛,自然也就捕获了更多的长期依赖关系),并保持网络的效率。详细说明见(下)篇)
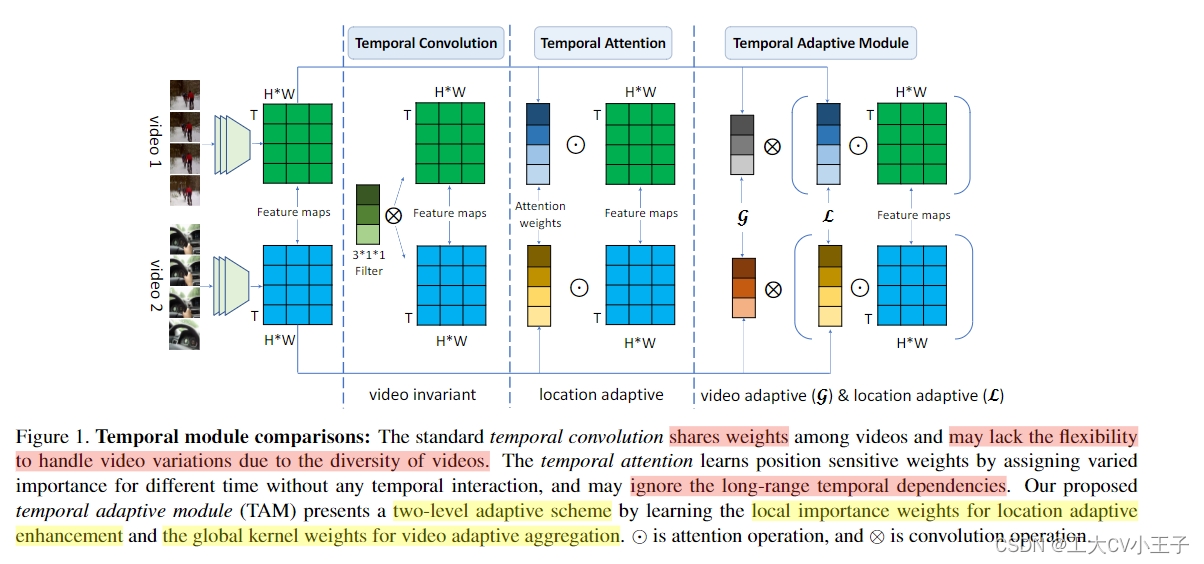
为了保持计算效率,L和G分支都是建立在输入数据压缩的基础上的,详细信息见(下)篇。
《Tam》论文笔记(下)-CSDN博客
原文翻译
Abstract
由于相机运动、速度变化和不同活动等因素,视频数据具有复杂的时间动态。为了有效地捕捉这种多样化的运动模式,本文提出了一种新的时间自适应模块(TAM),根据自己的特征图生成视频特定的时间核。TAM提出了一种独特的两级自适应建模方案,将动态核解耦为位置敏感重要性图和位置不变聚合权重。重要性图是在局部时间窗口中学习的,以捕获短期信息,而聚合权重是从全局视图生成的,重点是长期结构。TAM 是一个模块化块,可以集成到 2D CNN 中,以产生强大的视频架构 (TANet),具有非常小的额外计算成本。在Kinetics-400和Something-Something数据集上的大量实验表明,我们的TAM始终优于其他时间建模方法,并在相似复杂度下实现了最先进的性能。该代码可在以下链接获得GitHub - liu-zhy/temporal-adaptive-module: TAM: Temporal Adaptive Module for Video Recognition
1. Introduction
深度学习在图像分类[21,12]、目标检测[28]和实例分割[11]等图像识别任务中取得了很大的进展。这些成功的关键是设计灵活高效的架构,能够从大规模图像数据集[4]中学习强大的视觉表示。然而,视频理解的深度学习研究进展相对较慢,部分原因是视频数据的高度复杂性。视频理解的核心技术问题是设计一个有效的时间模块,该模块有望能够以高灵活性捕获复杂的时间结构,同时以低计算量实现对高维视频数据的高效处理。
3D卷积神经网络(3D CNN)[15,34]已被证明是视频建模的主流架构[1,8,36,27]。3D 卷积是其 2D 对应物的直接扩展,并为视频识别提供了一个可学习的算子。然而,这种简单的扩展缺乏对视频数据中的时间属性的特定考虑,并且也可能导致高计算成本。因此,最近的方法旨在通过将轻量级时间模块与 2D CNN 相结合来提高效率(例如 TSN [40]、TSM [23])或设计一个专用时间模块来更好地捕获时间关系(例如,非本地网络 [41]、ARTNet [38]、STM [17]、TDN [39])。然而,如何设计一个具有高效率和强大灵活性的时间模块仍然是一个未解决的问题。因此,我们的目标是沿着这个方向推进当前的视频架构。
在本文中,我们专注于设计一个自适应模块以更灵活的方式捕获时间信息。有趣的是,我们观察到视频数据由于相机运动和各种速度等因素,沿时间维度具有极其复杂的动态。因此,3D卷积(时间卷积)仅仅通过使用固定数量的固定参数的视频卷积核可能缺乏足够的表示能力来描述运动多样性,为了处理视频中如此复杂的时间变化,我们认为每个视频的自适应时间核是有效的,也是描述运动模式所必需的。为此,如图1所示,我们提出了一种两级自适应建模方案,将视频特定的时间核分解为位置敏感重要性图(location sensitive importance map)和位置不变(也是视频自适应)聚合核。(location invariant(also viseo adaptive)aggregation kernel)这种独特的设计允许位置敏感的重要性图专注于从局部视角增强有区别的时间信息,并使视频自适应聚合能够通过输入视频序列的全局视角捕获时间依赖性。
具体来说,时间自适应模块的设计(TAM)严格地遵循两个原则:高效率和强大的灵活性。为了确保我们的 TAM 计算成本低,我们首先通过使用全局空间池化来压缩特征图,然后以通道方式建立我们的 TAM 以保持效率。我们的 TAM 由两个分支组成:局部分支 (L) 和全局分支 (G)。如图 2 所示,TAM 以有效的方式实现。局部分支采用时间卷积生成位置敏感重要性图来增强局部特征,而全局分支使用全连接层生成位置不变核进行时间聚合。局部时间窗口生成的重要性图侧重于短期运动建模,使用全局视图的聚合内核更关注长期时间信息。此外,我们的 TAM 可以灵活地插入到现有的 2D CNN 中,以产生高效的视频识别架构,称为 TANet。
我们在视频中动作分类任务验证了所提出的 TANet。特别是,我们首先研究了 TANet 在 Kinetics-400 数据集上的性能,并证明我们的 TAM 在捕获时间信息方面比其他几个对应物更好,例如时间池化、时间卷积、TSM [23]、TEINet [24] 和Non-local block [41]。我们的 TANet 能够产生以类似于 2D CNN 的 FLOPs 产生非常有竞争力的准确性。我们进一步在Something-Something的运动主导数据集上测试我们的TANet,我们的模型在这个数据集上实现了最先进的性能。
2 Related Work
视频理解是计算机视觉领域的核心课题。在早期阶段,许多传统的方法[22, 20, 29, 43]设计了不同的手工特征去编码视频数据,但这些方法在推广到其他视频任务时过于不灵活。最近,由于视频理解的快速发展很大程度上得益于深度学习方法[21,32,12],特别是在视频识别中,人们提出了一系列基于cnn的方法来学习时空表示,我们的方法的差异将在后面澄清。此外,我们的工作还涉及 CNN 中的动态卷积和注意力。
CNNs-based methods for action recognition.由于深度学习方法已广泛用于图像任务,因此有许多尝试 [18, 31, 40, 46, 10, 23, 39] 基于2D CNN 专门用于建模视频片段的 。特别是,[40]使用从整个视频稀疏采样的帧,通过聚合最后一个全连接层之后的分数来学习长范围的信息。[23] 以有效的方式沿时间维度移动通道,与 2D CNN 产生了良好的性能。通过对空间域到时空域的简单扩展,提出了三维卷积[15,34]来捕获视频片段中编码的运动信息。由于大规模动力学数据集[19]的释放,3D CNN[1]被广泛应用于动作识别中。它的变体[27,36,44]将三维卷积分解为空间二维卷积和时间一维卷积来学习时空特征。[8]设计了一个具有双路径的网络来学习时空特征,并在视频理解中取得了有希望的准确性。
上述所有方法都有一个共同的见解,即它们是视频不变的,而忽略了视频中固有的时间多样性。与这些方法相比,我们设计了一种两级自适应建模方案,将视频特定操作分解为位置敏感激励和为每个视频片段设计的具有自适应核的位置不变卷积。(这段有点吓胡诌了,我说的是作者不是我)
Attention in action recognition.TAM 中的本地分支主要与 SENet [13] 有关。但是SENet为特征图的每个通道学习调制权重。几种方法 [24, 5] 也诉诸注意力来学习视频中更具辨别力的特征。与这些方法不同的是,我们提出的local branch的局部分支在保留时间信息的同时来学习位置敏感的重要性。[41]设计了一个非局部块,可以看作是自我注意来捕获长期依赖关系。我们的 TANet 通过简单地堆叠更多的 TAM 来捕获长期依赖关系,并保持网络的效率。
Dynamic convolutions.[16]首先提出了视频和立体预测任务的动态滤波器,设计了一种卷积编码器-解码器作为滤波-生成网络。图像任务中的几项工作 [45, 3] 试图为一组卷积核生成聚合权重,然后生成一个动态内核。我们的动机与这些方法不同。我们的目标是使用这个时间自适应模块来处理视频中的时间变化。具体来说,我们设计了一种基于输入特征图的有效形式实现这种时间动态内核,这对于理解视频内容至关重要。
3 Method(见下篇)
《Tam》论文笔记(下)-CSDN博客
相关文章:
《TAM》论文笔记(上)
原文链接 [2005.06803] TAM: Temporal Adaptive Module for Video Recognition (arxiv.org) 原文代码 GitHub - liu-zhy/temporal-adaptive-module: TAM: Temporal Adaptive Module for Video Recognition 原文笔记 What: TAM: Temporal Adaptive Module for …...
【Java的抽象类和接口】
1. 抽象类 1.1 抽象类概念 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果 一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。 以上代码中…...
今天开发了一款软件,我竟然只用敲了一个字母(文末揭晓)
软件课题:Python实现打印100内数学试题软件及开发过程 一、需求管理: 1.实现语言:Python 2.打印纸张:A4 3.铺满整张纸 4.打包成exe 先看效果: 1. 2.电脑打印预览 3.打印到A4纸效果(晚上拍的&#x…...

【C++杂货铺】红黑树
目录 🌈前言🌈 📁 红黑树的概念 📁 红黑树的性质 📁 红黑树节点的定义 📁 红黑树的插入操作 📁 红黑树和AVL树的比较 📁 全代码展示 📁 总结 🌈前言…...

css--控制滚动条的显示位置
各种学习后的知识点整理归纳,非原创! ① direction属性 滚动条在左侧显示② transform:scaleY() 滚动条在上侧显示 正常的滚动条会在内容超出规定的范围后在区域右侧和下侧显示在有些不正常的需求下会希望滚动条在上侧和左侧显示自己没有想到好的解决方案…...
华为设备display查看命令
display version //查看版本信息 display current-configuration //查看配置详情 display this //查看当前视图有效配置 display ip routing-table //查看路由表 display ip routing-table 192.168.3.1 //查看去往3.1的路由 display ip interface brief //查看接口下ip信息 dis…...

自动攻丝机进出料激光检测 进料出料失败报警循环手动及关闭报警退出无限循环
/**************进料检测********************/ /***缺料无限次循环 手动退出 超时报警*******/ void check_Pon() // { zstatus0; //报警计数器归零 Signauto1; …...
2024年去除视频水印的5种方法
如果你从事电影剪辑或者视频编辑工作,你经常需要从优酷、抖音、TikTok下载各种视频片段……。 通常这些视频带有水印和字幕。一些免费软件如CapCut、canva、Filmora也会给你制作的视频打上水印,这些水印嵌入在视频内部。 2024年去除视频水印的5种方法 …...
怎么用电脑接收手机文件 用备忘录传输更舒服
在这个数字化时代,手机已经成为我们随身携带的“百宝箱”,里面装满了各种重要的文件、资料和信息。然而,有时我们需要在电脑上处理这些文件,比如编辑文档、制作PPT或是查看照片。那么,如何在电脑与手机之间实现文件的顺…...

微信小程序、uniapp密码小眼睛
直接上代码喔喔喔喔喔喔喔喔~~ <input name"username" password"{{passwordHideShow}}" placeholder-style"color:#bdbdbd" type"text"maxlength"20" value"{{passwordNumber}}" bindinput"passwordInput…...

【手势操作-复习前一天的内容-预习今天的内容 Objective-C语言】
一、昨天呢,我们学习的是这个,事件 1.事件这一块儿呢,iOS事件,分为三大类, 1)触摸事件 2)加速计事件 3)远程控制事件 2.这个里边呢,我们主要学习的是这个触摸事件,触摸事件里边,就是Touch,touchesBegan:方法里边,有一个touches参数,它是set类型的, 3.Set,…...

【收录 Hello 算法】第 6 章 哈希表
目录 第 6 章 哈希表 本章内容 第 6 章 哈希表 Abstract 在计算机世界中,哈希表如同一位聪慧的图书管理员。 他知道如何计算索书号,从而可以快速找到目标图书。 本章内容 6.1 哈希表6.2 哈希冲突6.3 哈希算法6.4 小结...
)
rust类型和变量(二)
基础知识 Rust中的变量基础知识 1.在Rust中,使用Iet关键字来声明变量 2.Rust支持类型推导,但你也可以显式指定变量的类型: Ietx:i325;/显式指定x的类型为i32 3.变量名蛇形命名法(Snake Case),i 而枚举和结构体命名使用帕斯卡命名法(Pasca|Ca…...

linux学习:多媒体开发库SDL+视频、音频、事件子系统+处理yuv视频源
目录 编译和移植 视频子系统 视频子系统产生图像的步骤 api 初始化 SDL 的相关子系统 使用指定的宽、高和色深来创建一个视窗 surface 使用 fmt 指定的格式创建一个像素点编辑 将 dst 上的矩形 dstrect 填充为单色 color编辑 将 src 快速叠加到 dst 上编辑 更新…...
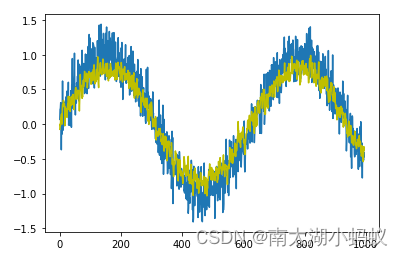
基于门控的循环神经网络:LSTM
之前我们介绍了循环神经网络的原理以及实现。但是循环神经网络有一个问题,也就是长期依赖问题。我们之前的01序列预测案例中可以看到,当序列长度到达10以上之后错误就会增多,说明简单的RNN记忆容量较小,当长度更大时就不怎么适用了…...

Web常见的攻击方式及其防御策略
随着互联网技术的快速发展,Web应用已成为我们日常生活和工作中不可或缺的一部分。然而,Web应用也面临着各种安全威胁和攻击。了解这些常见的攻击方式,并采取有效的防御策略,对于保护Web应用的安全至关重要。 一、常见的Web攻击方…...

关于SQL
数据库简介: 数据库分类 关系型数据库模型: 优点:易于维护,可以实现复杂的查询 缺点:海量数据 读取写入性能差,高并发下数据库的io是瓶颈 是把复杂的数据结构归结为简单的二元关系(即二维表…...
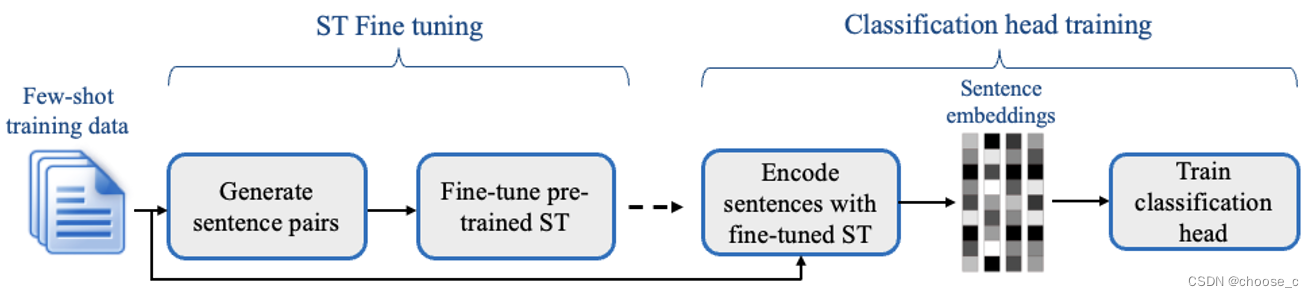
大模型时代下两种few shot高效文本分类方法
介绍近年(2022、2024)大语言模型盛行下的两篇文本分类相关的论文,适用场景为few shot。两种方法分别是setfit和fastfit,都提供了python的包使用方便。 论文1:Efficient Few-Shot Learning Without Prompts 题目:无需提示的高效少…...
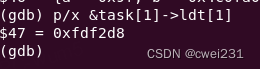
Linux0.11 中全局描述符表(GDT)
在Linux内核中,全局描述符表(Global Descriptor Table,简称GDT)是一个关键的数据结构,主要用于管理处理器的内存段和相关的权限与属性。它属于x86架构中的保护模式特性,允许操作系统对内存访问进行更精细的…...

搜维尔科技:数据手套用于外固定虚拟现实模拟 、外固定增强现实模拟
数据手套用于外固定虚拟现实模拟、外固定增强现实模拟 搜维尔科技:数据手套用于外固定虚拟现实模拟、外固定增强现实模拟...

Excel高手都在用的搜索式下拉菜单:一个OFFSET函数搞定,输入关键词自动筛选选项
Excel动态搜索式下拉菜单:用OFFSET函数打造智能数据录入系统 每次面对Excel里上千行的产品目录或员工名单时,传统下拉菜单的滚动条就像在考验你的耐心——滑动十几次才能找到目标项,还容易选错行。有没有更高效的解决方案?试试这个…...

3个步骤搞定Windows安卓应用安装:告别模拟器的轻量级解决方案
3个步骤搞定Windows安卓应用安装:告别模拟器的轻量级解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了臃肿的安卓模拟器?想…...
- 从零构建机器人URDF模型与Gazebo集成)
【SLAM建图与导航仿真实战】(一)- 从零构建机器人URDF模型与Gazebo集成
1. 从零开始:为什么需要构建机器人URDF模型 当你第一次接触机器人仿真时,可能会被各种专业术语搞得晕头转向。URDF(Unified Robot Description Format)作为ROS中的标准机器人描述格式,就像是机器人的"身份证&quo…...
CSS如何制作数字滚动效果_利用transform位移数字
数字滚动本质是通过transform: translateY()位移切换预排数字,非3D动画;需等宽字体、overflow: hidden、CSS自定义属性配合calc()与cubic-bezier过渡实现平滑效果。数字滚动效果的本质是位移切换,不是动画插值数字滚动效果看着像“数字在滚轮…...

抖音无水印批量下载实战指南:3分钟搞定高效内容管理
抖音无水印批量下载实战指南:3分钟搞定高效内容管理 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

企业级知识图谱构建解决方案:基于LLM的智能文档结构化架构与实践
企业级知识图谱构建解决方案:基于LLM的智能文档结构化架构与实践 【免费下载链接】llm-graph-builder Neo4j graph construction from unstructured data using LLMs 项目地址: https://gitcode.com/GitHub_Trending/ll/llm-graph-builder 在数字化转型浪潮中…...

别再写重复的Controller了!Spring Boot 3.x + Pageable 实现分页查询的5个最佳实践
Spring Boot 3.x分页查询工程化实践:从Controller优化到架构设计 每次打开IDE看到那些重复的分页查询代码,我都忍不住想重构。分页查询作为业务系统的高频操作,却在大多数项目中以最原始的方式被复制粘贴。今天我们就来聊聊如何用Spring Boot…...

终极显卡驱动清理指南:如何用DDU彻底解决Windows驱动残留问题
终极显卡驱动清理指南:如何用DDU彻底解决Windows驱动残留问题 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-unins…...

Nunchaku-flux-1-dev中文提示词分级体系:L1通用词→L3专业术语→L5文化典故生成效果对照
Nunchaku-flux-1-dev中文提示词分级体系:L1通用词→L3专业术语→L5文化典故生成效果对照 你是不是也遇到过这样的问题:用AI生成图片时,明明脑子里有很清晰的画面,但写出来的提示词就是出不来想要的效果? “古风少女&…...

3分钟搞定JetBrains IDE试用期重置:终极免费解决方案
3分钟搞定JetBrains IDE试用期重置:终极免费解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否遇到过这样的尴尬时刻:正在赶项目进度,JetBrains IDE突然弹出"…...