基于门控的循环神经网络:LSTM
之前我们介绍了循环神经网络的原理以及实现。但是循环神经网络有一个问题,也就是长期依赖问题。我们之前的01序列预测案例中可以看到,当序列长度到达10以上之后错误就会增多,说明简单的RNN记忆容量较小,当长度更大时就不怎么适用了。本质上是由于随时间反向传播算法当序列长度太长后产生的梯度爆炸和梯度消失问题导致的。具体推导可以参见邱锡鹏的《神经网络与深度学习》6.5节。
从算法顺序来说是先有LSTM再有GRU的,不过由于LSTM比较复杂,且名气也更大,因此我们先来看一下LSTM(长短期记忆网络)。
简单的来说,LSTM算法引入了三个门来解决这个问题,一个输入门input,一个遗忘门forget,一个输出门output。在每个时刻t,LSTM网络的内部状态ct记录了到当前时刻为止的历史信息。
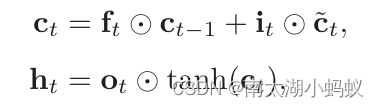
这里ft代表遗忘门,it代表输入门,ot代表输出门,ct代表上一个时刻的历史信息乘以遗忘门,决定是否要遗忘,再加上通过非线性函数得到的候选状态。
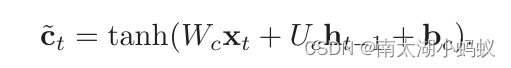
LSTM每个门取值都在(0,1)之间,ct在(-1,1)之间,候选状态也是在(-1,1)之间,ht也是在(-1,1)之间。
- 遗忘门ft控制上一个时刻的内部状态ct-1需要遗忘多少信息。
- 输入门it控制当前时刻的候选状态ct~多少信息需要保存。
- 输出门ot控制当前时刻的内部状态ct有多少信息需要输出给外部状态ht。
当ft=0,it=1时,记忆单元将历史信息清空,并将候选状态向量ct~写入,但此时记忆单元ct依然和上一时刻的历史信息相关,因为ct~的计算还是有ht-1参与的。当ft=1,it=0时,记忆单元将复制上一时刻的内容,不写入新的信息。
三个门的计算公式分别为:
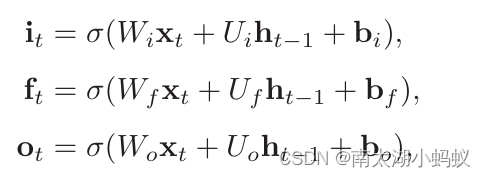
LSTM总体结构如下图所示:
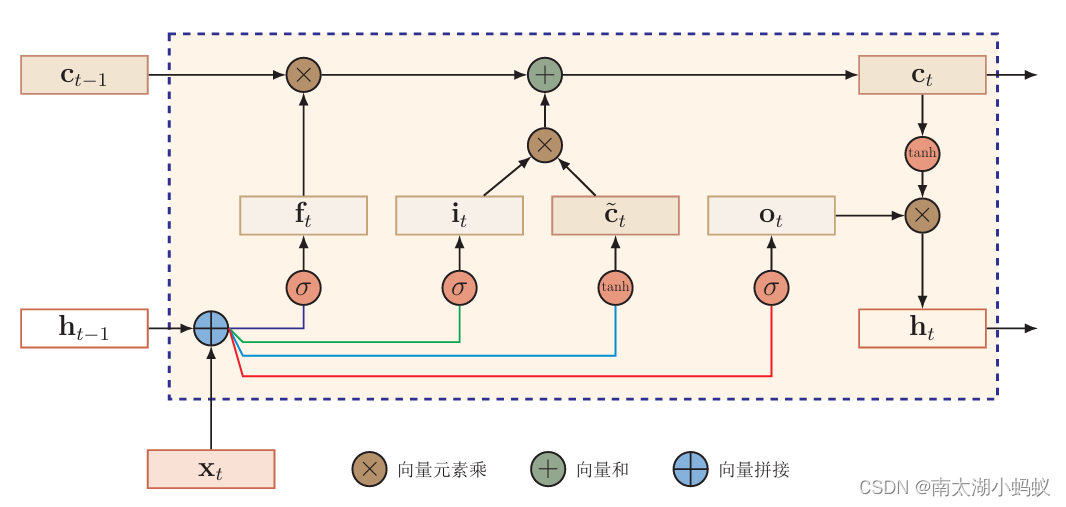
- 首先利用上一时刻的外部状态ht−1和当前时刻的输入xt,计算出三个门it,ft,ot,以及候选状态 ct~;
- 结合遗忘门ft和输入门it来更新记忆单元ct;
- 结合输出门ot,将内部状态的信息传递给外部状态ht。
循环神经网络中的隐状态h存储了历史信息,可以看作是一种“记忆”,在简单循环神经网络中,隐状态每个时刻都被会重写,可以看作是一种短期记忆。在神经网络中,网络参数可以看作是长期记忆,隐含了从训练数据中学到的经验,并且更新周期要远远慢于短期记忆。LSTM中的ct可以在某个时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔。ct中保存信息的生命周期要长于短期记忆h,又远远短于长期记忆,所以被称作是长短期记忆网络(LSTM)。
下面,我们来自己实现一下这个网络。
class LSTM(nn.Module):def __init__(self, input_size, num_hiddens, batch_first=True):super(LSTM,self).__init__()def normal(shape):return torch.randn(size = shape)*0.01def three(): # 定义输入的权重,隐藏神经元的权重,截距的权重wx = normal((input_size, num_hiddens)) wh = normal((num_hiddens, num_hiddens))b = torch.zeros(num_hiddens)return (wx,wh,b)W_xi, W_hi, b_i = three() # 输入门参数W_xf, W_hf, b_f = three() # 遗忘门参数W_xo, W_ho, b_o = three() # 输出门参数W_xc, W_hc, b_c = three() # C,候选记忆参数# 输出层参数W_hq = normal((num_hiddens, num_hiddens))b_q = torch.zeros(num_hiddens)self.params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q]self.batch_first = batch_firstself.num_hiddens = num_hiddensdef forward(self,inputs):# 获取各种预定义的权重[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = self.params# 如果第一个维度是批量大小batch_size,则第二个维度是序列长度,否则第一个维度是序列长度if self.batch_first:batch_size = inputs.shape[0]seq_len = inputs.shape[1] # 序列长度else:batch_size = inputs.shape[1]seq_len = inputs.shape[0] # 序列长度# 初始化状态stateself.h = torch.zeros((seq_len, self.num_hiddens))self.c = torch.zeros((seq_len, self.num_hiddens))H = self.hC = self.coutputs = []for X in inputs: # 这里遍历的,其实就是批量batch,X就是一个批量的输入# 输入门的计算I = torch.sigmoid((X@W_xi) + (H@W_hi) + b_i)# 遗忘门的计算F = torch.sigmoid((X@W_xf) + (H@W_hf) + b_f)# 输出门的计算O = torch.sigmoid((X@W_xo) + (H@W_ho) + b_o)# 候选状态的计算C_tilda = torch.tanh((X@W_xc) + (H@W_hc) + b_c)# 记忆单元的计算C = F*C + I*C_tilda# 输出的隐藏层权重H = O*torch.tanh(C)# 得到输出的结果Y = H@W_hq + b_q# 把每个批量的输出添加到数组outputs中outputs.append(Y)# 根据第0维进行拼接out = torch.cat(outputs, dim=0)# 恢复成输入的batch_size大小out = out.reshape(batch_size,seq_len,self.num_hiddens)return out,(H,C)# 我们构建一个输入维度位1,20个隐藏单元,默认一个隐藏层,输入的第一维度是batch_size
net = LSTM(input_size=1, num_hiddens=20, batch_first=True)
# 输入数据,第一维度是batch_size=8,第二个维度是序列长度,为10,第三个维度是input_size=1
data = torch.zeros(8,10,1)
out,ht = net(data)
print(out.shape)
print(out[:,-1,:].shape)
# 输出:
# 第一维度batch_size=10,第二维度是序列长度=10,第三维度是隐藏神经元的个数=20
torch.Size([8, 10, 20])
torch.Size([8, 20])我们可以用pytorch框架提供的LSTM模型和我们自己定义的LSTM对照一下:
input_size = 1
num_hiddens = 20lstm=nn.LSTM(input_size=input_size, #输入特征维度,当前特征为股价,维度为1hidden_size=num_hiddens, #隐藏层神经元个数,或者也叫输出的维度num_layers=1, # 隐藏层数量batch_first=True
# 输入数据的第一维度是batch_size)
data = torch.zeros(8, 10, 1)
out,ht = lstm(data)
print(out.shape)
print(out[:,-1,:].shape)
print(ht[0].shape)
print(ht[1].shape)
# 输出:
torch.Size([8, 10, 20])
torch.Size([8, 20])
torch.Size([1, 8, 20])
torch.Size([1, 8, 20])可以看到,pytorch框架提供的LSTM方法和我们自定义的LSTM方法的输出大小是一样的。下面我们可以根据LSTM的输出去做自己需要的事情,假设我们需要根据输入的序列数据,来预测序列数据的下一位,我们可以定义如下的神经网络模型:
class model(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(model, self).__init__() self.hidden_size = hidden_size self.lstm = LSTM(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): out, _ = self.lstm(x)out = self.fc(out[:, -1, :])#print("out.shape : ",out.shape)return out可以看到,我们调用了LSTM模块,并把输出结果,再进行了一次线性全连接操作,得到了符合输出大小的结果。我们用一个数据来测试一下输出:
# 定义一个input_size=1,hidden_size=1,output_size=1的模型
net = model(1, 20, 1)
# 定义一个输入,batch_size=8,序列长度seq_len=4,input_size=1
data = torch.zeros(8, 4, 1)
out = net(data)
print(out.shape)
# 输出:
torch.Size([8, 1])可以看到输出的大小是[8,1],第0维是8,batch_size,输出就是一个数值,我们可以利用这个输出去跟标签对比,求得loss,就可以训练了。
下面,我们将之前《循环神经网络简介》一文中介绍的根据正弦函数的前四个输入来预测下一个输出值的案例来重新实现一下,改成用自定义的LSTM。
假设我们有一个预先定义的正弦函数数据:
import matplotlib.pyplot as plt# 画出sin函数作为序列函数
y = []
for i in range(1000):y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动
x = [i for i in range(1000)]plt.plot(x, y)
plt.show()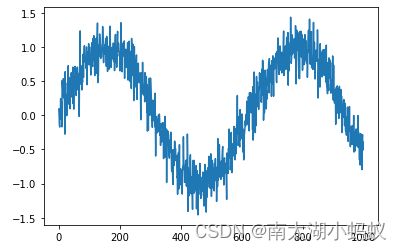
选择1000个样本,作为训练数据:
total = 1000
tau = 4
features = np.zeros((total-tau, tau))
data = [i for i in range(total)]
for i in range(tau):features[:,i] = y[i:total-tau+i] # 获取到每一列的特征值
print(len(features)) # 样本个数
print(features) # 输出特征值定义数据集Dataset和DataLoader:
# 用前600个数字作为训练集,后400个作为测试集
class myDataset(Dataset):def __init__(self, tau=4, total=600, transform=None):data = [i for i in range(total)]y = []for i in range(total):y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动# tau代表用多少个数字来作为输入,默认为4self.features = np.zeros((total-tau, tau)) # 构建了996行4列的输入序列,代表了996个训练样本,每个样本有4个数字构成for i in range(tau):self.features[:,i] = y[i: total-tau+i] # 给特征向量赋值self.data = dataself.transform = transformself.labels = y[tau:]def __len__(self):return len(self.labels)def __getitem__(self, idx):return self.features[idx], self.labels[idx]transform = transforms.Compose([transforms.ToTensor()])
trainDataset = myDataset(transform=transform)
train_loader = DataLoader(dataset=trainDataset, batch_size=32, shuffle=False) 定义一个训练方法:
def train(epochs=1000):net = model(1, 20, 1)criterion = nn.MSELoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.01)for epoch in range(epochs):total_loss = 0.0for i, (x, y) in enumerate(train_loader):x = Variable(x)x = x.to(torch.float32)# unsqueeze是在最后增加一个维度,否则x的shape是[32,4]x = x.unsqueeze(2)
# x的维度现在变成[32,4,1] y = Variable(y)y = y.to(torch.float32)# unsqueeze是在最后增加一个维度,否则输出shape是[32]y = y.unsqueeze(1) # 输出shape是[32,1]optimizer.zero_grad()outputs = net(x)loss = criterion(outputs, y)total_loss += loss.sum() # 因为标签值和输出都是一个张量,所以损失值要求和loss.sum().backward()optimizer.step()if (epoch+1)%50==0:print('Epoch {}, Loss: {:.4f}'.format(epoch+1, total_loss/len(trainDataset)))torch.save(net, 'lstm.pt')train(epochs=1000) # 训练1000个epochs
# 输出:
Epoch 50, Loss: 0.0170
Epoch 100, Loss: 0.0156
Epoch 150, Loss: 0.0144
Epoch 200, Loss: 0.0132
Epoch 250, Loss: 0.0121
Epoch 300, Loss: 0.0110
Epoch 350, Loss: 0.0100
Epoch 400, Loss: 0.0091
Epoch 450, Loss: 0.0082
Epoch 500, Loss: 0.0074
Epoch 550, Loss: 0.0067
Epoch 600, Loss: 0.0060
Epoch 650, Loss: 0.0053
Epoch 700, Loss: 0.0048
Epoch 750, Loss: 0.0042
Epoch 800, Loss: 0.0038
Epoch 850, Loss: 0.0034
Epoch 900, Loss: 0.0030
Epoch 950, Loss: 0.0027
Epoch 1000, Loss: 0.0025结果验证:
# 预测
net = torch.load('lstm.pt')
features = torch.from_numpy(features)
features = features.float()
features = features.unsqueeze(2)
y_pred = net(features)
# 画出sin函数作为序列函数
y = []
for i in range(996):y.append(np.sin(0.01*i)+np.random.normal(0,0.2))
x = [i for i in range(996)]fig, ax = plt.subplots()
ax.plot(x, y) # 画出输入数据
ax.plot(x, y_pred.detach().numpy(), color="y") #画出预测数据
plt.show()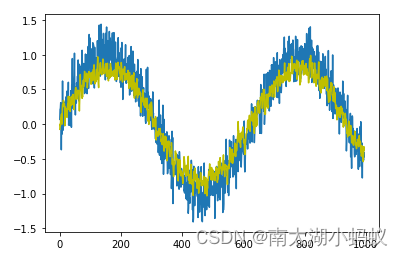
可以看到预测的结果和原始数据拟合较好,与我们前面使用的RNN网络模型结果类似。
相关文章:
基于门控的循环神经网络:LSTM
之前我们介绍了循环神经网络的原理以及实现。但是循环神经网络有一个问题,也就是长期依赖问题。我们之前的01序列预测案例中可以看到,当序列长度到达10以上之后错误就会增多,说明简单的RNN记忆容量较小,当长度更大时就不怎么适用了…...

Web常见的攻击方式及其防御策略
随着互联网技术的快速发展,Web应用已成为我们日常生活和工作中不可或缺的一部分。然而,Web应用也面临着各种安全威胁和攻击。了解这些常见的攻击方式,并采取有效的防御策略,对于保护Web应用的安全至关重要。 一、常见的Web攻击方…...

关于SQL
数据库简介: 数据库分类 关系型数据库模型: 优点:易于维护,可以实现复杂的查询 缺点:海量数据 读取写入性能差,高并发下数据库的io是瓶颈 是把复杂的数据结构归结为简单的二元关系(即二维表…...
大模型时代下两种few shot高效文本分类方法
介绍近年(2022、2024)大语言模型盛行下的两篇文本分类相关的论文,适用场景为few shot。两种方法分别是setfit和fastfit,都提供了python的包使用方便。 论文1:Efficient Few-Shot Learning Without Prompts 题目:无需提示的高效少…...
Linux0.11 中全局描述符表(GDT)
在Linux内核中,全局描述符表(Global Descriptor Table,简称GDT)是一个关键的数据结构,主要用于管理处理器的内存段和相关的权限与属性。它属于x86架构中的保护模式特性,允许操作系统对内存访问进行更精细的…...

搜维尔科技:数据手套用于外固定虚拟现实模拟 、外固定增强现实模拟
数据手套用于外固定虚拟现实模拟、外固定增强现实模拟 搜维尔科技:数据手套用于外固定虚拟现实模拟、外固定增强现实模拟...
《三》菜单栏_工具栏_状态栏动作与实现
上期我们创建了辣么多的动作,那么这次我们要是开始实现这些动作,撸起袖子来吧: //菜单动作(ACtion)QAction *newAct;//新建QAction *openAct;//打开QAction *saveAct;//保存QAction *saveAsAct;//另存为QAction *prin…...

基于NTP服务器获取网络时间的实现
文章目录 1 NTP1.1 简介1.2 包结构1.3 UNIX 时间戳和NTP时间戳 2 代码实现2.1 实现步骤2.2 完整代码 3 结果 在某些场景下,单片机需要通过网络获取准确的时间进行数据同步,例如日志记录、定时任务等。然而,单片机本身无法直接获得准确的标准时…...
Web APIs(获取元素+操作元素+节点操作)
目录 1.API 和 Web API 2.DOM导读 DOM树 3.获取元素 getElementById获取元素 getElementsByTagName获取元素 H5新增方法获取 获取特殊元素 4.事件基础 执行事件 操作元素 修改表单属性 修改样式属性 使用className修改样式属性 获取属性的值 设置属性的值 移除…...
Android adb shell关于CPU核的命令
Android adb shell关于CPU核的命令 先使用命令: adb shell 进入控制台。 然后,直接在$后面输入下面命令,针对CPU的命令。 cat /proc/cpuinfo | grep ^processor | wc -l 查看当前手机的CPU是几核的。 cat sys/devices/system/cpu/online …...
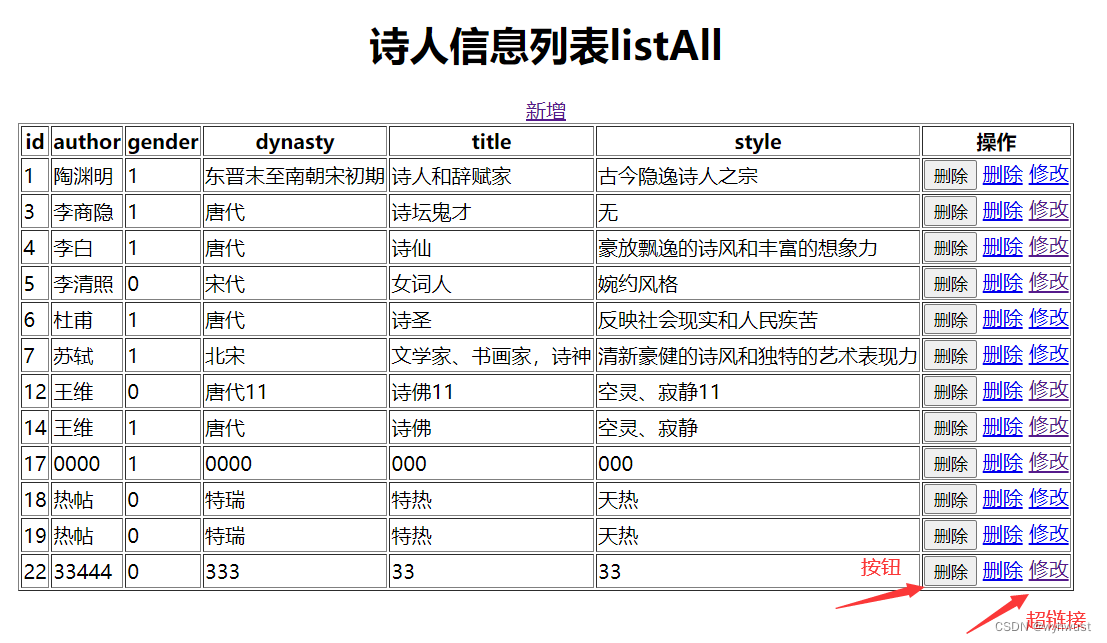
基于springboot+mybatis+vue的项目实战之页面参数传递
如图所示,删除操作可以用按钮实现,也可以用超链接来实现。 1、第一种情况,用按钮实现。 html页面相关: <button type"button" click"deleteId(peot.id)">删除</button> <script>new Vue(…...
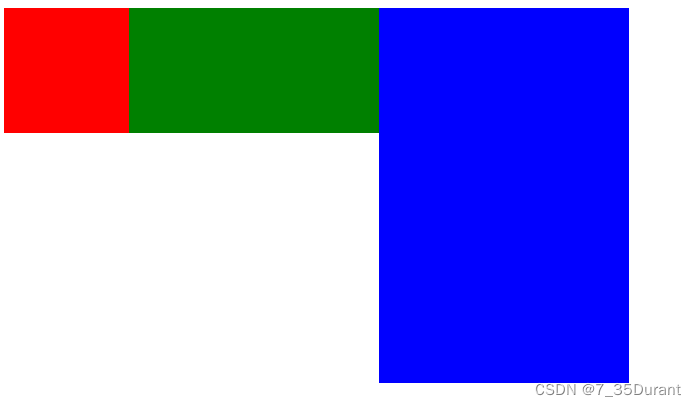
CSS-浮动
float (浮动) 作用:盒子的顶点是一样的,具备行内块的特征,能设置宽高 属性:float 属性值:left 浮动在网页左边 right 浮动在网页右边 .a{width: 100px;height: 100px;float:left;background-color: red;}.b…...

MFC:字符串处理
例子 //多字节char* szTest "abc多字节";int nLen strlen(szTest);//9//宽字节wchar_t* szTest2 L"abc多字节";int nlen2 wcslen(szTest2);//6//测试项目配置为Unicodewchar_t* szTesz3 TEXT("abcd");//char* -> CStringCString strTes…...

虚拟仿真云平台在教育应用中的优势和意义
虚拟仿真云实验教学平台作为一种新型的教学方法,近年来在高校教育中得到了十分广泛的应用。它通过模拟真实的实验场景和实验操作,让学生在计算机上进行实验操作和数据处理,为学生提供了更加便捷、可靠、有效的实验学习环境。本文,…...

CPU的的处理流程如何快速记忆
为了快速记忆CPU的处理流程,可以将其简化成五个主要阶段,通常称为“冯诺依曼架构”的五个基本步骤,或者是流水线处理的几个阶段。下面是一种便于记忆的简化版本: CPU处理流程的五个阶段: 取指令(Instructi…...

AI视频教程下载:基于OpenAl、LangChain、 Replicate开发AI应用程序
欢迎来到令人兴奋的 AI 应用世界!在这门课程中,你将学习到创建一个能够与用户互动、理解自然语言、处理音频输入,甚至分析图像的真正智能应用所需的技能和技术。 AI 工具和技术 你将获得使用几个知名 AI API 和技术的实际经验。这些行业领先…...

【C++】继承相关(基类与派生类的继承关系以及细节整理)
目录 00.引言 01.继承的定义 02.基类和派生类对象 03.继承中的作用域 04.派生类的默认成员函数 05.友元、静态成员 00.引言 继承是面向对象编程中的一个重要概念,它的作用是创建一个新的类,该类可以从一个已存在的类(父类/基类&#x…...

【Web后端】监听器Listener
1、简介 用来监听Servlet组件对象状态发生变化的组件可以监听的源包括:ServetRequest、HttpSession、ServletContext当监听到事件源状态发生变化时,会有对应的响应行为 2、使用方法 在web.xml文件中配置 <listener> <listener-class>com.coder.util.…...
C/C++ 初级球球大作战练手
效果演示: https://live.csdn.net/v/385490 游戏初始化 #include <stdbool.h> #include<stdio.h> #include<stdlib.h> #include<time.h> #include<graphics.h> #include <algorithm> #include<math.h> #include<mmsy…...

ES6之字符串的扩展
字符串的扩展 关键的扩展点及其示例: Unicode 表示与处理 JavaScript 共有6种方法可以表示一个字符。codePointAtpos:String.fromCodePoint…codePoints: **字符串的遍历 for … of **字符串方法的增强 includessearchString[, position]&…...

河北邯郸职称评审的方式有哪几种?
1、以考代评以考代评就是指有些专业技术岗位可以通过参加考试而不是递交繁琐的材料来获得专业技术职务资格。只要顺利通过国家指定的科目考试,你就可以获得专业技术资格,省去了各种审核流程的烦恼。2、只评不考只评不考是目前zui常见、适用范围zui广的一…...

通过curl命令快速测试Taotoken上不同大模型的响应效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken上不同大模型的响应效果 对于开发者而言,在集成大模型能力时,快速验证接口连…...

GEO生成引擎优化:当品牌竞争从搜索结果页迁移到大模型对话窗口
当生成式AI成为信息的首要分发渠道,你的品牌还只盯着SEO吗?一、用户获取信息的路径,已经变了过去十几年,我们习惯了"搜索关键词 → 浏览结果页 → 点击进入网站"这条线性路径。SEO(搜索引擎优化)…...

C++继承与组合设计
C继承与组合设计继承和组合是面向对象设计中两种重要的代码复用机制。继承表示"是一个"关系,而组合表示"有一个"关系。理解何时使用继承、何时使用组合是设计良好系统的关键。继承允许派生类继承基类的属性和方法,实现代码复用和多态…...
)
【独家实测】ChatGPT-4 Turbo vs GPT-3.5 Turbo单位token成本对比:附Python自动核算脚本(限免24h)
更多请点击: https://codechina.net 第一章:ChatGPT API价格计算的底层逻辑与成本认知 ChatGPT API 的计费并非基于会话时长或请求次数,而是严格依据模型实际处理的 token 数量——包括输入(prompt)和输出(…...

《Enterprise Architecture with SAP》—— 从“纸上蓝图”到“场景落地”
上一篇文章(《Enterprise Architecture with SAP》— 从“项目思维”到“企业级全局视角”),我们花了不少篇幅把SAP企业架构的“骨架”搭起来了——五大支柱是什么、方法论怎么走、参考内容给什么蓝图、EA在企业里和谁配合干活。用一句话总结…...

Pandas 数据处理进阶:缺失值、合并、分组聚合与透视表
Pandas 数据处理进阶:缺失值、合并、分组聚合与透视表 在完成 pandas 的基础操作(索引、筛选、赋值、函数应用)之后,下一步便是处理真实数据中常见的问题:缺失值、多表合并、分组统计以及数据透视。本文带你系统掌握这…...

Unity版本降级实战指南:从2021.1回退到2019.4的四步硬核操作
1. 为什么Unity版本降级不是“回退安装”那么简单 在Unity项目开发中,很多人把“降级”理解成卸载新版本、重装旧版本、再拖进工程——就像换手机系统时刷回上个固件。但Unity的版本管理机制远比这复杂得多。我第一次遇到从2021.1.7f1c1往回降到2019.4.17f1c1的问题…...

2026 AI 培训机构怎么选?6 类人群精准匹配 + 避坑指南
随着大模型、多模态、RAG、Agent 技术持续迭代,企业对于 AI 算法开发、计算机视觉、自然语言处理、工程落地类人才的需求持续上涨。目前国内主流AI学习平台包含咕泡科技、科大讯飞AI大学堂、腾讯云智学堂、深兰科技人工智能教育等,各家平台技术侧重点、课…...

稀疏记忆微调:面向边缘设备的持续学习落地方法
1. 项目概述:这不是又一篇“加个正则就叫持续学习”的水文“Continual Learning via Sparse Memory Finetuning”——光看标题,你可能以为这是某篇顶会里被塞进附录、连作者自己都懒得细讲的补充实验。但实际翻开原文,它像一把薄刃手术刀&…...