Kubernetes之Headless Services
Kubernetes中的Headless Services(无头服务)是一种特殊类型的服务(Service)定义,它不提供传统意义上的负载均衡和集群IP地址分配。在无头服务中,spec.clusterIP 字段被显式设置为None ,Kubernetes不会为该服务分配一个虚拟IP(ClusterIP)地址。
一、无头服务的特点
-
没有Cluster IP:不分配Cluster IP,客户端不能通过服务的Cluster IP地址访问后端Pod,而是直接通过Pod的具体地址进行通信。
-
直接使用DNS解析:Kubernetes的DNS系统会为无头服务生成一条特殊的DNS记录,这条记录列出所有关联Pod的IP地址,允许客户端通过域名解析直接获得Pod列表,进而实现自定义的负载均衡或服务发现逻辑。
-
适用于状态服务应用:特别适合那些需要直接与特定实例通信的应用场景,如分布式数据库、消息队列等有状态服务,因为这些服务往往需要客户端直接与服务实例建立会话或维持连接状态。
二、headless Service和普通Service的区别
-
headless不分配clusterIP
-
headless service可以通过解析service的DNS,返回所有Pod的地址
-
普通的service,只能通过解析service的DNS返回service的ClusterIP。client访问ClusterIP,通过iptables或者ipvs转发到Real Server(Pod)
三、无头服务应用场景
-
有状态应用(StatefulSet):在部署有状态应用时,如分布式数据库集群(如Zookeeper、MySQL等),需要客户端直接访问特定节点,而不是通过负载均衡随机分配。比如MongoDB副本集,需要每个节点直接相互通信或客户端直接访问特定节点。比如Zookeeper、etcd集群,节点间需要相互发现并建立连接。
-
服务发现与自定义负载均衡:当应用需要实现自定义的负载均衡算法或服务发现逻辑时,无头服务允许应用直接与后端Pod列表交互,便于实现更精细的控制逻辑。
-
Session亲和性:对于需要维护会话状态的应用,使用无头服务可以直接指向会话所属的Pod,确保会话的一致性。
四、实验测试
- 普通的service
[root@node1 ~]# kubectl get po -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-5977dc5756-ksff2 1/1 Running 0 22h 172.16.28.42 node3 <none> <none>
test-5977dc5756-vrbg2 1/1 Running 0 22h 172.16.154.23 node1 <none> <none>
test-5977dc5756-zgw4c 1/1 Running 0 22h 172.16.44.33 node2 <none> <none>
[root@node1 ~]# kubectl get svc -n test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc ClusterIP 10.233.23.79 <none> 80/TCP 19d
[root@node1 ~]#
[root@node1 ~]# kubectl get endpoints -n test
NAME ENDPOINTS AGE
nginx-svc 172.16.154.23:80,172.16.28.42:80,172.16.44.33:80 19d
[root@node1 ~]# 我们在物理机使用dig指定coredns 地址进行解析svc,如下:
[root@node1 ~]# dig @10.233.0.3 nginx-svc.test.svc.test.com; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.13 <<>> @10.233.0.3 nginx-svc.test.svc.test.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 1089
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;nginx-svc.test.svc.test.com. IN A;; ANSWER SECTION:
nginx-svc.test.svc.test.com. 30 IN A 10.233.23.79 ###此处得知返回结果为cluster ip;; Query time: 1 msec
;; SERVER: 10.233.0.3#53(10.233.0.3)
;; WHEN: Thu May 09 14:42:27 CST 2024
;; MSG SIZE rcvd: 99- headless service
[root@node1 ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
maradb-0 1/1 Running 0 22h 172.16.44.32 node2 <none> <none>
maradb-1 1/1 Running 0 22h 172.16.28.44 node3 <none> <none>
maradb-2 1/1 Running 0 21h 172.16.154.25 node1 <none> <none>
[root@node1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 396d
mariadb ClusterIP None <none> 3306/TCP 22h我们在物理机使用dig指定coredns 地址进行解析svc,如下:
[root@node1 ~]# dig @10.233.0.3 mariadb.default.svc.test.com; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.13 <<>> @10.233.0.3 mariadb.default.svc.test.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 35068
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;mariadb.default.svc.test.com. IN A;; ANSWER SECTION:
mariadb.default.svc.test.com. 30 IN A 172.16.28.44 ##此处得知返回的结果为pod的真实地址
mariadb.default.svc.test.com. 30 IN A 172.16.154.25
mariadb.default.svc.test.com. 30 IN A 172.16.44.32;; Query time: 1 msec
;; SERVER: 10.233.0.3#53(10.233.0.3)
;; WHEN: Thu May 09 14:27:43 CST 2024
;; MSG SIZE rcvd: 189五、使用无头服务的好处
-
简化服务发现:通过DNS记录直接提供Pod列表,简化了服务发现过程,特别是对于需要直接与各个实例交互的应用。
-
增强控制灵活性:允许应用层决定如何分配请求到各个Pod,适应特定的业务逻辑或性能需求。
-
支持有状态应用部署:更好地匹配有状态应用的部署需求,确保数据的一致性和可靠性。
-
减少网络跳转:去除了一层负载均衡,减少了网络延迟,提高了通信效率。
使用无头服务是为了在某些特定场景下,绕过Kubernetes的常规服务代理和负载均衡机制,以实现更直接、更灵活的服务实例访问方式,特别是在需要保持会话状态、实现自定义负载策略或部署有状态应用的场景中。这种方式提供了更高的灵活性和对底层基础设施的直接控制能力。
相关文章:

Kubernetes之Headless Services
Kubernetes中的Headless Services(无头服务)是一种特殊类型的服务(Service)定义,它不提供传统意义上的负载均衡和集群IP地址分配。在无头服务中,spec.clusterIP 字段被显式设置为None ,Kubernet…...

银行监管报送系统系列介绍(十七):一表通2.0
国家金融监督管理总局于9月发布了【一表通2.0(试用版)】(简称:一表通2.0),在原试点报送范围的基础上扩大了试点报送区域,意味着将陆续扩大试报送机构范围,推进的速度已明显加快。尽早…...
网络安全之OSPF进阶
该文针对OSPF进行一个全面的认识。建议了解OSPF的基础后进行本文的一个阅读能较好理解本文。 OSPF基础的内容请查看:网络安全之动态路由OSPF基础-CSDN博客 OSPF中更新方式中的触发更新30分钟的链路状态刷新。是因为其算法决定的,距离矢量型协议是边算边…...
Ubuntu虚拟机上推荐一款免费好用的git版本管理工具
工具叫: gitg 软件界面如下: FR:徐海涛(hunkxu)...
python下载及安装
1、python下载地址: Python Releases for Windows | Python.orgThe official home of the Python Programming Languagehttps://www.python.org/downloads/windows/ 2、python安装 (1) 直接点击下载后的可执行文件.exe (2&…...
visual studio2022 JNI极简开发流程
文章目录 1 创建java类2 生成JNI头文件3 使用visual studio2022创建DLL项目3.1 选择模板中(Windows桌面向导)3.2 为项目命名3.3 选择应用程序类型为动态链接库3.4 项目概览 4 导入需要的头文件4.1 导入需要的头文件4.2 修改头文件 5 编写C实现6 生成dll文…...
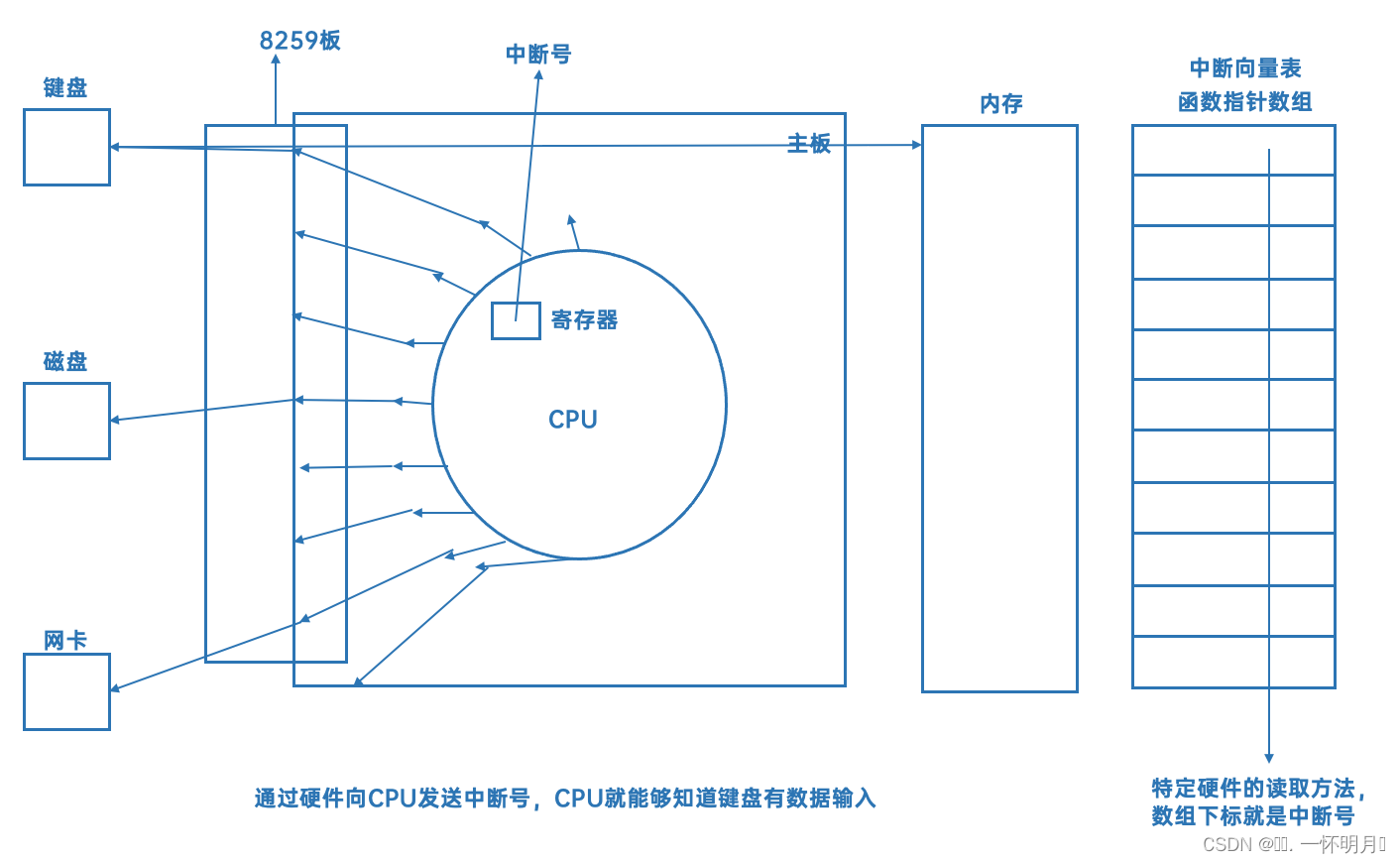
Linux 第三十章
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C,linux 🔥座右铭:“不要等到什么都没有了…...
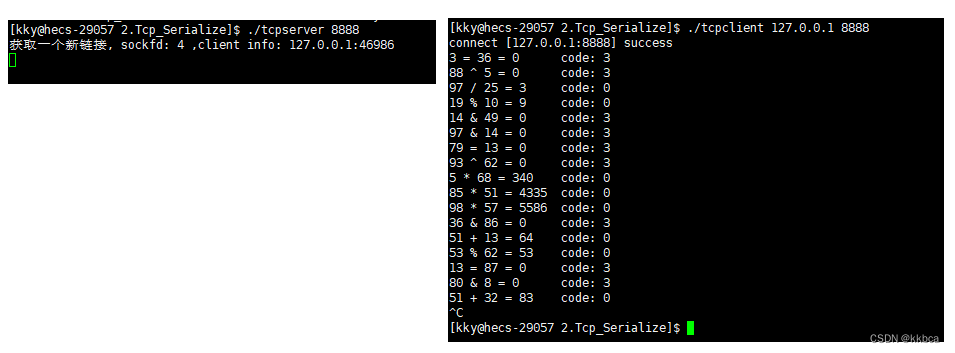
Linux网络——自定义序列化与反序列化
前言 之前我们学习过socket之tcp通信,知道了使用tcp建立连接的一系列操作,并通过write与read函数能让客户端与服务端进行通信,但是tcp是面向字节流的,有可能我们write时只写入了部分数据,此时另一端就来read了&#x…...

大模型介绍
大模型通常指的是参数量超过亿级别,甚至千亿级别的深度学习模型。这类模型能够处理更加复杂的任务,并在各项基准测试中取得了优异的成绩。大模型在自然语言处理、计算机视觉、推荐系统等领域都取得了显著的成果。 大模型的主要优势在于其强大的表征能力&…...

【思维】根号分治
写在前面的话: 个人理解 根号分治本身就是一种卡着评测机过题的做法,所以非必要不要写 #define int long long !!! 本篇博客参考:暴力美学——浅谈根号分治 做到过两三题根号分治了,来总结一下…...
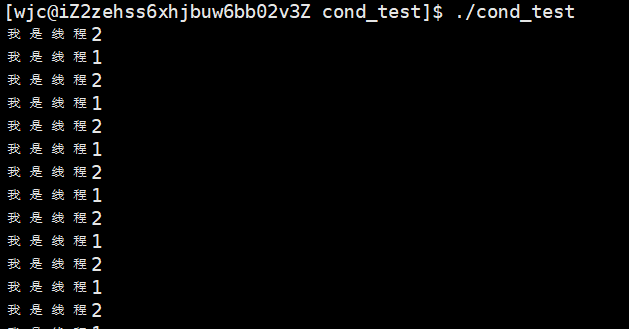
Linux线程(三)死锁与线程同步
目录 一、什么是死锁 死锁的四个必要条件 如何避免死锁 避免死锁算法 二、Linux线程同步 三 、条件变量 1、条件变量基本原理 2、条件变量的使用 3、条件变量使用示例 为什么 pthread_cond_wait 需要互斥量? 一、什么是死锁 死锁是计算机科学中的一个概念,…...
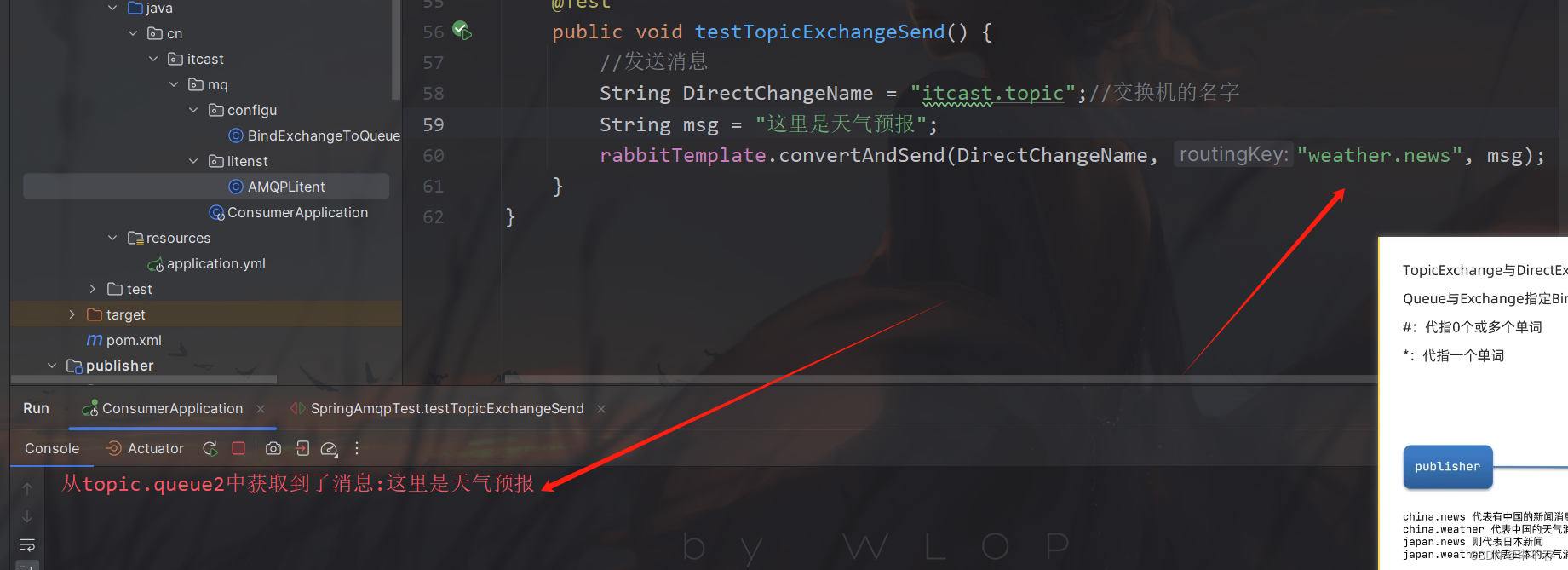
SpringAMQP 发布订阅-TopicExchange
根据这个模型编写代码: RabbitListener(bindings QueueBinding(value Queue(name "topic.queue1"),exchange Exchange(name "itcast.topic",type ExchangeTypes.TOPIC),key {"china.#"}))public void listenTopicQueue1(String msg){Syst…...
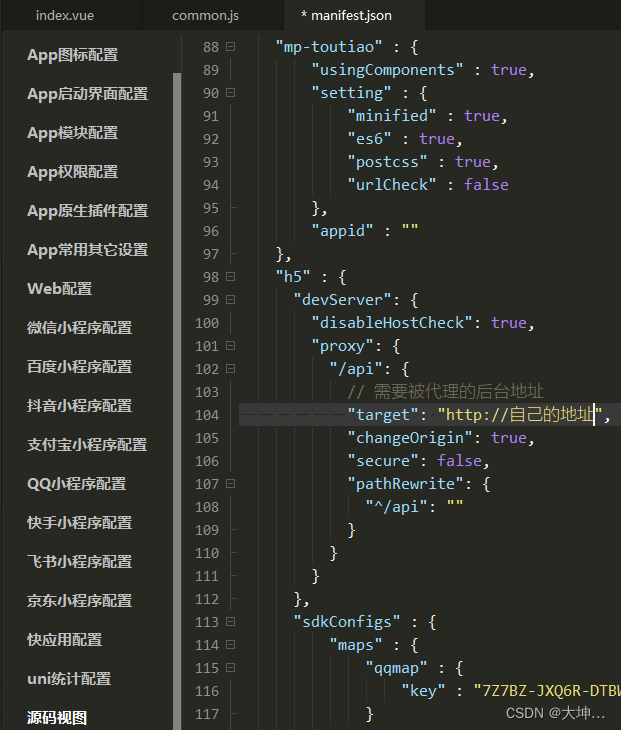
uniapp h5 配置代理服务器
"devServer": {"disableHostCheck": true,"proxy": {"/api": {// 需要被代理的后台地址"target": "http://自己的地址","changeOrigin": true,"secure": false,"pathRewrite": {&q…...

使用Apache Spark从MySQL到Kafka再到HDFS的数据转移
使用Apache Spark从MySQL到Kafka再到HDFS的数据转移 在本文中,将介绍如何构建一个实时数据pipeline,从MySQL数据库读取数据,通过Kafka传输数据,最终将数据存储到HDFS中。我们将使用Apache Spark的结构化流处理和流处理功能&#…...

一篇文章拿下Redis 通用命令
文章目录 Redis数据结构介绍Redis 通用命令命令演示KEYSDELEXISTSEXPIRE RedisTemplate 中的通用命令 本篇文章介绍 Redis 的通用命令, 通用命令在 Redis 的所有数据类型下都使用, 学好通用命令可以让我们更好的使用 Redis. Redis数据结构介绍 Redis 是一个key-value的数据库&…...

锂电池充电充放电曲线分析
前言 锂电池的充电曲线通常包括三个阶段:恒流充电阶段、恒压充电阶段和滞后充电阶段。在恒流充电阶段,电流保持恒定,电压逐渐增加;在恒压充电阶段,电压保持恒定,电流逐渐减小;在滞后充电阶段,电流进一步减小,电池开始充满。通过监测这些阶段的电流和电压变化,可以评…...
)
vue3 第二十九节 (vue3 事件循环之nextTick)
引言 vue 项目中为什么要使用 nextTick 这个函数,是做什么用的,解决了哪些问题 1、nextTick 作用 用于处理DOM更新完成之后,执行回调函数的方法; 2、实现方案 vue2 中 nextTick() 是基于浏览器的 异步队列和微任务队列而执行…...

使用Flask-SocketIO构建实时Web应用
文章目录 准备工作编写代码编写HTML模板运行应用 随着互联网的发展,实时性成为了许多Web应用的重要需求之一。传统的HTTP协议虽然可以实现实时通信,但是其长轮询等机制效率低下,无法满足高并发、低延迟的需求。为了解决这一问题,诞…...
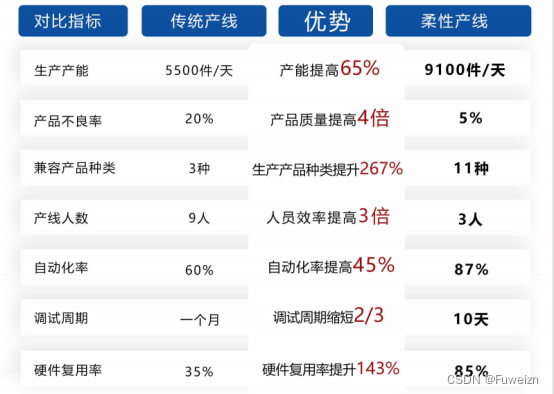
可重构柔性装配产线:为工业制造领域注入了新的活力
随着科技的飞速发展,智能制造正逐渐成为引领工业革新的重要力量。在这一浪潮中,可重构柔性装配产线以其独特的技术优势和创新理念,为工业制造领域注入了新的活力,开启了创新驱动的智能制造新篇章。 可重构柔性装配产线是基于富唯智…...
懒人网址导航源码v3.9
测试环境 宝塔Nginx -Tengine2.2.3的PHP5.6 MySQL5.6.44 为防止调试错误,建议使用测试环境运行的php与mysql版本 首先用phpMyAdmin导入数据库文件db/db.sql 如果导入不行,请直接复制数据库内容运行sql语句也可以 再修改config.php来进行数据库配置…...

数据缺失处理实战指南:从原理到应用,掌握KNN与MICE填补技术
1. 项目概述:数据缺失,一个绕不开的“坑”做数据分析、机器学习或者任何和数据打交道的工作,你大概率都遇到过这种情况:打开数据集,满怀期待地准备大干一场,结果发现好几列数据里都夹杂着刺眼的“NaN”、“…...

oracle数据库的了解和使用
文章目录 1. 概述1)数据库2)实例3)表空间4)用户5) schema6)数据库的持久化7)注释8)mysql和oracle数据库逻辑结构类比 2. 数据库操作1)创建表空间2)创建操作表空间的用户3…...

如何用OpenUtau实现多语言歌声合成:3大音素处理方案完全指南
如何用OpenUtau实现多语言歌声合成:3大音素处理方案完全指南 【免费下载链接】OpenUtau Open singing synthesis platform / Open source UTAU successor 项目地址: https://gitcode.com/gh_mirrors/op/OpenUtau OpenUtau作为开源歌声合成平台,通…...

Gemini 3.5十大应用场景:从代码生成到视频创作
一、软件开发场景 1.1 代码自动生成 Gemini 3.5 Flash在编码基准测试中达到76.2%,可以: 理解复杂技术文档生成高质量代码自动编写测试用例 # 代码生成示例 prompt """ 根据以下需求编写Python代码: 1. 创建一个REST API服…...

Nginx缓慢HTTP攻击防护:从Slowloris原理到四层生产加固
1. 这不是误报:缓慢HTTP拒绝服务攻击的真实杀伤力与Nginx暴露面 “检测到目标主机可能存在缓慢的http拒绝服务攻击”——当安全扫描工具弹出这行提示时,很多运维同学的第一反应是点掉、忽略、加白名单。我见过三次真实事故:一次是电商大促前…...

Unity工业级机械仿真:刚体约束链与运动学反解实战
1. 这不是“玩具模型”,而是一套可投产验证的机械运动逻辑沙盒在Unity里做机械结构仿真,很多人第一反应是“做个动画演示”——齿轮转得漂亮、连杆动得丝滑、液压缸伸缩带点粒子特效,导出个MP4发给客户就算交付。但MGS-Machinery这个项目完全…...

Playwright×CoPilot:用自然语言驱动UI自动化的新范式
1. 这不是“写代码”,而是让AI替你“看屏幕、点按钮、填表单”“Playwright CoPilot:UI自动化的超级加速器”——这个标题里藏着一个正在悄悄改变测试和RPA工作流的事实:我们正从“手写定位器硬编码断言”的时代,跨入“用自然语言…...
)
2026实测|5款AI论文写作软件深度对比(含降重/AIGC检测/价格)
根据2026年最新的实测数据,我为你整理了一份好用的AI论文写作软件清单,按适用场景分类,你可以根据自己的需求快速匹配。 📊 核心工具速览对比 工具名称核心优势最佳适用场景价格参考推荐指数PaperRed中文全流程、降重合规、文献真…...

终极AI音乐创作工具:5分钟生成专业级歌曲翻唱
终极AI音乐创作工具:5分钟生成专业级歌曲翻唱 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 你是否曾经梦想…...

双翌精翌亮相工业软件产业协同对接交流会,共筑国产精密测量新生态
本次交流会以“同心聚链、智造共赢”为主题,汇聚了来自全国各地的工业软件开发商、高端装备制造商、系统集成商以及行业专家,围绕工业软件国产化替代、软硬件协同适配、产业生态共建等核心议题展开深入探讨。在国家信创战略加速推进的大背景下࿰…...