使用Apache Spark从MySQL到Kafka再到HDFS的数据转移
使用Apache Spark从MySQL到Kafka再到HDFS的数据转移
在本文中,将介绍如何构建一个实时数据pipeline,从MySQL数据库读取数据,通过Kafka传输数据,最终将数据存储到HDFS中。我们将使用Apache Spark的结构化流处理和流处理功能,以及Kafka和HDFS作为我们的数据传输和存储工具。
1、环境设置:
首先,确保在您的环境中正确安装并配置了mysql、Kafka和HDFS。同时需要在idea中构建依赖配置的pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>spark_project</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><scala.version>2.12.12</scala.version><spark.version>3.2.0</spark.version><kafka.version>2.8.1</kafka.version></properties><dependencies><!-- Spark dependencies --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.76</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql-kafka-0-10_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>${spark.version}</version></dependency><!-- Kafka dependencies --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version></dependency><!-- Scala library --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency> </dependencies>
</project>
mysql中表结构:

2、从MySQL读取数据到Kafka:
我们将使用Spark的结构化流处理功能从MySQL数据库中读取数据,并将其转换为JSON格式,然后将数据写入到Kafka主题中。以下是相应的Scala代码:
package org.example.mysql2kafka2hdfsimport org.apache.spark.sql.SparkSessionimport java.util.Propertiesobject Mysql2Kafka {def main(args: Array[String]): Unit = {// 创建 SparkSessionval spark = SparkSession.builder().appName("MySQLToKafka").master("local[*]").getOrCreate()// 设置 MySQL 连接属性val mysqlProps = new Properties()mysqlProps.setProperty("user", "root")mysqlProps.setProperty("password", "12345678")mysqlProps.setProperty("driver", "com.mysql.jdbc.Driver")// 从 MySQL 数据库中读取数据val jdbcDF = spark.read.jdbc("jdbc:mysql://localhost:3306/mydb", "comment", mysqlProps)// 将 DataFrame 转换为 JSON 字符串val jsonDF = jdbcDF.selectExpr("to_json(struct(*)) AS value")// 将数据写入 KafkajsonDF.show()jsonDF.write.format("kafka").option("kafka.bootstrap.servers", "localhost:9092").option("topic", "comment").save()// 停止 SparkSessionspark.stop()}}以上代码首先创建了一个SparkSession,然后设置了连接MySQL所需的属性。接着,它使用jdbc.read从MySQL数据库中读取数据,并将数据转换为JSON格式,最后将数据写入到名为"comment"的Kafka主题中。提示:topic主题会被自动创建。
从Kafka消费数据并写入HDFS:
接下来,我们将设置Spark Streaming来消费Kafka中的数据,并将数据保存到HDFS中。以下是相应的Scala代码:
package org.example.mysql2kafka2hdfsimport com.alibaba.fastjson.JSON
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}case class Comment(author_name:String,fans:String,comment_text:String,comment_time:String,location:String,user_gender:String)object kafka2Hdfs {def main(args: Array[String]): Unit = {// 设置 SparkConfval sparkConf = new SparkConf().setAppName("KafkaToHDFS").setMaster("local[*]")// 创建 StreamingContext,每秒处理一次val ssc = new StreamingContext(sparkConf, Seconds(1))// 设置 Kafka 相关参数val kafkaParams = Map[String, Object]("bootstrap.servers" -> "localhost:9092", // Kafka broker 地址"key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "spark-consumer-group", // Spark 消费者组"auto.offset.reset" -> "earliest", // 从最新的偏移量开始消费"enable.auto.commit" -> (false: java.lang.Boolean) // 不自动提交偏移量)// 设置要订阅的 Kafka 主题val topics = Array("comment")// 创建 Kafka Direct Streamval stream = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))// 从 Kafka 中读取消息,然后将其写入 HDFSstream.map({rdd=>val comment = JSON.parseObject(rdd.toString(), classOf[Comment])comment.author_name+","+comment.comment_text+","+comment.comment_time+","+comment.fans+","+comment.location+","+comment.user_gender}).foreachRDD { rdd =>if (!rdd.isEmpty()) {println(rdd)rdd.saveAsTextFile("hdfs://hadoop101:8020/tmp/")}}// 启动 Spark Streamingssc.start()ssc.awaitTermination()}}以上代码设置了Spark Streaming来消费Kafka中的数据。它将JSON格式的数据解析为Comment类对象,并将其保存为逗号分隔的文本文件,最终存储在HDFS的/tmp目录中。

结论:
通过本文的介绍和示例代码,您现在应该了解如何使用Apache Spark构建一个实时数据流水线,从MySQL数据库读取数据,通过Kafka传输数据,最终将数据保存到HDFS中。这个流水线可以应用于各种实时数据处理和分析场景中。
**如有遇到问题可以找小编沟通交流哦。另外小编帮忙辅导大课作业,学生毕设等。不限于python,java,大数据,模型训练等。 hadoop hdfs yarn spark Django flask flink kafka flume datax sqoop seatunnel echart可视化 机器学习等 **

相关文章:
使用Apache Spark从MySQL到Kafka再到HDFS的数据转移
使用Apache Spark从MySQL到Kafka再到HDFS的数据转移 在本文中,将介绍如何构建一个实时数据pipeline,从MySQL数据库读取数据,通过Kafka传输数据,最终将数据存储到HDFS中。我们将使用Apache Spark的结构化流处理和流处理功能&#…...

一篇文章拿下Redis 通用命令
文章目录 Redis数据结构介绍Redis 通用命令命令演示KEYSDELEXISTSEXPIRE RedisTemplate 中的通用命令 本篇文章介绍 Redis 的通用命令, 通用命令在 Redis 的所有数据类型下都使用, 学好通用命令可以让我们更好的使用 Redis. Redis数据结构介绍 Redis 是一个key-value的数据库&…...

锂电池充电充放电曲线分析
前言 锂电池的充电曲线通常包括三个阶段:恒流充电阶段、恒压充电阶段和滞后充电阶段。在恒流充电阶段,电流保持恒定,电压逐渐增加;在恒压充电阶段,电压保持恒定,电流逐渐减小;在滞后充电阶段,电流进一步减小,电池开始充满。通过监测这些阶段的电流和电压变化,可以评…...
)
vue3 第二十九节 (vue3 事件循环之nextTick)
引言 vue 项目中为什么要使用 nextTick 这个函数,是做什么用的,解决了哪些问题 1、nextTick 作用 用于处理DOM更新完成之后,执行回调函数的方法; 2、实现方案 vue2 中 nextTick() 是基于浏览器的 异步队列和微任务队列而执行…...

使用Flask-SocketIO构建实时Web应用
文章目录 准备工作编写代码编写HTML模板运行应用 随着互联网的发展,实时性成为了许多Web应用的重要需求之一。传统的HTTP协议虽然可以实现实时通信,但是其长轮询等机制效率低下,无法满足高并发、低延迟的需求。为了解决这一问题,诞…...
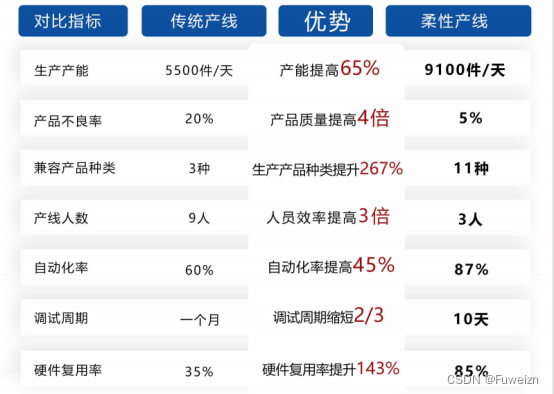
可重构柔性装配产线:为工业制造领域注入了新的活力
随着科技的飞速发展,智能制造正逐渐成为引领工业革新的重要力量。在这一浪潮中,可重构柔性装配产线以其独特的技术优势和创新理念,为工业制造领域注入了新的活力,开启了创新驱动的智能制造新篇章。 可重构柔性装配产线是基于富唯智…...
懒人网址导航源码v3.9
测试环境 宝塔Nginx -Tengine2.2.3的PHP5.6 MySQL5.6.44 为防止调试错误,建议使用测试环境运行的php与mysql版本 首先用phpMyAdmin导入数据库文件db/db.sql 如果导入不行,请直接复制数据库内容运行sql语句也可以 再修改config.php来进行数据库配置…...
)
springboot 开启缓存 @EnableCaching(使用redis)
添加依赖 pom.xml <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency>application.yml 配置redis连参数 spring:# redis 配置redis:# 地址host: 127.0.0.…...
Adobe After Effects AE v24.3.0 解锁版 (视频合成及视频特效制作)
Adobe系列软件安装目录 一、Adobe Photoshop PS 25.6.0 解锁版 (最流行的图像设计软件) 二、Adobe Media Encoder ME v24.3.0 解锁版 (视频和音频编码渲染工具) 三、Adobe Premiere Pro v24.3.0 解锁版 (领先的视频编辑软件) 四、Adobe After Effects AE v24.3.0 解锁版 (视…...
Qt---文件系统
一、基本文件操作 1. QFile对文件进行读和写 QFile file( path 文件路径) 读: file.open(打开方式) QlODevice::readOnly 全部读取->file.readAll(),按行读->file.readLine(),atend()->判断是否读到文件尾 …...
)
ruoyi-vue-pro 使用记录(2)
ruoyi-vue-pro 使用记录(2) 数据库商城商品模块数据表营销数据库交易数据库统计数据库 数据库 商城 参考官方文档 ruoyi-vue-pro yudao 项目商城 mall 模块启用及相关SQL脚本 商品模块(中心)以 product_ 作为前缀的表交易模块…...

centos7中如何全局搜索一下nginx的配置文件?
在CentOS 7中搜索Nginx的配置文件,你可以使用一些常用的命令行工具,比如find、grep等。这些工具可以帮助你在文件系统中查找文件,也可以用来查找Docker容器内部的文件,只要你知道如何访问容器的文件系统。 1. 搜索系统中的Nginx配…...

2024年5月10日有感复盘
2024年5月10日有感复盘 时间 今天是一个很美好的一天,原因是很平凡,读书很平凡,玩游戏很平凡,然后生活很平凡,未来可期,听歌很舒服,很喜欢一个人呆在图书馆的感觉,很喜欢发呆&…...

C++通过json文件配置参数
一、安装nlohmann json nlohmann json:安装_nlohmann安装-CSDN博客 依次执行下面指令: git clone https://gitee.com/cuihongxi/mov_from_github.gitcd json-developmkdir buildcd buildcmake ..makesudo make install 二、安装完成后使用 #include…...
idea连接远程仓库
git ->克隆。 url为远程仓库的地址,输入好后,选择项目存放目录,再点击克隆 点击新窗口打开。 切换到对应分支...

初始Django
初始Django 一、Django的历史 Django 是从真实世界的应用中成长起来的,它是由堪萨斯(Kansas)州 Lawrence 城中的一个网络开发小组编写的。它诞生于 2003 年秋天,那时 Lawrence Journal-World 报纸的程序员 Adrian Holovaty 和…...

leetcode56--合并区间
题目描述 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入:interv…...

赋能数据库智能托管,Akamai 发布首款云计算业务线产品!
为了尽可能地简化数据库管理的复杂性,降低数据库成本,Akamai 在近期推出了首款 DBaaS(数据库即服务)产品——Linode Managed Database。这一数据库产品是 Akamai 自3月份收购 Linode 后发布的首款计算业务线产品。 一、更易用的数…...
:杂项篇)
Go语言系统学习笔记(三):杂项篇
1. 写在前面 公司的新业务开发需要用到go语言,虽然之前没接触过这门语言,但在大模型的帮助下,边看项目边写代码也能进行go的项目开发,不过,写了一段时间代码之后,总感觉对go语言本身,我的知识体…...

黄仁勋炉边对话:创业的超能力与英伟达的加速计算之旅
在TiECon 2024大会上,英伟达的创始人兼CEO黄仁勋与风投公司Mayfield的管理合伙人纳文查德哈进行了一场深入的炉边对话。黄仁勋不仅分享了英伟达的创业故事,还谈到了他对创业和加速计算的深刻见解。下面是我对这次对话的总结,希望能给正在创业…...

Ostrakon-VL-8B入门必看:Gradio Web UI快速启动与单图分析详解
Ostrakon-VL-8B入门必看:Gradio Web UI快速启动与单图分析详解 如果你正在寻找一个能看懂店铺、厨房、商品图片,并能回答你各种问题的AI助手,那么Ostrakon-VL-8B可能就是你要找的答案。这是一个专门为餐饮服务和零售商店场景优化的多模态视觉…...

AI模型输出流被中间人篡改?FastAPI 2.0异步响应完整性保障方案:TLS 1.3+Chunked-Hash-Signature+WebTransport双通道校验
第一章:AI模型输出流被中间人篡改?FastAPI 2.0异步响应完整性保障方案:TLS 1.3Chunked-Hash-SignatureWebTransport双通道校验在高敏感AI服务场景中,LLM流式响应(如 Server-Sent Events 或 chunked transfer encoding&…...

LN3608 2A 高效率升压 DC/DC 电压调整器
■ 产品概述 LN3608 是一款微小型、高效率、升压型 DC/DC 调整器。电路由电流模 PWM 控制环路,误差放大器,斜波补偿电路,比较器和功率开关等模块组成。该芯片可在较宽负载范围内高效稳定的工作,内置一个 4A 的功率开关和软启动保护…...

作业3.7
10.import math# 输入三条边a float(input("请输入三角形的边A:"))b float(input("请输入三角形的边B:"))c float(input("请输入三角形的边C:"))# 判断是否能构成三角形if a > 0 and b > 0 and c >…...

如何用clawPDF高效解决日常办公中的5大文档处理难题?
如何用clawPDF高效解决日常办公中的5大文档处理难题? 【免费下载链接】clawPDF Open Source Virtual (Network) Printer for Windows that allows you to create PDFs, OCR text, and print images, with advanced features usually available only in enterprise s…...

3步实战Mermaid Live Editor:告别复杂图表工具,实现高效可视化协作
3步实战Mermaid Live Editor:告别复杂图表工具,实现高效可视化协作 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending…...

LFM2.5-1.2B-Thinking-GGUF入门必看:llama.cpp+GGUF轻量模型部署全流程
LFM2.5-1.2B-Thinking-GGUF入门必看:llama.cppGGUF轻量模型部署全流程 1. 模型与平台介绍 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低资源环境优化设计。该模型采用GGUF格式,结合llama.cpp运行时,能…...

Wan2.2-I2V-A14B惊艳效果:动态镜头推移、自然光影变化、流畅运镜展示
Wan2.2-I2V-A14B惊艳效果:动态镜头推移、自然光影变化、流畅运镜展示 1. 专业级视频生成能力 Wan2.2-I2V-A14B模型带来了令人惊叹的视频生成效果,能够将简单的文字描述转化为专业水准的动态视频。这个模型特别擅长处理复杂的镜头运动和光影变化&#x…...

Google Cloud Python客户端库版本管理终极指南:如何选择和使用不同版本
Google Cloud Python客户端库版本管理终极指南:如何选择和使用不同版本 【免费下载链接】google-cloud-python Google Cloud Client Libraries for Python 项目地址: https://gitcode.com/gh_mirrors/go/google-cloud-python Google Cloud Python客户端库为开…...

终极Qwen-Agent DevOps集成指南:AI助手的持续集成与部署全流程解析
终极Qwen-Agent DevOps集成指南:AI助手的持续集成与部署全流程解析 【免费下载链接】Qwen-Agent Agent framework and applications built upon Qwen>3.0, featuring Function Calling, MCP, Code Interpreter, RAG, Chrome extension, etc. 项目地址: https:/…...