pyppeteer中文文档
目录
1.命令
2.环境变量
3.Launcher(启动器)
4.浏览器类
5.浏览器上下文类
6.页面类
7.Worker 类
8.键盘类
9.鼠标类
10.Tracing类
11.对话框类
12.控制台消息类
13.Frame 类
14.执行上下文类
15.JSHandle 类
16.元素句柄类
17.请求类
18.响应类
19.Target 类
20.CDPSession类
21.Coverage类
22.调试
23.补充
安装
用法
puppeteer 和 pyppeteer 之间的区别
选项的关键字参数
元素选择器方法名称 ( $-> querySelector)
和Page.evaluate() _Page.querySelectorEval()
未来计划
学分
内容
索引和表格
pyppeteer官方说明网站
https://miyakogi.github.io/pyppeteer/reference.htmlhttps://miyakogi.github.io/pyppeteer/reference.html
1.命令
pyppeteer-install:下载并安装chromium for pyppeteer。-
pyppeteer要求Python >= 3.6
使用来自PyP的pip安装:
pip install pyppeteer或者从以下网站安装最新版本 this github repo:
pip install -U git+https://github.com/pyppeteer/pyppeteer@dev
2.环境变量
-
$PYPPETEER_HOME:指定pyppeteer要使用的目录。Pyppeteer使用这个目录来提取下载的Chromium,并创建临时用户数据目录。默认位置取决于平台:- windows:
C:\Users\<username>\AppData\Local\pyppeteer - OS X:
/Users/<username>/Library/Application Support/pyppeteer - Linux:
/home/<username>/.local/share/pyppeteer- 或者在
$XDG_DATA_HOME/pyppeteer如果$XDG_DATA_HOME已定义。
- 或者在
详情见appdirs · PyPI.
- windows:
-
$PYPPETEER_DOWNLOAD_HOST:覆盖用于下载Chromium的URL的主机部分。默认为https://storage.googleapis.com. -
$PYPPETEER_CHROMIUM_REVISION:指定您希望pyppeteer使用的某个版本的chromium。默认值可通过以下方式检查pyppeteer.__chromium_revision__.
3.Launcher(启动器)
pyppeteer.launcher.launch(options: dict = None, **kwargs) →pyppeteer.browser.Browser [源码]
启动chrome进程并返回Browser.
此功能是的快捷方式Launcher(options, **kwargs).launch().
可用选项包括:
ignoreHTTPSErrors(bool):是否忽略HTTPS错误。默认为False.headless(bool):是否以无头模式运行浏览器。默认为True除非appMode或者devtools选项是True.executablePath(str):运行Chromium或Chrome可执行文件的路径,而不是默认的捆绑Chromium。slowMo(int|float):将pyppeteer操作减慢指定的毫秒数。args(List[str]):要传递给浏览器进程的附加参数(标志)。ignoreDefaultArgs(bool):不要使用pyppeteer的默认参数。这是一个危险的选择;小心使用。handleSIGINT(bool):按Ctrl+C关闭浏览器进程。默认为True.handleSIGTERM(bool):关闭SIGTERM上的浏览器进程。默认为True.handleSIGHUP(bool):关闭SIGHUP上的浏览器进程。默认为True.dumpio(bool):是否将浏览器进程stdout和stderr通过管道传输到process.stdout和process.stderr。默认为False.userDataDir(字符串):用户数据目录的路径。env(dict):指定对浏览器可见的环境变量。默认与python过程相同。devtools(bool):是否为每个选项卡自动打开DevTools面板。如果此选项为True,的headless将设置选项False.logLevel(int|str):打印日志的日志级别。默认与根日志记录器相同。autoClose(bool):脚本完成时自动关闭浏览器进程。默认为True.loop(asyncio。AbstractEventLoop):事件循环(实验的).appMode(bool):已弃用。
注意
Pyppeteer也可以用来控制Chrome浏览器,但它最好与它捆绑的Chrome版本一起使用。不能保证它能与任何其他版本一起工作。使用executablePath选择时要格外小心。
pyppeteer.launcher.connect(options: dict = None, **kwargs) → pyppeteer.browser.Browser [来源]
连接到现有的chrome。
browserWSEndpoint选项是连接到chrome所必需的。格式是ws://${host}:${port}/devtools/browser/<id>。这个值可以通过wsEndpoint 获取.
可用选项包括:
browserWSEndpoint(str):要连接的浏览器websocket端点。(需要)ignoreHTTPSErrors(bool):是否忽略HTTPS错误。默认为False.slowMo(int|float):按指定的毫秒数减慢pyppeteer的速度。logLevel(int|str):打印日志的日志级别。默认与根日志记录器相同。loop(asyncio。AbstractEventLoop):事件循环(实验的).
pyppeteer.launcher.executablePath()→ str [来源]
获取默认chrome的可执行路径。
4.浏览器类
类 pyppeteer.browser.Browser(连接:pyppeteer.connection.Connection,contextIds:List [str],ignoreHTTPSErrors:bool,setDefaultViewport:bool,process:Optional [subprocess.Popen] = None,closeCallback:Callable [[],Awaitable [None]] = None , **kwargs )[来源]
基类:pyee.EventEmitter
浏览器类。
当 pyppeteer 通过launch()或 连接到 chrome 时,会创建一个 Browser 对象connect()。
browserContexts
返回所有打开的浏览器上下文的列表。
在新创建的浏览器中,这将返回一个实例 [BrowserContext]
协程close( ) → 无[来源]
关闭连接并终止浏览器进程。
协程createIncogniteBrowserContext( ) → pyppeteer.browser.BrowserContext[来源]
[弃用] 拼写错误的方法。
改用createIncognitoBrowserContext()方法。
协程createIncognitoBrowserContext( ) → pyppeteer.browser.BrowserContext[来源]
创建一个新的隐身浏览器上下文。
这不会与其他浏览器上下文共享 cookies/缓存。
browser = await launch()
# Create a new incognito browser context.
context = await browser.createIncognitoBrowserContext()
# Create a new page in a pristine context.
page = await context.newPage()
# Do stuff
await page.goto('https://example.com')
...协程disconnect( ) → 无[来源]
断开浏览器。
协程newPage( ) → pyppeteer.page.Page[来源]
在此浏览器上创建新页面并返回其对象。
协程pages( ) → 列表[pyppeteer.page.Page][来源]
获取该浏览器的所有页面。
不可见的页面,例如"background_page",将不会在此处列出。你可以找到然后使用pyppeteer.target.Target.page()。
process
本浏览器的返回过程。
如果浏览器实例是由创建的pyppeteer.launcher.connect(),则返回None。
targets( ) → 列表[pyppeteer.target.Target][来源]
获取浏览器内所有活动目标的列表。
在多个浏览器上下文的情况下,该方法将返回一个列表,其中包含所有浏览器上下文中的所有目标。
协程userAgent( ) → str[来源]
返回浏览器的原始用户代理。
笔记:页面可以使用 覆盖浏览器用户代理 pyppeteer.page.Page.setUserAgent()。
协程version( ) → str[来源]
获取浏览器的版本。
wsEndpoint
返回 websocket 端点 url。
5.浏览器上下文类
类pyppeteer.browser.BrowserContext(浏览器:pyppeteer.browser.Browser,contextId:可选[str] )[来源]
基类:pyee.EventEmitter
BrowserContext 提供多个独立的浏览器会话。
当浏览器启动时,它默认使用一个 BrowserContext。该方法browser.newPage()在默认浏览器上下文中创建一个页面。
如果一个页面打开另一个页面,例如通过调用window.open,弹出窗口将属于父页面的浏览器上下文。
Pyppeteer 允许使用方法创建“隐身”浏览器上下文 browser.createIncognitoBrowserContext()。“隐身”浏览器上下文不会将任何浏览器数据写入磁盘。
# Create new incognito browser context
context = await browser.createIncognitoBrowserContext()
# Create a new page inside context
page = await context.newPage()
# ... do stuff with page ...
await page.goto('https://example.com')
# Dispose context once it's no longer needed
await context.close()browser
返回此浏览器上下文所属的浏览器。
协程close( ) → 无[来源]
关闭浏览器上下文。
所有属于浏览器上下文的目标都将被关闭。
笔记:只能关闭隐身浏览器上下文。
isIncognite( ) → 布尔值[来源]
[弃用] 拼写错误的方法。
改用isIncognito()方法。
isIncognito( ) → 布尔值[来源]
返回 BrowserContext 是否隐身。
默认浏览器上下文是唯一的非隐身浏览器上下文。
笔记:无法关闭默认浏览器上下文。
协程newPage( ) → pyppeteer.page.Page[来源]
在浏览器上下文中创建一个新页面。
targets( ) → 列表[pyppeteer.target.Target][来源]
返回浏览器上下文中所有活动目标的列表。
6.页面类
类pyppeteer.page.Page(客户端:pyppeteer.connection.CDPSession,目标:Target,frameTree:Dict [KT,VT],ignoreHTTPSErrors:bool,screenshotTaskQueue:list = None )[来源]
基类:pyee.EventEmitter
页面类。
此类提供与单个 chrome 选项卡交互的方法。一个 Browser对象可能有多个页面对象。
该类Page发出各种可以通过使用或方法Events处理的类,它继承自 pyee的类。ononceEventEmitter
Events=命名空间(Close='close',Console='console',DOMContentLoaded='domcontentloaded',Dialog='dialog',Error='error',FrameAttached='frameattached',FrameDetached='framedetached',FrameNavigated='framenavigated' , Load='load', Metrics='metrics', PageError='pageerror', Request='request', RequestFailed='requestfailed', RequestFinished='requestfinished', Response='response', WorkerCreated='workercreated', WorkerDestroyed ='workerdestroyed')
可用事件。
协程J(选择器:str ) →可选[pyppeteer.element_handle.ElementHandle]
别名为querySelector()
协程JJ(选择器:str ) →列表[pyppeteer.element_handle.ElementHandle]
别名为querySelectorAll()
协程JJeval(选择器:str,pageFunction:str,*args ) →任何
别名为querySelectorAllEval()
协程Jeval(选择器:str,pageFunction:str,*args ) →任何
别名为querySelectorEval()
协程Jx(表达式:str ) →列表[pyppeteer.element_handle.ElementHandle]
别名为xpath()
协程addScriptTag(选项:Dict[KT,VT] = None,**kwargs ) → pyppeteer.element_handle.ElementHandle[来源]
将脚本标签添加到此页面。
url,path或选项之一content是必要的。
url(字符串):要添加的脚本的 URL。path(字符串):要添加的本地 JavaScript 文件的路径。content(字符串):要添加的 JavaScript 字符串。type(字符串):脚本类型。用于module加载 JavaScript ES6 模块。
| 返回元素句柄: | |
|---|---|
| ElementHandle 添加的标签。 | |
协程addStyleTag(选项:Dict[KT,VT] = None,**kwargs ) → pyppeteer.element_handle.ElementHandle[来源]
将样式或链接标记添加到此页面。
url,path或选项之一content是必要的。
url(字符串):要添加的链接标签的 URL。path(字符串):要添加的本地 CSS 文件的路径。content(字符串):要添加的 CSS 字符串。
| 返回元素句柄: | |
|---|---|
| ElementHandle 添加的标签。 | |
协程authenticate(凭证:Dict[str, str] ) →任何[来源]
提供用于 http 身份验证的凭据。
credentials应该是Noneor dict 其中有username和 password字段。
协程bringToFront( ) → 无[来源]
将页面置于最前面(激活选项卡)。
browser
获取页面所属的浏览器。
协程click(选择器:str,选项:dict = None,**kwargs ) →无[来源]
单击匹配的元素selector。
此方法使用 获取元素selector,在需要时将其滚动到视图中,然后用于mouse单击元素的中心。如果没有元素匹配selector,则该方法引发 PageError。
可用的选项是:
button(str):left,right, 或middle, 默认为left.clickCount(整数):默认为 1。delay(int|float):等待时间,以毫秒为mousedown单位mouseup。默认为 0。
笔记
如果此方法触发导航事件并且有一个单独的waitForNavigation(),您最终可能会遇到产生意外结果的竞争条件。单击并等待导航的正确模式如下:
await asyncio.gather(page.waitForNavigation(waitOptions),page.click(selector, clickOptions), )
协程close(选项:Dict[KT,VT] = None,**kwargs ) →无[来源]
关闭此页面。
可用选项:
runBeforeUnload(bool): 默认为False. 是否运行 前卸载 页面处理程序。
默认情况下,不运行 beforeunload 处理程序。close()
笔记
如果runBeforeUnload传递为True,则可能会调用一个beforeunload 对话框,并且应该通过页面的 dialog事件手动处理。
协程content( ) → str[来源]
获取页面的完整 HTML 内容。
返回包含文档类型的 HTML。
协程cookies( *urls ) → 字典[来源]
获取饼干。
如果未指定 URL,则此方法返回当前页面 URL 的 cookie。如果指定了 URL,则只返回这些 URL 的 cookie。
返回的 cookie 是包含以下字段的字典列表:
name(str)value(str)url(str)domain(str)path(str)expires(number): 以秒为单位的 Unix 时间httpOnly(布尔)secure(布尔)session(布尔)sameSite(str):'Strict'或'Lax'
coverage
返回Coverage。
协程deleteCookie( *cookies ) → 无[来源]
删除 cookie。
cookies应该是包含这些字段的字典:
name(str):必需url(str)domain(str)path(str)secure(布尔)
协程emulate(选项:dict = None,**kwargs ) →无[来源]
模拟给定的设备指标和用户代理。
此方法是调用两个方法的快捷方式:
- setUserAgent()
- setViewport()
options是一个包含这些字段的字典:
viewport(听写)width(int): 以像素为单位的页面宽度。height(int): 以像素为单位的页面宽度。deviceScaleFactor(float): 指定设备比例因子(可以认为是 dpr)。默认为 1。isMobile(bool):标签是否被考虑在内。默认为.meta viewportFalsehasTouch(bool): 指定视口是否支持触摸事件。默认为False.isLandscape(bool): 指定视口是否处于横向模式。默认为False.
userAgent(str): 用户代理字符串。
协程emulateMedia(mediaType: str = None ) →无[来源]
模拟页面的 css 媒体类型。
| 参数: | mediaType ( str ) – 更改页面的 CSS 媒体类型。唯一允许的值为'screen'、'print'和 None。传递None禁用媒体仿真。 |
|---|
协程evaluate(pageFunction: str , *args , force_expr: bool = False ) → 任意[来源]
在浏览器上执行 js-function 或 js-expression 并得到结果。
| 参数: |
|
|---|
注意:force_exproption 是仅关键字参数。
协程evaluateHandle(pageFunction: str , *args ) → pyppeteer.execution_context.JSHandle[来源]
执行此页面上的功能。
evaluate()和 之间的区别evaluateHandle()在于 evaluateHandle返回 JSHandle 对象(不是值)。
| 参数: | pageFunction ( str ) – 要执行的 JavaScript 函数。 |
|---|
协程evaluateOnNewDocument(pageFunction: str , *args ) → 无[来源]
向文档添加 JavaScript 函数。
在以下情况之一中将调用此函数:
- 每当浏览页面时
- 每当附加或导航子框架时。在这种情况下,该函数在新附加框架的上下文中被调用。
协程exposeFunction(名称:str,pyppeteerFunction:Callable[[…],Any] ) →无[来源]
将 python 函数window作为name.
可以从 chrome 进程中调用已注册的函数。
| 参数: |
|
|---|
协程focus(选择器:str ) →无[来源]
聚焦匹配的元素selector。
如果没有元素与 匹配selector,则引发PageError。
frames
获取该页面的所有帧。
协程goBack(选项:dict = None,**kwargs ) →可选[pyppeteer.network_manager.Response][来源]
导航到历史记录中的上一页。
可用选项与方法相同goto()。
回不去就回None。
协程goForward(选项:dict = None,**kwargs ) →可选[pyppeteer.network_manager.Response][来源]
导航到历史记录中的下一页。
可用选项与方法相同goto()。
如果不能前进,返回None。
coroutine goto( url: str , options: dict = None , **kwargs ) → 可选[pyppeteer.network_manager.Response][来源]
去url。
| 参数: | url ( string ) – 将页面导航到的 URL。网址应包括方案,例如https://。 |
|---|
可用的选项是:
timeout(int): 以毫秒为单位的最大导航时间,默认为 30 秒,传递0给禁用超时。可以使用setDefaultNavigationTimeout()方法更改默认值。waitUntil(str|List[str]): 什么时候认为导航成功,默认为load. 给定一个事件字符串列表,在触发所有事件后,导航被认为是成功的。事件可以是:load: 当load事件被触发时。domcontentloaded: 当DOMContentLoaded事件被触发时。networkidle0:当至少 500 毫秒内没有超过 0 个网络连接时。networkidle2:当至少 500 毫秒内不超过 2 个网络连接时。
如果出现以下情况,将Page.goto引发错误:
- 存在 SSL 错误(例如,在自签名证书的情况下)
- 目标网址无效
timeout导航期间超出- 然后主资源加载失败
笔记
goto()引发错误或返回主要资源响应。唯一的例外是导航到about:blank或导航到具有不同哈希值的相同 URL,这将成功并返回None。
笔记
Headless 模式不支持导航到 PDF 文档。
协程hover(选择器:str ) →无[来源]
鼠标悬停在匹配的元素上selector。
如果没有元素与 匹配selector,则引发PageError。
协程injectFile(文件路径:海峡) →海峡[来源]
[已弃用] 将文件注入此页面。
此方法已弃用。改用addScriptTag()。
isClosed( ) → 布尔值[来源]
表示页面已经关闭。
keyboard
获取Keyboard对象。
mainFrame
获取Frame此页面的主要内容。
协程metrics( ) → Dict[str, Any][来源]
获取指标。
返回包含指标作为键/值对的字典:
Timestamp(数字):获取指标样本时的时间戳。Documents(int): 页面中的文档数。Frames(int): 页面中的帧数。JSEventListeners(int): 页面中的事件数。Nodes(int): 页面中的 DOM 节点数。LayoutCount(int): 完整部分页面布局的总数。RecalcStyleCount(int): 页面样式重新计算的总数。LayoutDuration(int):页面持续时间的组合持续时间。RecalcStyleDuration(int):所有页面样式重新计算的组合持续时间。ScriptDuration(int):JavaScript 执行的组合持续时间。TaskDuration(int): 浏览器执行的所有任务的总持续时间。JSHeapUsedSize(float):使用的 JavaScript 堆大小。JSHeapTotalSize(float):总的 JavaScript 堆大小。
mouse
获取Mouse对象。
协程pdf(选项:dict = None,**kwargs ) → 字节[来源]
生成页面的 pdf。
选项:
path(str): 保存 PDF 的文件路径。scale(float): 网页渲染的比例,默认为1.displayHeaderFooter(bool): 显示页眉和页脚。默认为False.headerTemplate(str):打印标题的 HTML 模板。应该是具有以下类的有效 HTML 标记。date: 格式化打印日期title: 文件名url: 文档位置pageNumber: 当前页码totalPages: 文档中的总页数
footerTemplate(str):打印页脚的 HTML 模板。应使用与headerTemplate.printBackground(bool): 打印背景图形。默认为False.landscape(bool): 纸张方向。默认为False.pageRanges(字符串):要打印的纸张范围,例如“1-5,8,11-13”。默认为空字符串,表示所有页面。format(str): 论文格式。如果设置,优先于widthorheight。默认为Letter.width(str):纸张宽度,接受标有单位的值。height(str):纸张高度,接受标有单位的值。margin(dict):页边距,默认为None.top(str):上边距,接受标有单位的值。right(str):右边距,接受标有单位的值。bottom(str):底部边距,接受标有单位的值。left(str): 左边距,接受标有单位的值。
| 退货: | 返回生成的 PDFbytes对象。 |
|---|
笔记
目前仅在无头模式下支持生成 pdf。
pdf()print使用css 媒体生成页面的 pdf 。要生成带有媒体的 pdf screen,请 page.emulateMedia('screen')在调用pdf().
笔记
默认情况下,pdf()生成带有修改颜色的 pdf 以供打印。使用该--webkit-print-color-adjust属性强制渲染精确的颜色。
await page.emulateMedia('screen')
await page.pdf({'path': 'page.pdf'})
、和选项接受标有单位的值width。未标记的值被视为像素。heightmargin
几个例子:
page.pdf({'width': 100}):打印宽度设置为 100 像素。page.pdf({'width': '100px'}):打印宽度设置为 100 像素。page.pdf({'width': '10cm'}):打印宽度设置为 100 厘米。
所有可用的单位是:
px: 像素in: 英寸cm: 厘米mm: 毫米
格式选项是:
Letter:8.5 英寸 x 11 英寸Legal:8.5 英寸 x 14 英寸Tabloid: 11 英寸 x 17 英寸Ledger: 17 英寸 x 11 英寸A0:33.1 英寸 x 46.8 英寸A1:23.4 英寸 x 33.1 英寸A2:16.5 英寸 x 23.4 英寸A3:11.7 英寸 x 16.5 英寸A4:8.27 英寸 x 11.7 英寸A5:5.83 英寸 x 8.27 英寸A6:4.13 英寸 x 5.83 英寸
笔记
headerTemplate和footerTemplate标记有以下限制:
- 不评估模板内的脚本标签。
- 页面样式在模板中不可见。
协程plainText( ) → str[来源]
[已弃用] 以纯文本形式获取页面内容。
协程queryObjects(prototypeHandle:pyppeteer.execution_context.JSHandle ) →pyppeteer.execution_context.JSHandle[来源]
遍历js堆,找到所有带句柄的对象。
| 参数: | prototypeHandle ( JSHandle ) – 原型对象的 JSHandle。 |
|---|
协程querySelector(选择器:str ) →可选[pyppeteer.element_handle.ElementHandle][来源]
获取匹配的元素selector。
| 参数: | 选择器( str ) – 搜索元素的选择器。 |
|---|---|
| 返回可选[元素句柄]: | |
selector如果找到 与 匹配的元素 ,则返回其ElementHandle. 如果没有找到,返回None。 | |
协程querySelectorAll(选择器:str ) →列表[pyppeteer.element_handle.ElementHandle][来源]
获取所有匹配的元素selector作为列表。
| 参数: | 选择器( str ) – 搜索元素的选择器。 |
|---|---|
| 返回列表[元素句柄]: | |
ElementHandle其中匹配的 列表 selector。如果没有元素与 匹配selector,则返回空列表。 | |
协程querySelectorAllEval(选择器:str,pageFunction:str,*args ) →任意[来源]
对匹配的所有元素执行函数selector。
| 参数: |
|
|---|
协程querySelectorEval(选择器:str,pageFunction:str,*args ) →任意[来源]
使用匹配的元素执行函数selector。
| 参数: |
|
|---|
如果没有元素与selector.
协程reload(选项:dict = None,**kwargs ) →可选[pyppeteer.network_manager.Response][来源]
重新加载此页面。
可用选项与方法相同goto()。
协程screenshot(选项:dict = None,**kwargs ) → Union[bytes, str][来源]
截屏。
以下选项可用:
path(str): 保存图像的文件路径。屏幕截图类型将从文件扩展名推断出来。type(str): 指定截图类型,可以是jpeg或png. 默认为png.quality(int): 图像的质量,介于 0-100 之间。不适用于png图像。fullPage(bool): 当为 true 时,截取整个可滚动页面的屏幕截图。默认为False.clip(dict):指定页面裁剪区域的对象。此选项应包含以下字段:x(int): 剪辑区域左上角的 x 坐标。y(int): 剪辑区域左上角的 y 坐标。width(int): 裁剪区域的宽度。height(int): 裁剪区域的高度。
omitBackground(bool): 隐藏默认的白色背景并允许捕获透明的屏幕截图。encoding(str): 图像的编码,可以是'base64'或'binary'. 默认为'binary'.
协程select(选择器:str,*值) → List[str][来源]
选择选项并返回选定的值。
如果没有元素与 匹配selector,则引发ElementHandleError。
协程setBypassCSP(已启用:bool ) →无[来源]
切换绕过页面的内容安全策略。
笔记
CSP 绕过发生在 CSP 初始化而不是评估时。通常这意味着page.setBypassCSP 应该在导航到域之前调用它。
协程setCacheEnabled(已启用:bool = True ) →无[来源]
为每个请求启用/禁用缓存。
默认情况下,缓存是启用的。
协程setContent( html: str ) → 无[来源]
将内容设置到该页面。
| 参数: | html ( str ) – 分配给页面的 HTML 标记。 |
|---|
协程setCookie( *cookies ) → 无[来源]
设置饼干。
cookies应该是包含这些字段的字典:
name(str):必需value(str):必需url(str)domain(str)path(str)expires(number): 以秒为单位的 Unix 时间httpOnly(布尔)secure(布尔)sameSite(str):'Strict'或'Lax'
setDefaultNavigationTimeout(超时:整数) →无[来源]
更改默认的最大导航超时。
此方法更改以下方法的默认超时 30 秒:
- goto()
- goBack()
- goForward()
- reload()
- waitForNavigation()
| 参数: | timeout ( int ) – 最大导航时间(以毫秒为单位)。传递0 以禁用超时。 |
|---|
协程setExtraHTTPHeaders(标头:Dict[str, str] ) →无[来源]
设置额外的 HTTP 标头。
页面发起的每个请求都会发送额外的 HTTP 标头。
笔记
page.setExtraHTTPHeaders不保证传出请求中标头的顺序。
| 参数: | headers ( Dict ) – 一个字典,其中包含要随每个请求一起发送的附加 http 标头。所有标头值都必须是字符串。 |
|---|
协程setJavaScriptEnabled(已启用:bool ) →无[来源]
设置 JavaScript 启用/禁用。
协程setOfflineMode(已启用:bool ) →无[来源]
设置离线模式启用/禁用。
协程setRequestInterception(值:bool ) →无[来源]
启用/禁用请求拦截。
激活请求拦截会启用 Request类的 abort()、 continue_()和 response()方法。这提供了修改页面发出的网络请求的能力。
协程setUserAgent( userAgent: str ) → 无[来源]
设置要在此页面中使用的用户代理。
| 参数: | userAgent ( str ) – 在此页面中使用的特定用户代理 |
|---|
协程setViewport(视口:字典) →无[来源]
设置视口。
可用的选项是:
width(int): 以像素为单位的页面宽度。height(int): 以像素为单位的页面高度。deviceScaleFactor(浮动):默认为 1.0。isMobile(bool): 默认为False.hasTouch(bool): 默认为False.isLandscape(bool): 默认为False.
协程tap(选择器:str ) →无[来源]
点击与 匹配的元素selector。
| 参数: | 选择器( str ) – 用于搜索要触摸的元素的选择器。 |
|---|
target
返回创建此页面的目标。
协程title( ) → str[来源]
获取页面的标题。
touchscreen
获取Touchscreen对象。
tracing
获取跟踪对象。
协程type(选择器:str,文本:str,选项:dict = None,**kwargs ) →无[来源]
text在匹配的元素上键入selector。
如果没有元素与 匹配selector,则引发PageError。
详情见pyppeteer.input.Keyboard.type()。
url
获取此页面的 URL。
viewport
将视口作为字典获取。
返回字典的字段与 相同setViewport()。
waitFor( selectorOrFunctionOrTimeout: Union[str, int, float], options: dict = None, *args, **kwargs ) → Awaitable[T_co][来源]
等待页面上匹配的函数、超时或元素。
此方法的行为与第一个参数不同:
- 如果
selectorOrFunctionOrTimeout是数字(int 或 float),则将其视为以毫秒为单位的超时,并返回将在超时后完成的 future。 - 如果
selectorOrFunctionOrTimeout是一串 JavaScript 函数,此方法是waitForFunction(). - 如果是选择器字符串或 xpath 字符串,则此方法是or
selectorOrFunctionOrTimeout的快捷方式。如果字符串以 开头,则该字符串被视为 xpath。waitForSelector()waitForXPath()//
Pyppeteer 尝试自动检测函数或选择器,但有时会漏检。如果没有按预期工作,请 直接使用waitForFunction()或。waitForSelector()
| 参数: |
|
|---|---|
| 退货: | 返回解析为成功值的 JSHandle 的可等待对象。 |
可用选项:见waitForFunction()或 waitForSelector()
waitForFunction( pageFunction: str , options: dict = None , *args , **kwargs ) → Awaitable[T_co][来源]
等到函数完成并返回真值。
| 参数: | args ( Any ) – 要传递给的参数pageFunction。 |
|---|---|
| 退货: | pageFunction返回等待对象,该对象在返回真值时解析 。它解析为 JSHandle真值。 |
此方法接受以下选项:
polling(str|number): 执行的时间间隔pageFunction,默认为raf. 如果polling是一个数字,则将其视为函数执行的时间间隔(以毫秒为单位)。如果polling是字符串,则它可以是以下值之一:rafpageFunction:在回调中 不断执行requestAnimationFrame。这是最严格的轮询模式,适合观察样式变化。mutationpageFunction:在每个 DOM 突变上执行。
timeout(int|float):等待的最长时间,以毫秒为单位。默认为 30000(30 秒)。传递0以禁用超时。
协程waitForNavigation(选项:dict = None,**kwargs ) →可选[pyppeteer.network_manager.Response][来源]
等导航。
可用选项与方法相同goto()。
Response当页面导航到新 URL 或重新加载时返回。当您运行将间接导致页面导航的代码时,它很有用。如果由于 使用History API而导航到不同的锚点或导航 ,则导航将返回None。
考虑这个例子:
navigationPromise = async.ensure_future(page.waitForNavigation())
await page.click('a.my-link') # indirectly cause a navigation
await navigationPromise # wait until navigation finishes
或者,
await asyncio.wait([page.click('a.my-link'),page.waitForNavigation(),
])
笔记
使用 History API 更改 URL 被视为导航。
协程waitForRequest(urlOrPredicate: Union[str, Callable[[pyppeteer.network_manager.Request], bool]], options: Dict[KT, VT] = None, **kwargs ) → pyppeteer.network_manager.Request[来源]
等待请求。
| 参数: | urlOrPredicate – 要等待的 URL 或函数。 |
|---|
此方法接受以下选项:
timeout(int|float):以毫秒为单位的最长等待时间,默认为 30 秒,传递0以禁用超时。
例子:
firstRequest = await page.waitForRequest('http://example.com/resource')
finalRequest = await page.waitForRequest(lambda req: req.url == 'http://example.com' and req.method == 'GET')
return firstRequest.url
协程waitForResponse(urlOrPredicate: Union[str, Callable[[pyppeteer.network_manager.Response], bool]], options: Dict[KT, VT] = None, **kwargs ) → pyppeteer.network_manager.Response[来源]
等待回应。
| 参数: | urlOrPredicate – 要等待的 URL 或函数。 |
|---|
此方法接受以下选项:
timeout(int|float):以毫秒为单位的最长等待时间,默认为 30 秒,传递0以禁用超时。
例子:
firstResponse = await page.waitForResponse('http://example.com/resource')
finalResponse = await page.waitForResponse(lambda res: res.url == 'http://example.com' and res.status == 200)
return finalResponse.ok
waitForSelector(选择器:str,选项:dict = None,**kwargs ) → Awaitable[T_co][来源]
等到匹配的元素selector出现在页面上。
等待selector出现在页面中。如果调用方法的时候selector已经存在,方法会立即返回。timeout如果在等待几毫秒后选择器没有出现 ,该函数将引发错误。
| 参数: | 选择器( str ) – 要等待的元素的选择器。 |
|---|---|
| 退货: | 返回等待的对象,该对象在将选择器字符串指定的元素添加到DOM中时可以解决。 |
此方法接受以下选项:
visible(bool): 等待元素出现在 DOM 中并且可见;即没有或 CSS 属性。默认为.display: nonevisibility: hiddenFalsehidden(bool): 等待元素在 DOM 中找不到或被隐藏,即具有或CSS 属性。默认为.display: nonevisibility: hiddenFalsetimeout(int|float):等待的最长时间,以毫秒为单位。默认为 30000(30 秒)。传递0以禁用超时。
waitForXPath( xpath: str , options: dict = None , **kwargs ) → Awaitable[T_co][来源]
等到匹配的元素xpath出现在页面上。
等待xpath出现在页面中。如果调用方法的时刻已经xpath存在,方法将立即返回。timeout如果在等待几毫秒后 xpath 没有出现,该函数将引发异常。
| 参数: | xpath ( str ) – 要等待的元素的 [xpath]。 |
|---|---|
| 退货: | 返回可等待对象,当 xpath 字符串指定的元素添加到 DOM 时解析。 |
可用的选项是:
visible(bool): 等待元素出现在 DOM 中并且可见,即不具有或 CSS 属性。默认为.display: nonevisibility: hiddenFalsehidden(bool): 等待元素在 DOM 中找不到或被隐藏,即具有或CSS 属性。默认为.display: nonevisibility: hiddenFalsetimeout(int|float):等待的最长时间,以毫秒为单位。默认为 30000(30 秒)。传递0以禁用超时。
workers
获取此页面的所有工作人员。
协程xpath(表达式:str ) →列表[pyppeteer.element_handle.ElementHandle][来源]
计算 XPath 表达式。
如果此页面中没有此类元素,则返回一个空列表。
| 参数: | expression ( str ) – 要评估的 XPath 字符串。 |
|---|
7.Worker 类
类pyppeteer.worker.Worker(客户端:CDPSession,url:str,consoleAPICalled:Callable[[str,List[pyppeteer.execution_context.JSHandle]],None],exceptionThrown:Callable[[Dict[KT,VT]],None] )[来源]
基类:pyee.EventEmitter
Worker 类代表一个 WebWorker。
事件workercreated和workerdestroyed在页面对象上发出以指示工作人员生命周期。
page.on('workercreated', lambda worker: print('Worker created:', worker.url))
协程evaluate( pageFunction: str , *args ) → 任意[来源]
pageFunction用评价args。
的快捷方式。(await worker.executionContext).evaluate(pageFunction, *args)
协程evaluateHandle(pageFunction: str , *args ) → pyppeteer.execution_context.JSHandle[来源]
评估pageFunction并args返回JSHandle。
的快捷方式。(await worker.executionContext).evaluateHandle(pageFunction, *args)
协程executionContext( ) → pyppeteer.execution_context.ExecutionContext[来源]
返回执行上下文。
url
返回网址。
8.键盘类
类pyppeteer.input.Keyboard(客户端:pyppeteer.connection.CDPSession )[来源]
基类:object
键盘类提供用于管理虚拟键盘的 API。
高级 api 是type(),它采用原始字符并在您的页面上生成适当的 keydown、keypress/input 和 keyup 事件。
为了更好地控制,您可以使用down()、up()和 sendCharacter()来手动触发事件,就好像它们是从真实键盘生成的一样。
按住Shift以选择和删除某些文本的示例:
await page.keyboard.type('Hello, World!')
await page.keyboard.press('ArrowLeft')await page.keyboard.down('Shift')
for i in ' World':await page.keyboard.press('ArrowLeft')
await page.keyboard.up('Shift')await page.keyboard.press('Backspace')
# Result text will end up saying 'Hello!'.
按下的例子A:
await page.keyboard.down('Shift')
await page.keyboard.press('KeyA')
await page.keyboard.up('Shift')
协程down(键:str,选项:dict = None,**kwargs ) →无[来源]
使用 发送keydown事件key。
如果key是单个字符且没有其他修饰键Shift 被按住,也会产生keypress/事件。可以指定input该选项以强制 生成事件。textinput
如果key是修改键,如Shift、Meta或Alt,则随后的按键将在激活该修改键的情况下发送。要释放修改键,请使用up()方法。
| 参数: |
|
|---|
笔记
修改键确实影响down()。按住shift 将以大写形式键入文本。
协程press(键:str,选项:Dict[KT,VT] = None,**kwargs ) →无[来源]
按key。
如果key是单个字符并且没有其他修饰键 Shift被按住,也会生成keypress/事件。input可以指定该text选项以强制生成输入事件。
| 参数: | key ( str ) – 要按下的键的名称,例如ArrowLeft. |
|---|
此方法接受以下选项:
text(str):如果指定,则使用此文本生成输入事件。delaykeydown(int|float):和 之间等待的时间keyup。默认为 0。
笔记
修改键 DO 效果press()。按住Shift将以大写形式键入文本。
协程sendCharacter( char: str ) → 无[来源]
将字符发送到页面中。
此方法调度一个keypressandinput事件。这不会发送keydownorkeyup事件。
笔记
修改键不影响sendCharacter()。按住 shift不会以大写形式键入文本。
协程type(文本:str,选项:Dict[KT,VT] = None,**kwargs ) →无[来源]
在焦点元素中键入字符。
此方法 为 中的每个字符发送keydown、keypress/input和事件。keyuptext
要按特殊键,如Control或ArrowDown,请使用 press()方法。
| 参数: |
|
|---|
笔记
修改键不影响type()。按住shift 不会以大写形式键入文本。
协程up(键:str ) →无[来源]
调度keyup的事件key。
| 参数: | key ( str ) – 要释放的密钥的名称,例如ArrowLeft. |
|---|
9.鼠标类
类pyppeteer.input.Mouse(客户端:pyppeteer.connection.CDPSession,键盘:pyppeteer.input.Keyboard )[来源]
基地:object
鼠标类。
协程click( x: float , y: float , options: dict = None , **kwargs ) → None[来源]
x单击 ( , )处的按钮y。
move()、down()和 的快捷方式up()。
此方法接受以下选项:
button(str):left,right, 或middle, 默认为left.clickCount(整数):默认为 1。delay(int|float):等待时间,以毫秒为mousedown单位mouseup。默认为 0。
协程down(选项:dict = None,**kwargs ) →无[来源]
按下按钮(调度mousedown事件)。
此方法接受以下选项:
button(str):left,right, 或middle, 默认为left.clickCount(整数):默认为 1。
协程move( x: float , y: float , options: dict = None , **kwargs ) → None[来源]
移动鼠标光标(调度mousemove事件)。
选项可以接受steps(int) 字段。如果steps指定了此选项,则发送中间mousemove事件。默认为 1。
协程up(选项:dict = None,**kwargs ) →无[来源]
释放按下的按钮(调度mouseup事件)。
此方法接受以下选项:
button(str):left,right, 或middle, 默认为left.clickCount(整数):默认为 1。
10.Tracing类
类pyppeteer.tracing.Tracing(客户端:pyppeteer.connection.CDPSession )[来源]
基类:object
Tracing类。
您可以使用start()和创建可以在 Chrome DevTools 或时间线查看器stop()中打开的跟踪文件 。
await page.tracing.start({'path': 'trace.json'})
await page.goto('https://www.google.com')
await page.tracing.stop()
协程start(选项:dict = None,**kwargs ) →无[来源]
开始追踪。
每个浏览器一次只能激活一个跟踪。
此方法接受以下选项:
path(str):写入跟踪文件的路径。screenshots(bool): 在跟踪中捕获屏幕截图。categories(List[str]):指定要使用的自定义类别而不是默认类别。
协程stop( ) → str[来源]
停止追踪。
| 退货: | 跟踪数据作为字符串。 |
|---|
11.对话框类
类pyppeteer.dialog.Dialog(客户端:pyppeteer.connection.CDPSession,类型:str,消息:str,默认值:str = '' )[来源]
基地:object
对话框类。
对话框对象通过事件按页面分派dialog。
使用类的示例Dialog:
browser = await launch()
page = await browser.newPage()async def close_dialog(dialog):print(dialog.message)await dialog.dismiss()await browser.close()page.on('dialog',lambda dialog: asyncio.ensure_future(close_dialog(dialog))
)
await page.evaluate('() => alert("1")')
协程accept(promptText: str = '' ) →无[来源]
接受对话框。
promptText(str): 在提示中输入的文本。如果对话框的类型不是提示,则不会产生任何影响。
defaultValue
如果对话框是提示的,则获取默认提示值。
如果对话框没有提示,则返回空字符串 (‘’)。
协程dismiss( ) → 无[来源]
关闭对话框。
message
获取对话消息。
type
获取对话框类型。
alert、beforeunload、confirm或prompt。
12.控制台消息类
类pyppeteer.page.ConsoleMessage(类型:str,文本:str,args:List[pyppeteer.execution_context.JSHandle] = None )[来源]
基类:object
控制台消息类。
ConsoleMessage 对象通过事件按页面分派console。
args
返回此消息的 args (JSHandle) 列表。
text
返回此消息的文本表示。
type
此消息的返回类型。
13.Frame 类
类pyppeteer.frame_manager.Frame(客户端:pyppeteer.connection.CDPSession,parentFrame:可选[Frame],frameId:str )[来源]
基类:object
框架类。
框架对象可以通过pyppeteer.page.Page.mainFrame.
协程J(选择器:str ) →可选[pyppeteer.element_handle.ElementHandle]
别名为querySelector()
协程JJ(选择器:str ) →列表[pyppeteer.element_handle.ElementHandle]
别名为querySelectorAll()
协程JJeval(选择器:str,pageFunction:str,*args ) →可选[Dict[KT,VT]]
别名为querySelectorAllEval()
协程Jeval(选择器:str,pageFunction:str,*args ) →任何
别名为querySelectorEval()
协程Jx(表达式:str ) →列表[pyppeteer.element_handle.ElementHandle]
别名为xpath()
协程addScriptTag(选项:Dict[KT, VT] ) → pyppeteer.element_handle.ElementHandle[来源]
将脚本标签添加到此框架。
详情见pyppeteer.page.Page.addScriptTag()。
协程addStyleTag(选项:Dict[KT, VT] ) → pyppeteer.element_handle.ElementHandle[来源]
将样式标签添加到此框架。
详情见pyppeteer.page.Page.addStyleTag()。
childFrames
获取子帧。
协程click(选择器:str,选项:dict = None,**kwargs ) →无[来源]
单击匹配的元素selector。
详情见pyppeteer.page.Page.click()。
协程content( ) → str[来源]
获取页面的全部 HTML 内容。
协程evaluate(pageFunction: str , *args , force_expr: bool = False ) → 任意[来源]
在此框架上评估 pageFunction。
详情见pyppeteer.page.Page.evaluate()。
协程evaluateHandle(pageFunction: str , *args ) → pyppeteer.execution_context.JSHandle[来源]
在此框架上执行功能。
详情见pyppeteer.page.Page.evaluateHandle()。
协程executionContext() →可选[pyppeteer.execution_context.ExecutionContext][来源]
返回此帧的执行上下文。
返回ExecutionContext 关联到此帧。
协程focus(选择器:str ) →无[来源]
匹配的焦点元素selector。
详情见pyppeteer.page.Page.focus()。
协程hover(选择器:str ) →无[来源]
鼠标悬停在匹配的元素上selector。
详情见pyppeteer.page.Page.hover()。
协程injectFile(文件路径:海峡) →海峡[来源]
[已弃用] 将文件注入框架。
isDetached( ) → 布尔值[来源]
True如果此框架已分离,则返回。
否则返回False。
name
获取框架名称。
parentFrame
获取父框架。
如果此框架是主框架或分离框架,则返回None。
协程querySelector(选择器:str ) →可选[pyppeteer.element_handle.ElementHandle][来源]
获取匹配selector字符串的元素。
详情见pyppeteer.page.Page.querySelector()。
协程querySelectorAll(选择器:str ) →列表[pyppeteer.element_handle.ElementHandle][来源]
获取匹配的所有元素selector。
详情见pyppeteer.page.Page.querySelectorAll()。
coroutine querySelectorAllEval( selector: str , pageFunction: str , *args ) → Optional[Dict[KT, VT]][来源]
对匹配选择器的所有元素执行函数。
详情见pyppeteer.page.Page.querySelectorAllEval()。
协程querySelectorEval(选择器:str,pageFunction:str,*args ) →任意[来源]
在匹配选择器的元素上执行函数。
详情见pyppeteer.page.Page.querySelectorEval()。
协程select(选择器:str,*值) → List[str][来源]
选择选项并返回选定的值。
详情见pyppeteer.page.Page.select()。
协程setContent( html: str ) → 无[来源]
将内容设置到该页面。
协程tap(选择器:str ) →无[来源]
点击与 匹配的元素selector。
详情见pyppeteer.page.Page.tap()。
协程title( ) → str[来源]
获取框架的标题。
协程type(选择器:str,文本:str,选项:dict = None,**kwargs ) →无[来源]
text在匹配的元素上键入selector。
详情见pyppeteer.page.Page.type()。
url
获取框架的 url。
waitFor( selectorOrFunctionOrTimeout: Union[str, int, float], options: dict = None, *args, **kwargs ) → Union[Awaitable[T_co], pyppeteer.frame_manager.WaitTask][来源]
等到selectorOrFunctionOrTimeout。
详情见pyppeteer.page.Page.waitFor()。
waitForFunction( pageFunction: str , options: dict = None , *args , **kwargs ) → pyppeteer.frame_manager.WaitTask[来源]
等到函数完成。
详情见pyppeteer.page.Page.waitForFunction()。
waitForSelector(选择器:str,选项:dict = None,**kwargs ) → pyppeteer.frame_manager.WaitTask[来源]
等到匹配的元素selector出现在页面上。
详情见pyppeteer.page.Page.waitForSelector()。
waitForXPath( xpath: str , options: dict = None , **kwargs ) → pyppeteer.frame_manager.WaitTask[来源]
等到匹配的元素xpath出现在页面上。
详情见pyppeteer.page.Page.waitForXPath()。
协程xpath(表达式:str ) →列表[pyppeteer.element_handle.ElementHandle][来源]
计算 XPath 表达式。
如果此框架中没有此类元素,则返回一个空列表。
| 参数: | expression ( str ) – 要评估的 XPath 字符串。 |
|---|
14.执行上下文类
类pyppeteer.execution_context.ExecutionContext(客户端:pyppeteer.connection.CDPSession,contextPayload:Dict [KT,VT],objectHandleFactory:Any,frame:Frame = None )[来源]
基地:object
执行上下文类。
协程evaluate(pageFunction: str , *args , force_expr: bool = False ) → 任意[来源]
pageFunction在此上下文中执行。
详情见pyppeteer.page.Page.evaluate()。
协程evaluateHandle(pageFunction: str , *args , force_expr: bool = False ) → pyppeteer.execution_context.JSHandle[来源]
pageFunction在此上下文中执行。
详情见pyppeteer.page.Page.evaluateHandle()。
frame
返回与此执行上下文关联的帧。
协程queryObjects(prototypeHandle:pyppeteer.execution_context.JSHandle ) →pyppeteer.execution_context.JSHandle[来源]
发送查询。
详情见pyppeteer.page.Page.queryObjects()。
15.JSHandle 类
类pyppeteer.execution_context.JSHandle(上下文:pyppeteer.execution_context.ExecutionContext,客户端:pyppeteer.connection.CDPSession,remoteObject:Dict [KT,VT] )[来源]
基地:object
JSHandle类。
JSHandle 表示页内 JavaScript 对象。可以使用该evaluateHandle()方法创建 JSHandle。
asElement( ) → 可选[元素句柄][来源]
返回 null 或对象句柄本身。
协程dispose( ) → 无[来源]
停止引用句柄。
executionContext
获取此句柄的执行上下文。
协程getProperties( ) → Dict[str, pyppeteer.execution_context.JSHandle][来源]
获取此句柄的所有属性。
协程getProperty(propertyName:str ) →pyppeteer.execution_context.JSHandle[来源]
获取 的属性值propertyName。
协程jsonValue( ) → Dict[KT, VT][来源]
获取此对象的 Jsonized 值。
toString( ) → 海峡[来源]
获取字符串表示。
16.元素句柄类
类pyppeteer.element_handle.ElementHandle(上下文:pyppeteer.execution_context.ExecutionContext,客户端:pyppeteer.connection.CDPSession,remoteObject:dict,页面:Any,frameManager:FrameManager )[来源]
基类:pyppeteer.execution_context.JSHandle
元素句柄类。
此类表示页内 DOM 元素。ElementHandle 可以通过该方法创建pyppeteer.page.Page.querySelector()。
ElementHandle 防止 DOM 元素被垃圾回收,除非句柄被释放。ElementHandles 在其原始框架被导航时自动释放。
ElementHandle isinstance 可以用作 和 pyppeteer.page.Page.querySelectorEval()方法 中的参数pyppeteer.page.Page.evaluate()。
协程J(选择器:str ) →可选[pyppeteer.element_handle.ElementHandle]
别名为querySelector()
协程JJ(选择器:str ) →列表[pyppeteer.element_handle.ElementHandle]
别名为querySelectorAll()
协程JJeval(选择器:str,pageFunction:str,*args ) →任何
别名为querySelectorAllEval()
协程Jeval(选择器:str,pageFunction:str,*args ) →任何
别名为querySelectorEval()
协程Jx(表达式:str ) →列表[pyppeteer.element_handle.ElementHandle]
别名为xpath()
asElement( ) → pyppeteer.element_handle.ElementHandle[来源]
返回此 ElementHandle。
协程boundingBox( ) → Optional[Dict[str, float]][来源]
返回此元素的边界框。
如果该元素不可见,则返回None。
该方法返回边界框字典,其中包含:
x(int):元素的 X 坐标(以像素为单位)。y(int):元素的 Y 坐标(以像素为单位)。width(int): 元素的宽度,以像素为单位。height(int): 元素的高度,以像素为单位。
协程boxModel( ) → 可选[Dict[KT, VT]][来源]
返回元素框。
None如果元素不可见则返回。方框表示为点列表;每个点都是一本字典。框点按顺时针排序。{x, y}
返回值是一个包含以下字段的字典:
content(List[Dict]): 内容框。padding(List[Dict]): 填充框。border(List[Dict]): 边框框。margin(List[Dict]): 边距框。width(int): 元素的宽度。height(int): 元素的高度。
协程click(选项:dict = None,**kwargs ) →无[来源]
单击此元素的中心。
如果需要,此方法将元素滚动到视图中。如果元素与 DOM 分离,则该方法会引发ElementHandleError.
options可以包含以下字段:
button(str):left,right, ofmiddle, 默认为left.clickCount(整数):默认为 1。delay(int|float):等待时间,以毫秒为mousedown单位mouseup。默认为 0。
协程contentFrame( ) → 可选[pyppeteer.frame_manager.Frame][来源]
返回元素句柄的内容框架。
None如果此句柄未引用 iframe,则返回。
协程focus( ) → 无[来源]
专注于这个元素。
协程hover( ) → 无[来源]
将鼠标移到该元素的中心。
如果需要,此方法将元素滚动到视图中。如果此元素与 DOM 树分离,则该方法会引发一个ElementHandleError.
协程isIntersectingViewport( ) → 布尔[来源]
True如果元素在视口中可见,则返回。
协程press(键:str,选项:Dict[KT,VT] = None,**kwargs ) →无[来源]
压key在元件上。
此方法聚焦元素,然后使用 pyppeteer.input.keyboard.down()and pyppeteer.input.keyboard.up()。
| 参数: | key ( str ) – 要按下的键的名称,例如ArrowLeft. |
|---|
此方法接受以下选项:
text(str):如果指定,则使用此文本生成输入事件。delaykeydown(int|float):和 之间等待的时间keyup。默认为 0。
协程querySelector(选择器:str ) →可选[pyppeteer.element_handle.ElementHandle][来源]
selector返回在此元素下匹配的第一个元素。
如果没有元素与 匹配selector,则返回None。
协程querySelectorAll(选择器:str ) →列表[pyppeteer.element_handle.ElementHandle][来源]
selector返回在此元素下匹配的所有元素。
如果没有元素与 匹配selector,则返回空列表 ( [])。
协程querySelectorAllEval(选择器:str,pageFunction:str,*args ) →任意[来源]
Page.querySelectorAllEval在元素内运行。
Array.from(document.querySelectorAll)此方法在元素内运行,并将其作为第一个参数传递给pageFunction。如果没有元素匹配selector,则该方法引发 ElementHandleError。
如果pageFunction返回承诺,则等待承诺解决并返回其值。
例子:
<div class="feed"><div class="tweet">Hello!</div><div class="tweet">Hi!</div> </div>
feedHandle = await page.J('.feed')
assert (await feedHandle.JJeval('.tweet', '(nodes => nodes.map(n => n.innerText))')) == ['Hello!', 'Hi!']
协程querySelectorEval(选择器:str,pageFunction:str,*args ) →任意[来源]
Page.querySelectorEval在元素内运行。
document.querySelector此方法在元素内运行,并将其作为第一个参数传递给pageFunction。如果没有元素匹配selector,则该方法引发 ElementHandleError。
如果pageFunction返回承诺,则等待承诺解决并返回其值。
ElementHandle.Jeval是这种方法的捷径。
例子:
tweetHandle = await page.querySelector('.tweet')
assert (await tweetHandle.querySelectorEval('.like', 'node => node.innerText')) == 100
assert (await tweetHandle.Jeval('.retweets', 'node => node.innerText')) == 10
协程screenshot(选项:Dict[KT,VT] = None,**kwargs ) → 字节[来源]
截取此元素的屏幕截图。
如果元素与 DOM 分离,此方法会引发一个 ElementHandleError.
可用选项与pyppeteer.page.Page.screenshot().
协程tap( ) → 无[来源]
点击此元素的中心。
如果需要,此方法将元素滚动到视图中。如果元素与 DOM 分离,则该方法会引发ElementHandleError.
协程type(文本:str,选项:Dict[KT,VT] = None,**kwargs ) →无[来源]
聚焦元素,然后键入文本。
详情见pyppeteer.input.Keyboard.type()方法。
协程uploadFile( *filePaths ) → 字典[来源]
上传文件。
协程xpath(表达式:str ) →列表[pyppeteer.element_handle.ElementHandle][来源]
评估相对于此 elementHandle 的 XPath 表达式。
如果没有这样的元素,则返回一个空列表。
| 参数: | expression ( str ) – 要评估的 XPath 字符串。 |
|---|
17.请求类
类pyppeteer.network_manager.Request(客户端:pyppeteer.connection.CDPSession,requestId:可选[str],interceptionId:str,isNavigationRequest:bool,allowInterception:bool,url:str,resourceType:str,payload:dict,frame:可选[pyppeteer.frame_manager.Frame ], redirectChain: 列表[请求] )[来源]
基类:object
请求类。
每当页面发送请求(例如网络资源请求)时,pyppeteer 的页面都会发出以下事件:
'request': 当页面发出请求时发出。'response':当/如果收到请求的响应时发出。'requestfinished':在下载响应主体并且请求完成时发出。
如果请求在某个时候失败,则发出事件而不是'requestfinished'事件(也可能不是'response'事件) 。'requestfailed'
如果请求得到'redirect'响应,则请求成功完成'requestfinished'事件,并向重定向 url 发出新请求。
协程abort(errorCode: str = 'failed' ) →无[来源]
中止请求。
要使用它,请求拦截应该由 启用 pyppeteer.page.Page.setRequestInterception()。如果未启用请求拦截,则引发NetworkError.
errorCode是一个可选的错误代码字符串。默认为failed, 可以是以下之一:
aborted:操作已中止(由于用户操作)。accessdenied: 访问除网络以外的资源的权限被拒绝。addressunreachable: IP 地址无法访问。这通常意味着没有到指定主机或网络的路由。blockedbyclient: 客户端选择阻止请求。blockedbyresponse:请求失败,因为请求与未满足的要求一起交付(例如,“X-Frame-Options”和“Content-Security-Policy”祖先检查)。connectionaborted:由于未收到已发送数据的 ACK,导致连接超时。connectionclosed:连接已关闭(对应于 TCP FIN)。connectionfailed: 连接尝试失败。connectionrefused: 连接尝试被拒绝。connectionreset:连接已重置(对应于 TCP RST)。internetdisconnected: 互联网连接已丢失。namenotresolved: 无法解析主机名。timedout: 操作超时。failed: 发生一般故障。
协程continue_(覆盖:Dict[KT,VT] = None ) →无[来源]
使用可选的请求覆盖继续请求。
要使用此方法,应启用请求拦截 pyppeteer.page.Page.setRequestInterception()。如果未启用请求拦截,则引发NetworkError.
overrides可以有以下字段:
url(str): 如果设置,请求 url 将被更改。method(str):如果设置,则更改请求方法(例如GET)。postData(str):如果设置,则更改发布数据或请求。headers(dict):如果设置,则更改请求 HTTP 标头。
failure( ) → 可选[Dict[KT, VT]][来源]
返回错误文本。
None除非此请求失败,否则 返回,如requestfailed事件所报告的那样。
当请求失败时,此方法返回字典,其中有一个 errorText字段,其中包含人类可读的错误消息,例如 'net::ERR_RAILED'。
frame
返回匹配的frame对象。
None如果导航到错误页面则返回。
headers
返回此请求的 HTTP 标头字典。
所有标头名称都是小写的。
isNavigationRequest( ) → 布尔值[来源]
此请求是否驱动框架的导航。
method
返回此请求的方法(GET、POST 等)。
postData
返回此请求的帖子正文。
redirectChain
返回为获取资源而发起的请求链。
- 如果没有重定向且请求成功,链将为空。
- 如果服务器至少响应一个重定向,则该链将包含所有被重定向的请求。
redirectChain在同一链的所有请求之间共享。
resourceType
呈现引擎感知的此请求的资源类型。
ResourceType 将是以下之一:document, stylesheet, image, media, font, script, texttrack, xhr, fetch, eventsource, websocket, manifest, other。
协程respond(响应:Dict[KT, VT] ) →无[来源]
用给定的响应满足请求。
要使用它,请求拦截应该由 启用 pyppeteer.page.Page.setRequestInterception()。未启用请求 拦截,提高NetworkError。
response是一个字典,它可以有以下字段:
status(int): 响应状态码,默认为200。headers(dict): 可选的响应头。contentType(str): 如果设置,等于设置Content-Type响应头。body(str|bytes):可选的响应主体。
response
返回匹配Response对象,或None.
如果未收到响应,则返回None。
url
此请求的 URL。
18.响应类
类pyppeteer.network_manager.Response(客户端:pyppeteer.connection.CDPSession,请求:pyppeteer.network_manager.Request,状态:int,标头:Dict [str,str],fromDiskCache:bool,fromServiceWorker:bool,securityDetails:Dict [KT,VT] = None )[来源]
基地:object
响应类代表接收到的响应Page。
buffer( ) → 可等待[字节][来源]
返回 awaitable,它解析为带有响应正文的字节。
fromCache
True如果响应是从缓存中提供的,则返回。
这cache是浏览器的磁盘缓存或内存缓存。
fromServiceWorker
True如果响应是由 service worker 提供的,则返回。
headers
返回此响应的 HTTP 标头字典。
所有标头名称都是小写的。
协程json( ) → 字典[来源]
获取响应主体的 JSON 表示形式。
ok
无论此请求是否成功(200-299),都返回布尔值。
request
获取匹配Request对象。
securityDetails
返回与此响应关联的安全详细信息。
如果响应是通过安全连接或None其他方式接收到的,则为安全详细信息。
status
响应的状态代码。
协程text( ) → str[来源]
获取响应主体的文本表示。
url
响应的 URL。
19.Target 类
类pyppeteer.browser.Target(targetInfo: Dict[KT, VT], browserContext: BrowserContext, sessionFactory: Callable[[], Coroutine[Any, Any, pyppeteer.connection.CDPSession]], ignoreHTTPSErrors: bool, setDefaultViewport: bool, screenshotTaskQueue: List[T] , 循环: asyncio.events.AbstractEventLoop )[来源]
基类:object
浏览器的Target 类。
browser
获取目标所属的浏览器。
browserContext
返回目标所属的浏览器上下文。
协程createCDPSession( ) → pyppeteer.connection.CDPSession[来源]
创建附加到目标的 Chrome Devtools 协议会话。
opener
获取打开此目标的目标。
顶级目标返回None.
协程page( ) → 可选[pyppeteer.page.Page][来源]
获取此目标的页面。
如果目标不是“page”或“background_page”类型,则返回 None.
type
获取此目标的类型。
类型可以是'page'、'background_page'、'service_worker'、 'browser'或'other'。
url
获取此目标的 url。
20.CDPSession类
类pyppeteer.connection.CDPSession(连接:Union[pyppeteer.connection.Connection,CDPSession],targetType:str,sessionId:str,循环:asyncio.events.AbstractEventLoop )[来源]
基类:pyee.EventEmitter
Chrome Devtools 协议会话。
这些CDPSession实例用于讨论原始的 Chrome Devtools 协议:
- 可以使用方法调用协议方法send()。
- 可以使用方法订阅协议事件
on()。
可以在此处找到有关 DevTools 协议的文档 。
协程detach( ) → 无[来源]
从目标中分离会话。
一旦分离,会话将不会发出任何事件,也不能用于发送消息。
send(方法:str,参数:dict = None ) → Awaitable[T_co][来源]
向连接的会话发送消息。
| 参数: |
|
|---|
21.Coverage类
类pyppeteer.coverage.Coverage(客户端:pyppeteer.connection.CDPSession )[来源]
基类:object
Coverage类。
Coverage 收集有关页面使用的 JavaScript 和 CSS 部分的信息。
使用 JavaScript 和 CSS 覆盖率获取初始执行代码百分比的示例:
# Enable both JavaScript and CSS coverage
await page.coverage.startJSCoverage()
await page.coverage.startCSSCoverage()# Navigate to page
await page.goto('https://example.com')
# Disable JS and CSS coverage and get results
jsCoverage = await page.coverage.stopJSCoverage()
cssCoverage = await page.coverage.stopCSSCoverage()
totalBytes = 0
usedBytes = 0
coverage = jsCoverage + cssCoverage
for entry in coverage:totalBytes += len(entry['text'])for range in entry['ranges']:usedBytes += range['end'] - range['start'] - 1print('Bytes used: {}%'.format(usedBytes / totalBytes * 100))
协程startCSSCoverage(选项:Dict[KT,VT] = None,**kwargs ) →无[来源]
开始 CSS 覆盖测量。
可用的选项是:
resetOnNavigation(bool): 是否重置每次导航的覆盖范围。默认为True.
协程startJSCoverage(选项:Dict[KT,VT] = None,**kwargs ) →无[来源]
开始 JS 覆盖测量。
可用的选项是:
resetOnNavigation(bool): 是否重置每次导航的覆盖范围。默认为True.reportAnonymousScript(bool): 页面生成的匿名脚本是否应该被报告。默认为False.
笔记
匿名脚本是那些没有关联 url 的脚本。这些是使用eval . 如果设置为 ,匿名脚本将作为 它们的 url。new FunctionreportAnonymousScriptTrue__pyppeteer_evaluation_script__
协程stopCSSCoverage( ) → 列表[T][来源]
停止 CSS 覆盖测量并获得结果。
返回所有非匿名脚本的覆盖率报告列表。每份报告包括:
url(str):样式表 url。text(str):样式表内容。ranges(List[Dict]):已执行的样式表范围。范围已排序且不重叠。start(int): 文本中的起始偏移量,包括在内。end(int): 文本中的结束偏移量,独占。
笔记
CSS 覆盖范围不包括没有 sourceURL 的动态注入样式标签(但目前包括……待修复)。
协程stopJSCoverage( ) → 列表[T][来源]
停止 JS 覆盖测量并获得结果。
返回所有脚本的覆盖率报告列表。每份报告包括:
url(str): 脚本 url。text(str):脚本内容。ranges(List[Dict]):已执行的脚本范围。范围已排序且不重叠。start(int): 文本中的起始偏移量,包括在内。end(int): 文本中的结束偏移量,独占。
笔记
默认情况下,JavaScript 覆盖范围不包括匿名脚本。但是,会报告带有 sourceURL 的脚本。
22.调试
对于调试,您可以为 和功能设置logLevel选项 。但是,此选项会打印太多日志,包括 pyppeteer 的 SEND/RECV 消息。为了只显示被抑制的错误消息,您应该设置为.logging.DEBUGpyppeteer.launcher.launch()pyppeteer.launcher.connect()pyppeteer.DEBUGTrue
例子:
import asyncio import pyppeteer from pyppeteer import launchpyppeteer.DEBUG = True # print suppressed errors as error logasync def main():browser = await launch()... # do somethingasyncio.get_event_loop().run_until_complete(main()
23.补充
puppeteer JavaScript(无头)chrome/chromium 浏览器自动化库的非官方 Python 端口 。
- 免费软件:MIT 许可证(包括在 Apache 2.0 许可证下分发的作品)
- 文档: https: //miyakogi.github.io/pyppeteer
安装
Pyppeteer 需要 python 3.6+。(实验支持python 3.5)
从 PyPI 通过 pip 安装:
python3 -m pip install pyppeteer
或者从github安装最新版本:
python3 -m pip install -U git+https://github.com/miyakogi/pyppeteer.git@dev
用法
注意:当您第一次运行 pyppeteer 时,它会下载最新版本的 Chromium(~100MB)。如果您不喜欢这种行为,请
pyppeteer-install在运行使用 pyppeteer 的脚本之前运行命令。
示例:打开网页并截取屏幕截图。
import asyncio
from pyppeteer import launchasync def main():browser = await launch()page = await browser.newPage()await page.goto('http://example.com')await page.screenshot({'path': 'example.png'})await browser.close()asyncio.get_event_loop().run_until_complete(main())
示例:评估页面上的脚本。
import asyncio
from pyppeteer import launchasync def main():browser = await launch()page = await browser.newPage()await page.goto('http://example.com')await page.screenshot({'path': 'example.png'})dimensions = await page.evaluate('''() => {return {width: document.documentElement.clientWidth,height: document.documentElement.clientHeight,deviceScaleFactor: window.devicePixelRatio,}}''')print(dimensions)# >>> {'width': 800, 'height': 600, 'deviceScaleFactor': 1}await browser.close()asyncio.get_event_loop().run_until_complete(main())
Pyppeteer 具有与 puppeteer 几乎相同的 API。文档中列出了更多 API 。
Puppeteer 的文档 和故障排除对 pyppeteer 用户也很有用。
puppeteer 和 pyppeteer 之间的区别
Pyppeteer 是要和 puppeteer 一样相似,但是 python 和 JavaScript 之间的一些差异使它变得困难。
这些是 puppeteer 和 pyppeteer 之间的区别。
选项的关键字参数
Puppeteer 使用对象(python 中的字典)将选项传递给函数/方法。Pyppeteer 接受选项的字典和关键字参数。
字典样式选项(类似于木偶操纵者):
browser = await launch({'headless': True})
关键字参数样式选项(更像 pythonic,不是吗?):
browser = await launch(headless=True)
元素选择器方法名称 ( $-> querySelector)
在 python 中,$不能用于方法名。所以 pyppeteer 使用Page.querySelector()//而不是 // 。Pyppeteer 也有这些方法的简写,, , 和。Page.querySelectorAll()Page.xpath()Page.$()Page.$$()Page.$x()Page.J()Page.JJ()Page.Jx()
和Page.evaluate() _Page.querySelectorEval()
Puppeteer 的版本evaluate()采用 JavaScript 原始函数或 JavaScript 表达式字符串,但 pyppeteer 采用 JavaScript 字符串。JavaScript 字符串可以是函数或表达式。Pyppeteer 尝试自动检测字符串是函数还是表达式,但有时会失败。如果将表达式字符串视为函数并引发错误,请添加force_expr=True选项,这会强制 pyppeteer 将字符串视为表达式。
获取页面内容的示例:
content = await page.evaluate('document.body.textContent', force_expr=True)
获取元素内部文本的示例:
element = await page.querySelector('h1')
title = await page.evaluate('(element) => element.textContent', element)
未来计划
- 赶上puppeteer的发展
- 不打算添加 puppeteer 没有的原始 API
学分
这个包是用Cookiecutter和audreyr/cookiecutter-pypackage项目模板创建的。
内容
- API参考
- 命令
- 环境变量
- 启动器
- 浏览器类
- BrowserContext 类
- 页面类
- 工人阶级
- 键盘类
- 鼠标类
- 跟踪类
- 对话框类
- ConsoleMessage 类
- 帧类
- 执行上下文类
- JSHandle 类
- 元素句柄类
- 请求类
- 反应等级
- 目标班级
- CDPSession类
- 覆盖等级
- 调试
- 历史
- 版本 0.0.25 (2018-09-27)
- 版本 0.0.24 (2018-09-12)
- 版本 0.0.23 (2018-09-10)
- 版本 0.0.22 (2018-09-06)
- 版本 0.0.21 (2018-08-21)
- 版本 0.0.20 (2018-08-11)
- 版本 0.0.19 (2018-07-05)
- 版本 0.0.18 (2018-07-04)
- 版本 0.0.17 (2018-04-02)
- 版本 0.0.16 (2018-03-23)
- 版本 0.0.15 (2018-03-22)
- 版本 0.0.14 (2018-03-14)
- 版本 0.0.13 (2018-03-10)
- 版本 0.0.12 (2018-03-01)
- 版本 0.0.11 (2018-03-01)
- 版本 0.0.10 (2018-02-27)
相关文章:

pyppeteer中文文档
目录 1.命令 2.环境变量 3.Launcher(启动器) 4.浏览器类 5.浏览器上下文类 6.页面类 7.Worker 类 8.键盘类 9.鼠标类 10.Tracing类 11.对话框类 12.控制台消息类 13.Frame 类 14.执行上下文类 15.JSHandle 类 16.元素句柄类…...
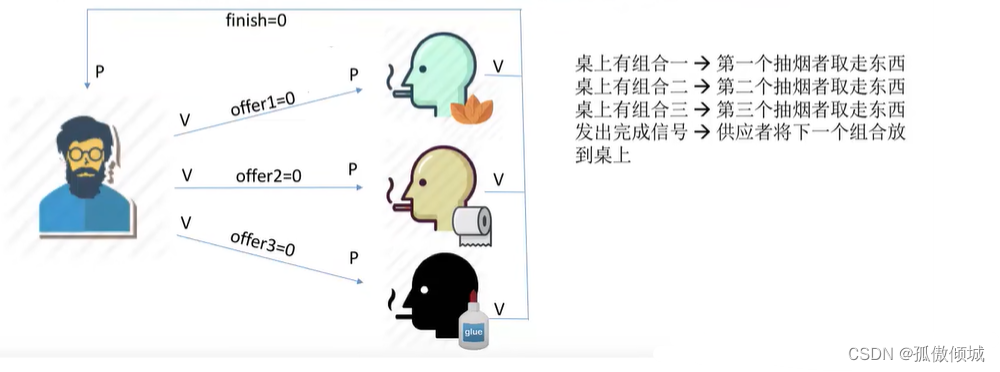
(二十四)操作系统-吸烟者问题
文章目录一、问题描述二、问题分析1.关系分析2.整理思路3.设置信号量三、实现四、总结一、问题描述 假设一个系统有三个抽烟者进程和一个供应者进程。每个抽烟者不停地卷烟并抽掉它,但是要卷起并抽掉一支烟,抽烟者需要…...
ReentranLock(可重入锁)
一、ReentranLock ReentranLock属于JUC并发工具包下的类,相当于 synchronized具备如下特点 ● 可中断 ● 可以设置超时时间 ● 可以设置为公平锁(防止线程出现饥饿的情况) ● 支持多个条件变量 与 synchronized一样,都支持可重…...
)
Kafka 入门 (一)
Kafka 入门(一) Apache Kafka起源于LinkedIn,后来于2011年成为开源Apache项目,然后于2012年成为First-class Apache项目。Kafka是用Scala和Java编写的。 Apache Kafka是基于发布订阅的容错消息系统。 它是快速,可扩展…...
)
linux内核开发入门二(内核KO模块介绍、开发流程以及注意事项)
linux内核开发入门二(内核KO模块介绍、开发流程以及注意事项) 一、什么是内核模块 内核模块:ko模块(Kernel Object Module)是Linux内核中的可加载模块,它可以动态地向内核添加功能。在运行时,可…...
设计模式(十七)----行为型模式之模板方法模式
行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。 行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间分派行为&…...

【嵌入式Linux内核驱动】01_内核模块
内核模块 宏内核&微内核 微内核就是内核中的一部分功能放到应用层 内核小,精简,可扩展性好,安全性好 相互之间通信损耗多 内核模块 Linux是宏内核操作系统的典型代表,所有内核功能都整体编译到一起,优点是效…...
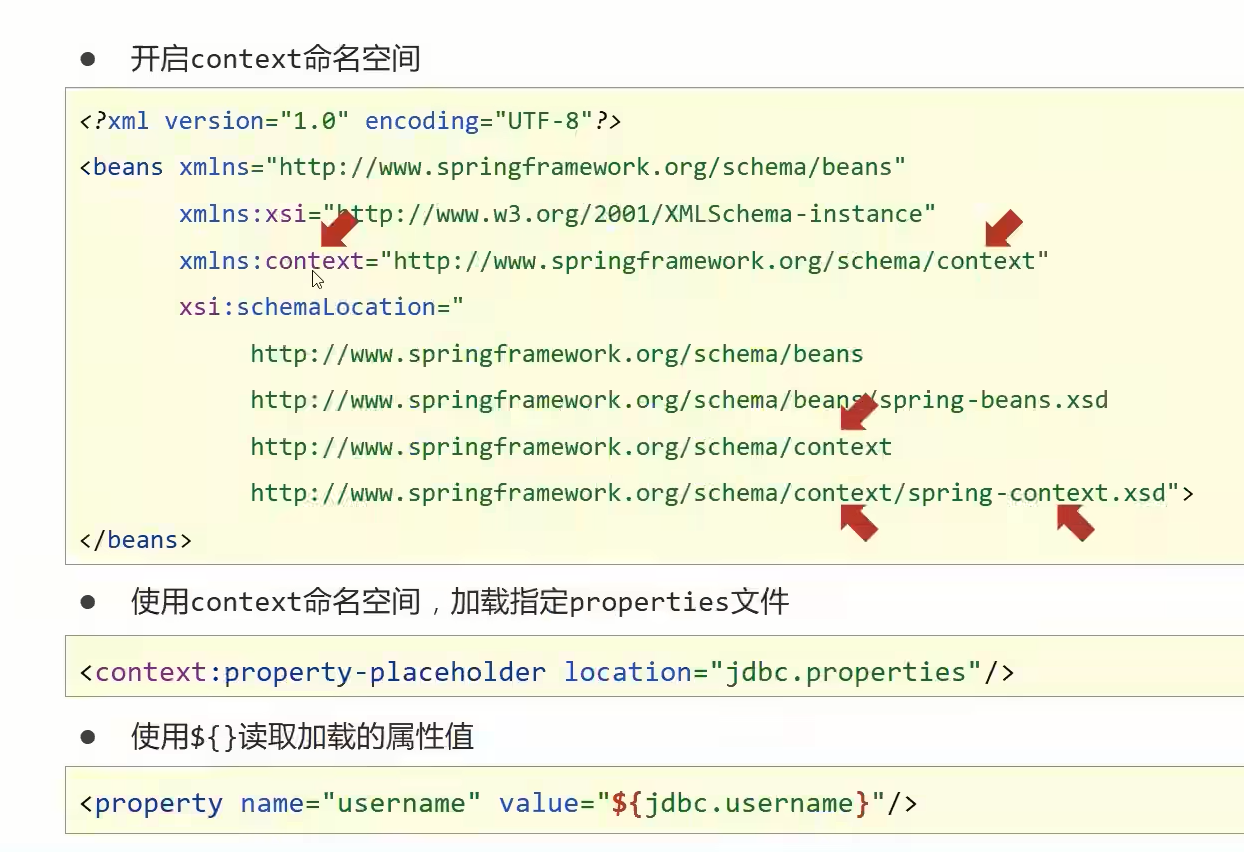
Spring——数据源对象管理和Spring加载properties文件
前面一直都是在管理自己内部创建的对象,这个是管理外部的对象。 这里先使用阿里巴巴的druid来演示。需要在pom.xml中添加如下的依赖 <dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1…...
Zeek安装、使用与压力测试
Zeek安装与压力测试Zeek安装、简单使用与压力测试环境Zeek安装zeek简单运行安装PF_RING修改Zeek配置文件,使用PF_RING,实现集群流量压力测试查看zeek日志Zeek安装、简单使用与压力测试 科研需要,涉及到Zeek的安装、使用和重放流量压力测试评…...

【javaEE初阶】第三节.多线程 (进阶篇 ) 死锁
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、"死锁"出现的典型场景二、产生 "死锁" 的必要条件 三、解决 "死锁" 问题的办法 总结前言 今天对于多线程进阶的学习&#…...
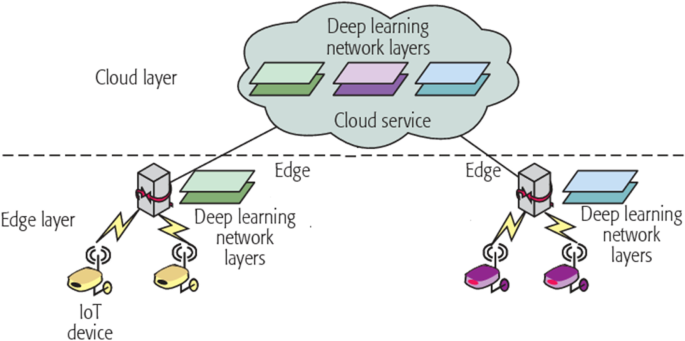
基于密集连接的轻量级卷积神经网络,用于使用边云架构的露天煤矿服务识别
遥感是快速检测非法采矿行为的重要技术工具。由于露天煤矿的复杂性,目前关于露天煤矿自动开采的研究较少。基于卷积神经网络和Dense Block,我们提出了一种用于从Sentinel-2遥感图像中提取露天煤矿区域的轻量级密集连接网络-AD-Net,并构建了三…...

无刷高速风筒方案介绍--【PCBA方案】
疫情三年过去,春节后,一个新的开始,大家满怀希望畅谈今年好气象。 三年来一波一波的封城、隔离、核酸,经济压抑到了无以复加的地步,也导致了诸多社会问题的出现。消费力被磨平,人们小心翼翼的生活。 常跟…...

花括号展开II[栈模拟dfs]
栈模拟dfs前言一、花括号展开II二、栈模拟dfs总结参考资料前言 递归调用,代码非常的简洁。但是可以通过显式栈来模拟栈中的内容,锻炼自己的代码能力,清楚知道栈帧中需要的内容。 一、花括号展开II 二、栈模拟dfs 每碰到一个左括号…...
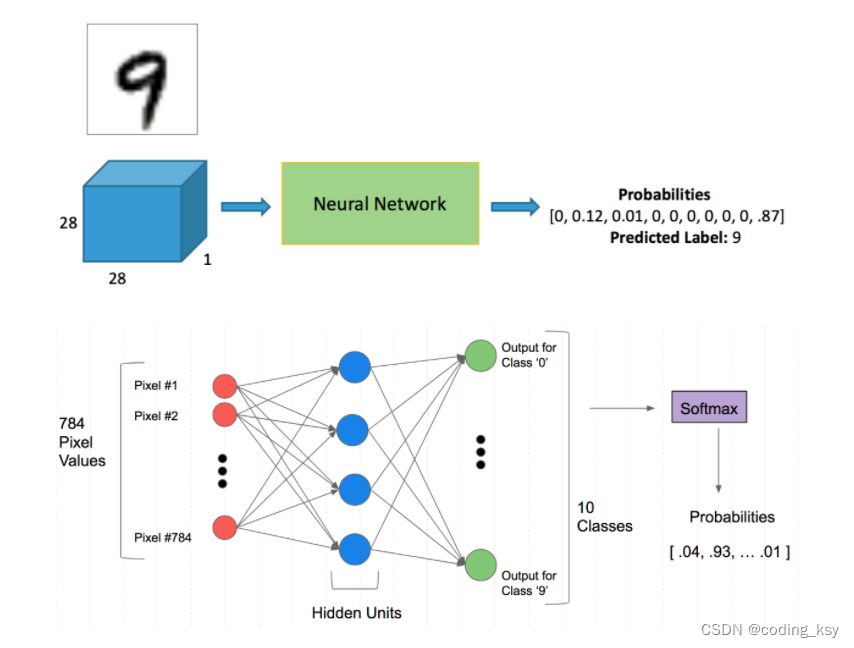
神经网络分类任务(手写数字识别)
1.Mnist分类任务 网络基本构建与训练方法,常用函数解析 torch.nn.functional模块 nn.Module模块 学习方法:边用边查,多打印,duogua 使用jupyter的优点,可以打印出每一个步骤。 2.读取数据集 自动下载 %matplotl…...
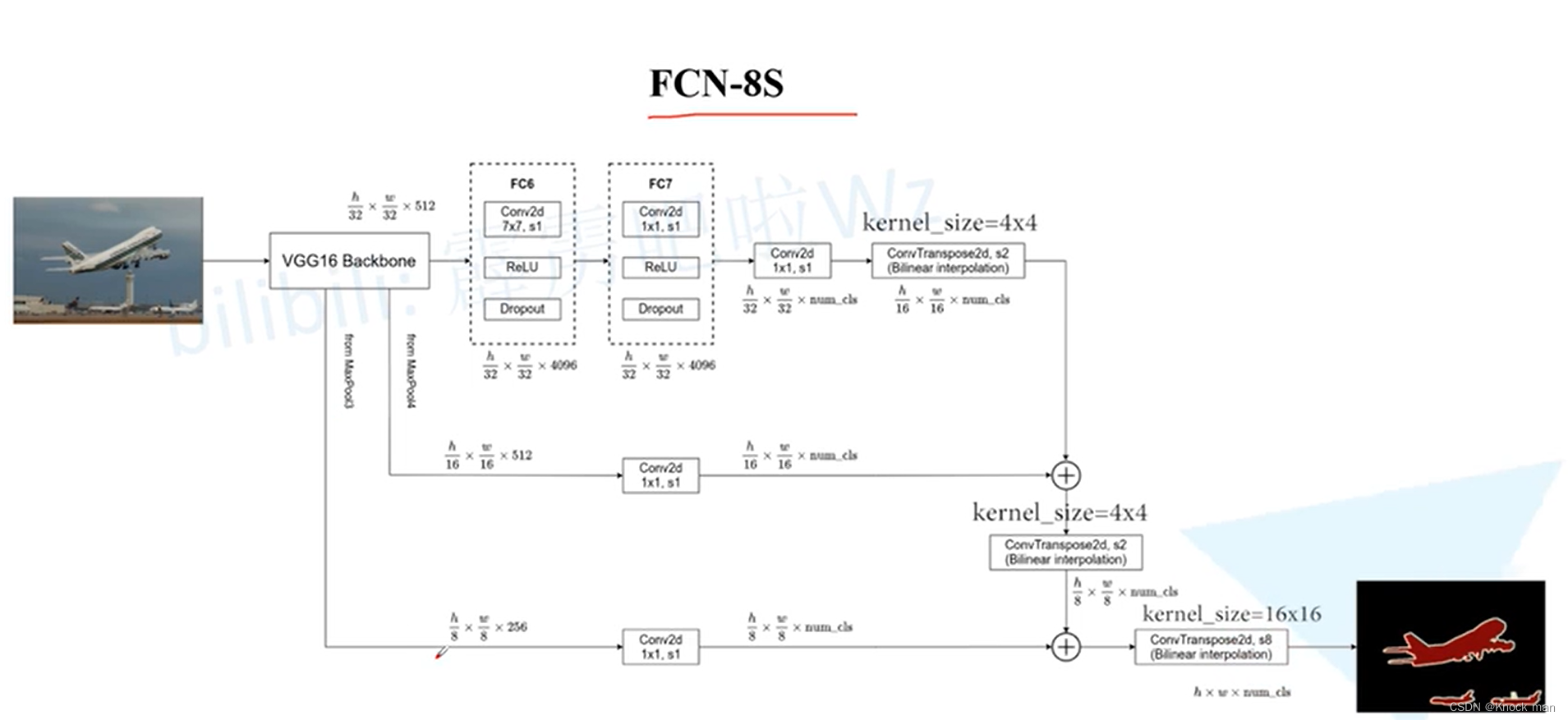
FCN网络(Fully Convolutional Networks)
首个端到端的针对像素级预测的全卷积网络 原理:将图片进行多次卷积下采样得到chanel为21的特征层,再经过上采样得到和原图一样大的图片,最后经过softmax得到类别概率值 将全连接层全部变成卷积层:通常的图像分类网络最后几层是全…...

随想录二刷Day15——二叉树
文章目录二叉树2. 递归遍历二叉树3. 二叉树的迭代遍历4. 二叉树的统一迭代法二叉树 2. 递归遍历二叉树 144. 二叉树的前序遍历 class Solution { public:vector<int> preorderTraversal(TreeNode* root) {vector<int> result;preorder(root, result);return res…...

docker-compose部署kafka服务时如何同时允许内外网访问?
背景 最近在学习kafka相关知识,需要搭建自己的kafka环境。综合考虑后决定使用docker-compose来管理维护这个环境。 docker-compose.yml Bitnami的yml文件就很不错,这里直接拿来用了。 version: "2"services:zookeeper:image: docker.io/bi…...
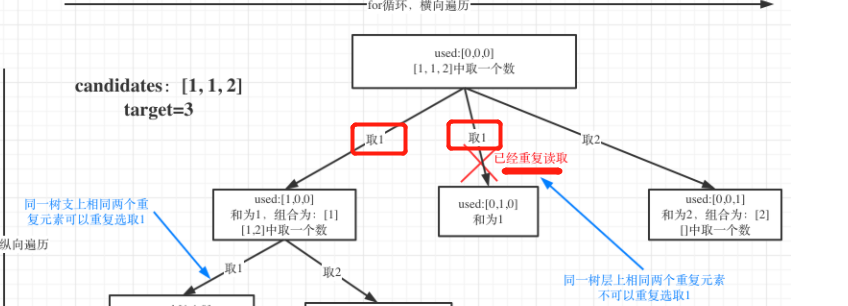
数据结构刷题(二十):17电话号码的字母组合、39组合总和、40组合总和II
一、电话号码的字母组合题目链接思路:回溯三部曲。确定回溯函数参数:题目中给的 digits,还要有一个参数就是int型的index(记录遍历第几个数字,就是用来遍历digits的,同时也代表了递归的深度)&am…...
)
Java面试总结(五)
sleep() 方法和 wait() 方法对比 相同点 两者都可以暂停线程的执行;两者都可以响应中断。 不同点 sleep()方法不会释放锁,wait()方法会释放锁; sleep()方法主要用于暂停线程的执行,wait()方法主要用于线程之间的交互/通信&…...
三维人脸实践:基于Face3D的渲染、生成与重构 <二>
face3d: Python tools for processing 3D face git code: https://github.com/yfeng95/face3d paper list: PaperWithCode 3DMM方法,基于平均人脸模型,可广泛用于基于关键点的人脸生成、位姿检测以及渲染等,能够快速实现人脸建模与渲染。推…...

CosyVoice多语言语音合成体验:支持中英日韩粤,一键生成
CosyVoice多语言语音合成体验:支持中英日韩粤,一键生成 1. 开篇:语音合成新体验 想象一下,你正在制作一个面向全球市场的产品宣传视频,需要中文、英文、日语、韩语和粤语五种语言的配音。传统方式需要找五位不同语种…...

5倍效率提升!Marker让PDF转Markdown零格式丢失的全场景指南
5倍效率提升!Marker让PDF转Markdown零格式丢失的全场景指南 【免费下载链接】marker 一个高效、准确的工具,能够将 PDF 和图像快速转换为 Markdown、JSON 和 HTML 格式,支持多语言和复杂布局处理,可选集成 LLM 提升精度࿰…...

OFA模型处理C语言文件读写操作生成的流程图描述
OFA模型处理C语言文件读写操作生成的流程图描述 最近在整理编程教学资料时,我遇到了一个挺有意思的需求:手头有一堆描述C语言文件读写操作的流程图,需要为每一张图配上清晰、准确的文字说明。这活儿听起来简单,做起来却挺费神&am…...

Emu3.5:vision、text 的vocab id 体系
Emu3.5 中视觉与语言 ID 体系的完整分析报告 https://huggingface.co/BAAI/Emu3.5 1. 报告目的 本文专门回答一个问题: Emu3.5 中,图片在进入大模型之前,视觉 tokenizer 的离散索引、视觉 special token 字符串、以及 LLM 最终接收的统一词表整数 id,三者之间到底是什么…...

OpenClaw飞书机器人配置:Qwen3-32B私有镜像对话触发详解
OpenClaw飞书机器人配置:Qwen3-32B私有镜像对话触发详解 1. 为什么选择OpenClaw飞书Qwen3-32B组合 去年底我开始尝试用AI自动化处理团队日常事务时,发现市面上大多数方案要么需要将敏感数据上传到第三方平台,要么只能完成简单的问答交互。直…...

快速掌握Clarke与Park变换的几何本质
1. 从三相坐标系到静止两相系的几何之旅 想象一下你站在一个布满彩色灯带的游乐场中央,头顶有三盏呈120度分布的聚光灯(A、B、C相),它们交替明暗形成旋转的光影。Clarke变换就像给你戴上一副特殊眼镜,能将三盏灯的光影…...

3个维度突破股票数据获取难题:MOOTDX量化分析实战指南
3个维度突破股票数据获取难题:MOOTDX量化分析实战指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 作为量化投资和金融数据分析的核心基础设施,稳定、高效、低成本的股票…...

FatFileSystem:面向资源受限MCU的轻量级FAT文件系统
1. FatFileSystem 嵌入式 FAT 文件系统库深度解析FatFileSystem 是一个轻量级、可移植的嵌入式 FAT 文件系统实现,专为资源受限的微控制器环境设计。它并非完整重写的 FAT32 标准栈(如 FatFs),而是对经典开源 FAT 实现的精简裁剪与…...

如何用MAT修复老照片?3个实用技巧让破损图像重获新生
如何用MAT修复老照片?3个实用技巧让破损图像重获新生 【免费下载链接】MAT MAT: Mask-Aware Transformer for Large Hole Image Inpainting 项目地址: https://gitcode.com/gh_mirrors/ma/MAT 想象一下,你从祖辈那里继承了一张珍贵的黑白老照片&a…...

【Unity3D】从零打造动态天空盒:Cubemap生成与实时环境映射实战
1. 动态天空盒的核心原理与场景价值 第一次在Unity里看到动态天空盒效果时,我盯着屏幕愣了三秒——云层在头顶流动,夕阳的光影实时投射在建筑表面,整个场景瞬间有了生命力。这种魔法般的体验,其实都建立在立方体贴图(C…...