Kafka和Spark Streaming的组合使用学习笔记(Spark 3.5.1)
一、安装Kafka
1.执行以下命令完成Kafka的安装:
cd ~ //默认压缩包放在根目录
sudo tar -zxf kafka_2.12-2.6.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.12-2.6.0 kafka-2.6.0
sudo chown -R qiangzi ./kafka-2.6.0二、启动Kafaka
1.首先需要启动Kafka,打开一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka-2.6.0
./bin/zookeeper-server-start.sh config/zookeeper.properties
注意:以上现象是Zookeeper服务器已经启动,正在处于服务状态。不要关闭!
2.打开第二个终端,输入下面命令启动Kafka服务:
cd /usr/local/kafka-2.6.0
./bin/kafka-server-start.sh config/server.properties//加了“&”的命令,Kafka就会在后台运行,即使关闭了这个终端,Kafka也会一直在后台运行。
bin/kafka-server-start.sh config/server.properties &
注意:同样不要误以为死机了,而是Kafka服务器已经启动,正在处于服务状态。
三、创建Topic
1.再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsender”的Topic:
cd /usr/local/kafka-2.6.0
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wordsender2.然后,可以执行如下命令,查看名称为“wordsender”的Topic是否已经成功创建:
./bin/kafka-topics.sh --list --zookeeper localhost:2181
3.再新开一个终端(记作“监控输入终端”),执行如下命令监控Kafka收到的文本:
cd /usr/local/kafka-2.6.0
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic wordsender注意,所有这些终端窗口都不要关闭,要继续留着后面使用。
四、Spark准备工作
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件),因此,需要为Spark添加相关jar包。访问MVNREPOSITORY官网(http://mvnrepository.com),下载spark-streaming-kafka-0-10_2.12-3.5.1.jar和spark-token-provider-kafka-0-10_2.12-3.5.1.jar文件,其中,2.12表示Scala的版本号,3.5.1表示Spark版本号。然后,把这两个文件复制到Spark目录的jars目录下(即“/usr/local/spark-3.5.1/jars”目录)。此外,还需要把“/usr/local/kafka-2.6.0/libs”目录下的kafka-clients-2.6.0.jar文件复制到Spark目录的jars目录下。
cd ~ .jar文件默认放在根目录
sudo mv ./spark-streaming-kafka-0-10_2.12-3.5.1.jar /usr/local/spark-3.5.1/jars/
sudo mv ./spark-token-provider-kafka-0-10_2.12-3.5.1.jar /usr/local/spark-3.5.1/jars/
sudo cp /usr/local/kafka-2.6.0/libs/kafka-clients-2.6.0.jar /usr/local/spark-3.5.1/jars/spark-streaming-kafka-0-10_2.12-3.5.1.jar的下载页面:
Maven Repository: org.apache.spark » spark-streaming-kafka-0-10_2.12 » 3.5.1 (mvnrepository.com)
spark-streaming-kafka-0-10_2.12-3.5.1.jar的下载页面:
Maven Repository: org.apache.spark » spark-token-provider-kafka-0-10_2.12 » 3.5.1 (mvnrepository.com)
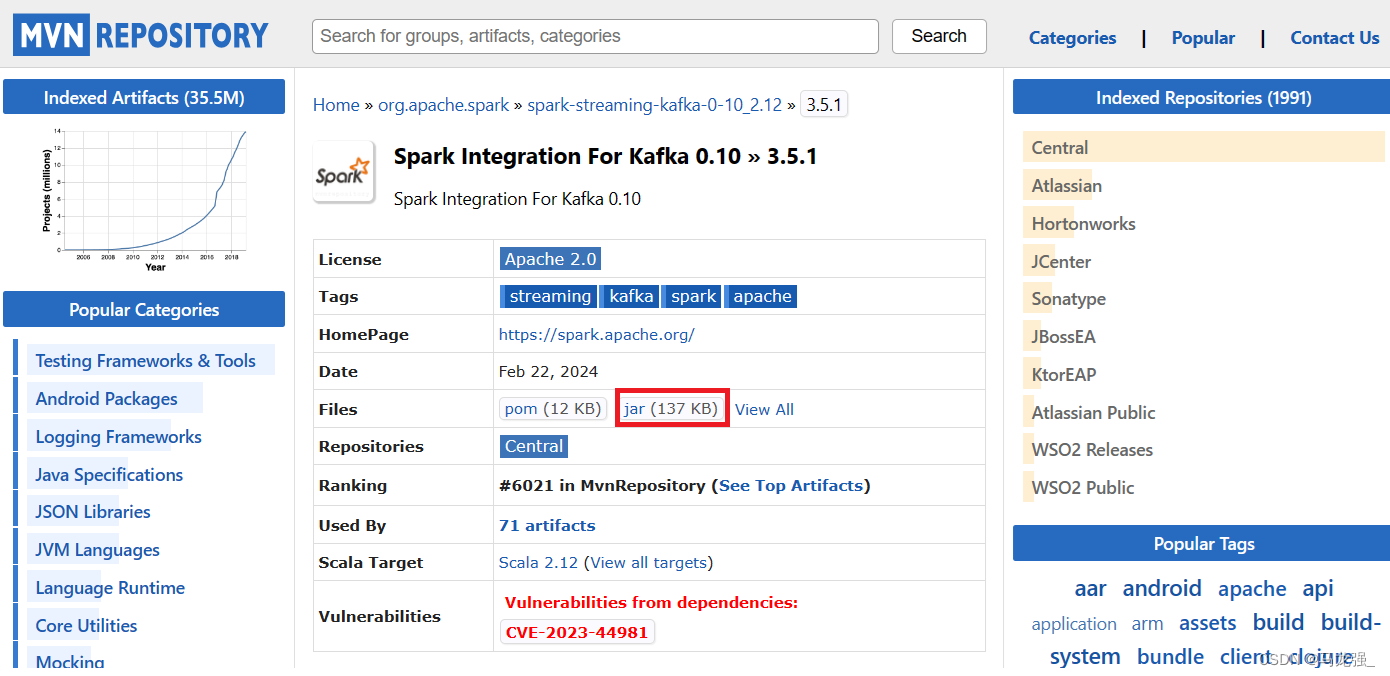
进入下载页面以后,如下图所示,点击红色方框内的“jar”,就可以下载JAR包了。
五、编写Spark Streaming程序使用Kafka数据源
1.编写生产者(Producer)程序
(1)新打开一个终端,然后,执行如下命令创建代码目录和代码文件:
cd /usr/local/spark-3.5.1
mkdir mycode
cd ./mycode
mkdir kafka
mkdir -p kafka/src/main/scala
vi kafka/src/main/scala/KafkaWordProducer.scala(2)使用vi编辑器新建了KafkaWordProducer.scala
它是用来产生一系列字符串的程序,会产生随机的整数序列,每个整数被当作一个单词,提供给KafkaWordCount程序去进行词频统计。请在KafkaWordProducer.scala中输入以下代码:
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object KafkaWordProducer {def main(args: Array[String]) {if (args.length < 4) {System.err.println("Usage: KafkaWordProducer <metadataBrokerList> <topic> " +"<messagesPerSec> <wordsPerMessage>")System.exit(1)}val Array(brokers, topic, messagesPerSec, wordsPerMessage) = args// Zookeeper connection propertiesval props = new HashMap[String, Object]()props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)// Send some messageswhile(true) {(1 to messagesPerSec.toInt).foreach { messageNum =>val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).
toString).mkString(" ")print(str)println()val message = new ProducerRecord[String, String](topic, null, str)producer.send(message)}Thread.sleep(1000)}}
}2.编写消费者(Consumer)程序
在“/usr/local/spark-3.5.1/mycode/kafka/src/main/scala”目录下创建文件KafkaWordCount.scala,用于单词词频统计,它会把KafkaWordProducer发送过来的单词进行词频统计,代码内容如下:
cd /usr/local/spark-3.5.1/mycode
vi kafka/src/main/scala/KafkaWordCount.scalaimport org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribeobject KafkaWordCount{def main(args:Array[String]){val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")val sc = new SparkContext(sparkConf)sc.setLogLevel("ERROR")val ssc = new StreamingContext(sc,Seconds(10))ssc.checkpoint("file:///usr/local/spark-3.5.1/mycode/kafka/checkpoint") //设置检查点,如果存放在HDFS上面,则写成类似ssc.checkpoint("/user/hadoop/checkpoint")这种形式,但是,要启动Hadoopval kafkaParams = Map[String, Object]("bootstrap.servers" -> "localhost:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "use_a_separate_group_id_for_each_stream","auto.offset.reset" -> "latest","enable.auto.commit" -> (true: java.lang.Boolean))val topics = Array("wordsender")val stream = KafkaUtils.createDirectStream[String, String](ssc,PreferConsistent,Subscribe[String, String](topics, kafkaParams))stream.foreachRDD(rdd => {val offsetRange = rdd.asInstanceOf[HasOffsetRanges].offsetRangesval maped: RDD[(String, String)] = rdd.map(record => (record.key,record.value))val lines = maped.map(_._2)val words = lines.flatMap(_.split(" "))val pair = words.map(x => (x,1))val wordCounts = pair.reduceByKey(_+_)wordCounts.foreach(println)})ssc.startssc.awaitTermination}
}3.在路径“file:///usr/local/spark/mycode/kafka/”下创建“checkpoint”目录作为预写式日志的存放路径。
cd ./kafka
mkdir checkpoint4.继续在当前目录下创建StreamingExamples.scala代码文件,用于设置log4j:
cd /usr/local/spark-3.5.1/mycode/
vi kafka/src/main/scala/StreamingExamples.scala/*StreamingExamples.scala*/
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger} /** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {/** Set reasonable logging levels for streaming if the user has not configured log4j. */def setStreamingLogLevels() {val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElementsif (!log4jInitialized) {// We first log something to initialize Spark's default logging, then we override the// logging level.logInfo("Setting log level to [WARN] for streaming example." +" To override add a custom log4j.properties to the classpath.")Logger.getRootLogger.setLevel(Level.WARN)} } } 5.编译打包程序
现在在“/usr/local/spark-3.5.1/mycode/kafka/src/main/scala”目录下,就有了如下3个scala文件:

然后,执行下面命令新建一个simple.sbt文件:
cd /usr/local/spark-3.5.1/mycode/kafka/
vim simple.sbt在simple.sbt中输入以下代码:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.18"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.5.1" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.5.1"
libraryDependencies += "org.apache.kafka" % "kafka-clients" % "2.6.0"然后执行下面命令,进行编译打包:
cd /usr/local/spark-3.5.1/mycode/kafka/
/usr/local/sbt-1.9.0/sbt/sbt package打包成功界面
6. 运行程序
首先,启动Hadoop,因为如果前面KafkaWordCount.scala代码文件中采用了ssc.checkpoint
("/user/hadoop/checkpoint")这种形式,这时的检查点是被写入HDFS,因此需要启动Hadoop。启动Hadoop的命令如下:
cd /usr/local/hadoop-2.10.1
./sbin/start-dfs.sh
或者
start-dfs.sh
start-yarn.sh启动Hadoop成功以后,就可以测试刚才生成的词频统计程序了。
要注意,之前已经启动了Zookeeper服务和Kafka服务,因为之前那些终端窗口都没有关闭,所以,这些服务一直都在运行。如果不小心关闭了之前的终端窗口,那就参照前面的内容,再次启动Zookeeper服务,启动Kafka服务。
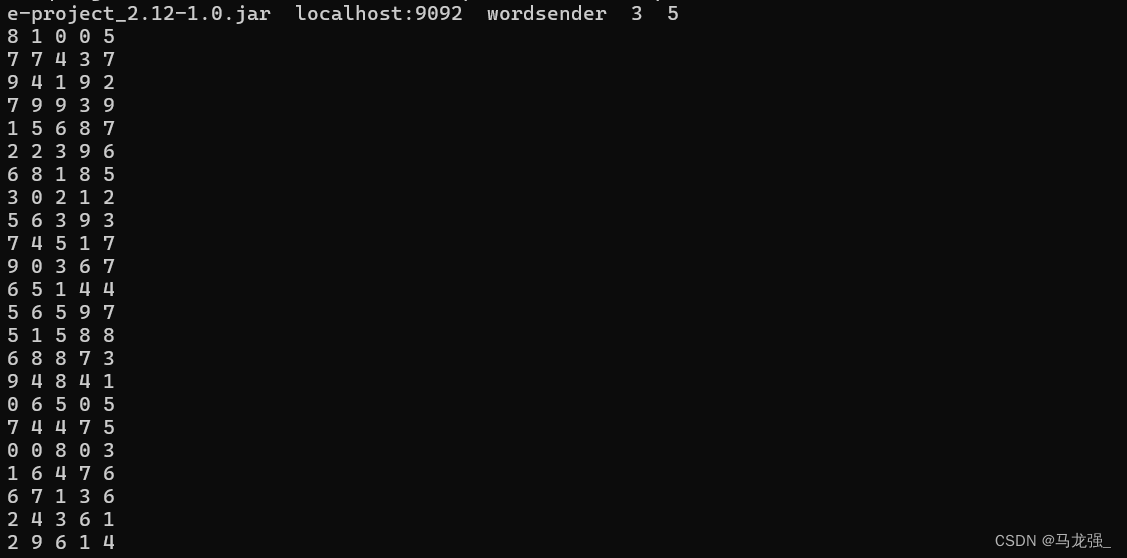
然后,新打开一个终端,执行如下命令,运行“KafkaWordProducer”程序,生成一些单词(是一堆整数形式的单词):
cd /usr/local/spark-3.5.1/mycode/kafka/
/usr/local/spark-3.5.1/bin/spark-submit --class "KafkaWordProducer" ./target/scala-2.12/sime-project_2.12-1.0.jar localhost:9092 wordsender 3 5注意,上面命令中,“localhost:9092 wordsender 3 5”是提供给KafkaWordProducer程序的4个输入参数,第1个参数“localhost:9092”是Kafka的Broker的地址,第2个参数“wordsender”是Topic的名称,我们在KafkaWordCount.scala代码中已经把Topic名称写死掉,所以,KafkaWordCount程序只能接收名称为“wordsender”的Topic。第3个参数“3”表示每秒发送3条消息,第4个参数“5”表示每条消息包含5个单词(实际上就是5个整数)。
执行上面命令后,屏幕上会不断滚动出现类似如下的新单词:
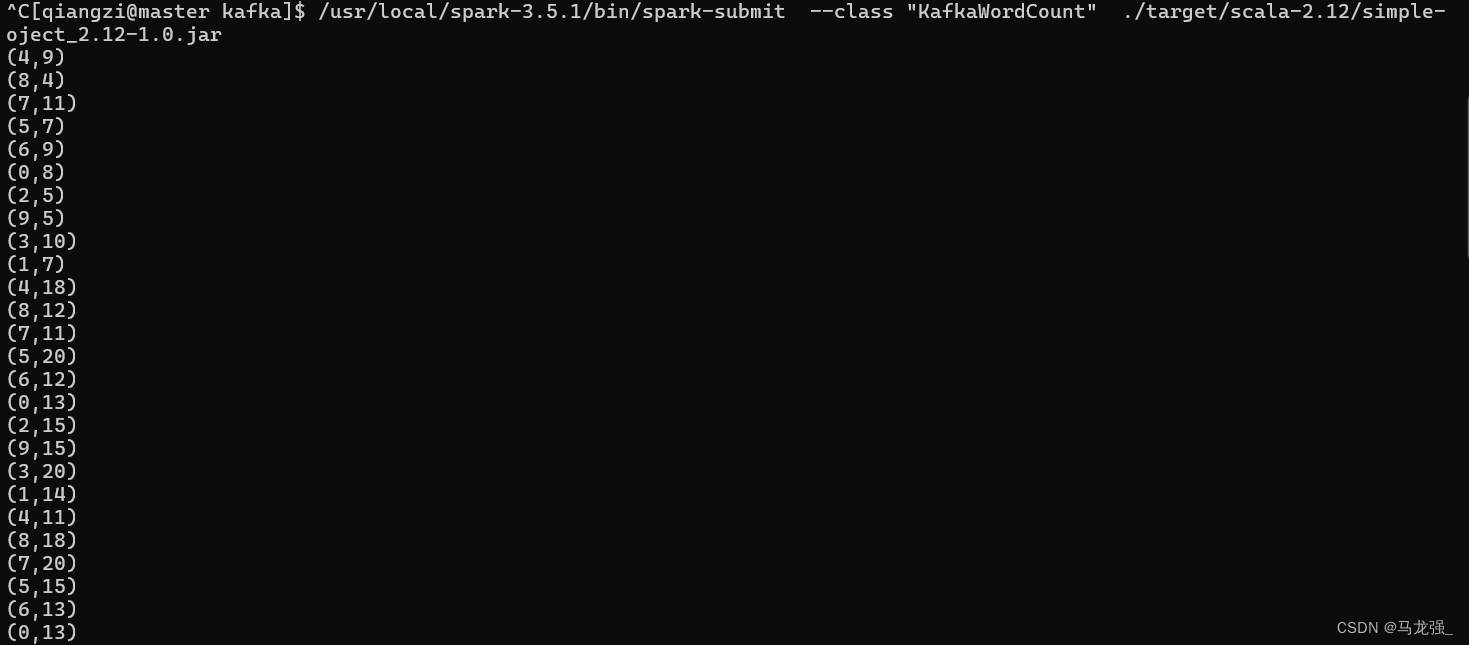
不要关闭这个终端窗口,让它一直不断发送单词。然后,再打开一个终端,执行下面命令,运行KafkaWordCount程序,执行词频统计:
cd /usr/local/spark-3.5.1/mycode/kafka/
/usr/local/spark-3.5.1/bin/spark-submit --class "KafkaWordCount" ./target/scala-2.12/simple-oject_2.12-1.0.jar运行上面命令以后,就启动了词频统计功能,屏幕上就会显示如下类似信息:
相关文章:
Kafka和Spark Streaming的组合使用学习笔记(Spark 3.5.1)
一、安装Kafka 1.执行以下命令完成Kafka的安装: cd ~ //默认压缩包放在根目录 sudo tar -zxf kafka_2.12-2.6.0.tgz -C /usr/local cd /usr/local sudo mv kafka_2.12-2.6.0 kafka-2.6.0 sudo chown -R qiangzi ./kafka-2.6.0 二、启动Kafaka 1.首先需要启动K…...
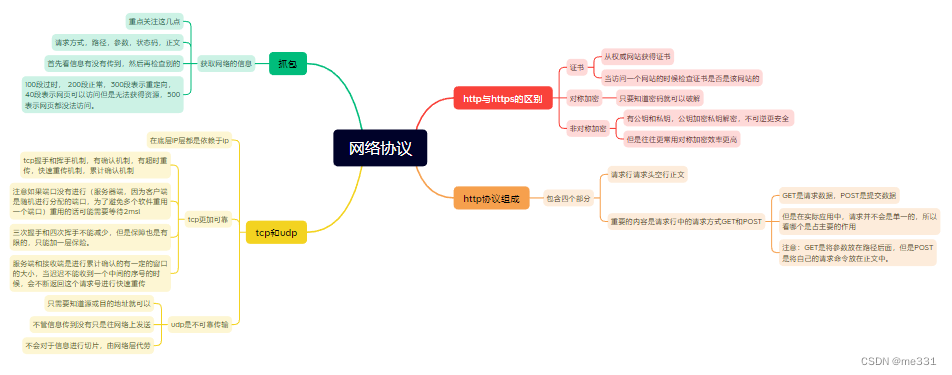
5.9网络协议
由网卡发送数据通过网线进行发送,当网卡接收到信号以后将数据传给内核数据区,然后由操作系统交给相应的进程。 将数据进行发送的时候需要借助于网线实现,这个时候会出现当传输的数据比较远的时候就借助于中继器将信号进行再生扩大࿰…...

QT客户端开发的注意事项
QT客户端开发是一个涉及图形用户界面(GUI)设计、网络编程、数据库交互等多个方面的复杂过程。以下是在进行QT客户端开发时应注意的一些关键事项,通过关注这些事项,可以提高QT客户端应用的质量和开发效率。北京木奇移动技术有限公司…...

k8s源码编译失败:Makefile:1: *** 缺失分隔符。 停止。
目录 问题解决 更换Arch或系统 问题解决 编译k8s源码的kubelet时执行make失败:Makefile:1: *** 缺失分隔符。 停止。 首先,查看文件内容 # cat Makefile build/root/Makefile 修改Makefile,给第一行前增加include,如下&…...

服务器数据恢复—拯救raid5阵列数据行动,raid5数据恢复案例分享
Raid5数据恢复算法原理: 分布式奇偶校验的独立磁盘结构(被称之为raid5)的数据恢复有一个“奇偶校验”的概念。可以简单的理解为二进制运算中的“异或运算”,通常使用的标识是xor。运算规则:若二者值相同则结果为0&…...

旅游集市数仓建设
旅游集市数仓建设 小白如何从0到1成为大数据工程师 目录 旅游集市数仓建设 1.上传数据 2.可能用到的UDF函数 3.创建所需数据库及表 1)ODS层 ①ods_oidd ②ods_wcdr ③ods_ddr ④ods_dpi 2)DWD层 ①dwd_res_regn_mergelocation_msk_d ②dwm_s…...

vue实现点击高亮效果
<view class"tabs"><textv-for"(item, index) in subTypes":key"item.id"class"text":class"{ active: index activeIndex }"//动态绑定高亮类:判断下标是否等于当前下标tap"activeIndex index&…...
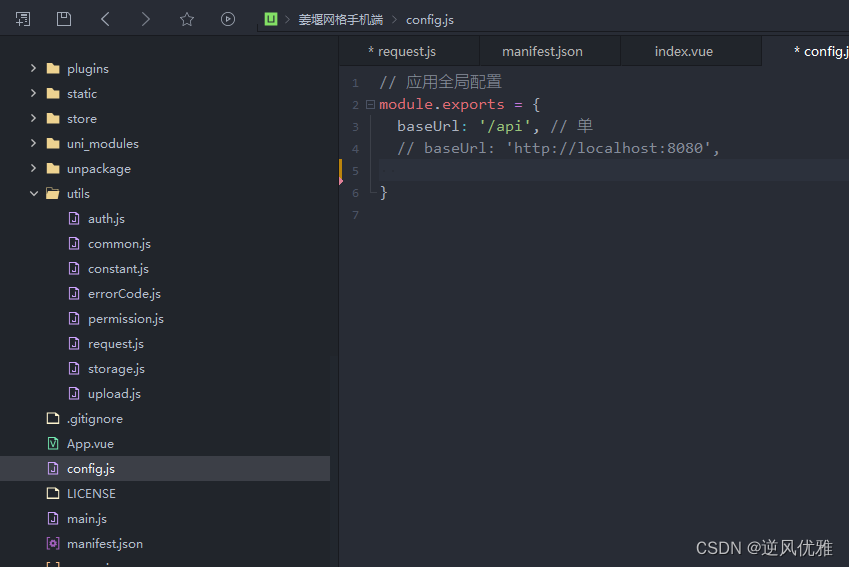
uniapp 配置请求代理+请求封装
uniapp官网提供了三种方式:什么是跨域 | uni-app官网 1. 通过uniapp自带浏览器 打开项目是不存在跨域的 第二种方式: "h5" : {"template" : "static/index.html","devServer": {"proxy": {&quo…...

代码随想录算法训练营第二十八天|216.组合总和III、17.电话号码的字母组合
216.组合总和III 文档讲解:代码随想录 题目链接:. - 力扣(LeetCode) 这一题与昨天的组合差不多,区别就在只有和是目标值的时候才会加入到result数组中,并且在回溯时,会处理sum的值 class Solution:def __i…...
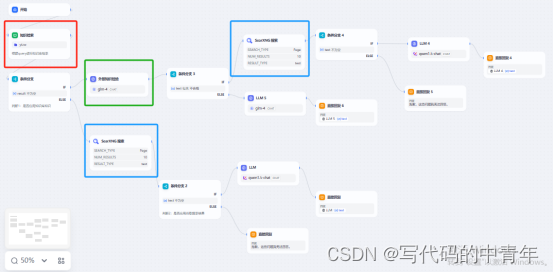
大模型prompt实例:知识库信息质量校验模块
大模型相关目录 大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。 大模型应用向开发路径:AI代理工作流大模型应用开发实用开源项目汇总大模…...

正则表达式和lambda表达式
正则表达式(Regular Expressions)和Lambda表达式虽然都包含“表达式”一词,但它们在编程中的作用和用法是完全不同的。让我们详细比较一下它们的定义、用途和应用场景: 正则表达式 定义:正则表达式是一种用于匹配文本…...
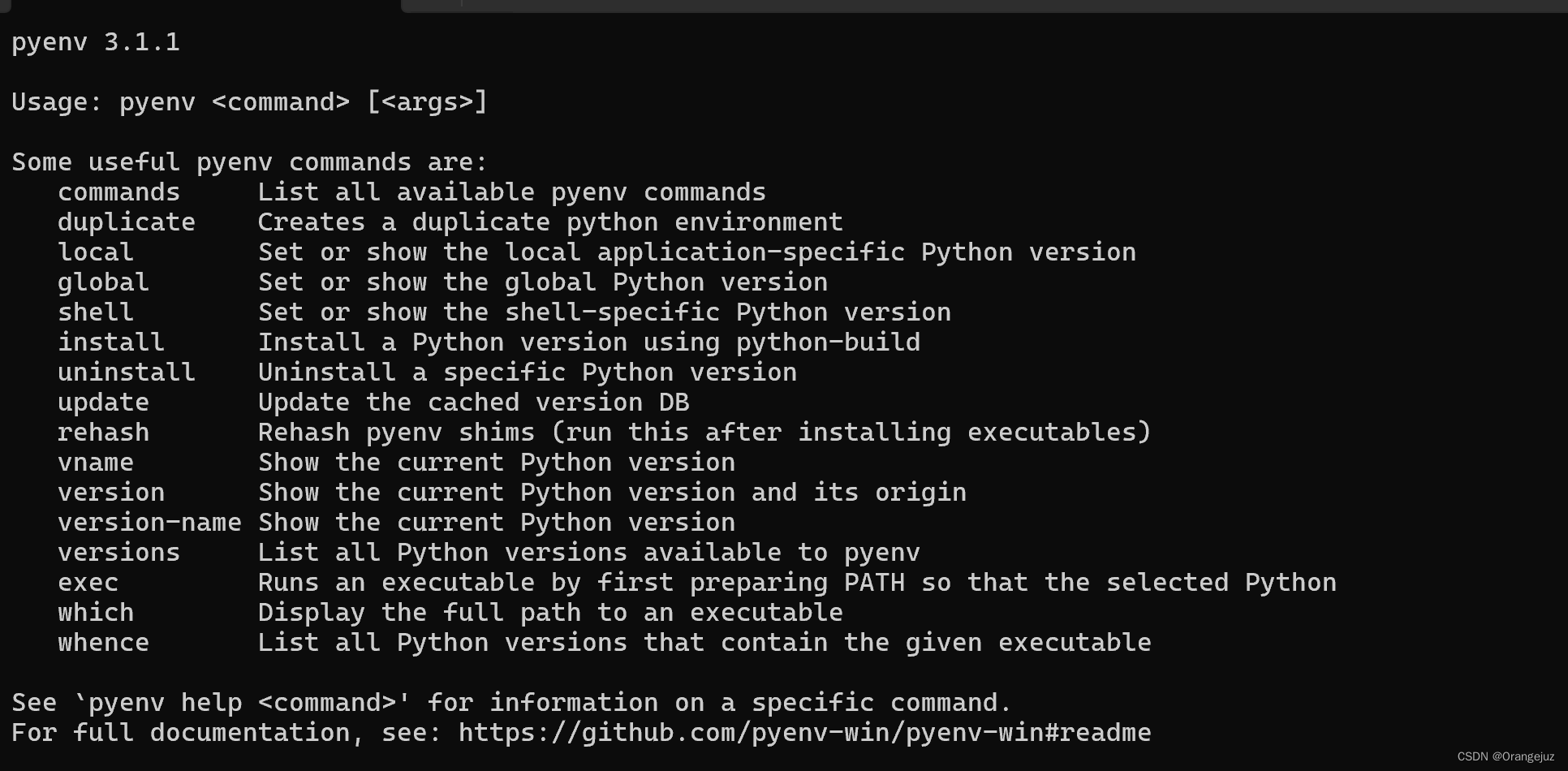
pyenv 之 python 多版本管理(win11)
1. 背景 常常会用到Python的多个版本,因此可以使用Pyenv来对Python版本进行管理。 2. win11下载 pyenv 在终端执行下载语句: pip install pyenv-win --target D:\software\pyenv 其中 D:\software\pyenv 为你想要下载到的文件目录,建议在 …...

nodemon运行ts文件
https://juejin.cn/post/7035637086451400734 nodemon经常用来调试js文件,大家都是知道的,但是用nodemon来调试ts文件,大家试过吗? 如果直接运行nodemon index.ts是会报错的。 ts 复制代码 //index.ts console.log(1) 需要全局…...

内网渗透瑞士军刀-impacket工具解析(二)
impacket工具解析之Kerberos认证协议 上一期我们介绍了impacket中ntlm协议的实现,在Windows认证中除了使用ntlm认证,还支持Kerberos认证协议,Kerberos认证也是Windows 活动目录中占比最高的认证方式。 什么是Kerberos协议? Kerb…...

huggingface 笔记:pipeline
1 介绍 pipeline() 是使用预训练模型进行推理的最简单和最快速的方式。可以针对不同模态的许多任务直接使用 pipeline() 2 举例:情感分析 2.1 创建pipeline实例 from transformers import pipelineclassifier pipeline("sentiment-analysis") #首先创…...
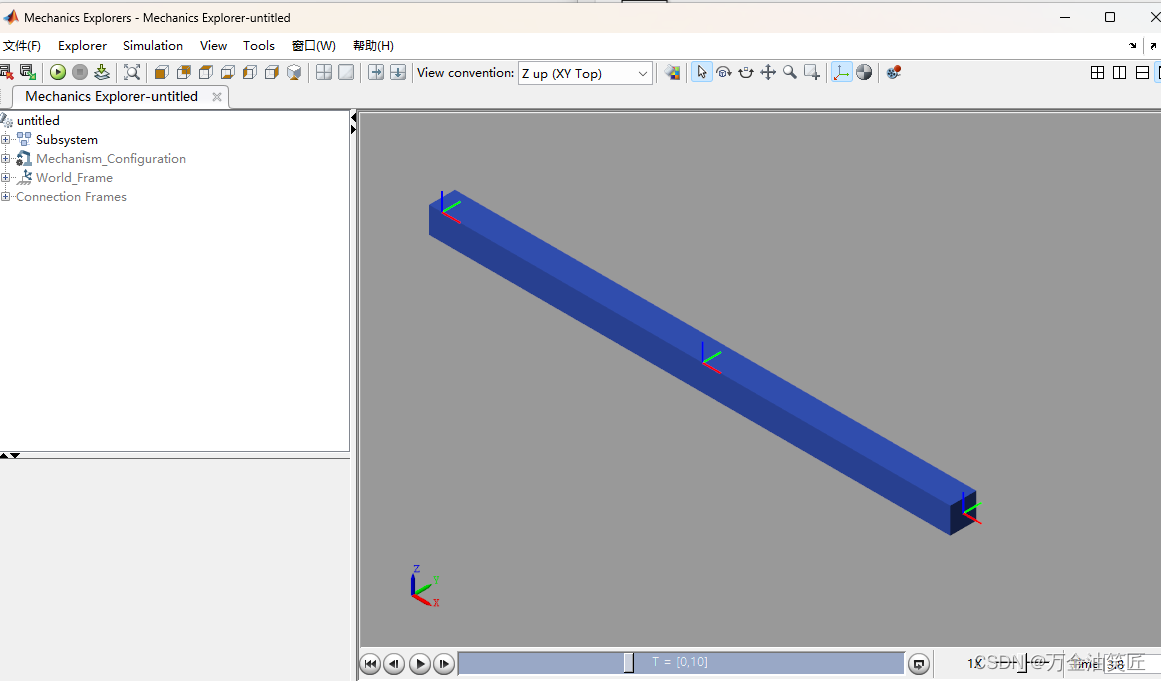
玩转Matlab-Simscape(初级)-01-从一个简单模型开始学习之旅
** 玩转Matlab-Simscape(初级)- 01 - 从一个简单模型开始学习之旅 ** 目录 玩转Matlab-Simscape(初级)- 01 - 从一个简单模型开始学习之旅 前言一、从模板开始建模二、建模一个简单的连杆2.1 建模2.2 生成子系统 总结 前言 在产…...
电脑录屏软件有哪些?这3款神器必须要知道
在当今现代社会,电脑录屏软件已经成为人们日常生活中不可或缺的一部分。无论是录制游戏精彩瞬间、制作教程、还是在线会议记录,一款好用的电脑录屏软件都能帮助我们更高效地完成任务。可是电脑录屏软件有哪些呢?接下来,我们将介绍…...
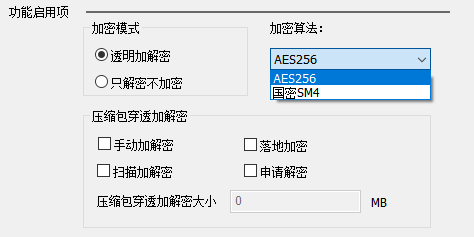
如何在华企盾DSC防泄密系统中设置文件自动加密?
在华企盾DSC系统中设置文件自动加密的过程,简单且用户友好,确保了企业数据的安全,同时不干扰日常工作流程。以下是设置文件自动加密的步骤: 系统安装与配置:确保华企盾DSC数据防泄密系统已经在企业的网络中正确安装和配…...

【DevOps】Dockerfile详解,做自己的docker镜像
学会使用DockerHub找自己想要的镜像以后,我们会很方便的使用一些公用镜像仓库的Docker镜像。但是开发和部署的过程中,能找到的镜像可能并不能满足我们需要,这样我们就需要自己制作Docker镜像。我们通过需要编写一个 Dockerfile,然…...
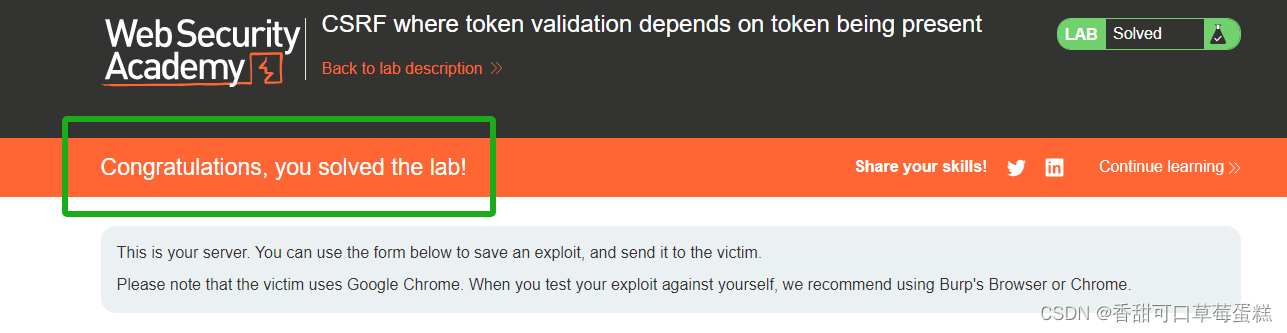
CSRF 攻击实验:Token 不存在绕过验证
前言 CSRF(Cross-Site Request Forgery),也称为XSRF,是一种安全漏洞,攻击者通过欺骗用户在受信任网站上执行非自愿的操作,以实现未经授权的请求。 CSRF攻击利用了网站对用户提交的请求缺乏充分验证和防范…...

思源宋体TTF格式终极指南:免费商用中文字体的完整使用教程
思源宋体TTF格式终极指南:免费商用中文字体的完整使用教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找既专业又免费的中文字体而烦恼吗?…...

3步解锁开源字体编辑器:从零基础到专业字体设计师的蜕变之路
3步解锁开源字体编辑器:从零基础到专业字体设计师的蜕变之路 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge FontForge是一款跨平台的开源字体编辑器&…...

手把手教你用Vivado配置Xilinx SEM IP 3.1:从IP Catalog到Tera Term串口调试全流程
手把手教你用Vivado配置Xilinx SEM IP 3.1:从IP Catalog到Tera Term串口调试全流程 在FPGA开发中,软错误缓解(SEM)IP核是确保设计可靠性的关键组件。对于使用Xilinx Artix-7系列芯片的工程师来说,掌握SEM IP的完整配置…...

3步解决Android Studio英文界面困扰:完整中文插件配置指南
3步解决Android Studio英文界面困扰:完整中文插件配置指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Andr…...

BBDown:专业高效的哔哩哔哩命令行下载器完全指南
BBDown:专业高效的哔哩哔哩命令行下载器完全指南 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown 在当今数字内容消费时代,高效获取和管理在线视频资源已成为许多…...

HD-G2L平台USB存储性能实测:U盘选型与嵌入式系统优化指南
1. 项目概述与测试背景在工业物联网和嵌入式人机界面(HMI)项目的开发中,外部存储设备的读写性能常常是决定系统响应速度和数据吞吐能力的关键一环。想象一下,一个用于生产线数据采集的终端,需要频繁地将传感器日志、操…...

【STM32】GuiLite在HAL库环境下的轻量级GUI移植实战
1. GuiLite框架简介 第一次接触GuiLite是在一个资源紧张的STM32F103项目上,当时需要给设备加个简单的用户界面,但传统的GUI框架动不动就几十KB的代码量实在吃不消。GuiLite这个只有5千行C代码的轻量级框架完美解决了我的痛点。 它的核心优势可以用三个关…...

Claude Code + Superpowers 实战:AI 驱动智能客服管理系统开发
当"会干活的 AI"遇上"会按流程干活的 AI",研发效率的质变由此开始 一、引言:AI 编程的"甜蜜陷阱" 在 AI 编程助手普及的今天,你可能有这样的体验: 让 AI "加个购物车功能",它…...

向量:一篇文章带你看清数学中最有“方向感“的概念
一、先讲一个让我"开窍"的故事 高中时第一次接触向量,老师在黑板上画了一个箭头,说:“这就是向量。” 我看着那个箭头,心想:这有什么稀奇的?不就是带方向的线段吗? 然后老师开始讲向量…...

影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案
影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案 一、问题场景:数据集里混入模糊图,模型效果怎么调都上不去 在图像识别、OCR、人脸识别、商品图审核、视频抽帧数据清洗中,经…...